






一 Elasticsearch7.2.0安装
安装Elasticsearch,需要保证elasticsearch、kibana、ik分词器这些的版本一致,否则会带来一些不兼容的问题。以下是容器安装单机Elasticsearch的教程
# docker安装es
docker run -d --name=elasticsearch7.2.0 -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx512m" elasticsearch:7.2.0
#ik分词器安装,版本要保持和es一致
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.2.0/elasticsearch-analysis-ik-7.2.0.zip
#拷贝ik分词器到容器内部插件
docker cp ./ik elasticsearch7.2.0:/usr/share/elasticsearch/plugins/
#重启es容器
docker restart elasticsearch7.2.0
#安装kibana
docker run -d --name kibana7.2.0 -p 5601:5601 kibana:7.2.0
#需要配置kibana.yml文件中的es地址
elasticsearch.hosts: [ "你的es的地址" ]
#重启kibana
docker restart kibana7.2.0
二.基础概念
1.倒排索引
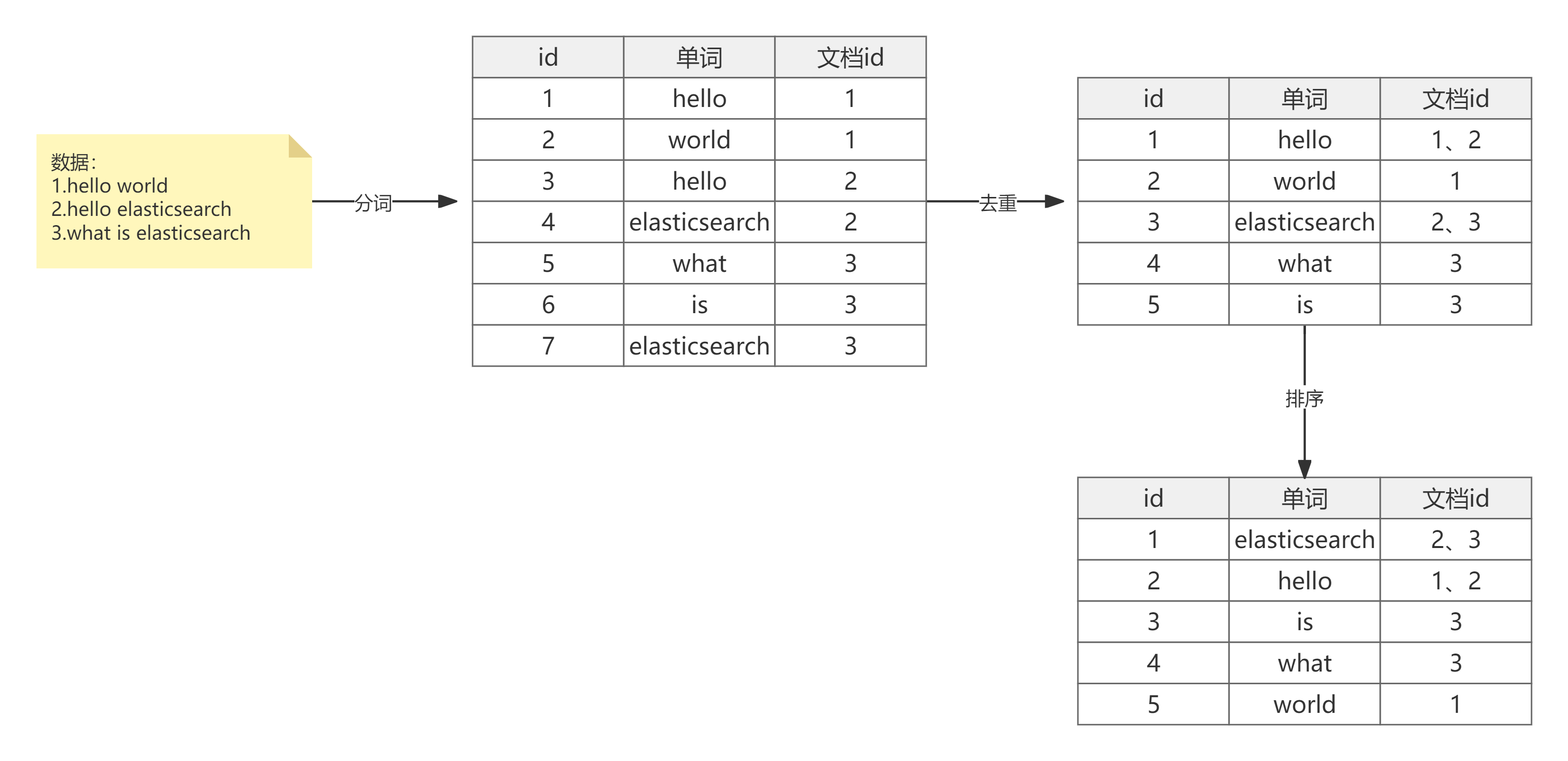
- 根据分词器进行分词
- 数据去重,记录单词出现的文档位置
- 根据字典序排序
- es还会在term词项的基础上利用term的前缀或者后缀构建term index,用于对term本身进行索引
- 倒排索引项构成
- 文档ID
- 词频TF-该单词在文档中出现的次数,用于相关性得分
- 位置-单词在文档中分词的位置。用于短语搜索
- 偏移-记录单词的开始结束位置,实现高亮显示
2.相关性算分
- es5.x之前的TF-IDF算分
- TF是词频,检索词在文档中出现的频率越高,该条文档的相关性也越高
- IDF逆向文本频率:每个检索词在整个索引库中出现的频率越高,该条文档的相关性越低
- 字段长度归一值:字段的长度越短,检索词所在的文档相关性越高。
- es5.x之后采用BM25的算法,主要位来改进TF-IDF的算分会随着TF词频增加而急剧的变大,BM25将这个增大趋势降低了,趋于平缓。
细节点
- elasticsearch的json文档中的每个字段,默认都有自己的倒排索引。可以手动指定字段不索引,这样就无法对该列进行搜索,好处在于节省存储空间。
- elasticsearch搜索非实时的原因,数据写入时先写到内存buffer缓冲区,每隔1s(刷新间隔时间refresh_interval)或者buffer满了才会将buffer数据写到segment file文件,这时候才可以查询到。可以通过refresh参数指定强制刷新,数据实时可见。
三.基础操作
1.索引操作
新建索引
#新建索引,在索引不存在时候才能执行成功
PUT /es_db
#新建索引,指定分片数和副本数
PUT /es_db
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
更新索引
#修改索引的副本数量
PUT /es_db/_settings
{
"number_of_replicas": 2
}
查询索引
#查询索引,可以查看索引具体信息
GET /es_db
#判断索引是否存在
HEAD /es_db
删除索引
DELETE /es_db
2.文档操作
文档新建
#新建索引,指定默认分词器
PUT /es_db
{
"settings": {
"analysis": {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
#新建一个指定id的文档
PUT /es_db/_doc/1
{
"name": "张三",
"sex": 1,
"age": 25,
"address": "广州天河公园",
"remark": "java developer"
}
#指定create进行创建文档
PUT /es_db/_create/1
{
"name": "张三",
"sex": 1,
"age": 25,
"address": "广州天河公园",
"remark": "java developer"
}
#已经存在id为1的文档,继续操作是更新操作,而且是全量更新,会先删除原有文档,再新建新文档
PUT /es_db/_doc/1
{
"name": "张三",
"sex": 1,
"age": 25
}
注意:PUT和POST操作都可以进行文档的新增/更新,PUT需要指定id才能操作,而POST在不指定id时候就是新增,指定id时候可以是新增/创建。
文档更新
全量更新,整个json都会替换,格式: [PUT | POST] /索引名称/_doc/id。如果文档存在,现有文档会被删除,新的文档会被索引
#全量更新
PUT /es_db/_doc/1/
{
"name": "张三",
"sex": 1,
"age": 25
}
使用_update部分更新,格式: POST /索引名称/_update/id。update不会删除原来的文档,而是实现真正的数据更新
#只更新需要更新的字段,id必须指定
POST /es_db/_update/1
{
"doc": {
"age": 28
}
}
使用 _update_by_query 更新文档。更新查询到的文档
POST /es_db/_update_by_query
{
"query": {
"match": {
"_id": 1
}
},
"script": {
"source": "ctx._source.age = 30"
}
}
并发场景下修改文档,采取乐观锁的机制去更新。
_seq_no和_primary_term是对_version的优化,7.X版本的ES默认使用这种方式控制版本,所以当在高并发环境下使用乐观锁机制修改文档时,要带上当前文档的_seq_no和_primary_term进行更新
POST /es_db/_doc/1?if_seq_no=21&if_primary_term=6
{
"name": "李四xxx"
}
查询文档
简单文档查询,DSL语句查询放在后面讲解
GET /es_db/_doc/1
删除文档
DELETE /es_db/_doc/1
批量操作
- 批量操作可以减少网络开销
- 在一次批量操作过程中,可以操作多个索引库
- 操作单条失败,不影响其他结果
- 返回结果包含每一条操作过程的执行结果
- 批量操作_bulk的api
POST _bulk
#指定操作的动作(create、index、update、delete),索引库,类型(_doc),id
{"actionName":{"_index":"indexName", "_type":"typeName","_id":"id"}}
#操作的数据内容
{"field1":"value1", "field2":"value2"}
批量创建文档create
POST _bulk
{"create":{"_index":"article","_type":"_doc","_id":3}}
{"id":3,"title":"老师A","content":"老师A666","tags":["java", "面向对象"],"create_time":1554015482530}
