






 本文提出了一种端到端的医疗QA匹配方法SCDE-Bi-LSTM,针对分词错误、深层信息缺失和注意力机制偏差等问题。模型利用双层嵌入和改进的Bi-LSTM,提升了中文医疗问题答案的匹配准确率,且公开了首个80%准确率的医疗QA数据库。
本文提出了一种端到端的医疗QA匹配方法SCDE-Bi-LSTM,针对分词错误、深层信息缺失和注意力机制偏差等问题。模型利用双层嵌入和改进的Bi-LSTM,提升了中文医疗问题答案的匹配准确率,且公开了首个80%准确率的医疗QA数据库。
待完成
Sum:
提出了一个新的端到端方法,包含语义的双层嵌入双向LSTM模型(SCDE-Bi-LSTM),解决医疗领域QA匹配的三个关键问题。
三个问题:(提出的解决方法)
1)现有QA方法在计算相似性时,不包含句子的深层信息;(包含语义信息的文本相似性计算方法)
2)中文医疗词汇分词错误;(双层嵌入句子表达方法)
3)注意力机制导致特征的后向偏差(backward deviation);(使用一个基于Bi-LSTM的改进算法进行特征提取)
I.Introdution
数据集:
1)医疗领域数据集(开源)
从http://www. 120ask.com上爬下来的60000个问题和112986个答案,每个问题有两个正确答案。问题平均长度是50个字,答案平均长度为70个字。
https://github.com/Vitas-Xiong/Chinese-Medical-Question-Answering-System

(a+):正确答案
(a-):错误答案
2)保险QA数据集(未知)
答案选择简化流程:
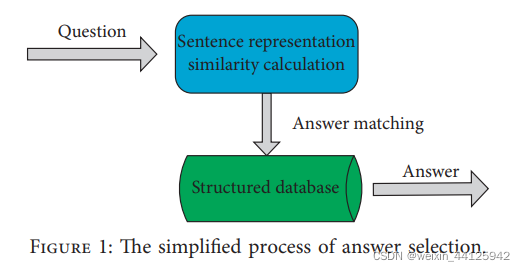
1)问题输入
2)句子表示向量初始化
3)QA相似度计算
4)在结构化数据库中对相似性排序
5)输出相似性最高的答案。
模型输入:
问题(q)和答案池{a1,a2,…,al}(l表示答案数,答案池中最少包括一个正确答案)
论文贡献:
1)我们是第一个在中文医疗QAmatching问题上准确率达到80%的,超过baseline
14%;
2)我们创建和发布了一个中文医疗QA数据库,数据库是开源的;
3)我们提出了一个基于Bi-LSTM的改进算法(SCDE-Bi-LSTM),在不同性能测试上超过了许多有竞争力的baseline;
4)在句子向量表示初始化处理中,我们提出了双层嵌入句子向量表示方法,避免了实验结果中中文分词错误带来的影响。
5)我们提出了一个考虑了语义信息的相似性计算方法,可以在语义层面计算相似性。
Iii.Methodology
模型:基于inner attention-based RNN(IARNN)的双层嵌入Bi-LSTM模型
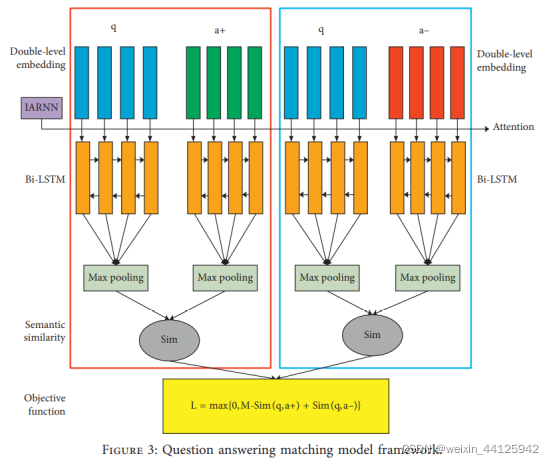
1)LSTM:定长LSTM,分享所有参数的权值,首先要对QA句子进行截断或补充,使其长度相同。
2)IARNN注意力机制:在抽取句子特征之前应用,避免特征的后向偏差。
3)将注意力机制处理过的时间序列信息输入Bi-LSTM模型中,Max池化后,LSTM选择序列特征
双层嵌入向量表示:
两个改进的模型实现
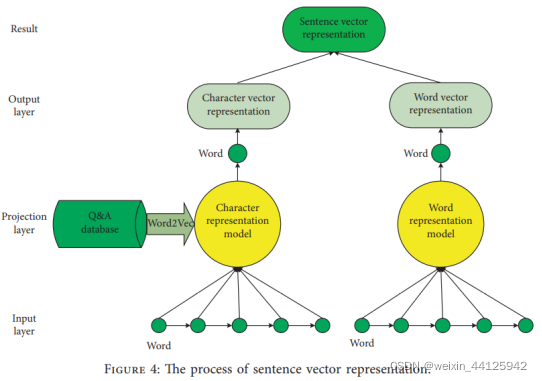
字表示模型、词表示模型:
对所有Q&A句子分词,用Word2Vec训练词和字向量,分别获得一个词表示训练模型和字表示训练模型。消重后获得5004个字和38745个词。用训练模型进行训练获得表示词典。
双层嵌入流程:
对输入的句子分词,分别输入两种模型训练,获得两种向量表示(100维)。
注意:因为两种嵌入方式长度要相同,对字嵌入用零向量补充。
最后的句子向量用Sen表示:
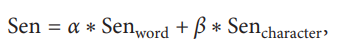
Senword和Sencharacter:词、字嵌入向量表示。
α,β:词、字向量的权重(α+β=1),本文α=0.6


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









