






数据结构研究的是数据的逻辑结构、存储结构及其操作
数据:计算机处理的对象(数据)已不再单纯是数值,更多的是一组数据

通常对数据操作增删改查
在对单链表操作比较多这里除过增删改查 增加排序和链表的逆序思想和源码
顺序
特点:
1.顺序并且连续存储、访问方便
2.大小固定
3.表满不能存、表空不能取
优点:访问方便
缺点:插入、删除不方便都需要移动元素
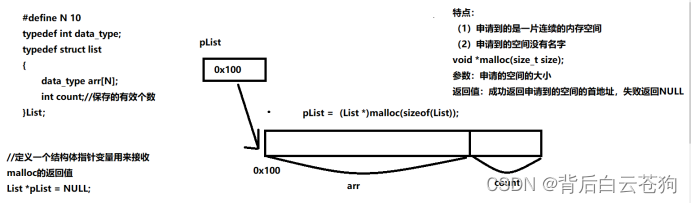
定义一个顺序表的类型
typedef int data_type;
#define N 10
typdef struct list
{
data_type arr[N];
int count;//有效数据的个数(0 == count不能取、N == count不能存)
}List;
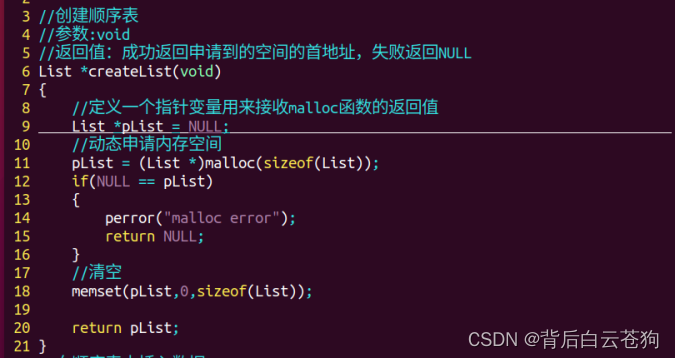
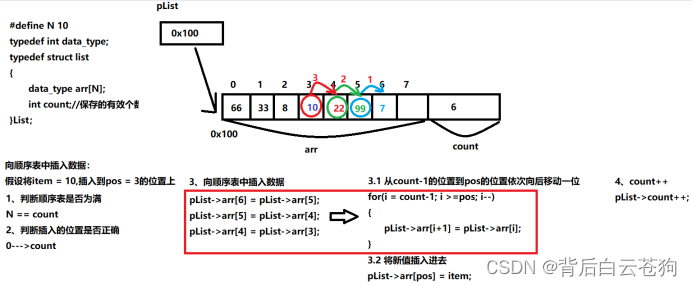
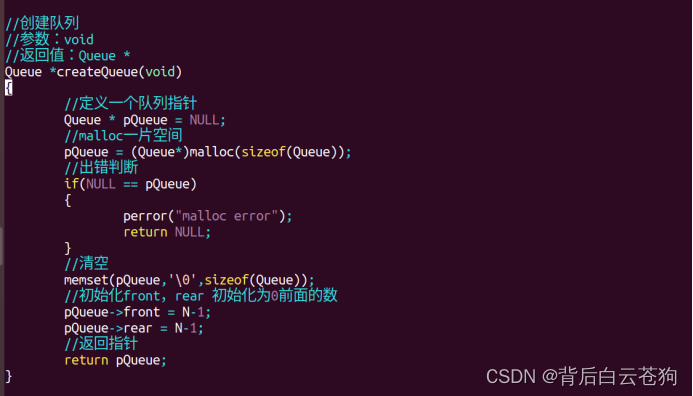
向顺序表中插入数据
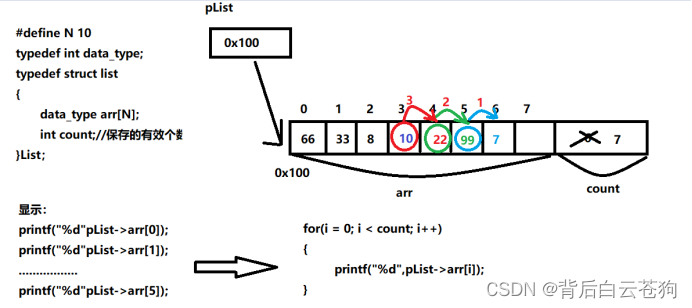
 遍历
遍历
