









 本文详细介绍了PromQL在监控Prometheus数据模型中的应用,涵盖时间序列、指标类型、PromQL查询、数学运算、布尔操作及内置函数,助您深入理解并利用PromQL进行高效数据分析和告警设置。
本文详细介绍了PromQL在监控Prometheus数据模型中的应用,涵盖时间序列、指标类型、PromQL查询、数学运算、布尔操作及内置函数,助您深入理解并利用PromQL进行高效数据分析和告警设置。
通过PromQL用户可以非常方便地对监控样本数据进行 统计分析,PromQL支持常见的运算操作符,同时PromQL中还提供了大量的内置函数可以实现对数据的高级处理。PromQL作为Prometheus的核心能力除了实 现数据的对外查询和展现,同时告警监控也是依赖PromQL实现的。
1、Prometheus的数据模型
1.1、理解时间序列
通过Node Exporter暴露的HTTP服务,Prometheus可以采集到当前主机所有监控指标的样本数 据。例如:
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="idle"} 362812.7890625
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 3.0703125其中非#开头的每一行表示当前Node Exporter采集到的一个监控样本:node_cpu和node_load1表明了当前指标 的名称、大括号中的标签则反映了当前样本的一些特征和维度、浮点数则是该监控样本的具体值。
1.2、样本
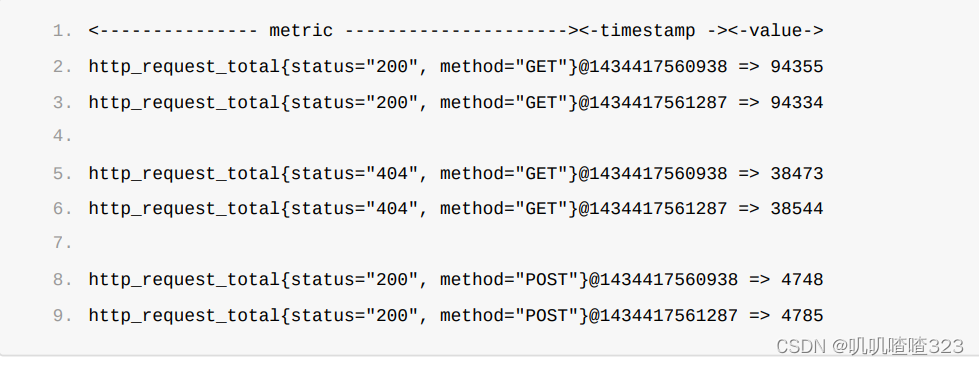
Prometheus会将所有采集到的样本数据以时间序列(time-series)的方式保存在内存数据库中,并且定时保存到 硬盘上。time-series是按照时间戳和值的序列顺序存放的,我们称之为向量(vector). 每条time-series通过 指标名称(metrics name)和一组标签集(labelset)命名。如下所示,可以将time-series理解为一个以时间为Y 轴的数字矩阵:

在time-series中的每一个点称为一个样本(sample),样本由以下三部分组成:
指标(metric):metric name和描述当前样本特征的labelsets;
时间戳(timestamp):一个精确到毫秒的时间戳;
样本值(value): 一个folat64的浮点型数据表示当前样本的值。
1.3、指标(Metric)
在形式上,所有的指标(Metric)都通过如下格式标示:
<metric name>{<label name>=<label value>, ...}
指标的名称(metric name):可以反映被监控样本的含义(比如, http_request_total 表示当前系统接收到的 HTTP请求总量)。指标名称只能由ASCII字符、数字、下划线以及冒号组成并必须符合正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]* 。
标签(label):反映了当前样本的特征维度,通过这些维度Prometheus可以对样本数据进行过滤,聚合等。标签的名 称只能由ASCII字符、数字以及下划线组成并满足正则表达式 [a-zA-Z_][a-zA-Z0-9_]* 。
其中以 【_】 作为前缀的标签,是系统保留的关键字,只能在系统内部使用。标签的值则可以包含任何Unicode编码的 字符。在Prometheus的底层实现中指标名称实际上是以 __name__= 的形式保存在数据库中的,因此以 下两种方式均表示的同一条time-series:
api_http_requests_total{method="POST", handler="/messages"}
等同于:
{__name__="api_http_requests_total",method="POST", handler="/messages"}
在Prometheus源码中指标(Metric)对应的数据结构,如下所示:
type Metric LabelSet
type LabelSet map[LabelName]LabelValue
type LabelName string
type LabelValue string2、Promthues中监控指标的类型
为了能够帮助用户理解和区分这些不同监控指标之间的差异,Prometheus定义了4中不同的指标类型(metric type):Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)。
2.1、Counter:只增不减的计数器
Counter类型的指标其工作方式和计数器一样,只增不减(除非系统发生重置)。常见的监控指标,如 http_requests_total,node_cpu都是Counter类型的监控指标。 一般在定义Counter类型指标的名称时推荐 使用_total作为后缀。
Counter是一个简单但有强大的工具,例如我们可以在应用程序中记录某些事件发生的次数,通过以时序的形式存储 这些数据,我们可以轻松的了解该事件产生速率的变化。PromQL内置的聚合操作和函数可以用户对这些数据进行进一 步的分析:
例如,通过rate()函数获取HTTP请求量的增长率:
rate(http_requests_total[5m])
查询当前系统中,访问量前10的HTTP地址:
topk(10, http_requests_total)2.2、Gauge:可增可减的仪表盘
Gauge类型的指标侧重于反应系统的当前状态。因此这类指标的样本数据可增可减。常见指标如: node_memory_MemFree(主机当前空闲的内容大小)、node_memory_MemAvailable(可用内存大小)都是 Gauge类型的监控指标。
通过Gauge指标,用户可以直接查看系统的当前状态:
node_memory_MemFree通过PromQL内置函数delta()可以获取样本在一段时间返回内的变化情况。例如,计算 CPU温度在两个小时内的差异:
delta(cpu_temp_celsius{host="zeus"}[2h])
使用deriv()计算样本的线性回归模型,甚至是直接使用predict_linear()对数据的变化趋势进行预测。例 如,预测系统磁盘空间在4个小时之后的剩余情况:
predict_linear(node_filesystem_free{job="node"}[1h], 4 * 3600)2.3、使用Histogram和Summary分析数据分布情况
Histogram和Summary主用用于统计和分析样本的分布情况。
