






Hadoop支持本地模式、伪分布式模式、完全分布式模式3种安装模式。本地模式,在系统中下载Hadoop,默认情况下,它会被配置为一个独立的模式, 用于运行Java程序;伪分布式模式,这是在单台机器上的分布式模拟,这种模式对开发非常有用:完全分布式模式,又叫集群安装,Hadoop 安装在最少两台计算机的集群中。
安装VMware并安装CentOS:
CentOS下载 https://www.centos.org/download/系统安装完成后需要进行如下配置
https://www.centos.org/download/系统安装完成后需要进行如下配置
一、配置CentOS
1. 设置IP
选择设置
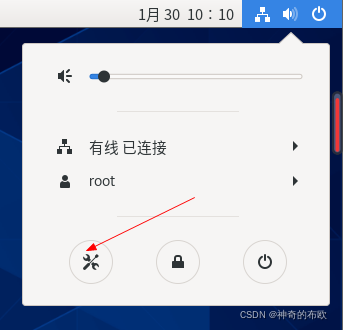
选择网络、选择设置

记住IPv4地址
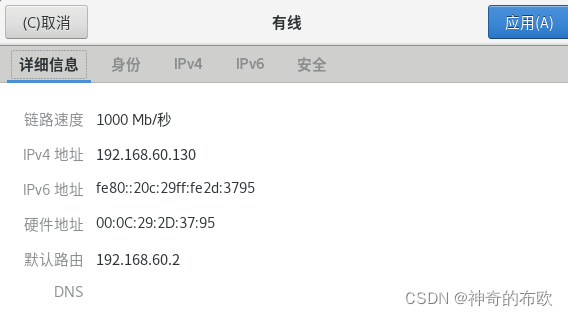
IPv4中如下设置

2. 修改主机名
hostnamectl set-hostname hadoop0
3. 使用vim编辑/etc/hosts
vim /etc/hosts
在最后一行添加IP hadoop0
如图:

4. 关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
5. 禁用selinux
使用vim编辑/etc/selinux/config
vim /etc/selinux/config
将SELINUX=enforcing改为SELINUX=disabled
6. 设置SSH免密登陆
cd /root/.ssh
rm -rf *
使用ssh-keygen -t dsa命令生成密码,之后使用回车确认配置。
ssh-keygen -t dsa
将生成的id_dsa.pub复制到指定的密钥目录authorized_keys中。
cat id_dsa.pub >>authorized_keys
如果出现没有.ssh目录
登录localhost并输入密码就会生成
ssh localhost
7. 重启CentOS
reboot
二、Hadoop伪分布式安装
1. 下载Hadoop3.0.0并解压
Hadoop3.0.0下载![]() http://archive.apache.org/dist/hadoop/core/hadoop-3.0.0/在CentOS中解压文件
http://archive.apache.org/dist/hadoop/core/hadoop-3.0.0/在CentOS中解压文件
tar -xvf hadoop-3.0.0.tar.gz
2. 配置它的环境变量
mv hadoop-3.0.0 hadoop
将Hadoop安装目录配置到/etc/profile的PATH环境变量
3. 使用source命令执行一次才能生效
source /etc/profile
4. 配置hadoop-env.sh
修改其中JAVA_HOME为本机的
5. 配置core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop0:9000/</value>
<description>NameNode URI</description>
</property>6. 配置hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop/data/datanode</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop0:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop0:50090</value>
</property>7. 配置yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop0:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop0:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop0:8050</value>
</property>完成以上操作即可配置完成。
Hadoop验证
启动之前需要格式化,启动后开查看进程信息,浏览文件,验证是否能正常运行。
格式化命令:
hadoop namenode -format如果没有报错则格式化成功
启动Hadoop
start-all.sh若果没有报错则正常启动了
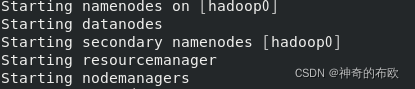
jps命令可查看进程信息

浏览文件
hadoop fs -ls /
浏览器中访问
http://本机IP:50070
结果如图:

个人学习,当做笔记记录。有误还望指出,仅供参考!















 3750
3750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