{"create":{"_index":"article","_type":"_doc","_id":4}}
{"id":4,"title":"老师B","content":"老师B-NB","tags":["java", "面向对象"],"create_time":1554015482530}
普通创建或全量替换index。如果原文档不存在,则是创建;如果原文档存在,则是替换(全量修改原文档)
POST _bulk
{"index":{"_index":"article","_type":"_doc","_id":1}}
{"id":3,"title":"老师A","content":"老师A666","tags":["java", "面向对象"],"create_time":1554015482530}
{"index":{"_index":"article","_type":"_doc","_id":4}}
{"id":4,"title":"老师B","content":"老师B-NB","tags":["java", "面向对象"],"create_time":1554015482530}
批量删除delete
POST _bulk
{"delete":{"_index":"article","_type":"_doc","_id":3}}
{"delete":{"_index":"article","_type":"_doc","_id":4}}
批量修改update
POST _bulk
{"update":{"_index":"article","_type":"_doc","_id":3}}
{"doc":{"title":"ES大法必修内功"}}
{"update":{"_index":"article","_type":"_doc","_id":4}}
{"doc":{"create_time":1554018421008}}
多种类型结合操作
#更新和删除一起执行
POST _bulk
{"update":{"_index":"article","_type":"_doc","_id":3}}
{"doc":{"title":"ES大法必修内功1"}}
{"delete":{"_index":"article","_type":"_doc","_id":4}}
批量读取mget和msearch
mget需要指定id,可以指定不同的index,也可以指定返回值source
#指定索引和id查询
GET _mget
{
"docs": [
{
"_index": "es_db",
"_id": 1
},
{
"_index": "article",
"_id": 3
}
]
}
#索引放在url上进行查询
GET /article/_mget
{
"docs": [
{
"_id": 1
},
{
"_id": 3
}
]
}
#简化方式
GET /article/_mget
{
"ids": [
"1",
"3"
]
}
四.文档映射Mapping
动态映射
在未定义Mapping映射关系时,在文档中插入数据,es会根据文档字段自动识别类型,称为动态映射。动态映射有可能有时无法推算出正确的类型,影响后面的使用。
| JSON类型 | Elasticsearch类型 |
|---|---|
| 字符串 | 匹配日期格式,设置成Date;匹配数字设置为float或long,该选项默认关闭;其余设置为Text,并且增加keyword子类型 |
| 布尔值 | boolean |
| 浮点数 | float |
| 整数 | long |
| 对象 | Object |
| 数组 | 由第一个非空数值的类型所决定 |
| 空值 | 忽略 |
静态映射
静态映射时elasticsearch事先定义好mapping的字段关系。
能否在后期更改Mapping的字段类型
- 新增加字段
- dynamic设为true时,有新增字段的文档写入时,mapping也会同时被更新
- dynamic设为false,Mapping不会被更新,新增字段的数据无法被索引,只存在_source中
- dynamic设为strict(严格控制策略),文档写入失败,抛出异常
- 对已有字段,一旦有数据写入,就不再支持修改字段的定义。只能通过reindex API来重建索引
索引重建流程
- 新建一个静态索引
- 把旧索引的数据通过reindex导入到新索引
- 删除原来的索引
- 为新索引起个别名,为原索引名
#数据导入,重建索引
POST _reindex
{
"source": {
"index": "user"
},
"dest": {
"index": "user2"
}
}
#设置别名
PUT /user2/_alias/user
1.常用Mapping参数设置
- index:设置当前字段是否被索引,默认true。设置为false时该字段不可被搜索。
- index_options:控制倒排索引记录的内容。
- docs:记录doc id (除text类型外的其他类型默认配置)
- freqs:记录doc id和term frequencies(词频)
- positions:记录doc id / term frequencies / term position(text类型默认配置)
- offsets: doc id / term frequencies / term posistion / character offsets
- null_value:需要对null值进行搜索,只有keywork类型支持设置null_value
- copy_to设置:将字段的数值拷贝到目标字段,满足一些特定的搜索需求。copy_to的目标字段不出现在_source中。
#配置provice和city的copy_to到full_address上
PUT /address
{
"mappings": {
"properties": {
"province": {
"type": "keyword",
"copy_to": "full_address"
},
"city": {
"type": "text",
"copy_to": "full_address"
}
}
},
"settings": {
"index": {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
#导入数据
PUT /address/_bulk
{"index":{"_id":"1"}}
{"province":"湖南","city":"长沙"}
{"index":{"_id":"2"}}
{"province":"湖南","city":"常德"}
{"index":{"_id":"3"}}
{"province":"广东","city":"广州"}
{"index":{"_id":"4"}}
{"province":"湖南","city":"邵阳"}
#根据copy_to的字段查询
GET /address/_search
{
"query": {
"match": {
"full_address": {
"query": "湖南常德",
"operator": "and"
}
}
}
}
五.索引模板Index Template
Index Templates可以帮助你设定Mappings和Settings,并按照一定的规则,自动匹配到新创建的索引之上
- 模版仅在一个索引被新创建时,才会产生作用。修改模版不会影响已创建的索引
- 模板应用顺序
- 应用Elasticsearch 默认的settings 和mappings
- 应用order数值低的lndex Template 中的设定
- 应用order高的 Index Template 中的设定,之前的设定会被覆盖
