









微服务
- SpringCloud
- 微服务架构
- 认识微服务
- 服务的拆分及远程调用
- eureka注册中心
- Ribbon负载均衡原理
- nacos注册中心
- Nacos配置管理
- Feign远程调用
- Gateway服务网关
- Docker
- MQ
- ES
- Spring Cloud Alibaba
SpringCloud
微服务架构
认识微服务
服务架构演变
单体架构
- 将业务的所有功能集中在一个项目中开发,打成一个包进行部署
- 比如一个商城项目,里面有订单模块,用户模块,支付模块,商品模块等,因为是单体项目,我们不需要设计复杂的架构,只需要创建一个项目,有什么功能就往项目中添加什么功能即可
- 优点:
- 架构简单:不需要设计复杂架构,所有代码堆集一起
- 部署成本低:所有代码打成一个包,部署到一台服务器,用户即可访问,即便数据量大,加服务器集群即可,依然是同一个代码包,因此部署成本低
- 缺点:
- 耦合度高:所有功能的所有代码都在一个项目中,不同功能的代码边界也比较模糊,一个项目体量较大,编译部署都比较耗费时间
- 因为代码耦合度高,因此代码的维护成本极高
- 因此,对于大型项目,就不适合使用单体架构,单体架构只适合一些小型项目
分布式架构
- 根据业务功能对系统进行拆分,每个业务模块作为独立项目开发,称为一个服务
- 比如一个商城项目中,有订单模块、用户模块、支付功能、商品模块等,我们就可以将每个模块或功能拆分出来,作为单独项目开发,每个项目也称为一个服务
- 优点:
- 降低服务耦合:将不同功能拆分作为独立项目开发,各个项目之间没有任何关联性,代码耦合度降低
- 有利于服务升级拓展:对每个单独的模块进行技术升级或使用不同的技术进行开发都可以,不会影响到其他业务功能或其他项目,用户在访问的时候,按照需要,访问不同的项目即可
- 缺点:
- 拆分问题:在拆分项目时,到底哪些模块需要拆分出来或者哪些代码需要拆分,拆分几个模块等都是拆分项目中会遇到的问题
- 部署成本提高:因为将一个大型项目拆分为多个服务,每个服务都需要部署,且每个服务之间可能需要相互调用访问,每个服务都有自己独立的数据库等因素,项目的部署成本会提高
服务治理
- 服务拆分粒度如何?主要考虑怎么拆、哪些模块作为单独服务,哪些业务在一起?
- 服务集群地址如何维护?每个服务都是不同的服务器,每个服务器地址不同,如果在项目中写死,后期更换地址等操作会影响代码,因此需要维护多个服务器地址
- 服务之间如何实现远程调用?多个服务之间可能有业务关系,比如添加一条订单,可能需要访问用户模块,访问商品模块等,这些模块都拆分后相互之间如何调用?都是跨服务的调用,需要专门的技术进行实现
- 服务健康状态如何感知?多个服务之间在调用时,必须知道对方服务是否正常运行,否则会影响本服务运行,导致级联失败,所以必须要监控每个服务的健康状态
- 因此,在解决分布式架构的问题中,也诞生了许多的技术,比如:WebService、ESB、Hession、Dubbo、SpringCloud等,目前这些分布式技术自身也在不断升级迭代,而针对分布式的问题,也在不断提出新的解决方案,诞生新的技术支持
- 而目前针对分布式架构应用最广泛的方案,就是微服务,因此微服务就是一种分布式架构的实现
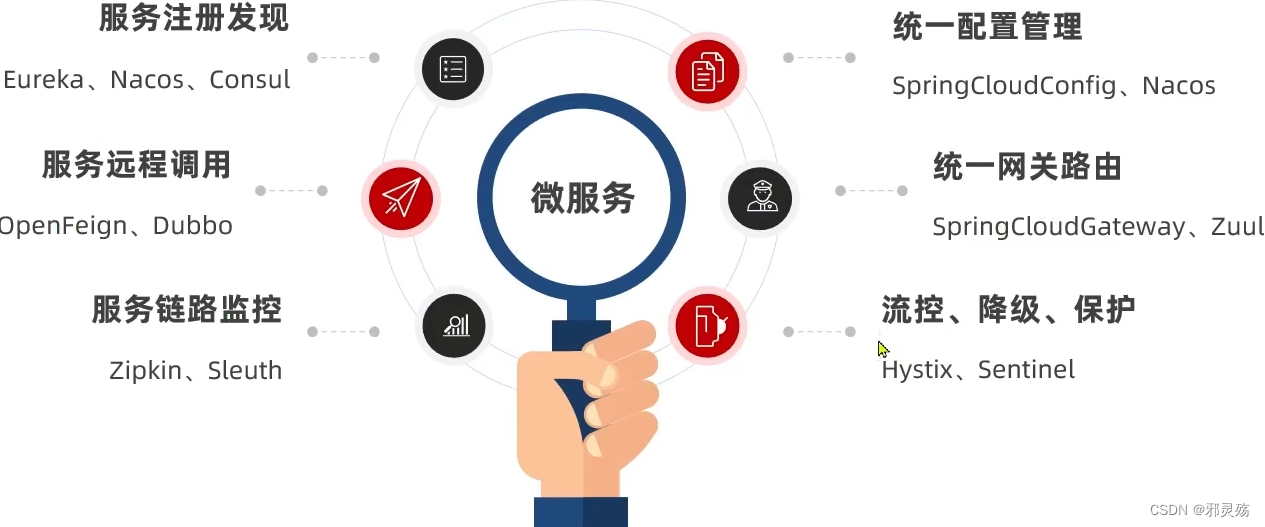
微服务
微服务是一种经过良好架构设计的分布式架构方案,微服务的特征有:
- 单一职责:微服务拆分粒度更小,每一个服务都对应唯一的业务能力,做到单一职责,尽量的避免重复业务开发,比如对于一个商城项目来说,如果我们将一个项目拆分为商品、订单、用户、支付等功能,显然是粒度比较大的,因为在用户模块中可能还设计到会员、用户等级、积分、积分商城等功能,因此我们在拆分时要尽可能拆分,做到单一职责,这样每个模块代码更少,体量更小,对其他模块的依赖及影响也更小
- 面向服务:微服务对外暴露业务接口。将一个大型项目拆分之后,肯定有多个服务之间都需要相互调用,比如用户服务在做积分时需要用到积分服务,因此积分服务应该提供一个对外的接口,用户通过用户查询对应的积分信息,这样当用户模块用到积分时,就可以调用积分服务提供的接口来查询积分
- 自治:团队独立、技术独立、数据独立、部署独立。所谓团队独立指将项目拆分后,每个微服务团队,依然是一个完整的团队,比如后端、前端、测试、运维等,他们独立负责一个服务的所有工作,技术独立是指每个服务都可以使用适合的技术或者团队擅长的技术,相互之间不影响,数据独立是指每个服务都有自己独立的数据库,有独立的数据,当其他服务需要本服务的数据时,调用暴露在外的接口操作即可,不会直接操作数据库,也避免了数据上的污染,部署独立,因为数据独立,技术独立,因此每个服务之间没有任何关联,因此可以做到独立部署
- 服务网关:当做到服务独立性之后,作为用户在操作某个功能时,可能不知道需要访问哪个服务,因此需要先访问网关,由网关负责将请求交个对应的服务进行处理
- 隔离性强:服务调用做好隔离、容错、降级、避免出现级联问题,服务虽然独立了,但是服务之间需要互相访问调用,因此要做好服务的隔离以及容错,比如一个服务挂掉了,不能影响其他服务的使用
微服务结构
- 微服务这种方案需要技术框架来落地,全球互联网公司也都在积极尝试微服务落地技术,在国内最知名的就是SpringCloud和阿里巴巴的Dubbo
- 而无论哪种技术,它们所包含的组件、实现的功能基本是一致的,都是做到微服务,每种框架仅仅是实现技术上的不同,因此都要做到如下功能与实现:
- 首先都要作为微服务的拆分,形成微服务的集群,而且集群中每个微服务,都要做到单一职责原则,并且面向服务开发,都要对外暴露接口,供服务之间相互调用,只不过不同技术在实现这些接口时会有差异
- 其次不管哪种实现技术,多个服务之间调用关系等,错综复杂,无法靠人力完成维护,因此都需要一个注册中心,用来维护微服务中每个节点的信息,并且去监控这些节点的状态
- 另外微服务数量庞大,每个服务都需要一些配置信息,如果靠人力维护每个微服务的配置也比较空难,因此往往也都需要一个配置中心,可以统一的管理整个微服务群的配置,如果有些微服务的配置需要变更,我们也可以利用通知的方式,让对应的服务监控到配置的变化,做到配置的热更新
- 而随着微服务的上线,用户需要访问微服务,而用户应该访问哪些微服务也需要进行管理控制,因此需要一个服务网关,将用户的请求路由到不同的服务中,在这个过程中还可以做负载均衡,且路由过程中或服务之间的调用时,还需要做好服务的容错处理,避免因为服务故障出现级联失败,还要做好服务隔离保护,降级等措施
- 而上面提到的无论是注册中心也好、配置中心也好、服务网关或者服务的调用关系,还是注册保护也好,这些功能都需要我们的技术去实现,SpringCloud和Dubbo在实现的过程中是有差异的,差异如下:
微服务技术对比
Dubbo
- Dubbo技术,早在2012年左右就开源了,是阿里巴巴开源的项目,而那个时候,微服务技术并不完善,因此Dubbo并不是一个严格意义上的微服务技术,在当时Dubbo的核心就是服务的远程调用以及注册发现
- 所以在Dubbo中,技术体系并不完整,主要的核心就是注册中心和服务远程调用,而且注册中心也是依赖于
zookeeper和Redis等技术框架实现,而且zookeeper是做集群管理、Redis是做集群的,这些技术都不是专业做注册中心用的,因此Dubbo并不具备完善的注册中心功能 - 而服务的远程调用才是Dubbo的核心,当时Dubbo基于http协议,专门定义了一套自己的协议,就是Dubbo协议,所以遵循Dubbo的远程调用,必须要定义Dubbo这种标准的接口,它要求我们必须要Java实现、必须实现JDK里面的Serializable接口等一系列的要求
- 而配置中心与服务网关,Dubbo里面都没有实现,对于服务的监控和保护,Dubbo只提供了一个最基本的
dubbo-admin功能,只是来统计一下服务调用时的响应时间、QBS等等,功能及其单一 - 因此,Dubbo对于实现服务的治理,是非常不完善的。
- 而到了2015年至2017年左右,就是微服务井喷式发展的时候,各种微服务技术层出不穷,但是一直没有一种能够统一这些技术的方案,直到SpringCloud的出现
- SpringCloud也并不是发明或创造什么独立的技术,而是整合了全球各个互联网公司的各种开源的微服务技术。之后形成了一套完整的微服务技术体系,成为了一个集大成者,因此SpringCloud的微服务功能是非常完善的:
SpringCloud
- 首先,它有非常完善的注册中心,里面包含有
Eureka、Consul这种专业的注册中心 - 而后对于服务远程调用,使用了
Feign它也没有搞一种全新的协议和标准,因为这样会增加学习和使用成本,因此它直接使用的就是基于Http协议的标准,因此我们之前单体项目中编写的Controller接口以及RestFull接口等,都是Http协议的接口,而这些接口也都可以进行远程调用,因此学习使用成本更低,只不过SpringCloud帮我们封装了一种客户端,也就是Feign客户端,来帮我们发起Http的请求,因此它就是基于Feign做服务的远程调用的,当然我们不使用这个客户端也可以,只要我们的接口符合RestFull风格就可以 - 然后SpringCloud还提供了专业的配置中心,叫做
SpringCloudConfig,如果在结合SpringCloudBase,我们轻松就可以实现配置变更时的自动通知以及热更新功能,其配置中心功能非常强大 - 另外,SpringCloud还提供了
SpringCloudGateway以及Zuul两个不同的网关,在目前比较流行就是SpringCloudGateway网关,因为它里面集成了最新的响应式编程,吞吐能力非常强 - 最后就是服务的保护,
Hystrix是一个非常强大的服务保护技术,当然它也携带了服务监控功能,但是其核心依然是保护功能,主要就是实现了服务的隔离、熔断等相关的技术,功能也十分强大
SpringCloudAlibaba
- 通过上述了解我们知道,对于Dubbo和SpringCloud之间,还是存在比较大的差距,它并不是一个完善的微服务技术栈,因此阿里巴巴在近几年,也在不断完善追赶SpringCloud,也实现了自己的注册中心、配置中心以及服务监控等组件,这样一套技术栈逐渐形成,名为SpringCloudAlibaba
- 按照其命名我们可以看到,它首先就是SpringCloud中的一部分,这一套技术栈是实现了SpringCloud中的一些标准接口,所以SpringCloudAlibaba中的一些组件使用上与SpringCloud没有什么差别,因为他们实现了统一的接口规范
- 首先在SpringCloudAlibaba中,兼容了
Eureka注册中心,Feign服务调用、SpringCloudConfig配置中心以及SpringCloudGateway和Zuul服务网关,但是其主要还是想要整合Dubbo,因此 - 对于注册中心,在SpringCloudAlibaba中,除了兼容
Eureka外,也实现了自己的注册中心Nacos - 对于服务调用,除了兼容
Feign外,也整合了Dubbo服务远程调用技术 - 对于配置中心,除了兼容
SpringCloudConfig外,也加入了Nacos作为配置中心 - 对于服务监控,则是实现了自己的服务监控
Sentinel - 而其实现的的注册中心
Nacos其强大之处在于,它既支持Dubbo技术调用,也支持Feign技术的调用,也就是说,在一个微服务中,既有Dubbo接口,也有Feign接口,就可以使用SpringCloudAlibaba提供的注册中心Nacos,它对于两种接口都实现了技术支持 - 因此,通过分析我们得知,SpringCloudAlibaba,同时兼容Dubbo和SpringCloud两种架构
| Dubbo | SpringCloud | SpringCloudAlibaba | |
|---|---|---|---|
| 注册中心 | zookeeper、Redis | Eureka、Consul | Nacos、Eureka |
| 服务远程调用 | Dubbo协议 | Feign(http协议) | Dubbo、Feign |
| 配置中心 | 无 | SpringCloudConfig | SpringCloudConfig、Nacos |
| 服务网关 | 无 | SpringCloudGateway、Zuul | SpringCloudGateway、Zuul |
| 服务监控和保护 | dubbo-admin,功能弱 | Hystrix | Sentinel |
企业需求
- SpringCloud+Feign: 使用SpringCloud技术栈,服务接口采用RestFul风格,服务调用采用Feign方式
- SpringCloudAlibaba+Feign:使用SpringCloudAlibaba技术栈,服务接口采用Restful风格,服务调用采用Feign方式
- SpringCloudAlibaba+Dubbo:使用SpringCloudAlibaba技术栈,服务采用Dubbo协议标准,服务调用采用Dubbo方式
- Dubbo原始模式:基于Dubbo老旧技术体系,服务接口采用Dubbo协议接口标准,服务调用采用Dubbo方式
SpringCloud
- SpringCloud是目前国内甚至全球使用最广泛的微服务框架
- SpringCloud的官网地址:https://spring.io/projects/spring-cloud
- SpringCloud集成了各种微服务功能组件,并基于SpringBoot实现了这些组件的自动装配,从而提供了良好的开箱即用体验:
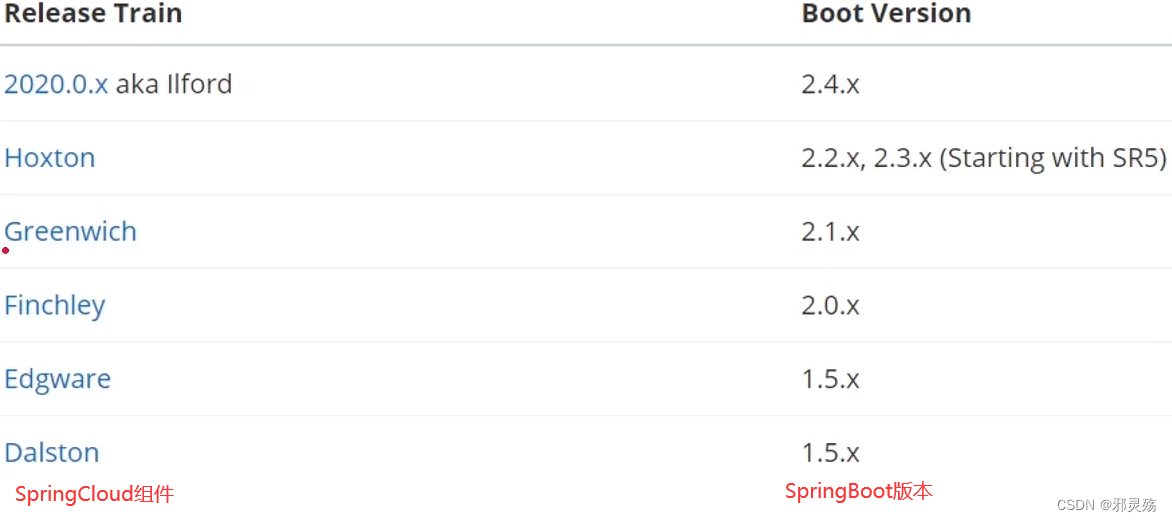
- 因为SpringCloud底层基于SpringBoot做了自动装配,因此需要注意其版本兼容问题,SpringCloud与SpringBoot的版本兼容关系如下:比如使用了Greenwich,那么SpringBoot必须是2.1.X及以上版本
服务的拆分及远程调用
任何分布式架构都离不开服务的拆分,微服务也是一样。
服务拆分
服务拆分原则
- 不同微服务,不要重复开发相同业务
- 微服务数据独立,不要访问其它微服务的数据库
- 微服务可以将自己的业务暴露为接口,供其它微服务调用
- 我们可以将不同的功能拆分成不同的服务,每个服务都有自己的独立数据库,也是强制不让一个服务中重复开发业务,因为没有能够调用的数据库
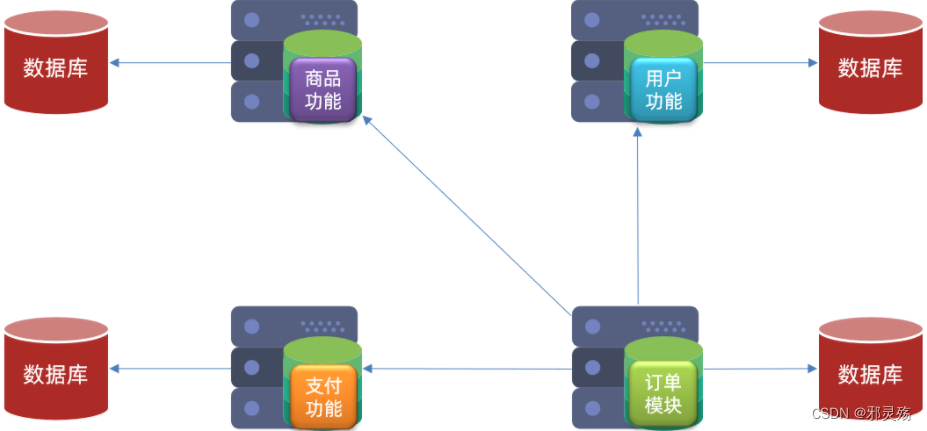
服务拆分实例
例如我们有一个商城项目,我们可以将用户模块拆分为一个独立的服务
此外我们还可以将订单功能拆分为一个独立的模块
这样在订单数据中,有个userid与用户数据关联即可,但是在订单模块中又没有用户数据
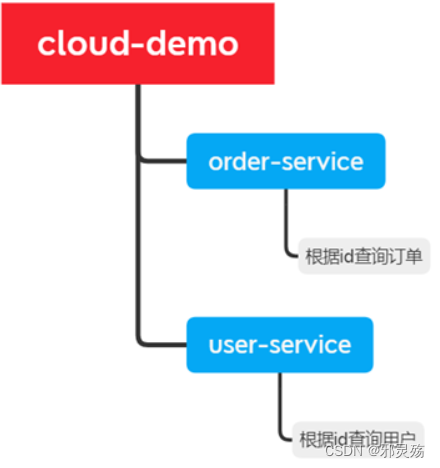
- cloud-demo:父工程,管理依赖
- order-service:订单微服务,负责订单相关业务
- user-service:用户微服务,负责用户相关业务
- 要求:
- 订单微服务和用户微服务都必须有各自的数据库,相互独立
- 订单服务和用户服务都对外暴露Restful的接口
- 订单服务如果需要查询用户信息,只能调用用户服务的Restful接口,不能查询用户数据库
- 创建两个数据库,模拟微服务发布时不同的服务器数据库
- 用户模块数据库中,创建一个user表,数据如下:
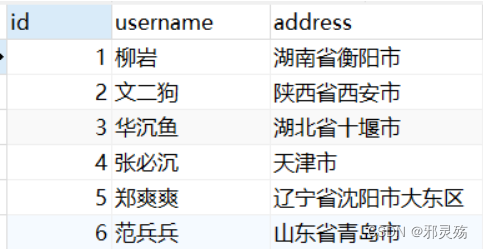
- 在订单数据库中,创建一个order表,数据如下:

- 用户模块数据库中,创建一个user表,数据如下:
- 创建项目,或者导入项目,其项目结构如下:

- 项目导入IDEA后,右下角有如下弹框:

- 打开弹窗,选择如下选项
- 选择好之后,就会自动打开如下菜单,方便我们启动不同的微服务

服务间调用
- 在订单服务中,有一个根据id查询订单信息的接口如下:
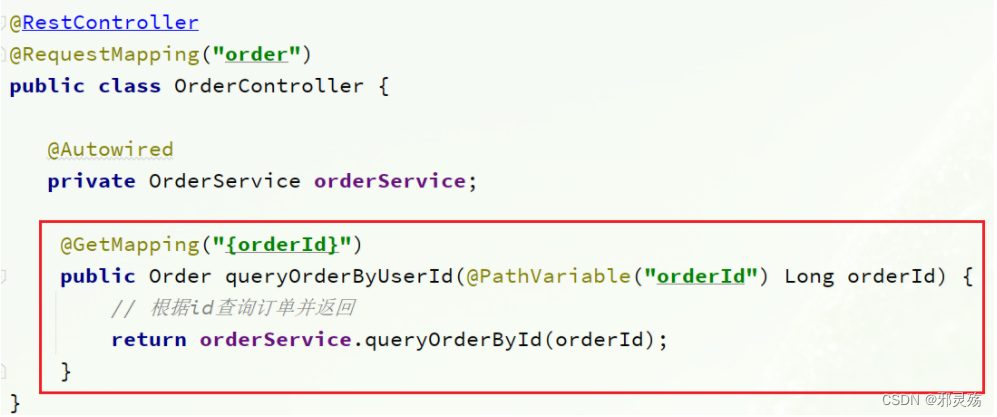
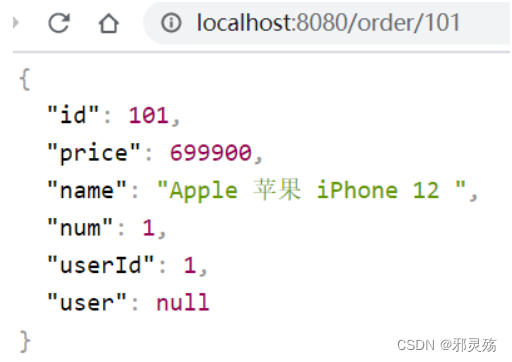
- 我们在浏览器访问后,通过id查询数据如下,需要注意的是其中的user对象是null
- 而在用户模块中,我们同样有一个根据id查询用户数据的接口如下:
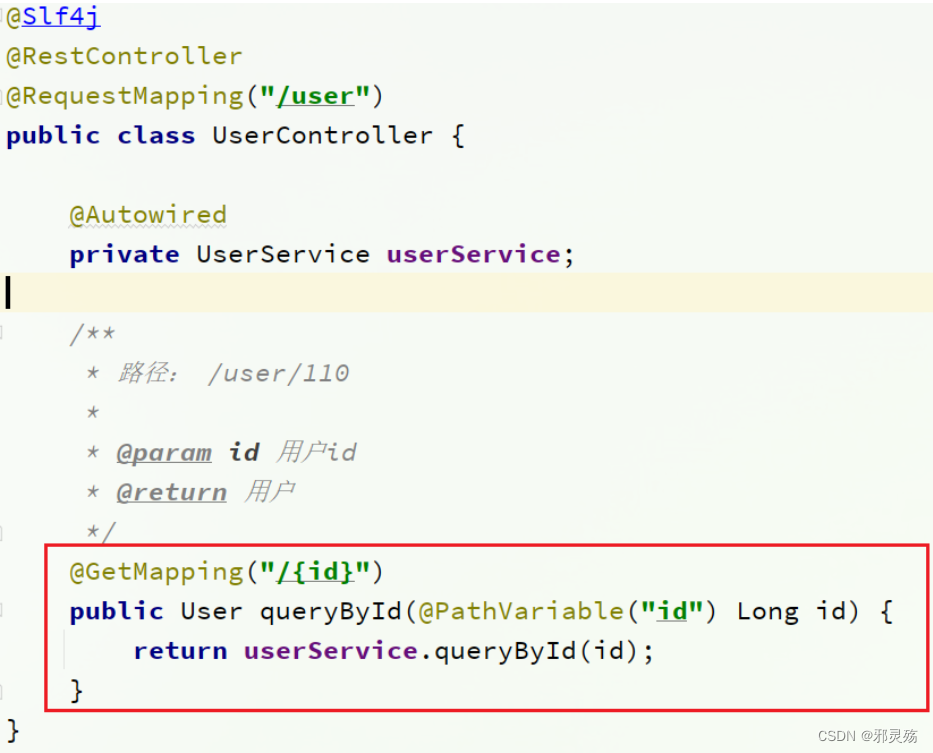
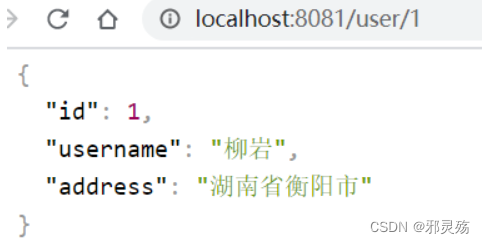
- 我们在浏览器访问用户服务,得到如下数据
案例需求
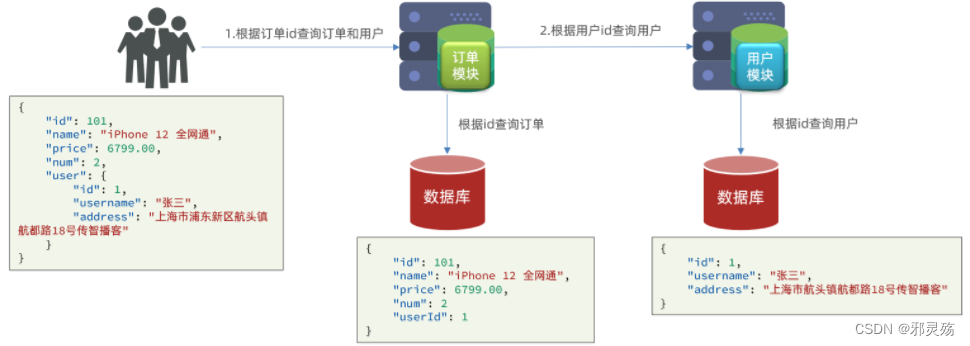
此时,我们修改order-service订单模块中的根据id查询订单业务,要求在查询订单的同时,根据订单中包含的userId查询出用户信息,一起返回。
因此,我们需要在order-service订单模块中 向user-service用户模块发起一个http的请求,调用http://localhost:8081/user/{userId}这个接口。根据订单关联的id来查询出用户信息
要实现上述需要,需要我们在Java中能够像浏览器或ajax等一样,通过url以及参数,发起一个请求,然后得到数据,因此需要如下步骤:
- 注册一个RestTemplate的实例到Spring容器
- 修改order-service服务中的OrderService类中的queryOrderById方法,根据Order对象中的userId查询User
- 将查询的User填充到Order对象,一起返回
RestTemplate
RestTemplate是Spring提供给我们的一个对象,它的作用就是能够像浏览器一样,通过url请求一个接口
首先,我们需要在订单模块的spring容器中,注册一个RestTemplate实例对象,而我们可以通过配置类中@Bean的方式来实现
而对于Springboot项目来说,启动类本身就是一个配置类,因此我们可以在订单模块启动类中注册RestTemplate实例对象
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
@MapperScan("cn.itcast.order.mapper")
@SpringBootApplication
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class, args);
}
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
实现远程调用
当我们成功注册好RestTemplate实例后,我们就可以修改订单的查询接口了
可以发现,当我们查询到订单信息以后,通过订单中的关联id,再利用RestTemplate对象发起一个GET请求,就可以获取到user数据了
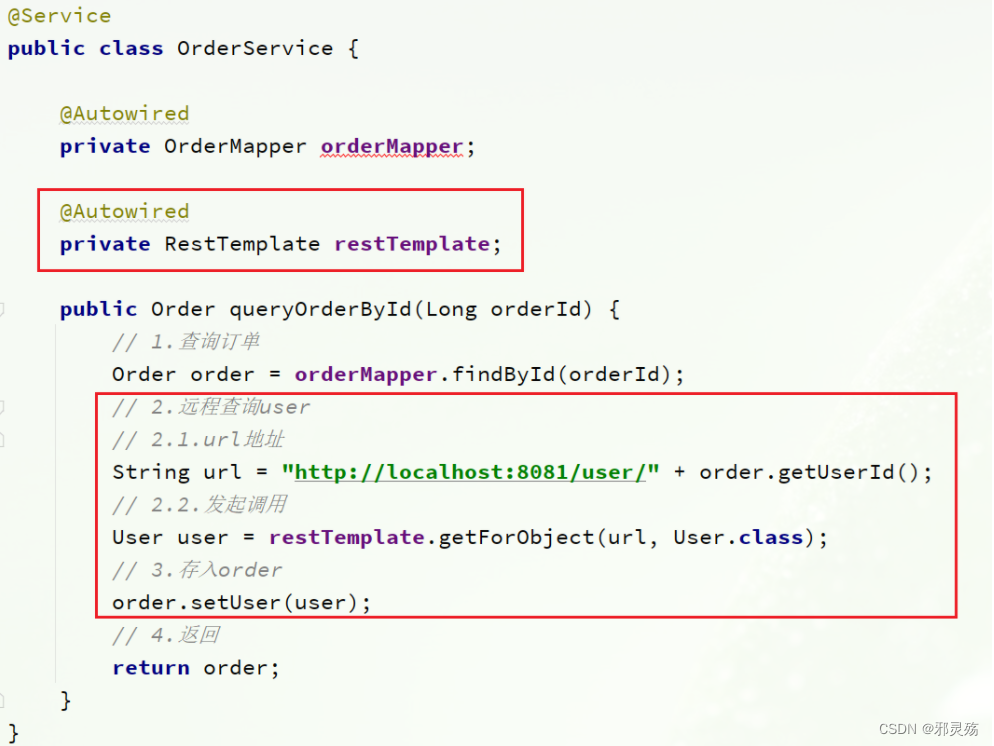
- 注意:
- RestTemplate对象中,需要发起一个GET请求就使用
getForObject()方法 - 如果需要发起一个POST请求,则需要调用方法
postForObject() - 两个方法仅仅是发起不同的请求,都需要两个参数:
- 参数一:需求请求的url地址信息
- 参数二:因为请求到的数据都是JSON格式,需要转换为对象类型,因此需要提供对应的数据类型
- RestTemplate对象中,需要发起一个GET请求就使用
提供者与消费者
- 在服务调用关系中,会有两个不同的角色:
- 服务提供者:一次业务中,被其它微服务调用的服务。(提供接口给其它微服务)
- 服务消费者:一次业务中,调用其它微服务的服务。(调用其它微服务提供的接口)

- 但是,服务提供者与服务消费者的角色并不是绝对的,而是相对于业务而言。如果服务A调用了服务B,而服务B又调用了服务C,服务B的角色是什么?
- 对于A调用B的业务而言:A是服务消费者,B是服务提供者
- 对于B调用C的业务而言:B是服务消费者,C是服务提供者
- 因此,服务B既可以是服务提供者,也可以是服务消费者。
- 所以需要知道,所谓的消费者与服务者,都是相对而言,对单一的微服务而言,这个概念没有意义
eureka注册中心
假如我们服务者用户服务,因为数据量等原因,部署了多个实例,也就是部署了多个服务在不同的服务器上,例如:
那么我们就需要思考几个问题:order-service在发起远程调用的时候,该如何得知user-service实例的ip地址和端口?
有多个user-service实例地址,order-service调用时该如何选择?
order-service如何得知某个user-service实例是否依然健康,是不是已经宕机?

Eureka的结构和作用
以上这些问题都需要利用SpringCloud中的注册中心来解决,其中最广为人知的注册中心就是Eureka,其结构如下:
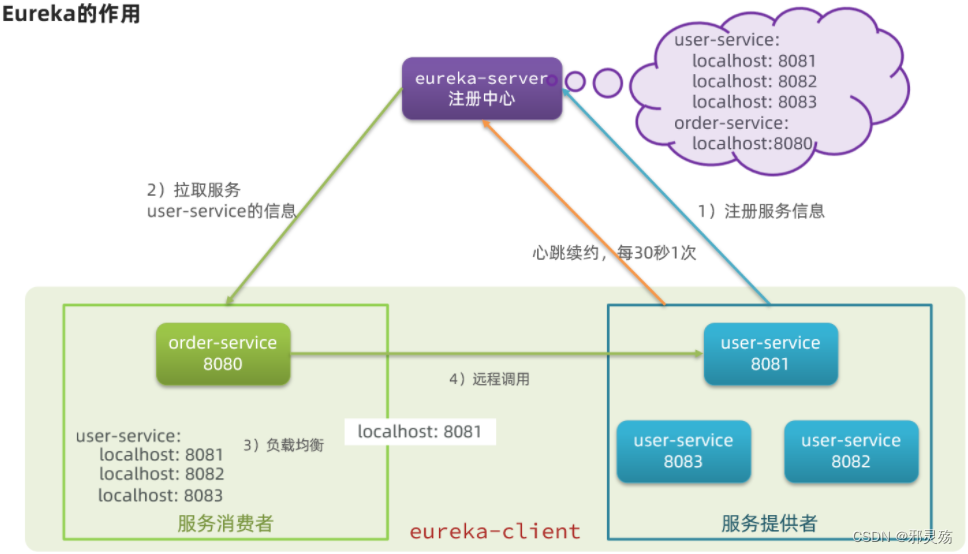
回答之前的各个问题。
问题1:order-service如何得知user-service实例地址?获取地址信息的流程如下:
- user-service服务实例启动后,将自己的信息注册到eureka-server(Eureka服务端)。这个叫服务注册
- eureka-server保存服务名称到服务实例地址列表的映射关系
- order-service根据服务名称,拉取实例地址列表。这个叫服务发现或服务拉取
问题2:order-service如何从多个user-service实例中选择具体的实例?
- order-service从实例列表中利用负载均衡算法选中一个实例地址
- 向该实例地址发起远程调用
问题3:order-service如何得知某个user-service实例是否依然健康,是不是已经宕机?
- user-service会每隔一段时间(默认30秒)向eureka-server发起请求,报告自己状态,称为心跳
- 当超过一定时间没有发送心跳时,eureka-server会认为微服务实例故障,将该实例从服务列表中剔除
- order-service拉取服务时,就能将故障实例排除了
注意:一个微服务,既可以是服务提供者,又可以是服务消费者,因此eureka将服务注册、服务发现等功能统一封装到了eureka-client端

搭建eureka-server
首先大家注册中心服务端:eureka-server,这必须是一个独立的微服务,也就是说,eureka本身就是一个微服务,只是作用就是用来做注册中心的
创建eureka-server服务
- 在cloud-demo父工程下,创建一个子模块:
- 填写模块信息
- 填写服务信息
引入eureka依赖
引入SpringCloud为eureka提供的start依赖,因为父目录指定了springboot以及SpringCloud版本,此处不需要指定版本信息
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
编写启动类
给eureka-server服务编写一个启动类,一定要添加一个@EnableEurekaServer注解,开启eureka的注册中心功能:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
@EnableEurekaServer
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class, args);
}
}
编写配置文件
注意:
- 上面spring下的name配置,是当前eureka作为微服务的名称,与其他普通微服务一样
- 下面的eureka是作为注册中心的配置,service-usl是其作为注册中心服务地址,也就是eureka本身作为一个微服务,我们同样需要注册到eureka中
server:
port: 10086
spring:
application:
name: eureka-server
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka
启动服务
启动微服务,然后在浏览器访问:http://127.0.0.1:10086
看到下面结果应该是成功了:
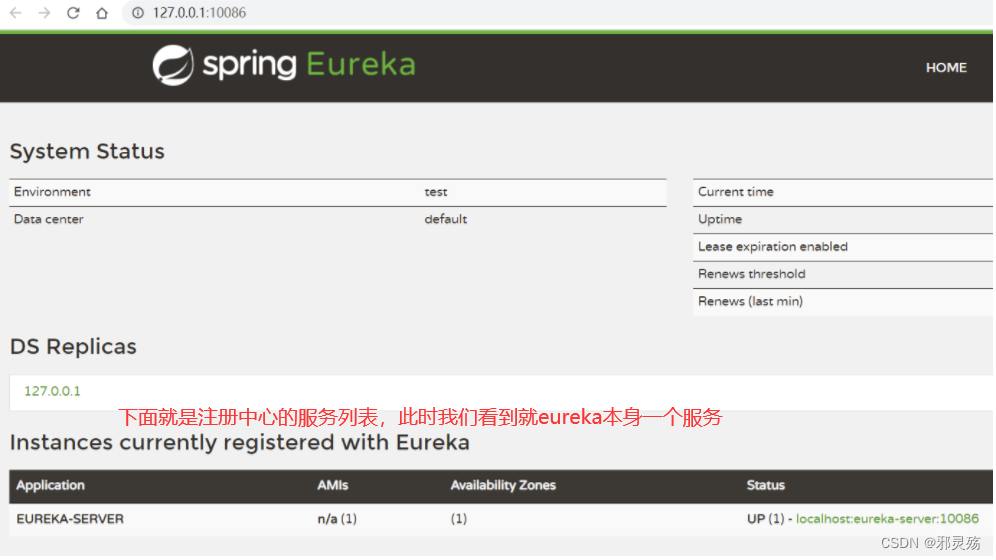
服务注册
下面,我们将user-service注册到eureka-server中去。可能需要在启动类上加注解@EnableEurekaClient
引入依赖
在user-service的pom文件中,引入下面的eureka-client依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
配置文件
在user-service中,修改application.yml文件,添加服务名称、eureka地址:
注意:
- 上面spring下的name配置,是当前eureka作为微服务的名称,与其他普通微服务一样,无论是提供者还是消费者,都需要一个服务名
- 下面同样是将该服务注册到对应地址下的eureka注册中心去
spring:
application:
name: userservice
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka
启动多个提供者
为了演示一个服务有多个实例的场景,我们添加一个SpringBoot的启动配置,再启动一个user-service。也就是在启动了user服务的基础上,在复制一个服务修改端口后启动
- 首先,复制原来的user-service启动配置,在对应需要复制的服务上右击:
- 然后,在弹出的窗口中,填写信息,主要是修改端口,-D是参数,后面的server.port,就是我们在yml配置中的端口配置,原理是一样的:

- 现在,SpringBoot窗口会出现两个user-service启动配置:
- 此时,我们就可以同时启动这两个服务了,其实是同一个服务,只是端口不同:

- 我们此时查看eureka管理页面,我们会发现用户服务有两个服务

服务发现
下面,我们将order-service的逻辑修改:向eureka-server拉取user-service的信息,实现服务发现。
- 其他首先要做到跟上面一样,都是需要将服务注册到eureka中,只不过是作为调用方,需要调用用户服务
引入依赖
之前说过,服务发现、服务注册统一都封装在eureka-client依赖,因此这一步与服务注册时一致。
在order-service的pom文件中,引入下面的eureka-client依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
配置文件
服务发现也需要知道eureka地址,因此第二步与服务注册一致,都是配置eureka信息:
在order-service中,修改application.yml文件,添加服务名称、eureka地址:
spring:
application:
name: orderservice
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka
服务拉取和负载均衡
最后,我们要去eureka-server中拉取user-service服务的实例列表,并且实现负载均衡。
不过这些动作不用我们去做,只需要添加一些注解即可。
在order-service的OrderApplication中,给RestTemplate这个Bean添加一个@LoadBalanced注解:
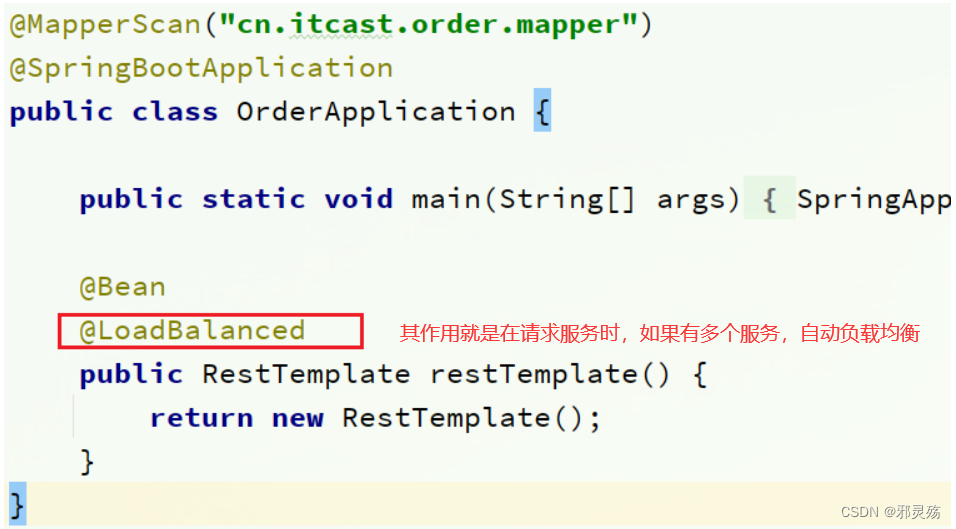
修改order-service服务中的cn.itcast.order.service包下的OrderService类中的queryOrderById方法。修改访问的url路径,用服务名代替ip、端口:

spring会自动帮助我们从eureka-server端,根据userservice这个服务名称,获取实例列表,而后完成负载均衡。
Ribbon负载均衡原理
上一节中,我们添加了@LoadBalanced注解,即可实现负载均衡功能,这是什么原理呢?
而且我们注意到一点,之前我们再Java中需要访问一个服务时,必须通过IP和端口等组成的url
二加了@LoadBalanced注解之后,我们直接通过服务名就可以进行访问,而我们将服务名通过浏览器访问发下无法访问,因为它本身也不是一个url地址
那么既然我们此时可以访问到再代码中,证明就是上面这个注解帮我们通过服务名找到了注册在eureka中的服务,且做了负载均衡处理,而提供这个功能的的组件,就是Ribbon
负载均衡原理
SpringCloud底层其实是利用了一个名为Ribbon的组件,来实现负载均衡功能的。
那么我们发出的请求明明是http://userservice/user/1,怎么变成了http://localhost:8081的呢?
源码跟踪
为什么我们只输入了service名称就可以访问了呢?之前还要获取ip和端口。
显然有人帮我们根据service名称,获取到了服务实例的ip和端口。它就是LoadBalancerInterceptor,这个类会在对RestTemplate的请求进行拦截,然后从Eureka根据服务id获取服务列表,随后利用负载均衡算法得到真实的服务地址信息,替换服务id。
我们进行源码跟踪:
1)LoadBalancerIntercepor
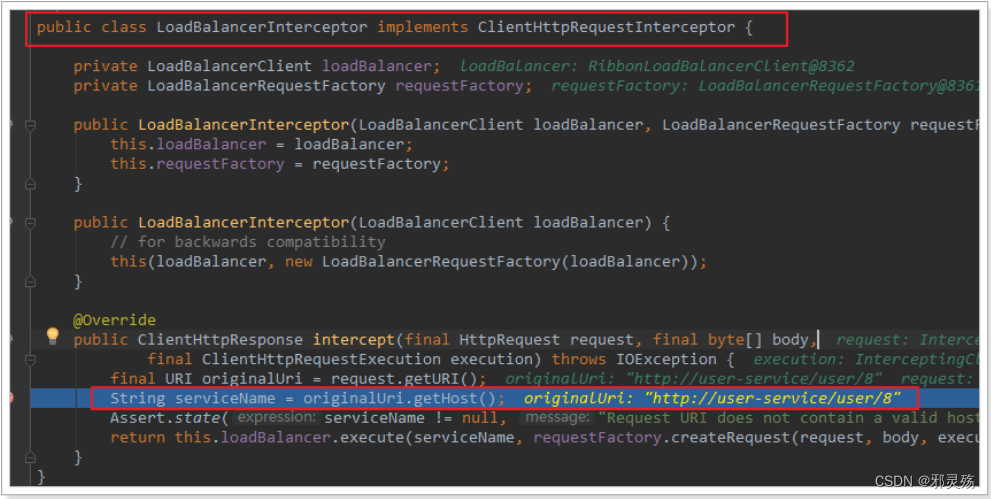
可以看到这里的intercept方法,拦截了用户的HttpRequest请求,然后做了几件事:
request.getURI():获取请求uri,本例中就是 http://user-service/user/8originalUri.getHost():获取uri路径的主机名,其实就是服务id,user-servicethis.loadBalancer.execute():处理服务id,和用户请求。
这里的this.loadBalancer是LoadBalancerClient类型,我们继续跟入。
2)LoadBalancerClient
继续跟入execute方法:
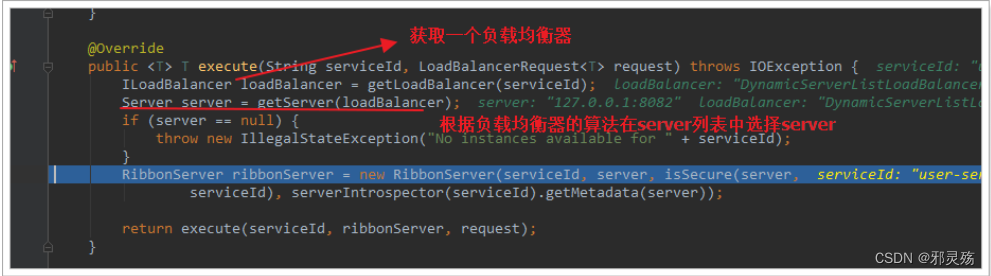
代码是这样的:
- getLoadBalancer(serviceId):根据服务id获取ILoadBalancer,而ILoadBalancer会拿着服务id去eureka中获取服务列表并保存起来。
- getServer(loadBalancer):利用内置的负载均衡算法,从服务列表中选择一个。本例中,可以看到获取了8082端口的服务
放行后,再次访问并跟踪,发现获取的是8081:

果然实现了负载均衡。
3)负载均衡策略IRule
在刚才的代码中,可以看到获取服务使通过一个getServer方法来做负载均衡:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AzrPQ4kG-1678288994004)(assets/1525620835911.png)]](https://img-blog.csdnimg.cn/7b882e727c1b4ea5b6e92739081217ca.png)
我们继续跟入:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1bbVutnK-1678288994005)(assets/1544361421671.png)]](https://img-blog.csdnimg.cn/0109d5ac6dc844e58c819947f49a831a.png)
继续跟踪源码chooseServer方法,发现这么一段代码:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KQY5200o-1678288994005)(assets/1525622652849.png)]](https://img-blog.csdnimg.cn/8f33512e1f0e4391af13a09f198f071c.png)
我们看看这个rule是谁:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AuzJZDs3-1678288994005)(assets/1525622699666.png)]](https://img-blog.csdnimg.cn/757666414f824a4ab4e0fa2c9705227b.png)
这里的rule默认值是一个RoundRobinRule,看类的介绍:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B4Td3gj9-1678288994006)(assets/1525622754316.png)]](https://img-blog.csdnimg.cn/6c69a8d99470401097f6b5b5681fb680.png)
这不就是轮询的意思嘛。
到这里,整个负载均衡的流程我们就清楚了。
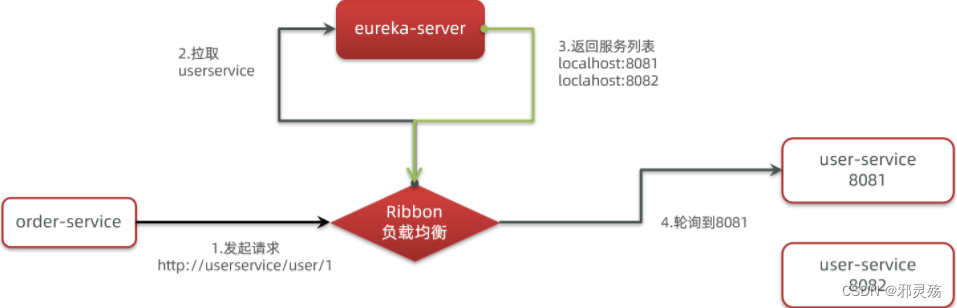
4)总结
SpringCloudRibbon的底层采用了一个拦截器,拦截了RestTemplate发出的请求,对地址做了修改。用一幅图来总结一下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zXN7AEIr-1678288994006)(assets/image-20210713224724673.png)]](https://img-blog.csdnimg.cn/bb15979534a84caa8a0fe1adf9047cfa.png)
基本流程如下:
- 拦截我们的RestTemplate请求http://userservice/user/1
- RibbonLoadBalancerClient会从请求url中获取服务名称,也就是user-service
- DynamicServerListLoadBalancer根据user-service到eureka拉取服务列表
- eureka返回列表,localhost:8081、localhost:8082
- IRule利用内置负载均衡规则,从列表中选择一个,例如localhost:8081
- RibbonLoadBalancerClient修改请求地址,用localhost:8081替代userservice,得到http://localhost:8081/user/1,发起真实请求
负载均衡策略
负载均衡的规则都定义在IRule接口中,而IRule有很多不同的实现类:

不同规则的含义如下:
| 内置负载均衡规则类 | 规则描述 |
|---|---|
| RoundRobinRule | 简单轮询服务列表来选择服务器。它是Ribbon默认的负载均衡规则。 |
| AvailabilityFilteringRule | 对以下两种服务器进行忽略: (1)在默认情况下,这台服务器如果3次连接失败,这台服务器就会被设置为“短路”状态。短路状态将持续30秒,如果再次连接失败,短路的持续时间就会几何级地增加。 (2)并发数过高的服务器。如果一个服务器的并发连接数过高,配置了AvailabilityFilteringRule规则的客户端也会将其忽略。并发连接数的上限,可以由客户端的..ActiveConnectionsLimit属性进行配置。 |
| WeightedResponseTimeRule | 为每一个服务器赋予一个权重值。服务器响应时间越长,这个服务器的权重就越小。这个规则会随机选择服务器,这个权重值会影响服务器的选择。 |
| ZoneAvoidanceRule | 以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询。 |
| BestAvailableRule | 忽略那些短路的服务器,并选择并发数较低的服务器。 |
| RandomRule | 随机选择一个可用的服务器。 |
| RetryRule | 重试机制的选择逻辑 |
默认的实现就是ZoneAvoidanceRule,是一种轮询方案,其与RoundRobinRule不同的是:
- RoundRobinRule:单纯的轮询,也就是说,当我们需要访问user服务,而拉取到了无论多少个user服务,都开始轮询
- ZoneAvoidanceRule:在轮询的基础上多了Zone,zone一般我们在时区中见过这个单词,其也是对服务的分类,也就是一般会按照地址,将服务进行分类,只在一类服务中轮询
- 比如同样是用户user服务,我们在上海部署了几台,在广东布置了几台,它会将上海地区的服务做为一类zone,将广东地区的作为一个zone,在做轮询时,只在一类zone中做轮询
- 当然要实现这个效果需要配置,我们默认没有配置的情况下,其与RoundRobinRule没有区别,都是将所有服务一起轮询
负载均衡策略
通过定义IRule实现可以修改负载均衡规则,有两种方式:
方式一:全局
代码方式:在order-service中的OrderApplication类中,定义一个新的IRule:
也就是说,将我们需要的策略,作为Bean注册到spring容器中,不需要其他配置,当我们进行服务调用时,会自动寻找我们配置的策略,没有的情况下才使用默认的,因此这种方式也是全局配置
全局配置意味着,当访问所有的服务时,都采用我们配置的策略进行处理
@Bean
public IRule randomRule(){
return new RandomRule();
}
方式二:指定服务
配置文件方式:在order-service的application.yml文件中,添加新的配置也可以修改规则:
userservice: # 给某个微服务配置负载均衡规则,这里是userservice服务,这里就是服务名
ribbon: # 需要配置的组件,就是ribbon组件
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 负载均衡规则
注意,一般用默认的负载均衡规则,不做修改。
饥饿加载
Ribbon默认是采用懒加载,即第一次访问时才会去创建LoadBalanceClient,请求时间会很长。
而饥饿加载则会在项目启动时创建,降低第一次访问的耗时,通过下面配置开启饥饿加载:
ribbon:
eager-load:
enabled: true
clients: userservice
注意:
- clients:是一个数组,也就是这里同样需要指定饥饿加载的服务,但是可以指定多个
- 当只需要指定一个服务时,可以向上面一样直接写,如果是多个服务,则需要下面语法,就是spring配置文件的语法,在spring笔记中有说明:
ribbon: # 需要配置的组件 eager-load: # 组件下配置饥饿加载 enabled: true # 开启饥饿加载,默认是false关闭的 clients: # 需要饥饿加载的服务列表,多个时再下面列出 -userserver # 指定用户服务用饥饿加载 -orderserver # 指定订单服务用饥饿加载
nacos注册中心
认识和安装Nacos
Nacos是阿里巴巴的产品,现在是SpringCloud中的一个组件。相比Eureka功能更加丰富,在国内受欢迎程度较高。

Windows安装
开发阶段采用单机安装即可。
下载安装包
- 在Nacos的GitHub页面,提供有下载链接,可以下载编译好的Nacos服务端或者源代码:
- GitHub主页:https://github.com/alibaba/nacos
- GitHub的Release下载页:https://github.com/alibaba/nacos/releases
- Windows使用zip压缩包
目录说明
- 下载好压缩包之后进行解压即可,目录说明如下:
- bin:启动脚本
- conf:配置文件
- rarget:代码包,Nacos就是java语言开发的
端口配置
- Nacos的默认端口是8848,如果你电脑上的其它进程占用了8848端口,请先尝试关闭该进程。
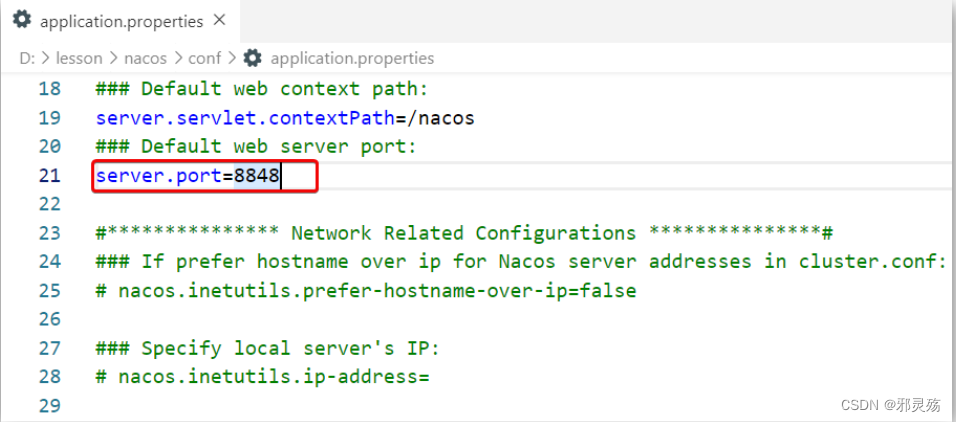
- 如果无法关闭占用8848端口的进程,也可以进入nacos的conf目录,修改配置文件中的端口:
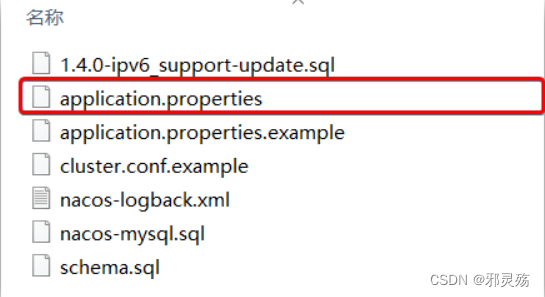
- 修改其中的内容:
启动
- 启动非常简单,进入到bin目录下,如图:
- 然后打开cmd,执行下面命令即可,-m参数指模型,standalone值单机启动
startup.cmd -m standalone - 启动后效果如下:

访问
- 在浏览器输入地址:http://127.0.0.1:8848/nacos即可:
- 输入账号和密码登录,默认账号和密码都是nacos
Linux安装
Linux或者Mac安装方式与Windows类似。
安装
- Nacos依赖于JDK运行,索引Linux上也需要安装JDK才行。
- 将Nacos压缩包上传到Linux服务器
- 使用命令进行解压:
tar -xvf nacos-server-1.4.1.tar.gz - 解压后压缩包就可以删除了:
rm -rf nacos-server-1.4.1.tar.gz - 端口配置,与Windows中已有,使用vi或vim修改配置文件即可
- 在nacos/bin目录中,输入命令启动Nacos:
sh startup.sh -m standalone
注意:在2.1之后的版本中,官方移除了其中默认的秘钥,当安装成功后启动,虽然提示启动成,但无法访问,此时需要到官方文档查询权限管理,找到密码配置属性,在配置中加入秘钥,重启服务后才可以访问
Nacos依赖
- 父工程
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-dependencies</artifactId> <version>2.2.5.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> - 客户端
<!-- nacos客户端依赖包 --> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency>
注册服务到Nacos
- Nacos是SpringCloudAlibaba的组件,而SpringCloudAlibaba也遵循SpringCloud中定义的服务注册、服务发现规范。
- 因此使用Nacos和使用Eureka对于微服务来说,并没有太大区别。
- 我们可以在SpringCloud官网看到comments模块,就是指通用模块,其中就定义了服务的注册和服务的发现两个接口,而Nacos或者eureka都是基于这两个接口实现的
- 因此其基本使用大致上相当,主要差异在于:
- 依赖不同
- 服务地址不同
引入依赖
- 在cloud-demo父工程的pom文件中的
<dependencyManagement>中引入SpringCloudAlibaba的依赖:<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-dependencies</artifactId> <version>2.2.6.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> - 然后在user-service和order-service中的pom文件中引入nacos-discovery依赖:
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> - 需要注意,在引入Nacos依赖时要注释掉eureka的依赖
配置nacos地址
- 在user-service和order-service的application.yml中添加nacos地址:
spring: cloud: nacos: server-addr: localhost:8848 - 同样需要注意的是,注释掉eureka的地址
重启
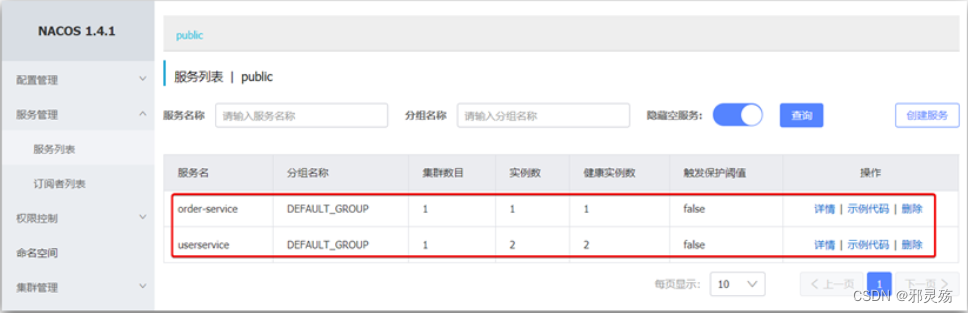
重启微服务后,登录nacos管理页面,可以看到微服务信息:
服务的发现
代码不同动,保持之前的就行,包括ribbo的配置都不用动,因为他们都遵循了SpringCloud的通用模块
Nacos服务分级存储模型
一个服务可以有多个实例,例如我们的user-service,可以有:
- 127.0.0.1:8081
- 127.0.0.1:8082
- 127.0.0.1:8083
假如这些实例分布于全国各地的不同机房,例如:
- 127.0.0.1:8081,在上海机房
- 127.0.0.1:8082,在上海机房
- 127.0.0.1:8083,在杭州机房
Nacos就将同一机房内的实例 划分为一个集群。
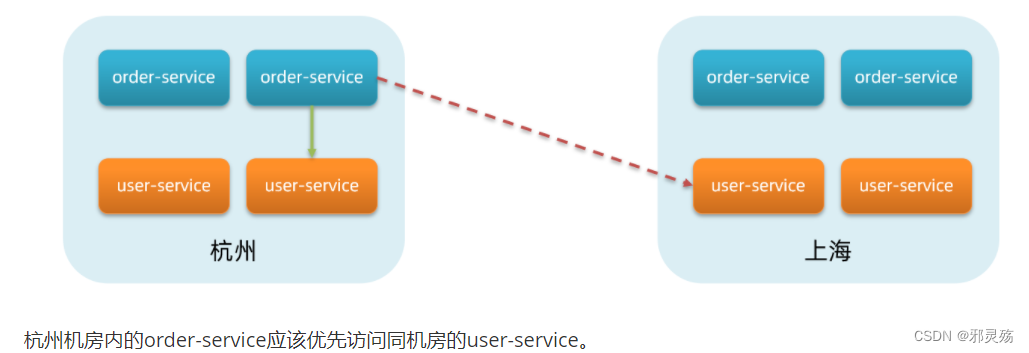
也就是说,user-service是服务,一个服务可以包含多个集群,如杭州、上海,每个集群下可以有多个实例,形成分级模型,如图:

微服务互相访问时,应该尽可能访问同集群实例,因为本地访问速度更快。当本集群内不可用时,才访问其它集群。例如:
给user-service配置集群
修改user-service的application.yml文件,添加集群配置:
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ # 集群名称,自定义
重启两个user-service实例后,我们可以在nacos控制台看到下面结果:

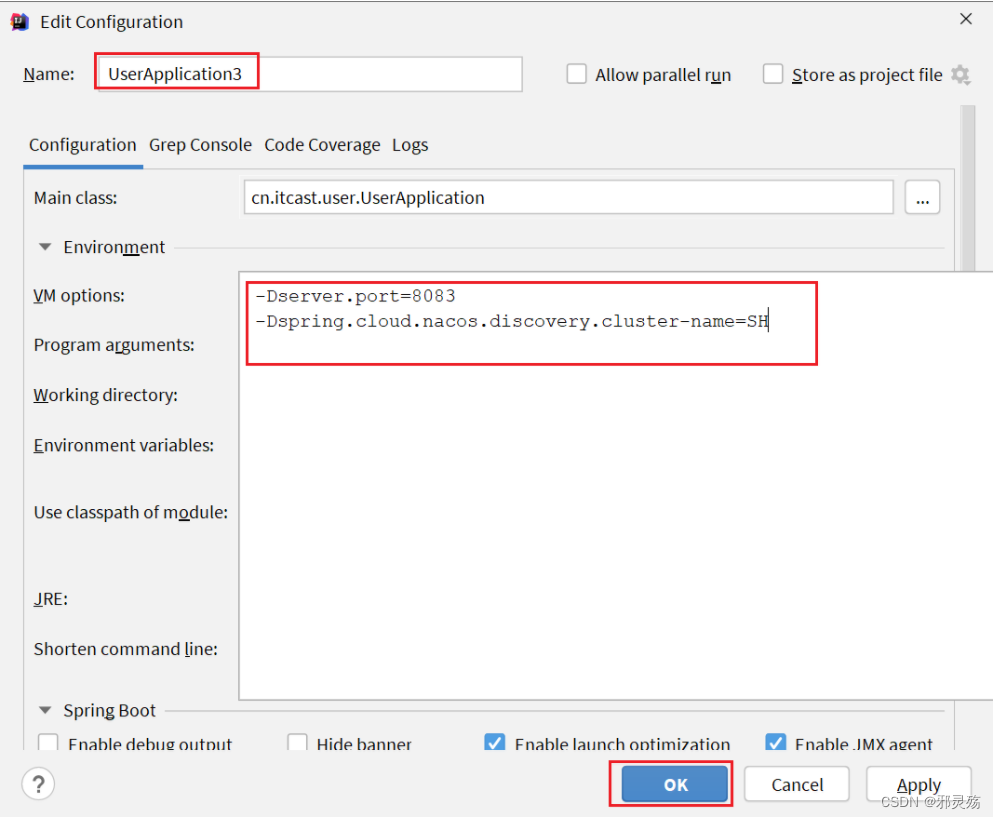
我们再次复制一个user-service启动配置,添加属性:
-Dserver.port=8083 -Dspring.cloud.nacos.discovery.cluster-name=SH
如图配置:
启动UserApplication3后再次查看nacos控制台:
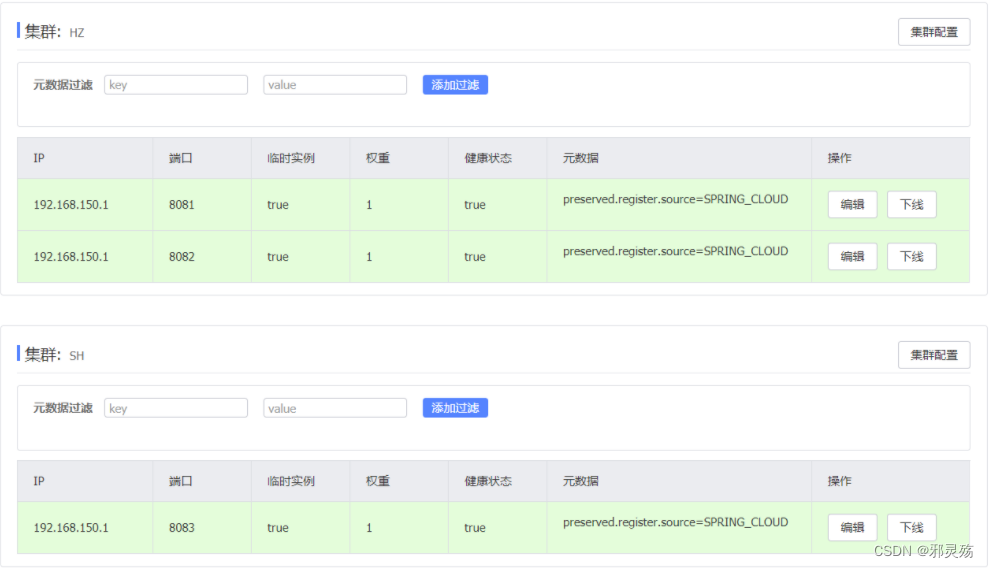
同集群优先的负载均衡
- 默认的
ZoneAvoidanceRule并不能实现根据同集群优先来实现负载均衡。 - 也就是说,即便我们配置了集群,默认也不会实现同集群优先调用
- 因此Nacos中提供了一个
NacosRule的实现,可以优先从同集群中挑选实例。 - 给order-service配置集群信息,修改order-service的application.yml文件,添加集群配置:
spring: cloud: nacos: server-addr: localhost:8848 discovery: cluster-name: HZ # 集群名称,也就是要优先访问的集群服务 - 修改负载均衡规则
userservice: ribbon: # 负载均衡规则 NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule - 需要注意的是,在同集群中,使用的是随机的均衡策略
权重配置
实际部署中会出现这样的场景:
服务器设备性能有差异,部分实例所在机器性能较好,另一些较差,我们希望性能好的机器承担更多的用户请求。
但默认情况下NacosRule是同集群内随机挑选,不会考虑机器的性能问题。
因此,Nacos提供了权重配置来控制访问频率,权重越大则访问频率越高。
在nacos控制台,找到user-service的实例列表,点击编辑,即可修改权重:
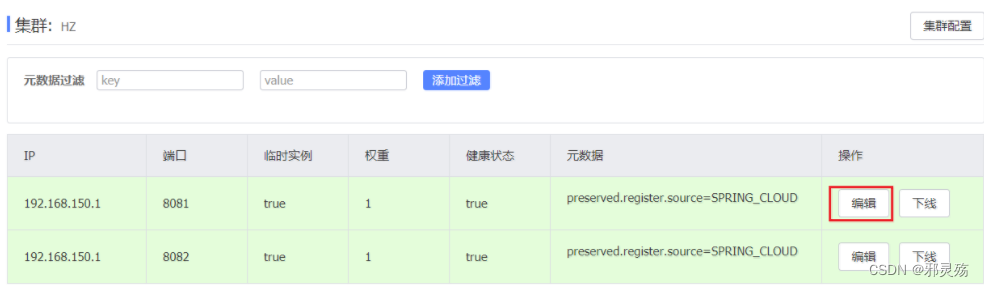
在弹出的编辑窗口,修改权重:值为0到10
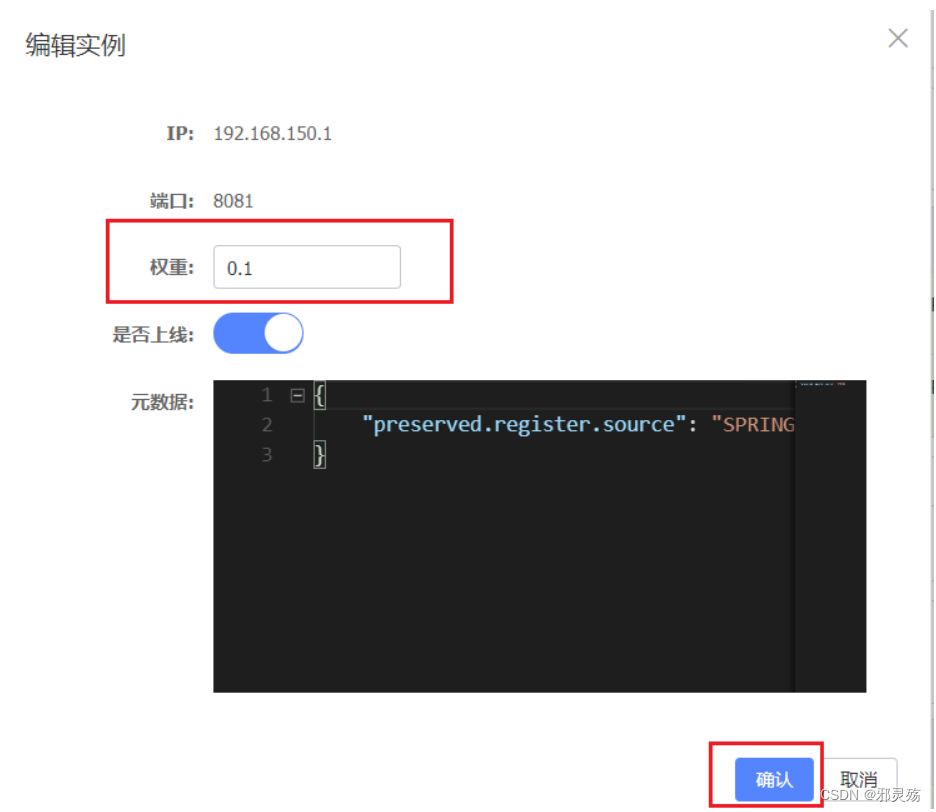
注意:如果权重修改为0,则该实例永远不会被访问,一般用来平滑的升级服务等操作,比如慢慢降低某个服务的权重,将访问给到其他服务,直到权重降到0,然后进行服务升级
升级成后,再慢慢提高权重,测试是否升级成功,直到将权重提高到正常水平
环境隔离
Nacos提供了namespace来实现环境隔离功能。
- nacos中可以有多个namespace
- namespace下可以有group、service等
- 不同namespace之间相互隔离,例如不同namespace的服务互相不可见

创建namespace
默认情况下,所有service、data、group都在同一个namespace,名为public:
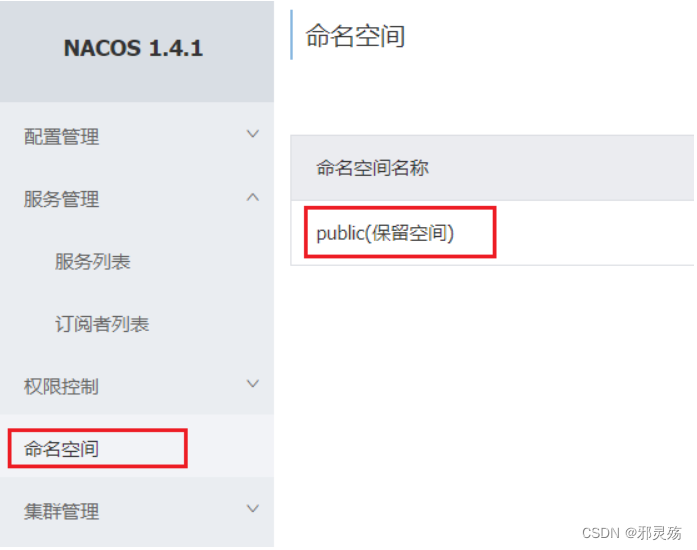
我们可以点击页面新增按钮,添加一个namespace:
然后,填写表单:

就能在页面看到一个新的namespace:
给微服务配置namespace
给微服务配置namespace只能通过修改配置来实现。
例如,修改order-service的application.yml文件:
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ
namespace: 492a7d5d-237b-46a1-a99a-fa8e98e4b0f9 # 命名空间,填ID
重启order-service后,访问控制台,可以看到下面的结果:

此时访问order-service,因为namespace不同,会导致找不到userservice,控制台会报错:

Nacos与Eureka的区别
Nacos的服务实例分为两种l类型:
- 临时实例:如果实例宕机超过一定时间,会从服务列表剔除,默认的类型。
- 非临时实例:如果实例宕机,不会从服务列表剔除,也可以叫永久实例。
配置一个服务实例为永久实例:
spring:
cloud:
nacos:
discovery:
ephemeral: false # 设置为非临时实例
Nacos和Eureka整体结构类似,服务注册、服务拉取、心跳等待,但是也存在一些差异:
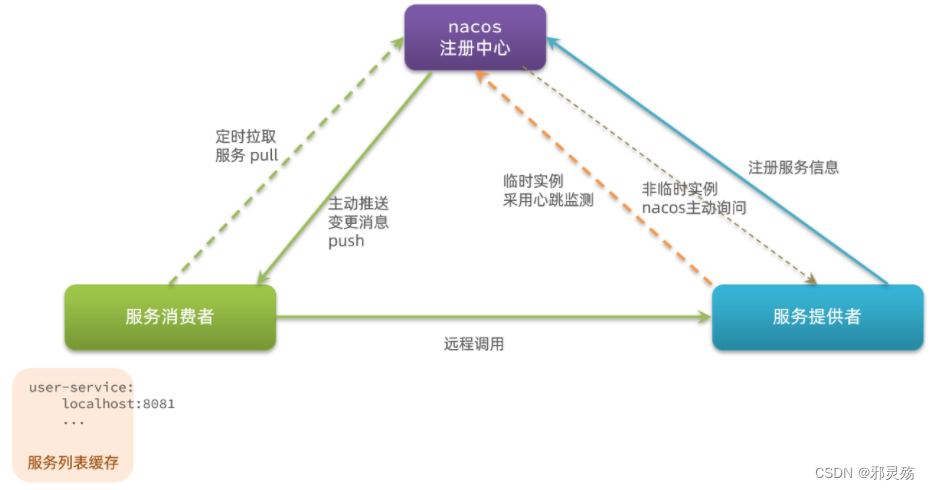
- Nacos与eureka的共同点
- 都支持服务注册和服务拉取
- 都支持服务提供者心跳方式做健康检测
- Nacos与Eureka的区别
- Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
- 临时实例心跳不正常会被剔除,非临时实例则不会被剔除
- Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
- Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式;Eureka采用AP方式
Nacos配置管理
Nacos与Eureka一样,都是注册中心
Nacos另外还有一个功能就是能够做配置管理中心
统一配置管理
当微服务部署的实例越来越多,达到数十、数百时,逐个修改微服务配置就会让人抓狂,而且很容易出错。我们需要一种统一配置管理方案,可以集中管理所有实例的配置。
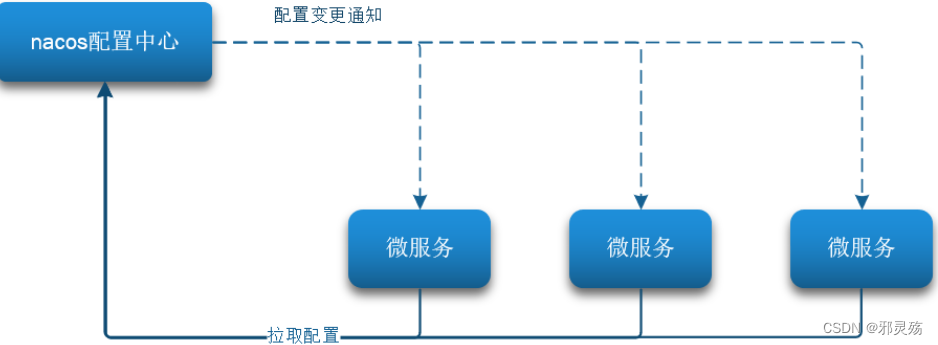
Nacos一方面可以将配置集中管理,另一方可以在配置变更时,及时通知微服务,实现配置的热更新。
在nacos中添加配置文件
- 打开配置列表,点击加号“+”添加配置
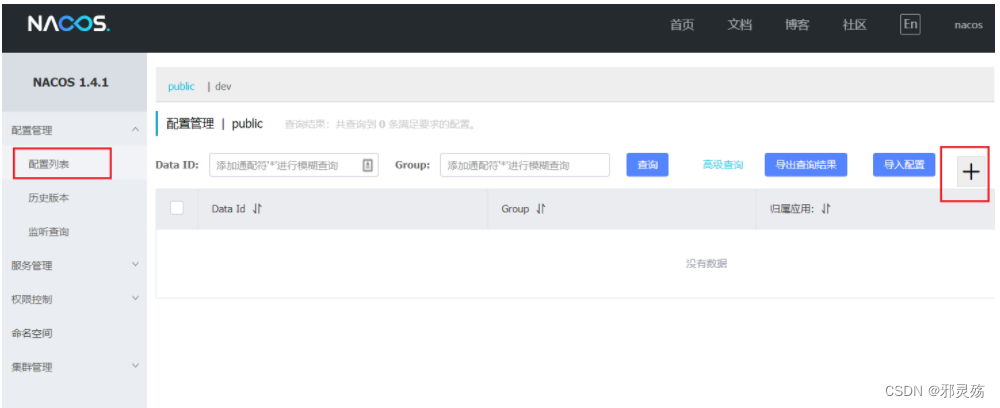
- 然后在弹出的表单中,填写配置信息:
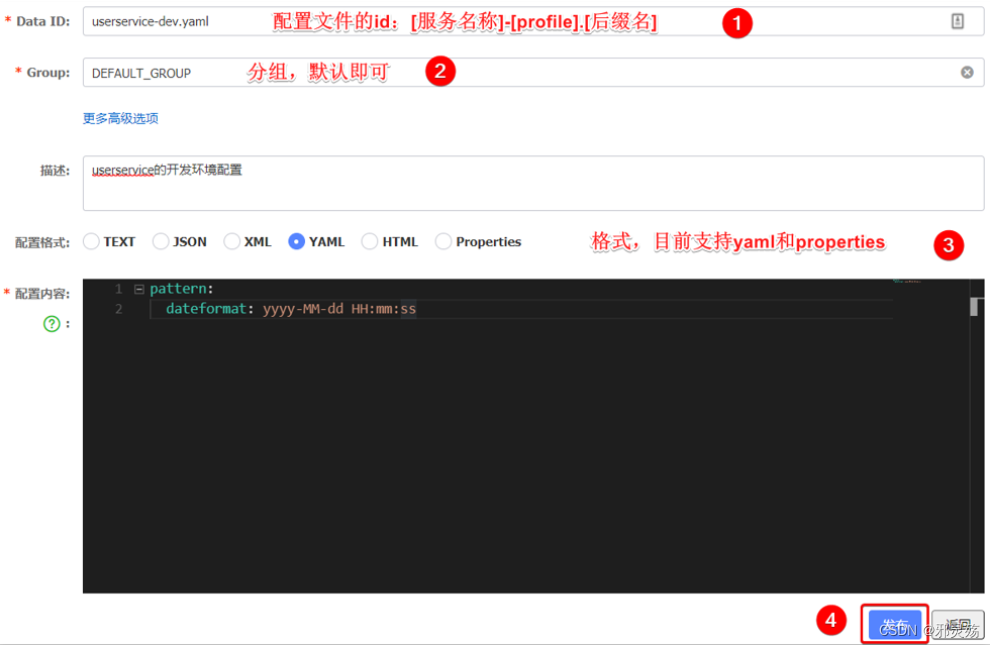
- 注意:项目的核心配置,需要热更新的配置才有放到nacos管理的必要。基本不会变更的一些配置还是保存在微服务本地比较好。
从微服务拉取配置
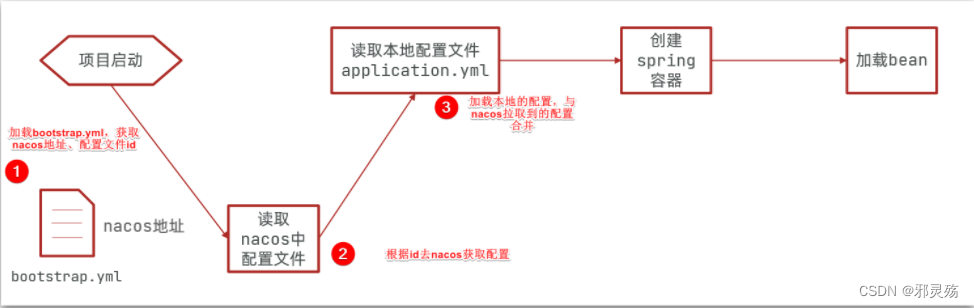
微服务要拉取nacos中管理的配置,并且与本地的application.yml配置合并,才能完成项目启动。
但如果尚未读取application.yml,又如何得知nacos地址呢?
因此spring引入了一种新的配置文件:bootstrap.yaml文件,会在application.yml之前被读取,bootstrap.yaml的优先级比application.yaml高,流程如下:
-
首先,在user-service服务中,引入nacos-config的客户端依赖:
<!--nacos配置管理依赖--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency> -
然后,在user-service中添加一个bootstrap.yaml文件,内容如下:
spring: application: name: userservice # 服务名称 profiles: active: dev #开发环境,这里是dev cloud: nacos: server-addr: localhost:8848 # Nacos地址 config: file-extension: yaml # 文件后缀名 -
这里会根据spring.cloud.nacos.server-addr获取nacos地址,再根据
${spring.application.name}-${spring.profiles.active}.${spring.cloud.nacos.config.file-extension}作为文件id,来读取配置。 -
本例中,就是去读取
userservice-dev.yaml:

-
测试,在user-service中的UserController中添加业务逻辑,读取pattern.dateformat配置:@Value就是spring提供的读取配置文件属性的注解
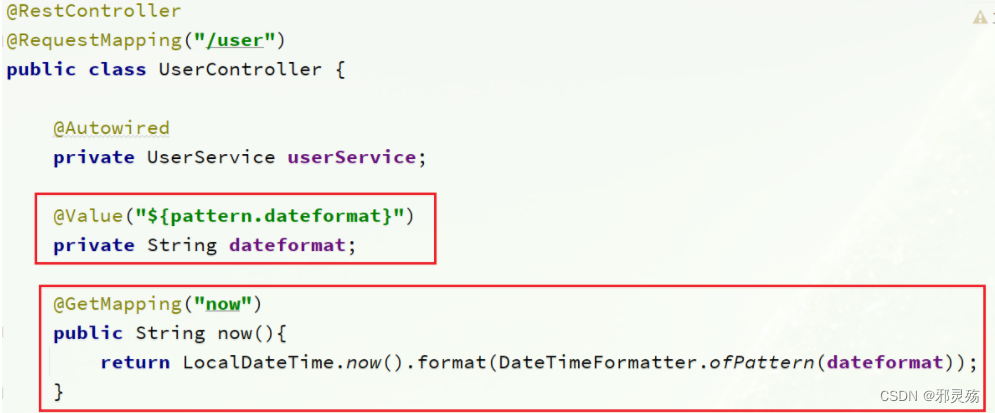
-
完整代码如下:
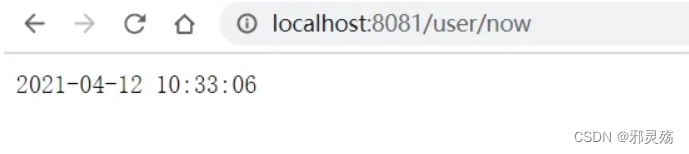
import cn.itcast.user.pojo.User; import cn.itcast.user.service.UserService; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.annotation.Value; import org.springframework.web.bind.annotation.*; import java.time.LocalDateTime; import java.time.format.DateTimeFormatter; @Slf4j @RestController @RequestMapping("/user") public class UserController { @Autowired private UserService userService; @Value("${pattern.dateformat}") private String dateformat; @GetMapping("now") public String now(){ // 基于格式来转换时间格式 return LocalDateTime.now().format(DateTimeFormatter.ofPattern(dateformat)); } // ...略 } -
访问接口,我们可以看到效果
配置热更新
我们最终的目的,是修改nacos中的配置后,微服务中无需重启即可让配置生效,也就是配置热更新。
要实现配置热更新,可以使用两种方式:
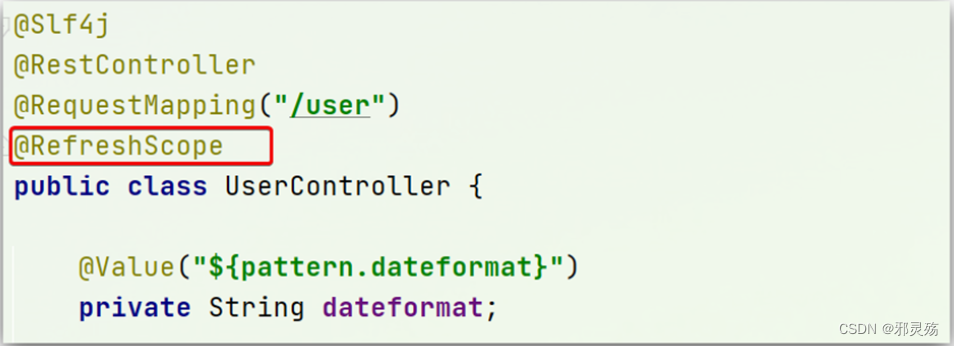
方式一:使用@Value读取配置文件中的属性
在@Value注入的变量所在类上添加注解@RefreshScope:
方式二:基于@ConfigurationProperties读取配置文件属性
使用@ConfigurationProperties注解代替@Value注解。
在user-service服务中,添加一个类,读取patterrn.dateformat属性:
package cn.itcast.user.config;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
@Component
@Data
@ConfigurationProperties(prefix = "pattern")
public class PatternProperties {
private String dateformat;
}
在UserController中使用这个类代替@Value:

