






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言

一、Flink 四大基石窗口和时间
1.四大基石
1)、窗口Window
- 流计算中一般在对流数据进行操作之前都会先进行开窗,即基于一个什么样的窗口上做这个计算
- Flink提供了开箱即用的各种窗口,比如滑动窗口、滚动窗口、会话窗口以及非常灵活的自定义的窗口
- 类似离线批处理分析中开窗函数中窗口大小设置
2)、时间Time
- Flink中窗口计算,基本上都是基于时间设置窗口
- Flink还实现了Watermark的机制,能够支持基于事件时间的处理,能够容忍迟到/乱序的数据
- 基于事件时间窗口计算:EventTime事件时间、窗口计算Window、窗口类型
3)、状态State
- Flink计算引擎,自身就是基于状态计算框架,默认情况下程序自己管理状态
- 提供一致性的语义,使得用户在编程时能够更轻松、更容易地去管理状态
- 提供一套非常简单明了的State API,包括ValueState、ListState、MapState,BroadcastState
4)、检查点Checkpoint
- Flink Checkpoint检查点:保存状态数据
- 基于Chandy-Lamport算法实现了一个分布式的一致性的快照,从而提供了一致性的语义
- 进行Checkpoint后,可以设置自动进行故障恢复
- 保存点Savepoint,人工进行Checkpoint操作,进行程序恢复执行
2.Flink Window
- 窗口(window)就是从 Streaming 到 Batch 的一个桥梁。窗口将无界流(unbounded data stream)划分很多有界流(bounded stream),对无界流进行计算:批处理Batch Processing。
Flink Window 窗口的结构中,有两个必须的两个操作:
- 第一、窗口分配器(WindowAssigner):将数据流中的元素分配到对应的窗口。
- 第二、窗口函数(Window Function):当满足窗口触发条件后,对窗口内的数据使用窗口处理函数(Window Function)进行处理,常用的有reduce、aggregate、process。
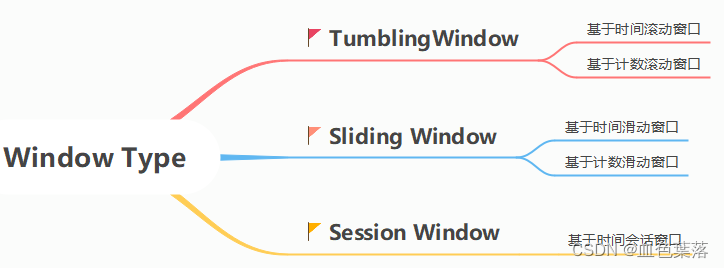
窗口类型:

-
1)、时间窗口
TimeWindow- 按照时间间隔划分出窗口,并对窗口中数据进行计,如每xx分钟统计,最近xx分钟的数据
- 划分为:**滚动(Tumbling)窗口和滑动(Sliding)**窗口
-
2)、计数窗口
CountWindow- 按照
数据条目数进行设置窗口,比如每10条数据统计一次 - 划分为:**滚动(Tumbling)窗口和滑动(Sliding)**窗口
- 按照
-
3)、会话窗口
SessionWindow- 会话Session相关,表示多久没有来数据,比如5分钟都没有来数据,将前面的数据作为一个窗口
- 当登录某个网站,超过一定时间对网站网页未进行任何操作(比如30分钟),自动退出登录,需要用户重新登录,Session会话超时
session窗口跟滚动窗口和滑动窗口相比,不会有重叠和固定的开始时间和结束时间的情况,相反,当它在一个固定的时间周期内不再收到元素,即非活动间隔产生,那个这个窗口就会关闭。
在Flink窗口计算中,无论时间窗口还是计数窗口,都可以分为2种类型:滚动Tumbling和滑动Sliding窗口
1)、滚动窗口(Tumbling Window)
- 条件:窗口大小size = 滑动间隔 slide
2)、滑动窗口(Sliding Window)
- 条件:窗口大小 != 滑动间隔,通常条件【
窗口大小size > 滑动间隔slide】
相较于滚动窗口,滑动窗口会出现重复数据;
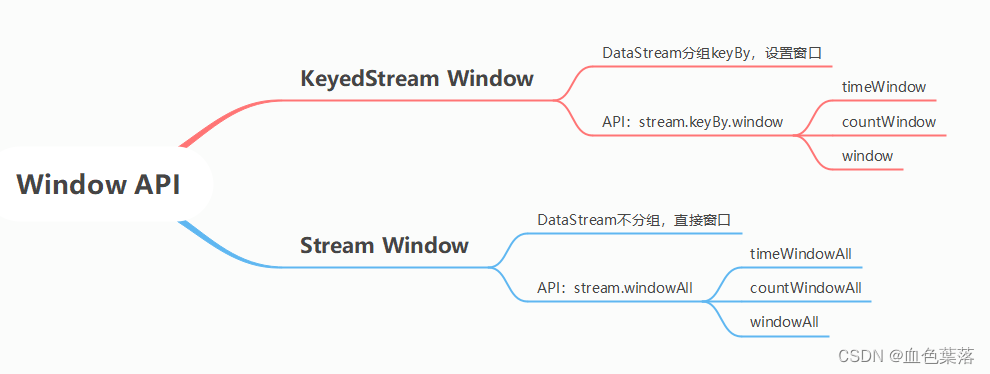
3、Window API
在Flink流计算中,提供Window窗口API分为2种:
-
1)、针对
KeyedStream窗口API:window先对数据流DataStream进行分组keyBy,再设置窗口window,最后进行聚合apply操作。- 第一步、数据流DataStream调用
keyBy函数分组,获取KeyedStream - 第二步、
KeyedStream.window设置窗口 - 第三步、聚合操作,对窗口中数据进行聚合统计,函数:reduce、aggregate、
apply()等

- 第一步、数据流DataStream调用
-
2)、非KeyedStream窗口API:
windowAll- 直接调用窗口函数:
windowAll,然后再对窗口所有数据进行处理,未进行分组 - 聚合操作,对窗口中数据进行聚合统计,函数:reduce、aggregate、
apply()等

- 直接调用窗口函数:
-
滚动时间窗口案例
// 3-1. 对数据进行转换处理: 过滤脏数据,解析封装到二元组中
SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = inputStream
.filter(line -> line.trim().split(",").length == 2)
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String line) throws Exception {
System.out.println("item: " + line);
String[] array = line.trim().split(",");
