







文章目录
指针就是存储了其他数据的位置的一个变量。这样想指针:对于装满了数据的柜子,更简单的做法是记录它的位置而不是复制全部内容。
7.1 指针到底是什么?
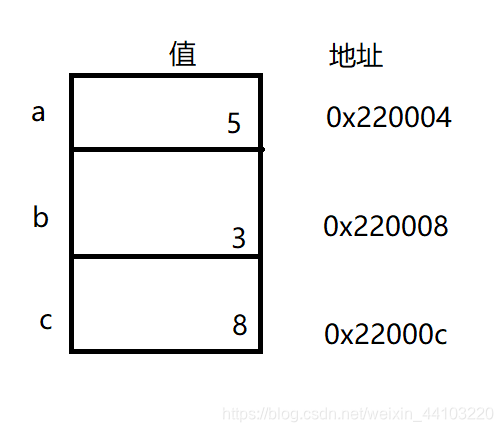
CPU不懂名称或字母,它用称为“地址”的数字引用内存位置。一般不需要直到具体数字,虽然想的话也可以打印出来。如下图索引,计算机可能将变量a, b 和 c分别存储在数字地址 0x220004, 0x220008 和 0x22000c, 地址用的是十六进制。
7.2 指针概念
指针是包含数字地址的变量。虽然大多数变量包含有用的信息(下图),但指针包含的是另一个变量的位置。所以,指针仅用于指向别的东西。和你不想拷贝的文件柜一样,指针在传递数据位置(而不是数据拷贝)时很高效。
函数有时要向另一个函数发送大量数据。一个办法时拷贝所有数据并传过去。更高效的时只传一个地址。C++函数实参默认传值。函数接收的实参是原始值的拷贝,然后可以对该拷贝做任何事情:修改、打印和乘除等。但所有修改都只影响临时拷贝。
那么,要修改原始值怎么办?传址就是一个发难。和文件柜一样,告诉别人位置,它就能跑去修改原始数据。相反,只给它数据的拷贝,修改就不是永久性的。
指针还有其他用处(第12章会谈到)。
地址像什么样?
使用十六进制是有原因的。16是2 的乘方(2x2x2x2 = 16),每个十六进制数位都对应4个二进制数位的唯一组合,不会多,也不会少,而且绝无重复。
十六进制的优点在于和二进制的密切关系。例如,十六进制8等于二进制1000,十六进制 f 等于1111. 所以,88ff 等于 1000 1000 1111 1111.
计算机需要快速将数字换算为二进制位模式,所以十六进制很好用。另外,由于每个十六进制都对应4个二进制位,所以一眼就能看出地址宽度:0x8000 有4位,对应16个二进制位。每种计算机架构都使用固定地址宽度,所以有必要一眼看出地址对于一台计算机来说是否太大。
目前个人电脑主流是使用32位和64位地址。使用32位地址,所有地址的宽度都不能超过32个二进制位(8个十六进制位)。技术上说,每个地址都要用8个十六进制位表示,例如:0x000080ff。本章为简化使用了较小的地址并忽略了前导零。
32位地址空间只支持40多亿个地址,随着硬件的发展这已成为瓶颈。要适应目前的大内存机型,最好是安装操作系统的64位版本。
7.3 声明和使用指针
声明指针用以下的语法:
类型 * 名称;
例如,以下代码声明指针p来指向int类型的变量:
int * p;
指针这时尚未初始化,只知道它能指向int类型的数据对象。类型很重要,指针的基本类型决定了如何解释它指向的数据。p具有int * 类型,所以只应指向 int 变量。
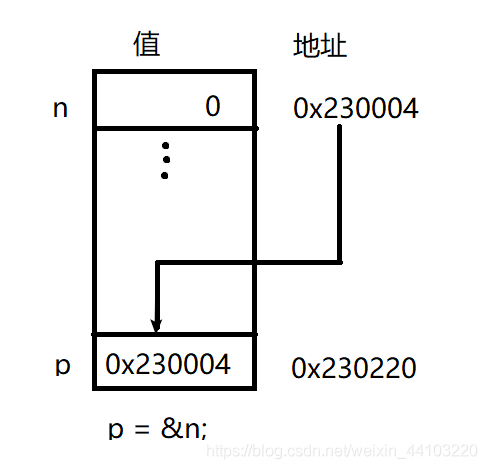
以下语句声明整数变量n,初始化位0,再把它的地址赋给指针 p;
int n = 0;
p = &n; // p现在指向n
&获取操作数的地址,称为“取地址符”。通常不必关心具体地址,只需直到p现在包含n的地址。换言之,p 指向 n,可用 p 来操作 n。
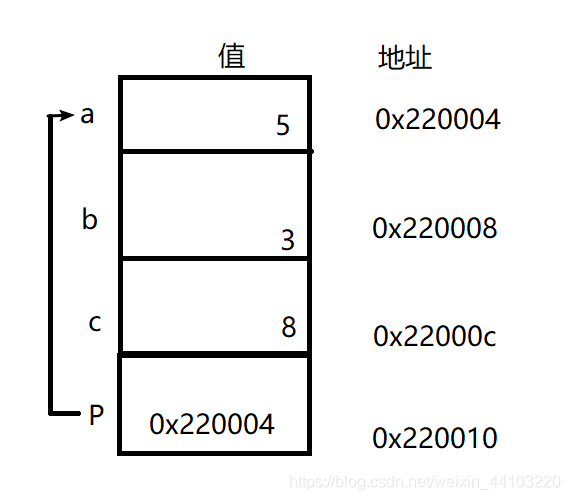
执行 p = &n 之后,p 就包含了 n 的地址。下图是一个可能的内存布局。
所有例子的地址都是任意取的。程序每次运行都可能使用不同地址。指针要点在于它所建立的关系。
下面来一点有趣的。间接寻址操作符(*)表示“指向的东西”。将值赋给 *p 等同于将值赋给n, 因为n是p指向的东西。
