









Python常用小技巧(五)——批量读取json文件
前言:其实Python能够批量读取很多文件,这里,本人以json文件为例(json是标注图片时生成的文件,记录有标注的坐标和标签,友情推荐标注图片的工具:labelme),读取想要的数据。大家也可以稍做修改,去读取其他类型的文件。
一、材料准备
- Python
- os
- json
二、代码编写
首先我们来观察一下我们需要处理的json文件

打开json文件,我们可以看到一下内容

我们需要获取的信息是 label 后面标注的种类,还有坐标信息
期望输出的格式是:
结构:
n.json x1,y1,x2,y2,lable1 x1,y1,x2,y2,label2
样例:
21.json 203,1,511,116,shoes 248,2,350,44,welt 所以,知道标准后,我们的代码如下:
# -*- coding:utf8 -*-
import json
from os import listdir
import os
path = '/home/ljt/Documents/labelme'
filelist = listdir(path)
#for i in filelist:
#print(filelist[0].split(".")[0])
# i.split()
fileIndex =[]
#文件名读入时并非按照我们常识中的按照文件名字顺序读入,
#例如:1.json,2.json,3.json;程序可能会按 3,1,2 的顺序读入,
#这对我们后面批量处理造成很大的不便,所以读入文件名后,
#我们要手动地对文件名进行一次排序
#以下就是排序操作
for i in range(0,len(filelist)):
index = filelist[i].split(".")[0]
fileIndex.append(int(index))
#new_filelist =[]
for j in range(1,len(fileIndex)):
for k in range(0,len(fileIndex)-1):
if fileIndex[k]>fileIndex[k+1]:
preIndex = fileIndex[k]
preFile = filelist[k]
fileIndex[k] = fileIndex[k+1]
filelist[k] = filelist[k+1]
fileIndex[k+1] =preIndex
filelist[k+1] = preFile
#完成排序后,开始按照文件名顺序读取文件内容信息
data = []#记录每个文件最终信息的列表
labelpath = '/home/ljt/Documents/labelme/'
for file in filelist:
with open(labelpath+file, 'r') as txt:
lines = txt.readlines()
eachdata = []#记录单个文件信息的列表
eachdata.append(file) # fileName
for each in range(0,len(lines)):
word = lines[each].split('"')
for i in range(0,len(word)):
if word[i] == 'shoes':
eachdata.append(int(int(lines[each + 5].split(',')[0]) * 416 / 512))
eachdata.append(int(int(lines[each + 6].split(',')[0]) * 416 / 512))
eachdata.append(int(int(lines[each + 9].split(',')[0]) * 416 / 512))
eachdata.append(int(int(lines[each + 10].split(',')[0]) * 416 / 512))#(xmin,ymin,xmax,ymax,'shoes')
eachdata.append('0')
elif word[i] == 'welt':
eachdata.append(int(int(lines[each + 5].split(',')[0]) * 416 / 512))
eachdata.append(int(int(lines[each + 6].split(',')[0]) * 416 / 512))
eachdata.append(int(int(lines[each + 9].split(',')[0]) * 416 / 512))
eachdata.append(int(int(lines[each + 10].split(',')[0]) * 416 / 512)) # (xmin,ymin,xmax,ymax,'shoes')
eachdata.append('1')
txt.close()
data.append(eachdata)
#记录完成后,开始将数据写入txt文件
with open('data.txt', 'w') as txt:
for eachdata in data:
line =eachdata[0]+' '
i=0
for i in range(1,len(eachdata)):
if i % 5 ==0 and i > 1 and i!=len(eachdata)-1:
s =str(eachdata[i])+' '
line = line + s
elif i==len(eachdata)-1:
line = line + str(eachdata[i])
else:
s=str(eachdata[i])+','
line = line+s
lines=line.replace('json','jpg')+'\n'
txt.writelines('resize/'+lines)
txt.close()
print('finish')
# line='json'
# while line:
# line = txt.readline()
# word = line.split()
# for i in range(0,len(word)):
# if word[i] == "shoes":
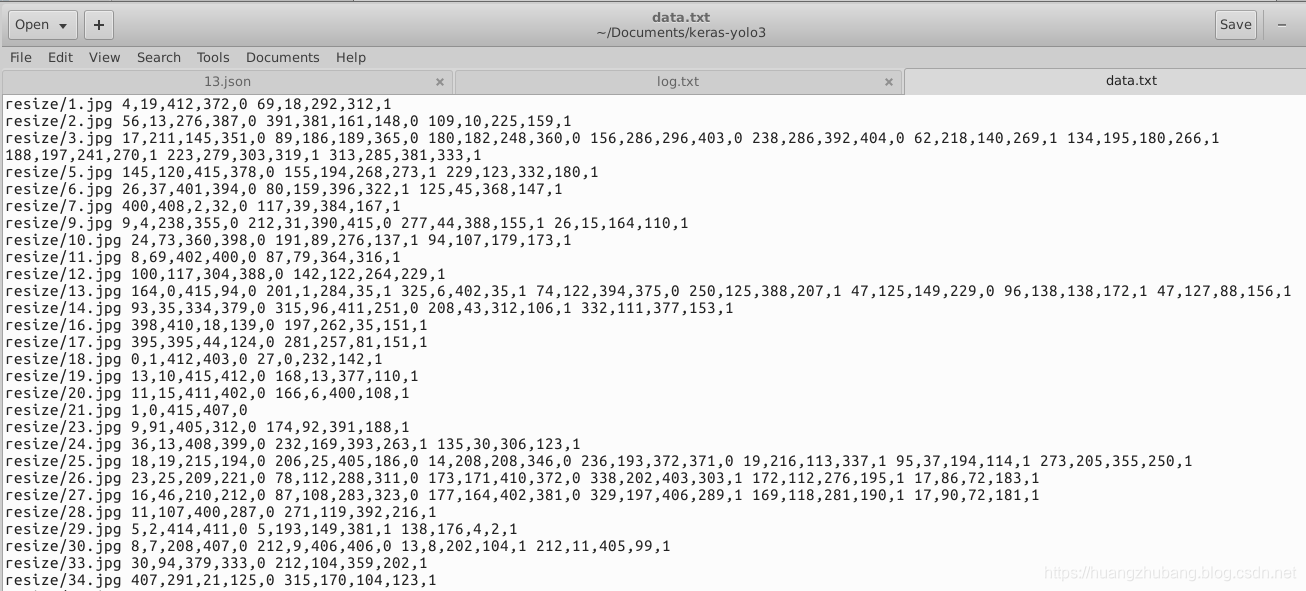
最终,我们能够得到一个这样的txt文件
其中 0代表的是shoes,1代表welt















 3813
3813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