PUT /_template/template_default
{
"index_patterns": [
"*"
],
"order": 0,
"version": 1,
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
PUT /_template/template_test
{
"index_patterns": [
"test*"
],
"order": 1,
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1
},
"mappings": {
"date_detection": false,
"numeric_detection": true
}
}
6.动态模板Dynamic Template
用于定义某个索引的mapping中。匹配规则的字段,会动态映射成模板里面指定的规则
PUT my_index
{
"mappings": {
"dynamic_templates": [
{
#动态映射成Boolean的规则
"strings_as_boolean": {
"match_mapping_type": "string",
"match": "is*",
"mapping": {
"type": "boolean"
}
}
},
{
#动态映射成keywork的规则
"strings_as_keywords": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
#结合路径
PUT /my_test_index
{
"mappings": {
"dynamic_templates": [
{
"full_name": {
"path_match": "name.*",
"path_unmatch": "*.middle",
"mapping": {
"type": "text",
"copy_to": "full_name"
}
}
}
]
}
}
7.高级查询Query DSL
构建数据
PUT /es_db
{
"settings": {
"index": {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
PUT /es_db/_bulk
{"index":{"_id":"1"}}
{"name":"张三","sex":1,"age":25,"address":"广州天河公园","remark":"java developer"}
{"index":{"_id":"2"}}
{"name":"李四","sex":1,"age":28,"address":"广州荔湾大厦","remark":"java assistant"}
{"index":{"_id":"3"}}
{"name":"王五","sex":0,"age":26,"address":"广州白云山公园","remark":"php developer"}
{"index":{"_id":"4"}}
{"name":"赵六","sex":0,"age":22,"address":"长沙橘子洲","remark":"python assistant"}
查询所有match_all和深度分页,排序
默认分页大小size=10,from索引下标
POST /es_db/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 2
}
深度分页
from+size默认最大只能10000。可以通过设置_settings的index.max_result_window改变这个大小。这个主要用来限制内存的消耗,不建议修改。当深度分页查询时候,不建议使用from+size来查询。
深度分页查询scroll
- 查询命令增加scroll参数,指定游标查询窗口时间。会将符合条件的数据生成快照。
- 后面查询通过第一步返回scroll_id来进行查询,需要在窗口时间失效前使用。
- 缺点:
- 因为查询的是快照,数据如果存在更新,快照查的是旧数据。
- 查询需要在窗口有效期内执行,而且没办法往前翻页
- 大量快照存在时候也会占据比较多内存,可以手动释放
GET /es_db/_search?scroll=30s
{
"query": {
"match_all": {}
},
"size": 1
}
GET /_search/scroll
{
"scroll": "30s",
"scroll_id" :"DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAd2AWZEstSEx4b3JUV09tdG5Ia2U2QWt4Zw=="
}
#删除scroll快照,释放内存
DELETE /_search/scroll
{
"scroll_id":["DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAd2AWZEstSEx4b3JUV09tdG5Ia2U2QWt4Zw=="]
}
排序
操作排序不进行算分
#排序,分页
GET /es_db/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": "desc"
}
],
"from": 0,
"size": 5
}
指定返回字段_source
GET /es_db/_search
{
"query": {
"match_all": {}
},
"_source": [
"name",
"address"
]
}
match
- match在匹配时会对所查找的关键词进行分词,然后按分词匹配查找。
- match支持参数
- query:指定匹配的值
- operator : 匹配条件类型。and / or(默认)
- minmum_should_match:用来指定匹配分词的最小个数
GET /es_db/_search
{
"query": {
"match": {
"address": {
"query": "广州白云山公园",
"operator": "OR",
"minimum_should_match": 2
}
}
}
}
短语查询match_phrase
match_phrase 会将检索关键词分词。match_phrase的分词结果必须在被检索字段的分词中都包含,而且顺序必
须相同,而且默认必须都是连续的。可以通过slop参数来配置分词相隔多远依然匹配。
#广州、白云两个分词在广州白云山公园的position位置相隔2位,通过配置slop来匹配
GET /es_db/_search
{
"query": {
"match_phrase": {
"address": {
"query": "广州云山",
"slop": 2
}
}
}
}
多字段查询multi_match
同时匹配文档的多个字段。查询字段分词就将查询条件分词查询,查询字段不分词将查询条件不分词查询
GET /es_db/_search
{
"query": {
"multi_match": {
"query": "长沙张龙",
"fields": [
"address",
"name"
]
}
}
}
query_string对整个文档内容查询
在单个查询字符串中指定AND | OR | NOT条件。支持多字段搜索。查询字段分词就将查询条件分词查询,查询字段不分词将查询条件不分词查询
GET /es_db/_search
{
"query": {
#不指定字段就是查询整个文档
"query_string": {
"fields": [
"name",
"address"
],
