






问题背景:
在处理分类问题时,会遇到一种情况:
假设一个二元分类问题:假设我们的预测算法是:,这个算法忽略特征值,不管任何情况下都是预测等于0。
毫无疑问这是一个糟糕的算法,但是在测试集中,99%的样本输出,1%的样本输出,这样计算预测算法的误差率的时候,会的到1%的误差率,这就是很糟糕的情况,一个完全错误的算法得到了一个正确率很高的测试结果。
实例:100个样本,10个是癌症,如果模型预测100个样本全为正常,那么准确率accuracy会有90%,但是显然这种不合理,因此衍生了recall precison
这种情况称之为偏斜类(Skewed Classes)的问题。
解决偏斜类问题的方法:


预测某些病人有没有得癌症。
假设有100个样本,真实情况是有10个得癌症的,通过预测函数遇到到了有12个得了癌症,其中有8个是真实得癌症的。
这种情况下:
TP=8
FP=12-8=4
FN=10-8=2
TN=(100-12)-2=86
准确率 Accuracy:检测对的数量 / 所有样本量F1score(Hmean):recall和precision的调和平均数
正确预测为1,正确预测为0的样本比率,公式为:(TP+TN) / ALL
上例中准确率为: (8+86/)100=0.94
查准率 Precision:检测得到的正样本 / 检测的总数
查准率是指在所有预测为1的样本中预测正确的比率,公式为:TP/(TP+FP)
上例中查准率为:8/(8+4)=0.67
查全率(召回率 )Recall:检测结果中正样本 / 实际有的正样本
召回率是指在所有真正为1的样本中预测正确的比率,公式为:TP/(TP+FN)
上例中召回率为:8/10
在最开始偏斜类问题中 TP=0,召回率为0,因此那个预测算法是错误的。
F1score(Hmean):recall和precision的调和平均数
在分类问题中, 大于概率阈值(threshold)是我们就预测为1, 小于概率阈值是我们就预测为0;
一般情况设置threshold=0.5
当提高threshold(0.99)时,precision会提高,recall会下降;
当减小threshold(0.01)时,recall会提高,precision会下降。
所以F1score就是为了综合recall和precision的办法,综合衡量算法的

ROC和AUC
思想是相当简单的:ROC 曲线展示了当改变在模型中识别为正例的阈值threshold时,召回率和精度的关系会如何变化。
计算公式如下: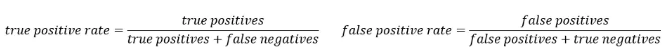
TPR = TP / (TP + FN) TPR 是召回率FPR = FP / (FP + TN) FPR 是反例被报告为正例的概率
下图是一个典型的 ROC 曲线:
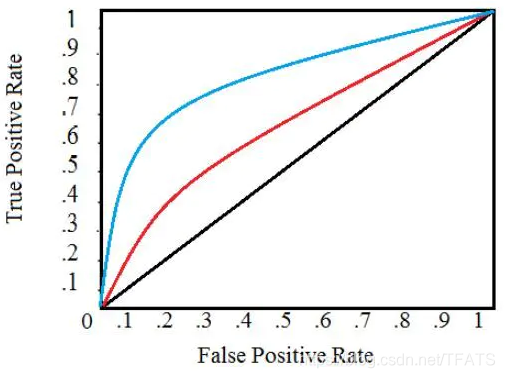
黑色对角线表示随机分类器,红色和蓝色曲线表示两种不同的分类模型。对于给定的模型,只能对应一条曲线。但是我们可以通过调整对正例进行分类的阈值来沿着曲线移动。通常,当降低阈值时,会沿着曲线向右和向上移动。
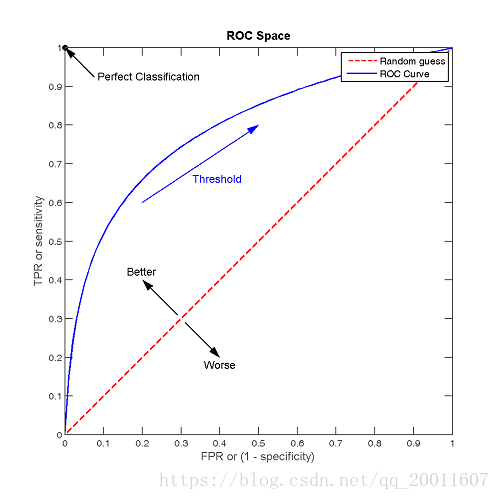
在阈值为 1.0 的情况下,我们将位于图的左下方,因为没有将任何数据点识别为正例,这导致没有真正例,也没有假正例(TPR = FPR = 0)。当降低阈值时,我们将更多的数据点识别为正例,导致更多的真正例,但也有更多的假正例 ( TPR 和 FPR 增加)。最终,在阈值 0.0 处,我们将所有数据点识别为正,并发现位于 ROC 曲线的右上角 ( TPR = FPR = 1.0 )。
最后,我们可以通过计算曲线下面积 ( AUC ) 来量化模型的 ROC 曲线,这是一个介于 0 和 1 之间的度量,数值越大,表示分类性能越好。在上图中,蓝色曲线的 AUC 将大于红色曲线的 AUC,这意味着蓝色模型在实现准确度和召回率的权衡方面更好。随机分类器 (黑线) 实现 0.5 的 AUC。
目录
准确率 Accuracy:检测对的数量 / 所有样本量F1score(Hmean):recall和precision的调和平均数
查准率 Precision:检测得到的正样本 / 检测的总数
查全率(召回率 )Recall:检测结果中正样本 / 实际有的正样本















 2186
2186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