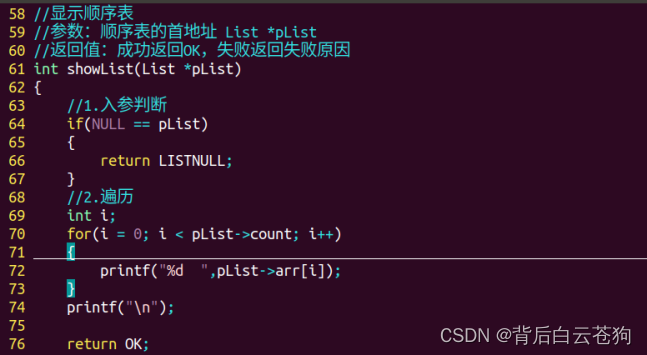
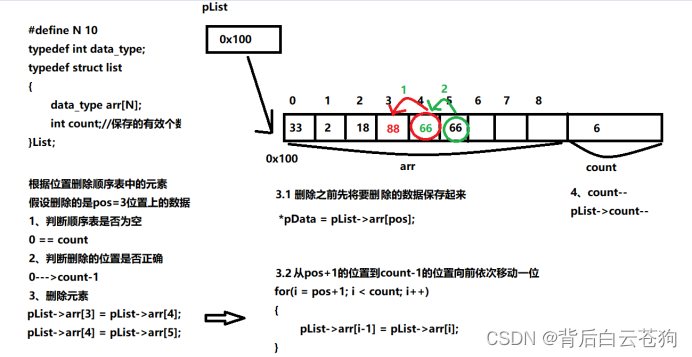
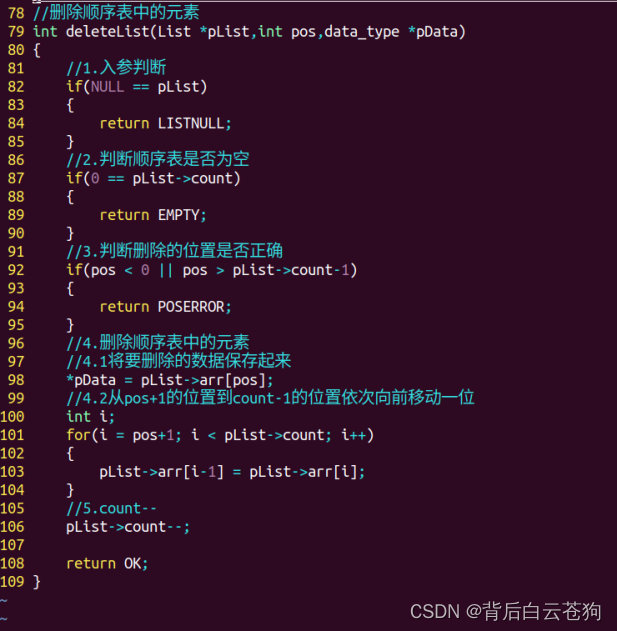
删除顺序表中的元素
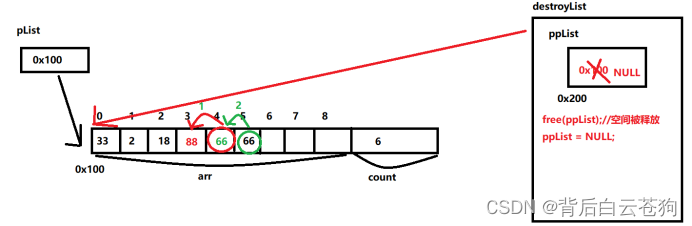
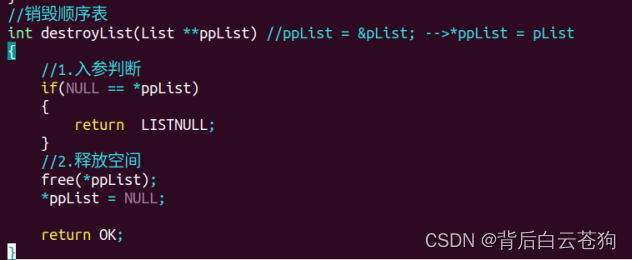
销毁顺序表
链表
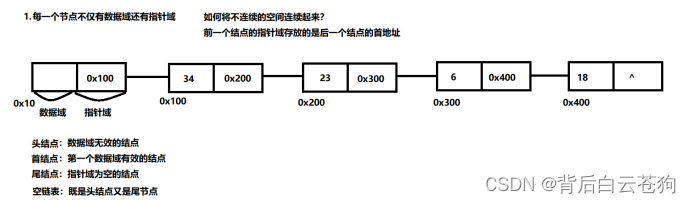
链表的特点
申请的空间可以不连续 访问不方便 插入、删除不需要移动元素
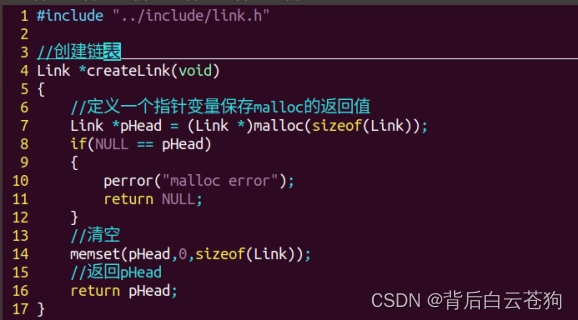
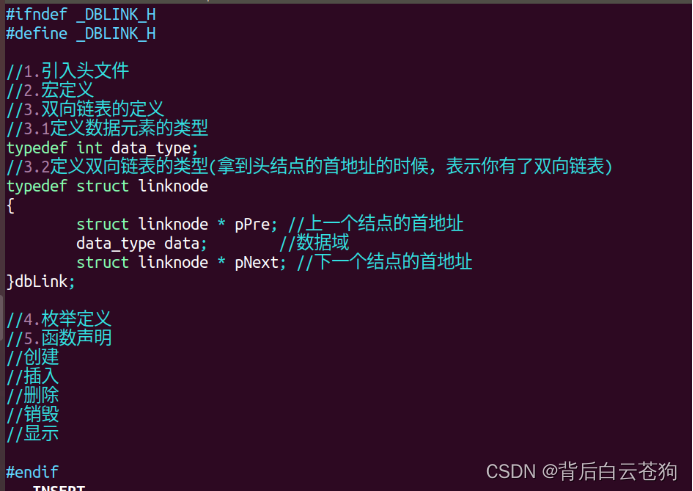
定义链表中的结点的数据类型
typedef int data_type;
typedef struct linkNode
{
data_type data;//数据域
struct linkNode *pNext;
}Link;
创建新结点
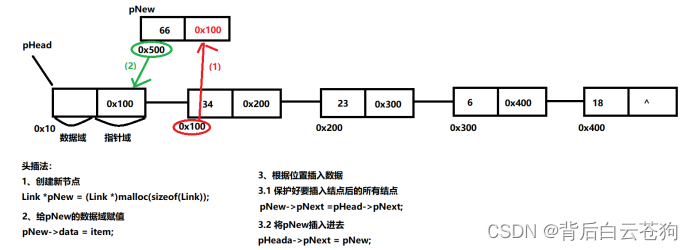
链表中插入数据
头插法

