






Elasticsearch是一款强悍的分布式搜索和分析引擎,以下简称为ES,通过本文我简单介绍下ES7部分新特性,内容包括:
聚合查询的优化
search.max_buckets现在命名的动态集群设置默认为10,000(而不是之前版本中的无限制,生产中常见大查询造成内存溢出而被系统kill的现象发生)。尝试返回超过限制的请求将因异常而失败。
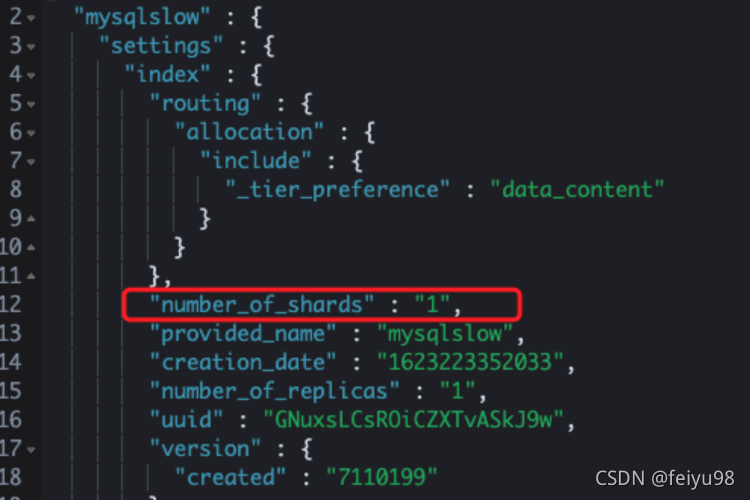
下面我们将测试search.max_buckets的作用,由于search.max_buckets对分片上生效,为了能达到测试的效果,我们设置索引test_aggs_max_buckets分片数为1。
创建测试索引test_aggs_max_buckets
PUT test_aggs_max_buckets
{
"settings":{
"number_of_shards" : 1
},
"mappings":{
"properties":{
"test_buckets":{
"type" : "text" ,
"fielddata":true
}
}
}
}
插入测试数据
>PUT test_aggs_max_buckets/_bulk
{"index":{"_id":1}}
{"test_buckets":"a"}
{"index":{"_id":2}}
{"test_buckets":"b"}
{"index":{"_id":3}}
{"test_buckets":"c"}
{"index":{"_id":4}}
{"test_buckets":"d"}
设置search.max_buckets为2
PUT /_cluster/settings
{"persistent": {"search.max_buckets": 2}}
聚合查询超过中分片中文档数超过2条
GET /test_aggs_max_buckets/_search
{"aggs":{
"term_aggs":{
"terms":{
"field":"test_buckets",
"size":3
}
}
}
}
见报错:

ES7中索引type被移除
ES6每一个index只能有一个type,在ES7中只能使用_doc作为type,type会在8.X版本彻底移除。因此api请求方式也发生相应的变化,例如新建mapping,如果没有设定include_type_name=true,不能再指定type(包括_doc)。

报错信息:

索引创建默认1个分片
以前版本的ES默认为每个索引创建5个分片。ES7默认值现在是每个索引一个分片。
多分片对于日志类的每天产生一个索引,会造成分片数急剧增长;分片太多对搜索并不友好,每个分片都是一个luence,都基于分片的评分返回相关文档,在数据量较少的情况下,可能会使结果集失真。当然,如果创建索引的时候我们依然可以自己设置分片数量。
优化查询速度
ES7底层用的是Lucene 8,Lucene 8为ES的许多功能的改进奠定了基础。
一般我们在计算文本相关性的时候,会通过倒排索引的方式进行查询,虽然通过倒排索引已经可以加快查询速度,但是当要在查询中返回TOP-K的结果,可能响应依然很慢,主要是一些较差的结果也进行了复杂的相关性算分,像用户经常查询的’a’,'the’等词汇,这种词汇不会增加多少文档得分,但迫使查询过程为大量的文档进行打分。
ES7在查询中返回TOP-K的结果时通过tracktotalhits参数来指定,默认值为10000,根据自己的需要设置返回前K个命中结果;或者设置为 true,返回全部命中结果数量。计算TOP-K的过程中需要评估文档的最大得分,这需要在索引过程中写入一些额外的信息。Lucene将词典划分一个个的block,并构建了一个跳跃表,在查询的时候跳过不匹配的文档,现在,索引过程中会为每个块中最高影响(impacts)的摘要添加到该跳表中,可以计算出该块可能产生的最大得分,如果该得分不具有竞争力,则可以跳过它。
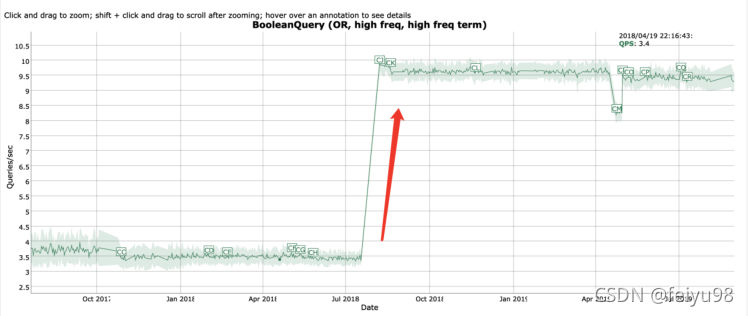
Bool or查询速度提高了近3倍
Term query速度提高了近40倍
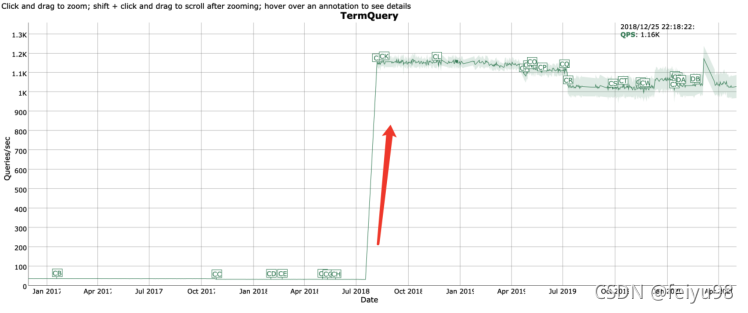
以上测试结果来自于lucene官方基准测试
hits.total返回对象
现在,与搜索请求匹配的总命中数将作为含有"value"和"relation"的对象返回,不再是具体的数值。value表示匹配数,relation表示值是准确的(eq)还是非准确的(gte)。

_flush和_force_merge不再强制生成新的segment
在以前的版本中,发出_flush或者 _force_merge(with flush=true)具有刷新索引的未记录的作用,这使得新文档对搜索和非实时GET操作可见。从现在开始,这些操作不再有这种作用。为了使文档可见_refresh ,除非索引被内部调度程序刷新,否则需要显式调用。
调用示例
PUT indices_name/_doc/1?refresh=true
track_total_hits 默认为 10,000
默认情况下,搜索请求将准确计算总命中数直至10,000 文档。如果与查询匹配的总命中数大于此值,则响应将指示返回值是下限