Tuple2<String, Integer> tuple = Tuple2.of(array[0], Integer.parseInt(array[1]));
// 返回
return tuple;
}
});
// todo: 3-2. 窗口计算,每隔5秒计算最近5秒各个卡口流量
SingleOutputStreamOperator<String> windowStream = mapStream
// a. 设置分组key,按照卡口分组
.keyBy(tuple -> tuple.f0)
// b. 设置窗口,并且为滚动窗口:size=slide
.window(
TumblingProcessingTimeWindows.of(Time.seconds(5))
)
// c. 窗口计算,窗口函数
.apply(new WindowFunction<Tuple2<String, Integer>, String, String, TimeWindow>() {
// 定义变量,对日前时间数据进行转换
private FastDateFormat format = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss") ;
@Override
public void apply(String key, TimeWindow window,
Iterable<Tuple2<String, Integer>> input,
Collector<String> out) throws Exception {
// 获取窗口时间信息:开始时间和结束时间
String winStart = this.format.format(window.getStart());
String winEnd = this.format.format(window.getEnd()) ;
// 对窗口中数据进行统计:求和
int sum = 0 ;
for (Tuple2<String, Integer> tuple : input) {
sum += tuple.f1 ;
}
// 输出结果数据
String output = "window: [" + winStart + " ~ " + winEnd + "], " + key + " = " + sum ;
out.collect(output);
}
});
- 滑动窗口案例
// 3-1. 对数据进行转换处理: 过滤脏数据,解析封装到二元组中
SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = inputStream
.filter(line -> line.trim().split(",").length == 2)
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String line) throws Exception {
System.out.println("item: " + line);
String[] array = line.trim().split(",");
return Tuple2.of(array[0], Integer.parseInt(array[1]));
}
});
// todo: 3-2. 窗口计算,每隔5秒计算最近5秒各个卡口流量
SingleOutputStreamOperator<String> windowStream = mapStream
// a. 设置分组key,按照卡口分组
.keyBy(tuple -> tuple.f0)
// b. 设置窗口,并且为滚动窗口:size != slide
.window(
SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))
)
// c. 窗口计算,窗口函数
.apply(new WindowFunction<Tuple2<String, Integer>, String, String, TimeWindow>() {
// 定义变量,对日前时间数据进行转换
private FastDateFormat format = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss") ;
@Override
public void apply(String key, TimeWindow window,
Iterable<Tuple2<String, Integer>> input,
Collector<String> out) throws Exception {
// 获取窗口时间信息:开始时间和结束时间
String winStart = this.format.format(window.getStart());
String winEnd = this.format.format(window.getEnd()) ;
// 对窗口中数据进行统计:求和
int sum = 0 ;
for (Tuple2<String, Integer> tuple : input) {
sum += tuple.f1 ;
}
// 输出结果数据
String output = "window: [" + winStart + " ~ " + winEnd + "], " + key + " = " + sum ;
out.collect(output);
}
});
- 计算时间窗口
// 3-1. 过滤和转换数据类型
SingleOutputStreamOperator<Integer> mapStream = inputStream
.filter(line -> line.trim().length() > 0)
