







基础操作
map/filter
先来个最简单:
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
// 我们先学中间操作
// 1.先获取流(不用管其他乱七八糟的创建方式,记住这一个就能应付95%的场景)
Stream<Person> stream = list.stream();
// 2.过滤得到年纪大于18岁的(filter表示过滤【得到】符合传入条件的元素,而不是过滤【去除】)
Stream<Person> filteredByAgeStream = stream.filter(person -> person.getAge() > 18);
// 3.只要名字,不需要整个Person对象(为什么在这个案例中,filter只能用Lambda,map却可以用方法引用?)
Stream<String> nameStream = filteredByAgeStream.map(Person::getName);
// 4.现在返回值是Stream<String>,没法直接使用,帮我收集成List<String>
List<String> nameList = nameStream.collect(Collectors.toList());
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
再来一个:
public static void main(String[] args) {
// 直接链式操作
List<String> nameList = list.stream()
.filter(person -> person.getAge() > 18)
.map(Person::getName)
.collect(Collectors.toList());
}
sorted
试着加入sorted()玩一下。
在此之前,我们先来见见一位老朋友:Comparator。
这个接口其实早在JDK1.2就有了,但当时只有两个方法:
- compare()
- equals()
JDK1.8通过默认方法的形式引入了很多额外的方法,比如reversed()、Comparing()等。
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
// JDK8之前:Collections工具类+匿名内部类。Collections类似于Arrays工具类,我经常用Arrays.asList()
Collections.sort(list, new Comparator<Person>() {
@Override
public int compare(Person p1, Person p2) {
return p1.getName().length()-p2.getName().length();
}
});
// JDK8之前:List本身也实现了sort()
list.sort(new Comparator<Person>() {
@Override
public int compare(Person p1, Person p2) {
return p1.getName().length()-p2.getName().length();
}
});
// JDK8之后:Lambda传参给Comparator接口,其实就是实现Comparator#compare()。注意,equals()是Object的,不妨碍
list.sort((p1,p2)->p1.getName().length()-p2.getName().length());
// JDK8之后:使用JDK1.8为Comparator接口新增的comparing()方法
list.sort(Comparator.comparingInt(p -> p.getName().length()));
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
来玩一下Stream#sorted(),看看和List#sort()有啥区别。
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
// 直接链式操作
List<String> nameList = list.stream()
.filter(person -> person.getAge() > 18)
.map(Person::getName)
.collect(Collectors.toList());
System.out.println(nameList);
// 我想按姓名长度排序
List<String> sortedNameList = list.stream()
.filter(person -> person.getAge() > 18)
.map(Person::getName)
.sorted()
.collect(Collectors.toList());
System.out.println(sortedNameList);
// Stream(默认自然排序)
// 按照长度倒序(注意细节啊,str2-str1才是倒序)
List<String> realSortedNameList = list.stream()
.filter(person -> person.getAge() > 18)
.map(Person::getName)
.sorted((str1, str2) -> str2.length() - str1.length())
.collect(Collectors.toList());
System.out.println(realSortedNameList);
// sorted()有重载方法,是sorted(Comparator)
// 上面Lambda其实就是调用sorted(Comparator),用Lambda给Comparator接口赋值
// 但Comparator还供了一些方法,能返回Comparator实例
List<String> optimizeNameList = list.stream()
.filter(person -> person.getAge() > 18)
.map(Person::getName)
.sorted(Comparator.reverseOrder())
.collect(Collectors.toList());
System.out.println(optimizeNameList);
// 又是一样的套路,Comparator.reverseOrder()返回的其实是一个Comparator
// 但上面的有点投机取巧,来个正常点的,使用Comparator.comparing()
List<String> result1 = list.stream()
.filter(person -> person.getAge() > 18)
.map(Person::getName)
.sorted(Comparator.comparing(t -> t, (str1, str2) -> str2.length() - str1.length()))
.collect(Collectors.toList());
System.out.println(result1);
// 我去,更麻烦了!!
// 不急,我们先来了解上面案例中Comparator的两个参数
// 第一个是Function映射,就是指定要排序的字段,由于经过上一步map操作,已经是name了,就不需要映射了,所以是t->t
// 第二个是比较规则
// 我们把map和sorted调换一下顺序,看起来就不那么别扭了
List<String> result2 = list.stream()
.filter(person -> person.getAge() > 18)
.sorted(Comparator.comparing(Person::getName, String::compareTo).reversed())
.map(Person::getName)
.collect(Collectors.toList());
System.out.println(result2);
// 为什么Comparator.comparing().reversed()可以链式调用呢?
