






1. 下载字体:可访问Github按照自己喜欢的方式下载,
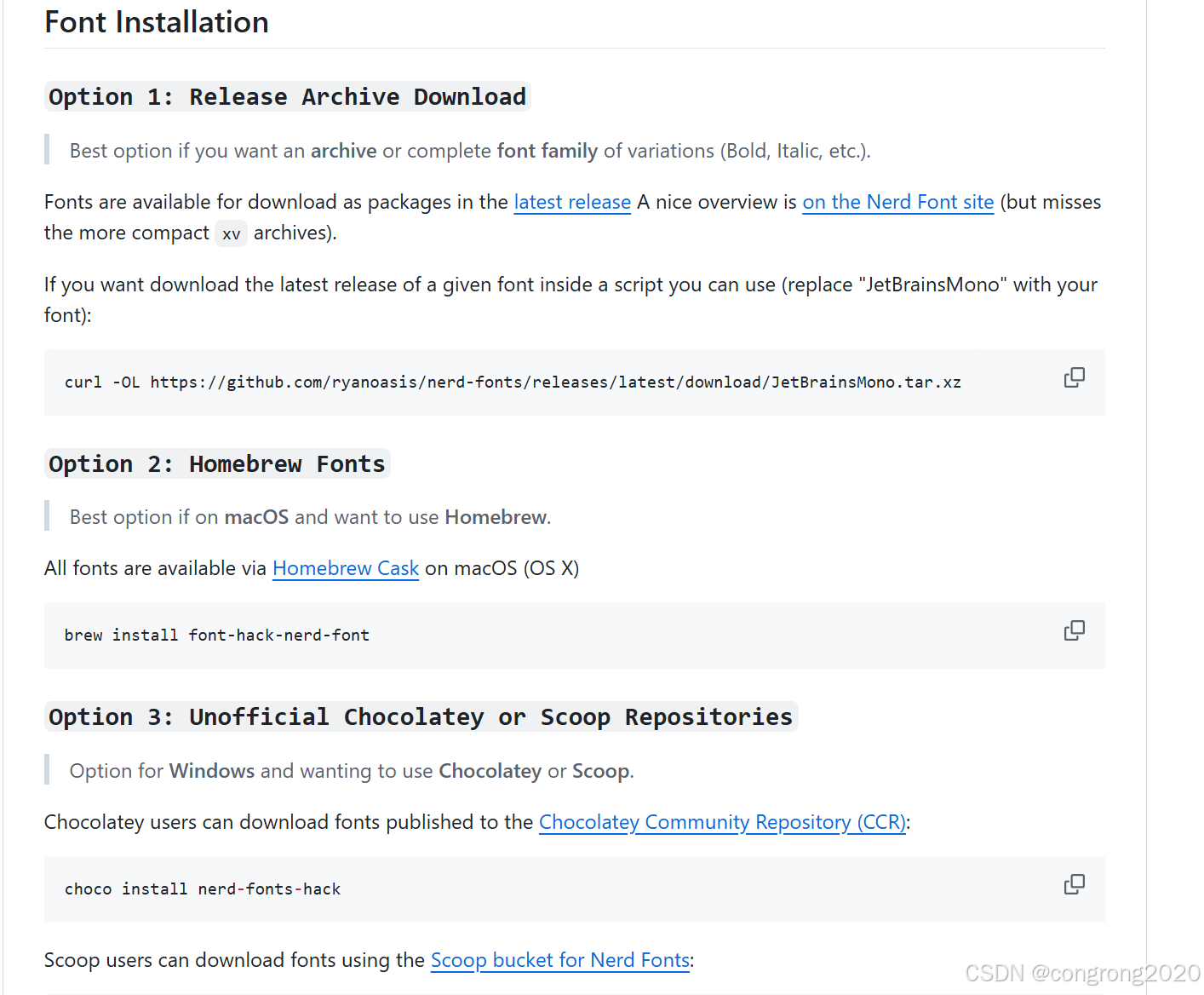
我使用的choco下载
备注:如果出现github 出现Failed to connect to github.com port 443 问题,可以参考解决方案
2. 打开终端的设置
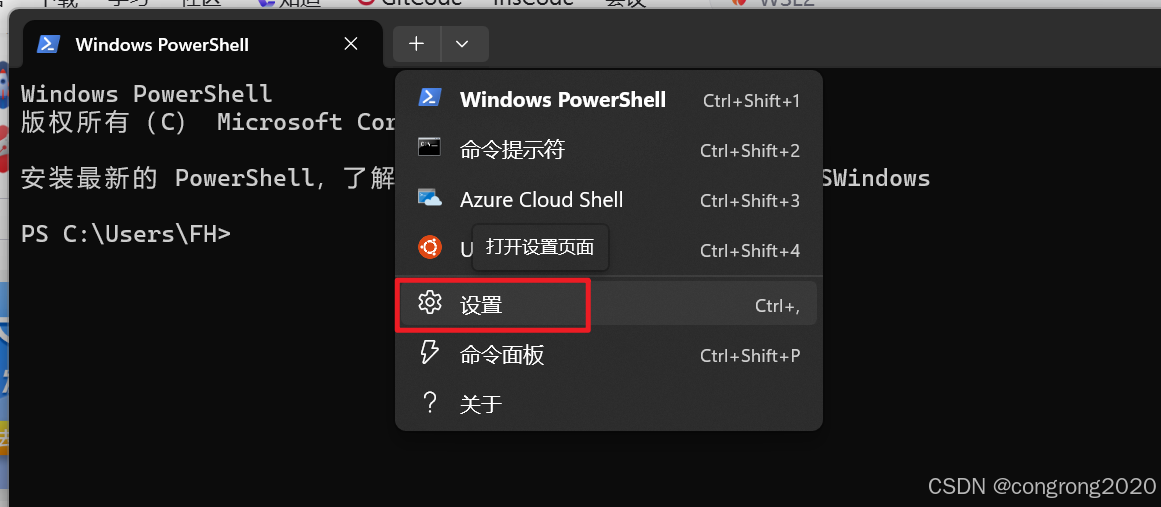