.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) throws Exception {
System.out.println("item: " + value);
return Integer.parseInt(value);
}
});
// TODO: 3-2. 直接对DataStream流进行窗口操作
SingleOutputStreamOperator<String> windowStream = mapStream
// a. 设置窗口,滚动计数窗口
.countWindowAll(5)
// b. 设置窗口函数,计算窗口中数据
.apply(new AllWindowFunction<Integer, String, GlobalWindow>() {
@Override
public void apply(GlobalWindow window, Iterable<Integer> values, Collector<String> out) throws Exception {
// 对窗口中数据进行求和
int sum = 0 ;
for (Integer value : values) {
sum += value ;
}
// 输出累加求和值
String output = "sum = " + sum ;
out.collect(output);
}
});
- 会话时间窗口
// 3-1. 过滤和转换数据类型
SingleOutputStreamOperator<Integer> mapStream = inputStream
.filter(line -> line.trim().length() > 0)
.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) throws Exception {
System.out.println("item: " + value);
return Integer.parseInt(value);
}
});
// 3-2. 直接对DataStream流进行窗口操作
SingleOutputStreamOperator<String> windowStream = mapStream
// a. 设置窗口:会话窗口,超时时间为5秒
.windowAll(
ProcessingTimeSessionWindows.withGap(Time.seconds(5))
)
// b. 设置窗口函数,对窗口中数据进行计算
.apply(new AllWindowFunction<Integer, String, TimeWindow>() {
// 定义变量,对日前时间数据进行转换
private FastDateFormat format = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss") ;
@Override
public void apply(TimeWindow window, Iterable<Integer> values, Collector<String> out) throws Exception {
// 获取窗口时间信息:开始时间和结束时间
String winStart = this.format.format(window.getStart());
String winEnd = this.format.format(window.getEnd()) ;
// 对窗口中数据进行求和
int sum = 0 ;
for (Integer value : values) {
sum += value ;
}
// 输出结果数据
String output = "window: " + winStart + " ~ " + winEnd + " -> " + sum ;
out.collect(output);
}
});
4、Time 时间语义
-
1)、事件时间
EventTime- 事件真真正正发生产生的时间,比如订单数据中订单时间表示订单产生的时间
-
2)、摄入时间
IngestionTime- 数据被流式程序获取的时间
-
3)、处理时间
ProcessingTime- 事件真正被处理/计算的时间
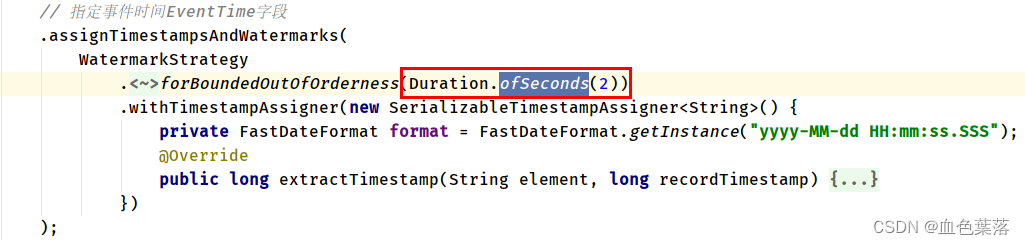
基于事件时间EventTime窗口分析,指定事件时间字段,使用 assignTimestampsAndWatermarks方法,类型必须为Long类型。
// 3-1. 过滤脏数据和指定事件时间字段字段
SingleOutputStreamOperator<String> timeStream = inputStream
.filter(line -> line.trim().split(",").length == 3)
// todo: step1、指定事件时间字段,并且数据类型为Long类型
.assignTimestampsAndWatermarks(
WatermarkStrategy
// 暂不考虑数据乱序和延迟
.<String>forBoundedOutOfOrderness(Duration.ofSeconds(0))
// 指定事件时间字段
.withTimestampAssigner(
new SerializableTimestampAssigner<String>() {
private FastDateFormat format = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss");
@SneakyThrows
