






Chrome-ChromeDriver配置
一定注意关闭Chrome浏览器的自动更新,每次我搞新爬虫项目都会出现版本不一致的问题(抓狂)。没有安装过Chrome的是最好的,新电脑一安装就是自动匹配好的。如果已有了Chrome,ChromeDriver安装网址:https://googlechromelabs.github.io/chrome-for-testing/#stable,下载与你Chrome版本一致-系统一致的ChromeDriver即可。ChromeDriver文件解压的两个文件后放在你python.exe的文件夹中替换原始版本即可。
项目简介
我想要获取的是《5:20AM》这首网易云音乐的评论,然后进行文本分析。获取的目标数据为:用户名、评论内容、评论时间。拟采用Selenium的方式采用非登录的方式进行数据获取。《5:20AM》这首歌的url为:https://music.163.com/#/song?id=2124731026,Let’s go!
Selenium 方式
Selenium 我觉得比之前我刚接触爬虫的时候方便许多,只要定义好要查找的Xpath即可。但是网易云网页中包含嵌入的iframe或frame元素,所以导致Selenium 只能访问主文档的DOM(文档对象模型),就会出现纯粹使用Selenium点击Xpath的方式失灵,导致一直停在一个网页不会出现任何模拟操作的情况,此时就需要switch_to.frame()方式与在网页中嵌入的iframe或frame元素交互,以防定位不到元素。
什么是Frame或iFrame
Frame:在HTML中, 元素用于在浏览器窗口中划分多个独立的区域,每个区域都能独立地加载文档。这是HTML4的特性,现在已经较少使用。
iFrame(Inline Frame):是HTML中的一个元素(),允许一个HTML文档被嵌入到另一个HTML文档中。它是现代网页中常用的技术,用于嵌入外部内容,例如视频、地图或其他从不同源或网站加载的互动内容。
如何使用switch_to.frame()
通过索引:如果页面中有多个frame,可以通过它们在页面中出现的顺序(从0开始的索引)来切换。
通过名称或ID:如果frame有 name 或 id 属性,可以直接使用这些属性值来切换。
通过WebElement:如果已经通过Selenium获取到了frame的WebElement,也可以直接传递这个WebElement来切换
如何发现网页里有嵌入的iframe或frame元素
使用Web浏览器(如Chrome、Firefox、Edge等)的开发者工具来检查网页的源代码:在“元素”标签页中,使用搜索功能(通常通过 Ctrl+F 快捷键激活),输入 或 来查找这些标签,如下图所示,可以发现网易云音乐的主界面是被iframe元素覆盖的,所以需要使用switch_to.frame()去定位真正的元素位置。
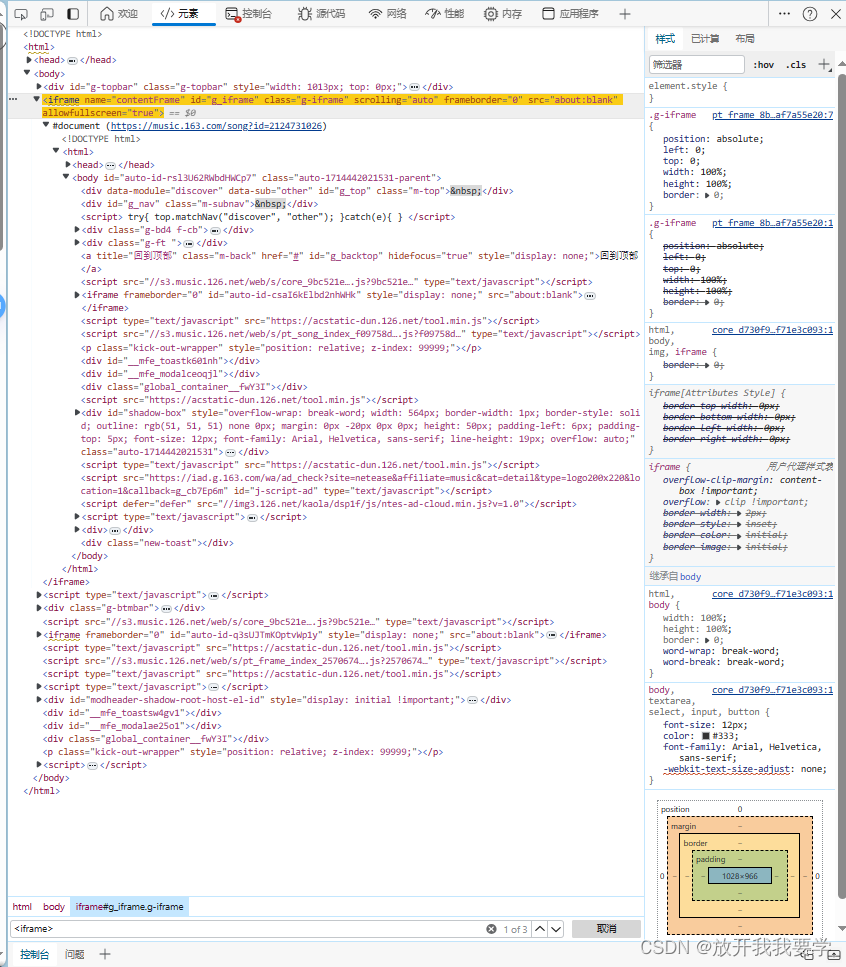
使用Selenium查找iframe或frame元素
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://music.163.com/#/song?id=2124731026")
# 查找所有iframe和frame元素
frames = driver.find_elements(By.TAG_NAME, 'iframe') + driver.find_elements(By.TAG_NAME, 'frame')
# 输出找到的frame和iframe的数量和属性
for frame in frames:
print(frame.get_attribute('id'), frame.get_attribute('name'))
driver.quit()
run了代码之后可以直接列出iframe或frame的名称,根据这些 ID 或名称,可以使用 Selenium 切换到相应的 iframe 进行进一步的操作。
