






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
Flink DataStream API中最底层API,提供process算子,其中需要实现ProcessFunction接口函数
一、ProcessFunction
1、基于state的词频统计
// 1. 执行环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 2. 数据源-source
DataStreamSource<String> sourceStream = env.socketTextStream("node1", 9999);
// 3. 数据转换-transformation
KeyedStream<Tuple2<String, Integer>, String> tupleStream = sourceStream
.filter(line -> line.trim().split("\\s+").length != 0)
.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] strings = value.trim().split("\\s+");
for (String string : strings) {
out.collect(string);
}
}
})
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
return new Tuple2<>(value, 1);
}
})
.keyBy(tuple -> tuple.f0);
// todo:按照单词分组及组内聚合【统计每个单词出现次数]
SingleOutputStreamOperator<String> valueStateStream = tupleStream
// 调用process算子,处理数据
.process(new KeyedProcessFunction<String, Tuple2<String, Integer>, String>() {
// 定义变量,存储每个Key(单词)状态(词频)
private ValueState<Integer> valueState = null;
@Override
public void open(Configuration parameters) throws Exception {
// 定义状态描述符
ValueStateDescriptor<Integer> valueStateDescriptor = new ValueStateDescriptor<Integer>("valueState", Integer.class);
// 设置状态生命周期
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(5))
// 设置什么时候更新状态中值
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
// 当前状态过期以后对程序的可见性
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
// 开启状态生命周期设置
valueStateDescriptor.enableTimeToLive(ttlConfig);
valueState = getRuntimeContext().getState(valueStateDescriptor);
}
@Override
public void processElement(Tuple2<String, Integer> value,
Context ctx,
Collector<String> out) throws Exception {
/*
value -> (flink, 1)
*/
// 获取分组key,此时就是单词:flink
String currentKey = ctx.getCurrentKey();
// a. 从State中获取以前状态的值
Integer historyValue = valueState.value();
// b. 获取传递进来的值
Integer currentValue = value.f1;
// c. 如果是第一次出现key,历史为null
if (null == historyValue) {
// 更新状态
valueState.update(currentValue);
} else {
int sumValue = historyValue + currentValue;
valueState.update(sumValue);
}
// d. 返回结果
String output = currentKey + " -> " + valueState.value();
out.collect(output);
}
});
2、ProcessFunction ontimer定时器
==Timer(定时器)==是Flink Streaming API提供的用于感知并利用处理时间/事件时间变化的机制。
KeyedProcessFunction,在processElement()方法中注册Timer,然后覆写其onTimer()方法作为Timer触发时的回调逻辑。
- 处理时间:调用
context.timerService().registerProcessingTimeTimer()注册,onTimer()在系统时间戳达到Timer设定的时间戳时触发。 - 事件时间:调用
context.timerService().registerEventTimeTimer()注册,onTimer()在Flink内部水印达到或超过Timer设定的时间戳时触发。
// 3. 数据转换-transformation
SingleOutputStreamOperator<OrderData> processStream = orderStream
// 按照订单ID分组
.keyBy(line -> line.split(",")[0])
// 对每个订单数据进行解析分装
.process(new OrderProcessFunction());
public class OrderProcessFunction extends KeyedProcessFunction<String, String, OrderData> {
// 自定义时间格式
private FastDateFormat format = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss.SSS");
// 处理每条数据
@Override
public void processElement(String value, KeyedProcessFunction<String, String, OrderData>.Context ctx, Collector<OrderData> out) throws Exception {
// 切割数据源
String[] strings = value.split(",");
// 封装为OrderData对象
OrderData orderData = new OrderData(strings[0], strings[1], strings[2], strings[3], Double.parseDouble(strings[4]));
out.collect(orderData);
// 设置状态为未付款的数据
if ("未付款".equals(orderData.getOrderStatus())) {
long time = format.parse(orderData.getOrderTime()).getTime();
// 设置定时器
ctx.timerService().registerProcessingTimeTimer(time + 10 * 1000);