完整代码:
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@Autowired
private PatternProperties patternProperties;
@GetMapping("now")
public String now(){
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(patternProperties.getDateformat()));
}
// 略
}
配置共享
其实微服务启动时,会去nacos读取多个配置文件,例如:
[spring.application.name]-[spring.profiles.active].yaml,例如:userservice-dev.yaml[spring.application.name].yaml,例如:userservice.yaml
而[spring.application.name].yaml不包含环境,只包含服务名,因此可以被多个环境共享。
下面我们通过案例来测试配置共享
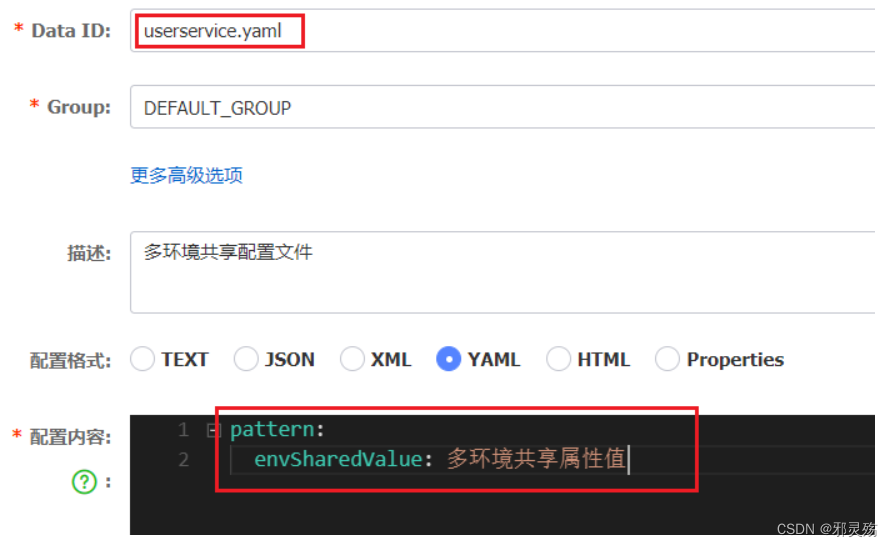
添加一个环境共享配置
我们在nacos中添加一个userservice.yaml文件:
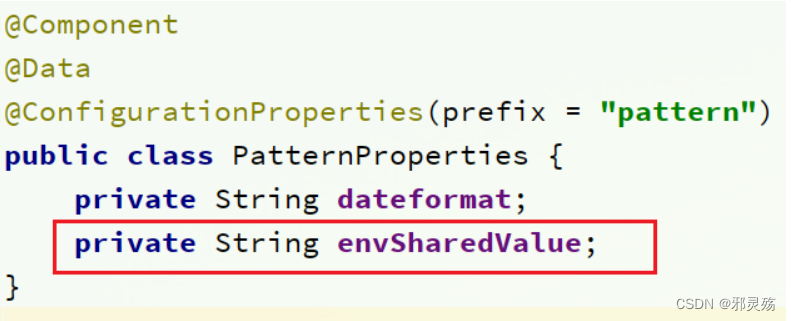
在user-service中读取共享配置
在user-service服务中,修改PatternProperties类,读取新添加的属性:
在user-service服务中,修改UserController,添加一个方法:
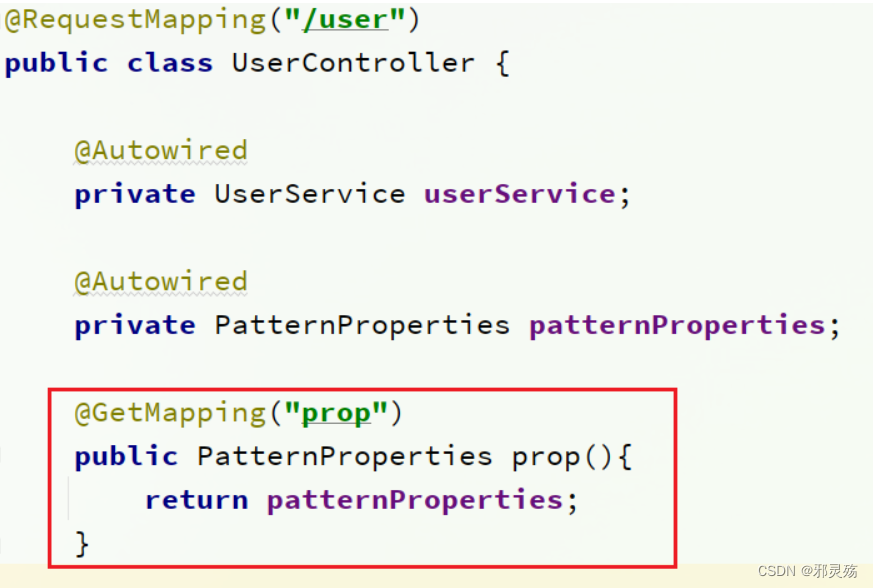
运行两个UserApplication,使用不同的profile
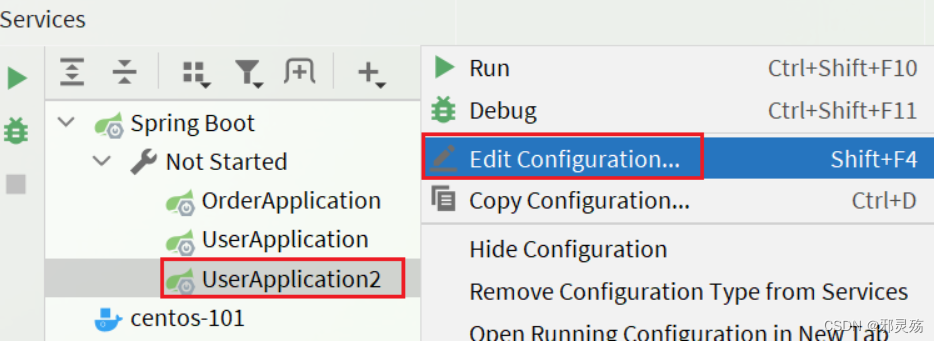
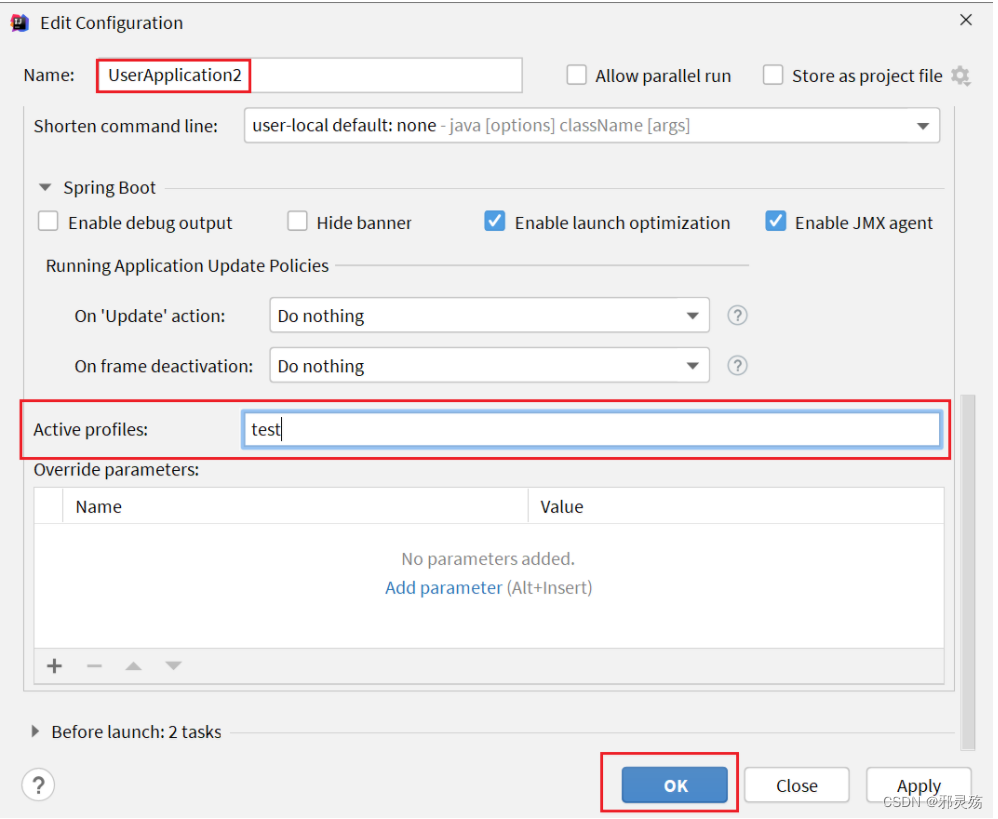
修改UserApplication2这个启动项,改变其profile值:当然也可以修改配置文件
这样,UserApplication(8081)使用的profile是dev,UserApplication2(8082)使用的profile是test。
启动UserApplication和UserApplication2
访问http://localhost:8081/user/prop,结果:

访问http://localhost:8082/user/prop,结果:

可以看出来,不管是dev,还是test环境,都读取到了envSharedValue这个属性的值。
配置共享的优先级
当nacos、服务本地同时出现相同属性时,优先级有高低之分:

也就是说,最终是以nacos中的环境为准,其次是nacos中的共享配置,最后才是本地配置
搭建Nacos集群
Nacos生产环境下一定要部署为集群状态
集群结构图
官方给出的Nacos集群图:
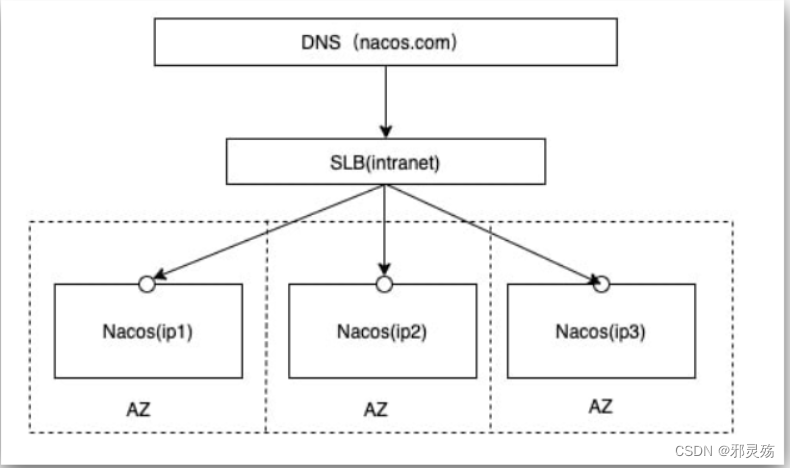
其中包含3个nacos节点,然后一个负载均衡器代理3个Nacos。这里负载均衡器可以使用nginx。
我们计划的集群结构:需要注意,这里的数据库是Nacos使用的,不是业务数据库,用来保存每个节点的访问信息等记录
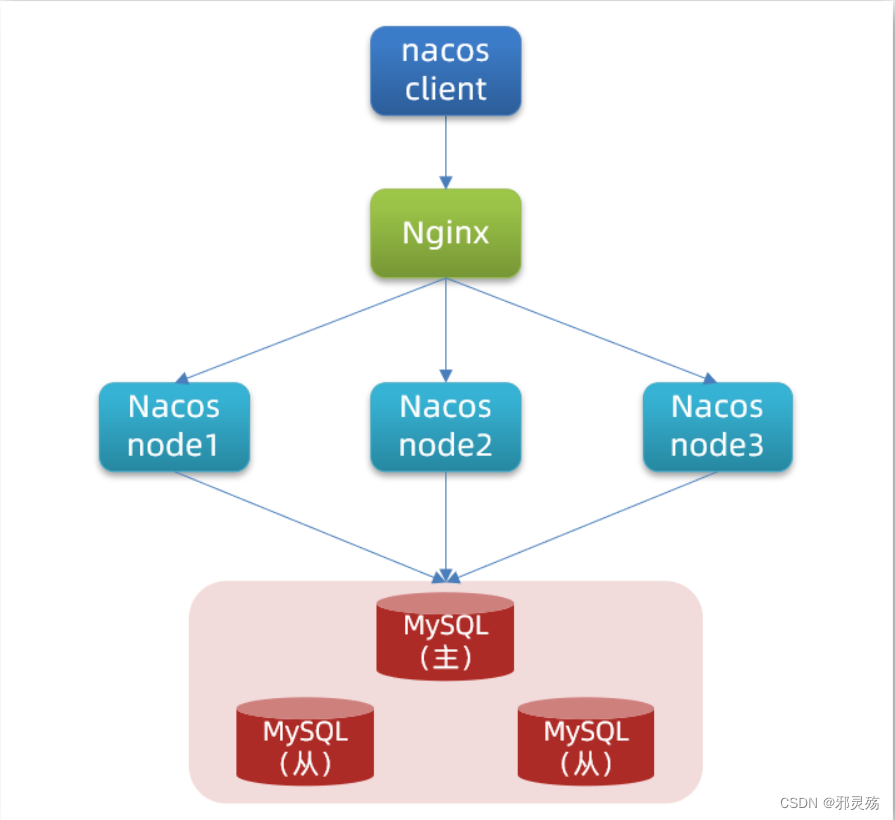
三个nacos节点的地址:
| 节点 | ip | port |
|---|---|---|
| nacos1 | 192.168.150.1 | 8845 |
| nacos2 | 192.168.150.1 | 8846 |
| nacos3 | 192.168.150.1 | 8847 |
搭建集群
搭建集群的基本步骤:
- 搭建数据库,初始化数据库表结构
- 下载nacos安装包
- 配置nacos
- 启动nacos集群
- nginx反向代理
初始化数据库
Nacos默认数据存储在内嵌数据库Derby中,不属于生产可用的数据库。也就是单机使用时
官方推荐的最佳实践是使用带有主从的高可用数据库集群,
这里我们以单点的数据库为例来讲解。
首先新建一个数据库,命名为nacos,而后导入下面的SQL:
CREATE TABLE `config_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(255) DEFAULT NULL,
`content` longtext NOT NULL COMMENT 'content',
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
`src_user` text COMMENT 'source user',
`src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip',
`app_name` varchar(128) DEFAULT NULL,
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
`c_desc` varchar(256) DEFAULT NULL,
`c_use` varchar(64) DEFAULT NULL,
`effect` varchar(64) DEFAULT NULL,
`type` varchar(64) DEFAULT NULL,
`c_schema` text,
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfo_datagrouptenant` (`data_id`,`group_id`,`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_info_aggr */
/******************************************/
CREATE TABLE `config_info_aggr` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(255) NOT NULL COMMENT 'group_id',
`datum_id` varchar(255) NOT NULL COMMENT 'datum_id',
`content` longtext NOT NULL COMMENT '内容',
`gmt_modified` datetime NOT NULL COMMENT '修改时间',
`app_name` varchar(128) DEFAULT NULL,
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfoaggr_datagrouptenantdatum` (`data_id`,`group_id`,`tenant_id`,`datum_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='增加租户字段';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_info_beta */
/******************************************/
CREATE TABLE `config_info_beta` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
`content` longtext NOT NULL COMMENT 'content',
`beta_ips` varchar(1024) DEFAULT NULL COMMENT 'betaIps',
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
`src_user` text COMMENT 'source user',
`src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip',
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfobeta_datagrouptenant` (`data_id`,`group_id`,`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info_beta';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_info_tag */
/******************************************/
CREATE TABLE `config_info_tag` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
`tenant_id` varchar(128) DEFAULT '' COMMENT 'tenant_id',
`tag_id` varchar(128) NOT NULL COMMENT 'tag_id',
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
`content` longtext NOT NULL COMMENT 'content',
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
`src_user` text COMMENT 'source user',
`src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfotag_datagrouptenanttag` (`data_id`,`group_id`,`tenant_id`,`tag_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info_tag';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_tags_relation */
/******************************************/
CREATE TABLE `config_tags_relation` (
`id` bigint(20) NOT NULL COMMENT 'id',
`tag_name` varchar(128) NOT NULL COMMENT 'tag_name',
`tag_type` varchar(64) DEFAULT NULL COMMENT 'tag_type',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
`tenant_id` varchar(128) DEFAULT '' COMMENT 'tenant_id',
`nid` bigint(20) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`nid`),
UNIQUE KEY `uk_configtagrelation_configidtag` (`id`,`tag_name`,`tag_type`),
KEY `idx_tenant_id` (`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_tag_relation';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = group_capacity */
/******************************************/
CREATE TABLE `group_capacity` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`group_id` varchar(128) NOT NULL DEFAULT '' COMMENT 'Group ID,空字符表示整个集群',
`quota` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值',
`usage` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '使用量',
`max_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值',
`max_aggr_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数,,0表示使用默认值',
`max_aggr_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值',
`max_history_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_group_id` (`group_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='集群、各Group容量信息表';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = his_config_info */
/******************************************/
CREATE TABLE `his_config_info` (
`id` bigint(64) unsigned NOT NULL,
`nid` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`data_id` varchar(255) NOT NULL,
`group_id` varchar(128) NOT NULL,
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
`content` longtext NOT NULL,
`md5` varchar(32) DEFAULT NULL,
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`src_user` text,
`src_ip` varchar(50) DEFAULT NULL,
`op_type` char(10) DEFAULT NULL,
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
PRIMARY KEY (`nid`),
KEY `idx_gmt_create` (`gmt_create`),
KEY `idx_gmt_modified` (`gmt_modified`),
KEY `idx_did` (`data_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='多租户改造';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = tenant_capacity */
/******************************************/
CREATE TABLE `tenant_capacity` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`tenant_id` varchar(128) NOT NULL DEFAULT '' COMMENT 'Tenant ID',
`quota` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值',
`usage` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '使用量',
`max_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值',
`max_aggr_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数',
`max_aggr_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值',
`max_history_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_tenant_id` (`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='租户容量信息表';
CREATE TABLE `tenant_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`kp` varchar(128) NOT NULL COMMENT 'kp',
`tenant_id` varchar(128) default '' COMMENT 'tenant_id',
`tenant_name` varchar(128) default '' COMMENT 'tenant_name',
`tenant_desc` varchar(256) DEFAULT NULL COMMENT 'tenant_desc',
`create_source` varchar(32) DEFAULT NULL COMMENT 'create_source',
`gmt_create` bigint(20) NOT NULL COMMENT '创建时间',
`gmt_modified` bigint(20) NOT NULL COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_tenant_info_kptenantid` (`kp`,`tenant_id`),
KEY `idx_tenant_id` (`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='tenant_info';
CREATE TABLE `users` (
`username` varchar(50) NOT NULL PRIMARY KEY,
`password` varchar(500) NOT NULL,
`enabled` boolean NOT NULL
);
CREATE TABLE `roles` (
`username` varchar(50) NOT NULL,
`role` varchar(50) NOT NULL,
UNIQUE INDEX `idx_user_role` (`username` ASC, `role` ASC) USING BTREE
);
CREATE TABLE `permissions` (
`role` varchar(50) NOT NULL,
`resource` varchar(255) NOT NULL,
`action` varchar(8) NOT NULL,
UNIQUE INDEX `uk_role_permission` (`role`,`resource`,`action`) USING BTREE
);
INSERT INTO users (username, password, enabled) VALUES ('nacos', '$2a$10$EuWPZHzz32dJN7jexM34MOeYirDdFAZm2kuWj7VEOJhhZkDrxfvUu', TRUE);
INSERT INTO roles (username, role) VALUES ('nacos', 'ROLE_ADMIN');
配置Nacos(新下载的包,与单机配置不同)
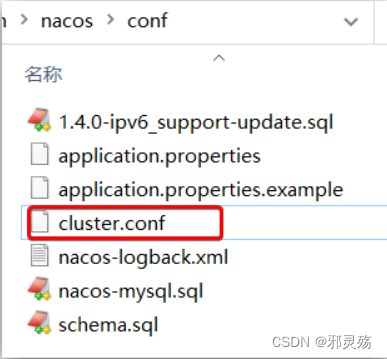
- 进入nacos的conf目录,修改配置文件cluster.conf.example,重命名为cluster.conf:
- 然后在里面添加内容,就是每个单点Nacos的地址端口信息
127.0.0.1:8845 127.0.0.1.8846 127.0.0.1.8847 - 然后修改application.properties文件,添加数据库配置,其实里面有,只是被注释了,不用管,直接新添加如下内容
spring.datasource.platform=mysql # 数据库数量,我们这里是一个 db.num=1 # 数据库地址,数据库下标索引,0开始,多个数据库就依次配置 db.url.0=jdbc:mysql://127.0.0.1:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC # 数据库用户名 db.user.0=root # 数据库密码 db.password.0=123
启动
- 将刚才配置好的nacos文件夹复制三份,分别命名为:nacos1、nacos2、nacos3
- 然后分别修改三个文件夹中的application.properties:就是修改端口为我们配置的端口
- nacos1:
server.port=8845 - nacos2:
server.port=8846 - nacos3:
server.port=8847
- nacos1:
- 然后分别启动三个节点,启动时命令不需要带
-m参数,默认就是集群方式
nginx反向代理(windows环境,Linux环境参考Nginx笔记)
- 下载Nginx安装包,解压到非中文路劲下
- 修改conf/nginx.conf文件,配置如下:
# 需要负载均衡的服务 upstream nacos-cluster { server 127.0.0.1:8845; server 127.0.0.1:8846; server 127.0.0.1:8847; } # 监听的端口及地址 server { listen 80; server_name localhost; # 拦截访问地址,也就是访问`/nacos`,就交给下面的地址,也就是上面配的负载均衡 location /nacos { proxy_pass http://nacos-cluster; } } - 而后在浏览器访问:http://localhost/nacos即可。看似打开一个,其实已经做了代理及负载均衡
- 代码中application.yml文件配置如下:这里就是Nginx配的地址,因为我们在Nginx监听的是80端口
spring: cloud: nacos: server-addr: localhost:80 # Nacos地址
优化
- 实际部署时,需要给做反向代理的nginx服务器设置一个域名,这样后续如果有服务器迁移nacos的客户端也无需更改配置.
- Nacos的各个节点应该部署到多个不同服务器,做好容灾和隔离
Feign远程调用
先来看我们以前利用RestTemplate发起远程调用的代码:

存在下面的问题:
- 代码可读性差,编程体验不统一
- 参数复杂URL难以维护
概念
- Feign是一个声明式的http客户端,官方地址:https://github.com/OpenFeign/feign
- 所谓声明式,我们以前在Spring中有声明式事务,就是不需要自己创建事务、开启事务等,在配置中声明即可使用,此时声明时客户端也是同样的道理
- 其作用就是帮助我们优雅的实现http请求的发送,解决上面提到的问题。
Feign替代RestTemplate
引入依赖
我们在消费者服务中引入相关依赖
该依赖已经被Spring管理,因此不需要指定版本
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
添加注解
在消费服务启动类上面添加注解开启Feign
编写Feign的客户端
在消费服务中创建一个接口,如下:
// 注解指明为一个客户端,参数未提供者服务名,也就是指定哪个服务
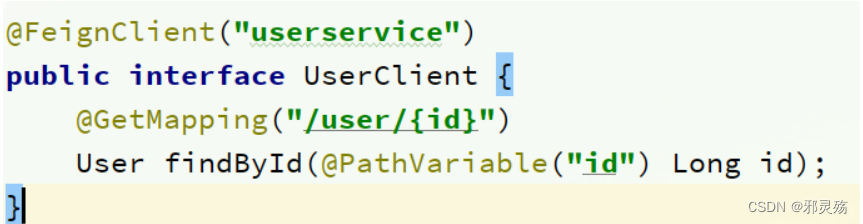
@FeignClient("userservice")
public interface UserClient {
// 需要请求的接口的请求方式,为GET,地址为/user/{id}
@GetMapping("/user/{id}")
// 方法名自定义,返回值为请求返回值,参数未请求所需参数,如果是地址中解析,也要指明
User findById(@PathVariable("id") Long id);
}
这个客户端主要是基于SpringMVC的注解来声明远程调用的信息,比如:
- 服务名称:userservice
- 请求方式:GET
- 请求路径:/user/{id}
- 请求参数:Long id
- 返回值类型:User
这样,Feign就可以帮助我们发送http请求,无需自己使用RestTemplate来发送了。
测试
修改order-service中的OrderService类中的queryOrderById方法,使用Feign客户端代替RestTemplate:
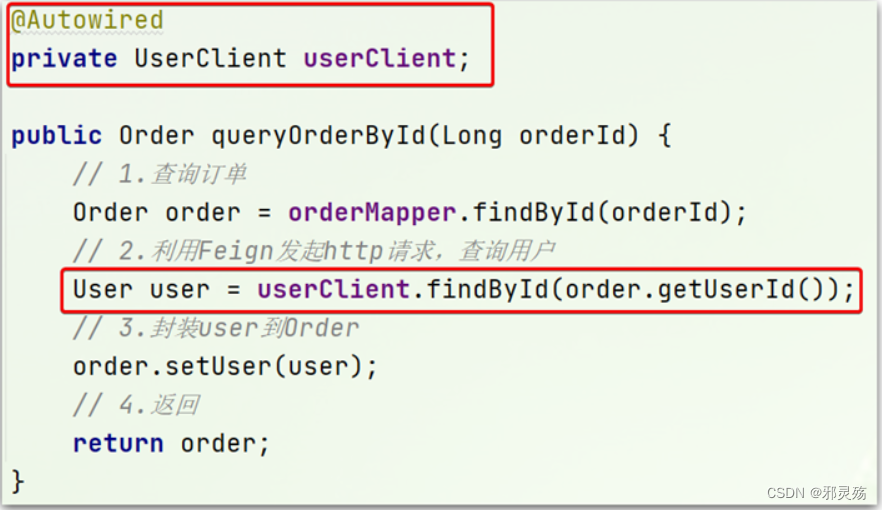
总结
① 引入依赖
② 添加@EnableFeignClients注解
③ 编写FeignClient接口
④ 使用FeignClient中定义的方法代替RestTemplate
自定义配置
Feign可以支持很多的自定义配置,其中常用如下表所示:
| 类型 | 作用 | 说明 |
|---|---|---|
| feign.Logger.Level | 修改日志级别 | 包含四种不同的级别:NONE、BASIC、HEADERS、FULL |
| feign.codec.Decoder | 响应结果的解析器 | http远程调用的结果做解析,例如解析json字符串为java对象 |
| feign.codec.Encoder | 请求参数编码 | 将请求参数编码,便于通过http请求发送 |
| feign. Contract | 支持的注解格式 | 默认是SpringMVC的注解 |
| feign. Retryer | 失败重试机制 | 请求失败的重试机制,默认是没有,不过会使用Ribbon的重试 |
一般情况下,默认值就能满足我们使用,如果要自定义时,只需要创建自定义的@Bean覆盖默认Bean即可。
下面以日志为例来演示如何自定义配置。
配置文件方式
- 基于配置文件修改feign的日志级别可以针对单个服务:
feign: client: config: userservice: # 服务名,针对某个微服务的配置,直接写服务名 loggerLevel: FULL # 日志级别 - 也可以针对所有服务:
feign: client: config: default: # 这里用default就是全局配置,如果是写服务名称,则是针对某个微服务的配置 loggerLevel: FULL # 日志级别 - 而日志的级别分为四种:
- NONE:不记录任何日志信息,这是默认值。
- BASIC:仅记录请求的方法,URL以及响应状态码和执行时间
- HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息
- FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
Java代码方式
- 也可以基于Java代码来修改日志级别,先声明一个类,然后声明一个Logger.Level的对象:
- 需要特别注意,该类虽然类似配置类,且申明了Bean,但是类上面不需要加configuration注解,这样这个配置类就不会起作用,只有我们主动调用才会运行
// 这个配置类不需要加注解 public class DefaultFeignConfiguration { @Bean public Logger.Level feignLogLevel(){ return Logger.Level.BASIC; // 日志级别为BASIC } } - 如果要全局生效,将其放到启动类的@EnableFeignClients这个注解中:
@EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration .class) - 如果是局部生效,则把它放到对应的@FeignClient这个注解中:
@FeignClient(value = "userservice", configuration = DefaultFeignConfiguration .class)
Feign使用优化
Feign底层发起http请求,依赖于其它的框架。其底层客户端实现有三种方式,包括:
- URLConnection:默认实现,不支持连接池
- Apache HttpClient :支持连接池
- OKHttp:支持连接池
因此提高Feign的性能主要手段就是使用连接池代替默认的URLConnection。
这里我们用Apache的HttpClient来演示。
引入依赖
在消费服务中,我们引入Apache的HttpClient依赖:
<!--httpClient的依赖 -->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
</dependency>
配置连接池
在配置文件中添加相应配置
feign:
client:
config:
default: # default全局的配置
loggerLevel: BASIC # 日志级别,BASIC就是基本的请求和响应信息
# 下面为对应apache连接池配置
httpclient:
enabled: true # 开启feign对HttpClient的支持
max-connections: 200 # 最大的连接数
max-connections-per-route: 50 # 每个路径的最大连接数
测试
-
接下来,在FeignClientFactoryBean中的loadBalance方法中打断点:
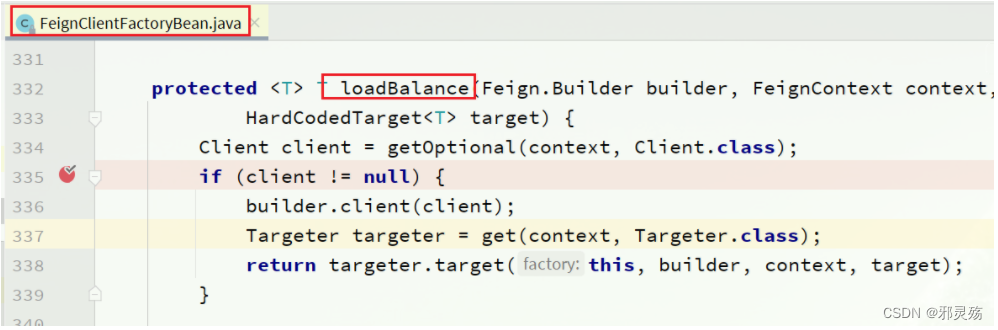
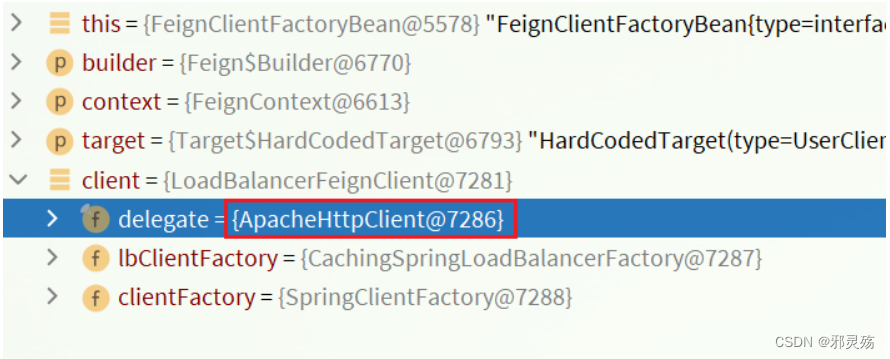
-
Debug方式启动order-service服务,可以看到这里的client,底层就是Apache HttpClient:
总结
1.日志级别尽量用basic
2.使用HttpClient或OKHttp代替URLConnection
① 引入feign-httpClient依赖
② 配置文件开启httpClient功能,设置连接池参数
最佳实践
所谓最近实践,就是使用过程中总结的经验,最好的一种使用方式。
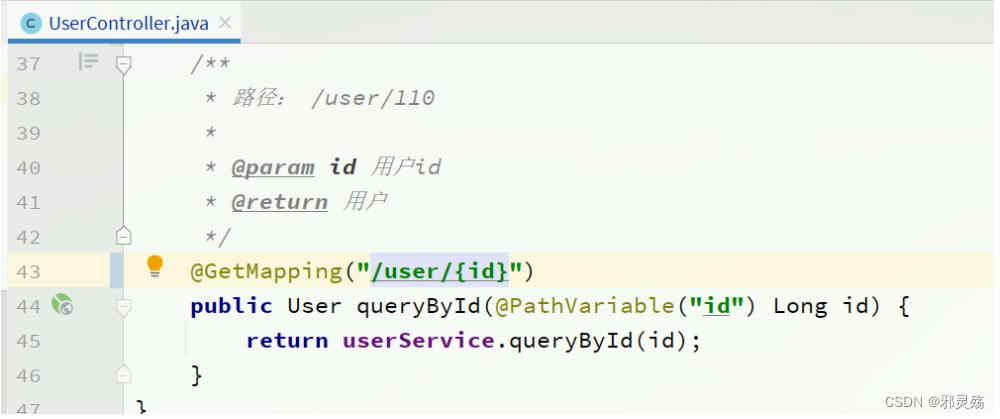
自习观察可以发现,Feign的客户端与服务提供者的controller代码非常相似:
-
feign客户端:
-
提供端UserController:
-
我们发现两个非常相似,有没有一种办法简化这种重复的代码编写呢?
继承方式
一样的代码可以通过继承来共享:
1)定义一个API接口,利用定义方法,并基于SpringMVC注解做声明。
2)Feign客户端和Controller都集成改接口
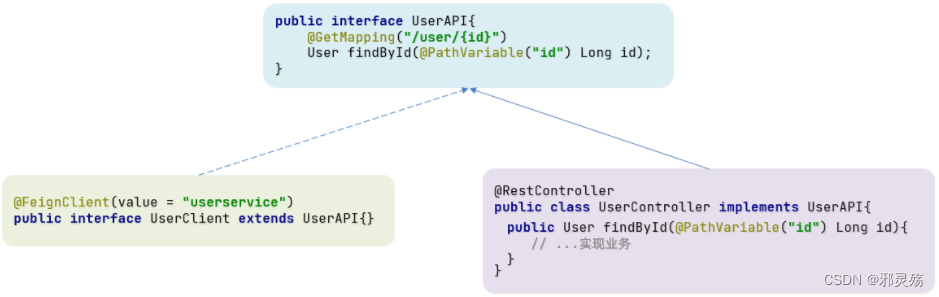
优点:
- 简单
- 实现了代码共享
缺点:
- 服务提供方、服务消费方紧耦合,提供方与消费方实现同一接口
- 参数列表中的注解映射并不会继承,springmvc特性,因此Controller中必须再次声明方法、参数列表、注解
抽取方式
将Feign的Client抽取为独立模块,并且把接口有关的POJO、默认的Feign配置都放到这个模块中,提供给所有消费者使用。
例如,将UserClient、User、Feign的默认配置都抽取到一个feign-api包中,所有微服务引用该依赖包,即可直接使用。
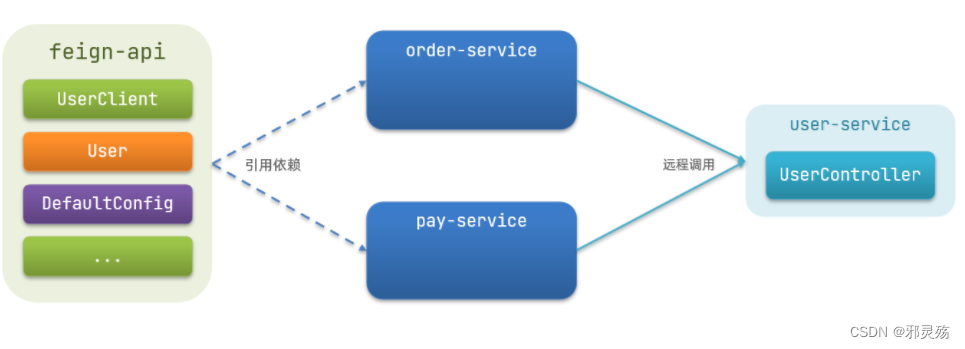
实现基于抽取的最佳实践
抽取
首先创建一个module,命名为feign-api:
项目结构:

在feign-api中然后引入feign的starter依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
然后,order-service中编写的UserClient、User、DefaultFeignConfiguration都复制到feign-api项目中

在消费端服务中使用feign-api
首先,删除order-service中的UserClient、User、DefaultFeignConfiguration等类或接口。
在order-service的pom文件中中引入feign-api的依赖:
<dependency>
<groupId>cn.itcast.demo</groupId>
<artifactId>feign-api</artifactId>
<version>1.0</version>
</dependency>
修改order-service中的所有与上述三个组件有关的导包部分,改成导入feign-api中的包
重启测试
重启后,发现服务报错了:

这是因为UserClient现在在cn.itcast.feign.clients包下,也就是说这个客户端,不在我们当前服务的容器中,虽然能够找到代码,编译没有问题,但是无法注入对象
而order-service的@EnableFeignClients注解是在cn.itcast.order包下,不在同一个包,无法扫描到UserClient。
解决扫描包问题
方式一:
指定Feign应该扫描的包:
@EnableFeignClients(basePackages = "cn.itcast.feign.clients")
方式二:
指定需要加载的Client接口:
@EnableFeignClients(clients = {UserClient.class})
Gateway服务网关
为什么需要网关
Gateway网关是我们服务的守门神,所有微服务的统一入口。
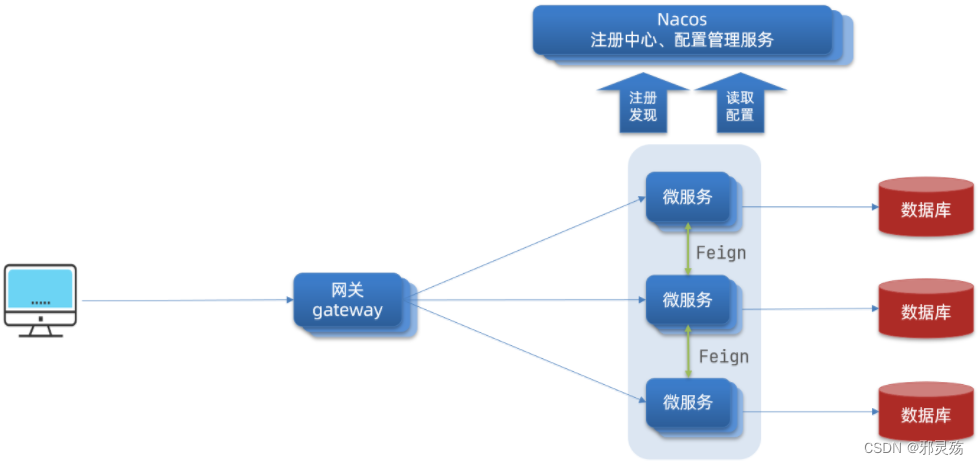
网关的核心功能特性:
- 请求路由和负载均衡:一切请求都必须先经过gateway,但网关不处理业务,而是根据某种规则,把请求转发到某个微服务,这个过程叫做路由。当然路由的目标服务有多个时,还需要做负载均衡。
- 权限控制:网关作为微服务入口,需要校验用户是是否有请求资格,如果没有则进行拦截。
- 限流:当请求流量过高时,在网关中按照下流的微服务能够接受的速度来放行请求,避免服务压力过大。
在SpringCloud中网关的实现包括两种:
- gateway
- zuul
Zuul是基于Servlet的实现,属于阻塞式编程。而SpringCloudGateway则是基于Spring5中提供的WebFlux,属于响应式编程的实现,具备更好的性能。
搭建网关服务
基本步骤
- 创建SpringBoot工程gateway,引入网关依赖
- 编写启动类
- 编写基础配置和路由规则
- 启动网关服务进行测试
创建gateway服务,引入依赖
- 创建服务
网关服务也是一个独立的服务,需要创建一个独立的服务,类似注册中心也是一个独立的服务
- 引入依赖
网关服务需要依赖gateway包,其次,还要将其注册进注册中心以及网关服务也需要到注册中心拉取服务,因此还需要nacos依赖包或eureka注册中心包
<!--网关--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency> <!--nacos服务发现依赖--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency>
编写启动类
此服务仅仅是网关服务,一般只通过配置实现公共,因此启动类一般不需要额外代码,普通的springboot启动类即可
@SpringBootApplication
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}
编写基础配置和路由规则
server:
port: 10010 # 网关端口,服务端口
spring:
application:
name: gateway # 服务名称
cloud:
nacos:
server-addr: localhost:8848 # nacos地址
gateway:
routes: # 网关路由配置
- id: user-service # 路由id,自定义,只要唯一即可
# uri: http://127.0.0.1:8081 # 路由的目标地址 http就是固定地址
uri: lb://userservice # 路由的目标地址 lb就是负载均衡,后面跟服务名称
predicates: # 路由断言,也就是判断请求是否符合路由规则的条件
- Path=/user/** # 这个是按照路径匹配,只要以/user/开头就符合要求
- id: order-service
# 路由地址可以写死,也可以写服务名,lb就是loadBanlence,
uri: lb://orderservice
predicates:
# 只有是/order开头的请求才进行路由到这个路由服务里面去
- Path=/order/**
我们将符合
Path规则的一切请求,都代理到uri参数指定的地址。
本例中,我们将/user/**开头的请求,代理到lb://userservice,lb是负载均衡,根据服务名拉取服务列表,实现负载均衡。
重启测试
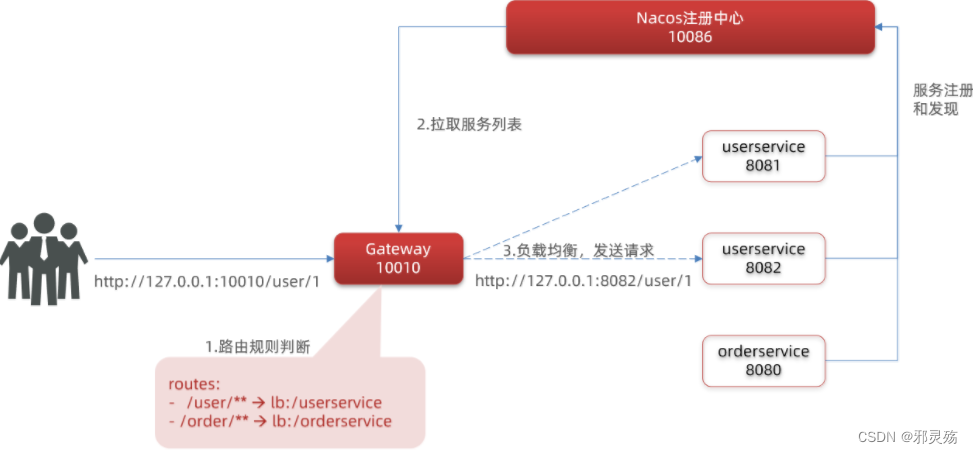
注意:此时我们再要请求user服务或order服务,不在请求具体的服务,请求网关服务,如浏览器输入http://localhost:10010/user/1,就会请求到网关,然后按照请求路径匹配路由规则,路由到具体的服务中,请求具体的接口进行响应
重启网关,访问http://localhost:10010/user/1时,符合/user/**规则,请求转发到uri:http://userservice/user/1,得到了结果:
网关路由的流程图
总结
网关搭建步骤:
- 创建项目,引入nacos服务发现和gateway依赖
- 配置application.yml,包括服务基本信息、nacos地址、路由
路由配置包括:
- 路由id:路由的唯一标示
- 路由目标(uri):路由的目标地址,http代表固定地址,lb代表根据服务名负载均衡
- 路由断言(predicates):判断路由的规则,
- 路由过滤器(filters):对请求或响应做处理
断言工厂
我们在配置文件中写的断言规则只是字符串,这些字符串会被Predicate Factory读取并处理,转变为路由判断的条件
例如Path=/user/**是按照路径匹配,这个规则是由
org.springframework.cloud.gateway.handler.predicate.PathRoutePredicateFactory类来
处理的,像这样的断言工厂在SpringCloudGateway还有十几个:
| 名称 | 说明 | 示例 |
|---|---|---|
| After | 是某个时间点后的请求 | - After=2037-01-20T17:42:47.789-07:00[America/Denver] |
| Before | 是某个时间点之前的请求 | - Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai] |
| Between | 是某两个时间点之前的请求 | - Between=2037-01-20T17:42:47.789-07:00[America/Denver], 2037-01-21T17:42:47.789-07:00[America/Denver] |
| Cookie | 请求必须包含某些cookie | - Cookie=chocolate, ch.p |
| Header | 请求必须包含某些header | - Header=X-Request-Id, \d+ |
| Host | 请求必须是访问某个host(域名) | - Host=.somehost.org,.anotherhost.org |
| Method | 请求方式必须是指定方式 | - Method=GET,POST |
| Path | 请求路径必须符合指定规则 | - Path=/red/{segment},/blue/** |
| Query | 请求参数必须包含指定参数 | - Query=name, Jack或者- Query=name |
| RemoteAddr | 请求者的ip必须是指定范围 | - RemoteAddr=192.168.1.1/24 |
| Weight | 权重处理 |
我们只需要掌握Path这种路由工程就可以了。如果有其它特殊需求,可以查看官方文档实例进行配置,需要注意的是,如果有多个断言条件,需要都满足才会路由到对应服务中去
过滤器工厂
GatewayFilter是网关中提供的一种过滤器,可以对进入网关的请求和微服务返回的响应做处理:
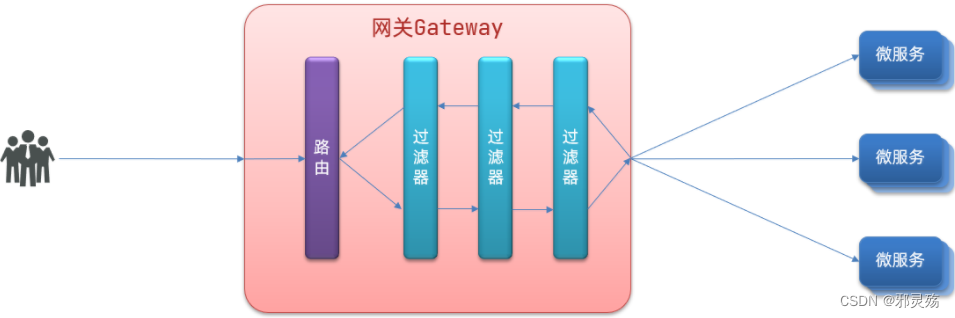
路由过滤器的种类
Spring提供了31种不同的路由过滤器工厂。例如:
| 名称 | 说明 |
|---|---|
| AddRequestHeader | 给当前请求添加一个请求头 |
| RemoveRequestHeader | 移除请求中的一个请求头 |
| AddResponseHeader | 给响应结果中添加一个响应头 |
| RemoveResponseHeader | 从响应结果中移除有一个响应头 |
| RequestRateLimiter | 限制请求的流量 |
请求头过滤器
下面我们以AddRequestHeader 为例来讲解。
需求:给所有进入userservice的请求添加一个请求头:Truth=itcast is freaking awesome!
只需要修改gateway服务的application.yml文件,添加路由过滤即可:
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
filters: # 过滤器
- AddRequestHeader=Truth, Itcast is freaking awesome! # 添加请求头
当前过滤器写在userservice路由下,因此仅仅对访问userservice的请求有效。
默认过滤器
如果要对所有的路由都生效,则可以将过滤器工厂写到default下。格式如下:
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
default-filters: # 默认过滤项
- AddRequestHeader=Truth, Itcast is freaking awesome!
总结
过滤器的作用是什么?
① 对路由的请求或响应做加工处理,比如添加请求头
② 配置在路由下的过滤器只对当前路由的请求生效
defaultFilters的作用是什么?
① 对所有路由都生效的过滤器
全局过滤器
上一节学习的过滤器,网关提供了31种,但每一种过滤器的作用都是固定的。如果我们希望拦截请求,做自己的业务逻辑则没办法实现。比如我们要判断请求是否登录状态或者判断某个token认证是否添加等自定义逻辑
全局过滤器作用
全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewayFilter的默认全局过滤器作用一样。区别在于GatewayFilter通过配置定义,处理逻辑是固定的;而GlobalFilter的逻辑需要自己写代码实现。
定义方式是实现GlobalFilter接口。
public interface GlobalFilter {
/**
* 处理当前请求,有必要的话通过{@link GatewayFilterChain}将请求交给下一个过滤器处理
*
* @param exchange 请求上下文,里面可以获取Request、Response等信息
* @param chain 用来把请求委托给下一个过滤器
* @return {@code Mono<Void>} 返回标示当前过滤器业务结束
*/
Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain);
}
在filter中编写自定义逻辑,可以实现下列功能:
- 登录状态判断
- 权限校验
- 请求限流等
自定义全局过滤器
需求:定义全局过滤器,拦截请求,判断请求的参数是否满足下面条件:
- 参数中是否有authorization,
- authorization参数值是否为admin
如果同时满足则放行,否则拦截
实现:
在gateway中定义一个过滤器:
package cn.itcast.gateway.filters;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.annotation.Order;
import org.springframework.http.HttpStatus;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
@Order(-1)
@Component
public class AuthorizeFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 1.获取请求参数
MultiValueMap<String, String> params = exchange.getRequest().getQueryParams();
// 2.获取authorization参数,需要逻辑处理的数据,自定义请求参数
String auth = params.getFirst("authorization");
// 3.校验,逻辑处理
if ("admin".equals(auth)) {
// 放行,逻辑成立,chain指过滤器链,filter就是放行,将整个请求响应对象作为参数
return chain.filter(exchange);
}
// 4.拦截
// 4.1.禁止访问,设置状态码,状态码不能设置int404或字符串,这里是枚举值
exchange.getResponse().setStatusCode(HttpStatus.FORBIDDEN);
// 4.2.结束处理,setComplete就是结束处理的意思
return exchange.getResponse().setComplete();
}
}
注意:
- 这里定义好过滤器类之后,加上
@Component注解,表示让Spring容器管理 - 再加上
@Order注解或者实现Order接口,写上排序参数,表示过滤器生效的顺序,因为我们可能会定义多个过滤器,值越小优先级越高
过滤器执行顺序
请求进入网关会碰到三类过滤器:当前路由的过滤器、DefaultFilter、GlobalFilter
请求路由后,会将当前路由过滤器和DefaultFilter、GlobalFilter,合并到一个过滤器链(集合)中,排序后依次执行每个过滤器:
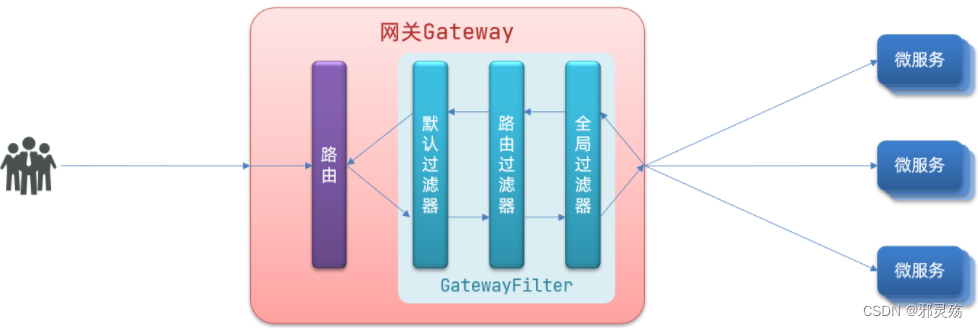
排序的规则是什么呢?
- 每一个过滤器都必须指定一个int类型的order值,order值越小,优先级越高,执行顺序越靠前。
- GlobalFilter通过实现Ordered接口,或者添加@Order注解来指定order值,由我们自己指定
- 路由过滤器和defaultFilter的order由Spring指定,默认是按照声明顺序从1递增。
- 比如当我们在一个路由中定义多个路由过滤器,其顺序就是1、2、3等顺序
- 当我们定义多个全局默认过滤器,其顺序也是1、2、3的顺序
- 也就是说路由过滤器与全局过滤器各自从1递增,自定义过滤器则是我们指定
- 当过滤器的order值一样时,会按照 defaultFilter > 路由过滤器 > GlobalFilter的顺序执行。
详细内容,可以查看源码:
org.springframework.cloud.gateway.route.RouteDefinitionRouteLocator#getFilters()方法是先加载defaultFilters,然后再加载某个route的filters,然后合并。
org.springframework.cloud.gateway.handler.FilteringWebHandler#handle()方法会加载全局过滤器,与前面的过滤器合并后根据order排序,组织过滤器链
跨域问题
什么是跨域问题
跨域:域名不一致就是跨域,主要包括:
- 域名不同: www.taobao.com 和 www.taobao.org 和 www.jd.com 和 miaosha.jd.com
- 域名相同,端口不同:localhost:8080和localhost8081
我们会发现我们微服务之间也是跨域,但是没有问题,这是因为:
跨域问题:是指浏览器禁止请求的发起者与服务端发生跨域ajax请求,请求被浏览器拦截的问题
主要是浏览器的特性决定,而微服务之间访问是没有这个问题的
解决方案:CORS,这个以前应该学习过,这里不再赘述了。不知道的小伙伴可以查看https://www.ruanyifeng.com/blog/2016/04/cors.html
解决跨域问题
在gateway服务的application.yml文件中,添加下面的配置:
spring:
cloud:
gateway:
# 。。。
globalcors: # 全局的跨域处理
add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题,也就是浏览器询问服务这个访问是否可以跨域,这个询问的请求就是指options请求
corsConfigurations:
'[/**]': # 指拦截哪些请求,这里指所有请求都需要拦截处理
allowedOrigins: # 允许哪些网站的跨域请求
- "http://localhost:8090"
allowedMethods: # 允许的跨域ajax的请求方式
- "GET"
- "POST"
- "DELETE"
- "PUT"
- "OPTIONS"
allowedHeaders: "*" # 允许在请求中携带的头信息
allowCredentials: true # 是否允许携带cookie
maxAge: 360000 # 这次跨域检测的有效期,也就是前面的options询问请求,在一定的时间内不再进行询问,否则服务器压力会比较大
Docker
在软件开发中,一个软件从开发到上线往往要经过几个阶段,比如开发、测试、部署等
而软件都需要自己的运行环境,而在经历每个阶段时可能环境不同导致项目出现问题,比如
开发环境是JDK8的环境,开发测试没有问题,而到了测试环境变成JDK7等,项目运行可能会报错
而为了避免这种问题,我们可以在项目打包时将代码和环境一同打包,这样能保证环境一致
而对于这种环境不一导致的代码问题,我们也称为项目水土不服,解决方案就是将代码和环境一同打包
而将代码和环境等项目依赖放置在一起,我们就称为容器,Docker就是一种容器引擎
Docker基础
概念
- Docker是一个开源的应用容器引擎
- 诞生于2013年初,基于GO语言实现,dotCloud公司出品(后改名为Docker Inc)
- Docker可以让开发者打包他们的应用以及应用依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的Linux机器上
- 容器是完全使用沙箱机制,相互隔离的,也就是一台机器可以有多个容器,互不干扰
- 容器性能开销极低
- Docker从17.03版本之后分为CE(Community Edition:社区版,免费)和EE(Enterprise Edition:企业版,收费)
- 总结:docker是一种容器技术,解决软件跨环境迁移的问题
安装
- Docker官方网站:https://www.docker.com
- Docker可以运行在MAC、Windows、Centos、UBUNTU等操作系统上
- 下面我们在Centos7系统安装Docker
# 1、yum包更新到最新 yum update # 2、安装需要的软件包,yum-util提供yum-config-manager功能,另外两个是devicemapper驱动依赖 yum install -y yum-utils device-mapper-persistent-data lvm2 # 3、设置yum源 yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo # 4、安装Docker,出现输入界面都按Y yum install -y docker-ce # 5、查看Docker版本,验证是否安装成功 docker -v
Docker架构
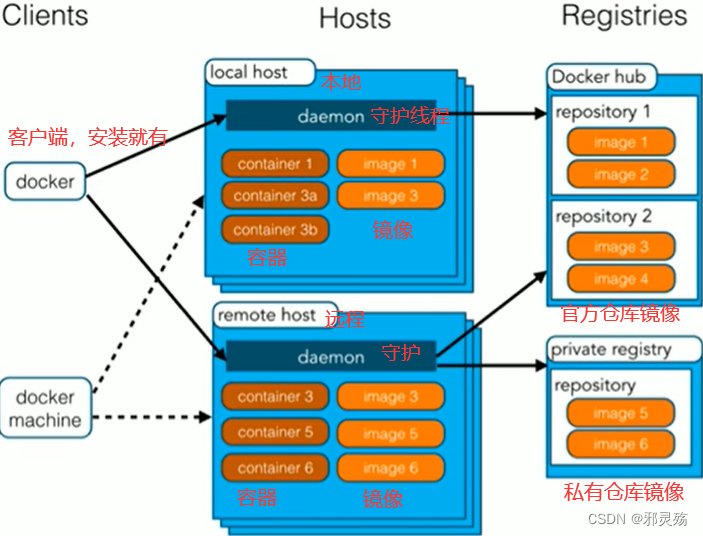
- 镜像(Image):Docker镜像(Image),就相当于是一个root文件系统。比如Centos7镜像文件就包含了一套centos7最小系统的root文件系统
- 容器(Container):镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的类和对象一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等
- 仓库:仓库可以看成一个代码控制中心,用来保存镜像。我们要使用镜像时可以从远处仓库(官方仓库或私服,类似maven仓库)中拉取到本地
配置Docker镜像加速器
默认情况下,我们从docker hub(https://hub.docker.com/)上下载Docker镜像,速度太慢,一般都会配置镜像加速器
常用国内镜像加速器有:
- USTC:中科大镜像加速器(https://docker.mirrors.ustc.edu.cn)
- 阿里云
- 网易云
- 腾讯云
下面我们配置阿里云镜像加速器,网易云、腾讯云都一样,中科大有些不同
- 第一步:登录阿里云官方账号,进入官网首页
- 第二步:登录后再首页右上角找到控制台模块,点击进入
- 第三步:进入控制台后点击左上角菜单图标,点击展开产品与服务,搜索镜像等关键字
- 第四步:在搜索结果中点击容器镜像服务,进入只有左侧菜单中找到镜像加速器,点击进入
- 第五步:进入后找到对应系统的操作文档,直接复制其提供的完整命令在系统运行即可
需要注意的是,如果要配置中科大镜像,则修改上面阿里云中配置文件中的地址即可
Docker命令
Docker服务相关的命令
- 启动Docker服务
systemctl start docker - 停止Docker服务
systemctl sotp docker - 重启Docker服务
systemctl restart docker - 查看Docker服务状态
systemctl status docker - 设置开机自启动docker服务
systemctl enable docker
Docker镜像相关的命令(Image)
-
查看本地镜像列表
docker images
-
搜索远程镜像
# docker search 镜像名 docker search redis # 搜索redis镜像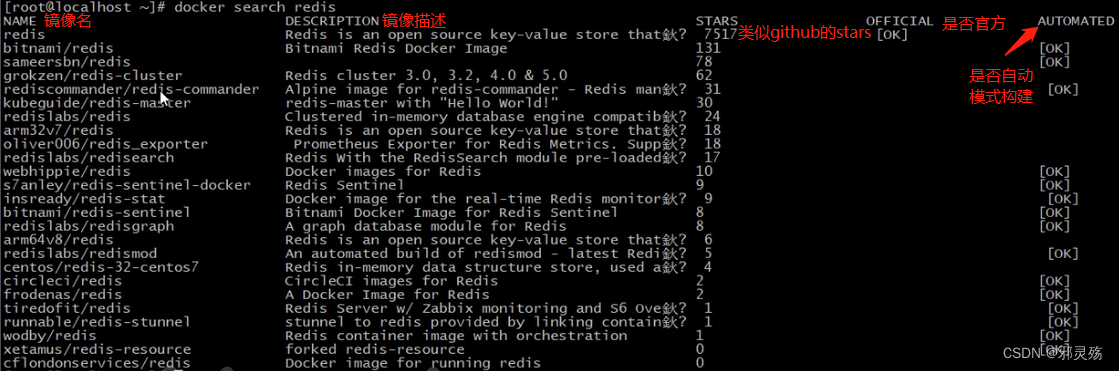
-
下载远程镜像
# docker pull 镜像名[:版本] docker pull redis # 不指定版本,下载最新版本 docker pull redis:3.2 # 下载指定3.2版本redis镜像如果想查看某个镜像有哪些具体版本,可以在官网http://hub.docker.com/搜索对应镜像查看
-
删除本地镜像
# rmi是remove和image,就是删除镜像,后面是镜像的唯一标识号 docker rmi 镜像id docker rmi de25a81a5a0b # 删除id为de25a81a5a0b的镜像 # 也可以根据镜像名和版本删除 docker rmi redis:3.2 # 查看本地所有镜像id值 docker images -q # 根据上面查询的id集删除所有本地镜像 docker rmi `docker images -q`
Docker容器相关的命令(container)
- 查看容器
- 查看正在运行的容器
docker ps # 只查看正在运行的容器,未运行的不显示 - 查看所有容器
docker ps -a # 查看所有容器,包括未运行的(状态exit) 正在运行的(状态up)
- 查看正在运行的容器
- 创建并启动容器
docker run 参数 镜像 进入容器的命令- 参数说明:
-i:保持容器运行,通常与-t同时使用,加入-it这两个参数后,容器创建后自动进入容器中,退出容器,容器自动关闭-t:为容器重新分配一个伪终端,通常与-i同时使用-d:以守护(后台运行)模式运行容器,创建一个容器在后台运行,需要使用命令docker exec进入容器,退出后,容器不会关闭-it:组合参数,创建的容器一般称为交互式容器-id:组合参数,创建的容器一般称为守护式容器--name:为创建的容器命名
- 镜像说明
- 一般就是需要以哪个镜像文件创建容器
- 语法
镜像名:版本,比如docker run -id centos:7
- 进入容器的命令
- 一般有默认的,也可以自己写
- 比如使用centos7创建的容器默认的进入命令就是
/bin/bash - 在进入容器时后面跟上,比如
docker exec /bin/bash
- 参数说明:
- 进入容器
# docker exec 进入容器的命令 docker exec /bin/bash - 退出容器
exit - 启动容器
# docker start 容器名 docker start c1 - 停止容器
# docker stop 容器名 docker stop c1 - 删除容器
- 根据容器名或容器id删除指定容器
# docker rm 容器名/容器id docker rm c1 # 根据容器名删除对应容器 docker rm 70e34795df15 # 根据容器id删除容器 - 根据组合命令删除所有容器
需要注意的是开启的容器是不能删除的# 查看所有容器id docker ps -aq docker rm `docker ps -aq` # 删除所有容器
- 根据容器名或容器id删除指定容器
- 查看容器信息
# docker inspect 容器名 docker inspect c1
Docker容器数据卷
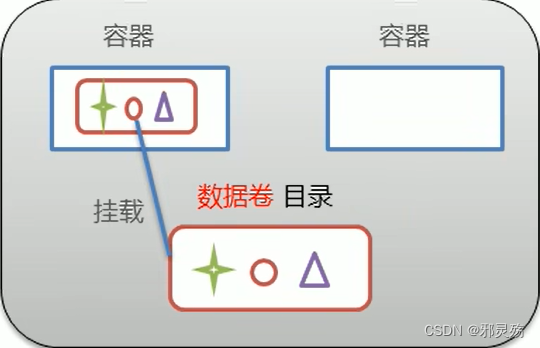
数据卷的概念及作用
-
概念
- 思考:
- Docker容器删除后,在容器中产生的数据会随之销毁?
- Docker容器和外部机器可以直接交换文件吗?
- 容器之间想要进行数据交互?
- 数据卷:
- 数据卷就是宿主机中的一个目录或文件,宿主机就是Docker所在的机器
- 当容器目录和数据卷目录绑定之后,不管哪一方的修改都会立即同步
- 一个数据卷可以被多个容器同时挂载
- 一个容器也可以被挂载多个数据卷
- 思考:
-
作用
- 容器数据持久化
- 外部机器和容器间接通信
- 容器之间交换数据
配置数据卷
- 创建容器时,使用-v参数,设置数据卷
# 基本语法 docker run ... -v 宿主机目录:容器内目录(文件) - 注意事项
- 目录(宿主机目录和容器内目录)必须是绝对路径
- 如果目录不存在,会自动创建(宿主机目录或容器内目录)
- 可以挂载多个数据卷
- 示例:
# 基于centos7创建容器并挂载一个数据卷 docker run -it --name=c1 -v /root/data:/root/data_contain centos:7 # 基于centos7创建容器并挂载多个数据卷 docker run -it --name=c2 -v /root/data01:/root/data01 -v /root/data02:/root/data02 centos:7 # 可以将同一数据卷挂载到不同容器实现容器之间数据共享交互
配置数据卷容器
-
数据卷容器
多容器进行数据交换- 多个容器挂载同一数据卷,就是我们前面看到的方式,但是如果容器较多,需要依次挂载同一数据卷,比较麻烦也容器出错
- 数据卷容器,我们可以创建一个容器,先挂载我们的数据卷,然后其他容器挂载当前容器即可,当前容器就称为数据卷容器,数据卷容器与其他容器并没有本质上的区别
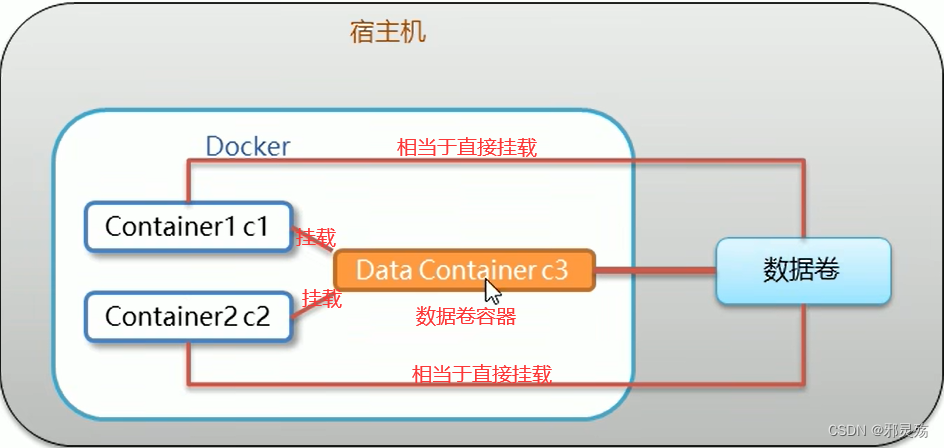
-
配置数据卷容器
- 创建启动一个数据卷容器,使用
-v参数设置数据卷,需要注意,此处不需要指定宿主机目录,docker会自动创建# 基于centos7镜像创建一个数据卷容器 docker run -it --name=c3 -v /volume centos:7 /bin/bash - 创建启动两个普通容器,使用
--volumes-from参数,设置绑定数据卷容器docker run -it --name=c1 --volumes-from c3 centos:7 /bin/bash docker run -it --name=c2 --volumes-from c3 centos:7 - 需要注意的是,当容器挂载到数据卷容器后,在物理上,普通容器也挂载到了数据卷容器挂载的宿主机目录(数据卷)上,此时即便数据卷容器停止或被删除,不会影响其他容器,也不会影响数据卷
- 创建启动一个数据卷容器,使用
Docker应用部署
MySQL部署
- 需求
- 在Docker容器中部署MySQL,并通过外部mysql客户端操作MySQL服务
- 存在的问题,外部机器可以直接访问宿主机,宿主机可以直接访问容器,外部机器无法直接访问容器
- 实现步骤
- 搜索mysql镜像文件
- 拉取远程mysql镜像文件到docker服务
- 基于拉取的mysql镜像创建容器
- 在外部机器上通过mysql客户端操作容器中的mysql服务
- 分析问题:
- 容器内的网络服务和外部机器不能直接通信
- 外部机器和宿主机可以直接通信
- 宿主机和容器可以直接通信
- 当容器中的网络服务需要被外部机器访问时,可以将容器中提供服务的端口映射到宿主机的端口上。外部机器访问宿主机的该端口,从而间接访问容器的服务
- 这种操作称为:端口映射
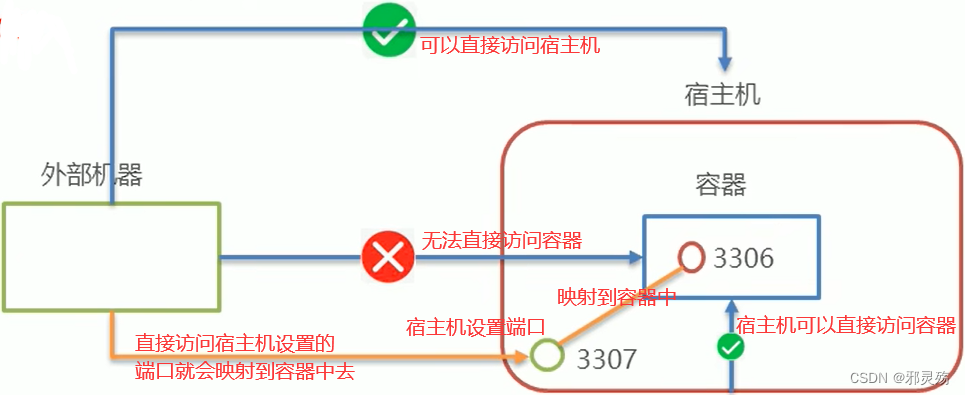
- 命令实现
- 搜索mysql镜像
docker search mysql - 拉取mysql镜像
docker pull mysql:5.6 - 创建容器,设置端口映射、目录映射
# 在/root目录下创建mysql目录用于存储mysql数据信息 mkdir /root/mysql cd /root/mysql - 创建容器并映射端口挂载数据卷
# 3307为宿主机映射端口,3306为容器mysql服务端口,后面的\表示命令没有结束,继续下一行 docker run -id -p 3307:3306 \ --name=c_mysql \ -v $PWD/conf:/etc/mysql/conf.d \ -v $PWD/logs:/logs \ -v $PWD/data:/var/lib/mysql \ -e MYSQL_ROOT_PASSWORD=123456 \ mysql:5.6 - 参数说明:
-p 3307:3306:将容器的3306端口映射到宿主机的3307端口。当然,一般宿主机映射端口与容器端口一致,也方便记忆,这里是方便理解映射-v $PWD/logs:/logs:将主机当前目录下的logs目录挂载到容器的/logs。日志目录。$PWD就是指当前命令所在的目录-v $PWD/conf:/etc/mysql/conf.d:将主机当前目录下的conf/my.cnf挂载到容器的/etc/mysql/my.cnf.配置目录-v $PWD/data:/var/lib/mysql:将主机当前目录下的data目录挂载到容器的/var/lib/mysql。数据目录-e MYSQL_ROOT_PASSWORD=123456:初始化root用户的密码
- 进入容器
docker exec -it c_mysql /bin/bash
- 搜索mysql镜像
Tomcat部署
- 需求
- 在Docker容器中部署Tomcat,并通过外部机器访问Tomcat部署项目
- 步骤
- 搜索tomcat镜像文件
- 拉取tomcat镜像文件
- 基于tomcat创建容器
- 外部机器部署项目
- 测试访问
- 实现
- 搜索tomcat镜像
docker search tomcat - 拉取tomcat镜像
docker pull tomcat - 创建容器,设置端口映射、目录映射
# 在/root目录下创建tomcat目录用于存储tomcat数据,并进入目录 mkdir ~/tomcat cd ~/tomcat # 创建容器 docker run -id --name=c_tomcat \ -p 8080:8080 \ -v $PWD:/usr/local/tomcat/webapps \ tomcat - 参数说明
-p 8080:8080:将容器的8080端口映射到主机的8080端口-v $PWD:/usr/local/tomcat/webapps:将主机当前目录挂载到容器的webapps
- 将项目部署到宿主机tomcat目录(数据卷)中,在外部机中访问项目
- 搜索tomcat镜像
Nginx部署
- 需求
- 在Docker容器中部署Nginx,并通过外部机器访问Nginx
- 步骤
- 搜索Nginx镜像
- 拉取Nginx镜像
- 创建容器
- 测试访问
- 实现
- 搜索nginx镜像
docker search nginx - 拉取nginx镜像
docker pull nginx - 创建容器,设置端口映射、目录映射
# 在/root目录下创建nginx目录用于存储nginx数据信息 mkdir ~/nginx cd ~/nginx mkdir conf cd conf # 在~/nginx/conf/下创建nginx.conf文件,粘贴下面内容 vim nginx.confuser nginx; worker_processes 1; error_log /var/log/nginx/error.log warn; pid /var/run/nginx.pid; events { worker_connections 1024; } http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user [$time_local] "$request" ' ' $status $body_bytes_sent "$http_referer" ' ' "$http_user_agent" "$http_x_forwarded_for" '; access_log /var/log/nginx/access.log main; sendfile on; #tcp_nopush on; keepalive_timeout 65; #gzip on; include /etc/nginx/conf.d/*.conf; }docker run -id --name=c_nginx \ -p 80:80 \ -v $PWD/conf/nginx.conf:/etc/nginx/nginx.conf \ -v $PWD/logs:/var/log/nginx \ -v $PWD/html:/usr/share/nginx/html \ nginx - 参数说明:
-p 80:80:将容器的80端口映射到宿主机的80端口-v $PWD/conf/nginx.conf:/etc/nginx/nginx.conf:将主机当前目录下的/conf/nginx.conf挂载到容器的/etc/nginx/nginx.conf。配置目录-v $PWD/logs:/var/log/nginx:将主机当前目录下的logs目录挂载到容器的/var/log/nginx。日志目录
- 搜索nginx镜像
- 使用外部机器访问nginx
Redis部署
- 需求
- 在Docker容器中部署Redis,并通过外部机器访问Redis。
- 步骤
- 搜索Redis镜像
- 拉取Redis镜像
- 创建容器
- 测试访问
- 实现
- 搜索redis镜像
docker search redis - 拉取redis镜像
docker pull redis:5.0 - 创建容器,设置端口映射
docker run -id --name=c_redis -p 6379:6379 redis:5.0 - 使用外部机器连接redis
# IP为宿主机IP ./redis-cli.exe -h 192.168.149.135 -p 6379
- 搜索redis镜像
Dockerfile
Docker镜像原理
- 思考
- Docker镜像本质是什么?
- Docker中一个centos镜像为什么只有200MB,而一个centos操作系统的iso文件要几个G?
- Docker中一个tomcat镜像为什么要500MB,而一个tomcat安装包只有70MB?
- 操作系统组成
-
进程调度子系统
-
进程通信子系统
-
内存管理子系统
-
设备管理子系统
-
文件管理子系统
-
网络通信子系统
-
作业控制子系统
Linux文件系统由bootfs和rootfs两部分组成:
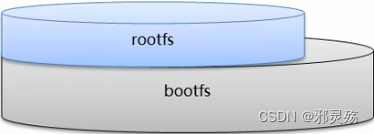
- bootfs:包含bootloader(引导加载程序)和kernel(内核)
- rootfs:root文件系统,包含的就是典型Linux系统中的/dev、/proc、/bin、/etc等标准目录和文件
-
- 原理
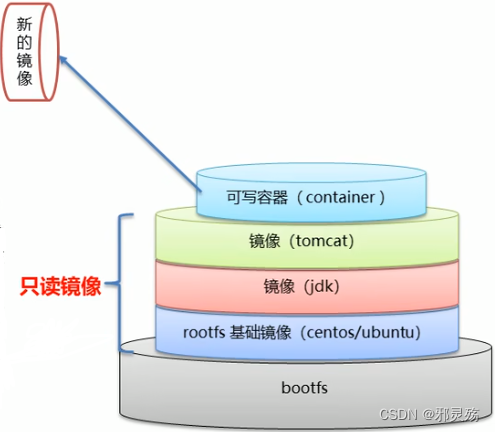
- Docker镜像是由特殊的文件系统叠加而成
- 最底层是bootfs,并使用宿主机的bootfs
- 第二层是root文件系统rootfs,称为base image
- 然后再往上可以叠加其他的镜像文件
- 统一文件系统(Union File System)技术能够将不同的层整合成一个文件系统,为这些层提供一个统一的视角,这样就隐藏了多层的存在,在用户看来,只存在一个文件系统
- 比如我们加载tomcat镜像,可能里面包含了rootfs基础镜像、jdk镜像,tomcat镜像,而我们看到的只有tomcat镜像,因此显示有700MB,而如果我们再加载redis镜像,就可以共享rootfs镜像与jdk镜像
- 一个镜像可以放在另一个镜像的上面。位于下面的镜像称为父镜像,最底层的镜像称为基础镜像
- 所谓的只读镜像,就是我们不能修改这些镜像文件,因为还有其他镜像文件使用
- 而我们要修改只能在一个镜像启动容器时,Docker会在最顶层加载一个读写文件系统作为容器,我们可以修改这个容器来形成新的镜像,达到我们修改的目的
- 回答思考:
- Docker镜像本质时什么?
- 是一个分层文件系统
- Docker中一个centos镜像为什么只有200MB,而一个centos操作系统ISO文件要几个G?
- Centos的ISO镜像文件包含bootfs和rootfs,而docker的centos镜像复用操作系统的bootfs,只有rootfs和其他镜像层
- Docker中一个tomcat镜像为什么又500MB,而一个tomcat安装包只有70MB?
- 由于docker中镜像是分层的,tomcat虽然只有70多MB,但他需要依赖于父镜像和基础镜像,所有整个对外暴露的tomcat镜像大小500多MB
- Docker镜像本质时什么?
- 镜像制作
- 方式一:容器转为镜像
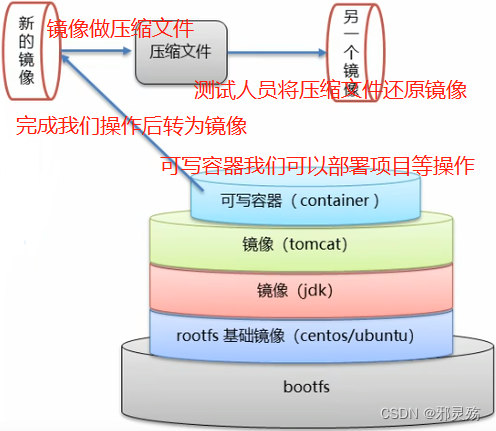
- 先将容器转为镜像
# 语法如下,如果不写版本,制作的镜像默认最新版本 docker commit 容器id 镜像名称:版本号 # 示例 docker commit 85d56sd5sdf my_tomcat:1.0 - 再将镜像制作压缩文件
# 语法如下 docker save -o 压缩文件名称 镜像名称:版本号 # 示例 docker save -o my_tomcat.tar my_tomcat:1.0 - 将压缩文件还原为镜像
# 语法如下 docker load -i 压缩文件名称 # 示例 docker load -i my_tomcat.tar - 注意:这种方式处理时,容器内部创建的文件等操作都会在转为镜像时带过去,但是挂载的数据卷会丢失
- 因此这种方式不怎么使用,多用dockerfile的方式
- 先将容器转为镜像
- 方式二:dockerfile
- 方式一:容器转为镜像
Dockerfile概念及作用
- Dockerfile是一个文本文件
- 包含了一条条的指令
- 每一条指令构建一层,基于基础镜像,最终构建出一个新的镜像
- 对于开发人员:可以为开发团队提供一个完全一致的开发环境
- 对于测试人员:可以直接拿开发时构建的镜像或者通过Dockerfile文件构建一个新的镜像开始工作
- 对于运维人员:在部署时,可以实现应用的无缝移植

Dockerfile关键字
| 关键字 | 作用 | 备注 |
|---|---|---|
| FROM | 指定父镜像 | 指定dockerfile基于那个image构建 |
| MAINTAINER | 作者信息 | 用来标注这个dockerfile谁写的 |
| LABEL | 标签 | 用来标明dockerfile的标签,可以使用Label代替Maintainer最终都是在docker image基本信息中可以查看 |
| RUN | 创建容器时执行的命令 | 执行一段命令,默认是/bin/sh格式:RUN command或者RUN[“command”,“param1”,“param2”] |
| CMD | 容器启动命令 | 提供启动容器时候的默认命令和ENTRYPOINT配合使用,格式CMD command param1 param2或者CMD[“command”,“param1”,“param2”] |
| ENTRYPOINT | 入口 | 一般在制作一些执行就关闭的容器中会使用 |
| COPY | 复制文件 | build的时候复制文件到image中 |
| ADD | 添加文件 | build的时候添加文件到image中,不仅仅局限于当前build上下文,可以来源与远程服务 |
| ENV | 环境变量 | 指定build时候的环境变量,可以在启动容器的时候,通过-e覆盖,格式ENV name=value |
| ARG | 构建参数 | 构建参数,只在构建的时候使用的参数,如果有ENV那么ENV的相同名字的值使用覆盖arg的参数 |
| VOLUME | 定义外部可以挂载的数据卷 | 指定build的image哪些目录可以启动的时候挂载到文件系统中,启动容器的时候使用-v绑定,格式VOLUME[“目录”] |
| EXPOSE | 暴露端口 | 定义容器运行的时候监听的端口,启动容器的时候使用-p来绑定暴露端口,格式:EXPOSE 8080或者EXPOSE 8080/udp |
| WORKDIR | 工作目录 | 指定容器内部的工作目录,如果没有创建则自动创建,如果指定 / 使用的是觉得地址,如果不是 / 开头那么是在上一条workdir的路径的相对路径 |
| USER | 指定执行用户 | 指定build或者启动的时候,用户在RUN CMD ENTRYPONT指定的时候的用户 |
| HEALTHCHECK | 健康检查 | 指定检测当前容器的健康检测的命令,基本上没用,因为很多时候,应用本身有健康监测机制 |
| ONBUILD | 触发器 | 当存在ONBUILD关键字的镜像作为基础镜像的时候,当执行FROM完成之后,会执行ONBUILD的命令,但是不影响当前镜像,用处也不怎么大 |
| STOPSIGNAL | 发送信号量到宿主机 | 该STOPSIGNAL指令设置将发送到容器的系统调用信号以退出 |
| SHELL | 指定执行脚本的shell | 指定RUN CMD ENTRYPOINT执行命令的时候,使用shell |
案例
部署springboot项目
- 需求
- 定义dockerfile,发布springboot项目
- 步骤
- 定义父镜像:FROM java:8
- 定义作者信息:MAINTAINER wzfwzf@168.com
- 将springbootjar包添加到容器:ADD springboot.jar app.jar // 后面的app.jar就是在容器中的名字
- 定义容器启动执行的命令:CMD java -jar app.jar
- 通过dockerfile构建镜像:
docker build -f dockerfile文件路径 -t 镜像名称:版本
Docker服务编排
微服务架构的应用系统中一般包含若干个微服务,每个微服务一般都会部署多个实例,如果每个微服务都要手动启停,维护工作量会很大,比如每个微服务都需要:
- 要从Dockerfile build image或者去dockerhub拉取image
- 要创建多个container(容器)
- 要管理这些container(启动停止删除)
**服务编排:**按照一定的业务规则批量管理容器
Docker Compose
概念
Docker Compose是一个编排多容器分布式部署的工具,提供命令集管理容器化应用的完整开发周期,包括服务构建,启动和停止。使用步骤:
- 利用Dockerfile定义运行环境镜像
- 使用docker-compose.yml定义组成应用的各服务
- 运行docker-compose up启动应用
安装和使用
- 安装Docker Compose
# Compose目前已经完全支持Linux、Mac OS和Windows,在我们安装Compose之前,需要先安装Docker。 # 下面我们以编译好的二进制包方式安装在Linux系统中 curl -L https://github.com/docker/compose/releases/download/1.22.0/docker-compose-`uname -s`-`uname -m` -o /use/local/bin/docker-compose # 设置文件可执行权限 chmod +x /usr/local/bin/docker-compose # 安装完成,查看版本信息 docker-compose -version - 卸载Docker Compose
# 二进制包方式安装的,删除二进制文件即可 rm /usr/local/bin/docker-compose - 使用docker compose编排nginx + springboot项目
- 创建docker-compose目录
mkdir ~/docker-compose cd ~/docker-compose - 编写docker-compose.yml文件
version: '3' services: nginx: image: nginx # 端口映射 ports: - 80:80 # links: -app volumes: - ./nginx/conf.d:/etc/nginx/conf.d app: image: app expose: - "8080" - 创建
./nginx/conf.d目录mkdir -p ./nginx/conf.d - 在
./nginx/conf.d目录下创建nginx配置文件,文件名自定义,后缀一致即可# 主要就是代理app那个springboot服务 server { listen 80; access_log off; location / { proxy_pass http://app:8080; } } - 在
~/docker-compose目录下,使用docker-compose启动容器# 前台启动 docker-compose up # 后台启动,类似守护线程方式启动 docker-compose up -d - 测试访问
http://192.168.0.200/
- 创建docker-compose目录
Docker私有仓库
- Docker官方的Docker hub(https://hub.docker.com)是一个用于管理公共镜像的仓库,我们可以从上面拉取镜像到本地,也可以把我们自己的镜像推送上去
- 但是有时候我们的服务器无法访问互联网,或者不希望将自己的镜像放到公网中,那么我们就需要搭建自己的私有仓库来存储和管理自己的镜像
- 需要注意,下面用到的私有仓库服务器IP,不能用localhost等,就写实际IP即可
搭建私有仓库
# 1、拉取私有仓库镜像
docker pull registry
# 2、启动私有仓库容器
docker run -id --name=registry -p 5000:5000 registry
# 3、打开浏览器,输入地址http://私有仓库服务器IP:5000/v2/_catalog,看到{"repositories":[]}表示私有仓库搭建成功
# 4、修改daemon.json,之前添加阿里云加速器的文件
vim /etc/docker/daemon.json
# 在上述文件中添加一个key,保存退出。此步骤用于让docker信任私有仓库地址;注意将私有仓库服务器IP修改为自己私有仓库服务器真实IP
# 在文件中与之前阿里云加速器的key用逗号隔开,后面添加即可
{"insecure-registries:["私有仓库服务器IP:5000"]}
# 5、重启docker服务
systemctl restart docker
docker start registry
上传镜像到私有仓库
# 1、标记镜像为私有仓库的镜像
docker tag centos:7 私有仓库服务器IP:5000/centos:7
# 2、上传标记的镜像
docker push 私有仓库服务器IP:5000/centos:7
从私有仓库拉取镜像
docker pull 私有仓库服务器IP:5000/centos:7
docker容器与传统虚拟机比较
容器
容器就是将软件打包成标准单元,以用于开发、交付和部署
- 容器镜像是轻量级的、可执行的独立软件包,包含软件运行所需的所有内容:代码、运行时环境、系统工具、系统库和设置
- 容器化软件在任何环境中都能够始终如一的运行
- 容器赋予了软件独立性,使其免受外在环境差异的影响,从而有助于减少团队间在相同基础设施上运行不同软件时的冲突
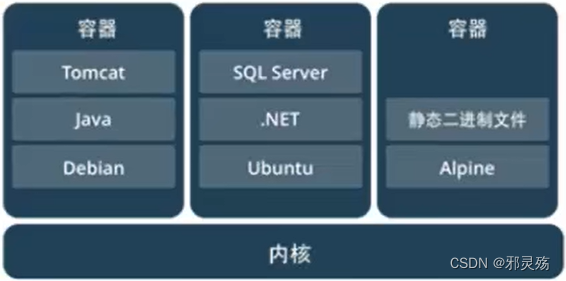
比较

相同:
- 容器和虚拟机具有相似的资源隔离和分配优势
不同:
- 容器虚拟化的是操作系统,虚拟机虚拟的是硬件
- 传统虚拟机可以运行不同的操作系统,只需要分配硬件
- 容器只能运行同一类型操作系统,共享系统内核
| 特性 | 容器 | 虚拟机 |
|---|---|---|
| 启动 | 秒级 | 分钟级 |
| 硬盘使用 | 一般为MB | 一般为GB |
| 性能 | 接近原生 | 弱于原生 |
| 系统支持量 | 单机支持上千个容器 | 一般几十个 |
MQ
同步通讯和异步通讯
概念
- 同步通讯:类似我们通电话,单线联系,时效性高,一旦一方发起,另一方几乎同时就能收到反馈,但是无法多线操作,比如我们通话时有其他人打电话,则提示占线无法接通
- 异步通讯,更像时微信聊天,可以多线操作,一方发起之后可以不用再管,可以接着给其他对象发送信息,同意的,哪方先收到消息我们也无法掌握,时效性相对同步通讯较差
同步调用的问题
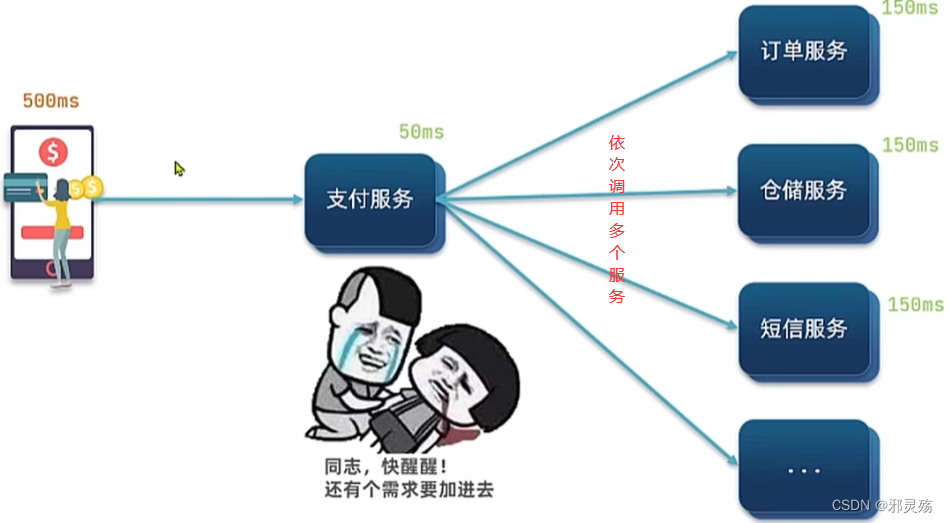
- 微服务间基于Feign的调用就属于同步方式,存在一些问题
- 耦合度高:每次加入新的需求,都要修改原来的代码
- 性能下降:调用者需要等待服务提供者响应,如果调用链过长则响应时间等于每次调用的时间之和
- 资源浪费:调用链中的每个服务在等待响应的过程中,不能释放请求占用的资源,高并发场景下会极度浪费系统资源
- 级联失败:如果某个服务提供者出现问题,所有调用方都会跟着出现问题,如同多米诺骨牌一样,迅速导致整个服务集群故障
异步调用方案

