







之前用node爬过表情包, 最近刚好python大作业需要做一个爬虫的项目, 所以就用python再爬一下
爬取网址: https://www.fabiaoqing.com/
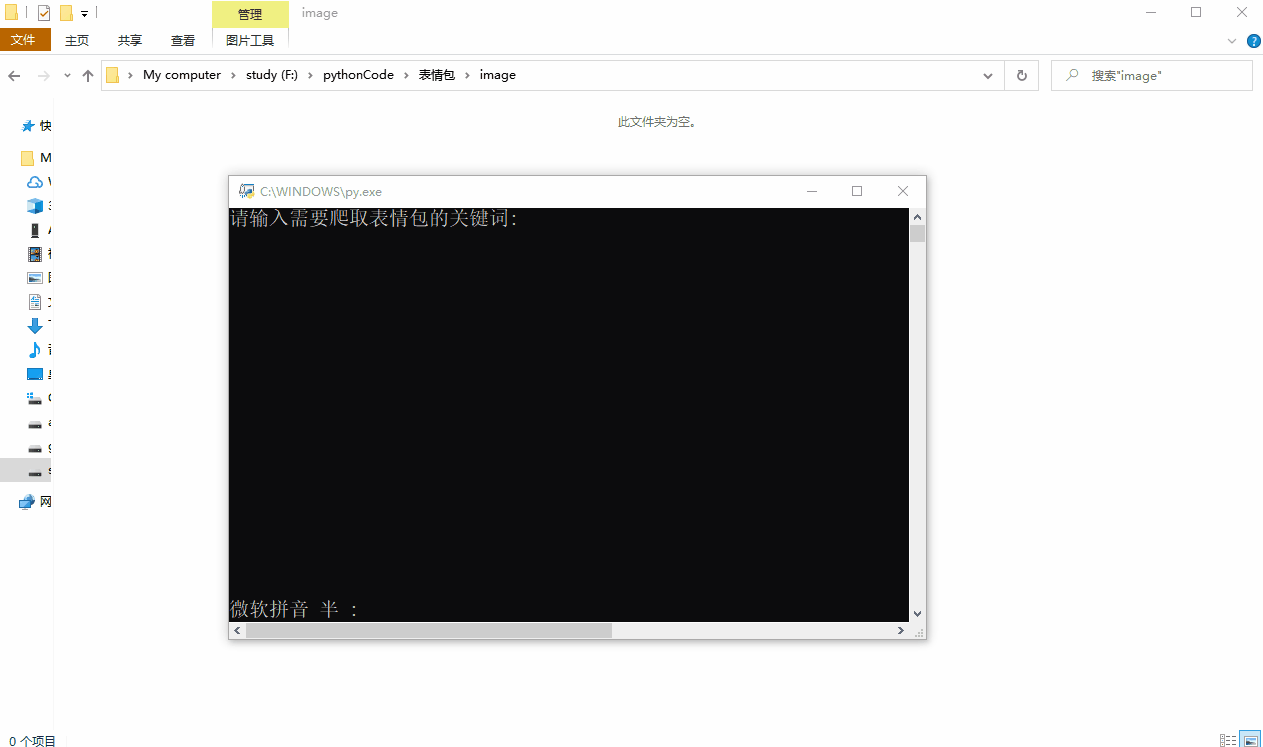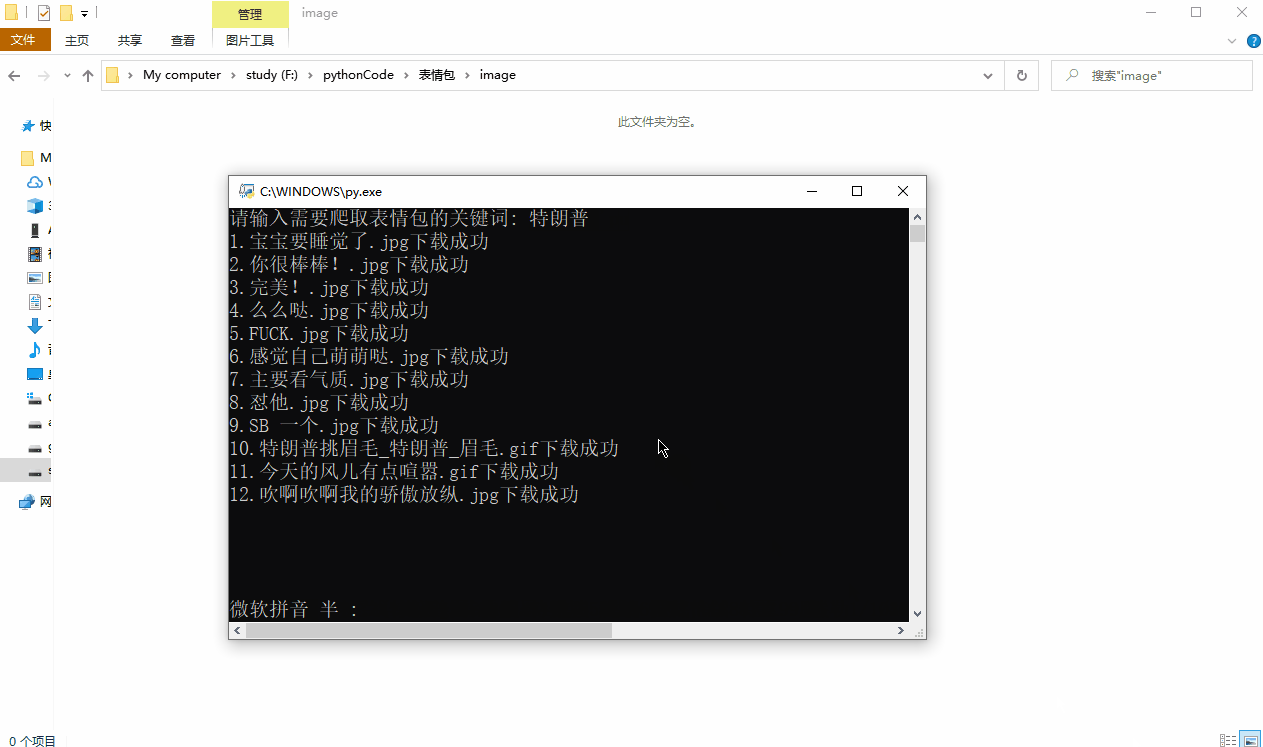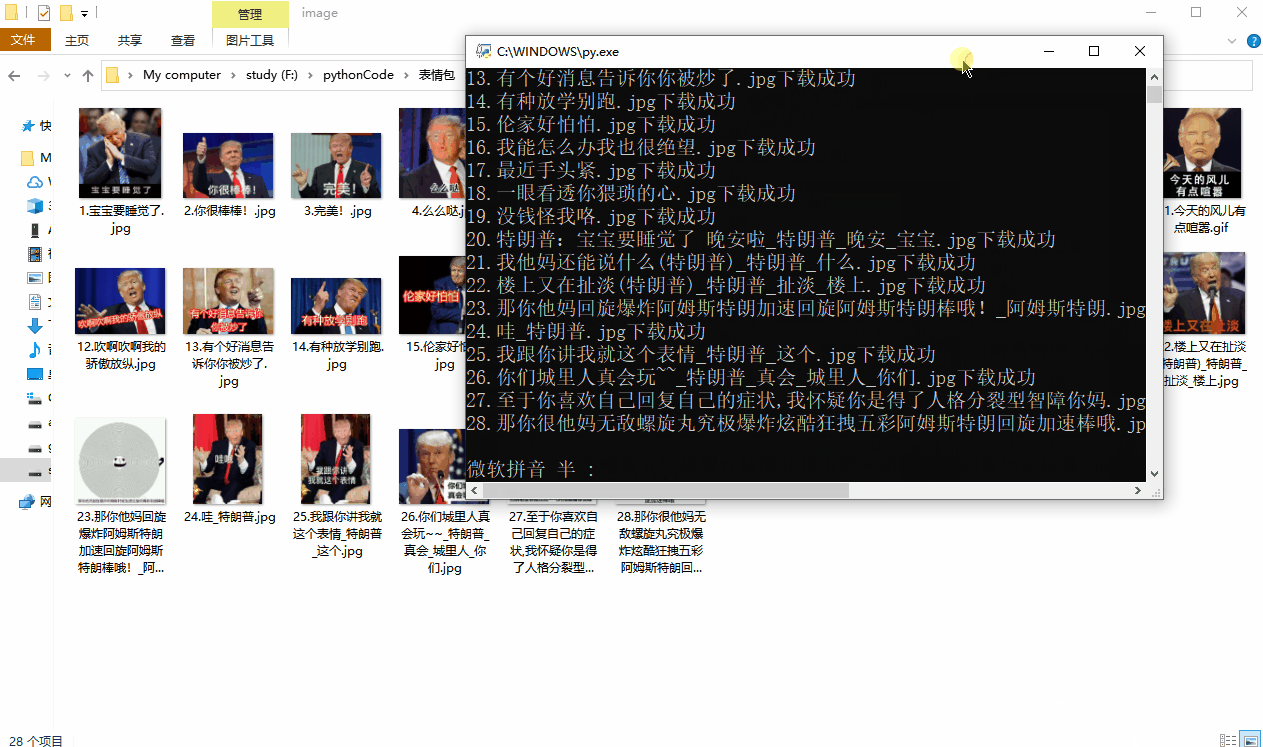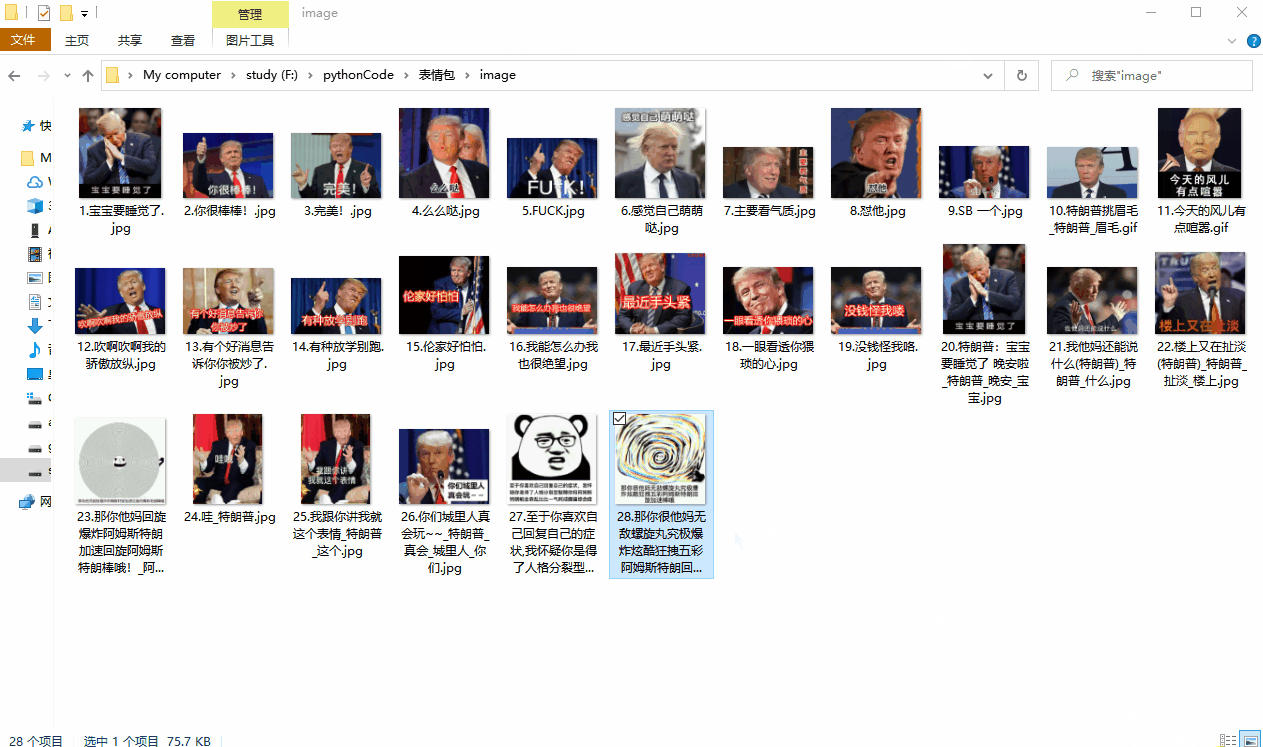
最终效果: 通过用户给定的关键词, 将该网站上所有有关该关键词的表情包都下载到同级目录中的image文件夹中
具体代码如下:
# @coding:utf-8
# @Time : 2020/12/23 11:11
# @Author : TomHe
# @File : main.py
# @Software : PyCharm
import os
import re
import time
import requests
from bs4 import BeautifulSoup
# 发送请求 获取网页源码
def askPage(httpUrl):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
res = requests.get(url=httpUrl, headers=headers)
htmlCode = res.text
return htmlCode
# 获取表情包页码总数
def getPageNum(soup):
