






批量归一化(Batch Normalization, BN)和层归一化(Layer Normalization, LN)是深度学习中常用的两种归一化技术,它们主要用于解决训练过程中的内部协变量偏移问题,加速模型收敛和提高稳定性。
1. 为什么需要归一化
由于数据来源的不同,不同数据的特征分布是不一致的。模型在训练过程中学习了这个批次的特征分布,如果下一批次的特征分布截然不同,那么模型的参数就会剧烈变化,得学习很多次之后才能平衡好不同特征分布的权重,造成训练过程变慢。
借用李沐老师的一张图:
在深度网络中,梯度通过反向传播需要从顶部层逐层传递到底部层。由于链式法则,每传递一层,梯度都会乘以该层权重的导数。如果这些导数较小,梯度会迅速衰减,导致底部层的权重更新非常缓慢,这就是所谓的梯度消失问题。
在深度学习中,底层数据会学习到底层的特征,比如图像的轮廓,顶层数据会学习到高级的特征,比如细腻的纹理等等。高级的纹理特征往往依赖于底层的基础特征,如果底层没有收敛的话,顶层的微调意义并不大。每一次的底层特征变化都会让顶层重新学习,所以底层的收敛慢决定了整个模型的收敛速度慢。
因此需要归一化来让将所有批数据强制在统一的数据分布下,加速收敛。
2. 什么是归一化
以批量归一化举例

但是批量归一化同时也降低了模型的拟合能力,归一化之后的输入分布被强制拉到均值为0和标准差为1的正态分布上来,简单来说特征之间的距离不会跑的很远,大部分特征都在正态分布的那个峰值附近。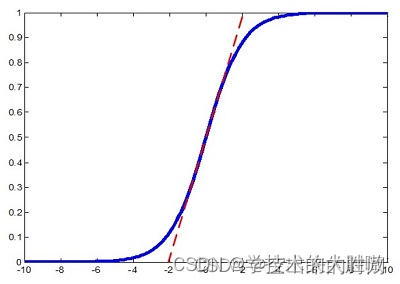
以Sigmoid激活函数为例,批量归一化之后数据整体处于函数的非饱和区域,只包含线性变换(多层的线性函数跟一层线性网络是等价的,网络的表达能力下降),破坏了之前学习到的特征分布。因此,为了使得归一化不对网络的表达能力造成负面印象,可以通过一个附加的缩放和平移变换改变取值区间。
3. 归一化是怎么实现的

批量归一化和层归一化的区别可以看下图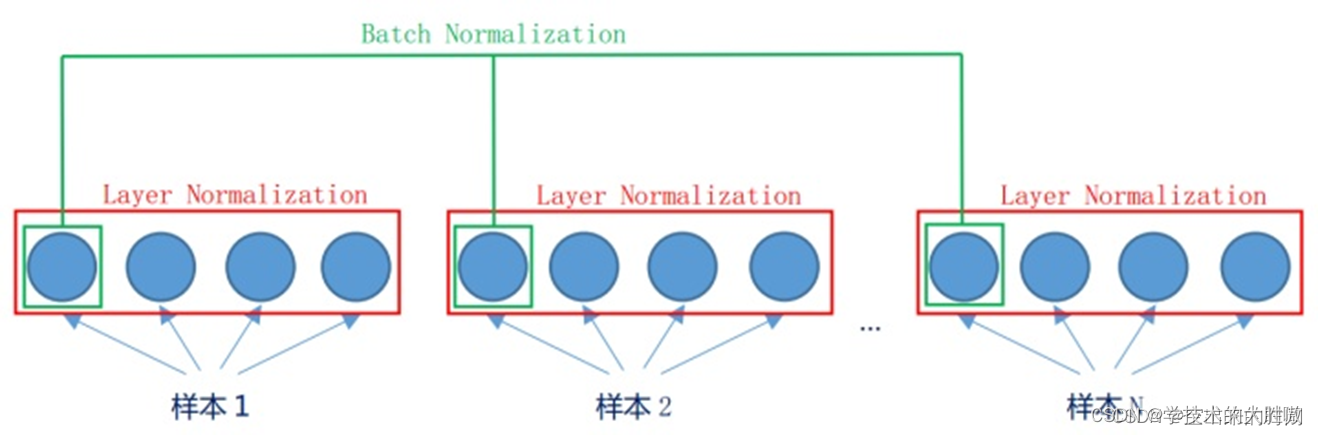
如果卷积计算输出多个通道,我们需要对这些通道的输出分别做批量归一化,且每个通道都拥有独立的拉伸和偏移参数,并均为标量。设小批量中有N个样本。在单个通道上,假设卷积计算输出的高和宽分别为h和w。我们需要对该通道中N×h×w个元素同时做批量归一化。
而层归一化就是对一个样本中的所有通道进行取归一化计算。
个人理解是BN消除特征间的差别而保留样本间的差别,LN保留了特征间的差别而消除了样本间的差别。
4. 注意点
训练时的均值和方差是计算每个批次中的样本,而训练时则是计算所有样本中的均值和方差。















 144
144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