* p = 5; // 将5赋给p指向的int 变量
由于星号的存在,这个操作修改的p 指向的东西,而不是修改p 本身的值。下图展示了现在的内存布局。
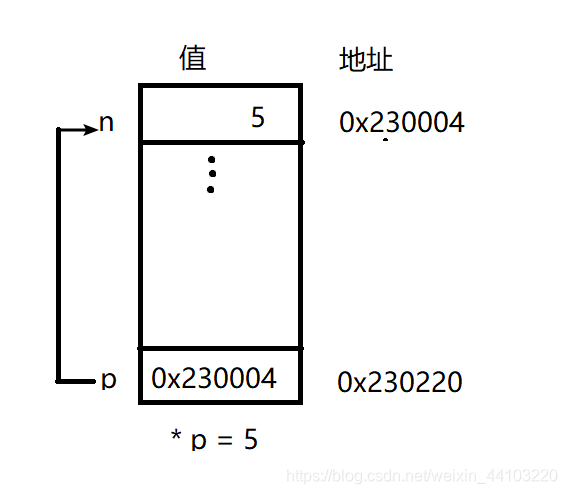 语句效果等同于 n = 5; 计算机找到p 指向的内存位置,将值5 放入该位置。
语句效果等同于 n = 5; 计算机找到p 指向的内存位置,将值5 放入该位置。
可以用指针同时取值和赋值,例如:
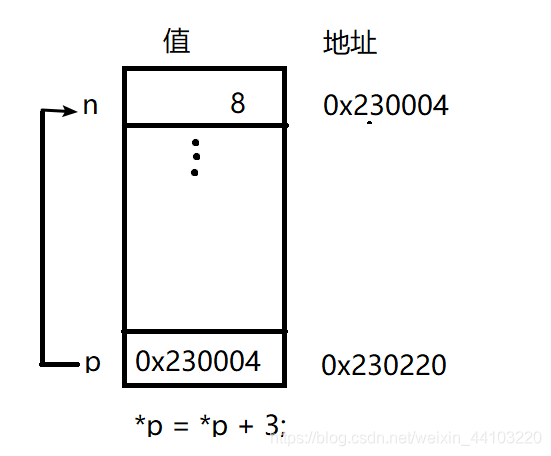
* p = *p + 3; // 在 p指向的int 上加3
n值再次发生变化,这次从 5 变成 8 . 效果等同于 n = n + 3。如下图所示,计算机找到 p指向的内存位置,在那个位置的值上加3.
总之,当p 指向n 时,*p 具有与n 等同的效果。下表展示了更多例子:
| 当p指向n时,该语句 | 等效于 |
|---|---|
| *p = 33; | n = 33; |
| *p = *p + 2; | n = n + 2; |
| cout << *P | cout << n; |
| cin >> *p | cin >> n; |
但既然*p 和n 效果一样,为何还要使用 *p?一个原因是指针使函数能修改传给它的实参值。C和C++具体如下所示:
- 调用者向函数传递要修改的一个变量的地址,例如&n(n的地址)。
- 函数通过指针实参(例如 p)接收该地址值,在函数主体中用*p 操作n的值。
例 7.1:打印地址
实际运用指针之前先来打印一些数据,将指针值和标准int 变量的值进行比较。重点是理解变量内容和它的地址的区别。
// pr_addr.cpp
# include <iostream>
# include <stdlib.h>
using namespace std;
int main()
{
int a = 2, b = 3, c = 4;
int *pa = &a;
int *pb = &b;
int *pc = &c;
cout << "指针pa的值是:" << pa << endl;
cout << "指针pb的值是:" << pb << endl;
cout << "指针pc的值是:" << pc << endl;
cout << "a, b, c 的值是:";
cout << a << ", " << b << ", " << c << endl;
return 0;
}
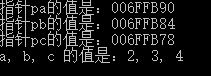
你的结果可能有所不同。
物理地址取决于太多我们控制不了的东西。重点是一旦获得指针(包含其他变量地址的变量),就可用它操作所指向的东西。虽然 a, b, 和 c按此顺序声明,但我的C++编译器反向分配它们的地址:c的地址低于 a。这给了我们一个教训:除了数组元素 和 类,绝对不要假设变量在内存 中的顺序。
例 7.2:double_it 函数
// double_it.cpp
# include <iostream>
using namespace std;
void double_it(int *p);
int main()
{
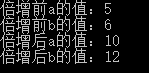
int a = 5, b = 6;
cout << "倍增前a的值:" << a << endl;
cout << "倍增前b的值:" << b << endl;
