






文章目录
week39 DSAMDL
摘要
本周阅读了题为Multimodal deep learning water level forecasting model for multiscale drought alert in Feiyun River basin的论文。该文开发了一种新颖的混合深度架构,即基于双阶段注意力的多模态深度学习(DSAMDL),用于可靠且可解释的多尺度水位预测。结果充分证明,DSAMDL 框架取得了令人满意的精度,在这四个指标上平均提高了 22.4%、27.8%、29.7% 和 11.5%,展示了该模型在处理复杂的多尺度干旱水位预测方面的有效性。本文最后实现了CNN-LSTM模型
Abstract
This article presents the main content of a paper entitled Multimodal deep learning water level forecasting model for multiscale drought alert in Feiyun River basin. In this paper, a novel hybrid deep architecture, i.e., Two-Stage Attention-based Multimodal Deep Learning (DSAMDL), is developed for reliable and explainable multi-scale water level prediction. The results fully demonstrate that the DSAMDL framework achieves satisfactory accuracy, with an average improvement of 22.4%, 27.8%, 29.7%, and 11.5% on these four indicators, demonstrating the effectiveness of the model in handling complex multi-scale drought water level predictions. Finally, this article implementes the CNN-LSTM model.
一、文献阅读
1. 题目
标题:Multimodal deep learning water level forecasting model for multiscale drought alert in Feiyun River basin
作者:Rui Dai, Wanliang Wang, Rengong Zhang, Lijin Yu
期刊名:Expert Systems With Applications
链接:https://doi.org/10.1016/j.eswa.2023.122951
2. abstract
该文开发了一种新颖的混合深度架构,即基于双阶段注意力的多模态深度学习(DSAMDL),用于可靠且可解释的多尺度水位预测。结果充分证明,DSAMDL 框架取得了令人满意的精度,在这四个指标上平均提高了 22.4%、27.8%、29.7% 和 11.5%,展示了该模型在处理复杂的多尺度干旱水位预测方面的有效性。
This article develop a novel hybrid deep architecture, that is Dual-Stage Attention-based Multi-modal Deep Learning (DSAMDL), for reliable and interpretable multi-scale water level forecasting. The results well-document that the DSAMDL framework achieves satisfactory accuracy, with an average improvement of 22.4%, 27.8%, 29.7%, and 11.5% in these four metrics, showcasing the model’s effectiveness in handling complex multiscale drought water level forecasting.
