







PMML(Predictive Model Markup Language,预测模型标记语⾔)⽂件,它⽤XML格式来描述⽣成的机器学习 模型,可以将在Python中训练好的模型部署到⽣产上,⽤⽬标环境解析PMML⽂件的库来加载模型,并做预测。
一、环境准备
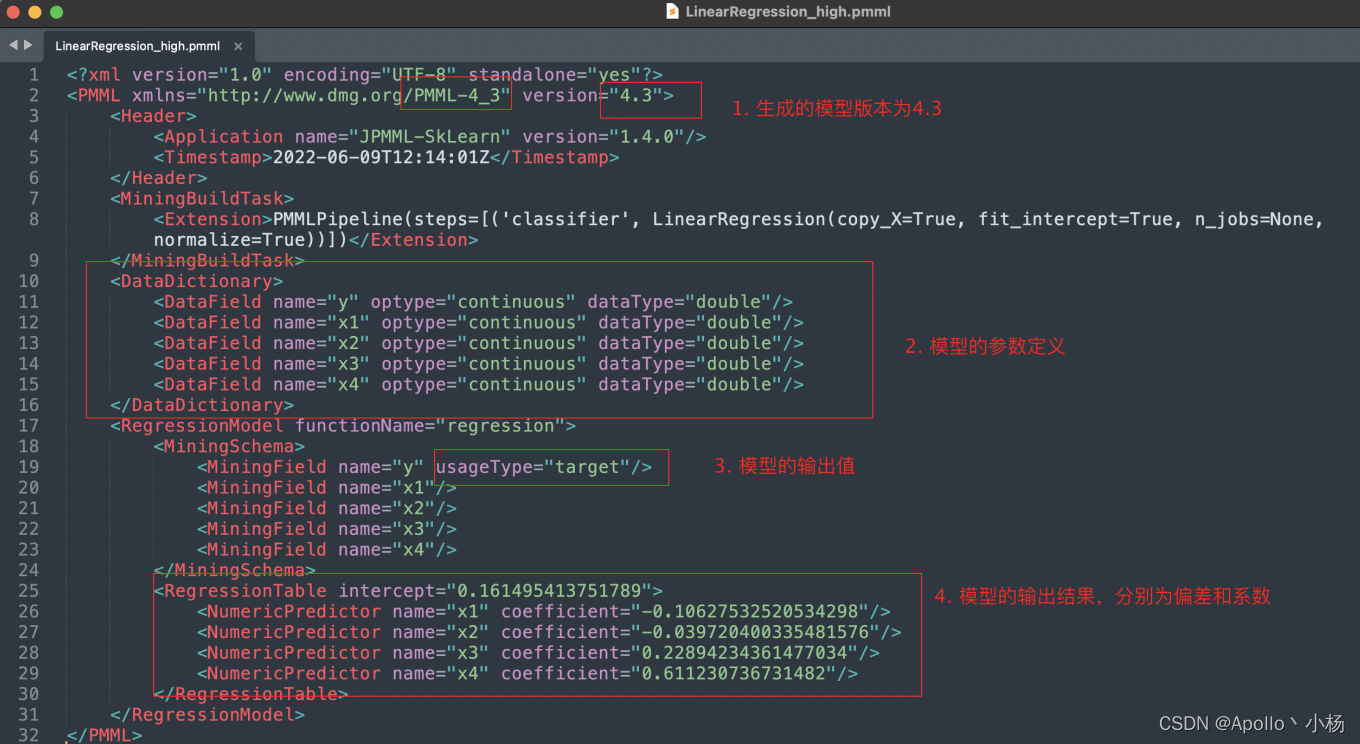
指定python库的版本,可以⽣成版本为4_3的PMML模型(最新是4_4版本):
● python 3.6
● scikit-learn 0.20.4
● sklearn2pmml 0.26.0
二、模型⽣成样例
1. 线性模型
from sklearn import datasets
from sklearn2pmml import PMMLPipeline, sklearn2pmml
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# 读取数据
iris = datasets.load_iris() # 鸢尾花数据
# 拆分训练数据和测试数据
train, test, train_labels, test_labels = train_test_split(iris.data,
iris.target, test_size=0.2, random_state=0)
# 模型定义
lr = PMMLPipeline([("classifier", LinearRegression(normalize=True))])
# 模型拟合
lr.fit(train, train_labels)
# 输出pmml模型⽂件
sklearn2pmml(lr, 'LinearRegression_high.pmml', with_repr=True,
debug=True)
⽣成的pmml模型,模型中的更多语法可⻅https://dmg.org/pmml/v4-3/GeneralStructure.html
2. 决策树模型
from sklearn import tree
tr = PMMLPipeline([("classifier",
tree.DecisionTreeClassifier(random_state=9))])
tr.fit(train, train_labels)
sklearn2pmml(tr, 'DecisionTreeClassifier.pmml', with_repr=True,
debug=True)
3. 朴素⻉叶斯
from sklearn.naive_bayes import GaussianNB
gnb = PMMLPipeline([("classifier", GaussianNB())])
gnb.fit(train, train_labels)
sklearn2pmml(gnb, 'GaussianNB.pmml', with_repr=True, debug=True)
4. ⽀持向量机⽤于分类
from sklearn.svm import SVC
svc = PMMLPipeline([("classifier", SVC(kernel='linear'))])
svc.fit(train, train_labels)
sklearn2pmml(svc, 'SVC.pmml', with_repr=True, debug=True)
a. 注意事项
PMML模型定义的出⼊参的需要遵循参数规范:变量名必须以字⺟开头,由字⺟、数字和下划线 组成,不可为DSL的保留关键字
b. 常⻅报错⾃助排查
NOT_SUPPORT_INNER_METHOD_CALL:看参数中是否包含括号 SYNTAX_ERROR:看参数中是否包含了DSL的关键字


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