double_it(&a); // 传址 a
double_it(&b); // 传址 b
cout << "倍增后a的值:" << a << endl;
cout << "倍增后b的值:" << b << endl;
return 0;
}
void double_it(int *p)
{
*p = *p * 2;
}
练习
练习 7.2.1
写程序调用 triple_it函数。函数获取一个 int 变量的地址,是变量的值变大3倍。测试时传递实参n,n初始化位15.打印函数调用前后的 n值。提示:函数应该和例7.1的 double_it 函数相似,记住传递 &n。
// 练习 7.2.1
# include <iostream>
using namespace std;
void triple_it(int *p);
int main()
{
int n = 15;
cout << " 传递前的 n值:" << n << endl;
triple_it(&n);
cout << " 传递后的 n值:" << n << endl;
return 0;
}
void triple_it(int *p)
{
*p = *p * 3;
}

练习 7.2.2
写程序调用 convert_temp 函数。函数获取一个 double 的地址并进行摄氏度到华氏度的换算。函数调用后,包含摄氏度值的变量应包含等同的华氏度值。测试该函数。提示:公式是:F = (C * 1.8) + 32。
// 练习 7.2.2
# include <iostream>
using namespace std;
void convert_temp(double *p);
int main()
{
double n = 0.0;
cout << " 请输入摄氏度的值:" << endl;
cin >> n;
convert_temp(&n);
cout << " 换算的华氏度是:" << n << endl;
return 0;
}
void convert_temp(double *p)
{
*p = (*p * 1.8) + 32.0;
}

7.4 函数中的数据流
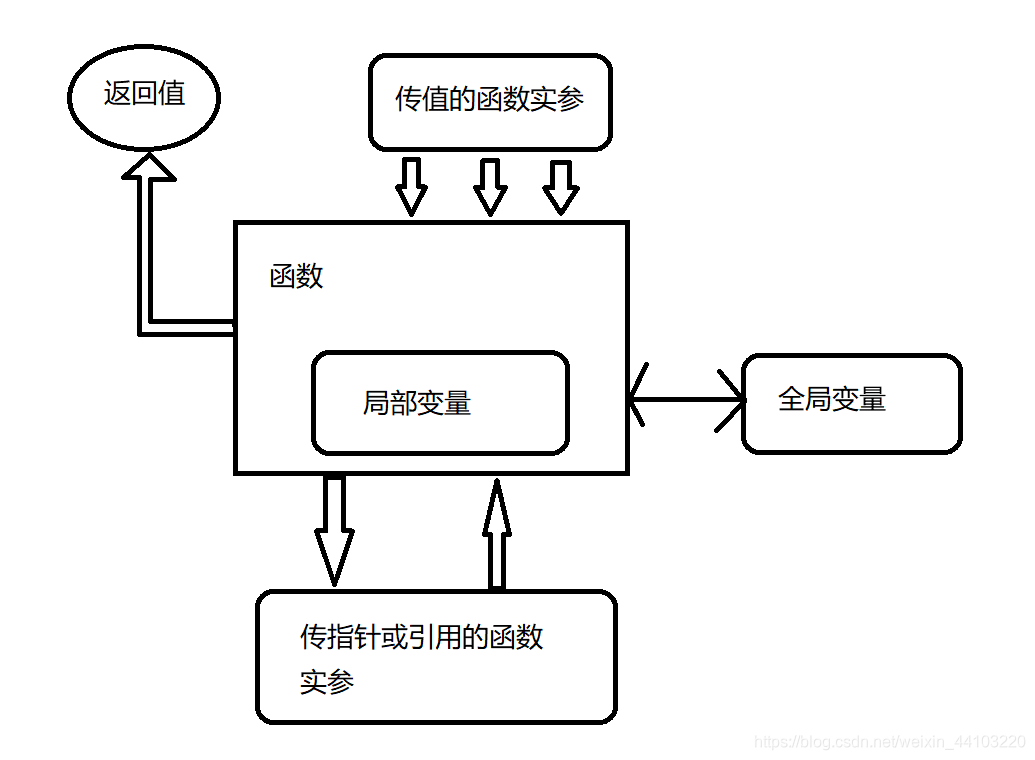
通过接收指针,函数不仅能够操作变量值的拷贝,这些操作还能影响原始变量。
函数经常需要传回多个值。例如,可能需要设置一整套值来执行“数据输出”。这时只有一个返回值是不够的。传回信息(向程序其余部分输出数据)的一个办法是让函数操作全局变量,但要尽量限制全局变量的使用。
如下图所示,知道如何传值或通过指针传引用之后,就可以在函数中实现更复杂的输入/输出流。
7.5 交换:另一个使用指针的函数
交换的一般模式:
temp = a;
a = b;
b = temp;
现在希望将上述代码放到一个函数中,需要时直接调用。例如,假定有两个变量A 和 B ,调用函数即可交换两者的值。
听起来不错,但记住除非传递变量的指针(地址),对变量的修改会被忽略。下面是一个可行的方案,通过指针使函数能修改变量。
// swap函数,交换p1 和 p2指向的值
void swap(int *p1, int *p2)
{
int temp = *p1;
*p1 = *p2;
*p2 = temp;
}
*p1 和 *p2 都是整数,可以像使用任何整数变量那样使用它们。只是记住p1 和 p2是 地址,地址本身是不会变的。修改的是p1 和 p2指向的数据。用例子很容易看清。
假定big 和 little分别初始化为 100和 1.