3. 网络架构
首先,使用一维卷积(1DCNN)来捕获局部趋势特征,然后使用双向长短期记忆网络(BiLSTM)来学习长期依赖性。随后,设计了一种双阶段注意力(Attention, Mutli-head&Vanilla)机制,以分阶段的方式将贡献分配给不同的时间和空间。最后,应用自适应融合方法(Fusion)来提高整体性能。
3.1 问题定义
形式上,给定一组观察到的历史值
X
1
:
T
=
{
X
1
t
,
…
,
X
D
t
}
t
=
1
T
∈
R
T
×
D
\mathcal X_{1:T}=\{X^t_1,\dots,X^t_D\}^T_{t=1}\in \mathbb R^{T\times D}
X1:T={X1t,…,XDt}t=1T∈RT×D,其中 T 是时间步长,D 是变量的维度,
X
l
t
X^t_l
Xlt是 第i模数据在t时间发生变化。水文预报的目的是根据历史观测值
X
1
:
T
\mathcal X_{1:T}
X1:T,预测未来水文格局
X
^
T
+
1
:
T
+
h
=
{
X
^
i
t
}
t
=
1
h
∈
R
h
\hat{\mathcal X}_{T+1:T+h}=\{\hat X^t_i\}^h_{t=1}\in \mathbb R^h
X^T+1:T+h={X^it}t=1h∈Rh,其中h代表未来时间范围,公式如下:
X
^
T
+
1
:
T
+
h
=
F
(
X
1
:
T
;
θ
)
(1)
\hat{\mathcal X}_{T+1:T+h}=\mathcal F(\mathcal X_{1:T};\theta)\tag{1}
X^T+1:T+h=F(X1:T;θ)(1)
其中
F
\mathcal F
F是映射函数,
θ
\theta
θ表示所有可学习的参数。
网络整体结构如下
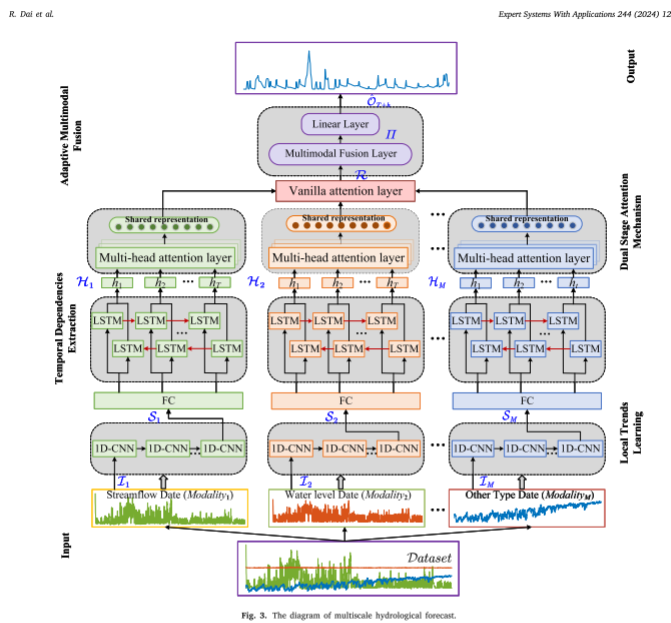

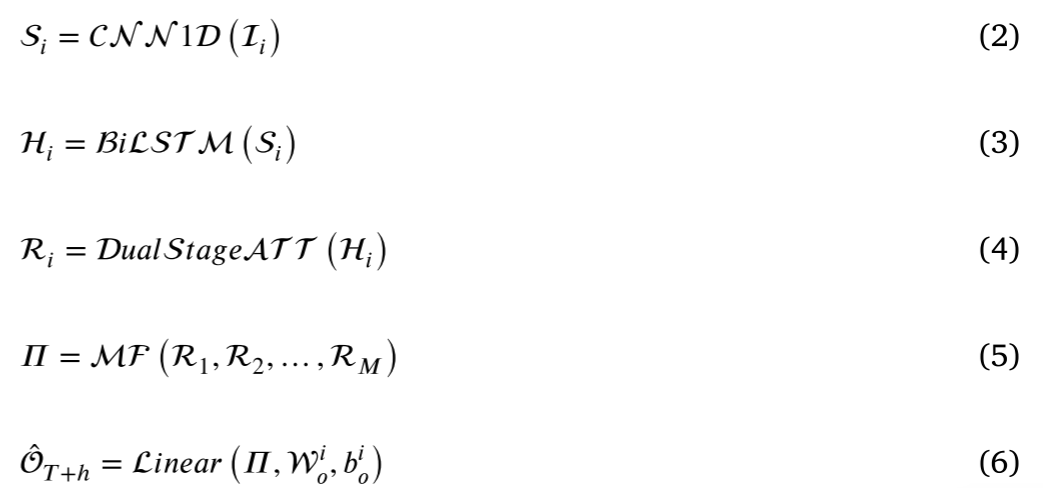