- 异步调用常见实现就是事件驱动模式
- 优势一:服务解耦
- 优势二:性能提升,吞吐量提高
- 优势三:服务没有强依赖,不担心级联失败
- 优势四:流量消峰
- 异步通讯的缺点:
- 依赖Broker的可靠性、安全性、吞吐能力
- 架构复杂了,业务没有明显的流程线,不好追踪
MQ的相关概念
什么是MQ
- MQ(Message Queue)即消息队列,本质上一个队列,FIFO先入先出,只不过队列中存放的内容是message而已,还是一种夸进程的通信机制,用于上下游传递消息。也就是事件驱动架构中的Broker
- 在互联网架构中,MQ是一种非常常见的上下游“逻辑解耦+物理解耦”的消息通信服务
- 使用了MQ之后,消息发送上游只需要依赖MQ,不用依赖其他服务
为什么要用MQ
- 流量消峰
- 举个例子,如果订单系统最多处理一万次订单,这个处理能力应付正常时段的下单时绰绰有余,正常时段我们下单一秒后就能返回结果
- 但是在高峰期,如果有两万次下单,操作系统是处理不了的,只能限制订单超过一万后不允许用户下单
- 如果使用消息队列做缓冲,我们可以取消这个限制,把一秒内下的订单分散成一段时间来处理,这时有些用户可能在下单十几秒后才能收到下单成功的操作,但是比不能下单的体验要好
- 应用解耦
- 以电商应用为例,应用系统中有订单系统、库存系统、物流系统、支付系统等
- 用户创建订单后,如果耦合调用库存系统、物流系统、支付系统,任何一个子系统出了故障,都会造成下单操作异常
- 当转变为基于消息队列的方式后,系统间调用的问题减少很多,比如物流系统因为发生故障,需要几分钟来修复,在这几分钟的时间里,物流系统要处理的内存被缓存在消息队列中,用户的下单操作可以正常完成
- 当物流系统恢复后,继续处理订单信息即可,中单用户感受不到物流系统的故障,提升系统的可用性
- 异步处理
- 有些服务间调用是异步的,例如A服务调用B服务,B需要花很长时间执行,但是A需要知道B什么时候可以执行完毕,以前一般有两种方式实现
- 方式一即A过一段时间调用B的查询API进行查询,根据查询结果判断是否执行完毕
- 方式二则是A提供一个callback回调API,B执行完之后调用API通知A服务
- 这两种方式都不是很优雅,使用消息总线,可以很方便的解决这个问题,A调用B服务后,只需要监听B处理完成的消息,当B处理完成后,会发送一条消息给MQ,MQ会将此消息转发给A服务。这样A服务既不用循环调用B的查询API,也不用提供callback回调API
- 同样B服务也不用做这些操作,A服务还能及时得到异步处理的结果消息
MQ的分类
| 参数 | RabbitMQ | ActiveMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 公司/社区 | Rabbit | Apache | 阿里(目前已交予Apache) | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 单机吞吐量 | 一般 | 差 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
- 对于开发语言,后三者中ActiveMQ与RocketMQ都是Java语言开发,因此比较容易做扩展,而Kafka是由Scala语言开发,但调用了JVM,因此也可以看作是由Java语言参与,当然一般公司直接使用即可,极少进行业务扩展
- 对于支持的协议,后两者支持的协议都只有自定义协议,能做的就比较少,比如AMQP协议,是跨平台的,也就是在不同语言之间可以进行通信
ActiveMQ
- 优点
- 单机吞吐量万级,时效性ms级,可用性高
- 基于主从架构实现高可用性,消息可靠性较低的概率丢失数据
- 缺点
- 官方社区现在对ActiveMQ5.X维护越来越少,高吞吐量场景使用较少
kafka
大数据的杀手锏,谈到大数据领域内的消息传输,则绕不开kafka
这款为大数据而生的消息中间件,以其百万级TPS的吞吐量名声大噪,迅速成为大数据领域的宠儿
在数据采集、传输、存储的过程中发挥着举足轻重的作用
目前已经被LinkedIn、Uber、Twitter、Netflix等大公司所采纳
- 优点
- 性能卓越,单机写入TPS约在百万条/秒,最大的优点,就是吞吐量高
- 时效性ms级,可用性非常高
- kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用
- 消费者采用pull的方式获取消息,消息有序,通过控制能够保证所有消息被消费且仅被消费一次
- 有优秀的第三方kafka Web管理界面kafka-manager
- 在日志领域比较成熟,被多家公司和多个开源项目使用
- 功能支持:功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用
- 缺点
- kafka单机超过64个队列/分区,Load会发生明显的飙高现象
- 队列越多,load越高,发送消息响应时间边长,使用短轮询方式,实时性取决于轮询间隔时间
- 消息失败不支持重试,支持消息顺序,但是一台代理宕机后,会产生消息乱序,社区更新较慢
RocktMQ
RocketMQ出自于阿里巴巴的开源产品,用Java语言实现,在设计时参考了Kafka,并做出了自己的一些改进
被阿里巴巴广泛应用在订单、交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景
- 优点
- 单机吞吐量十万级,可用性非常高,分布式架构,消息可以做到0丢失
- MQ功能较为完善,还是分布式的,扩展性好,支持10亿级别的消息堆积,不会因为堆积导致性能下降
- 源码是java,我们可以自己阅读源码,定制自己公司的MQ
- 缺点
- 支持的客户端语言不多,目前是java以及c++,其中c++不成熟
- 社区活跃度一般,没有在MQ核心中去实现JMS等接口,有些系统要迁移需要修改大量代码
RabbitMQ
2007年发布,是一个在AMQP(高级消息队列协议)基础上完成的,可服用的企业消息系统
是当前最主流的消息中间件之一
- 优点
- 由于erlang语言的高并发特性,性能好,吞吐量到万级,MQ功能比较完备
- 其健壮、稳定、易用、跨平台、支持多种语言,如Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等
- 支持AJAX文档齐全,开源提供的管理界面非常棒,用起来很好用,社区活跃度高
- 更新频率相当高https://www.rabbitmq.com/news.html
- 缺点
- 商业版需要收费
- 学习成本较高
MQ的选择
Kafka
- Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量
- 一开始的目的就是用于日志收集和传输,适合产生大量数据的互联网服务的数据收集业务
- 大型公司建议可以选用,如果有日志采集功能,肯定是首选Kafka
RocketMQ
- 天生为金融互联网领域而生,对于可靠性要求很高的场景,尤其是电商里面的订单和扣款,以及业务削峰,在大量交易涌入时,后端可能无法及时处理的情况
- RocketMQ在稳定性上可能更值得信赖,这些业务场景在阿里双11经历了多次考验,如果你的业务有上述场景,建议可以选用RocketMQ
RabbitMQ
- 结合erlang语言本身的并发优势,性能好,时效性微妙级,社区活跃度比较高
- 管理界面用起来十分方便,如果你的数据量没有那么大,中小型公司优先选择功能比较完备的RabbitMQ
rabbitMQ
基础
基本概念
RabbitMQ是一个消息中间件,它接受并转发消息
可以将其当做一个快递站点,当你要发送一个包裹时,可以将包裹放到快递站,快递员最终会将包裹送到收件人手里
按照这种逻辑RabbitMQ是一个快递站,一个快递员帮你传递快件
RabbitMQ与快递站的主要区别在于,它不处理快件而是接收、存储和转发消息数据
四大核心
- 生产者
- 产生数据发送消息的程序是生产者
- 交换机
- 交换机是RabbitMQ非常重要的一个部件,一方面它接受来自生产者的消息,另一方面它将消息推送到队列中
- 交换机必须确切知道如何处理它接收到的消息,是将这些消息推送到特定队列还是推送到多个队列,亦或是把消息丢弃,这个得由交换机类型决定
- 队列
- 队列是RabbitMQ内部使用的一种数据结构,尽管消息流经RabbitMQ和应用程序,但它们只能储存在队列中
- 队列仅受主机的内存和磁盘限制和约束,本质上是一个大的消息缓冲区
- 许多生产者可以将消息发送到一个队列,许多消费者可以尝试从一个队列接收数据,这就是我们使用队列的方式
- 消费者
- 消费与接收具有相似的含义。消费者大多时候是一个等待接收消息的程序
- 请注意生产者和消费者中间件很多时候并不在同一机器上
- 同一个应用程序既可以是生产者又可以是消费者

六大模式
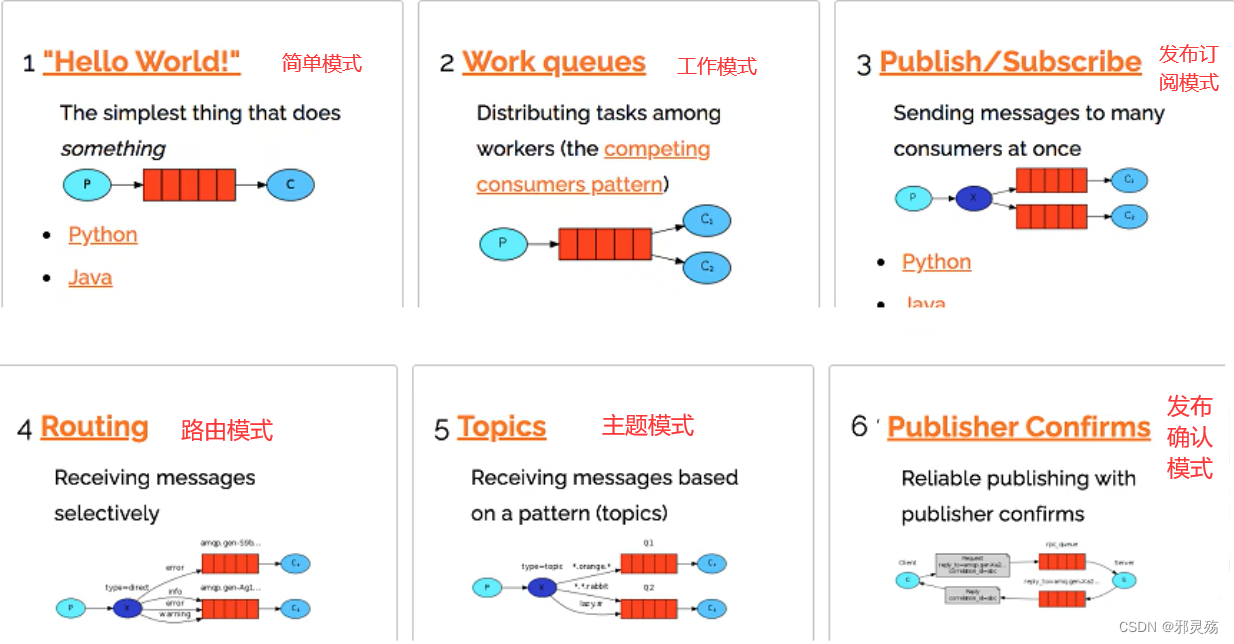
MQ的官方文档中给出了五个MQ的Demo示例,对应了几种不同的模式用法,我们可以简单将上面几种模式分为两大类:
- 直接基于队列的通信(没有交换机参与,直接基于队列,也不是完整的消息队列模型)
- 基本消息队列(BasicQueue),也就是简单模式
- 工作消息队列(WorkQueue),也就是工作模式
- 发布订阅(Publish、Subscribe),都有交换机参与,又根据交换机类型不同,分为三种
- Fanout Exchange:广播、扇出类型
- Direct Exchange:路由、直接类型
- Topic Exchange:主题、主题类型
名词解释
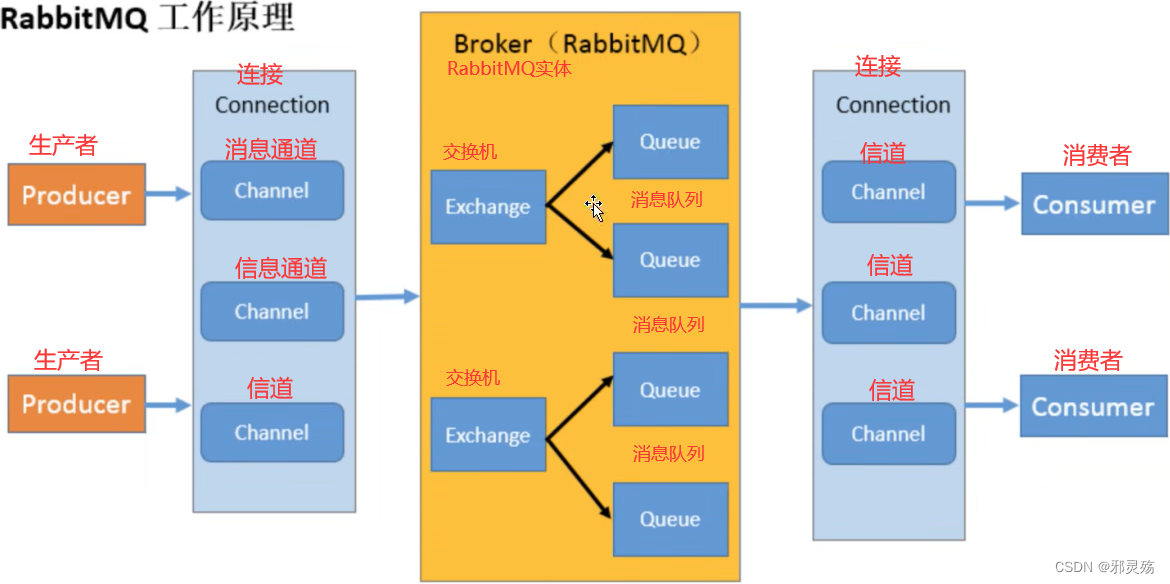
- Broker:接收和发布消息的应用,RabbitMQ Server就是Message Broker,也称为实体或消息实体
- Virtual host:出于多租户和安全因素设计的,把AMQP的基本组件划分到一个虚拟的分组中,类似于网络中的namespace概念。当多个不同的用户使用同一个RabbitMQ server提供服务时,可以划分出多个vhost,每个用户在自己的vhost创建exchange / queue等
- Connection:publisher / consumer和broker之间的TCP连接
- Channel:如果每一次访问RabbitMQ都建立一个Connection,在消息量大的时候建立TCP Connection的开销将是巨大的,效率也低。Channel是在connection内部建立的逻辑连接,如果应用程序支持多线程,通常每个Thread创建单独的channel进行通讯,AMQP method包含了channel id帮助客户端和message broker识别channel,所以channel之间完全隔离的。Channel作为轻量级的Connection极大减少了操作系统建立TCP connection的开销
- Exchange:message到达broker的第一站,根据分发规则,匹配查询表中的routing key,分发消息到queue中去。常用的类型有:direct(point-to-point)、topic(publish-subscribe)和fanout(multicast)
- Queue:消息最终被送到这里等待consumer取走
- Binding:exchange和queue之间的虚拟连接,binding中可以包含routing key,Binding信息被保存到exchange中的查询表中,用于message的分发依据
- 一个RabbitMQ服务,也就是RabbitMQ server中有多个Broker消息实体,一个Broker中可以有多个Vhost虚拟分组,一个分组中可以有多个Exchange交换机,一个交换机可以Binding绑定多个Queue消息队列
下载安装
-
官方网站
-
上传文件
- 上传到
/usr/local/software目录(如果没有software需要自己创建)

- 上传到
-
安装文件(分别按照以下顺序安装)
rpm -ivh erlang-21.3-1.el7.x86_64.rpm,命令中-i即安装install,vh即显示安装进度yum install socat -y,安装依赖rpm -ivh rabbitmq-server-3.8.8-1.el7.noarch.rpm
-
常用命令(按照以下顺序执行)
- 添加开机自启动RabbitMQ服务:
chkconfig rabbitmq-server on - 启动服务:
/sbin/service rabbitmq-server start - 查看服务状态:
/sbin/service rabbitmq-server status - 停止服务:
/sbin/service rabbitmq-server stop - 开启web管理界面,安装后台管理界面:
rabbitmq-plugins enable rabbitmq_management- 有可能安装中出现错误提示:
{:query, :rabbit@master, {:badrpc, :timeout}} - 此时可以先使用命令
hostnamectl查看主机名,出现的hostname就是主机名 - 然后通过命令
vim /etc/hosts修改hosts文件,在最后加入主机IP和主机名,保存退出 - 然后再次进行安装即可安装成功
- 有可能安装中出现错误提示:
- 安装好web界面后再次开启服务,使用默认的账号密码(guest)访问地址
http://ip:15672/出现权限问题
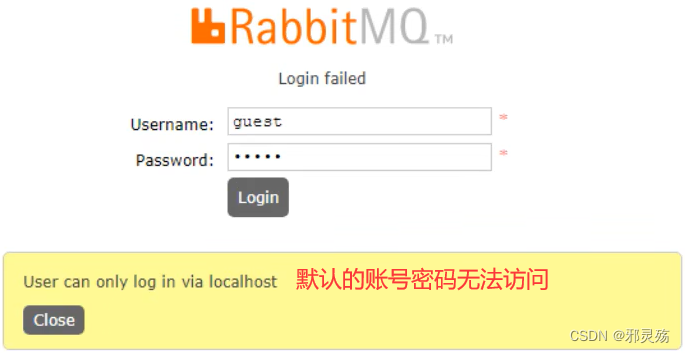
- 添加开机自启动RabbitMQ服务:
-
添加一个新用户
- 创建账号:
rabbitmqctl add_user admin 123,其中admin为用户名,123为密码 - 设置用户角色:
rabbitmqctl set_user_tags admin administrator授予管理员角色 - 设置用户权限:
- 命令格式:
set_permissions [-p <vhostpath>] <user> <conf> <write> <read>,表示设置哪个用户权限操作哪个vhost,并且设置对该vhost的配置、写,读的具体权限 - 例如:
rabbitmqctl set_permissions -p "/" admin ".*" ".*" ".*",设置admin用户对“/”这个vhost的配置、写、读的所有权限,注意,vhost是自己配置的,相当于自定义的,一个vhost类似于一个MQ的一个库,不同的vhost都有独立属于自己的交换机和队列 - 此时用户user_admin具有/vhost1这个virtual host中所有资源的配置、写、读权限
- 命令格式:
- 当前用户和角色:
rabbitmqctl list_users
- 创建账号:
-
Docker安装
- 在线拉取镜像或从本地导入镜像
- 在线拉取
docker pull rabbitmq:3-management - 从本地加载
# mq.tar就是本地镜像文件,在mq.tar所在目录之间运行命令 docker load -i mq.tar
- 在线拉取
- 安装MQ
docker rum \ # -e表示设置环境变量,这里设置用户名和密码 -e RABBITMQ_DEFAULT_USER=username \ -e RABBITMQ_DEFAULT_PASS=password \ # 给MQ服务起名 --name mq \ # 配置主机名(自定义如节点一),集群中用到,单机不配也可以,可以看后面MQ集群部分设置 --hostname mq1 # 端口映射,这里开放管理端口,就是服务界面连接端口 -p 15672:15672 \ # 端口映射,这里开放使用端口,就是业务中通讯使用时端口 -p 5672:5672 \ # 表示后台运行 -d \ # 镜像名称,操作哪个镜像 rabbitmq:3-management - 配置集群(待补充)
- 在线拉取镜像或从本地导入镜像
简单模式
简单模式中,我们将用Java编写两个程序,发送单个消息的生产者和接收消息并打印出来的消费者
下面创建一个普通的maven项目
依赖
<!-- 指定jdk编译版本-->
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<!-- RabbitMQ客户端依赖-->
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.8.0</version>
</dependency>
<!--操作文件流的一个依赖-->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
</dependencies>
生产者
- 步骤
- 第一步:创建连接工厂对象(ConnectionFactory),设置连接RabbitMQ的IP、用户名和密码
- 第二步:创建一个连接,得到连接对象(Connection)
- 第三步:通过连接对象获取信道(Channel)
- 第四步:生成一个队列,这里应该是操作交换机,交换机绑定队列,我们初始不用管交换机,当做没有即可,或者认为是一个默认交换机
- 通过方法queueDeclare()声明一个队列
- 参数一:队列名称,自定义即可
- 参数二:队列里面的消息是否持久化,默认存储与内存,不持久化,true表示持久化
- 参数三:该队列是否只供一个消费者进行消费,是否进行消息的共享,我们之前也说过,一般一个队列对应一个消费者,true表示多个消费者进行消费
- 参数四:是否自动删除,最后一个消费者断开连接以后,该队列是否自动删除,true表示自动删除
- 参数五:其他参数,如设置延迟消息、死信消息等,我们目前没有可以写null
- 第五步:通过信道发送消息,方法为basicPublish()
- 参数一:发送到哪个交换机,我们这里没有,给一个空字符串即可
- 参数二:路由的Key值是哪个,我们这里直接写前面的队列名,也就是前面什么对象时的参数一
- 参数三:其他参数,我们这里没有可以直接写null
- 参数四:发送消息的消息体,消息有消息头消息体等,这里不用消息对象,直接是消息体,二进制数据,我们可以发送一个字符串二进制数据
- 代码
/** * @Author: 邪灵 * @Date: 2023/3/21 21:33 * @Description: 生产者 * @version: 1.0 */ public class Producer { public static void main(String[] args) throws IOException, TimeoutException { // 创建连接工厂 ConnectionFactory factory = new ConnectionFactory(); // 设置RabbitMQ服务端口 factory.setHost("192.168.0.200"); // 设置虚拟主机,只有默认时可以不用设置,默认就是斜杠/ factory.setVirtualHost("/"); // 设置用户名 factory.setUsername("roor"); // 设置密码 factory.setPassword("root"); // 创建连接对象 Connection connection = factory.newConnection(); // 获取信道 Channel channel = connection.createChannel(); // 声明一个队列 channel.queueDeclare("myQueue", false, false, true,null); // 发送消息 channel.basicPublish("","myQueue",null,"我是发送的消息".getBytes("utf-8")); System.out.println("消息发送成功"); } }
消费者
- 步骤
- 第一步:创建连接对象,设置IP、账号和密码
- 第二步:创建一个连接,得到一个连接对象
- 第三步:通过连接对象获取一个信道
- 第四步:通过信道消费消息,通过basicConsume()方法
- 参数一:消费哪个队列,就是我们在生成者中自定义的队列名称
- 参数二:消费成功后是否自动应答,true表示自动应答,false为手动应答
- 参数三:消费者成功消费的回调函数,为
DeliverCallback类型的函数式接口- 参数一:。。。
- 参数二:消息对象,包含消息头、消息体等,通过getBody获取消息体
- 参数四:消费者取消消费的回调函数,为
CaneclCallback类型的函数式接口- 参数一:同消费成功回调函数的参数一,可以认为是消费者标签,字符串类型
- 方式二消费消息:通过basicConsume()方法
- 参数一:消费哪个队列,就是我们在生成者中自定义的队列名称
- 参数二:消费成功后是否自动应答,true表示自动应答,false为手动应答
- 参数三:DefaultConsumer(channel)类型的匿名对象,需要实现一个handleDelivery方法,里面有四个参数,参数四就是消息体
- 代码
/** * @Author: 邪灵 * @Date: 2023/3/21 22:18 * @Description: 消费者 * @version: 1.0 */ public class Consumer { public static void main(String[] args) throws IOException, TimeoutException { // 创建连接工厂 ConnectionFactory factory = new ConnectionFactory(); // 设置IP、账号、密码 factory.setHost("192.168.0.200"); factory.setUsername("root"); factory.setPassword("root"); // 获取连接 Connection connection = factory.newConnection(); // 获取信道 Channel channel = connection.createChannel(); // 消费消息 channel.basicConsume("myQueue",true, (consumerTag,message)->{ // 直接打印消息体信息 System.out.println(new String(message.getBody())); }, consumerTag->{ System.out.println("消息接收异常"); }); // 另一种简单方式进行消费,代码比较上面简单一点,用默认方法消费 channel.basicConsume("myQueue",true,new DefaultConsumer(channel){ public void handleDelivery(String consumerTag,Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException { // 处理消息,直接打印即可 System.out.println(new String(body)); } }); } }
工作模式
工作队列(也称为任务队列)的主要思想是避免立即执行资源密集型任务,而不得不等待它完成
相反我们安排任务之后执行。我们把任务封装为消息并将其发送到队列。在后台运行的工作进程将弹出任务并最终执行作业
当有多个工作线程时,这些工作线程将一起处理这些任务
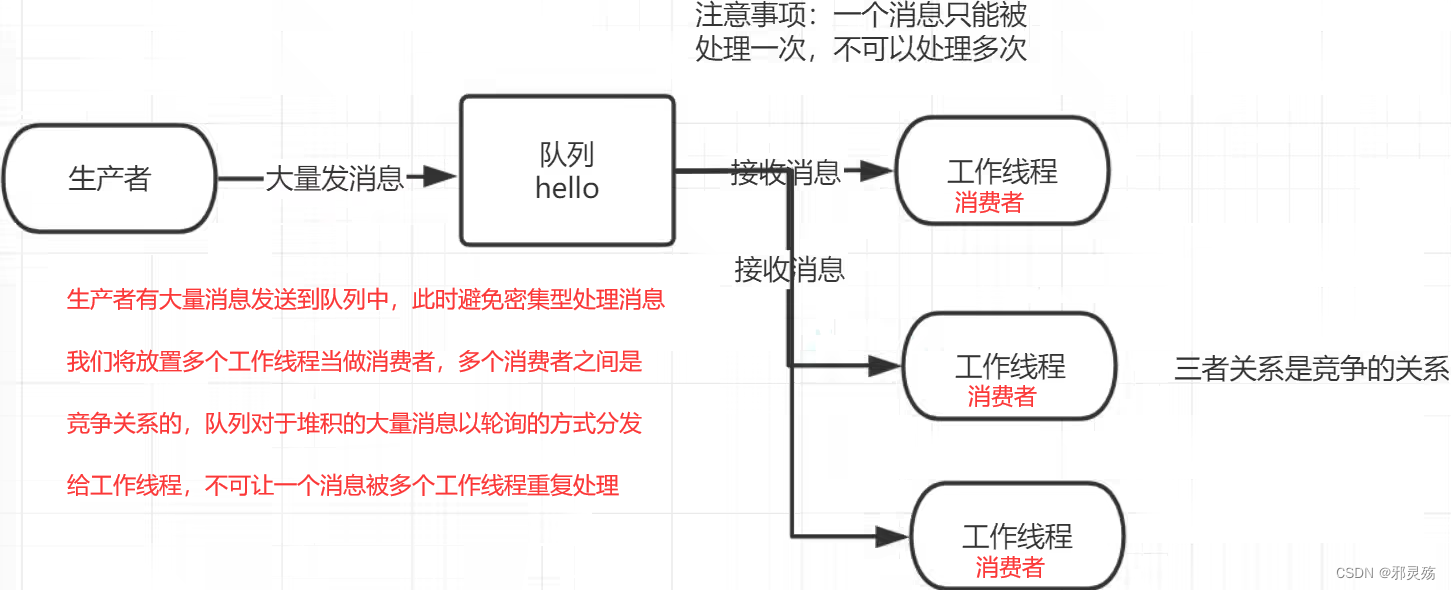
轮询分发消息
下面我们将启动一个消息发送线程,两个工作线程(消费者)
- 抽取工具类
/** * @Author: 邪灵 * @Date: 2023/3/21 22:53 * @Description: RabbitMQ工具类 * @version: 1.0 */ public class RabbitMQUtils { public static Channel getChannel() throws IOException, TimeoutException { ConnectionFactory factory = new ConnectionFactory(); factory.setHost("192.168.0.200"); factory.setUsername("root"); factory.setPassword("root"); return factory.newConnection().createChannel(); } } - 启动两个工作线程(这里我们不用多线程,直接启动两次main即可,当然也可以使用多线程)
public class Workers { public static void main(String[] args) throws IOException, TimeoutException { Channel channel = RabbitMQUtils.getChannel(); channel.basicConsume("hello",true, (consumerTag,message)-> System.out.println("接收到消息:"+new String(message.getBody())), consumerTag-> System.out.println(consumerTag+"取消接收消息") ); } } - 启动一个消息发送线程
public class Producer { public static void main(String[] args) throws IOException, TimeoutException { Channel channel = RabbitMQUtils.getChannel(); channel.queueDeclare("hello",false,false,true,null); // 获取控制台输入信息,多次发送 Scanner scanner = new Scanner(System.in); while (scanner.hasNext()) { String message = scanner.next(); channel.basicPublish("","hello",null,message.getBytes()); System.out.println("当前消息"+message+"发送完成"); } } } - 测试结果(自动实现轮询分发,四条信息两个工作线程各自接收两条)



消息应答
-
概念
- 消费者完成一个任务可能需要一段时间,如果其中一个消费者处理一个长的任务并仅只完成了部分突然挂掉了,会发生什么情况呢?
- RabbitMQ一旦向消费者传递了一条消息,便立即将该消息标记为删除
- 在这种情况下,突然有个消费者挂掉了,我们将丢失正在处理的消息,以及后续发送给该消费者的消息,因为它无法接收到
- 为了保证消息再发送过程中不丢失,RabbitMQ引入了消息应答机制,消息应答就是:
- 消费者在接收到消息并且处理该消息之后,告诉RabbitMQ它已经处理了,RabbitMQ可以把该消息删除了
-
自动应答
- 消息发送后立即被认为已经传送成功,这种模式需要在高吞吐量和数据传输安全性方面做权衡
- 在这种模式如果消息在接收到之前,消费者那边出现连接或者信道关闭,那么消息就丢失了
- 另一方面这种模式消费者那边可以传递过载的消息,没有传递的消息数量进行限制,当然这样有可能使得消费者这边由于接收太多还类不急处理的消息,导致这些消息积压,最终使得内存耗尽,最终这些消费者线程被操作系统杀死
- 所以这种模式仅适用在消费者可以高效并以某种速率处理这些消息的情况下使用
-
消息应答的方法(手动应答)
Channel.basicAck():用于肯定确认,RabbitMQ已知道该消息并且成功的处理该消息,可以将其丢弃了Channel.basicNack():用于否定确认Channel.basicReject():用于否定确认,与Channel.basicNack()相比少一个参数,不处理该消息了直接拒绝,可以将其丢弃了
-
Multiple的解释(上面方法中少的参数)
-
手动应答的好处是可以批量应答并减少网络拥堵
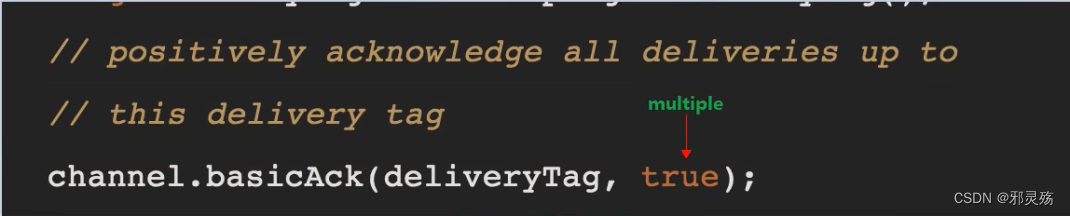
-
multiple的true和false代表不同的意思
- true:代表批量应答chanel上未应答的消息,比如说channel上有传送tag的消息5、6、7、8,当前tag是8,那么此时5至8这些还未应答的消息都会被确认收到消息应答
- false:同上面相比,只会应答tag=8的消息,5、6、7这三个消息依然不会被确认收到信息应答
- 当然一般我们设置为false,因为当前tag为8,也就是8被处理了,而5、6、7还在信道channel中,可能在处理时会出现问题,不建议都被应答
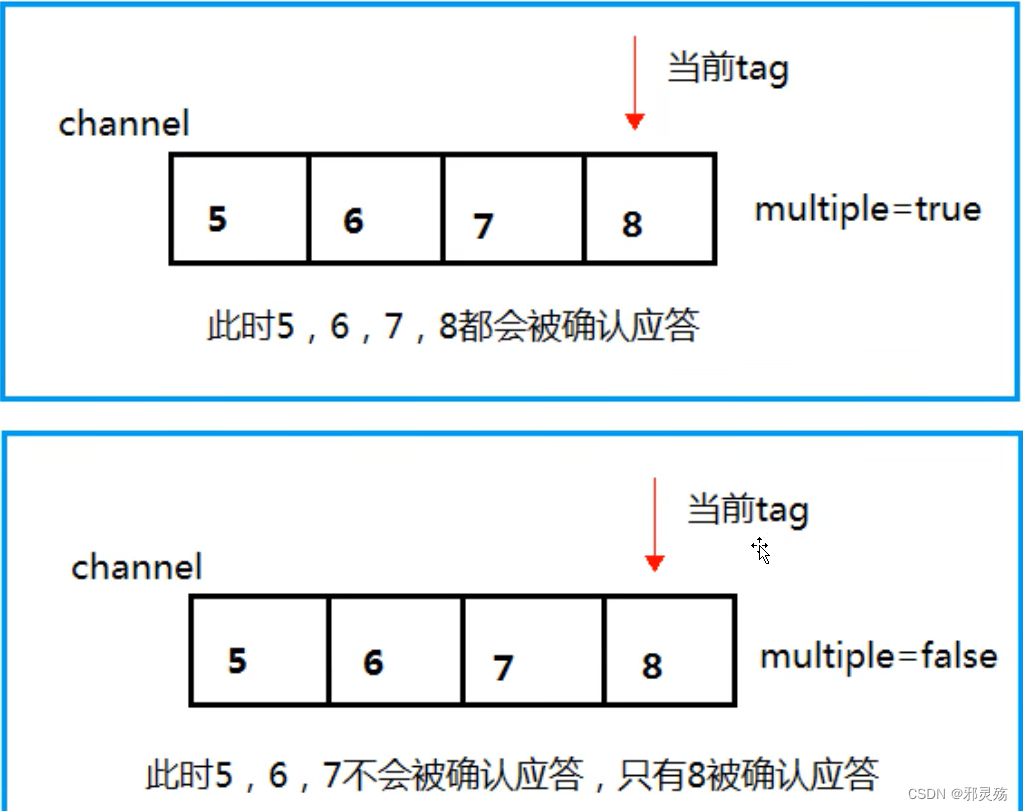
-
-
消息自动重新入队
- 如果消费者由于某些原因丢失连接(其通道已关闭,连接已关闭或TCP连接丢失),导致消息未发送ACK确认,RabbitMQ将了解到消息未完全处理,并将对其重新排队
- 如果此时其他消费者可以处理,它将很快将其重新分发给另一个消费者
- 这样即使某个消费者偶尔死亡,也可以确保不会丢失任何消息

-
消息手动应答代码实现
- 默认前面我们消费者接收消息都是自动应答,此时我们将应答改为自动,也就是接收消息的方法中第二个参数为false
- 另外就是在接收消息的函数中成功处理消息后再调用
basicACK()手动应答,该方法参数二就是前面我们说的是否批量应答,参数一为消息标记tag,表示哪个消息的应答 - 需要注意的是,与生产者没有关系,生产者只负责发送消息,而消费者负责应答,且出现问题时RabbitMQ自动实现消息重新排队
生产者:
消费者一,快速处理消息public class Producer { public static void main(String[] args) throws IOException, TimeoutException { Channel channel = RabbitMQUtils.getChannel(); channel.queueDeclare("hello",false,false,true,null); // 获取控制台输入信息,多次发送 Scanner scanner = new Scanner(System.in); while (scanner.hasNext()) { String message = scanner.next(); channel.basicPublish("","hello",null,message.getBytes()); System.out.println("当前消息"+message+"发送完成"); } } }
消费者二,处理消息时间长public class Worker01 { public static void main(String[] args) throws Exception { Channel channel = RabbitMQUtils.getChannel(); System.out.println("消费者一开始工作"); channel.basicConsume("hello",false // 手动应答 ,(consumerTag,message)->{ try { // 睡眠一秒,模拟快速处理消息 Thread.sleep(1000); } catch (InterruptedException e) { throw new RuntimeException(e); } // 接收消息 System.out.println("接收到消息:" + new String(message.getBody(),"utf-8")); // 手动应答,参数一表示消息唯一标识,参数二不批量应答 channel.basicAck(message.getEnvelope().getDeliveryTag(),false); } ,consumerTag-> System.out.println(consumerTag+"接收失败") ); } }public class Worker02 { public static void main(String[] args) throws Exception { Channel channel = RabbitMQUtils.getChannel(); System.out.println("消费者二开始工作"); channel.basicConsume("hello",false // 手动应答 ,(consumerTag,message)->{ try { // 睡眠三十秒,模拟处理长时间处理消息 Thread.sleep(30000); } catch (InterruptedException e) { throw new RuntimeException(e); } // 接收消息 System.out.println("接收到消息:" + new String(message.getBody(),"utf-8")); // 手动应答,参数一表示消息唯一标识,参数二不批量应答 channel.basicAck(message.getEnvelope().getDeliveryTag(),false); } ,consumerTag-> System.out.println(consumerTag+"接收失败") ); } }
-
因为消费者二处理消息花费时间较长,因此我们可以中途停掉该服务,模拟宕机等意外情况,可以发现本因属于消费者二处理的消息,又被消费者一进行处理
RabbitMQ持久化
- 概念
- 我们上面学习了如何处理任务不丢失的情况,但是如何保障当RabbitMQ服务停掉之后消息生产者发送过来的消息不丢失呢?
- 默认情况下RabbitMQ退出或由于某些原因奔溃时,它忽视队列和消息,除非告知它不要这样做
- 确保消息不会丢失需要做两件事:需要将队列和消息都标记为持久化
- 队列持久化
-
前面我们创建的队列都是非持久化的,RabbitMQ如果重启的话,该队列就会被删除掉
-
如果要队列实现持久化,需要在声明队列的时候把durable参数(也就是参数二)设置为true持久化

-
需要注意的是,如果之前声明的队列不是持久化的,需要把原先的队列先删除,或者重新声明一个持久化的队列,不能将已经声明的一个非持久化队列修改为持久化队列
-
- 消息持久化
-
要想让消息实现持久化需要在消息生产者修改代码,也就是发消息的时候,就告诉RabbitMQ该消息需要持久化
-
我们修改第三个参数即可,前面我们发消息时第三个参数是null,此时我们需要给定参数
MessageProperties.PERSISTENT_TEXT_PLAIN

-
将消息标记为持久化并不能完全保证不会丢失消息,尽管它告诉RabbitMQ将消息保存到磁盘
-
比如当消息准备存储到磁盘的时候,但是还没有存储完,消息还在缓存的一个间隔点,此时并没有真正写入磁盘,持久性保证并不强,但是对于简单任务队列而言,这已经绰绰有余了
-
如果需要更强有力的持久化策略,后续还可以通过其他方式实现
-
- 不公平分发
-
前面我们了解到RabbitMQ分发消息采用的是轮询分发,但是在某些场景下这种策略并不是很好
-
比如有两个消费者在处理任务,其中有个消费者处理任务的速度非常快,而另一个消费者处理速度很慢
-
这时候如果我们还是采用轮询分发的话就会导致处理速度快的这个消费者很大一部分时间处于空闲状态,而处理速度慢的那个消费者一直在处理任务,这种分配方式在这种情况下其实就不太好
-
但是RabbitMQ并不知道这种情况,它依然很公平的采用轮询分发
-
为了避免这种情况发生,我们可以设置参数
channel.basicQos(1);,默认这个参数是0,我们手动设置为0也是轮询分发
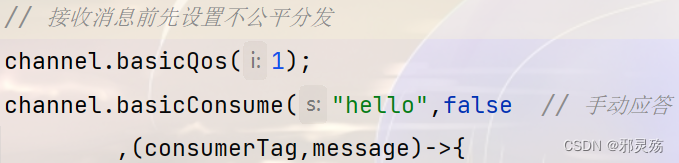
-
需要注意的是,这个设置是在消费者中进行的,根据每个消费者各自的处理能力进行设置
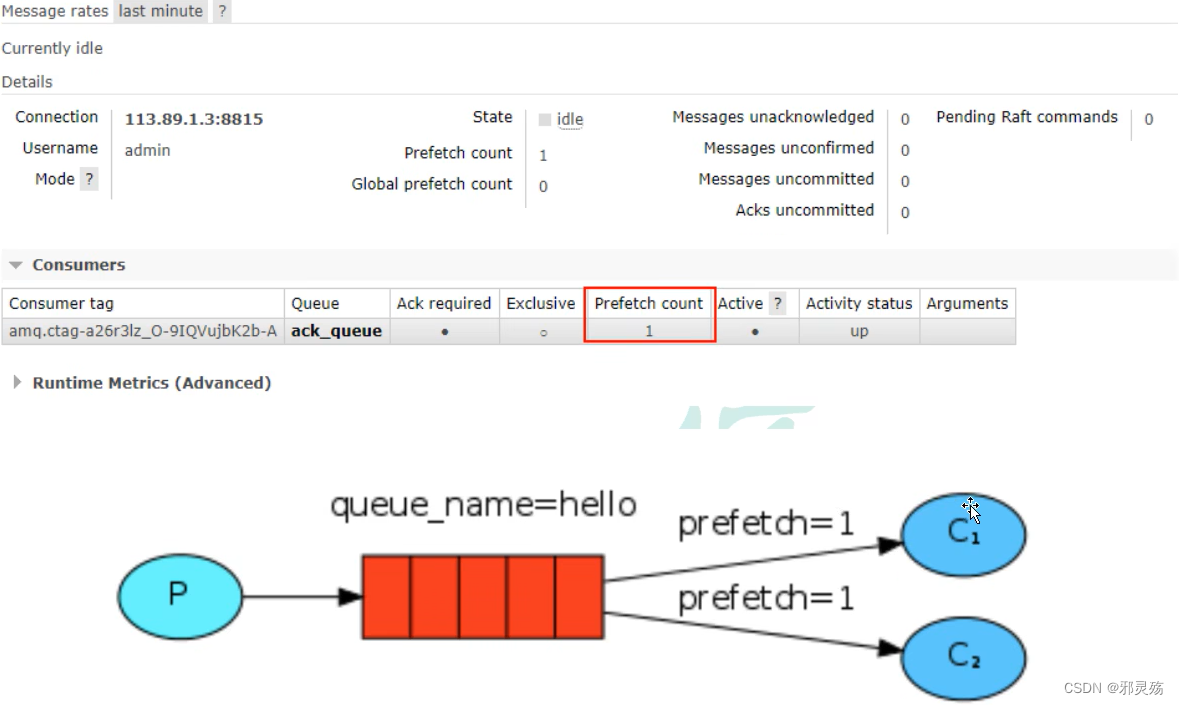
-
比如当处理速度慢的消费者设置为不公平分发之后,意思就是如果当前这个任务我还没有处理完或者我还没有应答你的情况下,你先别给我分发,给其他消费者分发,我目前只能处理一个任务
-
此时RabbitMQ就会把该任务分配给没有那么忙的空闲消费者
-
当然如果所有的消费者都没有完成手上的任务,队列还在不停的添加新任务,队列有可能就会遇到队列被撑满的情况,这个时候只能添加新的消费者或者改变其他存储任务的策略
-
- 预取值(就是上面不公平分发的值,只是值大小不同)
-
前面我们学习了默认的轮询分发消息策略和不公平分发策略,但是依然有些不完美
-
本身消息的发送就是异步发送的,所以在任何时候,channel上肯定不止只有一个消息
-
另外来自消费者的手动应答本质上也是异步的。因此这里就存在一个未确认的消息缓冲区
-
此时希望开发人员能够限制此缓冲区的大小,以避免缓冲区里面无限制的未确认消息问题
-
这个时候就可以通过使用
basic.qos方法设置预取计数值来完成,该值定义通道上允许的未确认消息的最大数量 -
一旦数量达到配置的数量,RabbitMQ将停止在通道上传递更多消息,除非至少有一个未处理消息被确认
-
例如,假设在通道上有未确认的5、6、7、8,并且通道的预取值设置为4,此时RabbitMQ将不会在该通道上再传递任何消息,除非至少有一个未应答的消息被ack,比如tag=6这个消息刚刚被确认ACK,RabbitMQ将会感知这个情况并再发送一条消息
-
消息应答和QoS预取值对用户吞吐量有重大影响,通常,增加预取值将提高向消费者传递消息的速度
-
虽然自动应答传输消息速率是最佳的,但是,在这种情况下已传递但尚未处理的消息的数量也会增加,从而增加消费者的RAM消耗(随机存取存储器)
-
应该小心使用具有无限预处理的自动确认模式或手动确认模式,消费者消费了大量的消息如果没有确认的话,会导致消费者连接节点的内存消耗变大,所以找到合适的预取值是一个反复试验的过程,不同的负载该值取值也不同
-
100到300范围内的值通常可提供最佳的吞吐量,并且不会给消费者带来太大的风险
-
预取值为1是最保守的,当然这将使得吞吐量变得很低,特别是消费者连接延迟很严重的情况下,特别是在消费者连接等待时间较长的环境中,对于大多数应用来说,稍微高一点的值将是最佳
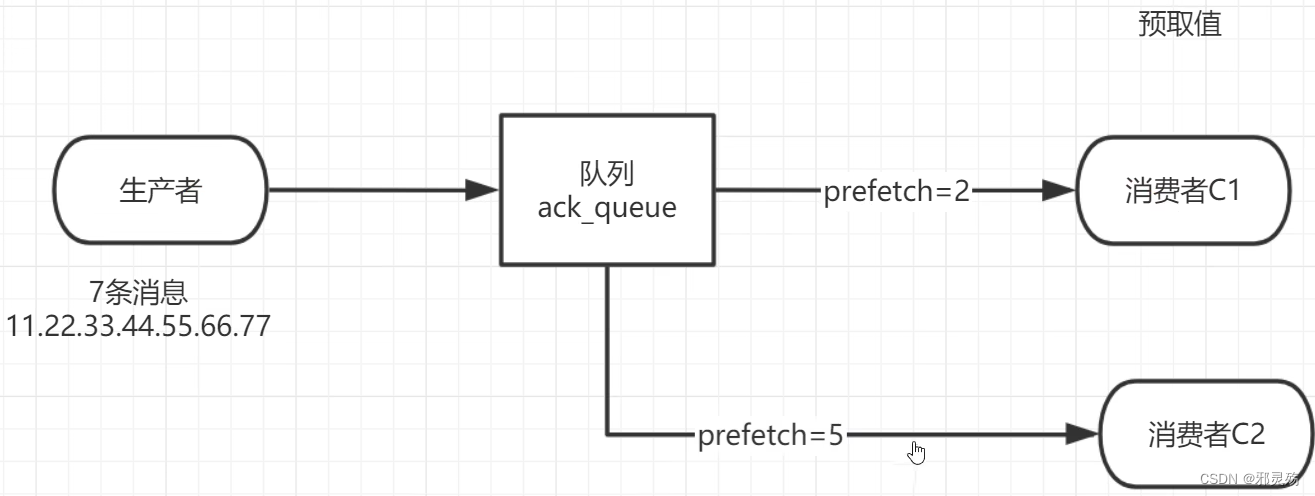
-
可以简单理解为,预取值就是当有足够多消息的时候,当前消费者会预先拿到设置的预取值条任务,可以认为就是在不公平分发的基础上,为了防止一个消费者处理完了消息但是还没有应答,导致将其他所有消息分发给另外的消费者,可以理解为就是对于不公平分发的更精确限制
-
需要注意的是,预取值是当前消费者信道堆积的消息量,而不是处理的消息量,比如消费者一设置是2,消费者二设置是5,七条消息在发送的时间中消费者一已经处理了一条,那么它的信道中还是可能分发到两条,剩余的给到消费者二,而再有消息时消费者二因为不够设置的5,就会分发给消费者二
-
发布确认模式
发布确认原理
- 生产者将信道设置成confirm模式,一旦信道进入confirm模式,所有该信道上面发布的消息都将会被指派一个唯一的ID(从1开始)
- 一旦消息被投递到所有匹配的队列之后,broker就会发送一个确认给生产者(包含消息的唯一ID)
- 这就使得生产者知道消息已经正确到达目的队列了,如果消息和队列是可持久化的,那么确认消息会在将消息写入磁盘之后发出,broker回传给生产者的确认消息中delivery-tag域包含了确认消息的序列号,此外broker也可以设置
basic.ack的multiple域,表示到这个序列号之前的所有消息都已经得到了处理 - confirm模式最大的好处在于它是异步的,一旦发布一条消息,生产者应用程序就可以在等信道返回确认的同时继续发送下一条消息,当消息最终得到确认之后,生产者应用便可以通过回调方法来处理该确认消息
- 如果RabbitMQ因为自身内部错误导致消息丢失,就会发送一条nack消息,生产者应用程序同样可以在回调方法中处理该nack消息
- 发布确认,就是当我们将队列设置为持久化,同时将队列中的消息也设置为持久化之后,可能在消息写入磁盘前由于RabbitMQ自身原因导致消息丢失,此时发布确认就是在消息被写入磁盘之后,向生产者返回一条持久化成功的消息,保障消息不被丢失
发布确认策略
- 开启发布确认
-
发布确认默认是没有开启的,如果要开启则需要调用方法
confirmSelect()