"query": "张三 OR (广州 AND 王五)"
}
}
}
simple_query_string
类似Query String,但是会忽略错误的语法,同时只支持部分查询语法,不支持AND OR
NOT,会当作字符串处理。支持部分逻辑:
- +替代AND
- | 替代OR
- -替代NOT
GET /es_db/_search
{
"query": {
"simple_query_string": {
"fields": [
"name",
"address"
],
"query": "广州公园",
"default_operator": "AND"
}
}
}
GET /es_db/_search
{
"query": {
"simple_query_string": {
"fields": [
"name",
"address"
],
"query": "广州 + 公园"
}
}
}
关键词查询Term
term查询对查询条件不进行分词,所以在有些text字段类型的字段上,如果想要精准匹配整个字段,可以使用子类型的keyword来查询
GET /es_db/_search
{
"query": {
"term": {
"address.keyword": {
"value": "广州白云山公园"
}
}
}
}
英文在建立倒排索引时候,单词会被转成小写,如果查询条件有大写字母时候会匹配不上。可以通过建立索引时忽略大小写。
PUT /product
{
"settings": {
"analysis": {
"normalizer": {
#大小写忽略配置
"es_normalizer": {
"filter": [
"lowercase",
"asciifolding"
],
"type": "custom"
}
}
}
},
"mappings": {
"properties": {
"productId": {
"type": "text"
},
"productName": {
"type": "keyword",
"normalizer": "es_normalizer",#配置忽略大小写
"index": "true"
}
}
}
}
可以通过 Constant Score 将查询转换成一个 Filtering,避免算分,并利用缓存,提高性能
GET /es_db/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"address.keyword": "广州白云山公园"
}
}
}
}
}
term处理多值字段,term查询是包含,不是等于。比如term查询数组字段时候。
前缀查询prefix
- 它不会分析要搜索字符串,传入的前缀就是想要查找的前缀
- 默认状态下,前缀查询不做相关度分数计算,它只是将所有匹配的文档返回。它的行为更像是一个过滤器而不是查询。两者实际的区别就是过滤器是可以被缓存的,而前缀查询不行。
- prefix的原理:需要遍历所有倒排索引,并比较每个term是否已所指定的前缀开头。
GET /es_db/_search
{
"query": {
"prefix": {
"address": {
"value": "广州"
}
}
}
}
范围查询range
- range:范围关键字
- gte 大于等于
- lte 小于等于
- gt 大于
- lt 小于
- now 当前时间
POST /es_db/_search
{
"query": {
"range": {
"age": {
"gte": 25,
"lte": 28
}
}
}
}
模糊查询fuzzy
在Elasticsearch中,我们可以使用fuzziness属性来进行模糊查询,从而达到搜索有错别字的情形。
fuzziness表示允许的错误字符数,指新增一个字符、删除一个字符、修改一个字符
prefix_length:表示限制输入关键字和ES对应查询field的内容开头的第n个字符必须完全匹配,不允许错别字匹配
GET /es_db/_search
{
"query": {
"fuzzy": {
"address": {
"value": "山",
"fuzziness": 1
}
}
}
}
注意: fuzzy 模糊查询 最大模糊错误 必须在0-2之间
- 搜索关键词长度为 2,不允许存在模糊
- 搜索关键词长度为3-5,允许1次模糊
- 搜索关键词长度大于5,允许最大2次模糊
高亮highlight
可以让符合条件的文档中的关键词高亮。
highlight相关属性:
- pre_tags 前缀标签
- post_tags 后缀标签
- tags_schema 设置为styled可以使用内置高亮样式
- require_field_match 多字段高亮需要设置为false
GET /products/_search
{
"query": {
"term": {
"name": {
"value": "牛仔"
}
}
},
"highlight": {
#指定高亮的前后标签
"pre_tags": [
"<font color='red'>"
],
"post_tags": [
"<font/>"
],
"require_field_match": "false",
# 指定需要高亮的字段
"fields": {
"name": {},
"desc": {}
}
}
}
Boosting控制相关性得分
参数boost的含义:
- 当boost > 1时,打分的权重相对性提升
- 当0 < boost <1时,打分的权重相对性降低
- 当boost <0时,贡献负分
返回匹配positive查询的文档并降低匹配negative查询的文档相似度分。
GET /test_score/_search
{
"query": {
"boosting": {
"positive": {
"term": {
"content": "elasticsearch"
}
},
#匹配消极的
"negative": {
"term": {
"content": "like"
}
},
#消极的会乘上这个系数
"negative_boost": 0.2
}
}
}
布尔查询bool Query
- 一个bool查询,是一个或者多个查询子句的组合,总共包括4种子句,其中2种会影响算分,2种不影响算分。
- must: 相当于&& ,必须匹配,贡献算分
- should: 相当于|| ,选择性匹配,贡献算分
- must_not: 相当于! ,必须不能匹配,不贡献算分
- filter: 必须匹配,不贡献算法
- 在Elasticsearch中,有Query和 Filter两种不同的Context
- Query Context: 相关性算分
- Filter Context: 不需要算分 ,可以利用Cache,获得更好的性能
- 如果多条查询子句被合并为一条复合查询语句,比如 bool查询,则每个查询子句计算得出的评分会被合并到总的相关性评分中。
单字符串多字段查询
最佳字段(Best Fields)
- 当字段之间相互竞争,又相互关联。例如,对于博客的 title和 body这样的字段,评分来自最匹配字段。
- 最佳字段查询Dis Max Query,通过tie_breaker参数调整。Tier Breaker是一个介于0-1之间的浮点数。0代表使用最佳匹配;1代表所有语句同等重要。
- 获得最佳匹配语句的评分_score 。
- 将其他匹配语句的评分与tie_breaker相乘
- 对以上评分求和并规范化
#构建数据
PUT /blogs/_doc/1
{
"title": "Quick brown rabbits",
"body": "Brown rabbits are commonly seen."