// 因为Comparator.comparing()返回的还是Comparator对象~
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
limit/skip
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
List<String> result = list.stream()
.filter(person -> person.getAge() > 17)
// peek()先不用管,它不会影响整个流程,就是打印看看filter操作后还剩什么元素
.peek(person -> System.out.println(person.getName()))
.skip(1)
.limit(2)
.map(Person::getName)
.collect(Collectors.toList());
System.out.println(result);
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
结果
==== 过滤后的元素有3个 ====
i
am
iron
==== skip(1)+limit(2)后的元素 ====
[am, iron]
所谓的skip(N)就是跳过前面N个元素,limit(N)就是只取N个元素。
collect
collect()是最重要、最难掌握、同时也是功能最丰富的方法。
最常用的4个方法:Collectors.toList()、Collectors.toSet()、Collectors.toMap()、Collectors.joining()
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
// 最常用的4个方法
// 把结果收集为List
List<String> toList = list.stream().map(Person::getAddress).collect(Collectors.toList());
System.out.println(toList);
// 把结果收集为Set
Set<String> toSet = list.stream().map(Person::getAddress).collect(Collectors.toSet());
System.out.println(toSet);
// 把结果收集为Map,前面的是key,后面的是value,如果你希望value是具体的某个字段,可以改为toMap(Person::getName, person -> person.getAge())
Map<String, Person> nameToPersonMap = list.stream().collect(Collectors.toMap(Person::getName, person -> person));
System.out.println(nameToPersonMap);
// 把结果收集起来,并用指定分隔符拼接
String result = list.stream().map(Person::getAddress).collect(Collectors.joining("~"));
System.out.println(result);
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
关于collect收集成Map的操作,有一个小坑需要注意:
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("iron", 17, "宁波", 888.8));
}
public static void main(String[] args) {
Map<String, Person> nameToPersonMap = list.stream().collect(Collectors.toMap(Person::getName, person -> person));
System.out.println(nameToPersonMap);
}
@Getter
@Setter
@AllArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
", address='" + address + '\'' +
", salary=" + salary +
'}';
}
}
}
尝试运行上面的代码,会观察到如下异常:
Exception in thread "main" java.lang.IllegalStateException: Duplicate key Person{name='iron', age=21, address='杭州', salary=888.8}
这是因为toMap()不允许key重复,我们必须指定key冲突时的解决策略(比如,保留已存在的key):
public static void main(String[] args) {
Map<String, Person> nameToPersonMap = list.stream()
.collect(Collectors.toMap(Person::getName, person -> person, (preKey, nextKey) -> preKey));
System.out.println(nameToPersonMap);
}
如果你希望key覆盖,可以把(preKey, nextKey) -> preKey)换成(preKey, nextKey) -> nextKey)。
你可能会在同事的代码中发现另一种写法:
public static void main(String[] args) {
Map<String, Person> nameToPersonMap = list.stream().collect(Collectors.toMap(Person::getName, Function.identity());
System.out.println(nameToPersonMap);
}
Function.identity()其实就是v->v:
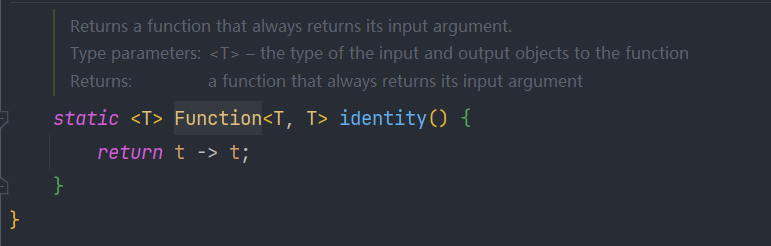
但它依然没有解决key冲突的问题,而且对于大部分人来说,相比person->person,Function.identity()的可读性不佳。
聚合:max/min/count
max/min
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
// 匿名内部类的方式,实现Comparator,明确按什么规则比较(所谓最大,必然是在某种规则下的最值)
Optional<Integer> maxAge = list.stream().map(Person::getAge).max(new Comparator<Integer>() {
@Override
public int compare(Integer age1, Integer age2) {
return age1 - age2;
}
});
System.out.println(maxAge.orElse(0));
Optional<Integer> max = list.stream().map(Person::getAge).max(Integer::compareTo);
System.out.println(max.orElse(0));
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
count
public static void main(String[] args) {
long count = list.stream().filter(person -> person.getAge() > 18).count();
System.out.println(count);
}
去重:distinct
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
long count = list.stream().map(Person::getAddress).distinct().count();
System.out.println(count);
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
所谓“去重”,就要明确怎样才算“重复”。那么,distinct()是基于什么标准呢?
还是那两样:hashCode() 和 equals(),所以记得重写这两个方法(一般使用Lombok的话问题不大)。
distinct() 提供的去重功能比较简单,就是判断对象重复。如果希望实现更细粒度的去重,比如根据对象的某个属性去重,可以怎么做呢?可以参考:分享几种 Java8 中通过 Stream 对列表进行去重的方法
一般来说,这些用法已经覆盖实际开发90%的场景了。
















 985
985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