-
每当需要使用发布确认,都需要在channel上调用该方法
-
- 单个确认发布
- 这是一种简单的确认方式,它是一种同步确认发布的方式,也就是发布一个消息之后只有它被确认发布,后续的消息才能续续发布
waitForConfirmsOrDie()这个方法只有在消息被确认的时候才返回,如果在指定时间范围内这个消息没有被确认那么它将抛出异常- 这种确认方式有一个最大的缺点就是:发布速度特别的慢,因为如果没有确认发布的消息就会阻塞所有后续消息的发布
- 这种方式最多提供每秒不超过数百条发布消息的吞吐量。当然对于一些应用程序来说这可能已经足够了,代码如下:
// 单个确认发布 public static void singleConfirm() throws IOException, TimeoutException, InterruptedException { // 获取信道 Channel channel = RabbitMQUtils.getChannel(); // 声明队列 channel.queueDeclare("hello",true,false,true,null); // 开启发布确认 channel.confirmSelect(); // 记录发送消息开始时间 long begin = System.currentTimeMillis(); // 发送消息,发送多条,测试不同方式耗时长短 for (int i = 0; i < 1000; i++) { channel.basicPublish("","hello",null,(i+"").getBytes()); // 发送一条确认一条 boolean flag = channel.waitForConfirms(); if (flag) { System.out.println("当前消息发送成功"); } else { System.out.println("当前消息发送失败"); } } // 记录发消息总耗时 System.out.println("单条确认发布总耗时:"+(System.currentTimeMillis()-begin)); }
- 批量确认发布
- 上面这种方式非常的慢,与单个等待确认消息相比,先发布一批消息然后一起确认可以极大地提高吞吐量
- 当然这种方式的缺点就是,当发生故障导致发布出现问题时,不知道是哪个消息出现问题了,我们必须将整个批处理保存在内存中,以记录重要的消息而后重新发布消息
- 当然这种方案任然是同步的,也一样阻塞消息的发布,代码如下:与单条确认发布代码一样,调用的方法一样,唯一不同的是发布一批消息后再调用waitForConfirms()进行确认
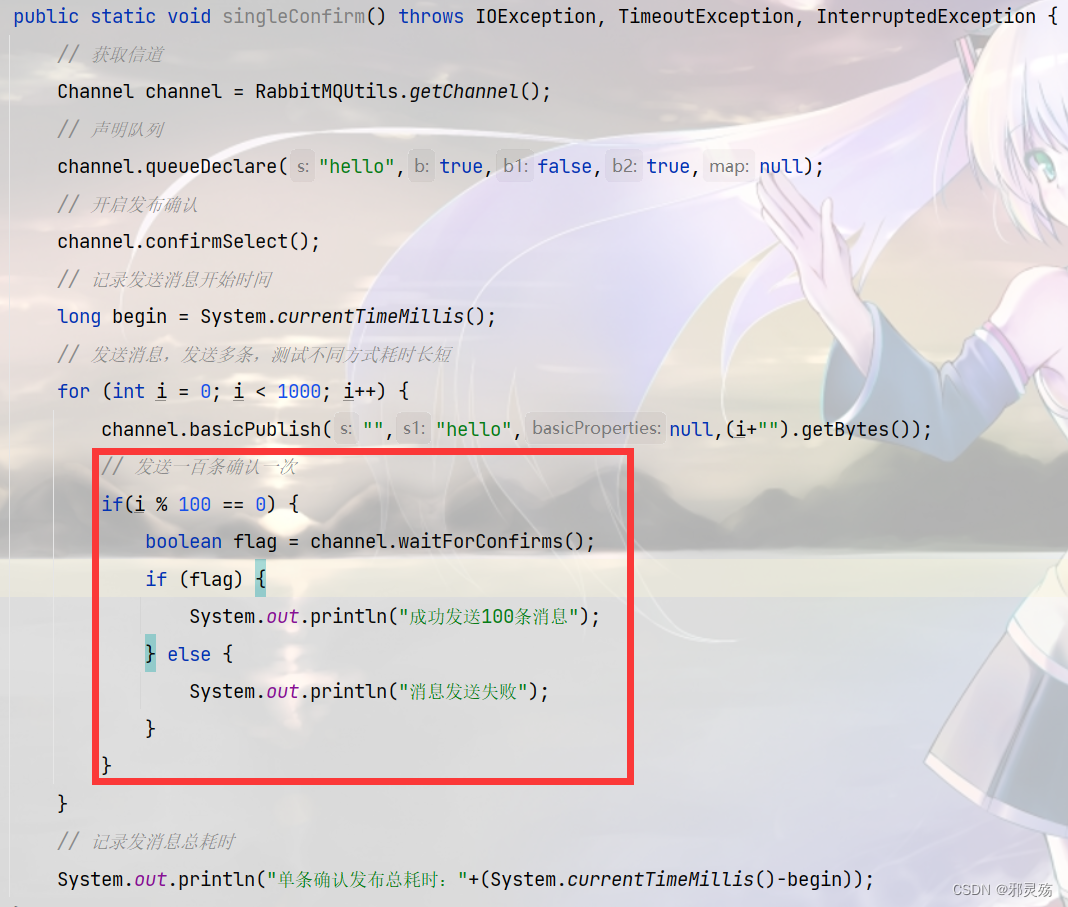
- 异步确认发布
-
异步确认虽然编程逻辑上比上面两种要复杂,但是性价比最高,无论是可靠性还是效率都比较好
-
它是利用回调函数来达到消息可靠性传递的,这个中间件也是通过函数回调来保证是否投递成功
-
此时不是在发送消息后确认,这样就跟前面一样了,而是在发送消息前准备监听器来监听发送成功或失败的返回信息即可,broker会进行回调,然后直接发送消息即可
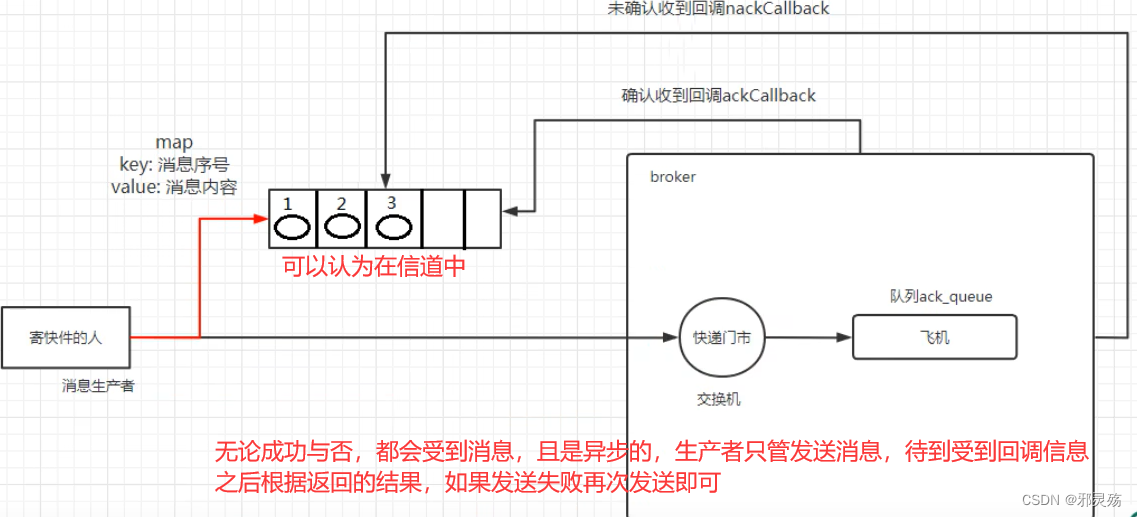
-
代码如下:
// 异步发布确认 public static void asyncConfirm() throws IOException, TimeoutException { // 获取信道 Channel channel = RabbitMQUtils.getChannel(); // 声明队列 channel.queueDeclare("hello",true,false,true,null); // 开启发布确认 channel.confirmSelect(); // 记录发送消息开始时间 long begin = System.currentTimeMillis(); // 发消息之前,添加监听器,监听成功和失败的消息,如果不需要成功或者失败回调,直接赋null即可 channel.addConfirmListener( // 发送成功回调,c为当前消息编号,m为是否批量 (c,m) -> { System.out.println("消息"+c+"发送成功!"); }, // 发送失败回调,c为当前消息编号,m为是否批量 (c,m) -> {System.out.println("消息"+c+"未确认!");} ); // 发送消息,发送多条,测试不同方式耗时长短 for (int i = 0; i < 1000; i++) { // 只管发送消息,其他不管 channel.basicPublish("","hello",null,(i+"").getBytes()); } // 记录发消息总耗时 System.out.println("单条确认发布总耗时:"+(System.currentTimeMillis()-begin)); }
-
- 处理异步未确认消息
- 最好的解决方案就是将未确认的消息放到一个基于内存的能被发布线程访问的队列,比如说用
ConcurrentLinkedQueue(并发链路队列)这个队列在confirm callbacks与发布线程之间进行消息的传递 - 因为监听发布确认是异步的,因此我们可以认为发送消息与监听器是两个独立的线程,而上面的这个队列就可以在两个线程之间传递消息
- 步骤:
- 发消息前准备一个线程安全的有序的哈希表,就是一个hashmap,键为消息编号,值就是消息
ConcurrentSkipListMap<Long,String> confirmMap = new ConcurrentSkipListMap<>() - 发消息时同时将消息存入上面的哈希表中,channel.getNextPublishSeqNo()就是获取下一次发消息的序号,message就是要发的消息
confirmMap.put(channel.getNextPublishSeqNo(),message) - 消息确认回调中将确认的消息从上面的哈希表中删除,最后剩下的就是未确认的,再次进行发送即可
- 发消息前准备一个线程安全的有序的哈希表,就是一个hashmap,键为消息编号,值就是消息
- 代码实现
// 异步发布确认 public static void asyncConfirm() throws IOException, TimeoutException { // 获取信道 Channel channel = RabbitMQUtils.getChannel(); // 声明队列 channel.queueDeclare("hello",true,false,true,null); // 开启发布确认 channel.confirmSelect(); // 准备一个线程安全的哈希表 ConcurrentSkipListMap<Long,String> map = new ConcurrentSkipListMap<>(); // 发消息之前,添加监听器,监听成功和失败的消息,如果不需要成功或者失败回调,直接赋null即可 channel.addConfirmListener( // 发送成功回调,c为当前消息编号,m为是否批量 (c,m) -> { System.out.println("消息"+c+"发送成功!"); // 然后将成功发送的消息从哈希表中删除 if (m) { // 如果是批量操作,就批量删除 ConcurrentNavigableMap<Long, String> deleMap = map.headMap(c); deleMap.clear(); } else { // 如果不是批量操作,就直接删除当前消息 map.remove(c); } }, // 发送失败回调,c为当前消息编号,m为是否批量 (c,m) -> { // 获取未确认消息 String message = map.get(c); System.out.println("消息"+message+"未确认!"); } ); // 记录发送消息开始时间 long begin = System.currentTimeMillis(); // 发送消息,发送多条,测试不同方式耗时长短 for (int i = 0; i < 1000; i++) { String message = i + ""; // 只管发送消息,其他不管 channel.basicPublish("","hello",null,message.getBytes()); // 发消息时将消息及其序号记录到哈希表中 map.put(channel.getNextPublishSeqNo(),message); } // 记录发消息总耗时 System.out.println("单条确认发布总耗时:"+(System.currentTimeMillis()-begin)); }
- 最好的解决方案就是将未确认的消息放到一个基于内存的能被发布线程访问的队列,比如说用
- 三种发布对比
- 单独发布消息:同步等待确认,简单,但吞吐量非常有限
- 批量发布消息:批量同步等待确认,简单,合理的吞吐量,一旦出现问题很难推断出是哪条消息出现问题
- 异步处理:最佳性能和资源使用,在出现错误的情况下可以很好的控制,但是实现稍微有些复杂
交换机
-
在前面的案例中,我们创建了一个工作队列,我们假设的是工作队列背后,每个任务都恰好交付给一个消费者(工作进程),因为我们前面说的简单模式或者工作模式,每个消息(任务)都只能交给一个消费者
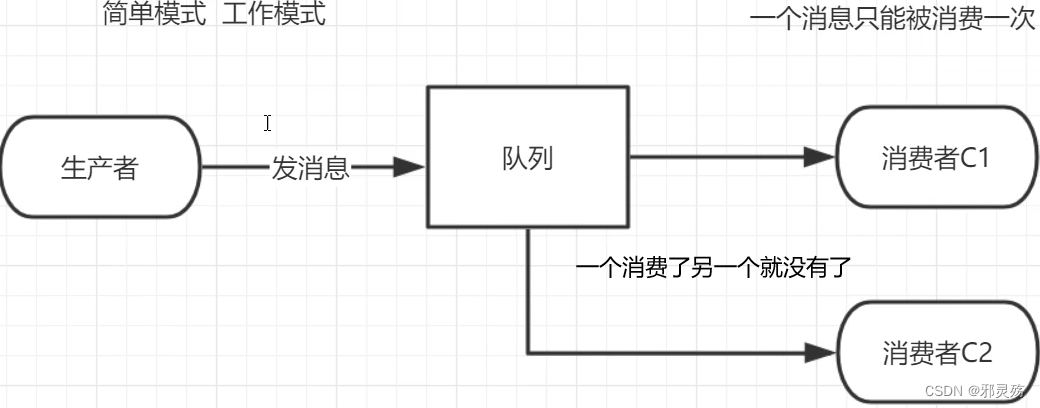
-
而在接下来的内容中,我们将做一些完全不同的事情,我们将一个消息传递给多个消费者。这种模式被称为“发布/订阅”模式
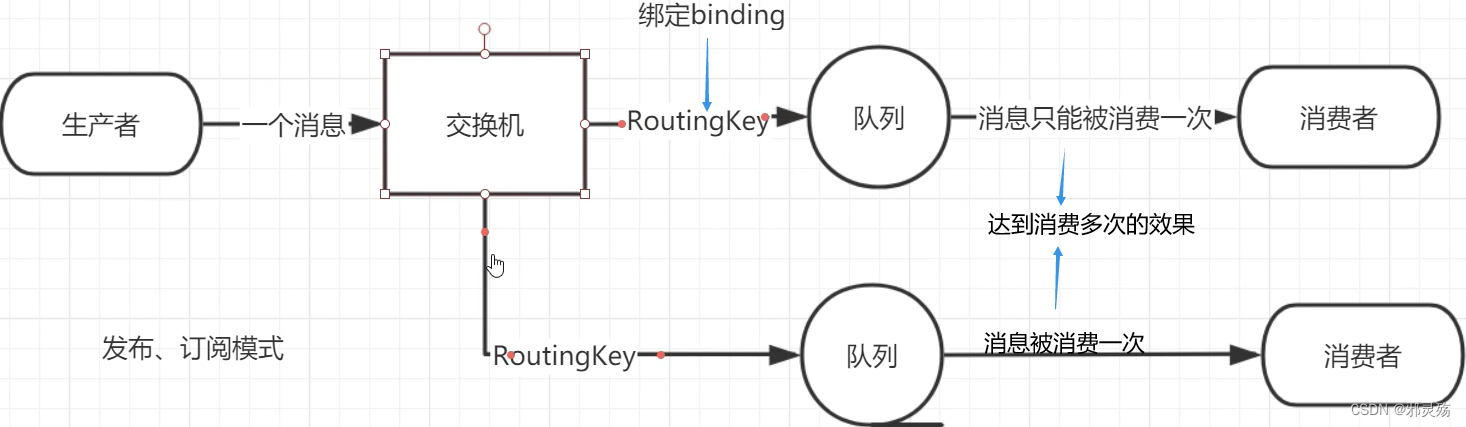
-
下面我们将构建一个简单的日志系统,用来说明发布订阅模式
-
它将由两个程序组成:第一个程序将发出日志消息,第二个程序是消费者。其中我们启动两个消费者,其中一个消费者接收到消息后把日志存储到磁盘,另一个消费者接收到消息后把消息打印在屏幕,事实上第一个程序发布的消息将广播给所有的消费者
Exchanges(交换机)
- 概念
- RabbitMQ消息传递模型的核心思想就是:生产者生产的消息从来不回直接发送到队列,即便之前我们简单模式和工作模式中交换机给定的是空字符串,实际用的是默认交换机
- 实际上,通常生产者甚至都不知道这些消息传递到了哪些队列中,相反的,生产者只能将消息发送到交换机(exchange)
- 交换机工作的内容非常简单,一方面它接收来自生产者的消息,另一方面将这些消息推入(路由)队列
- 交换机必须确切知道如何处理收到的消息。是应该把这些消息放到特定的队列还是把他们放到许多队列中还是说应该丢弃它们,这就交由交换机类型来决定
- 类型
- 直接类型(direct),也叫路由类型
- 主题类型(topic)
- 标题类型(headers)
- 扇出类型(fanout),发布订阅模式
- 无名类型,就是默认类型,前面我们用的都是这个类型
- 无名exchanges
- 在此之前我们对交换机(exchange)一无所知,但任然能够将消息发送到队列
- 之前能够实现的原因是因为我们使用了默认交换机,我们通过空字符串(“”)进行标识,就是第一个参数
channel.basicPublish("","hello",null,message.getBytes()); - 第一个参数是交换机名称。空字符串标识默认或无名交换机:消息能够路由发送到队列其实是由routingKey(bindingkey)绑定key指定的,如果它存在的话,前面我们没有指定绑定的其实就是队列的名称,而一旦我们指定了交换机,就不能再用队列名称了(第二个参数),必须指定routingKey的名称
临时队列
- 临时队列就是没有被持久化的队列
- 前面我们使用的是具有特定名称的队列,就是创建队列时我们给定了队列名称,队列名称对我们来说至关重要,因为我们需要指定我们的消费者去消费哪个队列,就是通过队列名指定的
- 每当我们连接到RabbitMQ时,我们都需要一个全新的空队列,为此我们可以创建一个具有随机名称的队列,或者能够让服务器为我们选择一个随机队列名那就更好了
- 其次一旦我们断开了消费者的连接,队列将被自动删除,也就是没有被持久化的队列
- 创建临时队列的方式:
String queueName = channel.queueDeclare().getQueue(),也就是声明队列时不需要指定名称,直接调用getQueue方法,会创建一个具有随机名称的队列,返回队列名称,并且该队列不会持久化且当所有消费者断开连接后会被自动删除
绑定(bindings)
-
什么是binding呢,binding其实就是exchange(交换机)和queue(队列)之间的桥梁
-
它告诉我们exchange和哪个队列进行了绑定关系,比如下面图示就是告诉我们X与Q1和Q2进行了绑定
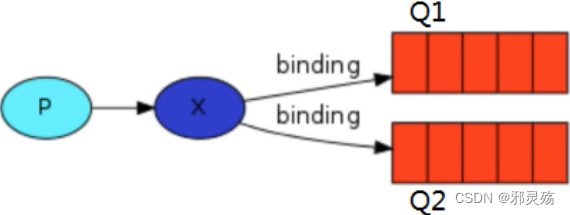
-
实现步骤
-
第一步:点击Queue队列标签,点击Add a new queue添加一个队列,然后添加队列名称、选择是否持久化、是否自动删除,然后点击Add queue按钮进行添加一个新队列
-
第二步:点击Exchanges标签,点击Add a new exchange添加一个交换机,然后填写交换机名称、选择交换机类型、选择是否持久化、选择是否自动删除,然后点击Add a exchange添加一个新的交换机
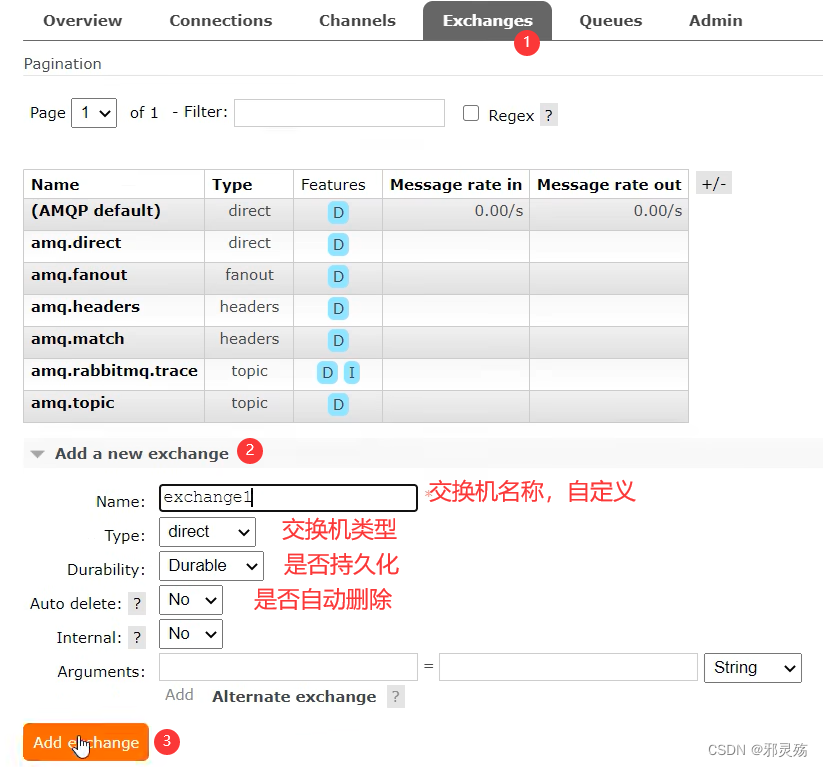
-
第三步:添加成功后可以在交换机列表中找到该交换机,点击进行操作
-
第四步:点击Bindings,填写需要绑定的队列名称、与队列路由的关键词Routing Key,然后点击Bind按钮进行绑定即可
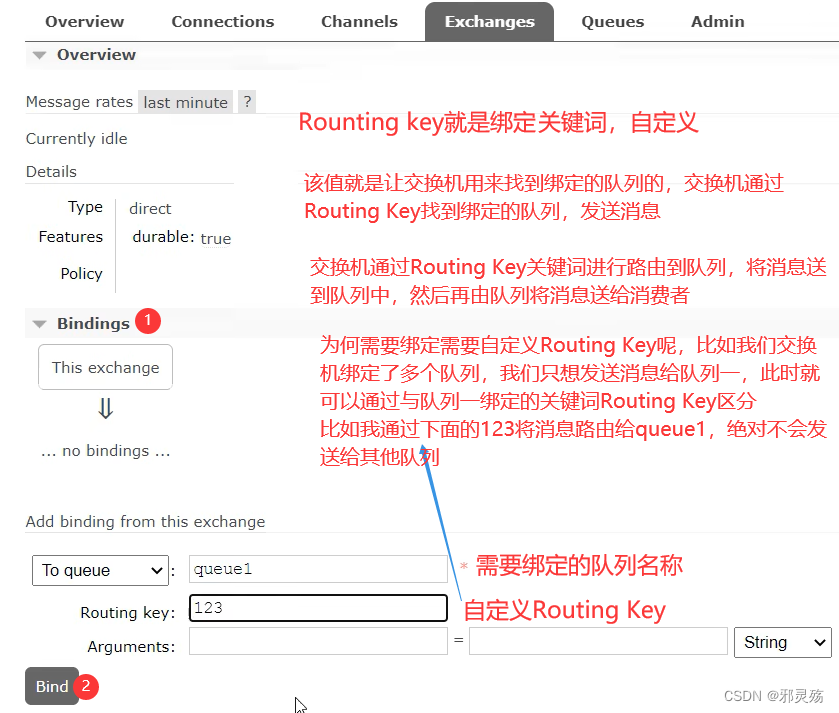
-
Fanout(扇出/发布订阅模式)
-
Fanout介绍
- Fanout这种类型非常简单,正如我们说的那样,它是将接收到的所有消息广播到它知道的所有队列中
- 系统中(RabbitMQ服务)默认有些exchange类型,其中就有一个Fanout类型的,我们直接可以使用,当然也可以自己再创建Fanout类型的exchange
-
Fanout实现
-
大致关系示意如下:
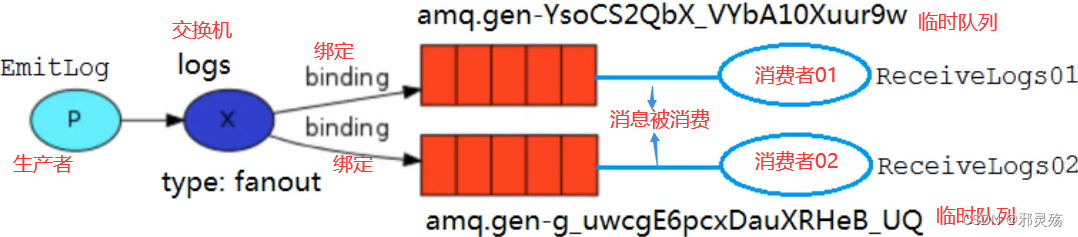
-
Logs(交换机)和临时队列绑定关系如下,这里我们不指定Routing Key(并非不指定,而是空字符串)
-
-
代码实现:
- 消费者一:
public class ReceiveLog02 { public static void main(String[] args) throws Exception{ // 通过工具类创建信道 Channel channel = RabbitUtils.getChannel(); // 声明一个交换机,因为交换机声明后就再MQ服务中,因此可以在提供者或消费者任意端进行声明,另一端直接使用 // 参数一:交换机名称自定义 // 参数二:交换机类型,此处我们使用扇出fanout类型 channel.exchangeDeclare("ExchangeName","fanout"); // 声明一个临时队列,队列名自动随机生成 String queue = channel.queueDeclare().getQueue(); // 绑定交换机与队列 // 参数一:队列名称,参数二:交换机名称,参数三:routingkey,此处我们直接给空字符串即可 channel.queueBind(queue,"ExchangeName",""); System.out.println("等待消息接收:"); // 接收消息 channel.basicConsume(queue,true,(tag,message)->{ System.out.println("控制台打印接收到的消息:"+new String(message.getBody())); },tag->{ System.out.println("未接收消息不做处理此处"); }); } } - 消费者二:
- 代码与消费者一相同,只是此处我们使用发布订阅模式,类似广播模式,当生产者发送消息后,因为我们多个消费者都是绑定的同样的扇出类型的交换机,因此多个消费者会同时消费同一消息
- 生产者:
public class EmitLog { public static void main(String[] args)throws Exception { // 获取信道 Channel channel = RabbitUtils.getChannel(); // 此处可以声明交换机,当然因为消费者已经声明,我们这里不用声明,当然也可以再次声明,不会受影响 //channel.exchangeDeclare("ExchangeName","fanout"); // 发送消息,参数一:交换机名称,参数二:routingKey,我们在消费者端定义的空字符串 channel.basicPublish("ExchangeName","",null,"我是消息".getBytes("UTF-8")); } }
- 消费者一:
Direct exchange(直接交换机/路由模式)
-
对比
- 在上一节中,我们构建了一个简单的日志记录系统。也就是前面我们写的发布订阅模式。
- 我们能够向许多接收者广播日志消息,而在本节中我们将向其中添加一些特别的功能,比如说我们只让某个消费者订阅发布的部分消息
- 例如我们只把严重错误消息定向存储到日志文件(以节省空间),同时任然能够在控制台打印所有日志消息
- 我们再次回顾一下什么是bindings,绑定是交换机和队列之间的桥梁,也可以理解:队列只对它绑定的交换机的消息感兴趣。绑定用参数:routingKey表示,也可以称该参数为binding key,创建绑定我们用代码
channel.queueBind(queueName,ExchangeName,"routingKey");绑定之后的意义由其交换机类型决定
-
Direct exchange
-
上一节中的我们的日志系统将所有消息广播给所有消费者,对此我们想做一些改变,例如我们希望将日志消息写入磁盘的程序仅仅接收严重错误(erros),而不存储那些警告(warning)或者信息(info)日志消息避免浪费磁盘空间
-
Fanout这种交换机类型并不能给我们带来很大的灵活性,它只能进行无意识的广播
-
在这里我们将使用Direct这种类型的交换机来进行替换,这种类型的工作方式是,消息只去到它绑定的routingkey队列中去
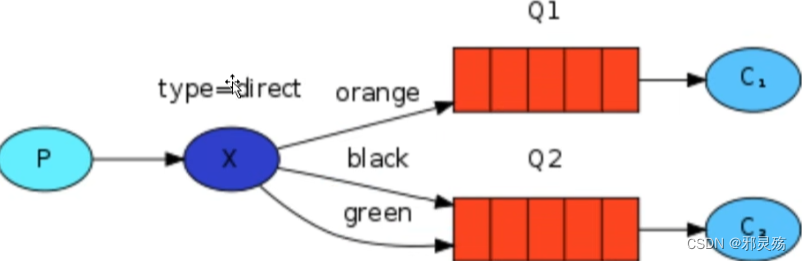
-
在上面这张图中,我们可以看到X绑定了两个队列,绑定类型是direct。队列Q1绑定键(routingKey)为orange,队列Q2绑定键有两个:一个绑定键为black,另一个绑定键位green。
-
在这种绑定情况下,生产者发布消息到exchange上,绑定键为orange的消息将会发布到队列Q1,绑定键为black和green的消息会被发布到队列Q2,其他消息类型的消息将会被丢弃
-
-
多重绑定:
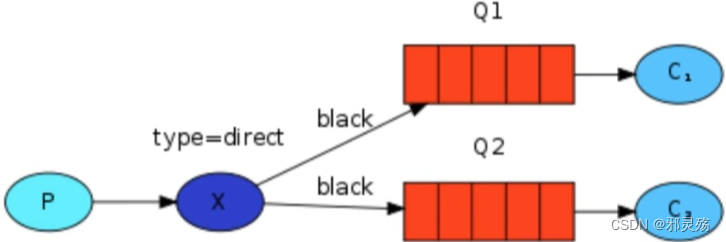
- 当然如果exchange的绑定类型是direct,但是它绑定的多个队列的key如果都相同,这种情况下虽然绑定的类型是direct,但是它表现的就和Fanout有点类似了,就跟广播差不多,如上图所示:
-
实战演练:
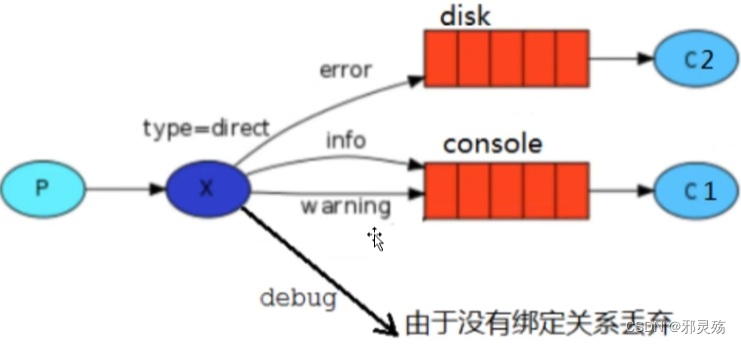
我们可以按照上面图片示例,用代码实现路由模式。-
服务中的路由类型交换机
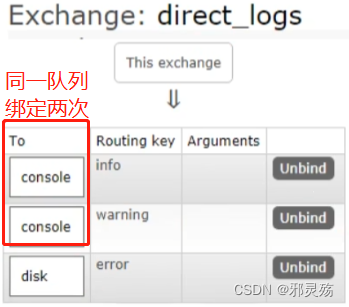
-
代码实现
- console队列,处理info和warning队列
public class ReceiveLogsDirect01{ public static void main(String[]args)throws Exception{ // 获取信道 Channel channel = RabbitUtils.getChannel(); // 声明一个交换机,类型用枚举,声明为路由类型 channel.exchangeDeclare("ExchangeName",BuiltinExchangeType.DIRECT); // 声明一个队列 channel.queueDeclare("console",false,false,true,null); // 用info作为routingKey绑定交换机 channel.queueBind("console","ExchangeName","info"); // 再次绑定一个routingKey,用warning作为绑定次 channel.queueBind("console","ExchangeName","warning"); // 接收消息 channel.gbasicConsume("console",true,(tag,message)->{System.out.println("打印普通日志和警告日志:"+new String(message.getBody(),"UTF-8"));},tag->{}); } } - disk队列,处理error日志
public class ReceiveLogsDirect02{ public static void main(String[]args)throws Exception{ // 获取信道 Channel channel = RabbitUtils.getChannel(); // 声明一个交换机,类型用枚举,声明为路由类型 channel.exchangeDeclare("ExchangeName",BuiltinExchangeType.DIRECT); // 声明一个队列 channel.queueDeclare("disk",false,false,true,null); // 用errot作为routingKey绑定交换机 channel.queueBind("console","ExchangeName","error"); // 接收消息 channel.gbasicConsume("disk",true,(tag,message)->{System.out.println("打印普通日志和警告日志:"+new String(message.getBody(),"UTF-8"));},tag->{}); } } - 生产者
public class EmitLog { public static void main(String[] args)throws Exception { // 获取信道 Channel channel = RabbitUtils.getChannel(); // 发送消息,参数一:交换机名称,参数二:routingKey,我们要发给哪个消费者,就用绑定的routingKey channel.basicPublish("ExchangeName","info(error/warning)",null,"我是消息".getBytes("UTF-8")); }
}
``` - console队列,处理info和warning队列
-
Topics(主题交换机/主题模式)
- 之前类型存在的问题
- 在上一节中,我们改进了日志记录系统。我们没有使用只能进行随意广播的fanout交换机,而是使用了direct直接交换机,从而实现有选择的接收日志
- 尽管使用direct交换机改进了我们的系统,但是它仍然存在局限性,比如说我们想接收的日志类型有info.base和info.advantage,某个队列只想要info.base的消息,那这个时候direct就办不到了。这个时候只能使用topic类型
- Topic的要求
- 发送到类型是topic交换机的 消息的routingKey不能随意写,必须满足一定的要求,它必须是一个单词列表,以点号分隔开。这些单词可以是任意单词,比如说:“stock.usd.nyse”,“nyse.vmw”,“quick.orange.rabbit”这种类型的当然这个单词列表最多不能超过255个字节。
- 在这个规则列表中,其中有两个替换符需要注意:
- *(星号):可以替代一个单词
- #(井号):可以替代零个或多个单词
- Topic匹配案例
-
下图绑定关系如下:
Q1–> 绑定的是:中间带有orange带有3个单词的字符串(*.orange.*)
Q2–>绑定的是:
最后一i个单词是rabbit的3个单词(*.*.rabbit)
第一个单词是lazy的多个单词(lazy.#)
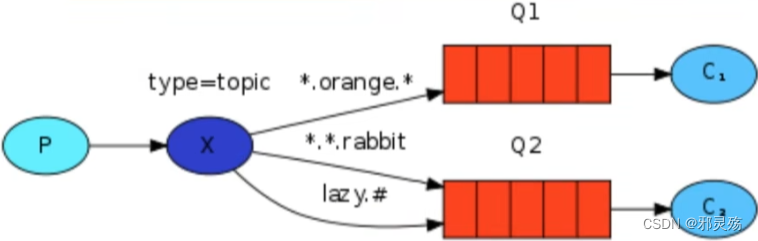
-
上图是一个队列绑定关系,我们可以看看它们之间数据接收情况
quick.orange.rabbit 被队列Q1Q2接收到
lazy.orange.elephant 被队列Q1Q2接收到
quick.orange.fox 被队列Q1接收到
lazy.brown.fox 被队列Q2接收到
lazy.pink.rabbit 虽然满足两个绑定但是都是Q2,所以只能被Q2接收到
quick.brown.fox 不匹配任何绑定,不会被任何队列接收到,会丢弃
quick.orange.male.rabbit 是四个单词,不匹配任何绑定,被丢弃
lazy.orange.male.rabbit 是四个单词,被Q2匹配接收到 -
当队列绑定关系是下列情况时需要注意:
- 当一个队列绑定键是#,那么这个队列将接收所有数据,就有点像fanout了
- 如果队列绑定键当中没有#和*出现,那么该队列只能精确匹配,该类型就是direct类型了
-
- 实战演练
- 消费者一:
public class ReceiveLogTopic01 { public static void main(String[] args) throws Exception{ // 获取信道 Channel channel = RabbitUtils.getChannel(); // 声明交换机 channel.exchangeDeclare("ExchangeName", BuiltinExchangeType.TOPIC); // 声明队列 channel.queueDeclare("队列1",false,false,true,null); // 绑定交换机 channel.queueBind("队列1","ExchangeName","*.change.*"); System.out.println("等待接收消息:"); channel.basicConsume("队列1",true,(tag,message)->{ System.out.println("接收消息未:"+message.getBody()); System.out.println("绑定关键词为:"+message.getEnvelope().getRoutingKey()); }, tag->{}); } } - 消费者二:
public class ReceiveLogTopic01 { public static void main(String[] args) throws Exception{ // 获取信道 Channel channel = RabbitUtils.getChannel(); // 声明交换机 channel.exchangeDeclare("ExchangeName", BuiltinExchangeType.TOPIC); // 声明队列 channel.queueDeclare("队列2",false,false,true,null); // 绑定交换机 channel.queueBind("队列2","ExchangeName","*.*.rabbit"); // 绑定另一个规则 channel.queueBind("队列2","ExchangeName","layz.#"); System.out.println("等待接收消息:"); channel.basicConsume("队列2",true,(tag,message)->{ System.out.println("接收消息未:"+message.getBody()); System.out.println("绑定关键词为:"+message.getEnvelope().getRoutingKey()); }, tag->{}); } } - 生产者:
public class EmitLog { public static void main(String[] args)throws Exception { // 获取信道 Channel channel = RabbitUtils.getChannel(); // 此处可以声明交换机,当然因为消费者已经声明,我们这里不用声明,当然也可以再次声明,不会受影响 //channel.exchangeDeclare("ExchangeName","fanout"); // 发送消息,参数一:交换机名称,参数二:routingKey,我们在消费者端定义的空字符串 channel.basicPublish("ExchangeName","quick.orange.rabbit",null,"我是消息1,被Q1和Q2同时接收".getBytes("UTF-8")); channel.basicPublish("ExchangeName","quick.orange.fox",null,"我是消息1,被Q1接收".getBytes("UTF-8")); channel.basicPublish("ExchangeName","lazy.brown.fox",null,"我是消息1,被Q2接收".getBytes("UTF-8")); channel.basicPublish("ExchangeName","lazy.pink.rabbit",null,"我是消息1,被Q2接收".getBytes("UTF-8")); } }
- 消费者一:
死信队列
死信的概念
- 先从概念解释上搞清楚这个定义,死信,顾名思义就是无法被消费的消息,字面意思可以这样理解
- 一般来说,producer将消息投递到broker或者直接到queue里了,consumer从queue取出消息进行消费
- 但某些时候由于特定原因导致queue中的某些消息无法被消费,这样的消息如果没有后续处理,就变成死信了,有死信自然就有了死信队列
- 应用场景:为了保证订单业务的消息数据不丢失,需要使用到RabbitMQ的死信队列机制,当消息消费发送异常时,将消息投入死信队列中。还比如说,用户在商城下单成功点击去支付后在指定时间未支付时自动失效等
死信的来源
- 消息TTL(存活时间)过期(过了存活时间没有被消费)
- 队列达到最大长度(队列满了,无法再添加数据到MQ中)
- 消息被拒绝(basic.reject或basic.nack)并且requeue=false(不放回队列中)
死信实战
- 代码架构
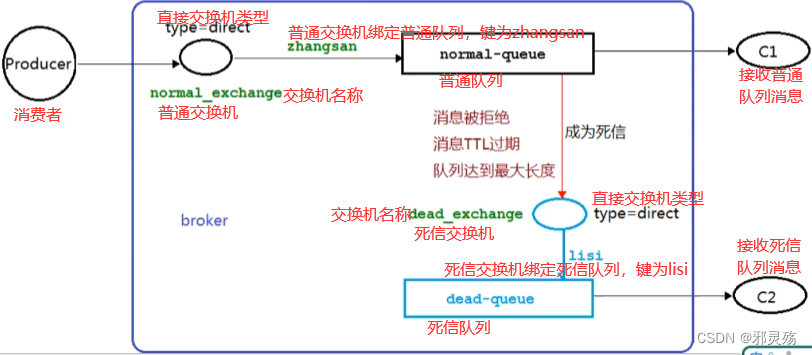
- 代码实现(消息TTL),我们先启动消费者一,创建交换机及队列,以及绑定对应关系,然后停掉消费者一,模拟长时间不接受消息,然后启动生产者发送消息,这样所有发送的消息都没有被正常接收,二十进入了死信队列,再由消费者二从死信队列中进行接收即可
- 消费者一(普通消费者)
public class Consumer01 { // 普通交换机名称 public static final String NORMAL_EXCHANGE = "normal_exchange"; // 普通队列名称 public static final String NORMAL_QUEUE = "normal_queue"; // 死信交换机名称 public static final String DEAD_EXHCANGE = "dead_exchange"; // 死信队列名称 public static final String DEAD_QUEUE = "dead_queue"; public static void main(String[] args) throws Exception{ // 创建信道 Channel channel = RabbitUtils.getChannel(); // 申明普通交换机,类型为直接交换机 channel.exchangeDeclare(NORMAL_EXCHANGE, BuiltinExchangeType.DIRECT); // 申明普通队列 /** * 这里需要参数,设置普通队列的消息不被接收后发送到死信队列,因此需要参数,就是最后一个参数,Map类型的键值对 */ Map<String, Object> map = new HashMap<>(); // 设置转发的死信交换机 map.put("x-dead-letter-exchange",DEAD_EXHCANGE); // 设置死信交换机的RoutingKey绑定键,绑定关键字自定义即可 map.put("x-dead-letter-routing-key","lisi"); // 设置过期时间,但是这里设置意味着所有该队列的消息都是这个时间过期,我们可以再生产者发消息时设置,比较灵活,当前发送的消息单独设置,这里旧不设置了 //map.put("x-message-ttl",1000);// 单位时毫秒 channel.queueDeclare(NORMAL_QUEUE,false,false,true,map); // 声明死信交换机,类型为直接交换机 channel.exchangeDeclare(DEAD_EXHCANGE,BuiltinExchangeType.DIRECT); // 声明死信队列 channel.queueDeclare(DEAD_QUEUE,false,false,true,null); // 将普通交换机和普通队列进行绑定 channel.queueBind(NORMAL_QUEUE,NORMAL_EXCHANGE,"zhangsan"); // 将死信队列和死信交换机进行绑定 channel.queueBind(DEAD_QUEUE,DEAD_EXHCANGE,"lisi"); System.out.println("等待接收消息。。。。。。"); // 接收消息,消费者一正常接收消息 channel.basicConsume(NORMAL_QUEUE,true,(tag,message)->{ // 接收消息 System.out.println("接收到的消息为:"+new String(message.getBody(),"UTF-8")); },tag->{}); } } - 消费者二(死信消费者),就是普通消费者,只是从死信队列中提取消息
public class Consumer02 { // 死信队列名称 public static final String DEAD_QUEUE = "dead_queue"; public static void main(String[] args) throws Exception{ // 创建信道 Channel channel = RabbitUtils.getChannel(); // 接收消息 channel.basicConsume(DEAD_QUEUE,true,(tag,message)->{ System.out.println("接收到死信消息:"+new String(message.getBody(),"UTF-8")); },tag->{}); } } - 生产者
public class Procedurer { public static final String NORMAL_EXCHANGE = "normal_exchange"; public static void main(String[] args) throws Exception{ // 创建信道 Channel channel = RabbitUtils.getChannel(); // 发送消息,设置过期时间,因为我们在消息接收方没有设置,这里直接在发送时就告诉队列,多久过期 // 下面这个参数就是设置过期时间为1000毫秒,并且发送消息到普通交换机,绑定关键字为zhangsan AMQP.BasicProperties properties = new AMQP.BasicProperties().builder().expiration("1000").build(); channel.basicPublish(NORMAL_EXCHANGE,"zhangsan",properties,"我是消息".getBytes("UTF-8")); // 再发一条消息,设置过期时间为10s AMQP.BasicProperties propertie = new AMQP.BasicProperties().builder().expiration("10000").build(); channel.basicPublish(NORMAL_EXCHANGE,"zhangsan",propertie,"我是消息02".getBytes("UTF-8")); } }
- 消费者一(普通消费者)
- 代码实现(队列达到最大长度),消费者二不变,与上面一样,只是从死信队列中消费消息而已,没有特殊设置,只是将我们过期时间的设置改为最大长度限制即可,需要注意的是,这里要在消费者一中队普通队列进行设置,不能在生产者设置了,就是设置普通队列的消息堆积条数,这里的长度就是消息堆积条数,已经消费的不算,也就是只能存我们设置的条数的消息,超过的没有被消费的消息才会存入到死信队列中,其他不管,其次删掉之前的过期时间的设置,然后删除队列,因为之前的队列属性已经设置死了,要重新设置重新声明
- 消费者一(普通消费者)
public class Consumer01 { // 普通交换机名称 public static final String NORMAL_EXCHANGE = "normal_exchange"; // 普通队列名称 public static final String NORMAL_QUEUE = "normal_queue"; // 死信交换机名称 public static final String DEAD_EXHCANGE = "dead_exchange"; // 死信队列名称 public static final String DEAD_QUEUE = "dead_queue"; public static void main(String[] args) throws Exception{ // 创建信道 Channel channel = RabbitUtils.getChannel(); // 申明普通交换机,类型为直接交换机 channel.exchangeDeclare(NORMAL_EXCHANGE, BuiltinExchangeType.DIRECT); // 申明普通队列 /** * 这里需要参数,设置普通队列的消息不被接收后发送到死信队列,因此需要参数,就是最后一个参数,Map类型的键值对 */ Map<String, Object> map = new HashMap<>(); // 设置转发的死信交换机 map.put("x-dead-letter-exchange",DEAD_EXHCANGE); // 设置死信交换机的RoutingKey绑定键,绑定关键字自定义即可 map.put("x-dead-letter-routing-key","lisi"); // 设置过期时间,但是这里设置意味着所有该队列的消息都是这个时间过期,我们可以再生产者发消息时设置,比较灵活,当前发送的消息单独设置,这里旧不设置了 //map.put("x-message-ttl",1000);// 单位时毫秒 // 设置该队列消息堆积最大条数,堆积多余6条的消息将被转发到死信队列 map.put("x-max-length",6); channel.queueDeclare(NORMAL_QUEUE,false,false,true,map); // 声明死信交换机,类型为直接交换机 channel.exchangeDeclare(DEAD_EXHCANGE,BuiltinExchangeType.DIRECT); // 声明死信队列 channel.queueDeclare(DEAD_QUEUE,false,false,true,null); // 将普通交换机和普通队列进行绑定 channel.queueBind(NORMAL_QUEUE,NORMAL_EXCHANGE,"zhangsan"); // 将死信队列和死信交换机进行绑定 channel.queueBind(DEAD_QUEUE,DEAD_EXHCANGE,"lisi"); System.out.println("等待接收消息。。。。。。"); // 接收消息,消费者一正常接收消息 channel.basicConsume(NORMAL_QUEUE,true,(tag,message)->{ // 接收消息 System.out.println("接收到的消息为:"+new String(message.getBody(),"UTF-8")); },tag->{}); } }
- 消费者一(普通消费者)
- 代码实现(消息被拒),这里消费者二也不变,生产者依然只管发送消息,只是消费者一在消费普通队列消息时进行了拒绝,同时不允许重新进入队列,该消息就会发送到死信队列,因此,需要改造消费者一的消费接收消息的代码进行消息的拒绝接收
- 消费者一(普通消费者)
public class Consumer01 { // 普通交换机名称 public static final String NORMAL_EXCHANGE = "normal_exchange"; // 普通队列名称 public static final String NORMAL_QUEUE = "normal_queue"; // 死信交换机名称 public static final String DEAD_EXHCANGE = "dead_exchange"; // 死信队列名称 public static final String DEAD_QUEUE = "dead_queue"; public static void main(String[] args) throws Exception{ // 创建信道 Channel channel = RabbitUtils.getChannel(); // 申明普通交换机,类型为直接交换机 channel.exchangeDeclare(NORMAL_EXCHANGE, BuiltinExchangeType.DIRECT); // 申明普通队列,这里不需要参数,直接在接收消息时拒绝即可 channel.queueDeclare(NORMAL_QUEUE,false,false,true,null); // 声明死信交换机,类型为直接交换机 channel.exchangeDeclare(DEAD_EXHCANGE,BuiltinExchangeType.DIRECT); // 声明死信队列 channel.queueDeclare(DEAD_QUEUE,false,false,true,null); // 将普通交换机和普通队列进行绑定 channel.queueBind(NORMAL_QUEUE,NORMAL_EXCHANGE,"zhangsan"); // 将死信队列和死信交换机进行绑定 channel.queueBind(DEAD_QUEUE,DEAD_EXHCANGE,"lisi"); System.out.println("等待接收消息。。。。。。"); // 接收消息,消费者一正常接收消息,既然要拒绝接收,也有正常接收,就要手动应答,不能自动应答 channel.basicConsume(NORMAL_QUEUE,false,(tag,message)->{ // 这里对消息判断,如果消息时info,则拒绝接收 String mess = new String(message.getBody(),"UTF-8"); if("info".equalse(mess)) { // 如果消息时info,那么拒绝接收,且不放回普通队列,参数二false表示不放回 channel.basicReject(message.getEnvelope().getDeliveryTag(),false); } else { // 如果时其他消息,则正常接收且进行应答 System.out.println("接收到其他的消息:"+new String(msg)); // 手动应答,且关闭批量应答 channel.basicAck(message.getEnvelope().getDeliveryTag(),false); } System.out.println("接收到的消息为:"+new String(message.getBody(),"UTF-8")); },tag->{}); } }
- 消费者一(普通消费者)
延迟队列(死信队列中TTL过期的情况)
延迟队列概念
- 延迟队列,队列内部是有序的,最重要的特性就是体现在它的延时属性上
- 延时队列中的元素是希望在指定时间到了以后或之前取出和处理,简单来说,延时队列就是用来存放需要在指定时间被处理的元素的队列
- 在前面死信队列中,如果没有消费者一,只有消费者二,且将消息设置过期时间,这样当消息由生产者发送到普通交换机,再有普通交换机发送到普通队列时,没有消费者能够消息,只能等过期,过期时间一到,消息就由普通队列转发到死信交换机