int big = 100;
int little = 1;
以下语句调用 swap 函数,传递这两个变量的地址。注意使用了取址操作符&。
swap(&big, &little);
打印两个变量的值,会发现它们已发生改变。现在,big包含1,而little包含100.
cout << “big现在的值是:” << big << endl;
cout << “little现在的值是:” << little;
注意,big 和 little 的内存地址没有变,但其是保存的值发生了改变。这正是许多人将间接寻址操作符*称为“at” (在)操作符的原因。*p = 0 更改 在 地址p 处的值。
中文一般不说 at(在)操作符,而是说提领操作符(源自dereference, 或解引用)。
例7.3:数组排序
下面来体验 swap 函数的强大。注意指针并非只能指向简单变量。例如,int 指针可指向存储了一个int 值的任意内存位置。这意味着除了能指向变量,还能指向数组元素。
例如,下面用 swap 函数交换arr数组的两个元素的值:
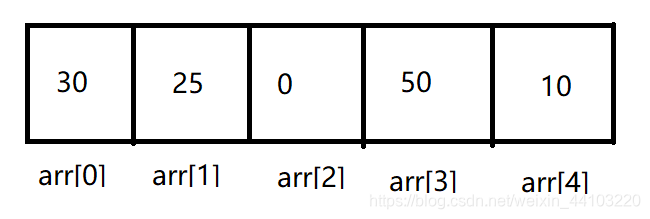
int arr[5] = {0, 10, 30, 25, 50};
swap(&arr[2], &arr[3]);
通过特定的算法,就可以用 swap 函数对一个数组的所有值进行排序。如下图所示,为例,这次打乱它的数据。
 下面是最傻瓜的“选择排序”算法。
下面是最傻瓜的“选择排序”算法。
- 找到最小值并放到arr[0]。
- 找到下个最小值并放到arr[1]。
- 以此类推,直到结束。
下面是算法的伪代码。
For i = 0 to n - 2,
查找 a[i] 到 a[n - 1]范围中的最小值
If i 不等于最小值的索引
交换a[i] 和 a[最小值的索引]
要点是将最小值放到a[0], 下个最小值放到 a[1],以此类推。注意以下伪代码:
For i = 0 to n - 2
它的意思是for 循环的第一次迭代将 i 设为0;下次迭代将 i 设为1;以此类推,直到 i 设为 n - 2,并完成最后一次迭代。每次迭代都将正确的元素放到 a[i] 中,然后使 i 递增1.
在循环主体中, a[i] 与从 a[i] 到 a[n - 1]的所有值比较。i 的每个值这样处理之后,整个数组就完成了排序。
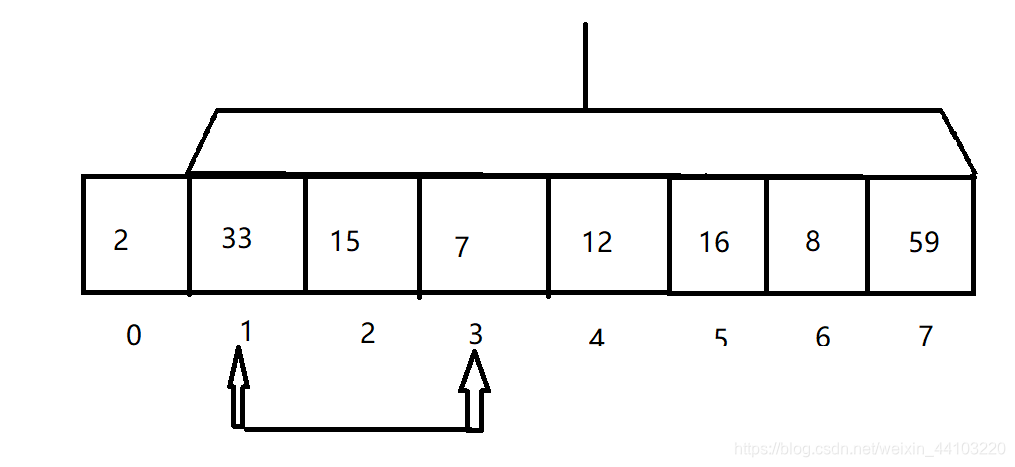
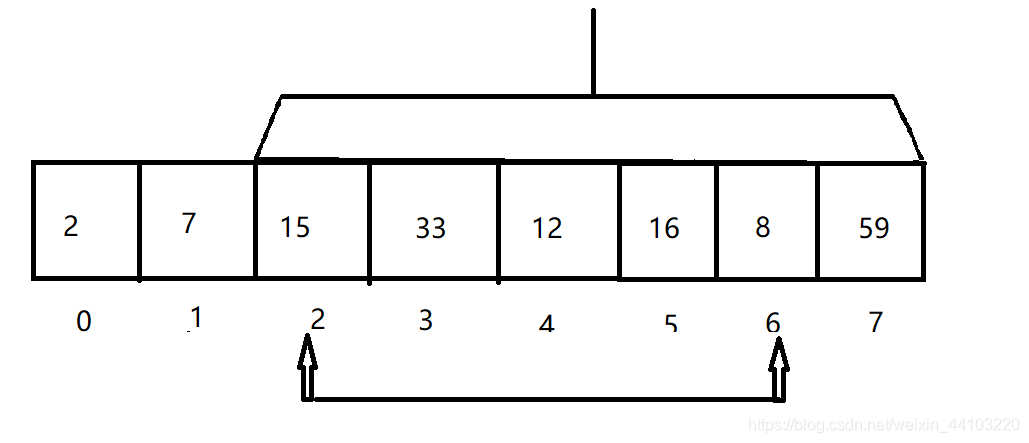
下面几个图展示了前三次循环迭代的情况。算法要点在于每个元素都和它右侧的所有元素进行比较,并根据需要进行交换。
-
将 a[0]与此范围中值最小的元素交换
![将 a[0]与此范围中值最小的元素交换](https://img-blog.csdnimg.cn/20200703162117699.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NDEwMzIyMA==,size_16,color_FFFFFF,t_70)
-
将a[1]与此范围中值最小的元素交换
-
将a[2]与此范围中值最小的元素交换
 但是,怎样找出a [i] 到 a[n - 1]范围中的最小值呢?需要再设计一个算法。
但是,怎样找出a [i] 到 a[n - 1]范围中的最小值呢?需要再设计一个算法。
以下算法做了两件事情。第一,首先假定 i 是值最小的元素,所以将 low 初始化为 i。第二,一旦找到值更小的元素,它就称为新的 low 元素。
为了查找 a[i] 到 a[n - 1]范围中的最小值:
将 low 设为 i
For j = i + 1 to n - 1
If a[j] 小于 a[low]
将 low 设为 j
两个算法可以合二为一,这样写 C++代码就容易了。
For i = 0 to n - 2,
将 low 设为 i
For j = i + 1 to n - 1,
If a[j] 小于 a[low]
将 low 设为 j
If i 不等于 low
交换 a[i] 和 a[low]
下面是用上述算法对数组进行排序的完整程序。
// sort.cpp
# include <iostream>
using namespace std;
void sort(int n);
void swap(int *p1, int *p2);
int a[10];
int main()
{
for (int i = 0; i < 10; ++i)
{
cout << "输入数组元素#" << i << ":";
cin >> a[i];
}
sort(10);