@Override
public long extractTimestamp(String element, long recordTimestamp) {
// 2022-04-01 09:00:01,a,1 -> 2022-04-01 09:00:01 -> 1648774801000
System.out.println("element -> " + element);
// 分割字符串
String[] array = element.split(",");
// 获取事件时间
String eventTime = array[0];
// 转换格式
Date eventDate = format.parse(eventTime);
// z转换Long类型并返回
return eventDate.getTime();
}
}
)
);
默认情况下(不考虑乱序和延迟),当数据事件时间EventTime >= 窗口结束时间,触发窗口数据计算。
基于事件时间EventTime窗口分析,如果不考虑数据延迟乱序,当窗口被触发计算以后,延迟乱序到达的数据将不会被计算,而是直接丢弃。
- 窗口起始时间计算方式:
timestamp - (timestamp - offset + wondowsize)%windowsize
如:00:00:01 窗口大小:5s 乱序时间:0s,则:
1 -(1 - 0 + 5 )% 5 = 0
4、乱序和延迟数据处理
-
Watermark 水印机制
在实际业务数据中,数据乱序到达流处理程序,属于正常现象,原因在于网络延迟导致数据延迟,无法避免的,所以应该可以允许数据乱序达到(在某个时间范围内),依然参与窗口计算。
-
Allowed Lateness 允许延迟
默认情况下,当watermark超过end-of-window之后,再有之前的数据到达时,这些数据会被删除。为了避免有些迟到的数据被删除,因此产生了allowedLateness的概念。

-
1)、乱序数据:Watermark,窗口数据计算等一下
- 使用水位线Watermark,给每条数据加上一个时间戳
- Watermark = 数据事件时间 - 最大允许乱序时间
- 当数据的Watermark >= 窗口结束时间,并且窗口内有数据,触发窗口数据计算
-
2)、延迟数据:AllowedLateness,窗口计算状态保存一段时间
- 设置方法参数:
allowedLateness,表示允许延迟数据最多可以迟到多久,还可以进行计算(保存窗口,并且触发窗口计算) - 当某个窗口触发计算以后,继续等待多长时间,如果在等待时间范围内,有数据达到时,依然会触发窗口计算。如果到达等待时长以后,没有数据达到,销毁窗口数据信息。
- 设置方法参数:
真正迟到的数据默认会被丢弃,可通过侧边流输出到文件:
- 1、窗口window 的作用是为了周期性的获取数据
- 2、watermark作用是防止数据出现乱序(经常),事件时间内获取不到指定的全部数据,做的一种保险方法
- 3、allowLateNess是将窗口关闭时间再延迟一段时间
- 4、sideOutPut是最后兜底操作,所有过期延迟数据,指定窗口已经彻底关闭,就会把数据放到侧输出流
5、综合案例
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
Configuration configuration = new Configuration();
configuration.setString("rest.port", "8081");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
env.setParallelism(1) ;
// todo: 设置Checkpoint
setEnvCheckpoint(env) ;
// todo: 设置重启策略
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 10000));
// 2. 数据源-source
DataStreamSource<String> inputStream = env.socketTextStream("node1.itcast.cn", 9999);
// 3. 数据转换-transformation
/*
业务数据:
o_101,u_121,11.50,2022-04-05 10:00:02
3-1. 过滤、解析和封装数据
3-2. 设置事假时间字段值和水位线Watermark
3-3. 窗口设置及处理数据
*/
// 3-1. 过滤、解析和封装数据
SingleOutputStreamOperator<OrderEvent> orderStream = inputStream
.filter(line -> null != line && line.trim().split(",").length == 4)
.map(new MapFunction<String, OrderEvent>() {
@Override
public OrderEvent map(String value) throws Exception {
// 分割为单次
String[] array = value.split(",");
// 封装实体类对象
OrderEvent orderEvent = new OrderEvent() ;
orderEvent.setOrderId(array[0]);
orderEvent.setUserId(array[1]);
orderEvent.setOrderMoney(Double.parseDouble(array[2]));