尾插法
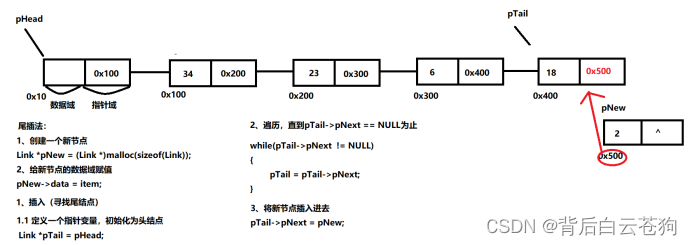

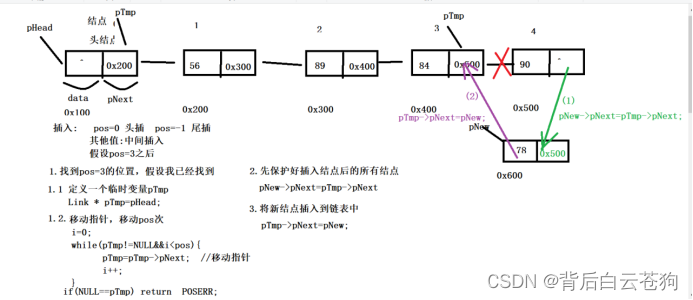
1.6.3. 中间插入

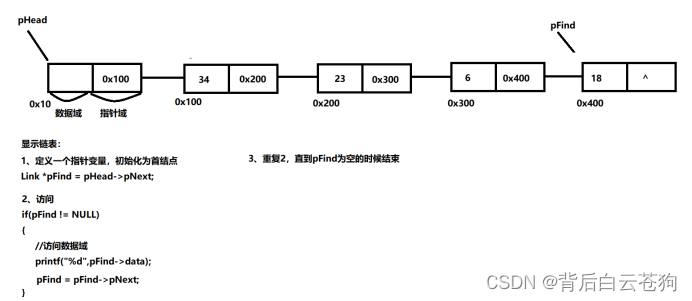
遍历
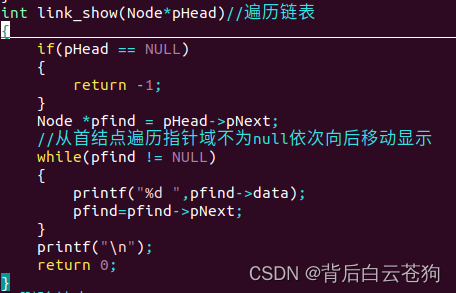
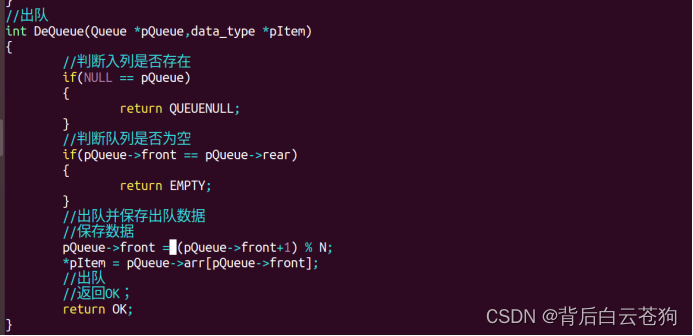
删除链表中的数据
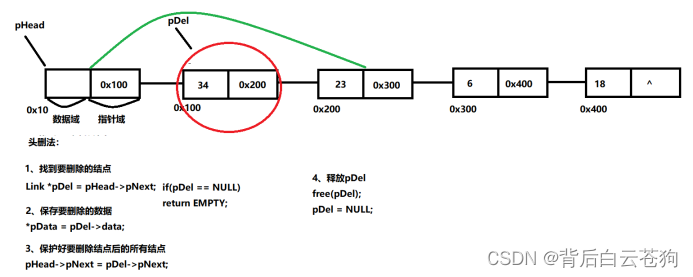
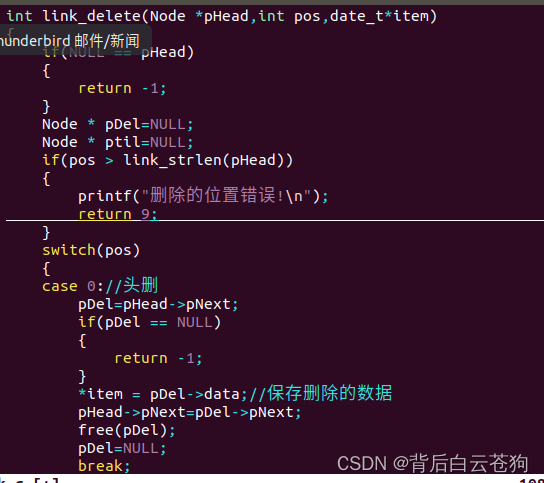
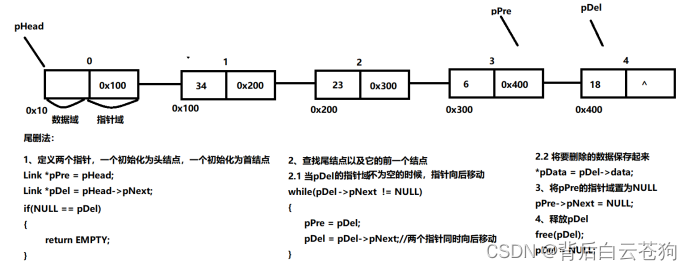
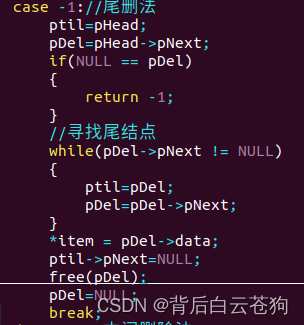
尾删除:
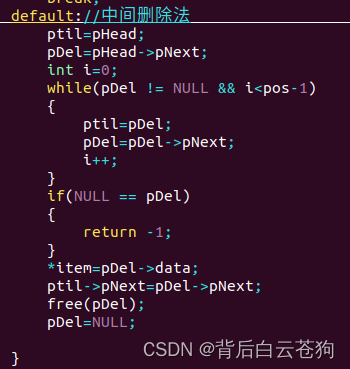
中间删除
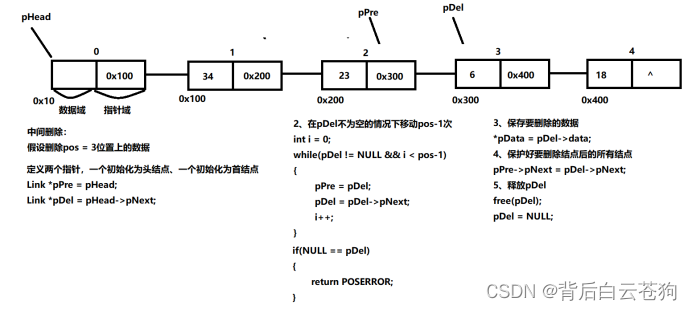
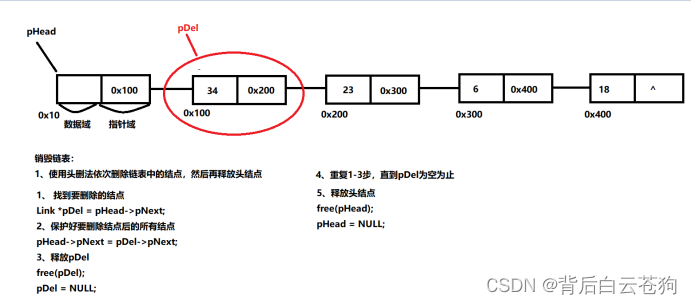
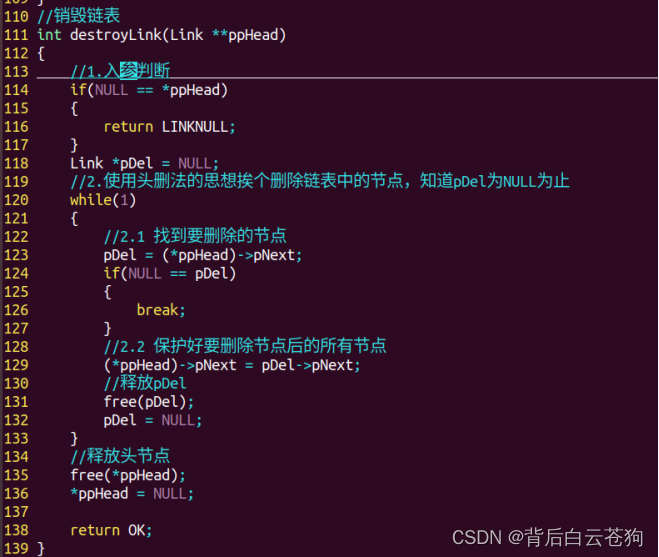
销毁链表
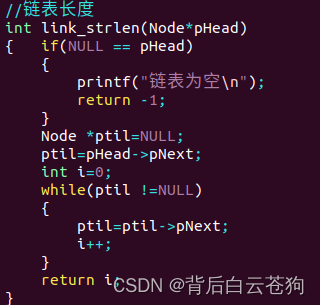
链表长度
改链表的数据
链表排序

