







CLoud
Critique-out-Loud Reward Models [pdf]
提出了一种奖励模型训练策略,不同于传统RM抛弃LM Head额外训练一个Reward Head的方式,CLoud保留LM Head并同时对两个头进行训练。
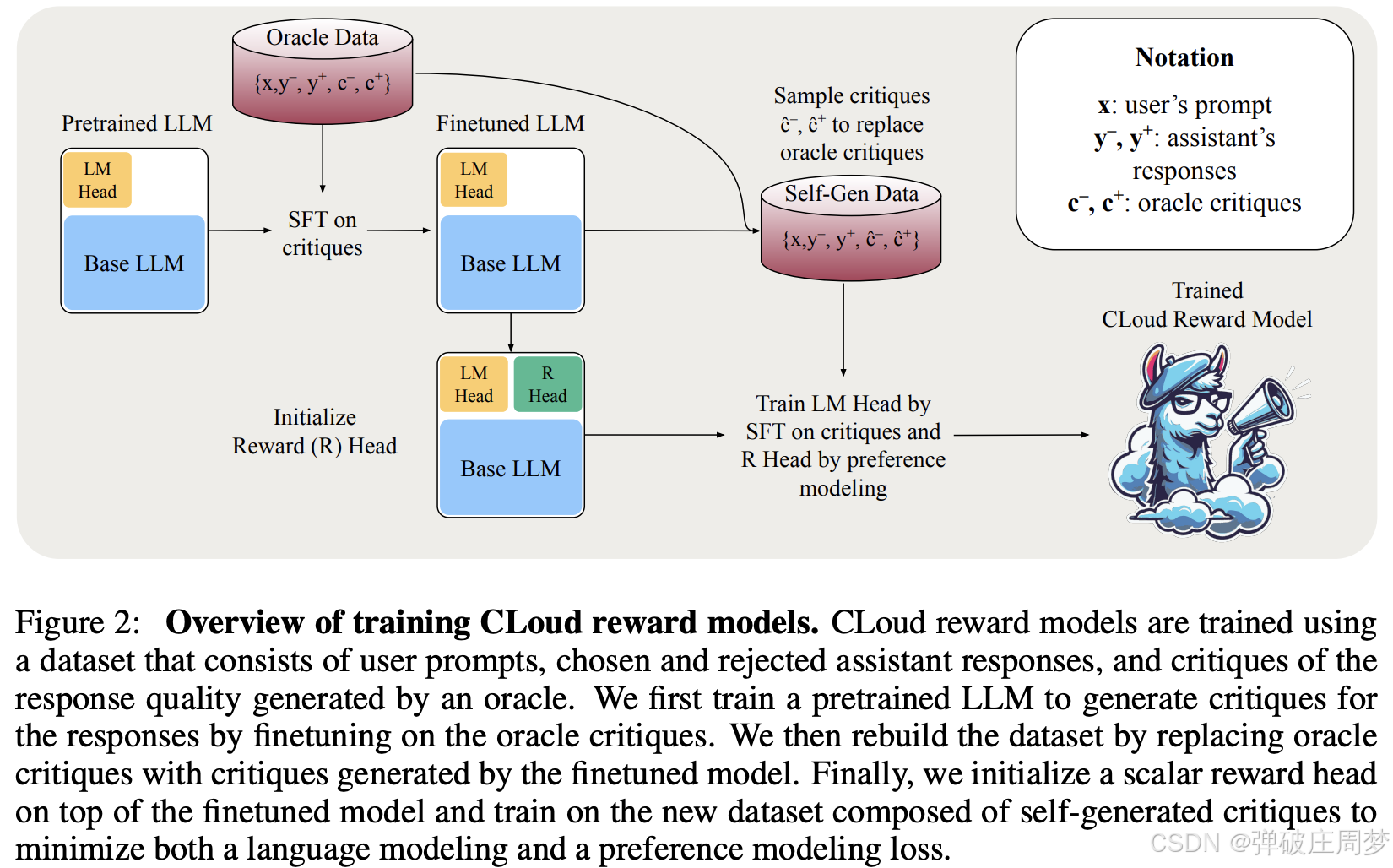
首先通过SFT让Pretrained LLM具备生成评论的能力,然后在它生成的评论与偏好集上训练出CLoud:
- 生成评论上的LM Loss是为了保留住整个模型的生成能力
- 将近似Ground Truth评论换成生成评论的操作很正常,减少了训练和推理的不一致(文中解释为on-policy和off-policy)
CLoud的Loss函数:
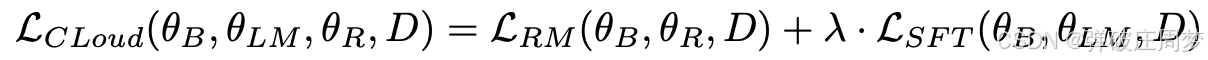
最终效果: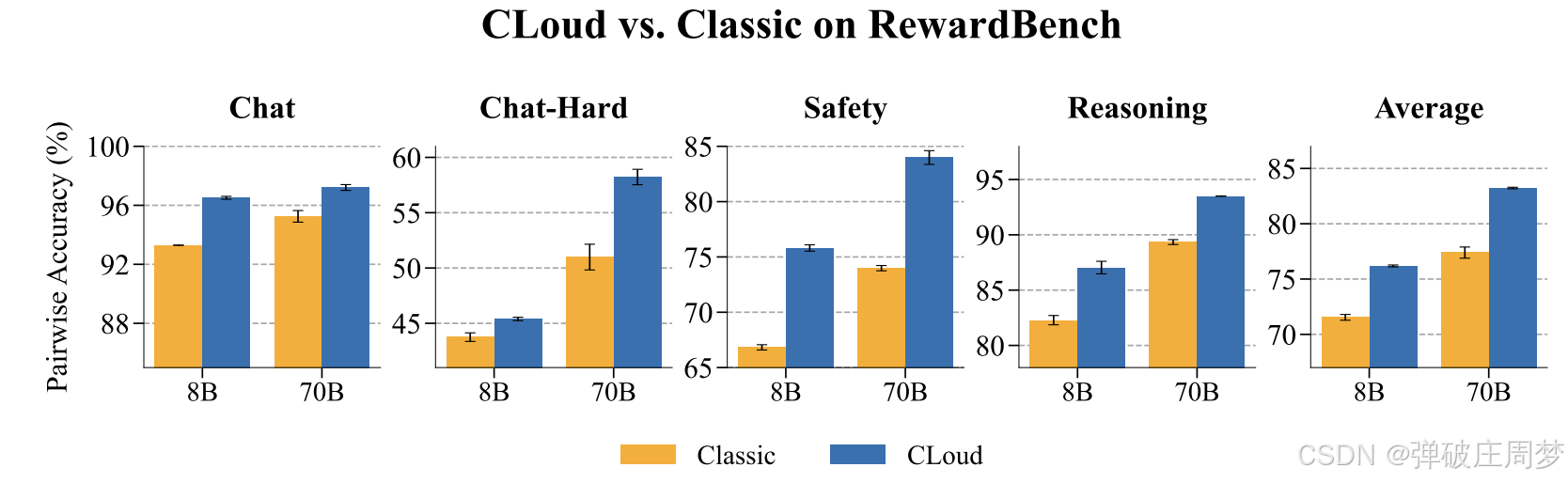
相较于传统RM有4、5个百分点的提升。
感觉就是保留住Base LLM的生成能力能提升它的奖励值预测能力。和CoT思路比较像,在输出结果前先输出思考过程,思考过程有利于做出最终决策。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