}
}
@Override
public void onTimer(long timestamp, KeyedProcessFunction<String, String, OrderData>.OnTimerContext ctx, Collector<OrderData> out) throws Exception {
// a.获取订单id
String orderId = ctx.getCurrentKey();
// b.查询订单的状态
String orderState = queryState(orderId);
System.out.println("订单【" + orderId + "】 查询数据库状态:" + orderState);
// 判断状态,并更新
if ("未付款".equals(orderState)) {
updateState(orderId);
System.out.println("更新订单【" + orderId + "】 数据库状态: 取消...........");
}
}
private void updateState(String orderId) throws Exception {
// a. 加载驱动类,获取连接
Class.forName("com.mysql.jdbc.Driver");
// b.获取连接
Connection conn = DriverManager.getConnection(
"jdbc:mysql://node1:3306/?useUnicode=true&characterEncoding=utf-8&useSSL=false",
"root", "123456"
);
// c.执行查询
PreparedStatement pstmt = conn.prepareStatement("UPDATE db_flink.tbl_orders SET order_status = ? WHERE order_id = ?");
pstmt.setString(1, "取消");
pstmt.setString(2, orderId);
pstmt.executeUpdate();
// c. 关闭连接
pstmt.close();
conn.close();
}
private String queryState(String orderId) throws Exception {
// a. 加载驱动类,获取连接
Class.forName("com.mysql.jdbc.Driver");
// b.获取连接
Connection conn = DriverManager.getConnection(
"jdbc:mysql://node1:3306/?useUnicode=true&characterEncoding=utf-8&useSSL=false",
"root", "123456"
);
// c.执行查询
PreparedStatement pstmt = conn.prepareStatement("SELECT order_status FROM db_flink.tbl_orders WHERE order_id = ?");
// 设置查询条件
pstmt.setString(1, orderId);
// 获取查询结果
ResultSet resultSet = pstmt.executeQuery();
String orderStatus = null;
// 更新返回值
while (resultSet.next()) {
orderStatus = resultSet.getString(1);
}
// 关闭连接
resultSet.close();
pstmt.close();
resultSet.close();
//返回值
return orderStatus;
}
}
3、Broadcast State
BroadcastState:将小数据流DataStream广播到各个Task中,数据存储在MapState中,以key/value对存储的。
Broadcast State 是 Flink 1.5 引入的新特性,可用于以特定方式组合和联合处理两个事件流。
- 第一个流的事件被广播到一个算子的所有并行实例,该算子将它们保存为状态。
- 另一个流的事件不广播,而是发送给同一个算子的单个实例,并与广播流的事件一起处理。
对于需要连接低吞吐量和高吞吐量流或需要动态更新处理逻辑的应用来说,新的broadcast state非常适合。
当大表数据流与小表数据流关联,采用广播Broadcast方式广播小表数据流以后,调用connect方法,将两个流数据进行关联。connect方法,将两个流(数据类型可以不一样)进行关联,分别对流中数据处理。

public static void main(String[] args) throws Exception {
// 1. 执行环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 2. 数据源-source
// 2-1. 构建小表数据流:用户信息 <userId, name, age>
DataStreamSource<UserInfo> userStream = env.addSource(new UserInfoSource());
// 2-2. 构建大表数据流:用户行为日志,<userId, productId, trackTime, eventType>
DataStreamSource<TrackLog> logStream = env.addSource(new TrackLogSource());
// 3. 数据转换-transformation
/*
将小数据流,广播以后,存储到MapState中,方便大表数据流处理数据依据key获取value值
Map[userId, userInfo]
大表数据处理,依据userId,获取小表中对应用户信息UserInfo
map.get(userId) -> userInfo
*/
// todo: 3-1. 广播小表数据
MapStateDescriptor<String, UserInfo> descriptor = new MapStateDescriptor<>("userInfoState", String.class, UserInfo.class);
BroadcastStream<UserInfo> broadcastStream = userStream.broadcast(descriptor);
// todo: 3-2. 将大表数据与广播数据进行connect连接
SingleOutputStreamOperator<String> processStream = logStream
.connect(broadcastStream)
.process(new BroadcastProcessFunction<TrackLog, UserInfo, String>() {
// 处理大表数据流中每条数据, todo:大表数据流中每条数据到BroadcastState中获取数据
@Override
public void processElement(TrackLog value, ReadOnlyContext ctx, Collector<String> out) throws Exception {
// 获取广播状态数据
ReadOnlyBroadcastState<String, UserInfo> broadcastState = ctx.getBroadcastState(descriptor);
// 获取日志数据中userId
String userId = value.getUserId();
// 依据userId到状态中获取对应的用户信息数据
UserInfo userInfo = broadcastState.get(userId);