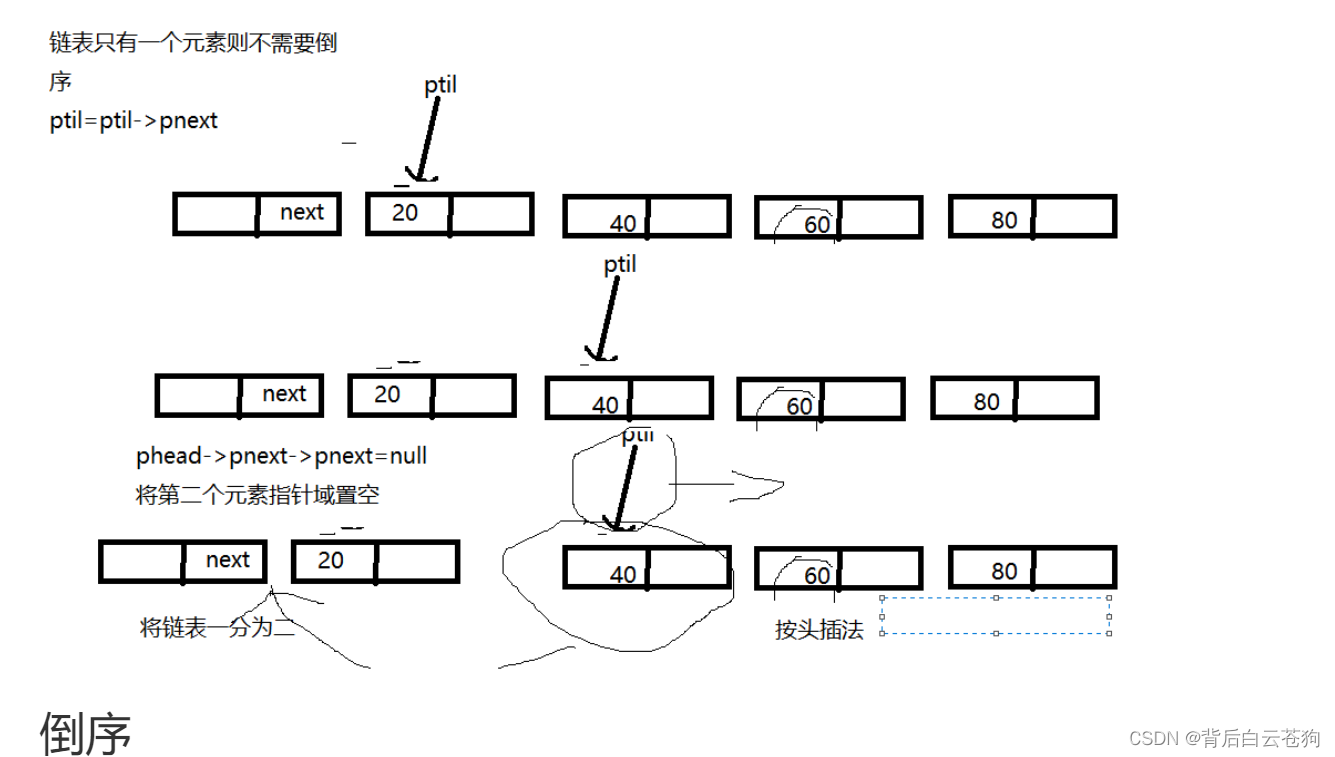
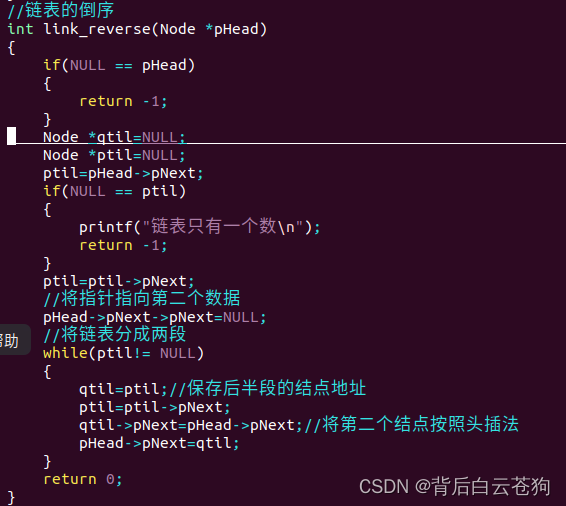
链表逆序
双向链表
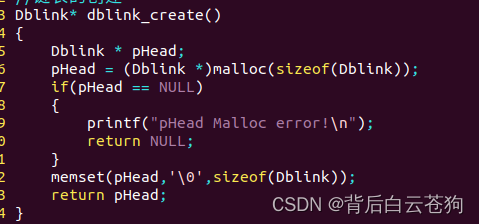
定义创建

