







Python学习-day8
字符串chapter2
长字符串
要表示很长的字符串(跨越多行的字符串),可使用三引号。
print('''This is a vary long string . It continues here.
And it's not over yet. "Hello,world!"
Still here.''')
常规写法也可跨多行,在结尾加“\”即可
print("Hello \
world")
这种写法也适用表达式和python语句
print(1+2+3\
+4)
print \
("Hello,world")
原始字符串
原始字符串不以特殊方式处理反斜杠,因此在有些情况下很有用。
在常规字符串中,反斜杠扮演着特殊角色:它对字符进行转义,让你能够在字符串中包含原本无法包含的字符。如:
print('Hello,\nworld!')
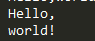
这不是想要结果。所以使用“\”转义“\”:
print('Hello,\\nworld!')
print('C:\\nowhere')
但是,如果路径很长,就要使用大量的“\”,这时,原始字符串可派上用场
print(r'Hello,\nworld!')
print(r'C:\nowhere')
原始字符串用前缀"r"表示。
注:
原始字符串不得以""结尾。
如果最后一个字符(位于结束引号前面的那个字符)为反斜杠,且未对其进行转义,Python将无法判断字符串是否到此结束。
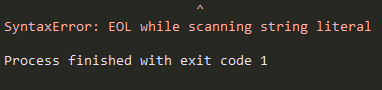
print(r'C:\nowhere\')
报错:
特殊情况下,如果一定要在结尾添加“\”,可用如下方式实现:
print(r'C:\nowhere' '\\')
字节
Python字符串使用Unicode编码来表示文本。
每个Unicode字符都用一个码点(code point)表示,而码点是Unicode标准给每个字符指定的数字。
这让我们能以任何现代软件都能识别的方式表示129个文字系统中的12万个以上的字符。
鉴于计算机上不可能有几十万个按键,因此有一种指定Unicode字符的通用机制:
使用16或着32位的十六进制字面量(分别加上前缀\u或\U)或者使用字符的Unicode名称(\N{name})。例:
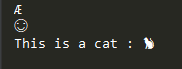
print("\u00C6")
print("\U0001F60A")
print("This is a cat : \N{Cat}")
感兴趣的同学可以浏览网站:http://unicode-table.com
Python添加不可变的bytes和可变的bytearray类型
bytes对象
>>>b'Hello World'
b'Hello World'
编码:
print('Hello,world!'.encode("ASCII"))
print('Hello,world!'.encode("UTF-8"))
print('Hello,world!'.encode("UTF-32"))
 几乎所有的情况下,都最好使用UTF-8编码。事实上,它也是默认使用的编码。
几乎所有的情况下,都最好使用UTF-8编码。事实上,它也是默认使用的编码。
bytearray
它是bytes的可变版,从某种意义上说,它就像可修改的字符串----常规字符串是不能修改的。然而,bytearray其实是为在某后使用而设计的,因此作为类字符串使用时对用户并不友好。
博文内容来自本人所选的学习Python的工具书-《Python基础教程》(第三版)人民邮电出版社。















 888
888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