// 关联数据
String output = userInfo + " -> " + value;
out.collect(output);
}
// 处理广播的小表数据流中数据, todo: 广播流中数据放入BroadcastState中
@Override
public void processBroadcastElement(UserInfo value, Context ctx, Collector<String> out) throws Exception {
// 获取广播状态数据,本地上map集合
BroadcastState<String, UserInfo> broadcastState = ctx.getBroadcastState(descriptor);
// 获取用户id
String userId = value.getUserId();
// 将广播流中数据存储到状态中
broadcastState.put(userId, value);
}
});
// 4. 数据终端-sink
processStream.printToErr();
// 5. 触发执行-execute
env.execute("StreamBroadcastStateDemo");
}
4、Window Aggregation 窗口聚合:全量、增量
第一种、全量聚合:指在窗口触发的时候才会对窗口内的所有数据进行一次计算(等窗口的数据到齐,才开始进行聚合计算,可实现对窗口内的数据进行排序等需求)。 窗口先缓存所有元素,等到触发条件后对窗口内的全量元素执行计算。
第二种、增量聚合:指窗口每进入一条数据就计算一次,窗口保存一份聚合中间数据,每流入一个新元素,新元素与中间数据两两合一,生成新的中间数据。
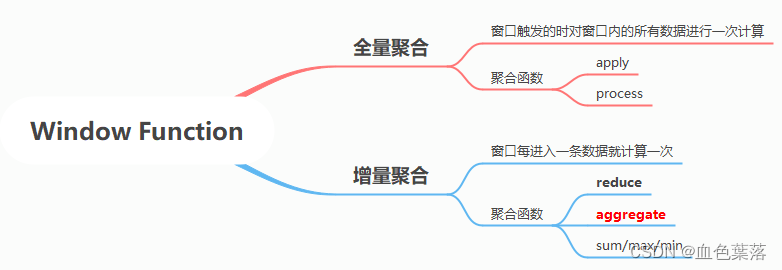
使用全量聚合函数:WindowFunction实时对窗口数据进行聚合:
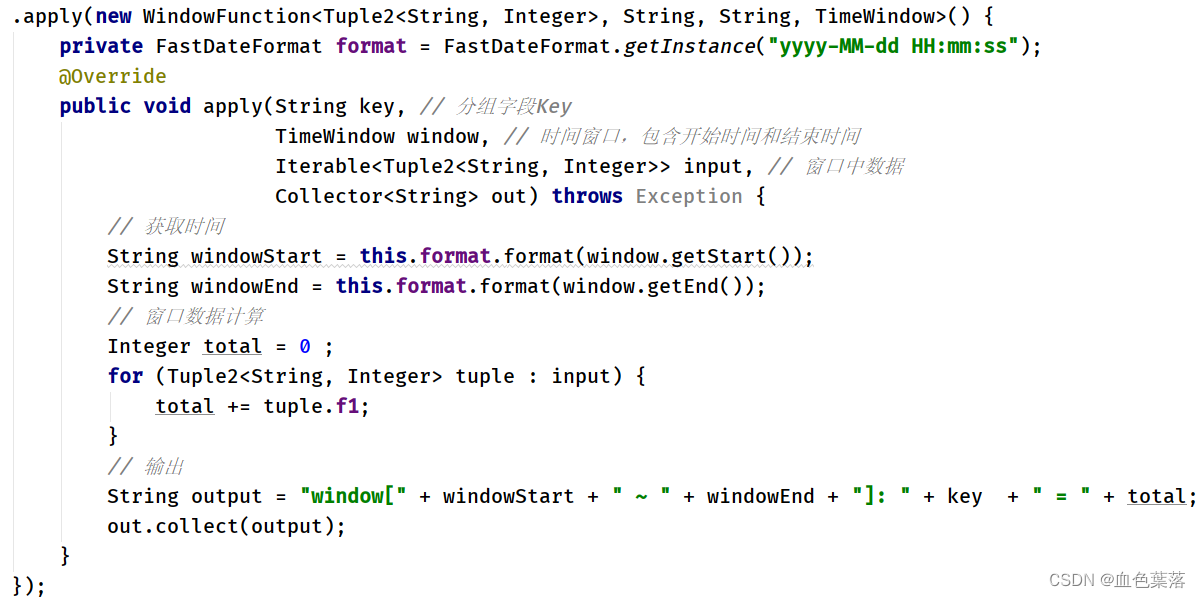
使用全量聚合函数:ProcessWindowFunction实时对窗口数据进行聚合:

使用增量聚合函数:ReduceFunction实时对窗口数据进行聚合:

当使用ProcessWindowFunction窗口函数对窗口中数据聚合时,可以结合使用ReduceFunction或AggregateFunction函数进行增量聚合。
ProcessWindowFunction窗口函数结合ReduceFunction增量函数,对窗口中数据实时增量聚合:
// todo: 3-2. 窗口计算,每隔5秒计算最近5秒各个卡口流量
SingleOutputStreamOperator<String> windowStream = mapStream
// a. 设置分组key,按照卡口分组
.keyBy(tuple -> tuple.f0)
// b. 设置窗口,并且为滚动窗口:size=slide
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
// c. 窗口计算:增量计算,当窗口中进入数据,立刻进行计算
.reduce(
// 增量聚合函数 // 全量聚合函数
new IncrementalReduceFunction(), new FullWindowFunction()
);
/*
对窗口中数据进行增量聚合,使用reduce函数
*/
private static class IncrementalReduceFunction implements ReduceFunction<Tuple2<String, Integer>> {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> tmp,
Tuple2<String, Integer> item) throws Exception {
System.out.println("tmp = " + tmp + ", item = " + item);
/*
tmp:
对窗口中数据聚合时,存储聚合中间结果变量,类型与窗口中数据类型一致
todo: 将窗口中第1条数据首先赋值给tmp
(flink, 10)
item:
窗口中每条数据,todo:从窗口中第2条数据开始赋值
(flink, 1)
*/
// 获取以前聚合值
Integer historyValue = tmp.f1;
// 获取当前值
Integer currentValue = item.f1;
// 合并数据
int updateValue = historyValue + currentValue;
// 返回聚合结果
return Tuple2.of(tmp.f0, updateValue);
}
}
/*
当触发窗口计算时,对窗口中数据进行聚合操作
*/
private static class FullWindowFunction
extends ProcessWindowFunction<Tuple2<String, Integer>, String, String, TimeWindow> {
private FastDateFormat format = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss") ;
@Override
public void process(String key,
Context context,
Iterable<Tuple2<String, Integer>> elements,
Collector<String> out) throws Exception {
// 获取窗口时间
TimeWindow window = context.window();
String winStart = this.format.format(window.getStart());
String winEnd = this.format.format(window.getEnd());
// 窗口数据计算
Tuple2<String, Integer> totalTuple = elements.iterator().next();
// 输出
String output = "window[" + winStart + " ~ " + winEnd + "]: " + key + " = " + totalTuple.f1 ;
out.collect(output);
}
}
5、Aysnc IO
1.2版本引入。主要目的是为了解决与外部系统交互时网络延迟成为了系统瓶颈的问题。
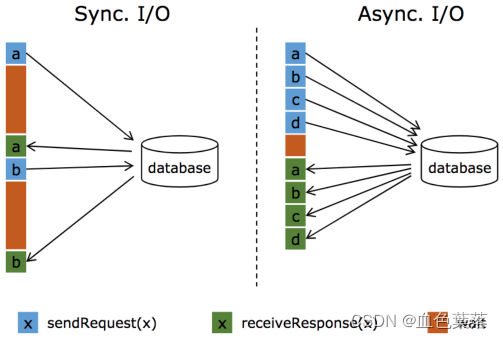
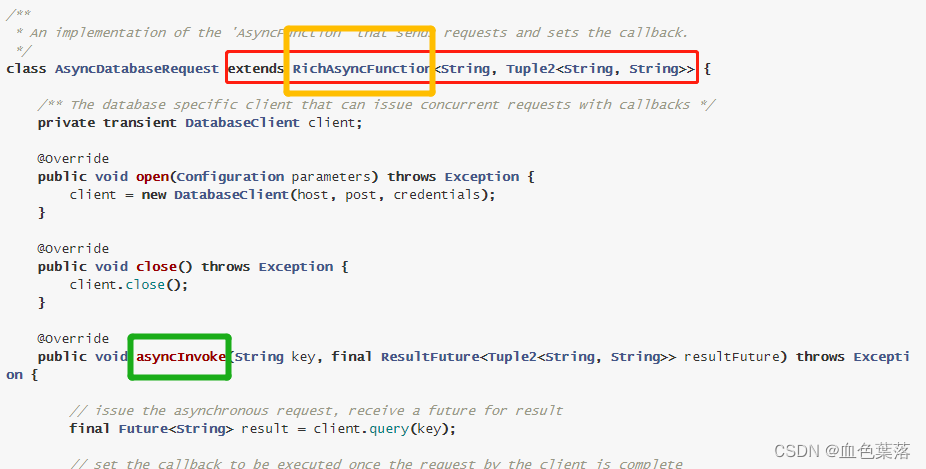
使用 Aysnc I/O 前提条件:

step1、使用AysncDataStream对数据流DataStream进行异步处理

step2、自定义类,转换异步处理数据,其中需要异步请求外部存储系统,处理结果
// 3-1. 将数据进行转换,封装到二元组中: userId -> log
SingleOutputStreamOperator<Tuple2<String, String>> logStream = dataStream.map(new MapFunction<String, Tuple2<String, String>>() {
@Override
public Tuple2<String, String> map(String value) throws Exception {
// 获取userId,便于后期直接使用,到数据库中查询用户名称
String userId = value.split(",")[0] ;
// 构建二元组对象,并返回
return Tuple2.of(userId, value);
}
});