3.2 局域趋势学习
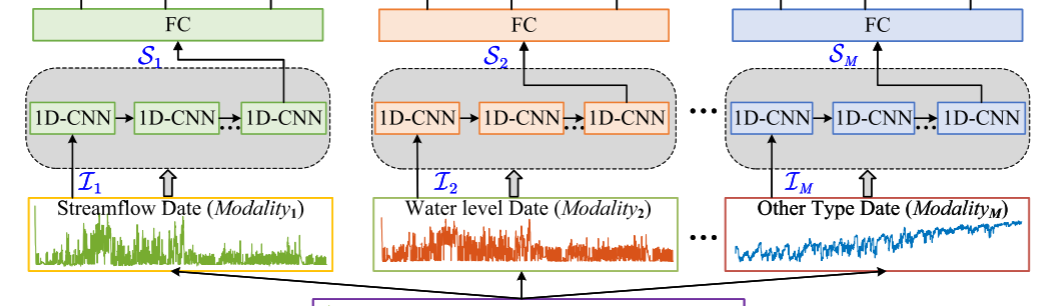
选择1D-CNN来学习从多个站点收集的每个模态数据的局部趋势。以下是计算过程:
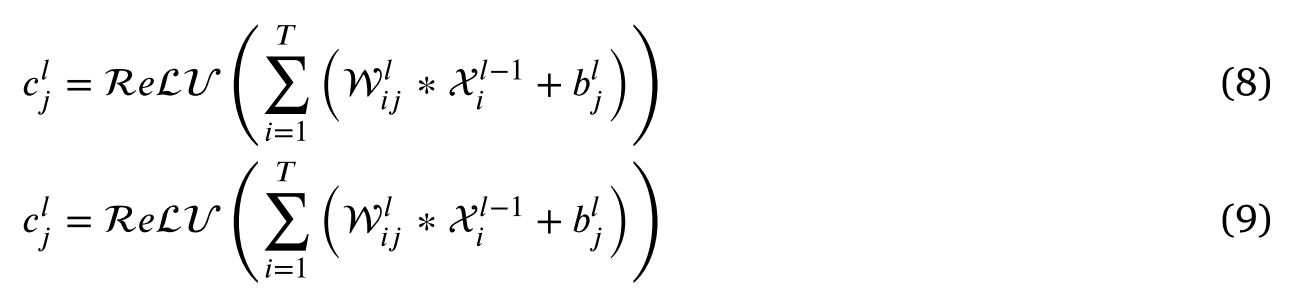
设计了三个用于局部趋势学习的卷积层,每层的输入维度分别为64×3、32×3和16×1。每层负责从前一层模型中获取每个模态数据的非线性特征表示。然后,这些特征通过 Dropout 层传播到后续层,从而能够提取越来越抽象的局部特征。随后,使用flatten函数将多维特征转换为一维特征向量。最后,通过全连接层生成特征向量作为输出
flatten操作公式如下:

3.3 长时间依赖性提取

上图为BiLSTM的大致结构,下图描绘了LSTM的内部单元结构。

典型的 LSTM 单元由一个核心单元(即记忆单元 Z t ( C ) \mathcal Z^{(C)}_t Zt(C))组成。 Z t ( C ) \mathcal Z^{(C)}_t Zt(C)负责存储神经元的状态。 Z t ( l ) \mathcal Z^{(l)}_t Zt(l)& Z t ( O ) \mathcal Z^{(O)}_t Zt(O)负责接收和修改细胞状态。最终, Z t ( F ) \mathcal Z^{(F)}_t Zt(F)决定了单元的输出。具体计算过程如下。
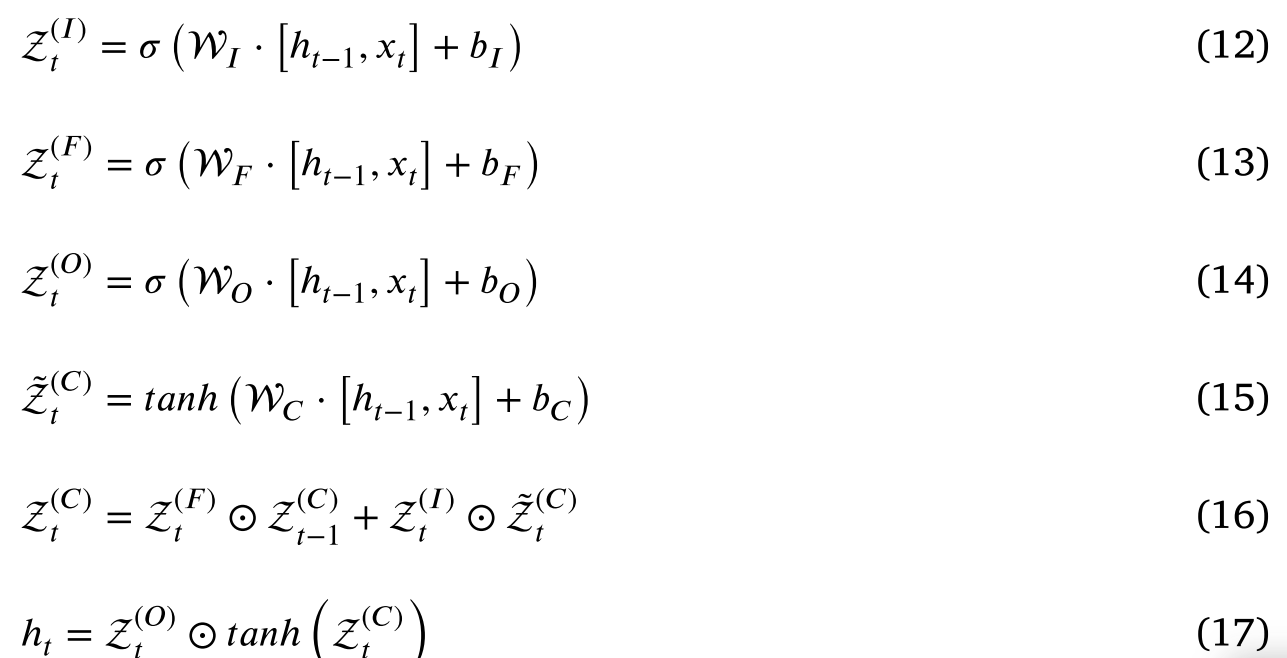
3.4 双阶段注意力机制
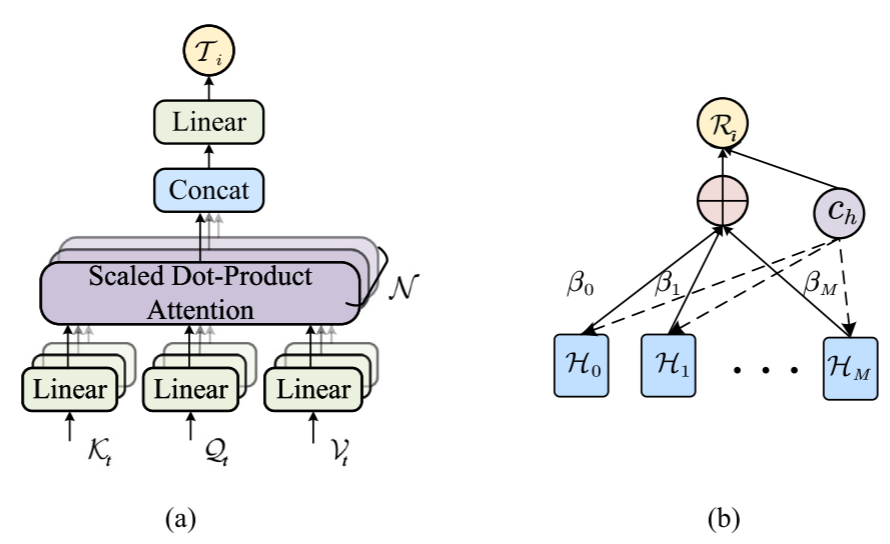
上图左侧为多头注意力层,上图右侧为原始注意力层
多头注意力使用H-head,整个计算过程描述如下:
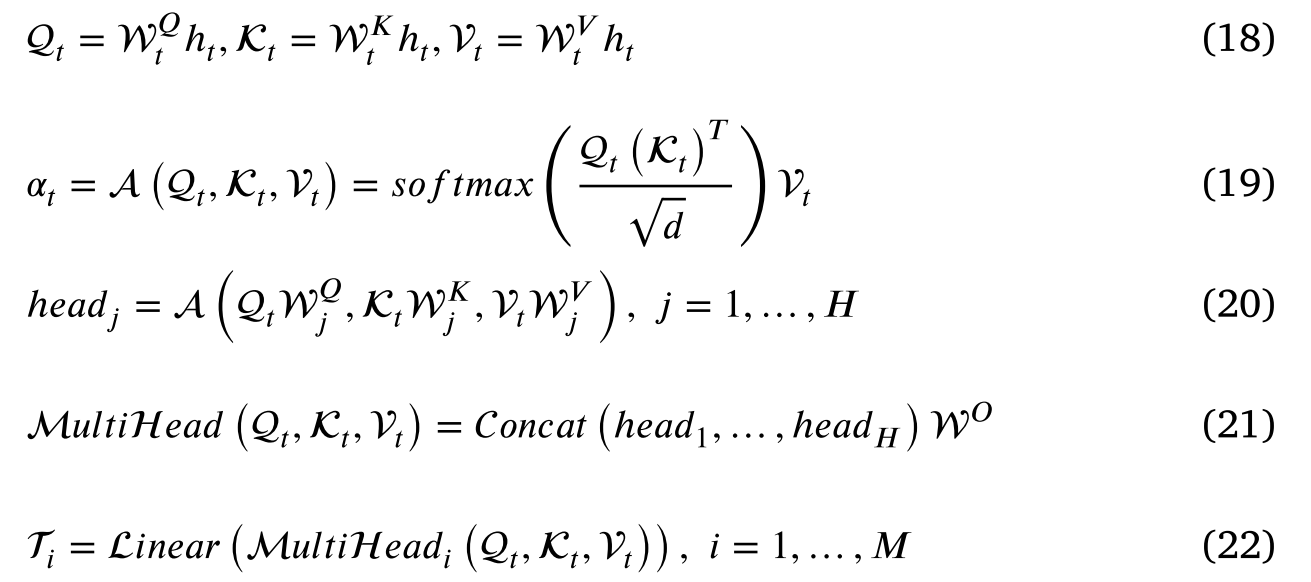
3.5 多模态融合预测
首先,通过连接 BiLSTM 和双阶段注意力机制从多模态数据中提取的特征向量
R
i
(
i
=
1
,
…
,
M
)
\mathcal R_i(i=1,\dots, M)