cout << "排序好的数组:" << endl;
for (int i = 0; i < 10; ++i)
{
cout << a[i] << " ";
}
return 0;
}
// 排序函数:对 n 个元素的 a 数组排序
void sort(int n)
{
int low = 0;
for (int i = 0; i < n - 1; ++i)
{
// 这一部分找到范围 i 到 n - 1的最小元素,索引赋给 low 变量
low = i;
for (int j = i + 1; j < n; ++j)
{
if (a[j] < a[low])
{
low = j;
}
}
// 这一部分根据需要执行交换
if (i != low)
{
swap(&a[i], &a[low]);
}
}
}
// swap 函数,交换 p1 和 p2指向的值
void swap(int *p1, int *p2)
{
int temp = *p1;
*p1 = *p2;
*p2 = temp;
}
练习
练习 7.3.1
修改例子,不要从小到大排序,改成从大到小排序。这实际上比你想象的容易。首先,变量low 应重命名为 high。然后,改一个执行比较的语句就可以了。
// 练习 7.3.1
# include <iostream>
using namespace std;
void sort(int n);
void swap(int *p1, int *p2);
int a[10];
int main()
{
for (int i = 0; i < 10; ++i)
{
cout << "输入数组元素#" << i << ":";
cin >> a[i];
}
sort(10);
cout << "排序好的数组:" << endl;
for (int i = 0; i < 10; ++i)
{
cout << a[i] << " ";
}
return 0;
}
// 排序函数:对 n 个元素的 a 数组排序
void sort(int n)
{
int high = 0;
for (int i = 0; i < n - 1; ++i)
{
// 这一部分找到范围 i 到 n - 1的最大元素,索引赋给 high 变量
high = i;
for (int j = i + 1; j < n; ++j)
{
if (a[j] > a[high])
{
high = j;
}
}
// 这一部分根据需要执行交换
if (i != high)
{
swap(&a[i], &a[high]);
}
}
}
// swap 函数,交换 p1 和 p2指向的值
void swap(int *p1, int *p2)
{
int temp = *p1;
*p1 = *p2;
*p2 = temp;
}
练习7.3.2
修改例子,对包含double 元素的数组进行排序。这要求重写swap 函数来支持正确的类型。但不能更改作为循环计数器或数组索引使用的任何变量的类型,它们始终都是int。
# include <iostream>
using namespace std;
void sort(int n);
void swap(double *p1, double *p2);
double a[10];
int main()
{
for (int i = 0; i < 10; ++i)
{
cout << "输入数组元素#" << i << ":";
cin >> a[i];
}
sort(10);
cout << "排序好的数组:" << endl;
for (int i = 0; i < 10; ++i)
{
cout << a[i] << " ";
}
return 0;
}
// 排序函数:对 n 个元素的 a 数组排序
void sort(int n)
{
int low = 0;
for (int i = 0; i < n - 1; ++i)
{
// 这一部分找到范围 i 到 n - 1的最小元素,索引赋给 low 变量
low = i;
for (int j = i + 1; j < n; ++j)
{
if (a[j] < a[low])
{
low = j;
}
}
// 这一部分根据需要执行交换
if (i != low)
{
swap(&a[i], &a[low]);
}
}
}
// swap 函数,交换 p1 和 p2指向的值
void swap(double *p1, double *p2)
{
int temp = *p1;
*p1 = *p2;
*p2 = temp;
}
例7.3.3