}
PUT /blogs/_doc/2
{
"title": "Keeping pets healthy",
"body": "My quick brown fox eats rabbits on a regular basis."
}
#使用bool should的算法,得到的id为1的分比较高,而id为2的body有完全匹配的缺排在后面
POST /blogs/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "Brown fox"
}
},
{
"match": {
"body": "Brown fox"
}
}
]
}
}
}
#采用dis_max可以得到想要的结果
POST /blogs/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"title": "Quick pets"
}
},
{
"match": {
"body": "Quick pets"
}
}
],
"tie_breaker": 0.2
}
}
}
bool should的算法过程:
- 查询should语句中的两个查询
- 加和两个查询的评分
- 乘以匹配语句的总数
- 除以所有语句的总数
Multi Match Query最佳字段(Best Fields)搜索
Best Fields是默认类型,可以不用指定
POST /blogs/_search
{
"query": {
"multi_match": {
"type": "best_fields",
"query": "Quick pets",
"fields": [
"title",
"body"
],
"tie_breaker": 0.2
}
}
}
使用多数字段(Most Fields)搜索
#title字段使用english分词器,title的子字段std使用standard分词器
#给title字段的评分进行*10
GET /titles/_search
{
"query": {
"bool": {
"query": "barking dogs",
"type": "most_fields",
"fields": [
"title^10",
"title.std"
]
}
}
}
跨字段(Cross Field)搜索
- Cross Field可以跨多个字段进行匹配,对比copy_to,可以节省空间
GET /address/_search
{
"query": {
"multi_match": {
"query": "湖南常德",
"type": "cross_fields",
"operator": "and",
"fields": [
"province",
"city"
]
}
}
}
8.聚合操作
数据准备
#创建索引库
PUT /employees
{
"mappings": {
"properties": {
"age": {
"type": "integer"
},
"gender": {
"type": "keyword"
},
"job": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 50
}
}
},
"name": {
"type": "keyword"
},
"salary": {
"type": "integer"
}
}
}
}
#插入数据
PUT /employees/_bulk
{"index":{"_id":"1"}}
{"name":"Emma","age":32,"job":"Product Manager","gender":"female","salary":35000}
{"index":{"_id":"2"}}
{"name":"Underwood","age":41,"job":"Dev Manager","gender":"male","salary":50000}
{"index":{"_id":"3"}}
{"name":"Tran","age":25,"job":"WebDesigner","gender":"male","salary":18000}
{"index":{"_id":"4"}}
{"name":"Rivera","age":26,"job":"Web Designer","gender":"female","salary":22000}
{"index":{"_id":"5"}}
{"name":"Rose","age":25,"job":"QA","gender":"female","salary":18000}
{"index":{"_id":"6"}}
{"name":"Lucy","age":31,"job":"QA","gender":"female","salary":25000}
{"index":{"_id":"7"}}
{"name":"Byrd","age":27,"job":"QA","gender":"male","salary":20000}
{"index":{"_id":"8"}}
{"name":"Foster","age":27,"job":"Java Programmer","gender":"male","salary":20000}
{"index":{"_id":"9"}}
{"name":"Gregory","age":32,"job":"Java Programmer","gender":"male","salary":22000}
{"index":{"_id":"10"}}
{"name":"Bryant","age":20,"job":"Java Programmer","gender":"male","salary":9000}
{"index":{"_id":"11"}}
{"name":"Jenny","age":36,"job":"Java Programmer","gender":"female","salary":38000}