Ri(i=1,…,M)产生新的共享表示向量。然后,引入线性回归来预测输出,如下所示:
O
^
T
+
h
=
W
(
R
1
⊕
⋯
⊕
R
m
)
+
b
(26)
\hat{\mathcal O}_{T+h}=\mathcal W(\mathcal R_1\oplus \dots \oplus \mathcal R_m)+b\tag{26}
O^T+h=W(R1⊕⋯⊕Rm)+b(26)
4. 文献解读
4.1 Introduction
为了克服这些障碍,本文受到视觉注意机制和多模态深度学习概念的启发,开发了一种基于双阶段注意力的多模态深度学习预测框架(DSAMDL)。与现有方法相比,该方法利用从飞云河流域主要观测站收集的水文数据,结合气象数据,将每个相关变量视为单峰数据集,然后进行全面的融合学习。此外,还设计了一种新颖的注意力机制,用于关键时空信息的分阶段学习,从而增强模型的可解释性。将可解释的深度学习应用于多尺度水位预测是一项新颖且有价值的尝试。
4.2 创新点
该文设计了DSAMDL模型,主要使用了一维卷积、双向长短记忆力、两种注意力机制、自适应融合方法。具体贡献如下:
- 建立一维CNN(1D-CNN)和双向LSTM(BiLSTM)的组合来从非平稳多模态数据中提取潜在特征。前者用于捕获局部趋势特征,而后者用于捕获长期依赖性。
- 设计了双阶段注意力机制,从多模态数据中捕获关键时空特征,包括水位、流量、蒸发、温度、降水、压力、湿度和风速八个变量。在第一阶段,堆叠多头注意力机制为不同时间步长的特征分配不同的权重。第二阶段使用普通注意力模块来提高关键模态数据的贡献。
- 通过自适应多模态融合过程实现信息互补,减少无关因素对模型性能的影响,显着提高短期和长期预测的准确性。
- 飞云河流域多尺度干旱水位预测的大量实验表明,该方法在预测精度和鲁棒性方面优于最新模型,具有巨大的实用潜力。
4.3 实验过程
为了验证其准确性和有效性,对温州市飞云江流域的6个水库站进行了短期长期干旱水位预报和各种事件下的预测。引入 RMSE、MAE、CORR 和 NSE 四个评估指标,根据起始基线进行综合评估。
4.3.1数据集
观测站设置如下