// 3-2. TODO: 异步请求MySQL数据库,采用JDBC方式查询数据,不支持异步请求,所以使用线程池方式请求
SingleOutputStreamOperator<String> resultStream = AsyncDataStream.unorderedWait(
logStream, // 数据流
new AsyncMySQLRequest(), //
1000, //
TimeUnit.MILLISECONDS,//
10
);
/**
* 异步请求MySQL数据库,依据userId获取userName,采用线程池方式请求
*/
public class AsyncMySQLRequest extends RichAsyncFunction<Tuple2<String, String>, String> {
// 定义变量
private Connection conn = null ;
private PreparedStatement pstmt = null ;
private ResultSet result = null ;
// 定义线程池变量
private ExecutorService executorService = null ;
// 请求数据库前,准备工作,todo:获取数据库连接
@Override
public void open(Configuration parameters) throws Exception {
// 初始化线程池
executorService = Executors.newFixedThreadPool(10) ;
// a. 加载驱动类
Class.forName("com.mysql.jdbc.Driver") ;
// b. 获取连接
conn = DriverManager.getConnection(
"jdbc:mysql://node1:3306/?useSSL=false",
"root",
"123456"
);
// c. 构建Statement对象
pstmt = conn.prepareStatement("SELECT user_name FROM db_flink.tbl_user_info WHERE user_id = ?") ;
}
// todo:对流中每条数据调用,进行异步请求,获取数据,并返回
@Override
public void asyncInvoke(Tuple2<String, String> input, ResultFuture<String> resultFuture) throws Exception {
/*
input -> (u_1000, u_1000,browser,2022-04-03 10:16:35.606)
|
zhenshi,u_1000,browser,2022-04-03 10:16:35.606
*/
String userId = input.f0 ;
// todo: 通过线程池请求MySQL数据库,达到异步请求效果
Future<String> future = executorService.submit(
new Callable<String>() {
@Override
public String call() throws Exception {
// 直接请求数据库,获取userName
String userName = "未知" ;
// d. 设置查询占位符值
pstmt.setString(1, userId);
// e. 请求数据库,查询数据
result = pstmt.executeQuery();
// f. 获取查询结果
while (result.next()){
userName = result.getString("user_name");
}
// 返回查询结果
return userName;
}
}
);
// 获取异步请求结果
String userName = future.get();
String output = userName + "," + input.f1 ;
// 将查询数据库结果异步返回
resultFuture.complete(Collections.singletonList(output));
}
// todo:异步请求超时,如何处理数据
@Override
public void timeout(Tuple2<String, String> input, ResultFuture<String> resultFuture) throws Exception {
// 获取日志数据
String log = input.f1;
// 输出数据
String output = "unknown," + log ;
// 最后返回
resultFuture.complete(Collections.singletonList(output));
}
// 请求数据收尾工作,todo:关闭数据库连接
@Override
public void close() throws Exception {
if(null != result) result.close();
if(null != pstmt) pstmt.close();
if(null != conn) conn.close();
}
}
6、双流join
在Flink中,流Join主要有两种,一种是Window Join,还有一种是Interval Join。

第一类:Window Join,基于窗口JOIN
- 利用window的机制,先将数据缓存在Window State中,当窗口触发计算时,执行join操作;
- 根据Window的类型细分出3种:
Tumbling WindowJoin、Sliding WindowJoin、Session WidnowJoin;
第二类:Interval Join,基于间隔JOIN
- 对两条流中拥有相同键值Key及彼此之间时间戳不超过某一指定间隔的事件进行 Join。
- 利用state存储数据再处理,区别在于state中的数据有失效机制,依靠数据触发数据清理;
- IntervalJoin 连接两个keyedStream, 按照相同的key在一个相对数据时间的时间段内进行连接。
window join
Window Join将流中两个key相同的元素联结在一起。这种联结方式看起来非常像inner join,两个元素必须都存在,才会出现在结果中。
两个流DataStream进行关联JOIN时步骤:
- 第一步、join 方法关联
- 第二步、where…equalTo…指定条件
- 第三步、window 方法设置窗口
- 第四步、apply 方法窗口数据聚合
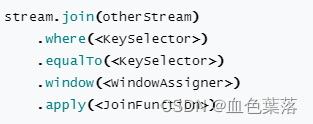
Thumbling Window Join:执行滚动窗口JOIN时,具有公共键和公共滚动窗口的所有元素将作为成对组合联接,并传递给JoinFunction或FlatJoinFunction。因为它的行为类似于内部连接,所以一个流中的元素在其滚动窗口中没有来自另一个流的元素,因此不会被发射!
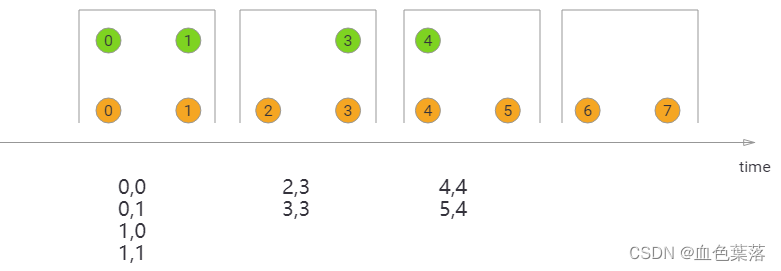
Sliding Window Join:在执行滑动窗口联接时,具有公共键和公共滑动窗口的所有元素将作为成对组合联接,并传递给JoinFunction或FlatJoinFunction。 在当前滑动窗口中,一个流的元素没有来自另一个流的元素,则不会发射!请注意,某些元素可能会连接到一个滑动窗口中,但不会连接到另一个滑动窗口中!
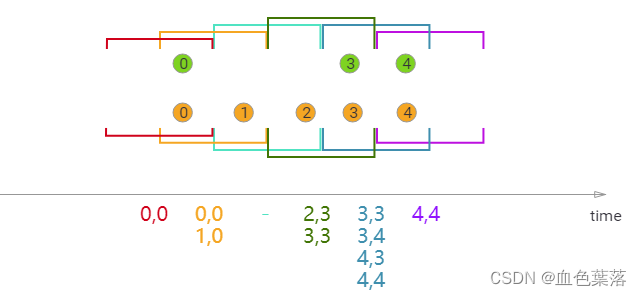
Session Window Join:**在执行会话窗口联接时,具有相同键(当“组合”时满足会话条件)的所有元素以成对组合方式联接,并传递给JoinFunction或FlatJoinFunction。**同样,这执行一个内部连接,所以如果有一个会话窗口只包含来自一个流的元素,则不会发出任何输出!