orderEvent.setOrderTime(array[3]);
// 返回实例对象
return orderEvent;
}
});
// 3-2. 设置事假时间字段值和水位线Watermark
SingleOutputStreamOperator<OrderEvent> timeStream = orderStream.assignTimestampsAndWatermarks(
WatermarkStrategy
// 允许最大乱序时间:2秒,等待2秒钟触发窗口计算
.<OrderEvent>forBoundedOutOfOrderness(Duration.ofSeconds(2))
// 获取订单时间,设置事件事假
.withTimestampAssigner(new SerializableTimestampAssigner<OrderEvent>() {
private FastDateFormat format = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss");
@SneakyThrows
@Override
public long extractTimestamp(OrderEvent element, long recordTimestamp) {
System.out.println("order -> " + element);
// 获取订单时间
String orderTime = element.getOrderTime();
// 转换为Date日期类型
Date orderDate = format.parse(orderTime);
// 转换Long并返回
return orderDate.getTime();
}
})
);
// 3-3. 窗口设置及处理数据
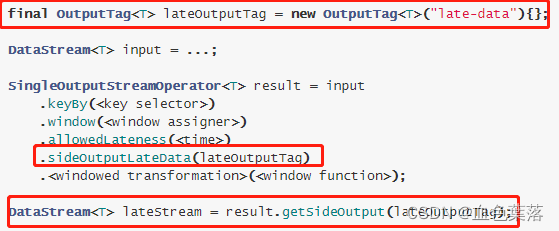
OutputTag<OrderEvent> lateOutputTag = new OutputTag<OrderEvent>("late-order"){} ;
SingleOutputStreamOperator<OrderReport> windowStream = timeStream
// 按照用户分组 event -> event.getUserId()
.keyBy(OrderEvent::getUserId)
// 设置窗口:10s,滚动窗口
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
// 设置最大允许延迟时间
.allowedLateness(Time.seconds(3))
// 设置延迟很久数据侧边输出
.sideOutputLateData(lateOutputTag)
// 设置窗口函数,进行计算
.apply(new OrderWindowFunction());
// 4. 数据终端-sink
windowStream.printToErr();
// 获取侧边流中延迟数据
DataStream<OrderEvent> lateOrderStream = windowStream.getSideOutput(lateOutputTag);
lateOrderStream.printToErr("late>");
// 5. 触发执行-execute
env.execute("StreamOrderWindowReport");
}
/**
* 流式应用Checkpoint检查点设置
*/
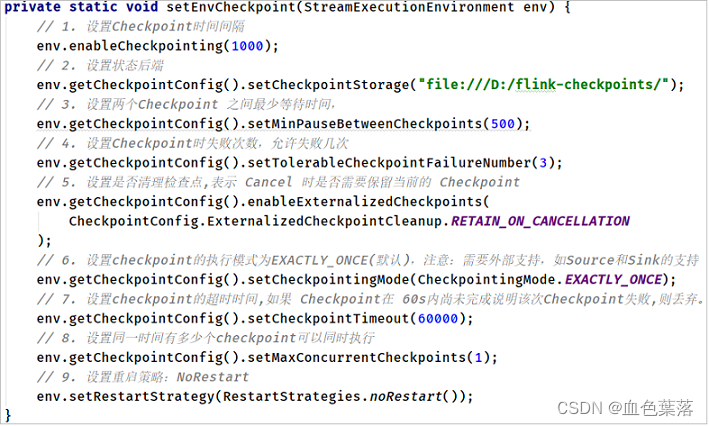
private static void setEnvCheckpoint(StreamExecutionEnvironment env) {
// 1. 启动Checkpoint
env.enableCheckpointing(10000) ;
// 2.设置StateBackend
env.setStateBackend(new HashMapStateBackend());
// 3.设置Checkpoint存储
env.getCheckpointConfig().setCheckpointStorage("file:///D:/ckpt/");
// 4. 设置相邻Checkpoint至少时间间隔
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// 5. 设置Checkpoint最大失败次数
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(3);
// 6. 设置取消job时Checkpoint是删除还是保留
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 7.设置Checkpoint超时时间
env.getCheckpointConfig().setCheckpointTimeout(10 * 60 * 1000);
// 8. 设置Checkpoint最大并发次数
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 9. 设置模式
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
}
二、Flink 四大基石状态和检查点
1.Flink State
什么是状态:流式计算的数据往往是转瞬即逝, 真实业务场景不可能说所有的数据都是进来之后就走掉,没有任何东西留下来,那么留下来的东西其实就是称之为state,中文可以翻译成状态。
- 状态储存类型

