







系列文章目录
第一篇:语言基础
第二篇:设计模式
第三篇:数据库
第四篇:计算机网络
第五篇:操作系统
第六篇:LInux
第七篇:数据结构
第八篇:智力题
[181]友元


友元提供了不同类的成员函数之间、类的成员函数和一般函数之间进行数据共享的机制。通过友元,一个不同函数或者另一个类中的成员函数可以访问类中的私有成员和保护成员。友元的正确使用能提高程序的运行效率,但同时也破坏了类的封装性和数据的隐藏性,导致程序可维护性变差。
一个函数可以是多个类的友元函数,但是每个类中都要声明这个函数
友元类的所有成员函数都是另一个类的友元函数,都可以访问另一个类中的隐藏信息(包括私有成员和保护成员)。
但是另一个类里面也要相应的进行声明
添加链接描述
友元类中申明友元函数:告诉类内的东西,这个函数是friend,可以访问类内任何东西
[182]解释下 C++ 中类模板和模板类的区别
类模板是模板的定义,不是一个实实在在的类,定义中用到通用类型参数
模板类是实实在在的类定义,是类模板的实例化。类定义中参数被实际类型所代替。

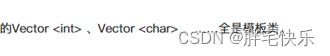
[183]空类
空类的⼤⼩不是0,是1字节。为了确保两个不同对象的地址不同。,空类也会实例化,所以编译器会给空类隐含的添加⼀个字节
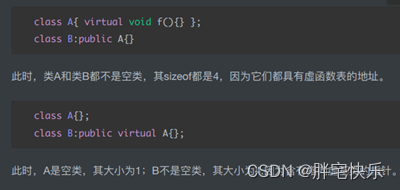
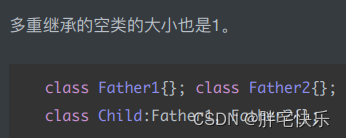
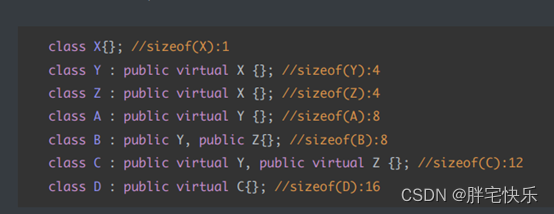
共享虚函数地址表:派⽣类继承的第⼀个是基类,且该基类定义了虚函数地址表,则派⽣类就共享该表⾸址占⽤的存储单元。
[184]STL优势
1.实现数据结构和算法的分离,使得STL非常通用。
2.STL具有高可重用性,高性能,高移植性,夸平台的优点。
高可重用性:STL中几乎所有的代码都采用了模板类和模板函数的方式实现,代码重用性高。
高性能:如 map 可以⾼效地从⼗万条记录⾥⾯查找出指定的记录,如map,采用红黑数的变体实现,效率高。
高移植性:STL模块很容易移植。
[185]请说说 STL 的基本组成部分
广义上讲,STL分为3类:Algorithm(算法)、Container(容器)和Iterator(迭代器&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