// 3-1. 对【订单数据流】中订单数据处理
SingleOutputStreamOperator<MainOrder> orderStream = rawOrderStream
.filter(line -> line.trim().split(",").length == 5)
// 设置事件时间字段
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<String>forBoundedOutOfOrderness(Duration.ofSeconds(2)) // 乱序数据,等待2秒
.withTimestampAssigner(new SerializableTimestampAssigner<String>() {
private FastDateFormat format = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss");
@SneakyThrows
@Override
public long extractTimestamp(String element, long recordTimestamp) {
System.out.println("order -> " + element);
String orderTime = element.split(",")[0];
Date orderDate = format.parse(orderTime);
return orderDate.getTime();
}
})
)
// 数据解析封装到实体类中
.map(new MapFunction<String, MainOrder>() {
@Override
public MainOrder map(String value) throws Exception {
// 2022-04-05 06:00:12,order_103,user_3,shanghai-changtai,45.00
String[] array = value.split(",");
MainOrder mainOrder = new MainOrder();
mainOrder.setOrderTime(array[0]);
mainOrder.setOrderId(array[1]);
mainOrder.setUserId(array[2]);
mainOrder.setAddress(array[3]);
mainOrder.setOrderMoney(Double.parseDouble(array[4]));
// 返回实体类对象
return mainOrder;
}
});
// 3-2. 对【详细订单数据流】中详情数据处理
SingleOutputStreamOperator<DetailOrder> detailStream = rawDetailStream
.filter(line -> line.trim().split(",").length == 6)
// 设置事件时间字段
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<String>forBoundedOutOfOrderness(Duration.ofSeconds(2)) // 乱序数据,等待2秒
.withTimestampAssigner(new SerializableTimestampAssigner<String>() {
private FastDateFormat format = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss");
@SneakyThrows
@Override
public long extractTimestamp(String element, long recordTimestamp) {
System.out.println("detail -> " + element);
String orderTime = element.split(",")[0];
Date orderDate = format.parse(orderTime);
return orderDate.getTime();
}
})
)
// 数据解析封装到实体类中
.map(new MapFunction<String, DetailOrder>() {
@Override
public DetailOrder map(String value) throws Exception {
// 2022-04-05 06:00:12,order_103,detail_1,milk,1,45.00
String[] array = value.split(",");
DetailOrder detailOrder = new DetailOrder() ;
detailOrder.setDetailTime(array[0]);
detailOrder.setOrderId(array[1]);
detailOrder.setDetailId(array[2]);
detailOrder.setGoodsName(array[3]);
detailOrder.setGoodsNumber(Integer.parseInt(array[4]));
detailOrder.setDetailMoney(Double.parseDouble(array[5]));
// 返回实体类对象
return detailOrder;
}
});
// todo: 3-3. 对2个流进行窗口join,基于事件时间滚动窗口
DataStream<DwdOrder> joinStream = orderStream
// 第1步、join数据流
.join(detailStream)
// 第2步、指定条件:关联key
.where(MainOrder::getOrderId).equalTo(DetailOrder::getOrderId)
// 第3步、窗口设置
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
// 第4步、窗口中数据JOIN处理
.apply(new JoinFunction<MainOrder, DetailOrder, DwdOrder>() {
@Override
public DwdOrder join(MainOrder order, DetailOrder detail) throws Exception {
/*
2022-04-05 06:00:12,order_103,user_3,shanghai-changtai,45.00
-----------------------------------------------------
2022-04-05 06:00:12,order_103,detail_1,milk,1,45.00
*/
DwdOrder dwdOrder = new DwdOrder();
dwdOrder.setOrderId(order.getOrderId());
dwdOrder.setOrderTime(order.getOrderTime());
dwdOrder.setUserId(order.getUserId());
dwdOrder.setAddress(order.getAddress());
dwdOrder.setOrderMoney(order.getOrderMoney());
dwdOrder.setDetailOrderTime(detail.getDetailTime());
dwdOrder.setDetailId(detail.getDetailId());
dwdOrder.setGoodsName(detail.getGoodsName());
dwdOrder.setGoodsNumber(detail.getGoodsNumber());
dwdOrder.setDetailMoney(detail.getDetailMoney());
// 返回关联数据
return dwdOrder;
}
});
Flink中基于DataStream的Join,只能实现在同一个窗口的两个数据流进行join,但是在实际中常常会存在数据乱序或者延时的情况,导致两个流的数据进度不一致,就会出现数据跨窗口的情况,那么数据就无法在同一个窗口内join。