ValueState<T>:类型为T的单值状态
- 保存一个可以更新和检索的值(每个值都对应到当前的输入数据的key,因此算子接收到的每个key都可能对应一个值)。
- 这个值可以通过update(T) 进行更新,通过T value() 进行检索。
ListState<T>:key上的状态值为一个列表
- 保存一个元素的列表,可以往这个列表中追加数据,并在当前的列表上进行检索。
- 可以通过add(T) 或者addAll(List) 进行添加元素,通过Iterable get() 获得整个列表。
- 还可以通过update(List) 覆盖当前的列表。
- 如统计按用户id统计用户经常登录的IP
MapState<UK,UV>:即状态值为一个map
- 维护了一个映射列表,可以添加键值对到状态中,也可以获得反映当前所有映射的迭代器。
- 使用put(UK,UV) 或者 putAll(Map<UK,UV>) 添加映射。
- 使用get(UK) 检索特定key。
- 使用entries(),keys()和values() 分别检索映射、键和值的可迭代视图
Broadcast State:具有Broadcast流的特殊属性
- 类比批处理中广播变量:将小表数据广播到TaskManager内存,被Slot中运行Task任务使用
- 一种小数据状态广播向其它流的形式,从而避免大数据流量的传输;
- 在这里,其它流是对广播状态只有只读操作的允许,因为不同任务间没有跨任务的信息交流。
- 一旦有运行实例对于广播状态数据进行更新了,就会造成状态不一致现象。
ReducingState<T>:
- 保存一个单值,表示添加到状态的所有值的聚合。
- 这种状态通过用户传入的reduceFunction,每次调用add方法添加值的时候,会调用reduceFunction,最后合并到一个单一的状态值。
AggregatingState<IN,OUT>:保留一个单值,表示添加到状态的所有值的聚合。和ReducingState相反的是,聚合类型可能与添加到状态的元素的类型不同。FoldingState<T,ACC>:保留一个单值,表示添加到状态的所有值的聚合。与ReducingState相反,聚合类型可能与添加到状态的元素类型不同。
2、state 类型
在Flink中,按照基本类型划分State:Keyed State 和 Operator State。
1)、Keyed State:键控状态
- 和Key有关的状态类型,KeyedStream流上的每一个key,都对应一个state;
- 只能应用于 KeyedStream 的函数与操作中;
- 存储数据结构:ValueState、ListState、MapState、ReducingState和AggregatingState等等
基于KeyedStream上的状态,是跟特定的key绑定的,对KeyedStream流上的每一个key,都对应一个state。
2)、Operator State:算子状态
- 又称为 non-keyed state,每一个 operator state 都仅与一个 operator 的实例(1个SubTask任务)绑定;
- 可以用在所有算子上,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。
- 常见的 operator state 是 数据源source state,例如记录当前 source 的 offset;
- 存储数据结构:ListState或BroadcastState等等
KeyedState案例:
// todo: 自定义状态,实现max算子获取最大值,此处KeyedState定义
SingleOutputStreamOperator<String> statStream = tupleStream
// 指定城市字段进行分组
.keyBy(tuple -> tuple.f0)
// 处理流中每条数据
.map(new RichMapFunction<Tuple3<String, String, Long>, String>() {
// todo: 第1步、定义变量,存储每个Key对应值,所有状态State实例化都是RuntimeContext实例化
private ValueState<Long> maxState = null ;
// 处理流中每条数据之前,初始化准备工作
@Override
public void open(Configuration parameters) throws Exception {
// todo: 第2步、初始化状态,开始默认值null
maxState = getRuntimeContext().getState(
new ValueStateDescriptor<Long>("maxState", Long.class)
);
}
@Override
public String map(Tuple3<String, String, Long> value) throws Exception {
// 获取流中数据对应值
Long currentValue = value.f2;
// todo: step3、从状态中获取存储key以前值
Long historyValue = maxState.value();
// 如果数据为key分组中第一条数据;没有状态,值为null
if(null == historyValue ||historyValue < currentValue){
// todo: step4、更新状态值
maxState.update(currentValue);
}
// 返回状态的最大值
return value.f0 + " -> " + maxState.value();