{"index":{"_id":"12"}}
{"name":"Mcdonald","age":31,"job":"JavaProgrammer","gender":"male","salary":32000}
{"index":{"_id":"13"}}
{"name":"Jonthna","age":30,"job":"JavaProgrammer","gender":"female","salary":30000}
{"index":{"_id":"14"}}
{"name":"Marshall","age":32,"job":"Javascript Programmer","gender":"male","salary":25000}
{"index":{"_id":"15"}}
{"name":"King","age":33,"job":"Java Programmer","gender":"male","salary":28000}
{"index":{"_id":"16"}}
{"name":"Mccarthy","age":21,"job":"Javascript Programmer","gender":"male","salary":16000}
{"index":{"_id":"17"}}
{"name":"Goodwin","age":25,"job":"Javascript Programmer","gender":"male","salary":16000}
{"index":{"_id":"18"}}
{"name":"Catherine","age":29,"job":"JavascriptProgrammer","gender":"female","salary":20000}
{"index":{"_id":"19"}}
{"name":"Boone","age":30,"job":"DBA","gender":"male","salary":30000}
{"index":{"_id":"20"}}
{ "name" : "Kathy","age":29,"job":"DBA","gender":"female","salary": 20000}
Metric Aggregation,可以对文档字段进行统计分析,类比Mysql中的 min(), max(), sum() 操作
POST /employees/_search
{
"size": 0,
"aggs": {
"max_salary": {
"max": {
"field": "salary"
}
},
"min_salary": {
"min": {
"field": "salary"
}
},
"avg_salary": {
"avg": {
"field": "salary"
}
},
"stats_salary": {
"stats": {
"field": "salary"
}
}
}
}
#去重
POST /employees/_search
{
"size": 0,
"aggs": {
"cardinate": {
"cardinality": {
"field": "job.keyword"
}
}
}
}
Bucket Aggregation分桶聚合
- Terms,需要字段支持filedata,keyword 默认支持fielddata,text也可以开启fielddata,但对文档分词后分桶没啥作用。
- 数字类型,可以Range / Data Range,Histogram(直方图) / Date Histogram进行分桶
- 支持嵌套: 也就在桶里再做分桶
#先进行分桶,然后对桶内进行聚合
POST employees/_search
{
"size": 0,
"aggs": {
"Job_salary_stats": {
"terms": {
"field": "job.keyword"
},
"aggs": {
"salary": {
"stats": {
"field": "salary"
}
}
}
}
}
}
#按范围进行分桶
POST employees/_search
{
"size": 0,
"aggs": {
"salary_range": {
"range": {
"field": "salary",
"ranges": [
{
"to": 10000
},
{
"from": 10000,
"to": 20000
},
{
"key": ">20000",
"from": 20000
}
]
}
}
}
}
#直方图分桶,以5000为一个区间
POST employees/_search
{
"size": 0,
"aggs": {
"salary_histrogram": {
"histogram": {
"field": "salary",
"interval": 5000,
"extended_bounds": {
"min": 0,
"max": 100000
}
}
}
}
}
top_hits应用场景: 当获取分桶后,桶内最匹配的顶部文档列表
#返回每个分桶内年龄最大的3个
POST /employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword"
},
"aggs": {
"old_employee": {
"top_hits": {
"size": 3,
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
}
}
}
}
}
Pipeline Aggregation支持对聚合分析的结果,再次进行聚合分析。
min_bucket使用
# 平均工资最低的工种
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