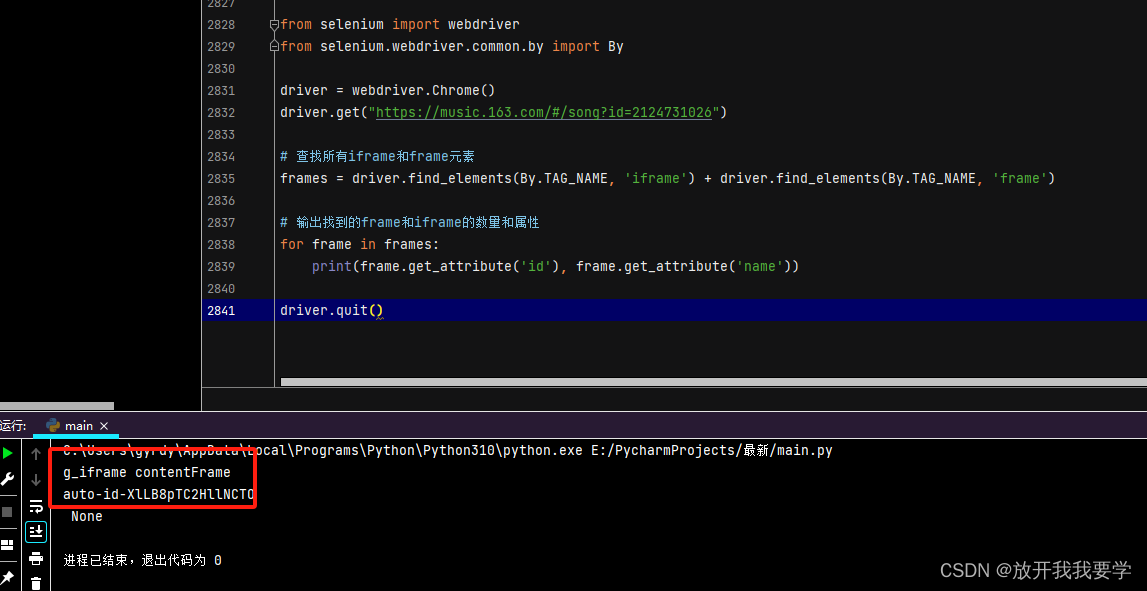
通过两种方式都可以发现这个网页覆盖的主iframe为:
由此可见,定位到的iframe name为"contentFrame",ID为g_iframe
使用switch_to.frame()重新定位元素
既然已经确认了 iframe 的名称 (contentFrame) 和 ID (g_iframe),就可以使用这两个属性中的任何一个来切换到这个iframe,并开始在其中操作元素。
通过名称切换
driver.switch_to.frame("contentFrame")
通过ID切换
driver.switch_to.frame("g_iframe")
本项目选取通过ID进行切换的方式(经多次调试发现使用ID切换才可以正确读取到数据,原因不详)。
测试 :
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
def get_browser():
chrome_options = Options()
browser = webdriver.Chrome(options=chrome_options)
browser.implicitly_wait(10) # 设置隐性等待时间
return browser
def get_comments(url, browser):
browser.get(url)
browser.switch_to.frame("g_iframe") # 如果评论在iframe中,请确保切换到该frame
# 使用 XPath 定位评论容器,注意字符串的正确用法
comments = browser.find_elements(By.XPATH, '//div[@class="cmmts j-flag"]')
for comment in comments:
print(comment.text) # 打印每条评论的文本
if __name__ == "__main__":
browser = get_browser()
try:
get_comments("https://music.163.com/#/song?id=2124731026", browser) # 替换为实际的网页URL
finally:
browser.quit()
print("Browser closed")
结果可见,通过定位到类的方式,成功获取到网易云的评论信息(精彩评论+最新评论)

数据调试part1:将用户名、评论内容、评论时间、点赞量切分
前文实现了,对于元素中所包含全部文本内容的获取,我想要实现自动化的数据切分,输出。通过将前述的定位到类的全部元素进行分析他们的正则式,引入CSS选择器,以实现对数据的精确定位:
使用 CSS 选择器:对于复杂的网页结构,CSS选择器通常提供了一种更快更简洁的方式来定位元素。
CSS选择器
CSS选择器(CSS Selector)是一种在HTML文档中定位和选择元素的语法,它是通过样式表(CSS)中定义的模式来选择HTML文档中的元素。在Selenium自动化测试中,CSS选择器被广泛用于快速、高效地查找页面上的元素,这对于自动化测试和网页数据抓取尤其有用。
CSS选择器的基本组成可以包括元素名称、ID、类名、属性等。这里是一些基本的CSS选择器及其用途:
元素选择器:
选择所有特定的HTML元素。例如,div 会选择所有的 < div > 元素。
ID选择器:
使用 # 符号,选择具有特定ID的单个元素。例如,#header 会选择ID为 header 的元素。
类选择器:
使用 . 符号,选择具有特定类的元素。例如,.menu 会选择所有具有 menu 类的元素。
属性选择器:
使用 [attribute=value] 格式,选择具有特定属性值的元素。例如,[type=“text”] 选择所有 type 属性为 text 的元素。
组合使用
CSS选择器可以组合使用,以更精确地定位元素:
后代选择器:
通过空格分隔,选择某元素内部的后代元素。例如,div p 会选择所有位于任意 < div > 元素内的 < p > 元素。
子选择器:
使用 > 符号,仅选择直接子元素。例如,ul > li 会选择所有直接作为 < ul > 子元素的 < li > 元素。
相邻兄弟选择器:
使用 + 符号,选择紧接在另一元素后的元素。例如,div + p 会选择所有紧跟在 < div > 元素后的第一个 < p > 元素。
通用兄弟选择器:
使用 ~ 符号,选择某元素之后的所有兄弟元素。例如,h1 ~ p 会选择所有在 < h1 > 元素之后的 < p > 元素。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
def get_browser():
chrome_options = Options()
browser = webdriver.Chrome(options=chrome_options)
browser.implicitly_wait(10) # 设置隐性等待时间
return browser
def extract_comment_data(comment_element):
# 用户名
username = comment_element.find_element(By.CSS_SELECTOR, '.cntwrap .cnt .s-fc7').text
# 评论内容
content = comment_element.find_element(By.CSS_SELECTOR, '.cntwrap .cnt').text.split(':', 1)[1]
# 评论时间
time = comment_element.find_element(By.CSS_SELECTOR, '.rp .time').text
# 点赞数,处理点赞数可能不存在的情况
likes_element = comment_element.find_elements(By.CSS_SELECTOR, '.rp a[data-type="like"]')
likes = likes_element[0].text if likes_element else '(0)' # 如果没有找到点赞数,设为'(0)'
likes = likes.strip('()') # 移除括号
return username, content, time, likes
def get_comments(url, browser):
browser.get(url)
browser.switch_to.frame("g_iframe") # 切换到评论所在的iframe
# 获取精彩评论元素
top_comments = browser.find_elements(By.CSS_SELECTOR, 'div.itm[data-id]')
for comment in top_comments:
print(extract_comment_data(comment))
if __name__ == "__main__":
browser = get_browser()
try:
get_comments("https://music.163.com/#/song?id=2124731026", browser)
finally:
browser.quit()
print("Browser closed")
run了代码后段时间内只出现了三行输出结果,就不再加载数据也不结束代码,只能人为断开浏览器(失败告终)
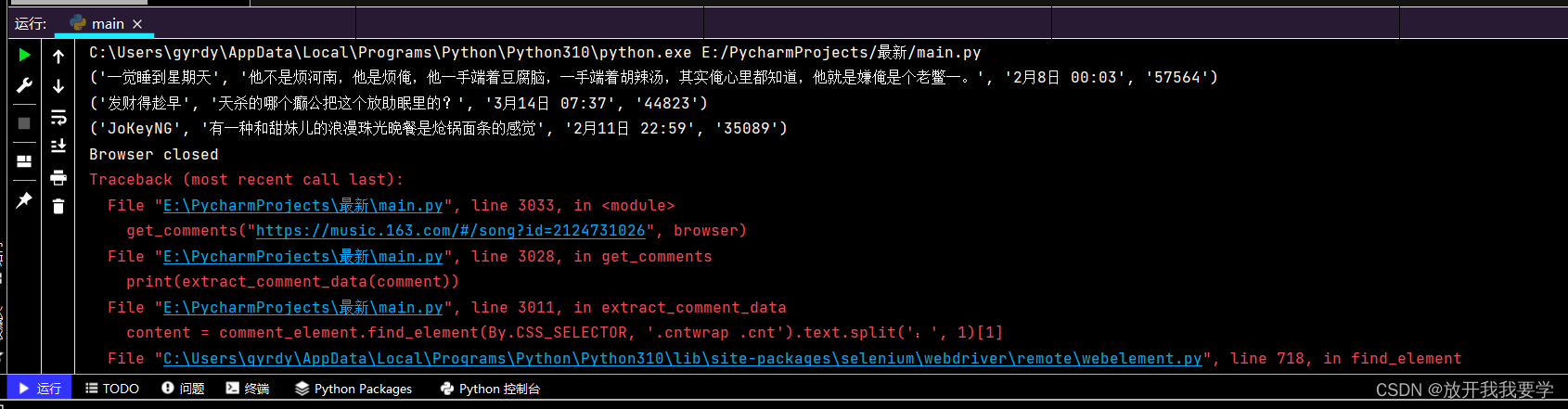
代码在输出三行之后停止执行而没有报错或异常,这可能意味着一些可能的情况:
**有限数量的评论元素:**代码只找到了三个评论元素。这可能是因为页面结构问题、定位器不正确或页面没有加载更多评论。
**加载或渲染问题:**页面可能需要更多时间来加载所有元素,或者需要用户交互(如滚动)来触发更多评论的加载。
**异常未捕获:**可能在处理过程中发生了异常,但没有在代码中捕获或记录。
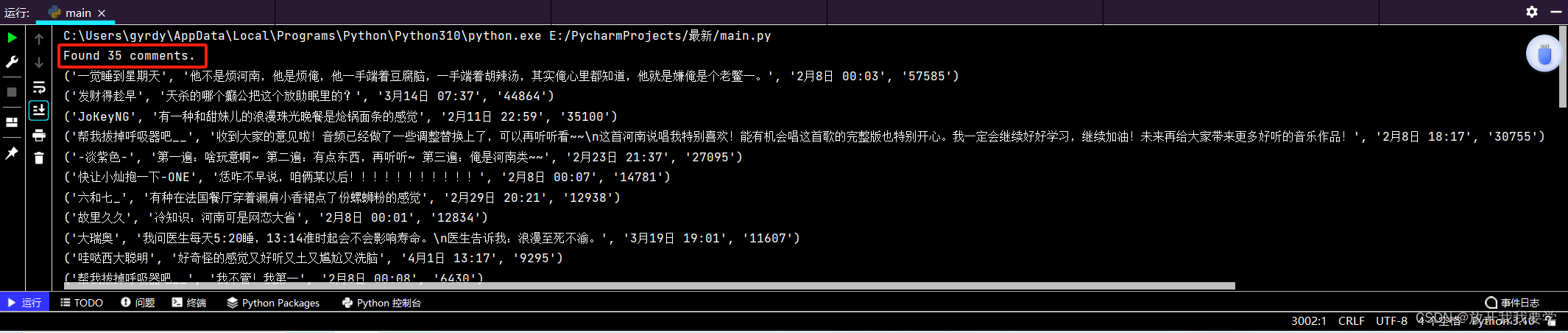