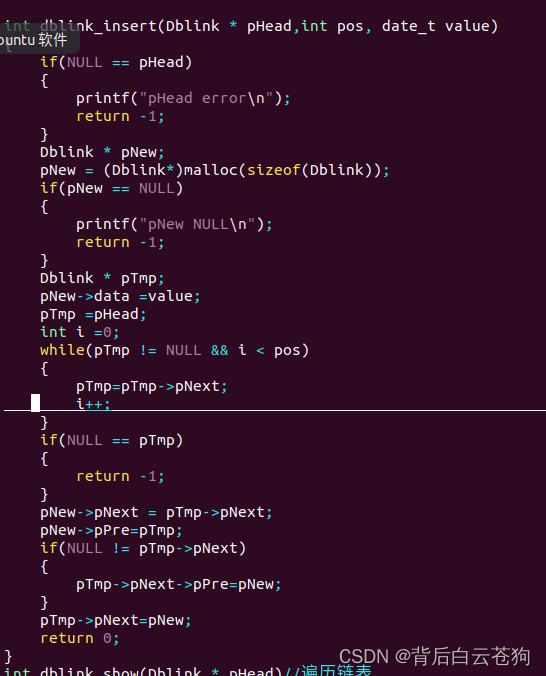
插入元素
遍历与删除
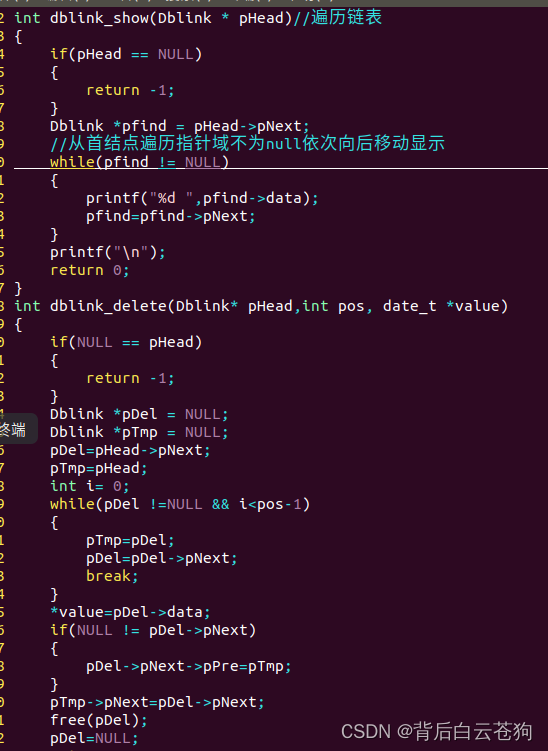 、
、
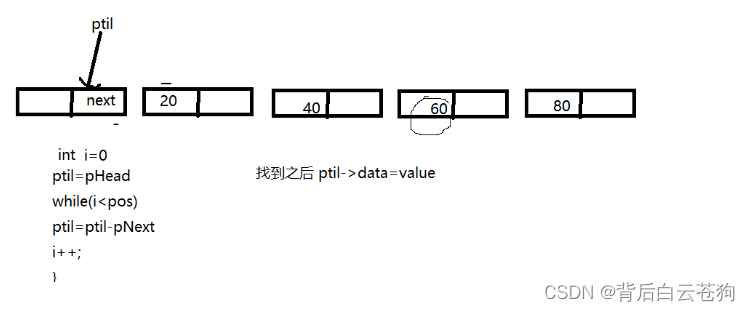
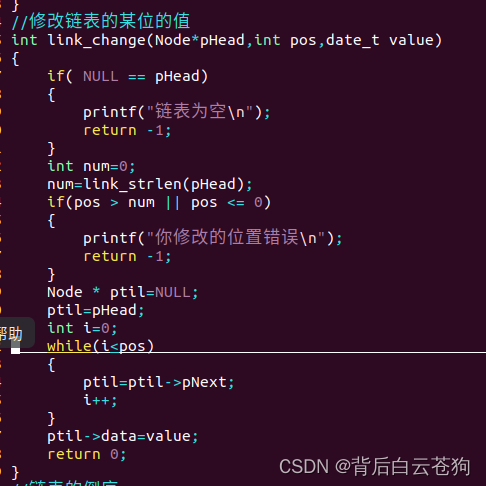
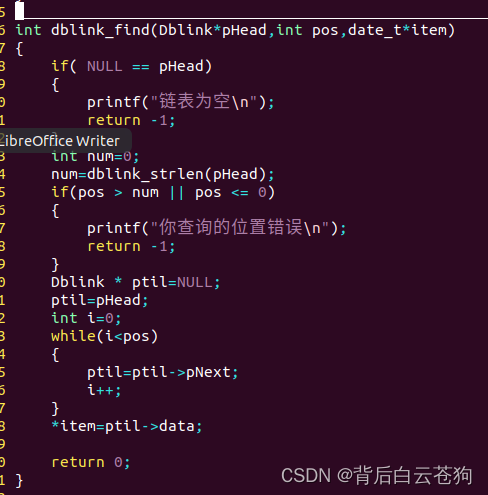
元素的查找 修改只需再引入一个参数
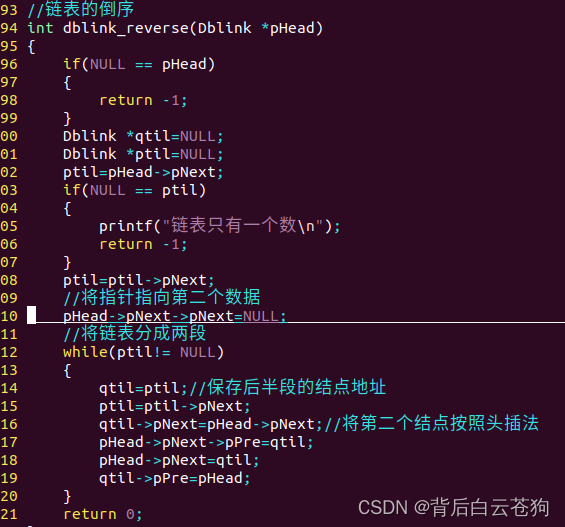