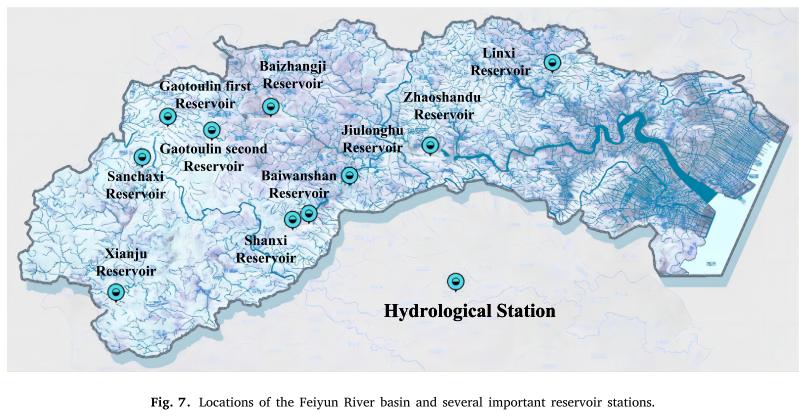
为了验证模型的性能,选择了飞云河流域内六个水库站(即山西薛口水库、百丈山水库、九龙湖水库、百丈集水库和赵山渡水库)从7月份开始总共11688小时的水位和来水观测数据。时间为2022年10月1日至2022年10月30日。此外,还纳入了该时期的温度、气压、相对湿度、风速、降雨量和蒸发量等6个相关特征数据作为输入模态数据。该文采用的多源数据结构如下所示。数据集的空间精度为0.01×0.01弧度。纬度和经度的范围是(120.54°,27.79°)。
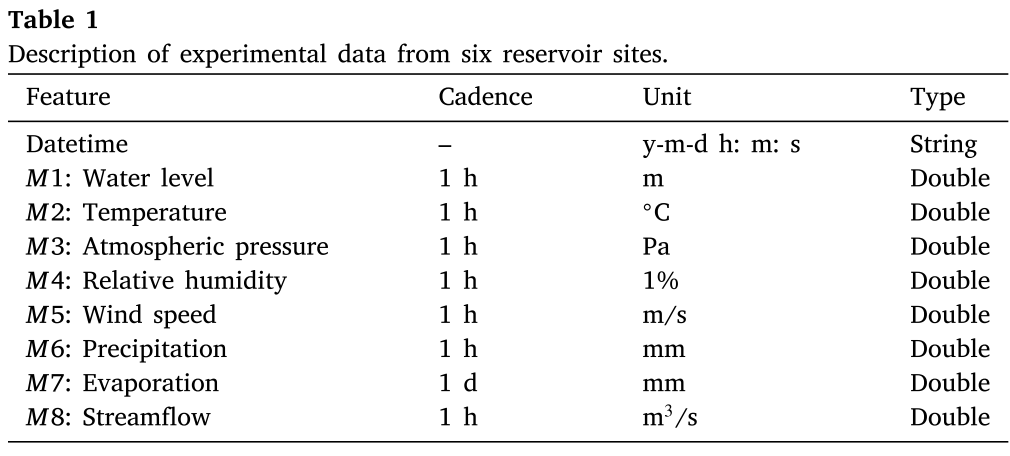
4.3.2 评估标准以及参数设置
评估标准:使用均方根误差 (RMSE)、平均绝对误差 (MAE)、经验相关系数 (CORR) 和 Nash-Sutcliffe 效率 (NSE)
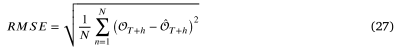
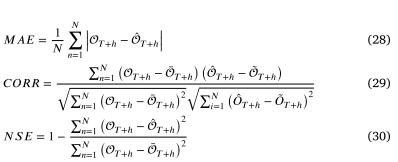
参数设置:
-
实验设置:通过对超参数空间的广泛探索,我们获得了一组优化所提出模型性能的超参数值。结果如图 10 所示。因此,实验中的所有优化器都是用 Adam 编译的,其中初始学习率为 1e−2,批量大小为 32,历元为 100。所提出模型的实现为基于以Tensorflow为背景的深度学习库Keras。所有实验均在单个 NVIDIA GeForce RTX 3090 GPU 上进行,PC 服务器配置为第 12 代 Intel ® Core ™ i9-12 900 K 3.20 GHz、64G RAM。进一步地,所有模型均重复建立五次,以减少随机性,取五次结果的平均值作为最终的预测结果。
-
基线方法:采用许多经典和最先进的基线模型进行性能分析。
- 对于短期预测,ARIMA 、神经基础扩展分析 (N-Beats)、自回归循环网络 (Deep-AR) 、LSTM-ED、TCN-LSTM、基于 Time2Vec 的 BiLSTM、基于 Time2Vec、具有宽第一层内核的深度 CNN (WDCNN) 和 BiLSTM (T2V-WDCNN-BiLSTM) 的混合模型 和基于自适应傅里叶分解方法的 TCN (AFDM-TCN)