经过手动检查显示页面上确实有35个 .itm[data-id] 元素——评论数量有35个,但我实际上只输出了3个-Debug
最后发现是我的网太差了,但是也增加了等待时间,最后输出了网易云评论的内容,代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def get_browser():
chrome_options = Options()
browser = webdriver.Chrome(options=chrome_options)
browser.implicitly_wait(20) # 设置隐性等待时间
return browser
def get_comments(url, browser):
browser.get(url)
WebDriverWait(browser, 20).until(EC.frame_to_be_available_and_switch_to_it((By.ID, "g_iframe"))) # 确保正确切换到iframe
# 等待直到至少35个评论元素出现
WebDriverWait(browser, 20).until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, 'div.itm[data-id]'))
)
# 提取评论
top_comments = browser.find_elements(By.CSS_SELECTOR, 'div.itm[data-id]')
print(f"Found {len(top_comments)} comments.") # 打印找到的评论数量
for comment in top_comments:
try:
print(extract_comment_data(comment))
except Exception as e:
print(f"Failed to extract data for a comment: {e}")
def extract_comment_data(comment_element):
username = comment_element.find_element(By.CSS_SELECTOR, '.cntwrap .cnt .s-fc7').text
content = comment_element.find_element(By.CSS_SELECTOR, '.cntwrap .cnt').text.split(':', 1)[1]
time = comment_element.find_element(By.CSS_SELECTOR, '.rp .time').text
likes_elements = comment_element.find_elements(By.CSS_SELECTOR, '.rp a[data-type="like"]')
likes = likes_elements[0].text.strip('()') if likes_elements else '0' # 直接在此处理点赞数的格式
return username, content, time, likes
if __name__ == "__main__":
browser = get_browser()
try:
get_comments("https://music.163.com/#/song?id=2124731026", browser)
finally:
browser.quit()
print("Browser closed")
但是仍有不完美,最新评论没有点赞的话没有成功赋值为0,继续debug但是网太差了!!
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def get_browser():
