







windows 10环境下安装Tesseract-OCR与python集成
我的环境win10+python3.7 +opencv3.4
前言
Tesseract是一个开源的ocr引擎,可以开箱即用,项目最初由惠普实验室支持,1996年被移植到Windows上,1998年进行了C++化。在2005年Tesseract由惠普公司宣布开源。2006年到现在,都由Google公司开发。
官网宣传目前支持100多种语言的识别,根据我的测试,目前感觉其对机器打印的比较规整的英语,或者阿拉伯数字的识别准确率还是挺高的,但是对手写的任何东西,效果都非常一般,不过这已经相当不错了。
Tesseract的安装
(1)Tesseract本身没有windows的安装包,不过它指定了一个第三方的封装的windows安装包,在其wiki上有说明,大家可直接到这个地址进行下载: https://digi.bib.uni-mannheim.de/tesseract/
下载后就是一个exe安装包,直接右击安装即可,安装完成之后,配置一下环境变量,编辑 系统变量里面 path,添加下面的安装路径:
C:\Program Files (x86)\Tesseract-OCR
安装完成之后,直接cmd输入:
命令:
tesseract -v
输出如下,即代表成功:
tesseract 4.0.0-beta.1-108-gf291
leptonica-1.76.0
libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.2.0
注意,这一步在windows上是必须安装的,否则运行程序时,会抛出异常
(2)安装python的封装接口:
pip install pillow #一个python的图像处理库,pytesseract依赖
pip install pytesseract
pip install pillow安装不上时,试下这个:
pip install Pillow-PIL
注意第一步必须安装成功,同时配置好环境变量,否则第二步必会报错,因为第二步是接口,运行时候会调用第一步的原C++写的类库。
数字验证码识别(有线段干扰)
import cv2 as cv
import numpy as np
from PIL import Image
import pytesseract as tess
def recognize_text():
#首先灰值处理 然后二值化
gray = cv.cvtColor(src, cv.COLOR_BGR2GRAY)
ret, binary= cv.threshold(gray, 0, 255, cv.THRESH_BINARY_INV | cv.THRESH_OTSU)
#去除干扰线 获取结构元素,进行开操作处理
kernel = cv.getStructuringElement(cv.MORPH_RECT, (1, 3))
bin1 = cv.morphologyEx(binary, cv.MORPH_OPEN, kernel)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (3, 1))
openout = cv.morphologyEx(bin1, cv.MORPH_OPEN, kernel)
cv.imshow("binary-image", binary)
cv.imshow("openout-image", openout)
cv.bitwise_not(openout, openout)
textImage = Image.fromarray(openout)
text = tess.image_to_string(textImage)
print("识别结果:%s" % text)
src = cv.imread("C:/Users/lenovo/Desktop/opencv/daima/banknum/template-matching-ocr/images/yanzhengma2.png") #读取图片位置
cv.namedWindow("input image", cv.WINDOW_AUTOSIZE)
cv.imshow("input image", src)
recognize_text()
cv.waitKey(0)
cv.destroyAllWindows()
运行截图:
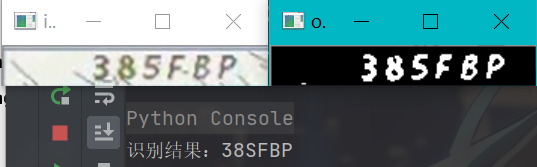
可能你第一次运行时会报错:
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your path
意思就是你tesseract 环境变量有问题
报错:pytesseract.TesseractNotFoundError: tesseract is not installed or it’s not in your path解决方案
数字验证码识别(无线段干扰,正常验证码)
import cv2 as cv
import numpy as np
from PIL import Image
import pytesseract as tess
def recognize_text():
#首先灰值处理 然后二值化
gray = cv.cvtColor(src, cv.COLOR_BGR2GRAY)
ret, openout = cv.threshold(gray, 0, 255, cv.THRESH_BINARY_INV | cv.THRESH_OTSU)
cv.imshow("openout-image", openout)
cv.bitwise_not(openout, openout)
textImage = Image.fromarray(openout)
text = tess.image_to_string(textImage)
print("识别结果:%s" % text)
src = cv.imread("C:/Users/lenovo/Desktop/opencv/daima/banknum/template-matching-ocr/images/yanzhengma3.png") #读取图片位置
cv.namedWindow("input image", cv.WINDOW_AUTOSIZE)
cv.imshow("input image", src)
recognize_text()
cv.waitKey(0)
cv.destroyAllWindows()
运行截图:
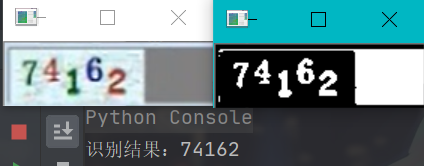
对于机器打印的比较规则的字符,Tesseract识别起来还是比较给力的,至于手写的字符,识别效果比较差,可以看到上面的手写数字识别出来的都是错误的,当然这里也有调优的余地,比如给图片做灰度,模糊,去燥,二值化等等,可能结果会稍微好一点。














 1643
1643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