双向表逆序
思想与单向链表一样
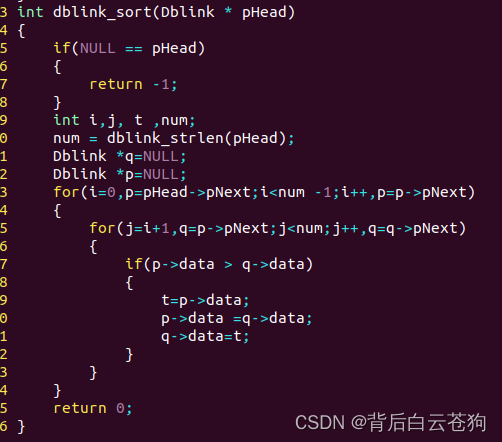
排序
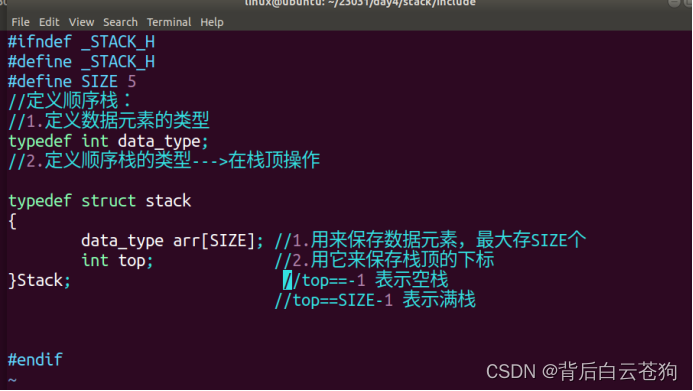
栈:
栈是限制在一端(栈顶)进行插入操作和删除操作的线性表
先入后出
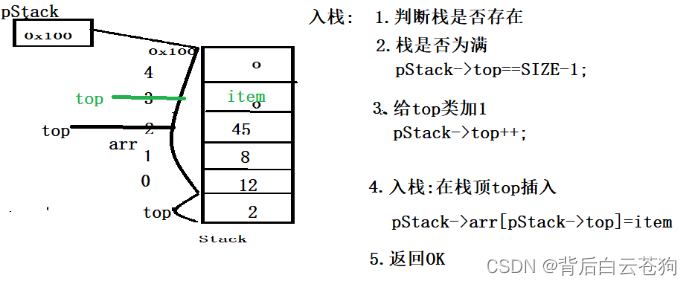
顺序栈:基本与顺序表的类似
zh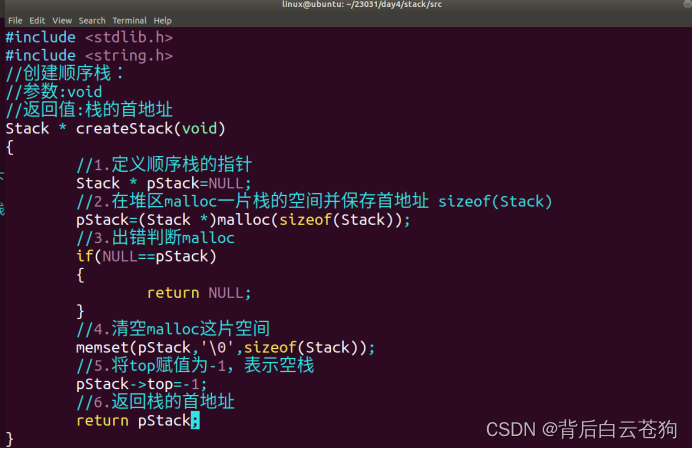
这对top的定义初始值可以时0 只不过再后续定位数据元素有所不同


