







 CLIP通过对比学习进行预训练,利用大量数据学习到的先验知识,只需标签文本即可实现强大的图像分类。在推理阶段,通过模板将类别转换为文本,然后与图片特征进行余弦相似度比较,实现零样本预测。
CLIP通过对比学习进行预训练,利用大量数据学习到的先验知识,只需标签文本即可实现强大的图像分类。在推理阶段,通过模板将类别转换为文本,然后与图片特征进行余弦相似度比较,实现零样本预测。
CLIP 就是在多模态领域里迈出了重要的一步。其具有非常好的迁移学习能力,预训练好的模型可以在任意一个视觉分类数据集上取得不错的效果,而且是 Zero-shot(不需要对新数据集重新训练,就能得到很好的结果)。换句话说,CLIP是zero-shot的,即没有用下游任务的数据。
常用术语:
- zero-shot,即没有用下游任务的数据。
- SOTA model:state-of-the-art model,并不是特指某个具体的模型,而是指在该项研究任务中,目前最好/最先进的模型。
- 多模态:通常主要研究模态包括"3V":即Verbal(文本)、Vocal(语音)、Visual(视觉)。
- ImageNet:ImageNet项目是一个用于视觉对象识别软件研究的大型可视化数据库,有着超过1400万的图像。
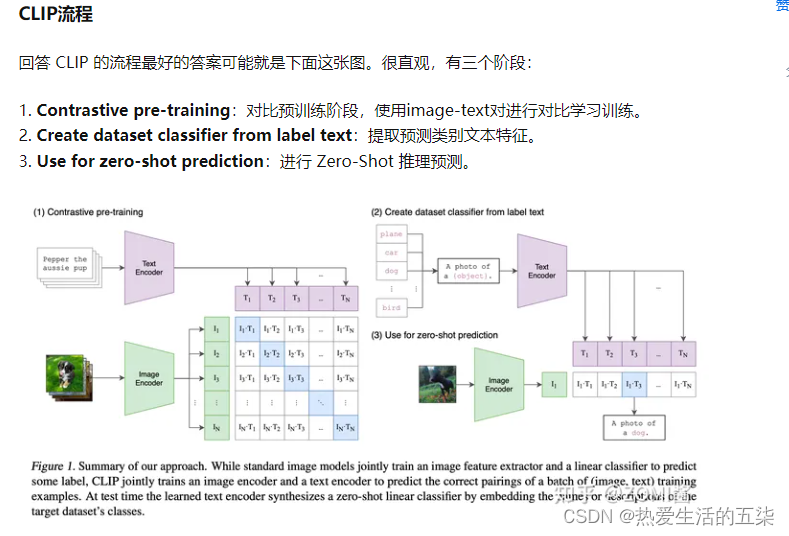
阶段一 :Contrastive pre-training
对比学习十分灵活,只需要定义好 正样本对 和 负样本对 就行了,其中能够配对的 image-text 对即为正样本。具体来说,先分别对图像和文本提特征,这时图像对应生成 I1、I2 ... In 的特征向量(Image Feature),文本对应生成 T1、T2 ... Tn 的特征向量(Text Feature),中间对角线为正样本,其余均为负样本。这样的话就形成了 n 个正样本,n^2 - n 个负样本。一旦有了正负样本,模型就可以通过对比学习的方式训练起来了,完全不需要手工的标注。
阶段二: Create dataset classifier from label text
CLIP最牛逼的地方在于,基于400M数据上学得的先验,仅用数据集的标签文本,就可以得到很强的图像分类性能。现在训练好了,然后进入前向预测阶段,通过 prompt label text 来创建待分类的文本特征向量。
首先需要对文本类别进行一些处理,ImageNet 数据集的 1000 个类别,原始的类别都是单词,而 CLIP 预训练时候的文本端出入的是个句子,这样一来为了统一就需要把单词构造成句子,怎么做呢?可以使用 “A photo of a {object}.” 的提示模板 (prompt template) 进行构造,比如对于 dog,就构造成 “A photo of a dog.”,然后再送入 Text Encoder 进行特征提取。
具体地,用模板填空(promot)的方式从类别标签生成文本。将得到的文本输入Text Encoder。
阶段三 :Zero-shot prediction
最后就是推理见证效果的时候,对于测试图片,选择相似度最大的那个类别输出。
在推理阶段,无论来了张什么样的图片,只要扔给 Image Encoder 进行特征提取,会生成一个一维的图片特征向量,然后拿这个图片特征和 N 个文本特征做余弦相似度对比,最相似的即为想要的那个结果,



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