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如CPU的平均使用率、页面的平均响应时间。这种方式的 问题很明显,以系统API调用的平均响应时间为例:如果大多数API请求都维持在100ms的响应时间范围内,而个别请 求的响应时间需要5s,那么就会导致某些WEB页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在0~10ms之间 的请求数有多少而10~20ms之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram和 Summary都是为了能够解决这样问题的存在,通过Histogram和Summary类型的监控指标,我们可以快速了解监控样 本的分布情况。
例如,指标prometheus_tsdb_wal_fsync_duration_seconds的指标类型为Summary。 它记录了 Prometheus Server中wal_fsync处理的处理时间,通过访问Prometheus Server的/metrics地址,可以获取 到以下监控样本数据:
# HELP prometheus_tsdb_wal_fsync_duration_seconds Duration of WAL fsync.
# TYPE prometheus_tsdb_wal_fsync_duration_seconds summary
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216从上面的样本中可以得知当前Prometheus Server进行wal_fsync操作的总次数为216次,耗时 2.888716127000002s。其中中位数(quantile=0.5)的耗时为0.012352463,9分位数(quantile=0.9)的 耗时为0.014458005s。
在Prometheus Server自身返回的样本数据中,我们还能找到类型为Histogram的监控指标 prometheus_tsdb_compaction_chunk_range_bucket。
# HELP prometheus_tsdb_compaction_chunk_range Final time range of chunks on their first compaction
# TYPE prometheus_tsdb_compaction_chunk_range histogram
prometheus_tsdb_compaction_chunk_range_bucket{le="100"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="400"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="1600"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="6400"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="25600"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="102400"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="409600"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="1.6384e+06"} 260
prometheus_tsdb_compaction_chunk_range_bucket{le="6.5536e+06"} 780
prometheus_tsdb_compaction_chunk_range_bucket{le="2.62144e+07"} 780
prometheus_tsdb_compaction_chunk_range_bucket{le="+Inf"} 780
prometheus_tsdb_compaction_chunk_range_sum 1.1540798e+09
prometheus_tsdb_compaction_chunk_range_count 780与Summary类型的指标相似之处在于Histogram类型的样本同样会反应当前指标的记录的总数(以_count作为后缀) 以及其值的总量(以_sum作为后缀)。不同在于Histogram指标直接反应了在不同区间内样本的个数,区间通过标签 len进行定义。
3、初识PromQL
PromQL是Prometheus内置的数据查询语言,其提供对时间序列数据丰富的查询,聚合以及逻辑运算能力的支持。并 且被广泛应用在Prometheus的日常应用当中,包括对数据查询、可视化、告警处理当中。可以这么说,PromQL是 Prometheus所有应用场景的基础,理解和掌握PromQL是Prometheus入门的第一课。
3.1、查询时间序列
当Prometheus通过Exporter采集到相应的监控指标样本数据后,我们就可以通过PromQL对监控样本数据进行查 询。
当我们直接使用监控指标名称查询时,可以查询该指标下的所有时间序列。如:
http_requests_total等同于:
http_requests_total{}该表达式会返回指标名称为http_requests_total的所有时间序列:
http_requests_total{code="200",handler="alerts",instance="localhost:9090",job="prometheus",method="get"}=(20889@1518096812.326)
http_requests_total{code="200",handler="graph",instance="localhost:9090",job="prometheus",method="get"}=(21287@1518096812.326)PromQL还支持用户根据时间序列的标签匹配模式来对时间序列进行过滤,目前主要支持两种匹配模式:完全匹配和正 则匹配。
PromQL支持使用 = 和 != 两种完全匹配模式:
- 通过使用 label=value 可以选择那些标签满足表达式定义的时间序列;
- 反之使用 label!=value 则可以根据标签匹配排除时间序列;
http_requests_total{instance="localhost:9090"}http_requests_total{instance!="localhost:9090"}除了使用完全匹配的方式对时间序列进行过滤以外,PromQL还可以支持使用正则表达式作为匹配条件,多个表达式之 间使用 | 进行分离:
- 使用 label=~regx 表示选择那些标签符合正则表达式定义的时间序列;
- 反之使用 label !~regx 进行排除;
例如,如果我们只需要查询所有http_requests_total时间序列中满足标签instance为localhost:9090的时间 序列,则可以使用如下表达式:
http_requests_total{environment=~"staging|testing|development",method!="GET"}3.2、范围查询
http_request_total{}[5m]
通过区间向量表达式查询到的结果我们称为区间向量。
3.3、时间位移操作
http_request_total{} # 瞬时向量表达式,选择当前最新的数据
http_request_total{}[5m] # 区间向量表达式,选择以当前时间为基准,5分钟内的数据http_request_total{} offset 5m
http_request_total{}[1d] offset 1d3.4、使用聚合操作
# 查询系统所有http请求的总量
sum(http_request_total)
# 按照mode计算主机CPU的平均使用时间
avg(node_cpu) by (mode)
# 按照主机查询各个主机的CPU使用率
sum(sum(irate(node_cpu{mode!='idle'}[5m])) / sum(irate(node_cpu[5m]))) by (instance)3.5、标量和字符串
"this is a string"
'these are unescaped: \n \\ \t'
`these are not unescaped: \n ' " \t`3.6、合法的PromQL表达式
http_request_total # 合法
http_request_total{} # 合法
{method="get"} # 合法
{job=~".*"} # 不合法{__name__=~"http_request_total"} # 合法
{__name__=~"node_disk_bytes_read|node_disk_bytes_written"} # 合法4、PromQL操作符
4.1、数学运算
node_memory_free_bytes_total / (1024 * 1024)node_disk_bytes_written + node_disk_bytes_read4.2、使用布尔运算过滤时间序列
例如,系统管理员在排查问题的时候可能只想知道当前内存使用率超过95%的主机
(node_memory_bytes_total - node_memory_free_bytes_total) / node_memory_bytes_total > 0.954.3、使用bool修饰符改变布尔运算符的行为
http_requests_total > bool 1000http_requests_total{code="200",handler="query",instance="localhost:9090",job="prometheus",method="get"} 1
http_requests_total{code="200",handler="query_range",instance="localhost:9090",job="prometheus",method="get"} 04.4、使用集合运算符
4.5、操作符优先级
1. ^
2. *, /, %
3. +, -
4. ==, !=, <=, <, >=, >
5. and, unless
6. or4.6、匹配模式详解
vector1 <operator> vector2<vector expr> <bin-op> ignoring(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) <vector expr><vector expr> <bin-op> ignoring(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> ignoring(<label list>) group_right(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_right(<label list>) <vector expr>5、PromQL聚合函数
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)] sum(http_requests_total) without (instance) sum(http_requests_total) by (code,handler,job,method)sum(http_requests_total) count_values("count", http_requests_total)topk(5, http_requests_total)例如,找到当前样本数据中的中位数:
quantile(0.5, http_requests_total)6、PromQL内置函数
increase(node_cpu[2m]) / 120rate(node_cpu[2m])irate(node_cpu[2m])predict_linear(node_filesystem_free{job="node"}[2h], 4 * 3600) < 0histogram_quantile(0.5, http_request_duration_seconds_bucket)动态标签替换
up { instance = "localhost:8080" , job = "cadvisor" } 1up { instance = "localhost:9090" , job = "prometheus" } 1up { instance = "localhost:9100" , job = "node" } 1
label_replace ( v instant - vector , dst_label string , replacement string , src_label string , regex string )
label_replace ( up , "host" , "$1" , "instance" , "(.*):.*" )
up { host = "localhost" , instance = "localhost:8080" , job = "cadvisor" } 1up { host = "localhost" , instance = "localhost:9090" , job = "prometheus" } 1 up { host = "localhost" , instance = "localhost:9100" , job = "node" } 1
label_join ( v instant - vector , dst_label string , separator string , src_label_1 string , src_label_2 string , ...)


















 663
663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