修改例子来实现“冒泡排序”算法。它可能比选择排序更高效。每个元素都和它旁边的元素比较,顺序不对就交换位置。第一次处理全部 n 个元素,最大值将 “冒泡” 到最高数组位置。第二次处理前 n - 1个元素。第三次处理前 n - 2个元素。以此类推。每次都将最大元素放到最右边的位置。算法优点是任何时候数组完全排好序就提前退出。伪代码如下所示:
For I 等于 N - 1 到(但不包括)0:
For J 等于0到(但不包括)I:
将 in_order 标志设为 true
If arr[J + 1] < arr[J]
交换 arr[J + 1] 和 arr[J]
将 in_order 标志设为false
If in_order 就提前中断循环
不要 in_order 标志也行,但就不能提前退出循环了。可能多费一些执行时间,但能少写一些代码。
// 练习 7.3.3
# include <iostream>
using namespace std;
void sort(int n);
void swap(int *p1, int *p2);
int a[10];
int main()
{
for (int i = 0; i < 10; ++i)
{
cout << "输入数组元素#" << i << ":";
cin >> a[i];
}
sort(10);
cout << "排序好的数组:" << endl;
for (int i = 0; i < 10; ++i)
{
cout << a[i] << " ";
}
return 0;
}
// 冒泡排序算法
void sort(int n)
{
int low = 0;
bool in_order = true;
for (int i = n - 1; i > 0; --i)
{
in_order = true;
for (int j = 0; j < i; ++j)
{
if (a[j + 1] < a[j])
{
swap(&a[j + 1], &a[j]);
in_order = false;
}
}
if (in_order)
{
break;
}
}
}
// swap 函数,交换 p1 和 p2 指向的值
void swap(int *p1, int *p2)
{
int temp = *p1;
*p1 = *p2;
*p2 = temp;
}
7.6 引用参数(&)
上一节实现了所谓的“传引用”,虽然从技术上说传递的是指针。
在经典C中,这是和“传引用”最接近的方案,所以任何真正意义上的程序都很难避免使用指针。但在C++中,还有一个方案是使用引用参数,为此只需在声明时为参数附加&前缀。&在其他地方是取址操作符,但在函数声明中代表引用,表明这是另一个变量的别名。例如:
void swap(int &a, int &b);
这样,函数主体就可直接操作参数,而不是把它们当成指针看待。由于是引用参数,对参数的操作是永久性的,会影响调用者。注意,使用时不涉及任何指针语法。
void swap(int &a, int &b)
{
int temp = p1;
p1 = p2;
p2 = temp;
}
优点是一旦声明是引用参数,传递实参就不需要取值或使用指针语法。这是实现“传引用”的更简单的方式。
swap(a[i], a[low]); // 交换a[i] 和 a[low]
当然,这个技术真正实现时还是使用了指针,只是幕后细节隐藏起来了。对指针的理解还是有必要的,它们还有其他许多应用。
7.7 指针运算
指针的一个重要用途时高效处理数组。假定声明了以下数组:
int arr[5] = {5, 15, 25, 35, 45};
当然,元素arr[0] 到 arr[4] 全都可作为单独的整数变量作用。例如,可以使用arr[1] = 10; 这样的语句。但表达式 arr 本质时什么? arr 能单独使用吗?
是的, arr 能单独使用。 arr 是常量,能转换成一个地址,具体是数组第一个元素的地址。由于是常量,所以不能更改 arr 本身的值。但可用它向指针变量赋值。
int *p;
p = arr;
语句 p = arr; 等价于:
p = &arr[0];
要将指针初始化为第一个元素 arr[0]的地址,前一个表达式 p = arr; 显得更简洁。其他元素能不能采取类似的方法?当然!以下语句将 arr[2] 的地址赋给 p:
p = arr + 2; // p = &arr[2]
C++将所有数组名都解释成地址表达式。例如,arr[2]被转换成:
*(arr + 2)
表面上似乎不合理。在数组起始地址上加2,但 arr[2]的偏移量不是2个字节,而是8个字节(假定使用32位系统,每个整数4个字节)。虽然如此,以上写法确实合法。为什么呢?