- 此时我们的消费者二就可以从死信队列中消费消息了,而中间的在普通队列中停留的时间就是我们设置的过期时间,也就是生产者发送消息到消费者消费消息的延迟时间
- 而这样以来,消息的延迟时间完全取决于生产者,因为我们生产者发送消息时就可以设置该消息的过期时间
延迟队列使用场景
-
订单在十分钟之内未支付则自动取消
-
新创建的店铺,如果在十天内都没有上传过商品,则自动发送消息提醒
-
用户注册成功后,如果三天内没有登陆则进行短信提醒
-
用户发起退款,如果三天内没有得到处理则通知相关运营人员
-
预定会议后,需要在预定的时间点前十分钟通过各个与会人员参加会议
这些场景都有一个特点,需要在某个时间发生之后或者之前的指定时间点完成某一项任务,例如:
发生订单生成事件,在十分钟之后检查该订单支付状态,然后将未支付的订单进行关闭
看起来似乎使用定时任务,一直轮询数据,每秒查一次,取出需要被处理的数据,然后处理不就完事了嘛,如果数据量比较少,确实可以这样做,比如:
对于“如果账单一周内未支付则进行自动结算”这样的需求,如果对于时间不严格限制,而是宽松定义上的一周,那么每天晚上跑个定时任务检查一下所有未支付的账单,确实时一个可行的方案
但对于数据量比较大,并且时效性比较强的场景,例如:“订单十分钟内未支付则关闭”,短期内未支付的订单数据可能会很多,活动期间甚至会达到百万甚至千万级别,对这么庞大的数据量仍旧使用轮询的方式显然时不可取的,很可能在一秒内无法完成所有订单检查,同时会给数据库带来很大的压力,无法满足业务要求而且性能低下

RabbitMQ中的TTL
- 消息设置TTL
- 队列设置TTL
- 两者的区别
整合SpringBooot
- 创建项目
- 创建普通的Springboot空项目即可
- 添加依赖
<dependencies> <!--springBoot启动依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <!--springBoot测试依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <!--springBoot服务依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--alibaba处理JSON依赖--> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.75</version> </dependency> <!--lombok快速构建实体类依赖--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> <!--RabbitMQ依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency> <!--RabbitMQ测试依赖--> <dependency> <groupId>org.springframework.amqp</groupId> <artifactId>spring-rabbit-test</artifactId> <scope>test</scope> </dependency> <!--swagger依赖--> <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger2</artifactId> <version>2.9.2</version> </dependency> <!--swagger界面依赖--> <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger-ui</artifactId> <version>2.9.2</version> </dependency> </dependencies> - 修改配置文件
spring: rabbitmq: host: 192.168.0.200 # rabbitmq的服务IP地址 pott: 5672 # rabbitmq的服务端口号 username: root # 用户名 password: root # 密码 - 添加Swagger配置类(Swagger界面用,用于RabbitMQ测试)
@Configuration @EnableSwagger2 public class SwaggerConfig { @Bean public Docket webApiConfig() { return new Docket(DocumentationType.SWAGGER_2) .groupName("webApi") .apiInfo(webApiInfo()) .select().build(); } private ApiInfo webApiInfo() { return new ApiInfoBuilder() .title("RabbitMQ接口文档") .description("本文描述了RabbitMQ微服务接口定义") .version("1.0.0") .contact(new Contact("admin","http://www.baidu.com","1075295452@qq.com")) .build(); } }
队列TTL
-
代码架构图
- 创建两个普通队列QA和QB,两者队列TTL分别设置为10s和40s过期(延迟时间)
- 再创建一个普通交换机X和死信交换机Y,它们的类型都是direct(直接交换机)
- 再创建一个死信队列QD,用于接收QA和QB过期后转发的消息
- 然后使用P生产者发送消息给普通交换机,通过绑定不同的RountingKey,发送到不同的普通队列,实现不同的延迟时间
- 最后再使用C消费者从死信队列中消费消息即可

-
配置文件代码(所有需要声明的以及绑定的)
- 之前的交换机、队列声明绑定都是一般在消费者代码中
- 在springboot中可以放在单独的配置文件代码中,来声明所有需要的交换机以及所有需要的队列和相互之间的绑定关系
- 我们只完成生产者发送消息和消费者接收消息即可
/** * @Author: King * @Date: 2023/4/8 00:54 * @Description: 延迟队列配置文件 * @version: 1.0 */ @Configuration public class TTLQueueConf { // 普通交换机名称 public static final String NOMAL_EXCHANGE = "nomal_exchange"; // 死信交换机名称 public static final String DEAD_EXCHANGE = "dead_exchange"; // 两个普通队列名称 public static final String NOMAL_QUEUE_QA = "nomal_queue_qa"; public static final String NOMAL_QUEUE_QB = "nomal_queue_qb"; // 死信队列名称 public static final String DEAD_QUEUE = "dead_queue"; /** * @return 直接交换机类型对象 * @description 声明普通交换机 */ @Bean("nomal_exchange") // 别名,spring注入时名称,一般与方法名同名即可 public DirectExchange nomal_exchange() { return new DirectExchange(NOMAL_EXCHANGE); } /** * @return 直接交换机类型对象 * @description 声明死信交换机 */ @Bean("dead_exchange") public DirectExchange dead_exchange() { return new DirectExchange(DEAD_EXCHANGE); } /** * @return 队列Queue类型对象 * @description 声明普通队列一 */ @Bean("nomal_queue_qa") public Queue nomal_queue_qa() { // 创建需要设置的参数Map对象 Map<String, Object> map = new HashMap<>(3); // 设置死信交换机名称 map.put("x-dead-letter-exchange",DEAD_EXCHANGE); // 设置绑定死信交换机RoutingKey map.put("x-dead-letter-routing-key","YD"); // 设置过期时间为10s map.put("x-message-ttl",10000); return QueueBuilder.durable(NOMAL_QUEUE_QA).withArguments(map).build(); } /** * @return 队列Queue类型对象 * @description 声明普通队列二 */ @Bean("nomal_queue_qb") public Queue nomal_queue_qb() { // 创建需要设置的参数Map对象 Map<String, Object> map = new HashMap<>(3); // 设置死信交换机名称 map.put("x-dead-letter-exchange",DEAD_EXCHANGE); // 设置绑定死信交换机RoutingKey map.put("x-dead-letter-routing-key","YD"); // 设置过期时间为40s map.put("x-message-ttl",40000); return QueueBuilder.durable(NOMAL_QUEUE_QB).withArguments(map).build(); } /** * @return 队列Queue类型对象 * @description 声明死信队列,不需要特殊设置 */ @Bean("dead_queue") public Queue dead_queue() { return QueueBuilder.durable(DEAD_QUEUE).build(); } /** * @return 返回绑定对象Binding * @description 将普通队列一与普通交换机绑定 * 绑定时需要普通队列对象和普通交换机对象,我们上面声明再了spring容器中 * 再这里,我们在参数中传入两个对象即可 * 需要注意的是连个对象声明在spring容器中,我们借助@Qualifier注解从spring容器中注入 */ @Bean public Binding nomalQueueABinding(@Qualifier("nomal_queue_qa")Queue queueA, // @Qualifier从容器中注入对象 @Qualifier("nomal_exchange")DirectExchange exchange) { // 绑定队列A到交换机用XA作为RoutingKey return BindingBuilder.bind(queueA).to(exchange).with("XA"); } /** * @return 返回绑定对象Binding * @description 将普通队列二与普通交换机绑定 * 绑定时需要普通队列对象和普通交换机对象,我们上面声明再了spring容器中 * 再这里,我们在参数中传入两个对象即可 * 需要注意的是连个对象声明在spring容器中,我们借助@Qualifier注解从spring容器中注入 */ @Bean public Binding nomalQueueBBinding(@Qualifier("nomal_queue_qb")Queue queueA, // @Qualifier从容器中注入对象 @Qualifier("nomal_exchange")DirectExchange exchange) { // 绑定队列B到交换机用XA作为RoutingKey return BindingBuilder.bind(queueA).to(exchange).with("XB"); } /** * @return 返回绑定对象Binding * @description 将死信队列与死信交换进行绑定 * 绑定时需要普通队列对象和普通交换机对象,我们上面声明再了spring容器中 * 再这里,我们在参数中传入两个对象即可 * 需要注意的是连个对象声明在spring容器中,我们借助@Qualifier注解从spring容器中注入 */ @Bean public Binding deadQueueBinding(@Qualifier("dead_queue")Queue queue, // @Qualifier从容器中注入对象 @Qualifier("dead_exchange")DirectExchange exchange) { // 绑定死信队列绑定到死信交换机,用YD作为RoutingKey return BindingBuilder.bind(queue).to(exchange).with("YD"); } }
-
生产者(用Controller请求接口,将请求接收的数据作为消息发送到交换机)
@Slf4j @RestController @RequestMapping("/ttl") public class SendMsgController { // 该对象为Spring提供操作RabbitMQ对象 @Resource private RabbitTemplate rabbitTemplate; @GetMapping("/sendMsg/{message}") public void sendMsg(@PathVariable("message")String message) { log.info("当前时间:{},发送一条消息给两个普通队列,消息为:{}",new Date().toString(),message); // 参数一:交换机名称,参数二:队列名称,参数三:要发送的消息 rabbitTemplate.convertAndSend("nomal_exchange","nomal_queue_qa",message); // 给队列二同时发送,两个队列同时发送,过期时间不同 rabbitTemplate.convertAndSend("nomal_exchange","nomal_queue_qb",message); log.info("消息发送完毕!!!"); } } -
消费者(要随时监听,就是一个监听器,@RabbitListener对应队列即可)
@Slf4j @Component public class DeadQueueConsumer { // 监听队列,后面是要监听的队列名称 @RabbitListener(queues = "dead_queue") // Channel不用可以不写 public void receiveDeadQueue(Message message, AMQP.Channel channel) { String msg = new String(message.getBody()); log.info("当前时间为:{},收到死信队列的消息:{}",new Date().toString(),msg); } } -
启动Springboot项目,然后进行访问,传入需要发送的消息即可实现效果:
- 第一条消息在10s后变成了死信消息,然后被消费者消费掉,第二条消息在40s之后变成了死信消息,然后被消费掉,这样一个延迟队列就打造完成了
- 不过,如果是这样使用的话,岂不是每增加一个新的时间需求,就要新增一个队列,这里只有10s和40s两个时间选项,如果需要一小时之后处理,那么就需要增加TTL(超时时间)为一小时的队列,如果是预定会议然后提前通知这样的场景,岂不是每次要根据预定时间增加要给队列,要增加无数队列才能满足需求
延迟队列优化
-
代码结构图
- 这里新增一个队列QC,绑定关系如下,也就是跟之前一样的普通队列,唯独不设置延迟时间,而是之前我们说过的,由生产者发送消息时设置延迟时间,这样一来无论需要延时多久,都是随着发送消息进行设置

- 这里新增一个队列QC,绑定关系如下,也就是跟之前一样的普通队列,唯独不设置延迟时间,而是之前我们说过的,由生产者发送消息时设置延迟时间,这样一来无论需要延时多久,都是随着发送消息进行设置
-
配置文件类代码
@Configuration public class RabbitConf{ // 普通队列QC名称 public static final String NOMAL_QUEUE = "nomal_queue"; // 普通交换机名称 public static final String NOMAL_EXCHANGE = "nomal_exchange"; // 死信队列名称 public static final String DEAD_QUEUE = "dead_queue"; // 死信交换机名称 public static final String DEAD_EXCHANGE = "dead_exchange"; // 声明普通队列 @Bean("nomal_queue") public Queue noaml_queue() { Map<String,Object> map = new HashMap<>(2); // 设置死信交换机 map.put("x-dead-letter-exhcange",DEAD_EXCHANGE); // 设置死信RoutingKey map.put("x-dead-letter-routing-key","YD"); return QueueBuilder.durable(NOMAL_QUEUE).withArguments(map).build(); } // 声明死信队列 @Bean("dead_queue") public Queue dead_queue() { return QueueBuilder.durable(DEAD_QUEUE).build(); } // 声明普通交换机 @Bean("nomal_exchange") public DirectExchange nomal_exchange(){ return new DirectExchange(NOMAL_EXCHANGE); } // 声明死信交换机 @Bean("dead_exhcange") public DirectExchange dead_exhcange(){ return new DirectExchange(DEAD_EXCHANGE); } // 绑定普通队列到普通交换机 @Bean public Binding nomalQueueToNomalExchange(@Qualifier("nomal_queue") Queue queue,@Qualifier("nomal_exchange") DirectExchange exchange) { return BindingBuilder.bind(queue).to(exchange).with("xc"); } // 绑定死信队列到死信交换 @Bean public Binding deadQueueToDeadExchange(@Qualifier("dead_queue") Queue queue,@Qualifier("dead_exchange") DirectExchange exchange) { return BindingBuilder.bind(queue).to(exchange).with("YD"); } } -
生产者(发送消息时设置过期时间)
@Slf4j @RestController @RequestMapping("/ttl") public class SendMsgController { // 该对象为Spring提供操作RabbitMQ对象 @Resource private RabbitTemplate rabbitTemplate; @GetMapping("/sendMsg/{message}") public void sendMsg(@PathVariable("message")String message) { log.info("当前时间:{},发送一条消息给普通队列,消息为:{}",new Date().toString(),message); // 参数一:交换机名称,参数二:队列名称,参数三:要发送的消息,参数四:函数是接口,设置过期时间 rabbitTemplate.convertAndSend("nomal_exchange","nomal_queue",message,msg->{ // 设置过期时间为10S,需要注意过期时间为Sting类型 msg.getMessageProperties().setExpiration("10000"); // 将msg原样返回 return msg; }); log.info("消息发送完毕!!!"); } } -
消费者
- 与前面一样,普通的消费者,负责监听死信队列,接收消息即可
延迟队列(基于死信存在的问题)
-
我们按照上面优化后的代码运行,发送两条消息,第一天设置过期时间为20S,第二条设置过期时间为2S
-
按照我们理解的,应该时第二条消息先过期被转发到死信队列,然后由消费者接收,然后到20S过期时间之后,第一条消息才会被转发到死信队列,由消费者进行接收
-
但是实际情况却不是这样的,而是一直到20S之后,两条消息同时被消费者所接收

-
我们在最开始的时候,就介绍过如果使用在消息属性上设置TTL的方式,消息可能不会按时死亡,因为Rabbit MQ只会检查第一个消息是否过期,如果过期则丢到死信队列,如果第一个消息的延时时间很长,而第二个消息的延时时间很短,第二个消息不回优先得到执行
-
也就是说消息时按照顺序进行转发的,直到第一个消息被丢到死信队列之后,才会执行后续的消息处理
-
所以当第一条消息过期后,再执行第二条消息发现也已经过期,就同时被转发到死信队列,然后由消费者同时进行消费
基于插件的延迟队列(弥补上面提到的死信延时缺陷)
上面提到的问题,确实时一个问题,如果不能实现在消息粒度上的TTL,并使其在设置的TTL时间及时死亡,就无法设计成一个通用的延时队列
那么接下来我们尝试解决这个问题,使用插件的方式进行处理
-
安装延时队列插件
- 在官网上下载:https://www.rabbitmq.com/community-plugins.html
- 下载rabbitmq_delayed_message_exchange插件,然后解压放置到Rabbit MQ的插件目录
- 进入到Rabbit MQ的安装目录下的plugins目录,执行下面命令让该插件生效,然后重启Rabbit MQ
- 进入目录:
/usr/lib/rabbitmq/lib/rabbitmq_server-3.8.8/plugins - 执行命令:
rabbitmq-plugins enable rabbitmq_delayed_message_exchange
-
代码架构图
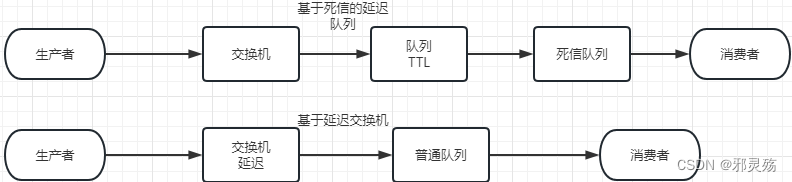
-
配置文件类代码(延迟交换机,普通队列,绑定)
- 在我们自定义的交换机中,这是一种新的交换机类型(由前面的插件提供)
- 该类型消息支持延迟投递机制,消息传递后并不会立即投递到目标队列中,而是存储在mnesia(一个分布式数据系统)表中
- 当达到投递时间时,才投递到目标队列中
@Configuration public class DelayedQueueConfig { // 队列名称 public static final String DELAYED_QUEUE_NAME = "delayed.queue"; // 交换机名称 public static final String DELAYED_EXCHANGE_NAME = "dealyed.exchange"; // 绑定RoutingKey public static final String DELAYED_ROUTING_KEY = "delayed.routingkey"; // 声明队列,就是一个普通队列 @Bean public Queue delayedQueue() { return new Queue(DELAYED_QUEUE_NAME); } // 声明交换机,这里不能用前面的直接交换机,也不能用扇出等已有类型交换,而是要用自定义交换 @Bean public CustomExchange delayedExchange() { /** * 参数一:交换名称 * 参数二:交换机类型 * 参数三:是否需要持久化 * 参数四:是否自动删除 * 参数五:其他参数,依然时Map类型 */ Map<String,Object> map = new HashMap<>(); // 延迟类型,为直接类型 map.put("x-delayed-type","direct"); return new CustomExchange(DELAYED_EXCHANGE_NAME,"x-delayed-message",true,false,map); } // 交换机与队列进行绑定,当前面声明队列与交换机没有在Bean指定名称,默认就是方法名 @Bean public Binding delayedQueueExchange(@Qualifier("delayedQueue")Queue queue,@Qualifier("delayedExchange")CustomExchange exchange) { return BindingBuilder.bind(queue).to(exchange).with(DELAYED_ROUTING_KEY).noargs(); } }
-
生产者
@Slf4j @RestController @RequestMapping("/delayed") public class RabbitController() { @Resource private RabbitTemplate rabbitTemplate; @GetMapping("/sendDelayMsg/{message}/{delayTime}") public void sendMsg(@PathVariable String message,@PathVaribale Integer delayTime) { log.info("当前时间:{},发送一条时长{}毫秒TTL信息给队列,消息为:{}",new Date().toString(),delayTime,message); rabbitTemplate.convertAndSend(DelayedQueueConfig.DELAYED_EXCHANGE_NAME,DelayedQueueConfig.DELAYED_ROUTING_KEY,message,msg->{ // 设置发送消息的延迟时间,类型为Integer,单位为ms msg.getMessageProperties().setDelay(delayTime); return msg; }); } } -
消费者
@Slf4j @Component public class DelayQueueConsumer{ // 监听队列 @RabbitListener(queues = DelayedQueueConfig.DELAYED_QUEUE_NAME) public void receiverDelayQueue(Message message) { String msg = new String(message.getBody()); log.info("当前时间:{},收到延迟消息:{}",new Date().toString(),msg); } } -
测试结果
- 还时像之前一样,发送两条消息,第一条消息设置20S延迟时间,第二条消息设置2S的延迟时间
- 发送之后会发现如我们预期的效果,第二条消息两秒之后被消费者接收,第一条消息一直到20S之后才被消费者接收
- 第二条消息被先消费,符合预期的结果
-
总结
- 延时队列在需要延时处理的场景下非常有用,使用Rabbit MQ来实现延时队列可以很好的利用RabbitMQ的特性
- 比如消息可靠发送、消息可靠投递、死信队列来保障消息至少被消费一次以及未被正确处理的消息不会被丢弃
- 另外,通过RabbitMQ集群的特性,可以很好的解决单点故障问题,不会因为单个节点挂掉导致延时队列不可用或者消息丢失
- 当然延时队列还有很多其他选择,比如利用Java的DelayQueue,利用Redis的zset,利用Quartz或者利用kafka的时间轮,这些方式各有特点,根据实际需求选择利用不同的技术栈
发布确认(高级)
- 在生产环境中由于一些不明原因,导致RabbitMQ重启,在RabbitMQ启动期间生产者消息投递失败,导致消息丢失,需要手动处理和恢复
- 于是,我们开始思考,如何才能进行RabbitMQ的消息可靠投递呢,特别时在这样比较极端的情况下,RabbitMQ集群不可用的时候,无法投递的消息该如何处理呢
发布确认SpringBoot版本
-
确认机制方案
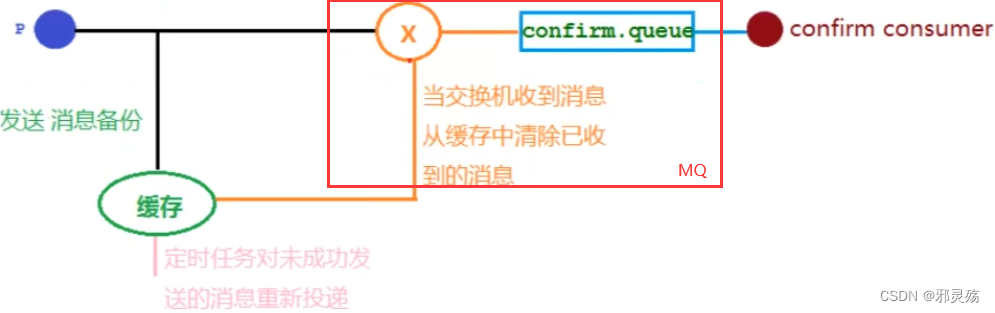
-
代码架构图(下图时正常情况,我们要在这个情况下加缓存机制)

-
配置文件(在配置文件中添加下面配置)
spring: rabbitmq: publisher-confirm-type: correlated- NONE:禁用发布确认模式,时默认值
- CORRELATED:发布消息成功后交换器会触发回调方法
- SIMPLE:经过测试有两种效果,分别如下:
- 效果一:和CORRELATED值一样会触发回调方法
- 效果二:发布消息成功后使用rabbitTemplate调用waitForConfirms或waitForConfirmsOrDie方法等待broker节点返回发送结果,根据返回结果判定下一步的逻辑,需要注意的是,waitForConfirmsOrDie方法如果返回false则会关闭channel,则接下来无法发送消息到broker
- 类似与我们之前最早使用的同步确认,就是发送一条消息确认一次
- 完整的配置项:
spring: rabbitmq: host: 192.168.0.200 port: 5672 username: root password: root publisher-confirm-type: correlated
-
添加配置类(配置交换机和队列)
@Configuration public class RabbitConfig { public static final String CONFIRM_EXCHANGE_NAME = "confirm.exchange"; public static final String CONFIRM_QUEUE_NAME = "confirm.queue"; // 声明业务Exchange @Bean public DirectExchange confirmExchange() { return new DirectExchange(CONFIRM_EXCHANGE_NAME); } // 声明确认队列 @Bean public Queue confirmQueue() { return QueueBuilder.durable(CONFIRM_QUEUE_NAME).build(); } // 将队列绑定到交换 @Bean public Binding queueBinding(@Qualifier("confirmQueue") Queue queue,@Qualifier DirectExchange exchange) { return BindingBuilder.bind(queue).to(exchange).with("key"); } } -
消息生产者(虽然下面回调函数接口我们写好了,但是里面的CorrelationData这个参数时没有的,因为这个参数时消息相关的数据,是由消息生产者给的,因此我们在发送消息时,要填写这个参数,这样回调的时候,才会有这个参数的值)
@Slf4j @RestController @RequestMapping("/confirm") public class ProducerController { @Resouce private RabbitTemplate rabbitTemplate; // 发送消息 @GetMapping("/sendMessage/{message}") public void sendMessage(@PathVariable String message) { // 最后一个参数就是我们回调中用到的第一个参数,需要我们自己指定 // 该对象中有id和message两个属性,我们因为在回调中用到了id,因此这里我们设置id即可,直接在构造函数中给定id值 CorrelationData correlationData = new CorrelationData("1"); rabbitTemplate.convertAndSend(RabbitConfig.CONFIRM_EXCHANGE_NAME,"key",message); } } -
回调接口(是Rabbit的交换机收到消息确认接口,实现自己的逻辑即可)
@Slf4j @Component public class RabbitConfirmCallback implements RabbitTemplate.ConfirmCallback { // 因为该接口时RabbitTemplate内部接口,我们这样实现之后并不能生效,因此要手动注入到RabbitTemplate中去,这里先引入RabbitTemplate这个对象 @Resouce private RabbitTemplate rabbitTemplate; // 我们定义一个方法,放当前这个实现类注入给RabbitTemplate这个类 @PostConstruct // 这个注解的作用可以实现在运行工程时,自动运行该注解下的方法 public void init() { // 将当前我们这个实现了对象this,设置给RabbitTemplate rabbitTemplate.setConfirmCallback(this); } /** * 该回调,无论交换机是否收到生产者的消息,都会回调,回调返回的结果不同 * 参数一(correlationData):消息相关的数据 * 参数二(ack):交换机是否受到消息 * 参数三(cause):没有收到消息的原因,收到消息该值为null */ @Override public void confirm(CorrelationData correlationData,boolean ack,String cause) { String id = Object.isNull(correlationData)?"":correlationData.getId(); if (ack) { log.info("交换机已经成功接收到id为{}的消息",id); } else { log.info("交换机还未接收到id为{}的消息,由于原因:{}",id,cause); } } } -
消息消费者
@Component public class Consumer { @RabbitListener(queues = RabbitConfig.CONFIRM_QUEUE_NAME) public void receiveConfirmMessage(Message message) { System.out.println("接收到消息:"+new String(message.getBody())); } } -
结果分析:
- 结果如我们预期的,没有问题,无论交换机有没有接收到消息,都会进行回调
- 但是需要注意的时,只要交换机接收消息成功,就会应答成功,无论队列是否成功接收到消息,因为这里只管生产者到交换机的过程,而不管交换机到队列的过程
- 因此,如果时队列出现了问题,没有接收到交换机的消息,我们时无法掌握的
回退消息
- Mandatory参数
- 在仅开启了生产者确认机制的情况下,交换机接收到消息后,会直接给消息生产者发送确认消息
- 如果发现该消息不可路由(由于一些原因无法发送到队列中),那么该消息会被直接丢弃掉,此时生产者时不知道消息被丢弃这个事件的
- 那么如何让无法路由的消息帮我们处理一下?最起码通知生产者一声,好进行处理
- 通过设置mandatory参数可以在当消息传递过程中不可达目的地时将消息返回给生产者
- 配置文档(在前面配置的基础上添加)
# 表示消息可以被回退 spring.rabbitmq.publisher-returns = true - 回调接口(直接在前面的交换机确认回调类同时实现回退接口RabbitTemplate.ReturnCallback)
@Slf4j @Component public class RabbitConfirmCallback implements RabbitTemplate.ConfirmCallback,RabbitTemplate.ReturnCallback { // 因为该接口时RabbitTemplate内部接口,我们这样实现之后并不能生效,因此要手动注入到RabbitTemplate中去,这里先引入RabbitTemplate这个对象 @Resouce private RabbitTemplate rabbitTemplate; // 我们定义一个方法,放当前这个实现类注入给RabbitTemplate这个类 @PostConstruct // 这个注解的作用可以实现在运行工程时,自动运行该注解下的方法 public void init() { // 将当前我们这个实现了对象this,设置给RabbitTemplate rabbitTemplate.setConfirmCallback(this); // 将回退接口也注入到里面去 rebbitTemplate.setReturnCallback(this); } /** * 该回调,无论交换机是否收到生产者的消息,都会回调,回调返回的结果不同 * 参数一(correlationData):消息相关的数据 * 参数二(ack):交换机是否受到消息 * 参数三(cause):没有收到消息的原因,收到消息该值为null */ @Override public void confirm(CorrelationData correlationData,boolean ack,String cause) { String id = Object.isNull(correlationData)?"":correlationData.getId(); if (ack) { log.info("交换机已经成功接收到id为{}的消息",id); } else { log.info("交换机还未接收到id为{}的消息,由于原因:{}",id,cause); } } /** * 该方法为回退接口实现方法,可以在当消息传递过长中不可送达目的地时将消息返回给生产者,成功时不会回退 * 参数一:被回退的消息对象 * 参数二:失败状态码 * 参数三:失败原因 * 参数四:交换机 * 参数五:交换机与队列绑定键routingKey */ @Override public void returnedMessage(Message message,int replyCode,String replyText,String exchange,String routingKey) { log.error("消息{},被交换机{},退回,退回原因{},路由key{}",new String(message.getBody()),exchange,replyText,routingKey); } } - 消息生产者代码与其他代码都不用动
- 结果分析
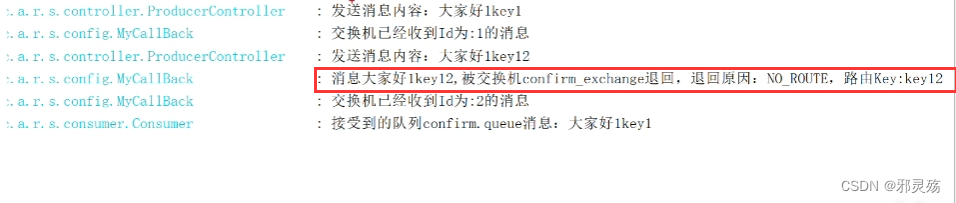
备份交换机
- 有了mandatory参数和回退消息,我们获得了对无法投递消息的感知能力,有机会在生产者的消息无法被投递时发现并处理
- 但有时候,我们并不知道该如何处理这些无法路由的消息,最多打个日志,然后触发报警,再来手动处理
- 而通过日志来处理这些无法路由的消息时很不优雅的做法,特别是当生产者所在的服务有多台机器的时候,手动复制日志会更加麻烦而且容易出错。而且设置mandatory参数会增加生产者的复杂性,需要添加处理这些被回退的消息的逻辑
- 如果既不想丢失信息,又不想增加生产者的复杂性,该怎么做呢?
- 前面我们再设置死信队列时提到过,可以为队列设置死信交换机来存储那些处理失败的消息,可是这些不可路由消息根本无法进入到队列中,因此无法使用死信队列来保存消息
- 再RabbitMQ中,有一种备份交换机的机制存在,可以很好的应对这个问题
- 什么时备份交换机呢?备份交换机可以理解为RabbitMQ中交换机”备胎“,当我们为某一个交换机声明一个对应的备份交换机时,就是为它创建一个备胎,当交换机接收到一条不可路由消息时,将会把这个消息转发到备份交换机中,由备份交换机来进行转发和处理,通常备份交换机的类型为Fanout(扇出类型),这样就把所有消息都投递到与其绑定的队列中,然后我们再备份交换机下绑定一个队列,这样所有那些原交换机无法被路由的消息,就会都进入这个队列了
- 当然我们还可以建立一个报警队列,用独立的消费者来进行检测和报警。
代码架构图

修改配置类(添加备份交换机,回退消息队列和报警队列以及报警消费者,还需要在更改业务交换机,当消息失败时转发到备份交换机)
@Configuration
public class DelayedQueueConfig {
// 队列名称
public static final String DELAYED_QUEUE_NAME = "delayed.queue";
// 交换机名称
public static final String DELAYED_EXCHANGE_NAME = "dealyed.exchange";
// 绑定RoutingKey
public static final String DELAYED_ROUTING_KEY = "delayed.routingkey";
// 备份交换机
public static final String BACKUP_EXCHANGE = "backup_exchange";
// 备份队列
public static final String BACKUP_QUEUE_NAME = "back_queue";
// 报警队列
public static final String WARNING_QUEUE_NAME = "warning_queue";
// 声明队列,就是一个普通队列
@Bean
public Queue delayedQueue() {
return new Queue(DELAYED_QUEUE_NAME);
}
// 声明交换机,使用参数绑定备份交换机
@Bean
public CustomExchange delayedExchange() {
return ExchangeBuilder.directExchange(DELAYED_EXCHANGE_NAME).durable(true).withArgument("alternate-exchange",BACKUP_EXCHANGE).build();
}
// 交换机与队列进行绑定,当前面声明队列与交换机没有在Bean指定名称,默认就是方法名
@Bean
public Binding delayedQueueExchange(@Qualifier("delayedQueue")Queue queue,@Qualifier("delayedExchange")CustomExchange exchange) {
return BindingBuilder.bind(queue).to(exchange).with(DELAYED_ROUTING_KEY).noargs();
}
// 备份交换机声明,需要注意是扇出类型
@Bean
public FanoutExchange backupExchange() {
return new FanoutExchange(BACKUP_EXCHANGE);
}
// 备份队列声明
@Bean
public Queue backupQueue() {
return QueueBuilder.durable(BACKUP_QUEUE_NAME).build();
}
// 报警队列声明
public Queue warningQueue() {
return QueueBuilder.durable(WARNING_QUEUE_NAME).build();
}
// 绑定备份队列
@Bean
public Binding backupQueueBindingBackupExchange(@Qualifier("backupQueue") Queue queue,@Qualifier("backupExchange") FanoutExchange exchange) {
// 扇出类型的交换机RoutingKey不用写
return BindingBuilder.bind(queue).to(exchange);
}
// 绑定报警队列
@Bean
