






索引结构
Mysql按页来存储数据。

每个节点的第一个数据是其索引。通过建立索引可以快速查询。
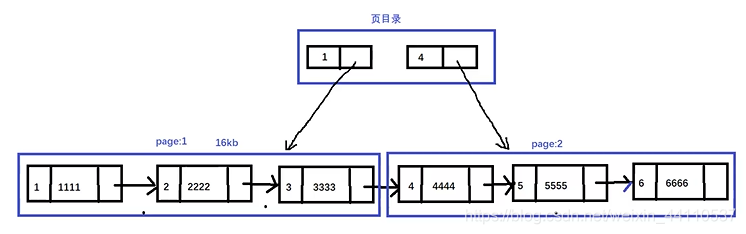
通过页目录能加快查询。如要查询大于索引大于4的节点则只需在页目录中找到4就行。
这种结构只在叶节点上挂数据。是B+树的结构,而不是B-树结构。为什么用B+树而不用B-树呢?因为B-树每个节点都要挂数据。这会导致页目录表示的范围不够。
可以将叶子节点中挂的数据的不同分为普通索引和聚集索引。
普通索引是指叶子节点并不是挂表中的这一行数据,而是挂行号。
聚集索引是指叶子结点中挂的是这个表中的这一行数据。
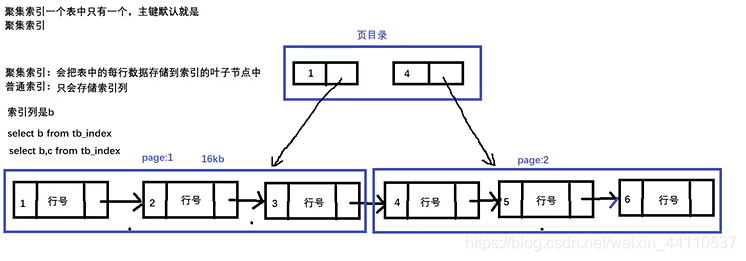
由于聚集索引只有一个(主键默认就是聚集索引)。所以当我们新建一个索引列b时这只能是一个普通索引。
当查询这个b这个索引列时,刚好这个b是一个索引,这也叫做覆盖索引。
这样他就会去查找这颗树。而当是查找b,c这两个字段时肯定还要到表中去找。
查询时最好不要回表查找。
MySQL索引失效
为什么会失效呢?,当使用联合索引查询时(相对于单值索引)比如a,b两个字段。
这两个字段的顺序如下:

可以发现a有序而b无序,但在a有序的情况下b也是有序的。(叶子结点就是按这个排序的)。
也就是说在查询时,一定要先查询确定下a,再查询b这样才能用到索引。(和书写的顺序无关,会做优化)否则的话a未确定b也就不能保证有序。这也就是说要保证最佳左前缀原理
像没遵循最佳左前缀法则、范围查询的右边会失效、like查询用不到索引这些失效情况基本都是基于这个原理。
如
select * from table where b=2
由于没有确定a 无法用到索引。
select * from table where a>5 and b=2
还是没用到索引,还是因为a没有确定。
select * from table where a like “%char”
由于%未表示确定的数据所以还是无法用到索引。
牛客上有这样的一道题:最佳左前缀
图来源b站讲解视频:mysql索引














 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