Flink基于KeyedStream提供的interval join机制,interval join 连接两个keyedStream, 按照相同的key在一个相对数据时间的时间段内进行连接。
基于时间间隔的 Join 目前只支持事件时间以及 INNER JOIN 语义
- b.timestamp ∈ [a.timestamp + lowerBound; a.timestamp + upperBound]
or
- a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
// 3-1. 对【订单数据流】中订单数据处理
SingleOutputStreamOperator<MainOrder> orderStream = rawOrderStream
.filter(line -> line.trim().split(",").length == 5)
// 设置事件时间字段
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<String>forBoundedOutOfOrderness(Duration.ofSeconds(2)) // 乱序数据,等待2秒
.withTimestampAssigner(new SerializableTimestampAssigner<String>() {
private FastDateFormat format = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss");
@SneakyThrows
@Override
public long extractTimestamp(String element, long recordTimestamp) {
System.out.println("order -> " + element);
String orderTime = element.split(",")[0];
Date orderDate = format.parse(orderTime);
return orderDate.getTime();
}
})
)
// 数据解析封装到实体类中
.map(new MapFunction<String, MainOrder>() {
@Override
public MainOrder map(String value) throws Exception {
// 2022-04-05 06:00:12,order_103,user_3,shanghai-changtai,45.00
String[] array = value.split(",");
MainOrder mainOrder = new MainOrder();
mainOrder.setOrderTime(array[0]);
mainOrder.setOrderId(array[1]);
mainOrder.setUserId(array[2]);
mainOrder.setAddress(array[3]);
mainOrder.setOrderMoney(Double.parseDouble(array[4]));
// 返回实体类对象
return mainOrder;
}
});
// 3-2. 对【详细订单数据流】中详情数据处理
SingleOutputStreamOperator<DetailOrder> detailStream = rawDetailStream
.filter(line -> line.trim().split(",").length == 6)
// 设置事件时间字段
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<String>forBoundedOutOfOrderness(Duration.ofSeconds(2)) // 乱序数据,等待2秒
.withTimestampAssigner(new SerializableTimestampAssigner<String>() {
private FastDateFormat format = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss");
@SneakyThrows
@Override
public long extractTimestamp(String element, long recordTimestamp) {
System.out.println("detail -> " + element);
String orderTime = element.split(",")[0];
Date orderDate = format.parse(orderTime);
return orderDate.getTime();
}
})
)
// 数据解析封装到实体类中
.map(new MapFunction<String, DetailOrder>() {
@Override
public DetailOrder map(String value) throws Exception {
// 2022-04-05 06:00:12,order_103,detail_1,milk,1,45.00
String[] array = value.split(",");
DetailOrder detailOrder = new DetailOrder() ;
detailOrder.setDetailTime(array[0]);
detailOrder.setOrderId(array[1]);
detailOrder.setDetailId(array[2]);
detailOrder.setGoodsName(array[3]);
detailOrder.setGoodsNumber(Integer.parseInt(array[4]));
detailOrder.setDetailMoney(Double.parseDouble(array[5]));
// 返回实体类对象
return detailOrder;
}
});
// todo: 3-3. 对2个流进行间隔join,基于事件时间滚动窗口
SingleOutputStreamOperator<DwdOrder> joinStream = orderStream
.keyBy(MainOrder::getOrderId) // 订单流按照Key:orderId分组
// 第1步、JOIN 数据流
.intervalJoin(
detailStream.keyBy(DetailOrder::getOrderId) // 详情流按照Key:orderId分组
)
// 第2步、指定条件,上限和下限
.between(Time.seconds(-1), Time.seconds(2))
// 第3步、关联join计算
.process(new ProcessJoinFunction<MainOrder, DetailOrder, DwdOrder>() {
@Override
public void processElement(MainOrder order, DetailOrder detail,
Context ctx, Collector<DwdOrder> out) throws Exception {
DwdOrder dwdOrder = new DwdOrder();
dwdOrder.setOrderId(order.getOrderId());
dwdOrder.setOrderTime(order.getOrderTime());
dwdOrder.setUserId(order.getUserId());
dwdOrder.setAddress(order.getAddress());
dwdOrder.setOrderMoney(order.getOrderMoney());
dwdOrder.setDetailOrderTime(detail.getDetailTime());
dwdOrder.setDetailId(detail.getDetailId());
dwdOrder.setGoodsName(detail.getGoodsName());
dwdOrder.setGoodsNumber(detail.getGoodsNumber());
dwdOrder.setDetailMoney(detail.getDetailMoney());