这是指针运算的功劳!指针和其他地址表达式(比如 arr)只能执行以下运算:
地址表达式 + 整数
整数 + 地址表达式
地址表达式 - 整数
地址表达式 - 地址表达式
整数和地址表达式相加,结果是另一个地址表达式。但在计算完成之前,整数会自动乘以基类型的大小。C++编译器帮你执行这个乘法运算。
新地址 = 旧地址 + (整数 * 基类型大小)
例如,假定p的基类型是 int, 那么在 p 上加2实际会使他增大8.基类型大小(4字节)乘以2,得到的是8个字节。
指针运算是C++的一个很实用的功能。假定指针 p 指向一个数组元素, 递增1肯定造成 p 指向下一个元素:
++p; // 指向数组的下一个元素
使用指针时记住以下设计规范:
在地址表达式上加减整数值,编译器自动使整数乘以指针基类型大小。
换个说法,在指针上加N,将生成距离原始指针值N个元素的新地址。
地址表达式还可以相互比较。除非是数组元素,否则不要对内存布局做出任何假设。以下表达式求值结果总数 true:
&arr[2] < &arr[3]
相当于:
arr + 2 < arr + 3
7.8 指针和数组处理
由于能执行运算,函数可通过指针引用而非数组索引来访问元素。结果一样,但指针版本稍快(稍后说明)。
如今CPU速度都挺快的,所以轻微的速度提升对大多数程序来说没什么区别。
但对于某些类型的程序,通过C和C++而获得的高超执行效率仍然有用。C和C++是写操作系统的首选语言。操作系统的一些子程序和设备驱动一秒钟要执行成千上万次。这时,使用指针获得的些微效率提升显得至关重要。
以下函数使用指针引用清零n个元素的一个数组。
void zero_out_array(int *p, int n)
{
while(n-- > 0) // 保证执行n次
{
*p = 0; // 将0赋给p指向的元素
++p; // 指向下一个元素
}
}
这是一个简练的函数:去掉注释更甚(但要记住,注释对于程序的运行没有任何影响)。下面是函数的另一个版本,它使用了你或许更熟悉的代码。
void zero_out_array2( int *arr, int n)
{
for (int i = 0; i < n; i++)
{
arr[i] = 0;
}
}
这个版本虽然仍然比较简练,但运行速度可能稍慢(具体取决于编译器是否优化)。原因是每次循环迭代,i 值都必须按比例增大并加到 arr 上,从而获得数组元素 arr[i] 的地址。
arr[i] = 0;
它等价于:
*(arr + i) = 0;
更糟的是,由于必须在运行时按比例增大i 值(在 arr 上的并不是 i 值本身, 而是 “i 乘以基类型大小”),所以在机器码的级别上,实际要执行以下计算:
*(arr + (i * 4)) = 0;
反复计算地址浪费时间。在指针版本中, arr的地址只需计算一次。循环语句要做的工作并不多:
*p = 0;
当然,p 还是要在每次循环时递增。但两个版本都要更新一个循环变量。就工作量来说,递增 p并不比递增 i 多。
下图展示了指针版本的工作方式。每次循环迭代时, *p 都设为0, 然后使 p自身递增到下一个数组元素(由于会自动按比例增大,所以 p 每次实际会递增4, 但那是一个很容易完成的操作)。
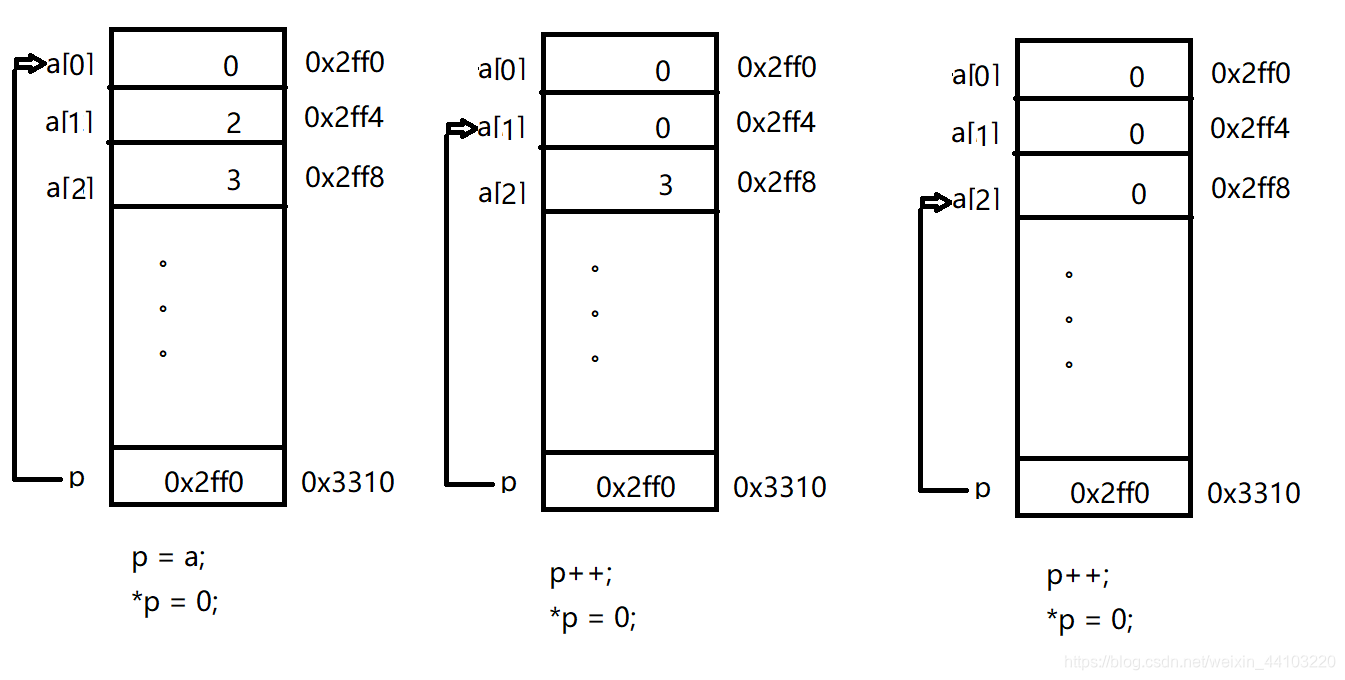
例 7.4 :数组清零
本节用一个完整的例子演示 zero_out_array 函数的用法。程序初始化数组,调用函数,然后打印元素。
// zero_out.cpp
# include <iostream>
using namespace std;
void zero_out_array(int *arr, int n);
int a[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int main()
{
zero_out_array(a, 10);
// 打印 数组所有元素
for (int i = 0; i < 10; ++i)
{
cout << a[i] << " ";
}
return 0;
}