}
});
3、State TTL 状态生命周期
Flink State Time-To-Live:状态的存活时间
- 在开发Flink应用时,对于许多有状态流应用程序的一个常见要求是自动清理应用程序状态,以有效管理状态大小。
- 从 Flink 1.6 版本开始,社区为状态引入了TTL(time-to-live,生存时间)机制,支持Keyed State 的自动过期,有效解决了状态数据在无干预情况下无限增长导致 OOM 的问题。
设置状态过期:

4、Flink Checkpoint
什么是Checkpoint?也就是所谓的检查点,是用来故障恢复的一种机制。Spark也有Checkpoint,Flink与Spark一样,都是用Checkpoint来存储某一时间或者某一段时间的快照(snapshot),用于将任务恢复到指定的状态。
1)、State:存储的是某一个Operator的运行的状态/历史值,是维护在内存Memory中。
2)、Checkpoint:某一时刻,Flink中所有Operator当前State的全局快照,一般存在磁盘上。
Flink的Checkpoint的核心算法叫做Chandy-Lamport,是一种分布式快照(Distributed Snapshot)算法,应用到流式系统中就是确定一个 Global 的 Snapshot,错误处理的时候各个节点根据上一次的 Global Snapshot 来恢复。
- Checkpoint实现的核心就是
barrier(栅栏或屏障),Flink通过在数据集上间隔性的生成屏障barrier,并通过barrier将某段时间内的状态State数据保存到Checkpoint中(先快照,再保存)。
- Flink的
JobManager创建CheckpointCoordinator; - Coordinator向所有的
SourceOperator发送Barrier栅栏(理解为执行Checkpoint的信号); - SourceOperator接收到Barrier之后,暂停当前的操作(暂停的时间很短,因为后续的写快照是异步的),并制作State快照, 然后将自己的快照保存到指定的介质中(如HDFS), 一切 ok之后向Coordinator汇报并将Barrier发送给下游的其他Operator;
- 其他的如TransformationOperator接收到Barrier,重复第3步,最后将Barrier发送给Sink;
- Sink接收到Barrier之后重复第3步;
- Coordinator接收到所有的Operator的执行ok的汇报结果,认为本次快照执行成功;
栅栏对齐:下游subTask必须接收到上游的所有SubTask发送Barrier栅栏信号,才开始进行Checkpoint操作。
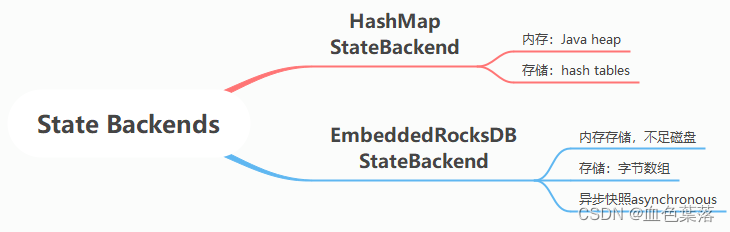
5、StateBackend 状态后端
StateBackend(状态后端):
-
1、State状态存储地方: 内存Memory
-
2、Checkpoint检查点存储地方:Fs文件系统或Memory
Checkpoint其实就是Flink中某一时刻,所有的Operator的全局快照,那么快照应该要有一个地方进行存储,而这个存储的地方叫做状态后端(StateBackend)。
1.13前几种存储方式:
1)、MemoryStateBackend
- State存储:TaskManager内存中
- Checkpoint存储:JobManager内存中
2)、FsStateBackend
- State存储:TaskManager内存
- Checkpoint存储:可靠外部存储文件系统,本地测试可以为LocalFS,测试生产HDFS

3)、RocksDBStateBackend
RocksDB是一个 嵌入式本地key/value 内存数据库,和其他的 key/value 一样,先将状态放到内存中,如果内存快满时,则写入到磁盘中。类似Redis内存数据库。- State存储:TaskManager内存数据库(RocksDB)
- Checkpoint存储:外部文件系统,比如HDFS可靠文件系统中
Flink 1.13 中将状态State和检查点Checkpoint两者区分开来。
-
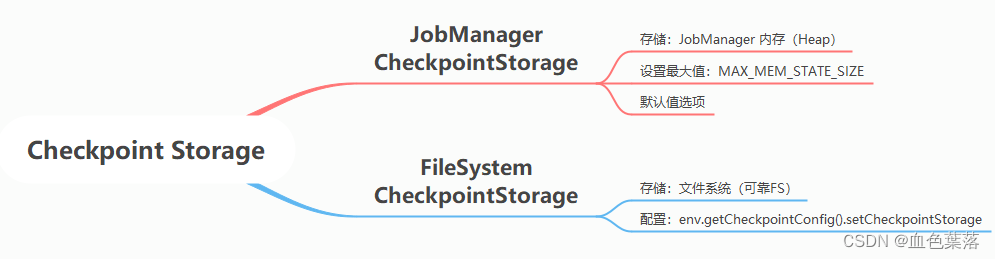
State Backend 的概念变窄,只描述状态访问和存储;
-
Checkpoint storage,描述的是 Checkpoint 行为,如 Checkpoint 数据是发回给 JM 内存还是上传到远程。
设置案例:
程序重启:
- 手动重启
- 使用
flink run运行Job执行,指定参数选项-s path,从Checkpoint检查点启动,恢复以前状态。
- 使用
- 自动重启

Savepoint ,手动设置checkpoint:
# Trigger a Savepoint
$ bin/flink savepoint :jobId [:targetDirectory]
# Trigger a Savepoint with YARN
$ bin/flink savepoint :jobId [:targetDirectory] -yid :yarnAppId
# Stopping a Job with Savepoint
$ bin/flink stop --savepointPath [:targetDirectory] :jobId
# Resuming from Savepoint
$ bin/flink run -s :savepointPath [:runArgs]
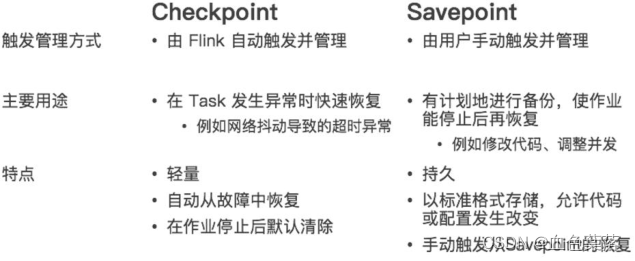