// 输出关联后数据
out.collect(dwdOrder);
}
});
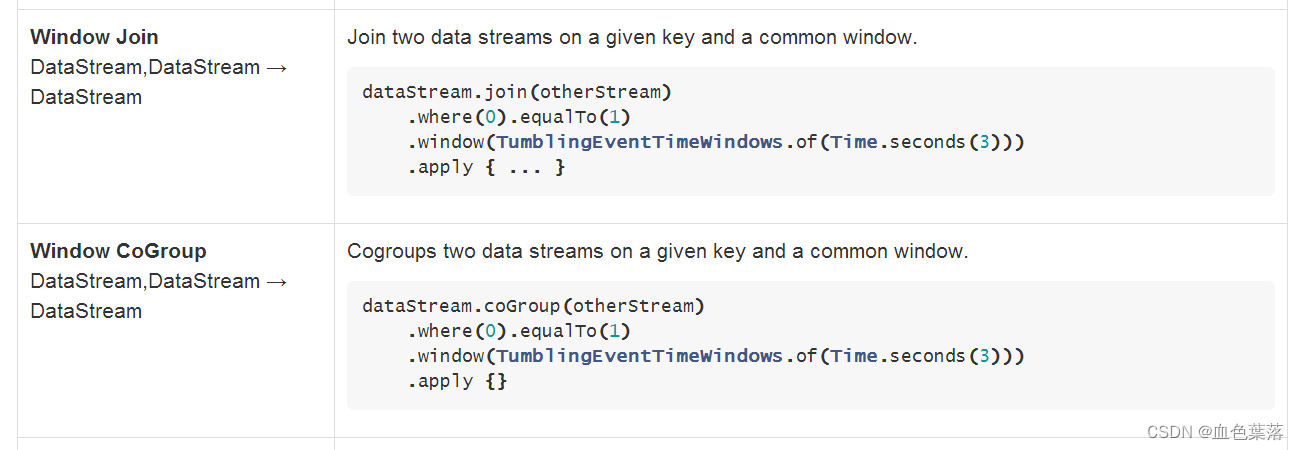
CoGroup操作是将两个数据流/集合按照key进行group,然后将相同key的数据进行处理,但是它和join操作稍有区别,它在一个流/数据集中没有找到与另一个匹配的数据还是会输出。
- 侧重于group,对同一个key上的两组集合进行操作;
- 如果在一个流中没有找到与另一个流的window中匹配的数据,任何输出结果,即只输出一个流的数据;
- 仅能使用在window中;
// 3-1. 对【订单数据流】中订单数据处理
SingleOutputStreamOperator<MainOrder> orderStream = rawOrderStream
.filter(line -> line.trim().split(",").length == 5)
// 设置事件时间字段
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<String>forBoundedOutOfOrderness(Duration.ofSeconds(2)) // 乱序数据,等待2秒
.withTimestampAssigner(new SerializableTimestampAssigner<String>() {
private FastDateFormat format = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss");
@SneakyThrows
@Override
public long extractTimestamp(String element, long recordTimestamp) {
System.out.println("order -> " + element);
String orderTime = element.split(",")[0];
Date orderDate = format.parse(orderTime);
return orderDate.getTime();
}
})
)
// 数据解析封装到实体类中
.map(new MapFunction<String, MainOrder>() {
@Override
public MainOrder map(String value) throws Exception {
// 2022-04-05 06:00:12,order_103,user_3,shanghai-changtai,45.00
String[] array = value.split(",");
MainOrder mainOrder = new MainOrder();
mainOrder.setOrderTime(array[0]);
mainOrder.setOrderId(array[1]);
mainOrder.setUserId(array[2]);
mainOrder.setAddress(array[3]);
mainOrder.setOrderMoney(Double.parseDouble(array[4]));
// 返回实体类对象
return mainOrder;
}
});
// 3-2. 对【详细订单数据流】中详情数据处理
SingleOutputStreamOperator<DetailOrder> detailStream = rawDetailStream
.filter(line -> line.trim().split(",").length == 6)
// 设置事件时间字段
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<String>forBoundedOutOfOrderness(Duration.ofSeconds(2)) // 乱序数据,等待2秒
.withTimestampAssigner(new SerializableTimestampAssigner<String>() {
private FastDateFormat format = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss");
@SneakyThrows
@Override
public long extractTimestamp(String element, long recordTimestamp) {
System.out.println("detail -> " + element);
String orderTime = element.split(",")[0];
Date orderDate = format.parse(orderTime);
return orderDate.getTime();
}
})
)
// 数据解析封装到实体类中
.map(new MapFunction<String, DetailOrder>() {
@Override
public DetailOrder map(String value) throws Exception {
// 2022-04-05 06:00:12,order_103,detail_1,milk,1,45.00
String[] array = value.split(",");
DetailOrder detailOrder = new DetailOrder() ;
detailOrder.setDetailTime(array[0]);
detailOrder.setOrderId(array[1]);
detailOrder.setDetailId(array[2]);
detailOrder.setGoodsName(array[3]);
detailOrder.setGoodsNumber(Integer.parseInt(array[4]));
detailOrder.setDetailMoney(Double.parseDouble(array[5]));
// 返回实体类对象
return detailOrder;
}
});
// todo: 3-3. 对2个流进行窗口cogroup,基于事件时间滚动窗口
DataStream<DwdOrder> joinStream = orderStream
// 第1步、jion数据流
.coGroup(detailStream)
// 第2步、指定条件
.where(MainOrder::getOrderId).equalTo(DetailOrder::getOrderId)
// 第3步、窗口设置
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
// 第4步、窗口数据JOIN处理
.apply(new CoGroupFunction<MainOrder, DetailOrder, DwdOrder>() {
@Override
public void coGroup(Iterable<MainOrder> first, Iterable<DetailOrder> second, Collector<DwdOrder> out) throws Exception {
// 以左表为准遍历数据
for (MainOrder order : first) {
DwdOrder dwdOrder = new DwdOrder() ;
dwdOrder.setOrderId(order.getOrderId());
dwdOrder.setOrderTime(order.getOrderTime());
dwdOrder.setUserId(order.getUserId());
dwdOrder.setAddress(order.getAddress());
dwdOrder.setOrderMoney(order.getOrderMoney());
//定义变量,表示是否与右表关联
boolean isJoin = false ;
// todo: 直接遍历右表数据,当且仅当右表有数据时,才执行遍历
for (DetailOrder detail : second) {
isJoin = true;
// 关联以后,设置属性值
dwdOrder.setDetailOrderTime(detail.getDetailTime());
dwdOrder.setDetailId(detail.getDetailId());