3. 依次点击设置左侧的“Ubuntu”,“打开JSON文件”,打开配置文件进行修改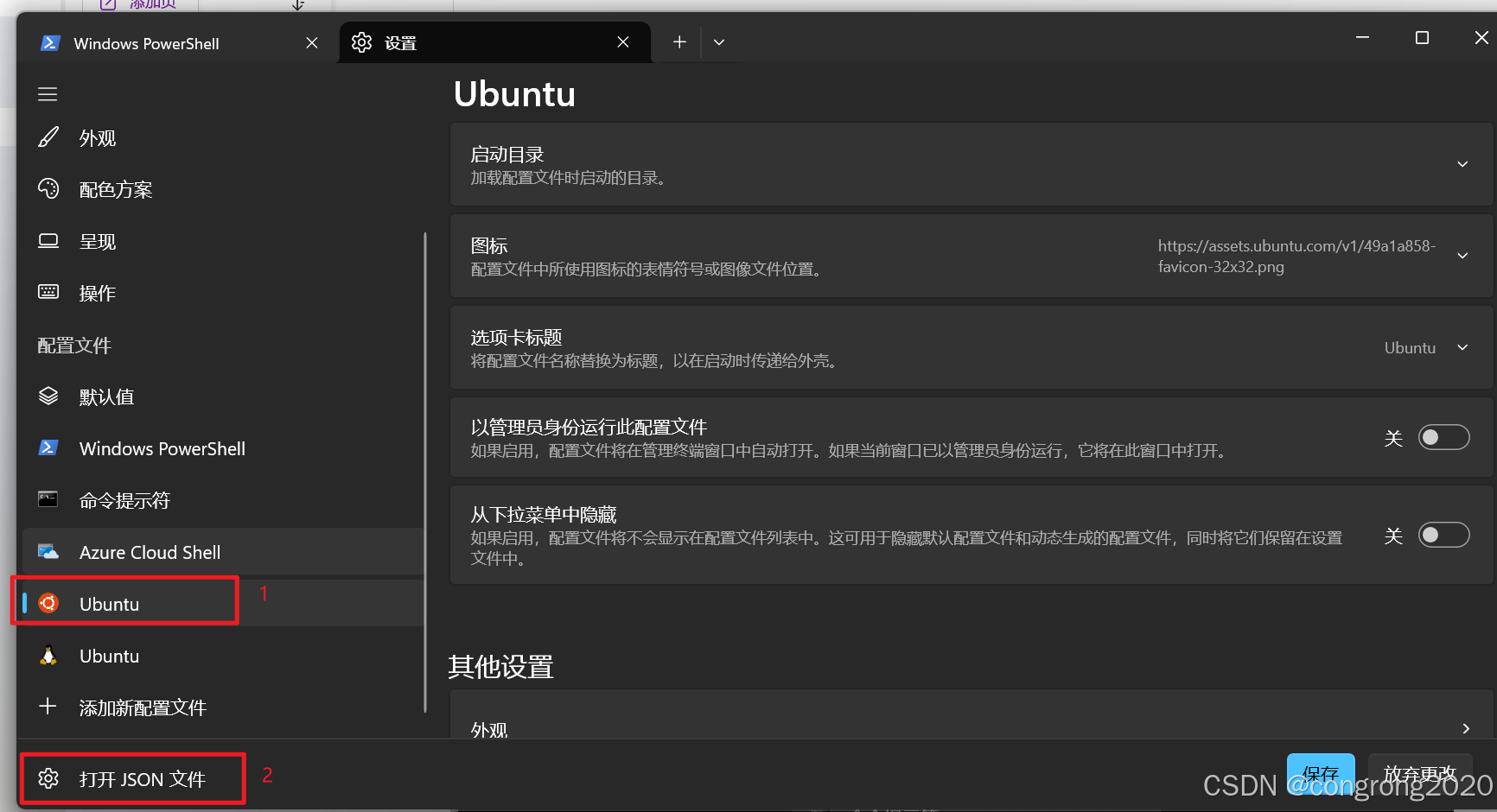
4. 在Profiles.list字段下找到Ubuntu相关配置,新增字体配置字段
"font": {
"face": "Hack Nerd Font"
}注:旧版本可能使用fontFace字段进行配置
"fontFace": "Hack Nerd Font"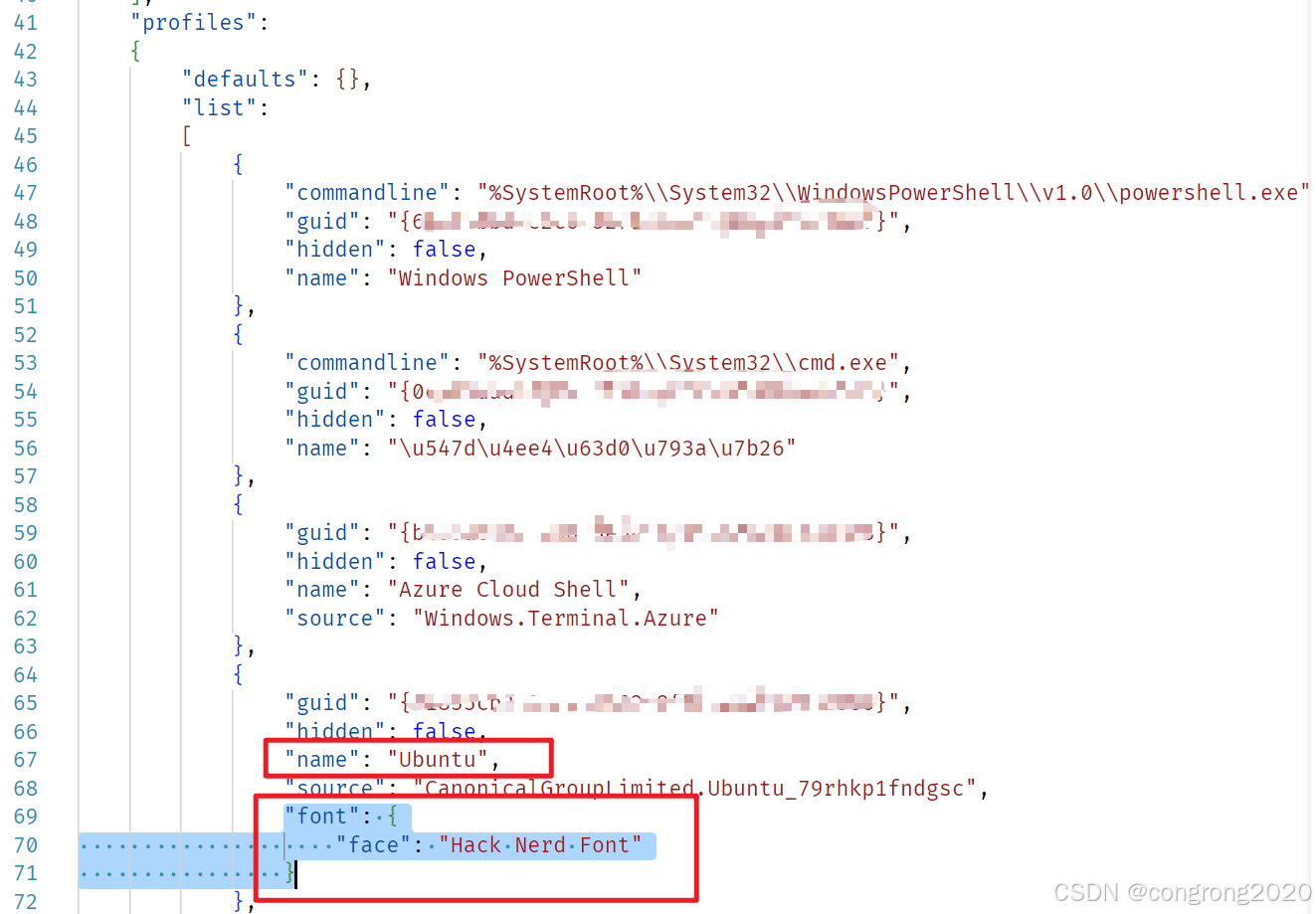
5. 重新打开终端即生效(笔者是想使用oh-my-bash的powerline-icon主题,有些符号默认字体不支持,所以更换WSL2的字体,使用支持更多符号的Hack Nerd Font字体


















 2230
2230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