},
"min_salary_by_job": {
"min_bucket": {
"buckets_path": "jobs>avg_salary"
}
}
}
}
聚合分析不精确原因分析
- 数据分散到多个分片,聚合是每个分片的取 Top X,然后在协调节点进行数据聚合,可能导致结果不精准。
- 解决方式
- 设置主分片为1
- 调大 shard_size 值。这个值是聚合时候每次从每个分片获取shard_size条。shard_size数值越大,结果越准确,但性能越差。官方推荐这个值为size*1.5+10。
聚合性能优化
- 启用 eager global ordinals 提升高基数聚合性能
- 插入数据时对索引进行预排序
- 会导致写性能下降
- 使用节点查询缓存,可用于有效缓存过滤器(filter)操作的结果
- 使用分片请求缓存,设置:size:0,就会使用分片请求缓存缓存结果。
- 拆分聚合,使聚合并行化。借助msearch实现并行聚合。
- 默认情况下,聚合不是并行运行。所以可以用msearch来优化并行聚合
8.Elasticsearch集群架构
核心概念
集群
- 一个集群可以有一个或者多个节点
- 不同的集群通过不同的名字来区分,默认名字“elasticsearch“
- 通过配置文件修改,或者在命令行中 -E cluster.name=es-cluster进行设定
节点
- master node:可以允许作为主节点的节点。被选为主节点的作用:
- 处理索引的创建删除
- 决定分片被分配到哪个节点
- 维护并且更新Cluster State
- data node:存储数据的节点
- 通过增加数据节点可以解决数据水平扩展和解决数据单点问题。原有存在的索引需要重建索引才能做到水平拓展。
- Coordinating Node:协调节点。负责接受Client的请求, 将请求分发到合适的节点,最终把结果汇集到一起
- Ingest Node:数据前置处理转换节点,支持pipeline管道设置,可以使用ingest对数据进行过滤、转换等操作
- 其他节点类型:Hot & Warm Node,Machine Learning Node
分片
- 主分片
- 数据水平拓展
- 一个分片就是一个运行的lucene实例
- 主分片数在索引创建时候指定,不允许修改,只能通过Reindex来重建
- 副本分片
- 解决数据高可用
- 可以动态调整副本分片数
- 增加副本数,可以一定程度提升服务可用性,读取的吞吐
- 副本会影响写入数据的性能
- 分片带来的问题
- 影响聚合查询结果和相关性打分。
- 相关性得分是在每个分片上面单独计算的,可以通过指定search_type=dfs_query_then_fetch来解决,这个原理是把数据从每个分片查询到协调节点,在协调节点上进行重新算分。
- 分片数量不宜过多,对master节点维护元数据加大负担
- 影响聚合查询结果和相关性打分。
集群的搭建
修改/etc/hosts
vim /etc/hosts
192.168.65.174 es‐node1
192.168.65.192 es‐node2
192.168.65.204 es‐node3
修改每个节点的elasticsearch.yml
#192.168.65.174的配置
# 指定集群名称3个节点必须一致
cluster.name: es‐cluster
#指定节点名称,每个节点名字唯一
node.name: node‐1
#是否有资格为master节点,默认为true
node.master: true
#是否为data节点,默认为true
node.data: true
# 绑定ip,开启远程访问,可以配置0.0.0.0
network.host: 0.0.0.0
#用于节点发现
discovery.seed_hosts: ["es‐node1", "es‐node2", "es‐node3"]
#7.0新引入的配置项,初始仲裁,仅在整个集群首次启动时才需要初始仲裁。
#该选项配置为node.name的值,指定可以初始化集群节点的名称
cluster.initial_master_nodes: ["node‐1","node‐2","node‐3"]
#解决跨域问题
http.cors.enabled: true
http.cors.allow‐origin: "*"
#192.168.65.192的配置
cluster.name: es‐cluster
node.name: node‐3
node.master: true
node.data: true
network.host: 0.0.0.0
discovery.seed_hosts: ["es‐node1", "es‐node2", "es‐node3"]
cluster.initial_master_nodes: ["node‐1","node‐2","node‐3"]
http.cors.enabled: true
http.cors.allow‐origin: "*"
#192.168.65.204的配置
cluster.name: es‐cluster
node.name: node‐2
node.master: true
node.data: true
network.host: 0.0.0.0
discovery.seed_hosts: ["es‐node1", "es‐node2", "es‐node3"]
cluster.initial_master_nodes: ["node‐1","node‐2","node‐3"]
http.cors.enabled: true
http.cors.allow‐origin: "*"
可以通过安装 Cerebro来访问集群。下载地址https://github.com/lmenezes/cerebro/releases/download/v0.9.4/cerebro-0.9.4.zip