dwdOrder.setGoodsName(detail.getGoodsName());
dwdOrder.setGoodsNumber(detail.getGoodsNumber());
dwdOrder.setDetailMoney(detail.getDetailMoney());
// 输出关联数据
out.collect(dwdOrder);
}
// 如果右表没有数据,此时单独输出左表数据即可,todo:类似左外连接
if(!isJoin){
out.collect(dwdOrder);
}
}
}
});
join和coGroup都是基于事件时间EventTime关联2个流数据
7、flink 调度
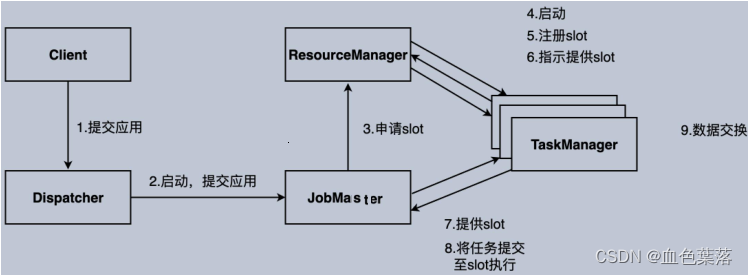
Flink Runtime 层的整个架构采用了标准 Master-Slave 的结构:由一个Flink JobManager和一个或多个Flink TaskManager组成。
Flink JobManager是Master,负责管理整个集群中的资源并处理作业提交、作业监督;Flink TaskManager是 Slave,工作(worker)进程,负责提供具体的资源并实际执行作业。
Flink JobManager是Flink集群的主进程,包含三个不同的组件:Resource Manager、Dispatcher以及每个运行Job的JobMaster。

- Dispatcher,负责接收用户提供的作业,并且负责为这个新提交的作业拉起一个新的JobMaster 组件。
- ResourceManager,负责资源的管理,在整个 Flink 集群中只有一个 ResourceManager。
- JobMaster,负责管理作业的执行,在一个 Flink 集群中可能有多个作业同时执行,每个作业都有自己的 JobMaster组件。
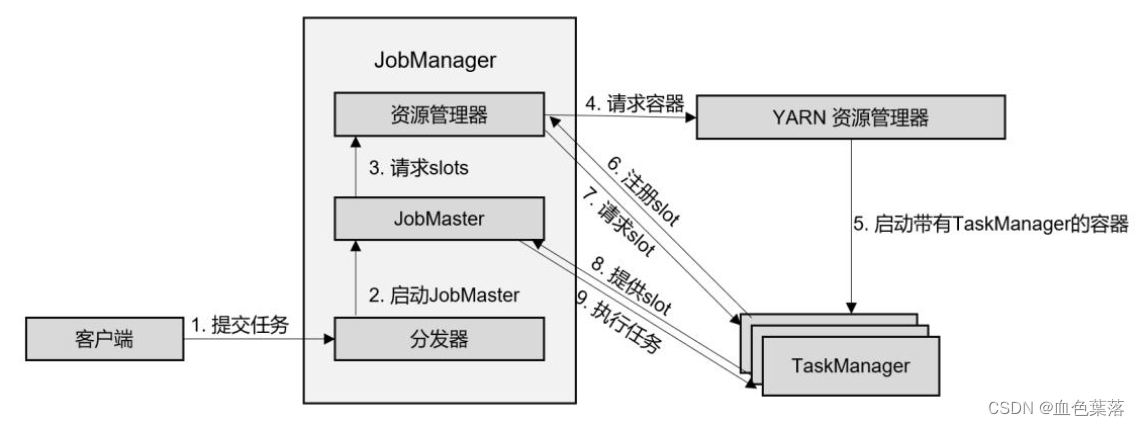
Flink on YARN部署:Session 会话模式:
1)、客户端通过 REST 接口,将作业提交给分发器。
2)、分发器启动 JobMaster,并将作业(包含 JobGraph)提交给 JobMaster。
3)、JobMaster 向资源管理器请求资源(slots)。
4)、资源管理器向 YARN 的资源管理器请求 container 资源。
5)、YARN 启动新的 TaskManager 容器。
6)、TaskManager 启动之后,向 Flink 的资源管理器注册自己的可用任务槽。
7)、资源管理器通知 TaskManager 为新的作业提供 slots。
8)、TaskManager 连接到对应的 JobMaster,提供 slots。
9)、JobMaster 将需要执行的任务分发给 TaskManager,执行任务。
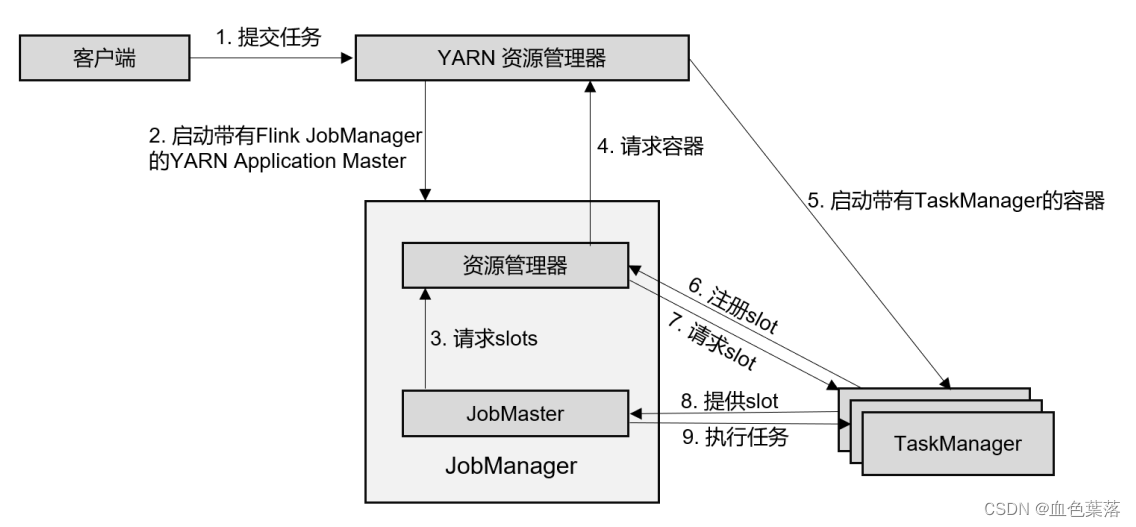
Flink on YARN部署:Per-Job 单作业模式:
在单作业模式下, Flink 集群不会预先启动,而是在提交作业时,才启动新的 JobManager。
并行度与算子链:
Flink 程序本质上是并行的和分布式的,在执行过程中,一个流(stream)包含一个或多个流分区,而每一个 operator 包含一个或多个 operator 子任务。
- 操作子任务间彼此独立,在不同的线程中执行,甚至是在不同的机器或不同的容器上。
- operator 子任务的数量是这一特定 operator 的并行度,相同程序中的不同 operator 有不同级别的并行度。
- 一个 Stream 可以被分成多个 Stream 的分区,也就是 Stream Partition。一个 Operator 也可以被分为多个 Operator Subtask。
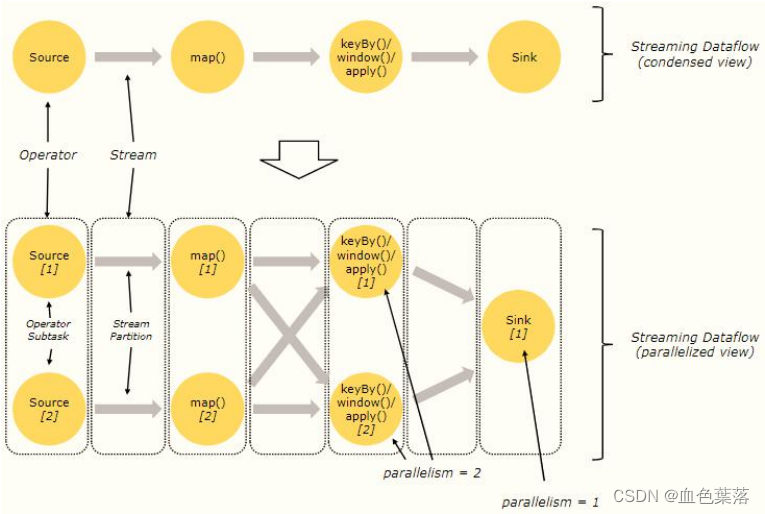
数据在两个 operator 之间传递的时候有两种模式:
-
One to One 模式:两个 operator 用此模式传递的时候,会保持数据的分区数和数据的排序;如下图中的 Source1 到 Map1,它就保留的 Source 的分区特性,以及分区元素处理的有序性。
-
Redistributing (重新分配)模式:这种模式会改变数据的分区数;每个一个 operator subtask 会根据选择 transformation 把数据发送到不同的目标 subtasks,比如 keyBy()会通过 hashcode 重新分区,broadcast()和 rebalance()方法会随机重新分区;
Flink的所有操作都称之为Operator,客户端在提交任务的时候会对Operator进行优化操作,能进行合并的Operator会被合并为一个Operator,合并后的Operator称为Operator chain,实际上就是一个执行链,每个执行链会在TaskManager上一个独立的线程中执行。
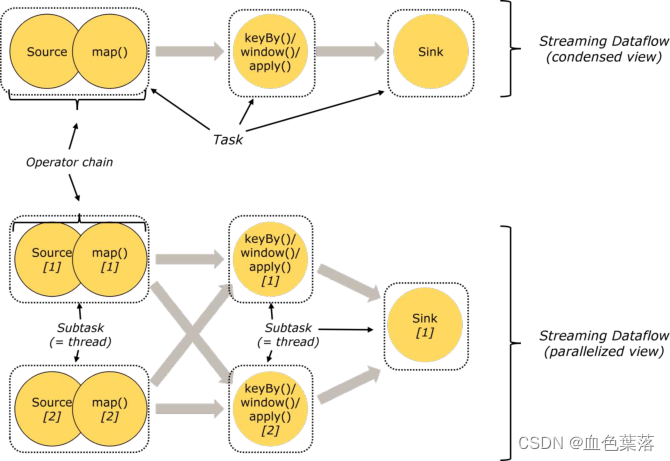
Operator合并,形成Operator Chain:
- 条件1:相邻2个Operator并行度(parallelism)相同;
- 条件2:相邻2个Operator之间数据传递方式为One-to-One 模式;
Operator Chain,两个好处:
- 减少线程到线程的切换和缓冲的开销(reduces the overhead of thread-to-thread handover
and buffering); - 增加总体吞吐量,同时减少延迟( increases overall throughput while decreasing latency);
资源任务槽Slot
每个TaskManager是一个JVM Process,将在不同线程Treads中执行一个或多个SubTask任务。每个SubTask任务运行地方称为:Task Slots(任务槽,资源槽等)。
Slot是TaskManager资源粒度的划分,每个Slot都有自己独立的内存。所有Slot平均分配TaskManger的内存。
Slot是Flink中的任务执行器,每个Slot可以运行多个subtask,而且一个subtask会以单独的线程来运行。
Slot可以被多个SubTask共享使用,需要满足以下条件:
- SubTask必须是不同SubTask(Operator),也就是说一个Slot中的SubTask属于不同Operator操作;
- SubTask属于一个Job中任务,必须是一个Job中不同SubTask。

Slot 共享主要的好处有以下几点:
- 可以起到隔离内存的作用,防止多个不同job的task竞争内存;
- Slot个数就代表了一个Flink程序的最高并行度,简化了性能调优的过程;
- 允许多个Task共享Slot,提升了资源利用率。举一个实际的例子,kafka有3个partition,对应flink的source有3个subtask,而keyBy设置的并行度为20,这个时候如果Slot不能共享的话,需要占用23个Slot,如果允许共享的话,只需要20个Slot即可(Slot默认共享规则计算为20个);
在Flink job中,判断Job需要多少Slot资源槽运行SubTask任务,取决于:Job中最大Operator并行度。
作业图与执行图
由Flink程序直接映射成的数据流图是StreamGraph,也被称为逻辑流图,因为它们表示的是计算逻辑的高级视图。为了执行一个流处理程序,Flink需要将逻辑流图转换为物理数据流图(也叫执行图)。

- StreamGraph:最初的程序执行逻辑流程,也就是算子之间的前后顺序(全部都是Subtask)
- JobGraph:将部分可以合并的Subtask合并成一个Task
- ExecutionGraph:为Task赋予并行度,此时确定Job中SubTask数目
- 物理执行图:将Task赋予并行度后的执行流程,落实到具体的TaskManager上,将具体的Task落实到具体的Slot内进行运行。此处考虑槽Slot共享,确定运行SubTask需要资源Slot
总结
FLINK底层过程方法函数实现,广播状态流,窗口聚合,Aysnc IO,窗口join,flink任务调度。
时光如水,人生逆旅矣。














 263
263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









