







工作中发现一些细节掌握的不到位,特此记下。
1.字符数组查找指定字符
在一段字符数组中查找指定的字符串,仅使用C。
例:
char cmdline[4096] = { "core_ctl_disable_cpumask=0-7 kpti=0 mdtp console=" };
char *ptr;
int find = 0;
ptr = cmdline;
while (ptr && *ptr) {
char *x = strchr(ptr, ' ');
if (x != 0)
*x++ = 0;
if (!strcmp(ptr, "mdtp")) {
find = 1;
break;
}
ptr = x;
}
return find;
其中需要注意的细节点:
- *x++ = 0;//这里是先x++再赋值0,作用是将‘ ’字符改成ASCII码为0,即‘\0’,表述字符结束。可以将ptr仅指向一个被空格分割后的字符串。
- !strcmp(ptr, “mdtp”)。strcmp可以返回正数,负数,跟0.而负数也是数字,所以!负数为false。
2.指针指向问题
当把指针作为参数进行传递时,也是将实参的一个拷贝传递给形参,两者指向的地址相同,但不是同一个变量,在函数中改变这个变量的指向不影响实参。
传送门:https://blog.csdn.net/u013130743/article/details/80806179
void testchar2(char* p)
{
*p = 'a';
*(p+1) = 'b';
}
void testchar1(char* p)
{
char a[100] = "ffffaaa";
p = a;
*(p+1) = 'b';
}
void main()
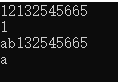
{
char a[100] = "12132545665";
char* b1 = a;
char* b2 = a;
testchar1(b1);//改变指针指向,但是没改变指针的所指的内容
cout << a << endl;
cout << *b1 << endl;
testchar2(b2);
cout <<a << endl;
cout <<*b2 << endl;
}
运行结果:
3.类初始化与赋值的区别
#include <iostream>
using namespace std;
class A {
public:
int num1;
int num2;
public:
A(int a = 0, int b = 0) :num1(a), num2(b)
{
cout << "param constructor" << endl;
};
A(const A& a)
{
cout << "Copy constructor" << endl;
};
//重载 = 号操作符函数
A& operator=(const A& a) {
cout << "=" << endl;
num1 = a.num1 + 1;
num2 = a.num2 + 1;
return *this;
};
};
int main() {
A a(1, 1);
A a1 = a; //拷贝初始化操作,调用拷贝构造函数
A b;
b = a;//赋值操作,对象a中,num1 = 1,num2 = 1;对象b中,num1 = 2,num2 = 2
return 0;
}
结果:

4.隐藏:派生类中的函数屏蔽了基类中的同名函数
#include <iostream>
using namespace std;
//父类
class A {
public:
virtual void fun(int a) {
cout << "A中的fun函数" << endl;
}
};
//子类
class B : public A {
public:
//隐藏父类的fun函数
virtual void fun(char* a) {
cout << "A中的fun函数" << endl;
}
};
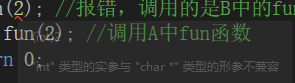
int main() {
B b;
b.fun(2); //报错,调用的是B中的fun函数,参数类型不对
b.A::fun(2); //调用A中fun函数
return 0;
}
5.内联函数
传送门:https://www.cnblogs.com/QG-whz/p/4641479.html
6.大小端
字数据的高低字节:左边是高位,右边是低位。
高低地址:数字越大,地址越高。例如0x0001为低地址,0x0099相对0x0001为高地址
大端存储:字数据的高字节存储在低地址中
小端存储:字数据的低字节存储在低地址中
7.unordered_set
- 不再以键值对的形式存储数据,而是直接存储数据的值;
- 容器内部存储的各个元素的值都互不相等,且不能被修改。
- 不会对内部存储的数据进行排序
std::set和std::multiset底层实现都是红黑树,std::unordered_set的底层实现是哈希表, 使用unordered_set 读写效率是最高的,并不需要对数据进行排序,而且还不要让数据重复

8.map
| 映射 | 底层实现 | 是否有序 | 数组是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::map | 红黑树 | key有序 | key不可重复 | key不可更改 | O(logn) | O(logn) |
| std::multimap | 红黑树 | key有序 | key可重复 | key不可更改 | O(logn) | O(logn) |
| std::unordered_map | 哈希表 | key无序 | key不可重复 | key不可更改 | O(1) | O(1) |
1)std::map
常见用法
std::map<int, int> test;
int a,=0,b=0;
test[a] = b;
auto c = test.size();
for (auto it : test){
//……
}
auto it = test.find(a);
if (it != test.end())
{
test.erase(it );
}
2)std::multimap
常见用法
typedef std::multimap<uint32_t, uint32_t> t_TestMap;
std::shared_ptr<t_TestMap> spTsetMap;
spTsetMap = std::make_shared<t_TestMap>();
//插入
spTsetMap->insert(t_TestMap::value_type(a, b));
//count
auto Cnt = spTsetMap->count(a);
auto range = spTsetMap->equal_range(a);
for (auto i = range.first; i != range.second; ++i)
{
if(i->second == a)
{
spTsetMap->erase(i);
break;
}
}















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