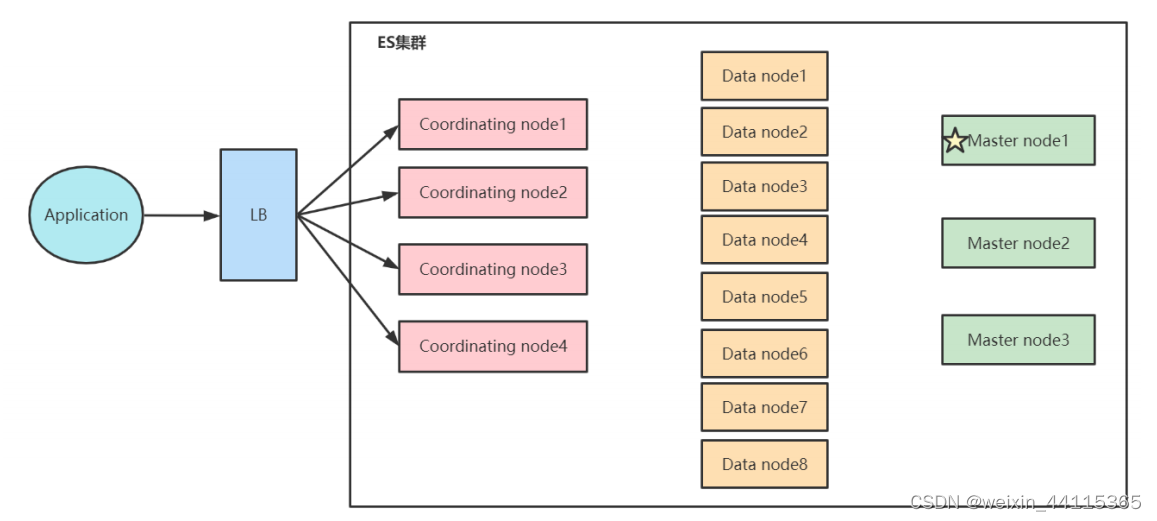
生产环境常见部署结构
大量读请求架构,通过协调节点处理查询
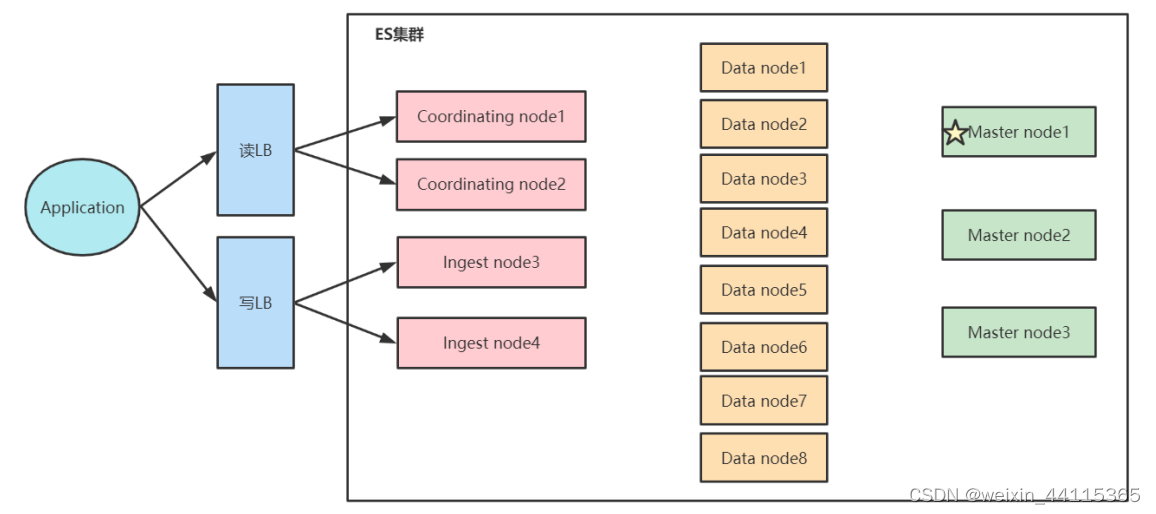
读写分离架构
通过引入数据处理节点和协调节点处理不同业务
跨集群搜索方案Cross Cluster Search(CCS)
在每个集群上进行配置
//在每个集群上设置动态的设置
PUT _cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"cluster0": {
"seeds": [
"127.0.0.1:9300"
],
"transport.ping_schedule": "30s"
},
"cluster1": {
"seeds": [
"127.0.0.1:9301"
],
"transport.compress": true,
"skip_unavailable": true
},
"cluster2": {
"seeds": [
"127.0.0.1:9302"
]
}
}
}
}
}
跨集群搜索
#查询结果获取到所有集群符合要求的数据
#指定每个集群的索引
GET /users,cluster1:users,cluster2:users/_search
{
"query": {
"range": {
"age": {
"gte": 30,
"lte": 40
}
}
}
}
Elasticsearch读写工作原理
写请求是写入 primary shard,然后同步给所有的 replica shard;读请求可以从 primaryshard 或 replica shard 读取,采用的是随机轮询算法。
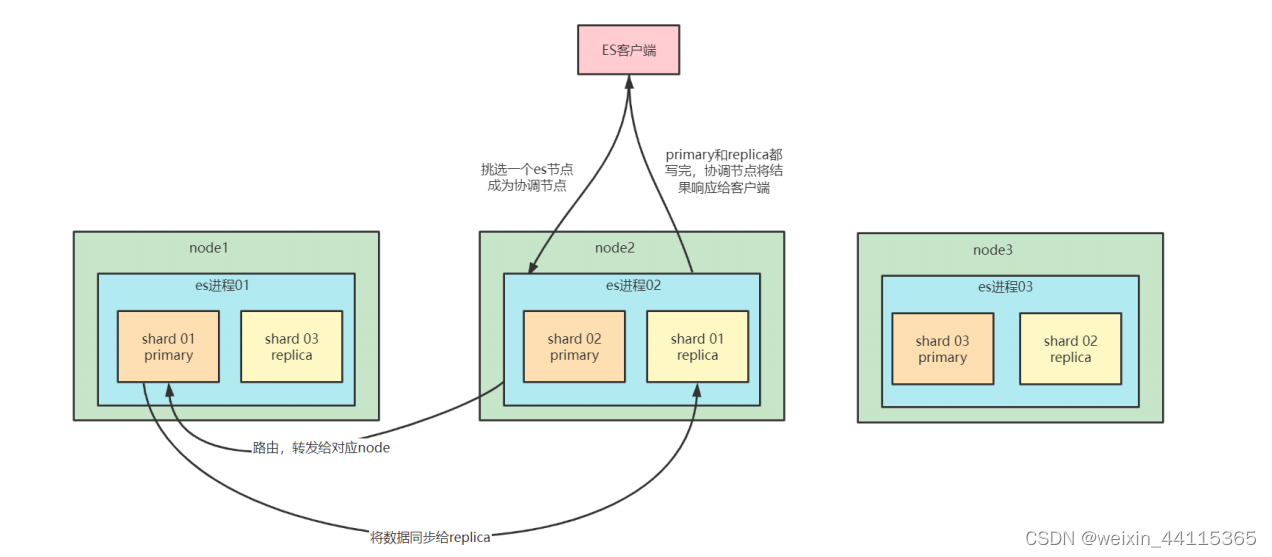
ES写入数据的过程
- 客户端选择一个node发送请求过去,这个node就是coordinating node (协调节点)
- coordinating node,对document进行路由,将请求转发给对应的node
- node上的primary shard处理请求,然后将数据同步到replica node
- coordinating node如果发现primary node和所有的replica node都搞定之后,就会返回请求到客户端
ES读取数据的过程
根据id查询数据的过程。根据 doc id 进行 hash,判断出来当时把 doc id 分配到了哪个 shard 上面去,从那个shard 去查询。
- 客户端发送请求到任意一个 node,成为 coordinate node 。
- coordinate node 对 doc id 进行哈希路由,将请求转发到对应的 node,此时会使用 round-robin 随机轮询算法,在 primary shard 以及其所有 replica 中随机选择一个,让读请求负载均衡。
- 接收请求的 node 返回 document 给 coordinate node 。
- coordinate node 返回 document 给客户端。
根据关键词查询数据的过程
- 客户端发送请求到一个 coordinate node 。
- 协调节点将搜索请求转发到所有的 shard 对应的 primary shard 或 replica shard ,都可以。
- query phase:每个 shard 将自己的搜索结果返回给协调节点,由协调节点进行
- 数据的合并、排序、分页等操作,产出最终结果。
- fetch phase:接着由协调节点根据 doc id 去各个节点上拉取实际的document 数据,最终返回给客户端。有点类似mysql的回表查询
写数据底层原理
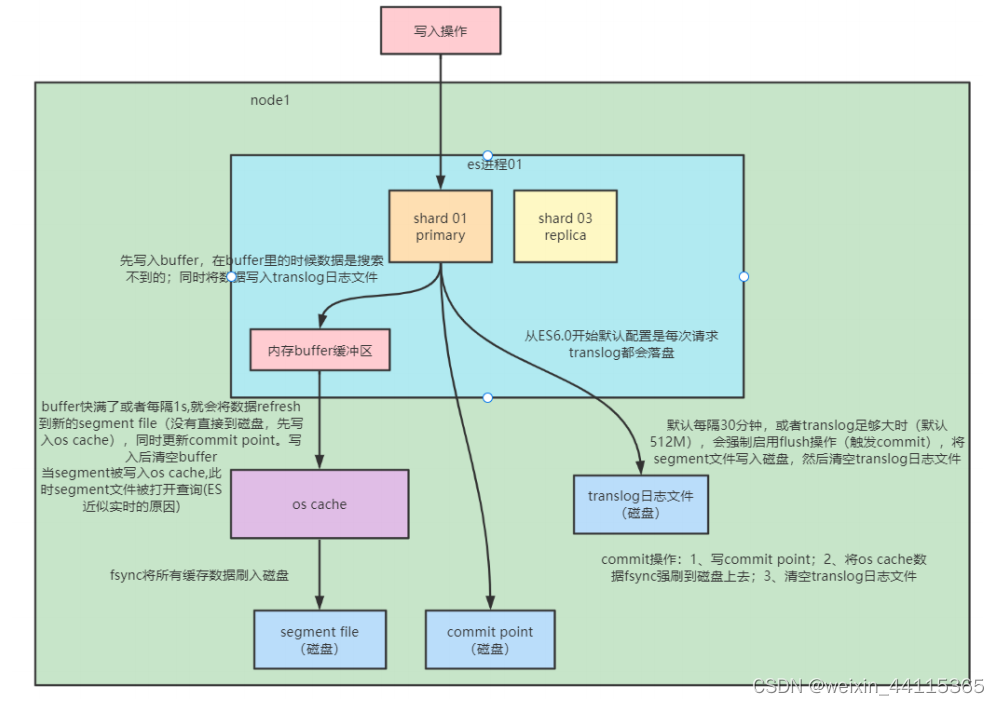
- segment file: 存储倒排索引的文件,每个segment本质上就是一个倒排索引,每秒都会生成一个segment文件,当文件过多时es会自动进行segment merge(合并文件),合并时会同时将已经标注删除的文档物理删除。
- commit point: 记录当前所有可用的segment,每个commit point都会维护一个.del文件,即每个.del文件都有一个commit point文件(es删除数据本质是不属于物理删除),当es做删改操作时首先会在.del文件中声明某个document已经被删除,文件内记录了在某个segment内某个文档已经被删除,当查询请求过来时在segment中被删除的文件是能够查出来的,但是当返回结果时会根据commit point维护的那个.del文件把已经删除的文档过滤掉
- translog日志文件: 为了防止elasticsearch宕机造成数据丢失保证可靠存储,es会将每次写入数据同时写到translog日志中。
- os cache:操作系统里面,磁盘文件其实都有一个东西,叫做os cache,操作系统缓存,就是说数据写入磁盘文件之前,会先进入os cache,先进入操作系统级别的一个内存缓存中去
- Refresh: 将文档先保存在Index buffer中,以refresh_interval为间隔时间,定期清空buffer,生成 segment,借助文件系统缓存的特性,先将segment放在文件系统缓存中,并开放查询,以提升搜索的实时性
- Translog: Segment没有写入磁盘,即便发生了当机,重启后,数据也能恢复,从ES6.0开始默认配置是每次请求都会落盘
- Flush: 删除旧的translog 文件生成Segment并写入磁盘│更新commit point并写入磁盘。ES自动完成,可优化点不多















 3701
3701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