public Binding backupQueueBindingBackupExchange(@Qualifier("warningQueue") Queue queue,@Qualifier("backupExchange") FanoutExchange exchange) {
// 扇出类型的交换机RoutingKey不用写
return BindingBuilder.bind(queue).to(exchange);
}
}
报警消费者
@Component
@Slf4j
public class WarningConsumer {
@RabbitListener(queues = DelayedQueueConfig.WARNING_QUEUE_NAME)
public void receiveWarningMsg(Message message) {
String msg = new String(message.getBody(),"UTF-8");
log.error("报警发现发送失败消息:{}",msg);
}
}
- mandatory参数与备份交换机可以一起使用的时候,如果两者同时开启,消息究竟何去何从?
- 经过上面测试,备份交换机优先级高,也就是会转发到备份交换机,而不会回退
RabbitMQ其他知识点
幂等性
- 概念
- 用户对同一操作发起的一次请求或多次请求的结果是一致的,不会因为多次点击而产生副作用
- 比如支付问题,用户购买商品后支付,支付扣款成功,但是返回结果的时候网络异常,此时钱已经扣了,用户再次点击按钮,此时会进行第二次扣款,返回结果成功,用户查询余额发现多扣了钱,流水记录就变成两条了
- 再以前的但应用中,我们只需要把数据操作放入事务中即可,发生错误立即回滚,但是在影响客户端的时候也有可能出现网络中断或异常等等
- 消息重复消费
- 消费者在消费MQ中的消息时,MQ已经把消息发送给消费者,消费者在MQ返回ack时网络中断
- 此时MQ未收到确认消息,该条消息会重新发送给其他消费者或者在网络重连后再次发送给消费者
- 但是实际上该消费者已经成功消费了该条消息,造成消费者消费了重复的消息
- 解决思路
- MQ消费者的幂等性的解决一般使用全局ID或者写一个唯一性标识比如时间戳或者UUID或者订单消费者消费MQ中的消息也可以利用MQ的该ID来判断
- 或者可以按自己的规则生成一个全局唯一ID,每次消费消息时用该ID先判断该消息是否已经消费过
- 消费端的幂等性保障
- 在海量订单生成的业务高峰期,生产端有可能会重复发送了消息,这时候消费端就要实现幂等性
- 这就意味着我们的消息永远不会被消费多次,即使我们收到了一样的消息
- 业界主流的幂等性有两种操作
- 唯一ID+指纹码机制,利用数据库主键去重
- 利用Redis的原子性去实现
- 唯一ID加指纹码机制
- 指纹码:我们的一些规则或者时间戳加别的服务给到的唯一信息码,它并不一定时我们系统生成的
- 基本上都是由我们的业务规则拼接而来,但是一定要保证唯一性,然后就利用查询语句进行判断这个ID是否存在数据库中
- 优势就是实现简单,就一个拼接,然后查询判断是否重复
- 劣势就是在包并发时,如果时单个数据库就会有写入性能瓶颈,当然也可以采用分库分表提升性能,但也不是我们推荐的方式
- Redis原子性
- 利用redis执行setnx命令,天然具有幂等性,从而实现不重复消费
优先级队列
- 使用场景
- 在我们系统中有一个订单催付的场景,我们的客户在天猫下的订单,淘宝会及时将订单推送给我们
- 如果在用户设定的时间内未支付那么就会给用户推送一条短信提醒,很简单的一个功能,但是天猫商家对我们来说肯定时要分大客户和小客户的,比如像苹果、小米这样大商家一年起码能给我们创造很大的利润,所以理所当然,他们的订单必须得到优先处理
- 而曾经我们的后端系统时使用redis来存放的定时轮询,我们都知道Redis只能用List做一个简单的消息队列,并不能实现一个优先级的场景
- 所以订单量大了之后采用RabbitMQ进行改造和优化,如果发现时大客户的订单给一个相对比较高优先级,否则就是默认优先级
- 原理:
- 默认的队列中,消息时先进先出的,也就是说先进入队列的消息,优先被消费者进行消费
- 而当我们设置了优先级队列之后,当消费者链接到队列时(排队是由消费者进行的),不是马上进行消费,而是对队列中的消息进行重新排队,对每个消息设置优先级,优先级可以设置0到255,超过这个数就报错,数字越大优先级越高
- 当对消息进行重新排队之后,再按照新的顺序进行依次消费
- 如何添加
-
页面添加(就是一般队列,多加了一个参数)
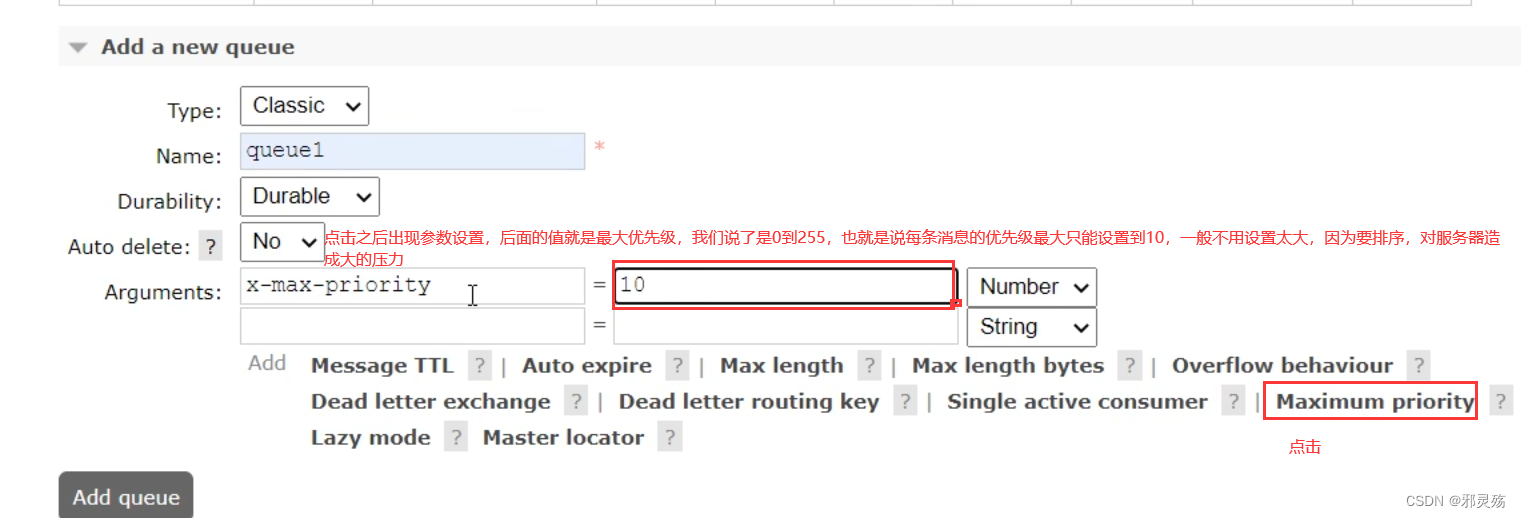
-
代码中添加
Map<String,Object> map = new HashMap<>(); map.put("x-max-priority",10); channel.queueDeclare("hello",true,false,false,map); -
消息中添加优先级(上面只是将队列设置为优先级队列)
// 设置消息优先级为5,因为我们前面最大优先级是10,不能超过10 AMQP.basicProperties properties = new AMQP.basicProperties().builder().priority(5).build(); -
注意事项
- 要让队列实现优先级需要做的事情有:队列需要设置为优先级队列
- 消息需要设置消息的优先级
- 消费者需要等待消息已经发送到队列中去才能去消费,这样才有机会对消息进行排序,否则发送一条这边消费一条,等消息发送完也就接收消费完了
-
- 实战(主要时队列声明与消息发送时设置,其他不变)
- 生产者
public class Producer { public static void main(String[] args) throws IOException, TimeoutException { // 创建连接工厂 ConnectionFactory factory = new ConnectionFactory(); // 设置RabbitMQ服务端口 factory.setHost("192.168.0.200"); // 设置用户名 factory.setUsername("roor"); // 设置密码 factory.setPassword("root"); // 创建连接对象 Connection connection = factory.newConnection(); // 获取信道 Channel channel = connection.createChannel(); // 声明一个队列 Map<String,Object> map = new HashMap<String,Object>(); map.put("x-max-priority",10); // 声明时设置最大优先级,也就是将队列声明为优先级队列 channel.queueDeclare("myQueue", false, false, true,map); // 发送消息 AMQP.BasicProperties properties = new AMQP.BasicProperties().builder().priority(5).build(); // 同时设置消息的优先级 channel.basicPublish("","myQueue",properties,"我是发送的消息".getBytes("utf-8")); System.out.println("消息发送成功"); } }
- 生产者
惰性队列
-
使用场景
- RabbitMQ从3.6.0版本开始引入了惰性队列的概念,惰性队列会尽可能的将消息存入磁盘中,而在消费者消费到相应的消息时才会被加载到内存中
- 它的一个重要的设计目标时能够支持更长的队列,即支持更多的消息存储
- 当消费者由于各种原因(比如消费者下线、宕机亦或者时由于维护关闭等)而致使很长时间内不能消费消息造成堆积时,惰性队列就很有必要了
- 默认情况下,当生产者将消息发送到RabbitMQ的时候,队列中的消息会尽可能的存储再内存中,这样可以更加快速的将消息发送给消费者
- 即使时持久化的消息,再被写入磁盘的同时也会在内存中驻留一份备份,当RabbitMQ需要释放内存的时候,会将内存中的消息换至磁盘中,这个操作会耗费较长的时间,也会阻塞队列操作,进而无法接收新的消息
- 虽然RabbitMQ的开发者们一直在升级相关的算法,但是效果始终不太理想,尤其是在消息量特别大的时候
- 因为惰性队列在消息进入队列时先进入磁盘,然后当消费者进行消费时再从磁盘进行读取,因此惰性队列效率较低,一般情况下不需要,当有大量消息堆积在队列中时就比较适合设置为惰性队列
-
两种模式
- 队列具备两种模式:default和lazy,默认的是default模式,在3.6.0之前的版本无需做任何变更
- lazy模式即为惰性队列模式,可以通过调用channel.queueDeclare方法的时候在参数中设置,也可以通过Policy的方式设置,如果一个队列中同时使用这两种方式设置的话,那么Policy的方式具备更高的优先级
- 如果要通过声明的方式改变已有队列的模式的话,那么只能先闪出队列,然后重新声明一个新的
- 在队列声明的时候可以通过”x-queue-mode“参数来设置队列的模式,取值为”default“和”lazy“。代码如下:
Map<String,Object> map = new HashMap<>(); map.put("x-queue-mode","lazy"); channel.queueDeclare("myqueue",false,false,false,map); - 通过页面设置队列为惰性队列
-
内存开销对比:在发送一百万条消息的情况下,每条消息大概占1KB的情况下,普通队列占用内存时1.2GB,而惰性队列仅仅占用1.5MB
RabbitMQ集群(我们搭建三台服务示例)
clustering
- 使用集群的原因
- 最开始我们介绍如何安装及运行RabbitMQ服务,不过这些都是单机版的,无法满足目前真实应用的要求
- 如果RabbitMQ服务器遇到内存奔溃、机器停电或主板故障等情况该怎么办
- 单台RabbitMQ服务器可以满足每秒1000条消息的吞吐量,那么如果应用需要RabbitMQ服务满足每秒10万条消息的吞吐量呢
- 购买昂贵的服务器来增强单机RabbitMQ服务的性能显得捉襟见肘,搭建一个RabbitMQ集群才是解决实际问题的关键
- 搭建集群时,我们先搭建一台单机,然后将第二台MQ服务器连接到第一台MQ服务中,第三台服务可以连接第二台或者第一台服务,也就时说,将所有服务连接起来,可以任意连接任何一个节点,只要将所有要搭建的服务连接到一起,那么访问一台服务,也就是能够访问所有服务,实现集群效果
- 搭建集群的步骤
- 修改三台机器的主机名称,修改完重启系统,让修改生效
# 分别在三台机器上执行命令,修改机器名为node1、node2、node,都是自定义,好记 vim /etc/hostname - 配置各个节点(机器)的hosts文件,让各个节点能够互相访问
# 分别在三台机器上运行命令,修改文件,三台机器都有配置,这样相互可以访问 vim /etc/hosts 10.211.55.74 node1 # 节点一IP以及对应主机名 10.211.55.74 node2 # 节点二IP以及对应主机名 10.211.55.74 node3 # 节点三以及对应主机名 - 以确保各个节点的cookie文件使用的同一个值(集群要求MQ底层erlang的cookie必须时一样的值)
在node1上面执行下面两个命令即可,这时远程操作命令,会设置其他两个节点与节点一相同值,执行时会询问是否连接,选择yes即可,然后会要求输入对应的机器的密码# 设置节点二与节点一cookie保持一致 scp /var/lib/rabbitmq/.erlang.cookie root@node2:/var/lib/rabbitmq/.erlang.cookie # 设置节点三与节点一cookie保持一致 scp /var/lib/rabbitmq/.erlang.cookie root@node3:/var/lib/rabbitmq/.erlang.cookie - 启动RabbitMQ服务,顺带启动Erlang虚拟机和RabbitMQ应用服务(三台机器都有执行下面命令启动RabbitMQ)
rabbitmq-server -detached - 在节点二上执行下面命令(以第一个节点为基准,将节点二连接到节点一)
# 关闭服务,rabbitmqctl stop会将Erlang虚拟机关闭,rabbitmqctl stop_app之关闭RabitMQ服务 rabbitmqctl sotp_app # 重置服务,会将服务中之前的queue等所有数据重置 rabbitmqctl reset # 将当前服务连接到节点一的服务中 rabbitmqctl join_cluster rabbit@node1 # 启动服务,值启动RabbitMQ服务 rabbitmqctl start_app - 在节点三上只想下面命令(节点二已经连接节点一,我们将节点三连接节点二,也可以选择都连接节点一)
# 关闭服务,rabbitmqctl stop会将Erlang虚拟机关闭,rabbitmqctl stop_app之关闭RabitMQ服务 rabbitmqctl sotp_app # 重置服务 rabbitmqctl reset # 将当前服务连接到节点二的服务中,要确保服务时启动的,也即是节点二完成第六步操作 rabbitmqctl join_cluster rabbit@node2 # 启动服务,值启动RabbitMQ服务 rabbitmqctl start_app - 查看集群状态(此时集群搭建完毕,后续操作在任意机器上都可,集群就是一个整体)
rabbitmqctl cluster_status - 需要重新设置集群访问账号
创建账号
设置账号角色# rabbitmqctl add_user 账号名 密码 rabbitmqctl add_user admin admin
设置账号权限# rabbitmqctl set_user_tags 账号名 角色名,角色名一般就是下面的管理员角色 rabbitmqctl set_user_tags admin administaratorrabbitmqctl set_permissions -p "/" admin "." "." "." - 解除集群节点(在需要解除的节点执行下面命令,我们解除节点二为例)
# 关闭节点二服务 rabbitmqctl stop_app # 重置节点二服务 rabbitmqctl reset # 启动节点二服务 rabbitmqctl start_app # 查看节点二状态 rabbitmqctl cluster_status # 在节点一执行,因为节点二连接节点一,需要让节点一忘记节点二,也就是在基础节点执行,如果要解除节点三,也直接在节点一上执行即可 rabbitmqctl forget_cluster_node rabbit@node2 # 需要注意,虽然节点三连接节点二,但是我们这里解除节点二对节点三没有影响,会自动连接到节点一
- 修改三台机器的主机名称,修改完重启系统,让修改生效
镜像队列(集群节点备份队列)
- 使用镜像的原因
- 如果RabbitMQ集群中只有一个Broker节点,那么该节点的失效将导致整体服务的临时性不可用,并且也可能会导致消息的丢失
- 换句话说,虽然我们部署了集群,但是节点直接创建的队列等都是不通用的,虽然我们可以从节点二上读取或写入到节点一的队列中,但是如果节点一宕机了,那么队列就不可用了,里面的信息也就可能丢失掉
- 虽然可以将所有消息都设置为持久化,并且对应队列的durable属性也设置为true,但是这样仍然无法避免由于缓存导致的问题,因为消息在发送之后和被写入磁盘并执行刷盘动作之间存在一个短暂却会产生为题的时间窗
- 通过publisherconfirm机制能够确保客户端知道哪些消息已经存入磁盘,尽管如此,一般不希望遇到因单点故障导致的服务不可用
- 引入镜像队列(Mirror Queue)的机制,可以将队列镜像到集群中的其他Broker节点之上,如果集群中的一个节点失效了,队列能够自动的切换到镜像中的另一个节点上以保证服务的可用性
- 搭建镜像的步骤
-
启动前面我们部署的三个集群节点
-
随便找要给节点添加policy(策略)
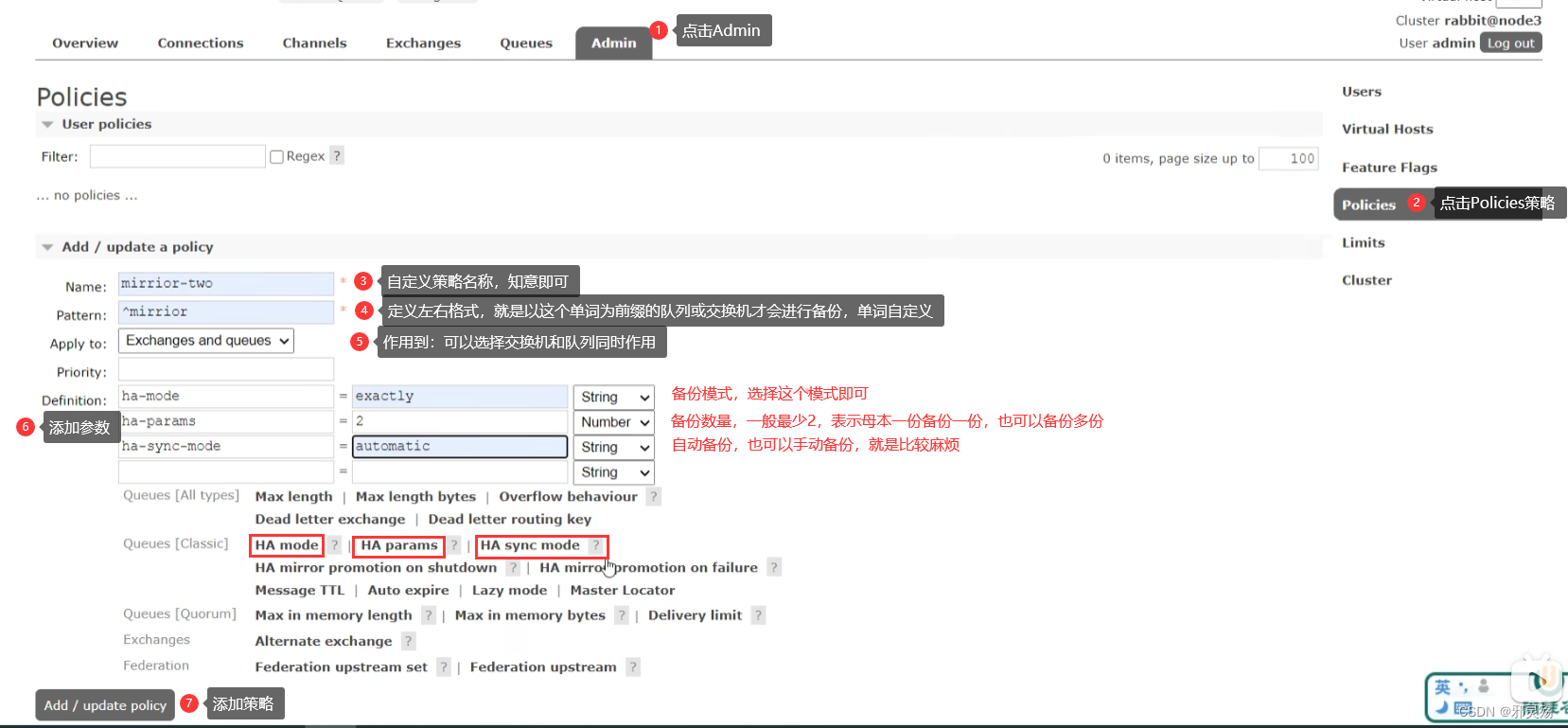
-
此时在node1(任意节点)上创建一个队列发送一条消息,队列存在镜像队列(按照设置的前缀规则创建队列名称),那么会自动再其他任意(随机)一个节点上备份一个队列,此时如果节点一宕机,我们正常从其他节点读取都可以,同时,当节点一宕机后,还会自动将备份的队列再在另一个节点上备份一个,始终保持有两份队列
-
因此,就算整个集群只剩一台机器了,依然能够消费队列中的消息,因为当母本或镜像队列所在一台机器宕机后,会自动寻找一个节点进行重新备份
-
Haproxy+Keepalive实现高可用
前面集群搭建完成,而且备份容错性也做好了,但是还存在一个问题,我们的代码中或者说操作MQ时,始终只能操作一台机器或一个节点,如SpringBoot配置也只会配置一个IP,而当我们操作的节点刚好宕机之后,我们无法得知是否有其他节点或无法修改代码中的IP重新操作,因此需要(通过代理服务、负载均衡)实现统一配置操作
- 整体架构图
- 当客户端要使用有MQ服务时,请求VIP(公用的IP,可以理解为代理IP)
- 在VIP下配置有主服务和备份服务,一般都是走主服务,通过主服务访问整个MQ集群
- 当主服务出现问题无法访问时,便走备份服务(keepalive实现双机),同时备份服务还会间歇性的主动询问主机的健康状况,一旦得不到回应,便会接管来自VIP的访问请求
- Haproxy实现负载均衡
- HAProxy提供高可用性、负载均衡及基于TCPHTTP应用的代理,支持虚拟主机
- 它时免费的、快速并且可靠的一种解决方案,包括Twitter、Reddit、StackOverflow、GitHub在内的多家知名互联网公司都在使用它
- HAProx实现了一种事件驱动、单一进程模型,此模型支持非常大的并发连接数
- 扩展:nginx、lvs、haproxy之间的区别http://www.ha97.com/5646.html
- 搭建步骤
- Keepalived实现双机
- 搭建步骤
FederationExchange(联邦交换机,通过交换机同步数据)
-
使用它的原因
- (broker北京),(broker深圳)彼此之间相距甚远,网络延迟时一个不得不面对的问题
- 有一个在北京的业务(Client北京)需要连接(broker北京),向其中的交换机exchangeA发送消息,此时的网络延迟很小,(Client北京)可以迅速将消息发送至exchangeA.中,就算在开启了publisherconfirm.机制或者事务机制的情况下,也可以迅速收到确认信息。
- 此时又有个在深圳的业务(Client深圳)需要向exchangeA发送消息,那么(Client深圳)(broker北京)之间有很大的网络延迟,(Client深圳)将发送消息至exchangeA会经历一定的延迟,尤其是在开启了publisherconfirm.机制或者事务机制的情况下,(Client深圳)会等待很长的延迟时间来接收(broker北京)的确认信息,进而必然造成这条发送线程的性能降低,甚至造成一定程度上的阻塞。
- 将业务(Client深圳)部署到北京的机房可以解决这个问题,但是如果(Client深圳)调用的另些服务都部署在深圳,那么又会引发新的时延问题,总不见得将所有业务全部部署在一个机房,那么容灾又何以实现?这里使用Federation插件就可以很好地解决这个问题.
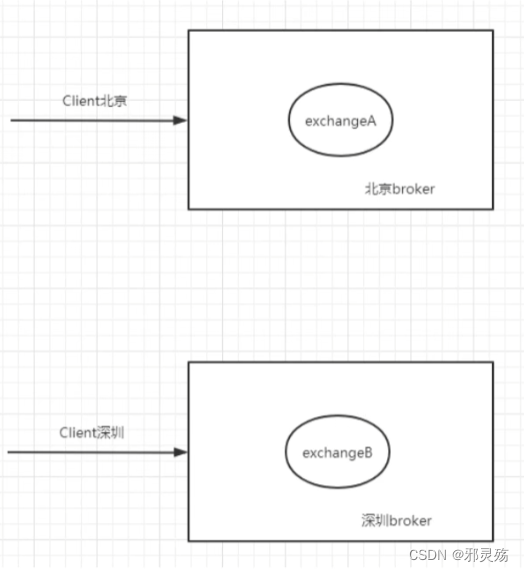
-
搭建步骤
-
需要保证每台节点单独运行(每个节点都要执行,这里节点非同集群节点,同集群数据直接备份即可,这里只不同集群直接数据同步)
-
在每台机器上开启federation相关插件(不用下载自带的)
# 在每个节点服务器上,MQ服务开启的情况下之间执行两个命令 rabbitmq-plugins enable rabbitmq_federation rabbitmq-plugins enable rabbitmq_federation_management -
按照成功后直接刷新页面即可看到,否则重启服务
-
原理图(先在下游MQ创建交换机,上游交换机才能同步数据过去)
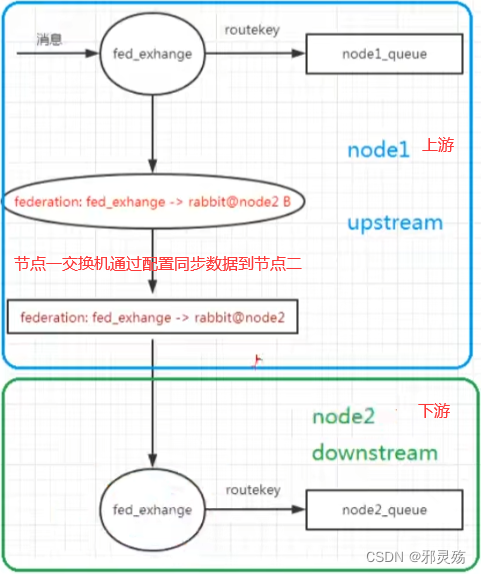
-
在downstream(下游node2)上配置upstream(上游node1)

-
添加policy(策略)
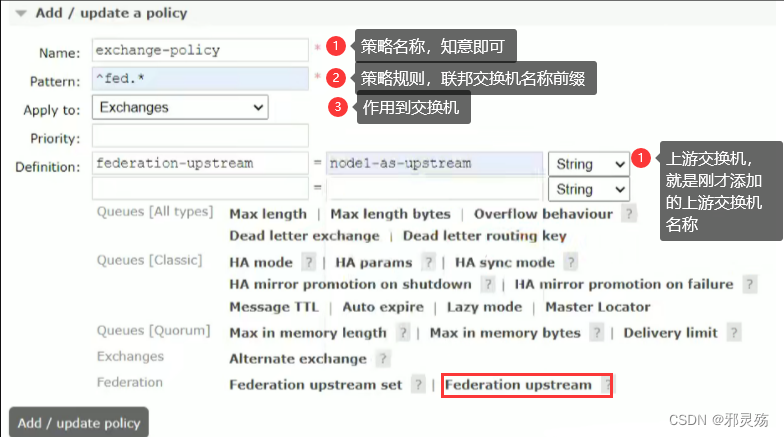
-
Federation Queue(联邦队列,通过队列同步数据)
- 使用它的原因
- 联邦队列可以在多个broker节点(或者集群)之间为单个队列提供均衡负载的功能
- 一个联邦队列可以连接一个或者多个上游队列(upstream queue),并从这些上游队列中获取消息以满足本地消费者消费消息的需求
- 搭建步骤
-
原理图
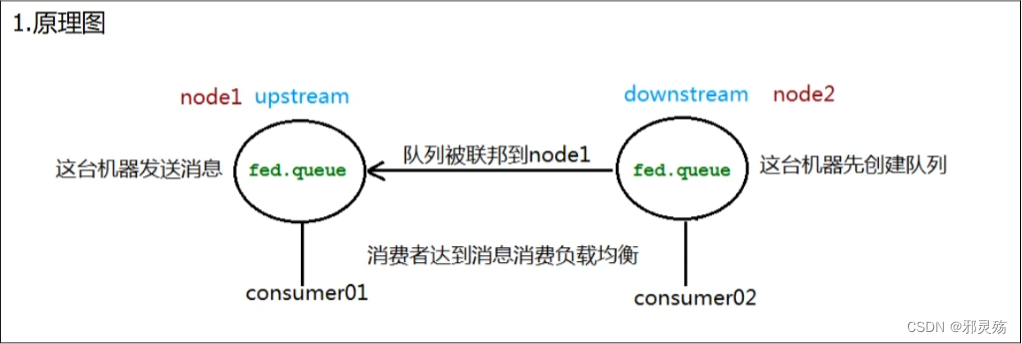
-
添加upstream(添加上游,同上面联邦队列)
-
添加policy
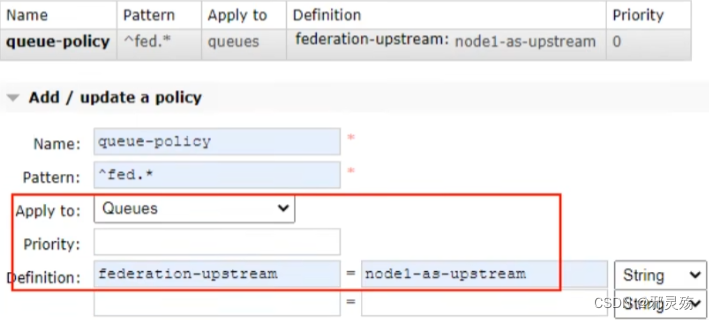
-
Shovel(类似联邦交换机和联邦队列作用)
- 使用它的原因
- Federation具备的数据转发功能类似,Shovel够可靠、持续地从一个Broker中的队列(作为源端,即source)拉取数据并转发至另一个Broker中的交换器(作为目的端,即destination)。
- 作为源端的队列和作为目的端的交换器可以同时位于同一个Broker,也可以位于不同的Broker上。
- Shovel可以翻译为"铲子",是一种比较形象的比喻,这个"铲子"可以将消息从一方"铲子"另一方。
- Shovel行为就像优秀的客户端应用程序能够负责连接源和目的地、负责消息的读写及负责连接失败问题的处理。
- 搭建步骤
-
开启插件(需要的服务上都要开启)
rabbitmq-plugins enable reabbitmq_shovel rabbitmq-plugins enable rabbitmq_shovel_management -
原理图(在源头发送的消息直接进入到目的地队列)
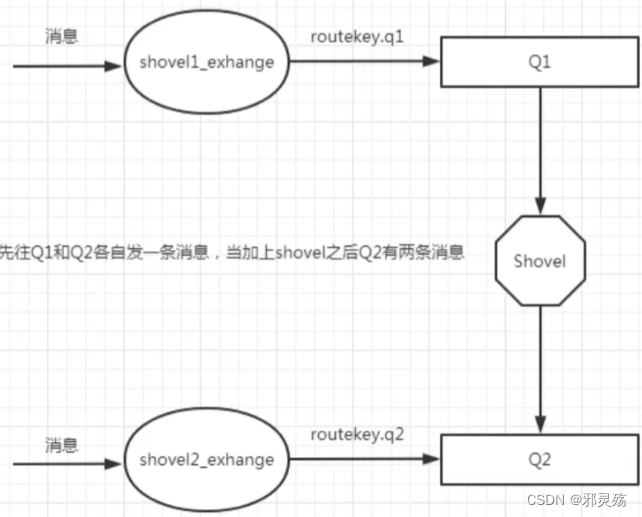
-
添加Shovel源和目的地
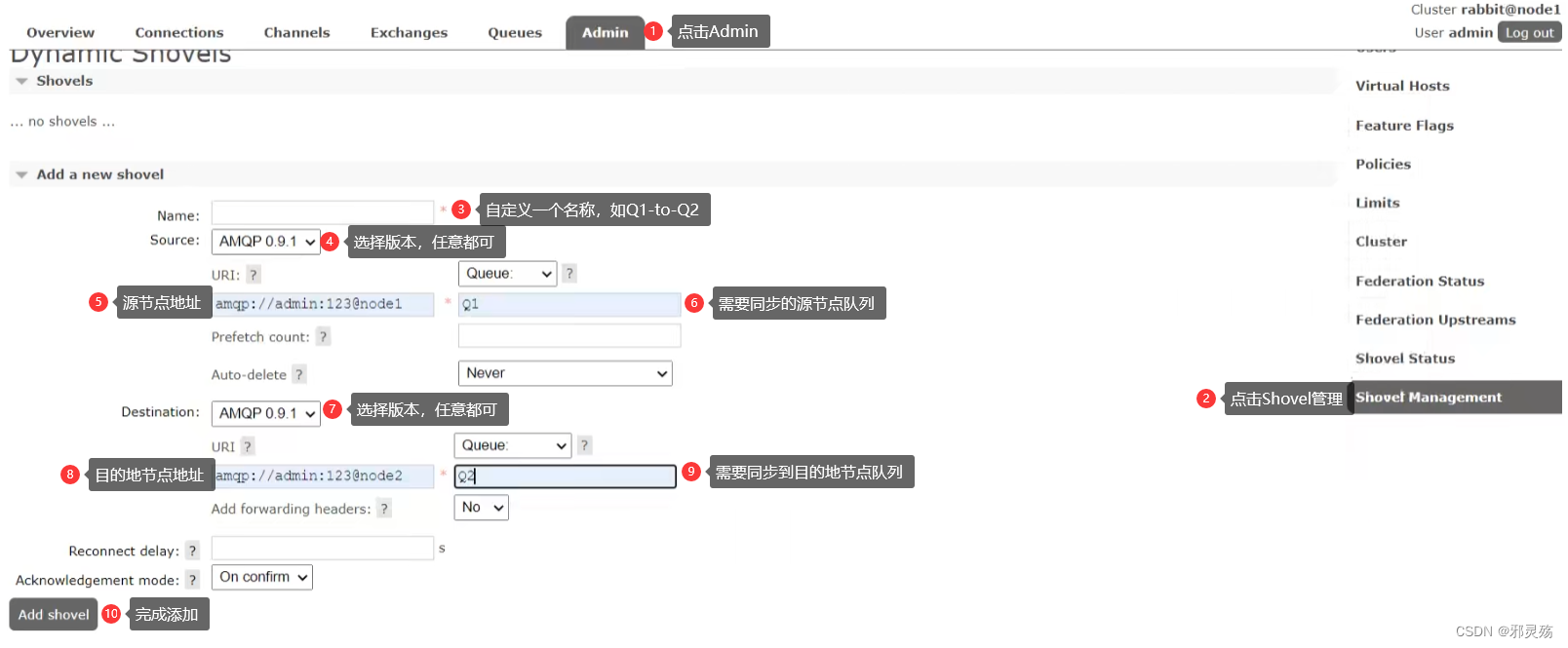
-
SpringAMQP
概念
SpringAmqp的官方地址:https://spring.io/projects/spring-amqp
AMQP
- Advanced Message Queuing Protocol
- 是用于在应用程序或之间传递业务消息的开放标准(标准、规范、接口)
- 该协议与语言和平台无关,更符合微服务中独立性的要求
Spring AMQP(完整整合springboot/springcloud)
- Spring AMQP是基于AMQP协议定义的一套API规范
- 提供了模板来发送和接收消息
- 包含两部分,其中spring-amqp是基础抽象,spring-rabbit是底层默认实现
- 特征:
- 侦听器容器,用于异步处理入站消息(一般用于消费消息)
- 用于发送和接收消息的RabbitTemplate(一般用于发送消息,上面侦听器消息消息,类似spring提供的Redis工具RedisTemplate,我们直接使用即可,不需要创建绑定等)
- RabbitAdmin用于自动声明队列、交换机和绑定
基于队列消费模型
- 因为publisher和consumer服务 都需要amqp依赖,因此这里把依赖直接放入的Springcloud父工程中:
<!--AMQP依赖,包含RabbitMQ--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency>
简单模型
- 生产者者服务
- 在publisher服务中编写application.yml,添加mq连接信息
spring: rabbitmq: host: 192.168.0.200 # 主机名/IP地址 port: 5672 # 服务端口 virtual-host: / # 虚拟主机 username: admin # 用户名 password: root # 密码 - 在publisher服务中新建一个测试类,编写测试方法
@RunWith(SpringRunner.class) @SpringBootTest public class SpringAmqpTest { // 注入RabbitTemplate对象 @Autowired private RabbitTemplate rabbitTemplate; @Test public void testSimpleQueue() { // 需要发送消息的队列名称,没有的话RabbitTemplate自动创建,连接,获取channel String queueName = "simple.queue"; // 需要发送的消息,不用特殊处理 String message = "hello,spring amqp"; // 调用方法convertAndSend(转换并发送)进行消息发送 rabbitTemplate.convertAndSend(queueName, message); } } - 直接运行测试方法即可完成消息发送
- 在publisher服务中编写application.yml,添加mq连接信息
- 消费者服务
- 在consumer服务中编写application.yml,添加mq连接信息
spring: rabbitmq: host: 192.168.0.200 # 主机名/IP地址 port: 5672 # 服务端口 virtual-host: / # 虚拟主机 username: admin # 用户名 password: root # 密码 - 在consumer服务中新建一个类,编写信息消费逻辑:
@Component public class SpringRabbitListener { // 侦听器,侦听指定队列,侦听到有消息后spring直接将消息投递到注解对应方法中 @RabbitListener(queues = "simple.queue") // 接收消息的类型,我们生产者发的什么类型,这边就什么类型,spring都会自动处理 public void listenSimpleQueueMessage(String msg) throws InterruptedException { System.out.println("spring 消费者接收到消息:【"+ msg +"】"); } } - 启动项目,因为消息是spring帮我们进行投递,因此需要启动整个项目
- 在consumer服务中编写application.yml,添加mq连接信息
工作队列模型
与之前的简单队列类似,只是在一个队列上挂上多个消费者,提高消息消费的效率,避免消息在队列中堆积
我们下面模拟工作队列,实现一个队列绑定多个消费者:消费者一每秒消费50条消息,消费者二每秒消费5条消息,模拟不同的处理速度
- 生产者
@RunWith(SpringRunner.class) @SpringBootTest public class SpringAmqpTest { // 注入RabbitTemplate对象 @Autowired private RabbitTemplate rabbitTemplate; @Test public void testWorkQueue() { // 需要发送消息的队列名称,没有的话RabbitTemplate自动创建,连接,获取channel String queueName = "simple.queue"; // 需要发送的消息,不用特殊处理 String message = "hello,spring amqp"; // 调用方法convertAndSend(转换并发送)进行消息发送,发送50条消息 for(int i = 0; i < 50; i++) { rabbitTemplate.convertAndSend(queueName, message + i); } } } - 消费者,两个消费者,监听同一队列
@Component public class SpringRabbitListener { // 侦听器,侦听指定队列,侦听到有消息后spring直接将消息投递到注解对应方法中 @RabbitListener(queues = "simple.queue") // 接收消息的类型,我们生产者发的什么类型,这边就什么类型,spring都会自动处理 public void listenWork1QueueMessage(String msg) throws InterruptedException { System.out.println("spring 消费者1接收到消息:【"+ msg +"】"); } // 侦听器,侦听指定队列,侦听到有消息后spring直接将消息投递到注解对应方法中 @RabbitListener(queues = "simple.queue") // 接收消息的类型,我们生产者发的什么类型,这边就什么类型,spring都会自动处理 public void listenWork2QueueMessage(String msg) throws InterruptedException { System.out.println("spring 消费者2接收到消息:【"+ msg +"】"); } } - 结果
- 我们发现虽然两个消费者处理消息的速度不同,但是消息是平均分配的,也就是比如消费者消费单数消息,那么消费者二就消费双数消息,各自消费了25条消息
- 而我们总共就50条消息,处理消息花费的时间却是消费者二处理25条消息花费的时间,而此时消费者一早就处理完自己的25条消息了
- 那么这中情况显然是不合理的,这是因为MQ的特性决定的,也就是消息预取机制,也就是如果有50条消息,我消费者一取一条,消费者二紧接着取一条,而不管有没有处理完,消费者一紧接着再取一条,以此类推,也就是当有大量消息时,我不管消费者的处理能力,先预先将消息取过来,为了公平取消息时就时公平的取的
- 取完消息之后再由消费者自己根据自己的能力进行处理,此时即便处理速度极慢,也要将获取的消息全部消费,因为不可能再交由其他消费者了
- 消息预取
- 而我们像要按照消费者的能力进行分配,那就将消息预取的值设置为1,也就是处理完一条再取出一条,这样处理快的取的多,处理慢的取的少,当然也可以根据实际情况进行设置,该值最小为1,也就是每次取一条,最大无穷大,也就是有多少消息全部先取出来
- 需要在配置文件中进行配置,preFetch就是指预取值的大小
spring: rabbitmq: host:192. 168.0.200 # 主机名 port: 5672 # 端口 virtual-host: / #虚拟主机 username: root # 用户名 password: root # 密码 listener: simple: prefetch: 1 # 每次只能获取一条消息,处理完才能获取下一个消息
发布订阅模型
发布订阅模式与之前案例的区别就是允许将同一消息发送给多个消费者
实现的方式就是加入了exchange(交换机)
具体的交换机是将消息发送给一个队列还是多个队列,是由交换机决定的,常见的交换机类型包括Fanout(广播、扇出)、Direct(路由、直接)、Topic(话题、主题)
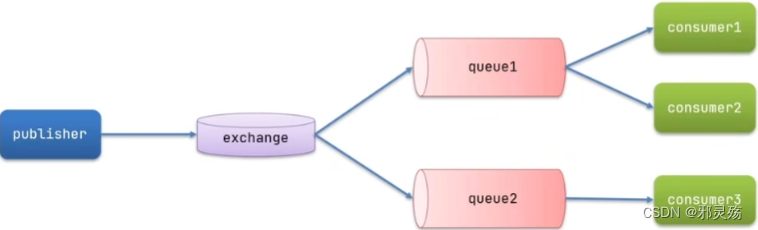
exchange只负责消息的路由(转发),而不是存储,路由失败则消息丢失,只有队列是存消息的
广播模式(Fanout Exchange)
Fanout Exchange会将接收到的消息路由到每一个跟其绑定的queue
- 声明两个队列,一个交换机,将队列与交换机进行绑定,这里绑定直接用变量名入参,不需要注解声明
@Configuration public class FanoutConfig{ // 交换机 @Bean public FanoutExchange fanoutExchange(){ return new FanoutExchange("iotek.fanout"); } // 队列1 @Bean public Queue fanoutQueue1(){ return new Queue("fanout.queue1"); } // 队列2 @Bean public Queue fanoutQueue2(){ return new Queue("fanout.queue2"); } // 绑定队列1到交换机 @Bean public Binding fanoutBinding1(Queue fanoutQueue1,FanoutExchange fanoutExchange){ return BindingBuilder.bind(fanoutQueue1).to(fanoutExchange); } // 绑定队列2到交换机 @Bean public Binding fanoutBinding1(Queue fanoutQueue2,FanoutExchange fanoutExchange){ return BindingBuilder.bind(fanoutQueue2).to(fanoutExchange); } } - 生产者
public class Demo{ @Test public void testSendFanoutExchange(){ // 交换机 String exchangeName = "iotek.fanout"; // 消息 String message = "hello,every one!"; // 发送消息 rabbitTemplate.convertAndSend(exhcangeName,"",message); } } - 消费者
@RabbitListener(queues = "fanout.queue1") public void listenWork2QueueMessage(String msg) throws InterruptedException { System.out.println("spring 消费者接收到fanout.queue1消息:【"+ msg +"】"); } @RabbitListener(queues = "fanout.queue2") public void listenWork2QueueMessage(String msg) throws InterruptedException { System.out.println("spring 消费者接收到fanout.queue2消息:【"+ msg +"】"); }
订阅模式(Direct Exchange)
Direct Exchange会将接收到的消息根据规则路由到指定的Queue,因此称为路由模式(routes)
每一个Queue都与Exchange设置一个BindingKey
发布者发送消息时,指定消息的RoutingKey
Exchange将消息路由到BindingKey与消息RoutingKey一致的队列
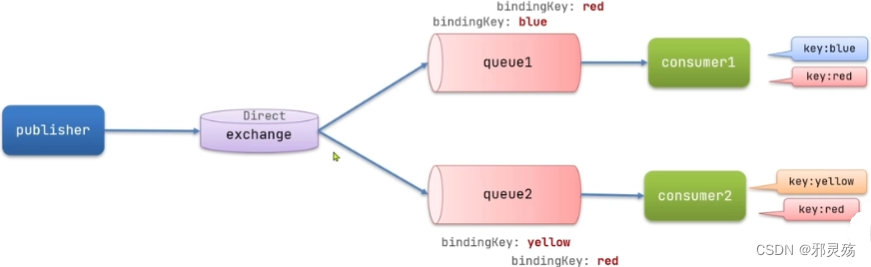
- 直接声明并监听:我们不需要额外写交换机,队列及绑定关系的声明,直接在监听时进行声明,也就是类似于我们在消费者端进行声明,使用注解的方式
@Component public class SpringRabbitListener { // 声明队列一,直接交换机,绑定,设置routingkey并监听队列 @RabbitListener(bindings = @QueueBinding(// 参数为绑定类型,值是注解 value = @Queue(name = "direct.queue1"),// value声明队列,值是注解,注解中name指定队列名 exchagen = @Exchange(name = "iotke.direct",type = ExchangeTypes.DIRECT),// 指定交换机,name名称,type类型,类型可用字符串或枚举,枚举由spring提供的类 key = {"blue","red"}//指定RoutingKey,可多个,字符串数组 )) public void listenDirectQueue1(String msg){ System.out.println("消费者接收到dierct.queue1的消息【"+msg+"】"); } // 声明队列二,直接交换机,绑定,设置routingkey并监听队列 @RabbitListener(bindings = @QueueBinding(// 参数为绑定类型,值是注解 value = @Queue(name = "direct.queue2"),// value声明队列,值是注解,注解中name指定队列名 exchagen = @Exchange(name = "iotke.direct",type = ExchangeTypes.DIRECT),// 指定交换机,name名称,type类型,类型可用字符串或枚举,枚举由spring提供的类 key = {"red","yellow"}//指定RoutingKey,可多个,字符串数组 )) public void listenDirectQueue2(String msg){ System.out.println("消费者接收到dierct.queue2的消息【"+msg+"】"); } } - 生产者
public class Demo{ @Test public void testSendDirectExchange(){ // 交换机 String exchangeName = "iotek.direct"; // 消息 String message = "hello,blue!"; // 发送消息 rabbitTemplate.convertAndSend(exhcangeName,"blue",message); } }
主题模式(Topic Exchange)
TopicExchange与DirectExchage类似,区别在于routingKey必须是多个单词的列表,并且以点号(.)分割
Queue与Exchange指定BindingKey时可以使用通配符:
#:代指0个或多个单词
*:代指一个单词

- 声明并监听队列
@Component public class SpringRabbitListener { // 声明队列一,主题交换机,绑定,设置routingkey并监听队列 @RabbitListener(bindings = @QueueBinding(// 参数为绑定类型,值是注解 value = @Queue(name = "topic.queue1"),// value声明队列,值是注解,注解中name指定队列名 exchagen = @Exchange(name = "iotke.topic",type = ExchangeTypes.TOPIC),// 指定交换机,name名称,type类型,类型可用字符串或枚举,枚举由spring提供的类 key = "china.#"//指定RoutingKey,可多个,字符串数组 )) public void listenTopicQueue1(String msg){ System.out.println("消费者接收到dierct.queue1的消息【"+msg+"】"); } // 声明队列二,主题交换机,绑定,设置routingkey并监听队列 @RabbitListener(bindings = @QueueBinding(// 参数为绑定类型,值是注解 value = @Queue(name = "topic.queue2"),// value声明队列,值是注解,注解中name指定队列名 exchagen = @Exchange(name = "iotke.topic",type = ExchangeTypes.TOPIC),// 指定交换机,name名称,type类型,类型可用字符串或枚举,枚举由spring提供的类 key = "#.news"//指定RoutingKey,可多个,字符串数组 )) public void listenTopicQueue2(String msg){ System.out.println("消费者接收到dierct.queue2的消息【"+msg+"】"); } } - 生产者
public class Demo{ @Test public void testSendDirectExchange(){ // 交换机 String exchangeName = "iotek.topic"; // 消息 String message = "我国新闻!"; // 发送消息 rabbitTemplate.convertAndSend(exhcangeName,"china.news",message); } }
消息转换器
- 说明
- 在SpringAMQP的发送消息的方法中,消息的参数类型是Object,也就是说我们可以发送任意对象类型的消息,SpringAMQP会帮我们序列化为字节后发送
- 例如我们发送一个Map对象测试发现可以发送成功,且在界面查看队列中确实有一条消息
- 我们在Consumer中利用@Bean声明一个队列,接收我们对象消息
@Bean public Queue objectQueue() { return new Queue("object.queue"); } - 在publisher中发送一个Map对象类型的消息到队列中
@Test public void testSendMap() throws InterruptedException{ // 准备对象类型消息 Map<String,Object> map = new HashMap<>(); map.put("name","张三"); map.put("age",28); // 发送消息到队列中 rabbitTemplate.convertAndSend("object.queue",map); }
- 消息转换器发送消息
- Spring对消息对象的处理是由org.springframework.amqp.support.converter.MessageConverter来处理的
- 而默认实现是SimpleMessageConverter,基于JDK的ObjectOutputStream完成序列号
- 而这种方式序列化不安全,且序列化之后的数据大小变大,因此不推荐使用这种默认的序列化方式
- 如果要修改序列化方式只需要定义一个MessageConverter类型的Bean即可。Spring会自动注入进去,推荐用JSON方式进行序列化对象,我们操作的是消息发送代码,因此在生产者方实现,步骤如下:
- 我们在publisher服务引入依赖,就是JSON依赖,fastJson或jackson都可
<dependency> <groupId>com.fasterxml.jackson.dataformat</group> <artifactId>jackson-dataformat-xml</artifactId> <version>2.9.10</version> </dependency> - 我们在publisher服务声明MessageConverter:
@Bean public MessageConverter jsonMessageConverter() { return new Jackson2JsonMessageConverter(); }
- 消息转换器接收消息
- 我们在consumer服务引入Jackson依赖,消费者要解析消息
<dependency> <groupId>com.fasterxml.jackson.dataformat</group> <artifactId>jackson-dataformat-xml</artifactId> <version>2.9.10</version> </dependency> - 我们在consumer服务定义MessageConverter,消费者接收解析消息
@Bean public MessageConverter jsonMessageConverter() { return new Jackson2JsonMessageConverter(); } - 定义一个消费者,监听object.queue队列并消费消息
@RabbitListener(queues = "object.queue") public void listenObjectQueue(Map<String,Object> msg) { System.out.println("接收到Map类型的消息【"+msg+"】"); }
- 我们在consumer服务引入Jackson依赖,消费者要解析消息
- 总结
- SpringAMQP利用messageConverter实现消息的序列化和反序列化,默认是JDK序列化方式
- 我们推荐使用JSON序列化方式,需要注意消息发送方与接收方必须使用相同的MessageConverter,否则无法解析















 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