dict = soup.find_all('a', attrs={'class': 'item', 'href': True, 'title': False})
# 获取倒数第二个a标签内的内容
lastPageNum = int(dict[-2].text.strip())
return lastPageNum
# 格式化表情包名称
def formatImgName(str):
# 截取 - 之前的名称
flag = str.find('-')
str = str[0:flag - 1]
# 去掉名称中的\n / \ : * ? " < > | ! \f \r
res = re.sub(r'[\f\t\r\n?!<>:"*/|\\]', '', str)
# 当名称大于等于30时 去前30个
if (len(res) >= 30):
res = res[0:31]
return res
# 获取指定网页所有的表情包
def getImgInfo(soup):
# 返回的图片信息列表
imgInfoList = []
# 获得指定的img标签 列表
imgList = soup.find_all('img', attrs={'class': 'ui image bqppsearch lazy', 'src': True, 'title': True})
for item in imgList:
imgInfo = {}
imgInfo['name'] = formatImgName(item.get('alt'))
imgInfo['href'] = item.get('data-original')
imgInfoList.append(imgInfo)
return imgInfoList
# 下载表情包到本地
def downloadImg(imgUrl, imgName):
# 截取url的扩展名
extName = imgUrl[-4:]
res = requests.get(imgUrl)
imgName = imgName + extName
with open('./image/' + imgName, 'wb') as f:
f.write(res.content)
print(imgName + '下载成功')
# 爬虫主函数
def spider(baseUrl):
# 统计图片总个数
imgCount = 0
# 统计开始时间
startTime = time.time()
# 首页URL
mainHttpUrl = baseUrl + '1.html'
# 获取首页html代码
htmlCode = askPage(mainHttpUrl)
# 初始化 BeautifulSoup 获得首页的BeautifulSoup对象
soup = BeautifulSoup(htmlCode, 'html.parser')
# 获取指定表情包页码总数
lastPageNum = getPageNum(soup)
# 判断当前文件目录是否还有 image 文件夹
if ('image' not in os.listdir('./')):
os.mkdir('image')
print('成功创建文件夹 image')
# 循环遍历每一页
for index in range(1, lastPageNum + 1):
# 动态拼接URL
httpUrl = baseUrl + str(index) + '.html'
# 获取HTMl源码
htmlCode = askPage(httpUrl)
# 初始化 BeautifulSoup 获得每一页的BeautifulSoup对象
soup = BeautifulSoup(htmlCode, 'html.parser')
# 获取表情包链接
imgInfoList = getImgInfo(soup)
for img in imgInfoList:
imgCount = imgCount + 1
# 下载到本地
downloadImg(img.get('href'), str(imgCount) + '.' + img.get('name'))
# 统计结束时间
endTime = time.time()
runTime = round(endTime - startTime)
print('下载完成!!!')
print('共耗时 ' + str(runTime) + ' 秒。。。')
print('共下载 ' + str(imgCount) + ' 张表情包。。。')
if __name__ == '__main__':
keyword = input('请输入需要爬取表情包的关键词: ')
baseUrl = 'https://www.fabiaoqing.com/search/bqb/keyword/' + keyword + '/type/bq/page/'
spider(baseUrl)
运行效果如下:















 2557
2557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









