







 本文详细介绍了因子分析的四个关键步骤:1)确认前提条件(如相关系数和KMO值),2)提取因子和构建因子载荷矩阵,3)通过旋转方法赋予因子命名解释,4)计算样本的因子得分。强调了主成分分析和旋转在清晰因子含义中的作用。
本文详细介绍了因子分析的四个关键步骤:1)确认前提条件(如相关系数和KMO值),2)提取因子和构建因子载荷矩阵,3)通过旋转方法赋予因子命名解释,4)计算样本的因子得分。强调了主成分分析和旋转在清晰因子含义中的作用。
因子分析的基本步骤
-
(1)判断因子分析的前提条件是否满足
- 通常有以下几种方法:
- 计算原有变量的相关系数矩阵
- 一般小于0.3就不适合作因子分析
- 计算反映像相关矩阵
- 巴特利特球度检验
- “近似卡方”分布统计量的观测值,对应的概率P值小于给定的显著性水平α,则拒绝原假设原有变量,适合作因子分析;反之,不拒绝原假设,不适合作因子分析。
- KMO检验
- 比较变量间简单相关系数和偏相关系数的指标;
- KMO值越接近1,变量间相关性越强,原有变量越适合作因子分析;
- KMO值越接近0,变量间相关性越弱,原有变量越不适合作因子分析;
- KMO值在0.9以上表示非常适合作因子分析,0.8表示适合,0.7表示一般,0.6表示不适合,0.5以下表示极不适合。
-
(2)因子提取(构造因子变量)和因子载荷矩阵的求解
- 因子分析的关键是根据样本数据求解因子载荷矩阵。因子载荷矩阵的求解方法有:基于主成分模型的主成分分析法、基于因子分析模型的主轴因子法,等等。
- 使用最广泛的是主成分分析法
- 主成分法的主要问题是确定因子变量个数
- 通常有两个标准,来确定k个因子变量
- 根据特征值λi确定因子数:取特征值大于1的特征根
- 根据累计贡献率:通常选取方差累计贡献率大于0.85的特征值个数为因子个数k。
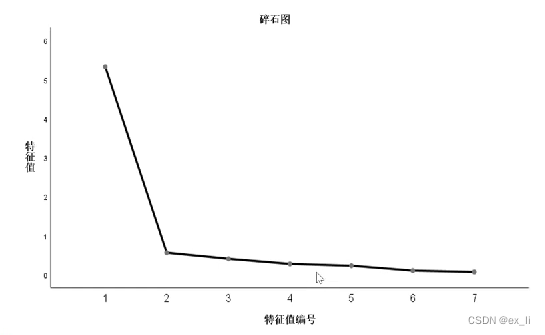
- 因子分析的碎石图:确定因子变量的个数。横坐标为特征值编号,纵坐标为各特征值。第1个特征值较大,像陡峭的山坡;第二个特征值次之;第三个以后的特征值都很小,好像是高山脚下的碎石。
-
(3)使因子具有命名解释性(利用旋转方法使因子变量具有可解释性)
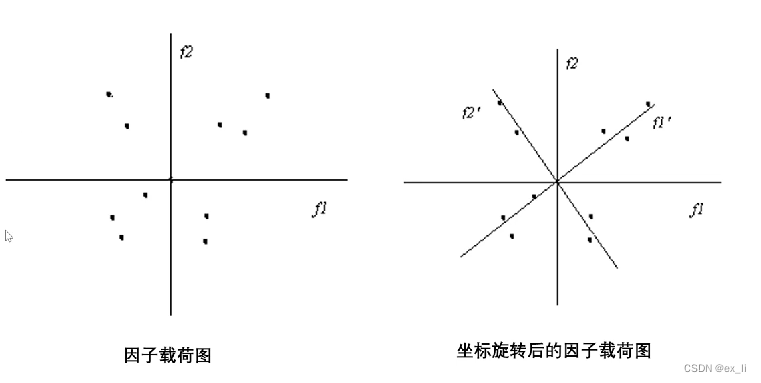
- 发现:aij的绝对值可能在某一行的多个列上都有较大的取值(通常大于0.5),或aij的绝对值可能在某一列的许多行上都有较大的取值。
- 表明:某个原有变量xi可能同时与多个因子都有比较大的相关关系,也就是说,某个原有变量xi的信息需要由若干个因子变量来共同解释;同时,虽然一个因子变量可能能够解释许多变量的信息,但它却只能解释某个变量的一少部分信息,不是任何一个变量的典型代表。
- 结论:因子变量的实际含义不清楚。
- 为了解决因子的实际含义模糊不清的情况,通过因子旋转使:
- 每个变量在尽可能少的因子上有比较高的载荷,即:在立项状态下,让某个变量在某个因子的载荷趋于1,而在其他因子上的载荷趋于0.
- 这样:一个因子变量就能够成为某个变量的典型代表,它的实际含义也就清楚了。
- 因子旋转的目的是通过改变坐标轴的位置,重新分配各个因子所解释的方差比例,使因子结构更简单。
- 因子旋转不改变模型对数据的拟合程度,不改变每个变量的方差共同度。
-
(4)计算各观测(样本)的因子变量得分。
- 因子得分是因子变量构造的最终体现,应给出因子对应每个样本上的值。
- 基本思想:是将因子表示为原有变量的线性组合,即通过因子得分函数计算因子得分
- 某样本的因子得分可看作各观测变量值的加权平均,权数的大小表示了变量对因子的重要程度。

















 2328
2328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