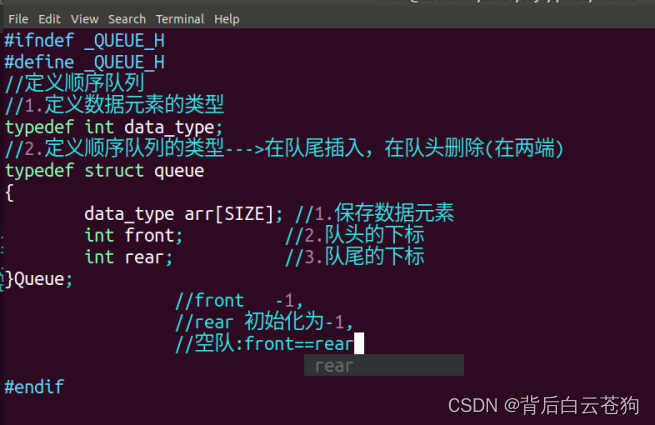
队列
队列允许在两端进行操作,在队尾插入,在队头删除
先进先出

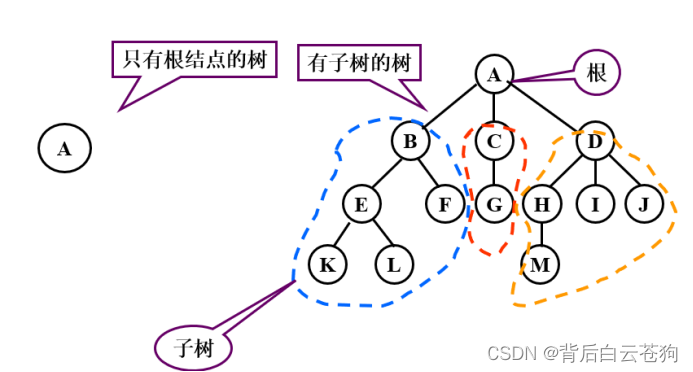
树
树(Tree)是 n(n≥0)个节点的有限集合T,它满足两个条件 :
(1)有且仅有一个特定的称为根(Root)的节点;
(2).其余的节点可以分为m(m≥0)个互不相交的有限集合T1、T2、……、Tm,其中每一个集合又是一棵树,并称为其根的子树(Subtree)。