乐观并发控制的改进
ES为其存储的每个文档维护一个数字版本字段,该字段随着文档的每次更改而增加1,在ES7之前,API允许使用该字段进行乐观并发控制,即以当前文档版本为条件进行写操作。但是这种方法是有缺陷的,因为版本的值并不总是唯一地代表对文档的更改。如果主节点在处理写入操作时失败,它可能会公开一个版本,然后新的主节点会重用该版本。由于这个问题,内部版本控制不能再使用,而是被一种基于序列号的新方法所取代。参考地址
索引生命周期管理
索引生命周期管理(Index Lifecycle Management)作为一个beta特性在6.6发布,在7.0GA。索引生命周期管理现在可以管理frozen indices,他作为其cold阶段的一部分,frozen indices是只读的,不能索引它们。每次搜索分片时,ES都会构建冻结索引的每个分片的瞬态数据结构,并在搜索完成后立即丢弃这些数据结构。由于ES不会在内存中维护这些瞬态数据结构,因此冻结索引消耗的堆比普通索引少得多。与其他方式相比,这允许更高的磁盘堆比。也可以对其管理的索引使用CCR功能。frozen indices详情
不再内存溢出
ES7加了一个全新的断路器,可以跟踪JVM使用的总内存,如果请求导致预留的内存和实际堆使用量超过95%,则拒绝请求。官方还将更改默认的最大桶数search.max_buckets为10000,这在6及之前的版本中是不受限制的。
另外由于在早期版本的ES中默认启用了doc values,因此对fielddata的需求较少。ES7将该设置的默认值indices.breaker.fielddata.limit已从JVM堆大小的60%降低到40%。
后台延迟refresh搜索空闲的分片
ES6和之前的版本默认每秒都会在后台自动refresh索引数据,生成一个新的segment,ES可以“近乎实时”得到搜索结果。如果ES没有任何查询搜索的任务,那么这个功能就能对ES的性能影响是显著的。
ES7引入搜索空闲(search idle)的概念,在默认配置的情况下该分片如果在30秒内没有任何查询搜索,就处于搜索空闲状态,那么默认每秒的refresh任务都会被跳过,直至新的一次查询才会触发新的refresh任务。ES7如果明确设置了refresh间隔时间,则仍按配置中的间隔时间进行调度执行。
在生产中,大量的日志类索引查询搜索较少,减少refresh次数,相应减少segment个数,减少刷盘和merge的次数等,这会极大的提提升ES的吞吐量。
ES7自带JDK环境
ES运行依赖于JDK环境,对于小白来说,配置较为困难。ES7捆绑了一个OpenJDK发行版,以帮助用户更快地开始使用ES。同时也支持用户自己配置JDK。如果想使用自己机器环境的JDK,仍然可以通过在启动Elasticsearch之前设置JAVA_HOME来实现。
引入新的集群协调子系统
ES7以前的版本,集群故障转移依赖于配置minimum_master_nodes的设置。集群动态增减节点较为常见,因此维护此设置较为困难,这会使群集更容易出现裂脑和丢失数据的风险。ES7移除minimum_master_nodes参数,让ES自己选择可以形成仲裁的节点。典型的主节点选举现在只需要很短的时间就可以完成。
集群的伸缩变得更安全、更容易,并且可能造成丢失数据的系统配置选项更少了。节点更清楚地记录它们的状态,有助于诊断为什么它们不能加入集群或为什么无法选举出主节点。
搜索自动绕过busy的节点
虽然ES6的时候官方已经添加了一个实验性的自适应副本选择的特性。每个节点会跟踪和比较搜索请求与其他节点的耗时,并使用这个数据调整向特定节点上的分片发送请求的频率。在官网的基准测试中,这会很显著的提高搜索的吞吐量,但默认是关闭的。在ES7中是打开的,如果关闭这个功能,搜索的操作将会以循环方式发送到所有的索引分片。在生产中经常遇到data节点负载不均衡的想象,部分和该参数有一定的关系。
在ES6我们也可以用命令的方式打开该参数:
PUT _cluster/settings
{
"transient": {
"cluster.routing.use_adaptive_replica_selection":"true"
}
}
减少故障检测的默认超时时间
默认情况下,如果节点未能响应3次连续ping(每次10秒后超时),集群故障检测子系统现在会认为该节点出现故障。因此,无响应时间超过30秒的节点很可能会从集群中删除。以前,每次ping的默认超时为30秒,因此无响应的节点可能会在集群中保留90秒以上
关闭状态索引也可以复制
在ES7.2后关闭状态的索引也可以进行分片复制,以便于后面集群异常时可以成为主分片,或者进行数据恢复。
发现忽略主节点不合格节点
在早期版本中,可以在发现过程中使用非主节点作为种子节点或在主节点之间间接传输发现八卦。像这样依赖于非主节点的集群很脆弱,无法从某些类型的故障中自动恢复。发现现在只涉及集群中符合主节点的节点,因此不可能像这样依赖不符合主节点的节点。您应该配置 discovery.seed_hosts或其他种子主机提供程序来提供集群中所有符合主节点条件的节点的地址。
说明
ES7优化了很多功能,新增了很多新特性,详情请查看官方文档。
若说明有错,请予以指正,谢谢。

















 3034
3034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