// zero_out_array 函数
// 为大小 n 的 int 数组的所有元素赋值0
void zero_out_array(int *p, int n)
{
while (n-- > 0) // 保证执行 n 次
{
*p = 0; // 将0赋给p 指向的元素
++p; // 指向下一个元素
}
}
练习
练习 7.4.1
重写程序,在循环中使用直接指针引用来打印数组的值。声明指针p 并初始化它指向数组开头。循环条件是 p < a + 10。
// 练习 7.4.1
# include <iostream>
using namespace std;
void zero_out_array(int *arr, int n);
int a[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int main()
{
zero_out_array(a, 10);
// 打印 数组所有元素
for (int *p = a; p < a + 10; ++p)
{
cout << *p << " ";
}
cout << endl;
return 0;
}
// zero_out_array 函数
// 为大小 n 的 int 数组的所有元素赋值0
void zero_out_array(int *p, int n)
{
while (n-- > 0) // 保证执行 n 次
{
*p = 0; // 将0赋给p 指向的元素
++p; // 指向下一个元素
}
}
练习 7.4.2
编写并测试 copy_array 函数将一个 int 数组的内容复制到相同大小的另一个数组。函数获取两个指针实参。循环内的操作如下:
*p1 = *p2;
p1++;
p2++;
较精简但较晦涩的代码如下:
*(p1++) = *(p2++);
甚至可以使用以下代码,效果一样:
*p1++ = *p2++;
// 练习 7.4.2
# include <iostream>
using namespace std;
void copy_array(int *p1, int *p2, int n); // 复制 b[] 到 a[]
int a[10];
int b[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int main()
{
copy_array(a, b, 10);
// 打印 a数组所有元素
for (int *p = a; p < a + 10; ++p)
{
cout << *p << " ";
}
cout << endl;
return 0;
}
// copy_array 函数
// 复制 b[]中的元素 到 a[],n为数组长度。
void copy_array(int *p1, int *p2, int n)
{
while (n-- > 0) // 保证执行 n 次
{
*p1++ = *p2++;
}
}
小结
- 指针是包含数值内存地址的变量。用以下语法声明指针。
类型 *p; - 可用取值操作符&初始化指针:
p = &n; // n的地址赋给p。 - 指针初始化好之后,用间接寻址操作符*操纵指针指向的数据:
p = &n;
*p = 5; // 5 赋给n - 为了允许函数操纵数据(传引用),需要传递一个地址:
double_it(&n); - 为接收地址,声明指针类型的实参:
void double_it(int *p); - 数组名称是一个常量,转换为数组第一个元素的地址。
- a[n] 转换成指针引用 *(a + n)。
- 地址表达式加一个整数,C++将按比例增大地址,整数要乘以表达式基类型大小:
新地址 = 旧地址 + (整数* 基类型大小) - 一元操作符 * 和 ++ 具有从右到左的结合性,所以表达式 *p++ = 0; 相当于 *(p++) = 0; 。先将 *p 设为0,再递增指针p 来指向下个元素。
















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