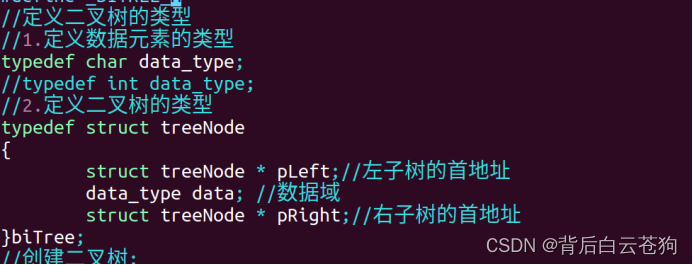
二叉树的定义 :
二叉树(Binary Tree)是n(n≥0)个节点的有限集合,它或者是空集(n=0),或者是由一个根节点以及两棵互不相交的、分别称为左子树和右子树的二叉树组成
定义二叉树
对二叉树的遍历

举例:创建一颗有序树,54 13 78 89 50 34 45 85 90 67
序列中第一数作为根结点,比根结点大的作为它的右子树,比根结点小的左子树

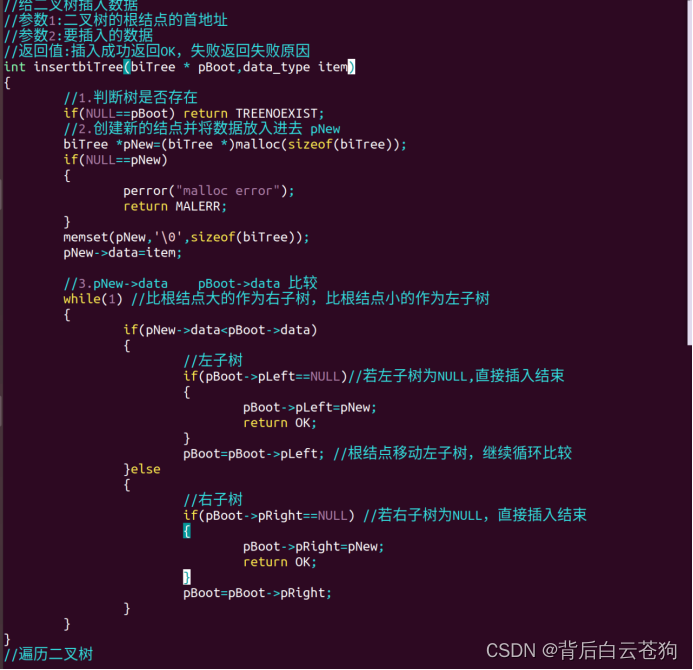

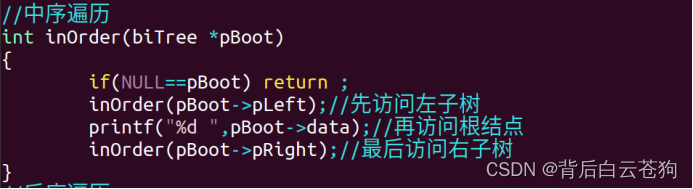
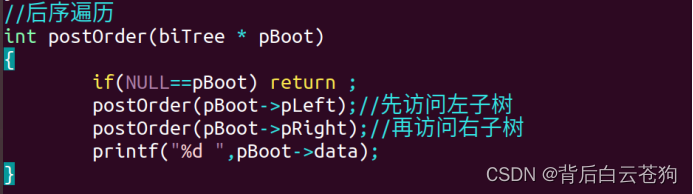
这里主要使用的递归遍历二叉树
注:这里递归遍历一般会存在一个误区当函数到最后一个子叶感觉函数不会返回,看下图一步一步执行就会明白

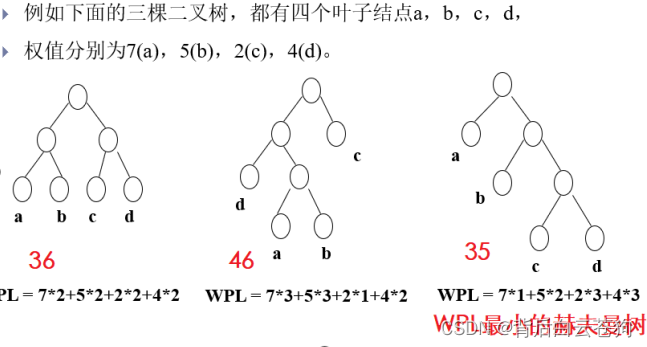
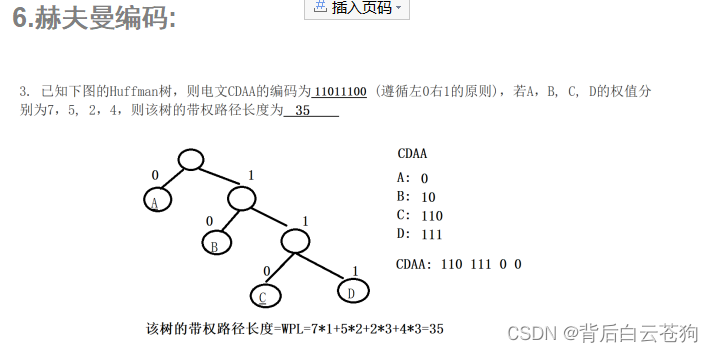
赫夫曼树:
结点的带权路径长度指的是从树根到该结点的路径长度和结点上权的乘积。树的带权路径长度是指所有叶子节点的带权路径长度之和,记作 WPL 。WPL最小的二叉树就是最优二叉树,又称为赫夫曼树















 4407
4407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