chrome_options = Options()
browser = webdriver.Chrome(options=chrome_options)
browser.implicitly_wait(20) # 设置隐性等待时间
return browser
def get_comments(url, browser):
browser.get(url)
WebDriverWait(browser, 20).until(EC.frame_to_be_available_and_switch_to_it((By.ID, "g_iframe"))) # 确保正确切换到iframe
# 等待直到至少35个评论元素出现
WebDriverWait(browser, 20).until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, 'div.itm[data-id]'))
)
# 提取评论
top_comments = browser.find_elements(By.CSS_SELECTOR, 'div.itm[data-id]')
print(f"Found {len(top_comments)} comments.") # 打印找到的评论数量
for comment in top_comments:
try:
print(extract_comment_data(comment))
except Exception as e:
print(f"Failed to extract data for a comment: {e}")
def extract_comment_data(comment_element):
username = comment_element.find_element(By.CSS_SELECTOR, '.cntwrap .cnt .s-fc7').text
content = comment_element.find_element(By.CSS_SELECTOR, '.cntwrap .cnt').text.split(':', 1)[1]
time = comment_element.find_element(By.CSS_SELECTOR, '.rp .time').text
# likes_elements = comment_element.find_elements(By.CSS_SELECTOR, '.rp a[data-type="like"]')
# likes = likes_elements[0].text.strip('()') if likes_elements else '0' # 直接在此处理点赞数的格式
likes_elements = comment_element.find_elements(By.CSS_SELECTOR, '.rp a[data-type="like"]')
if likes_elements and likes_elements[0].text: # Check 元素是否存在
likes = likes_elements[0].text.strip('()')
else:
likes = '0' # 赋值为0
return username, content, time, likes
if __name__ == "__main__":
browser = get_browser()
try:
get_comments("https://music.163.com/#/song?id=2124731026", browser)
finally:
browser.quit()
print("Browser closed")
网太差了,啊啊啊啊啊啊啊结果输出全靠随缘。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