6、End-to-End Exactly-Once
-
端到端的精确一次:结果的正确性贯穿了整个流处理应用的始终,每一个组件都保证了它自己的一致性;
-
端到端的精确一次:Flink 应用从 Source 端开始到 Sink 端结束,数据必须经过的起始点和结束点;
-
实现方式:
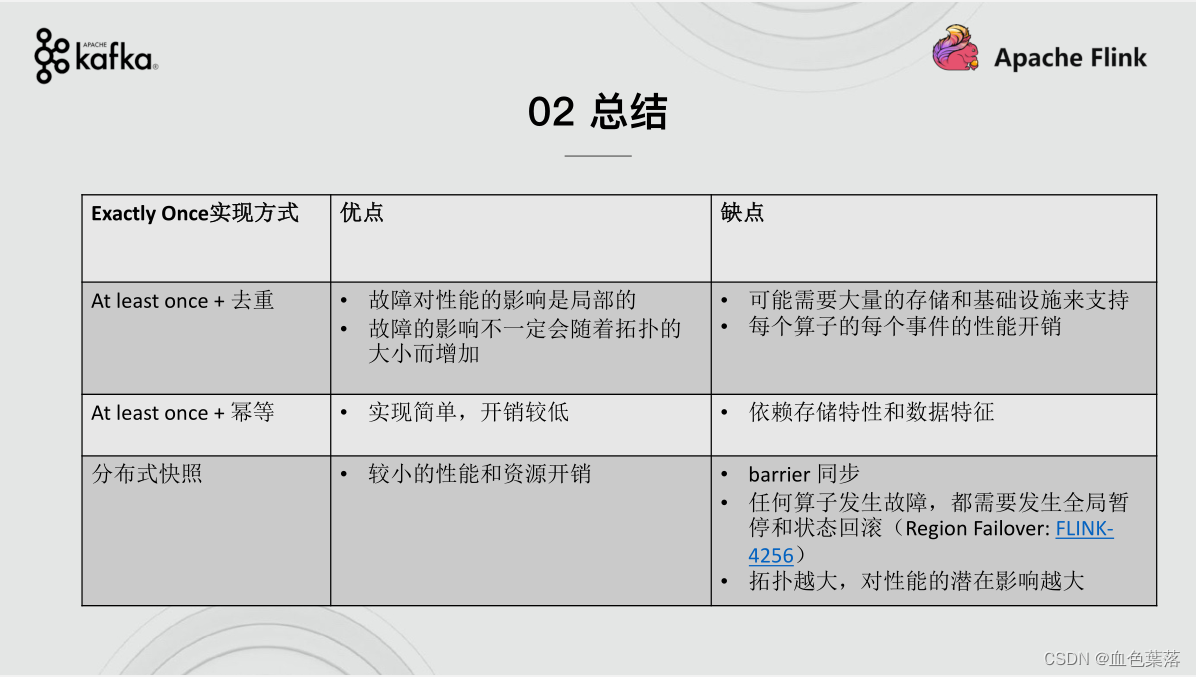
-
要求
- 数据源Source:支持
重设数据的读取位置,比如偏移量offfset(kafka消费数据) - 数据转换Transformation:Checkpoint检查点机制(采用分布式快照算法实现一致性)
- 数据终端Sink:要么支持幂等性写入,要么事务写入。
幂等写入:
-
1、Redis 内存KeyValue数据库
set flink:wordcount:spark 99 -
2、HBase NoSQL数据库
put t1 rk1 info:name zhangsan -
3、MySQL 数据库
replace into tbl_xx (id, name, age) Values(1001, ‘张三’, 34 ) ;
或者
INSERT INTO tab(column) VALUES(?) ON DUPLICATE KEY UPDATE column = VALUES(column);
在事务写入的具体实现上,Flink目前提供了两种方式:
1、预写日志(Write-Ahead-Log)WAL
- 把结果数据先当成状态保存,然后在收到 checkpoint 完成的通知时,一次性写入 sink 系统;
- 简单易于实现,由于数据提前在状态后端中做了缓存,所以无论什么 sink 系统,都能用这种方式;
- DataStream API 提供了一个模板类:
GenericWriteAheadSink,来实现这种事务性 sink;
2、两阶段提交(Two-Phase-Commit,2PC)
- step1、对于每个 checkpoint,Data Sink 任务会启动一个事务,并将接下来所有接收的数据添加到事务里;
- step2、然后将这些数据写入外部 sink 系统,但不提交它们 —— 这时只是预提交;
- step3、当它收到 checkpoint 完成的通知时,它才正式提交事务,实现结果的真正写入;
- 这种方式真正实现了 exactly-once,它需要一个提供事务支持的外部 sink 系统;
- Flink 提供了
TwoPhaseCommitSinkFunction接口。

Exactly-once 两阶段提交步骤总结:
-
第1步、Flink 消费到Kafka数据之后,就会开启一个Kafka的事务,正常写入Kafka分区日志但标记为未提交,这就是Pre-commit(预提交)。
-
第2步、一旦所有的Operator完成各自的Pre-commit,它们会发起一个commit操作。
-
第3步、如果有任意一个Pre-commit失败,所有其他的Pre-commit必须停止,并且Flink会回滚到最近成功完成的Checkpoint。
-
第4步、当所有的Operator完成任务时,Sink段就收到Checkpoint barrier(检查点分界线),Sink保存当前状态存入Checkpoint,通知JobManager,并提交外部事务,用于提交外部检查点的数据。
-
第5步、JobManager收到所有任务的通知,发出确认信息,表示Checkpoint已完成,Sink收到JobManager的确认信息,正式commit(提交)这段时间的数据。
-
第6步、外部系统(Kafka)关闭事务,提交的数据可以正常消费了。
上述过程可以发现,一旦Pre-commit完成,必须要确保commit也要成功,Operator和外部系统都需要对此进行保证。整个 两阶段提交协议2PC就是解决分布式事务问题,所以才能有如今Flink可以端到端精准一次处理。
-
checkpiont 流程
1)、Checkpoint Coordinator 向所有 source 节点 trigger Checkpoint(触发Checkpoint,发送Barrier栅栏);2)、广播barrier并进行持久化
- Source将状态State进行快照,并且进行持久化到存储系统。
- Source节点向下游广播 barrier,这个 barrier 就是实现 Chandy-Lamport 分布式快照算法的核心,下游的 task
只有收到所有 上游 的 barrier才会执行相应的 Checkpoint。
3)、当task完成state备份后,会将
备份数据的地址(state handle)通知给 Checkpointcoordinator4)、下游的 sink 节点收集齐上游两个 input 的 barrier 之后(栅栏对齐),将执行本地快照。
- 展示了
RocksDBincremental Checkpoint (增量Checkpoint)的流程,首先 RocksDB 会全量刷数据到磁盘上,然后 Flink 框架会从中选择没有上传的文件进行持久化备份。
5)、同样的,sink 节点在完成自己的 Checkpoint 之后,会将 state handle 返回通知Coordinator。
6)、最后,当 Checkpoint coordinator 收集齐所有 task 的 state handle,就认为这一次的Checkpoint 全局完成了,向持久化存储中再备份一个 Checkpoint meta 文件。
总结
flink 四大基石
时光如水,人生逆旅矣。














 654
654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