- 对于中长期预报,CNN-GRU、BiLSTM-S2S、CNN -S2S和 LSTM-SS
- 三种具有注意力机制的预测模型,AT-BiLSTM、TATCN和 SAT-LSTM
实验中,所有对比方法的超参数均按照原论文设置。其中,输入时间步长为 T = { 7 h , 21 h , 35 h , 7 d , 14 d , 35 d } T = \{7 h, 21 h, 35 h, 7 d, 14 d, 35 d\} T={7h,21h,35h,7d,14d,35d},输出时间间隙为 h = { 1 h , 3 h , 7 h , 1 d , 7 d , 15 d } h = \{1 h, 3 h, 7 h, 1 d, 7d,15d\} h={1h,3h,7h,1d,7d,15d}。
4.3.3 实验过程
短期预测
下表记录了ARIMA、N-Beats、Deep-AR、LSTMED、TCN-LSTM、T2V-BiLSTM、T2V-WDCNN-BiLSTM、AFDM-的四个评估指标(即RMSE、MAE、NSE和CORR)的平均值TCN 和 DSAMDL 分别在时间范围 T + 1 h、T + 3 h 和 T + 7 h 处。其中,最优值以黑色粗体突出显示。ARIMA、N-Beats、Deep-AR 和 AFDM-TCN 仅适用于单变量序列预测,而其他方法则用于多变量序列预测。
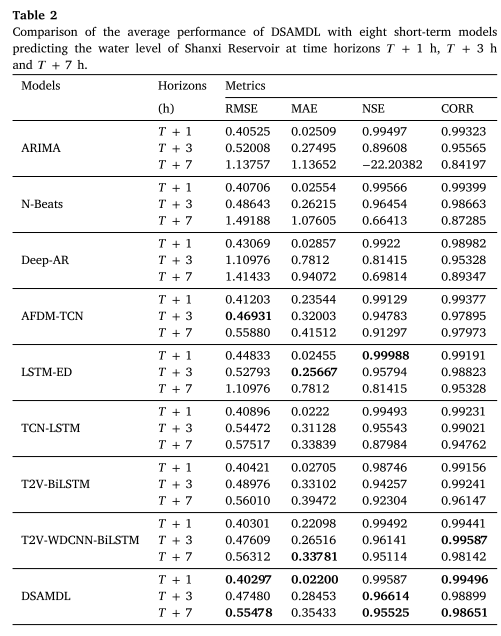
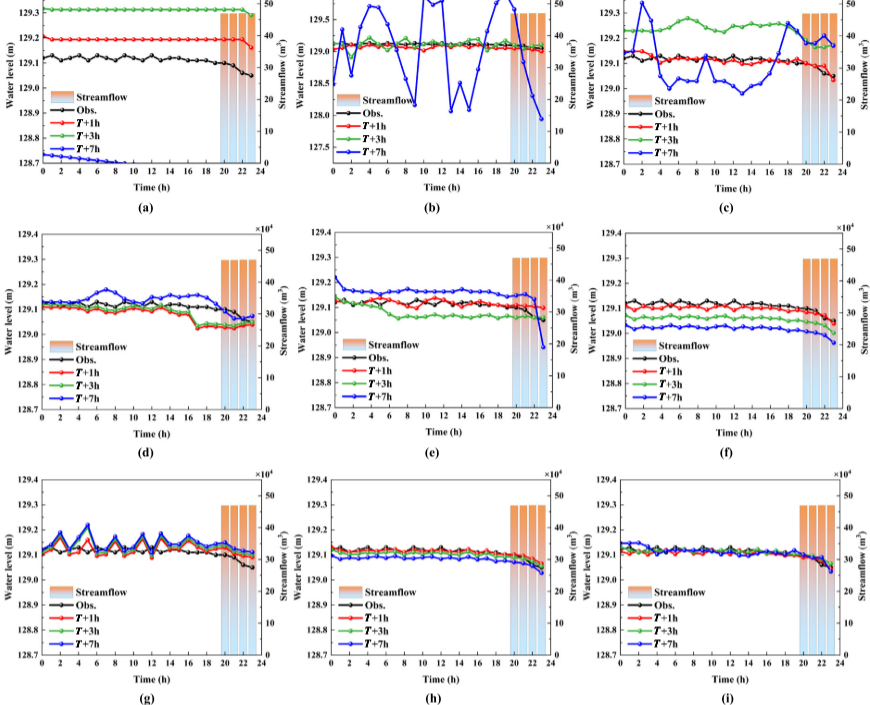
如上图为2022年10月30日,9个预报模型分别在𝑇+1 h、𝑇+3 h和𝑇+7 h时间范围内获得的山西水库水位预测值与实测值对比结果。其中(a)–(i)是ARIMA、N-Beats、Deep-AR、AFDM-TCN、LSTM-ED、TCN-LSTM、T2V-BiLSTM、T2V-WDCNN-BiLSTM和DSAMDL的结果。条形图表示来流量,点图表示水位值。
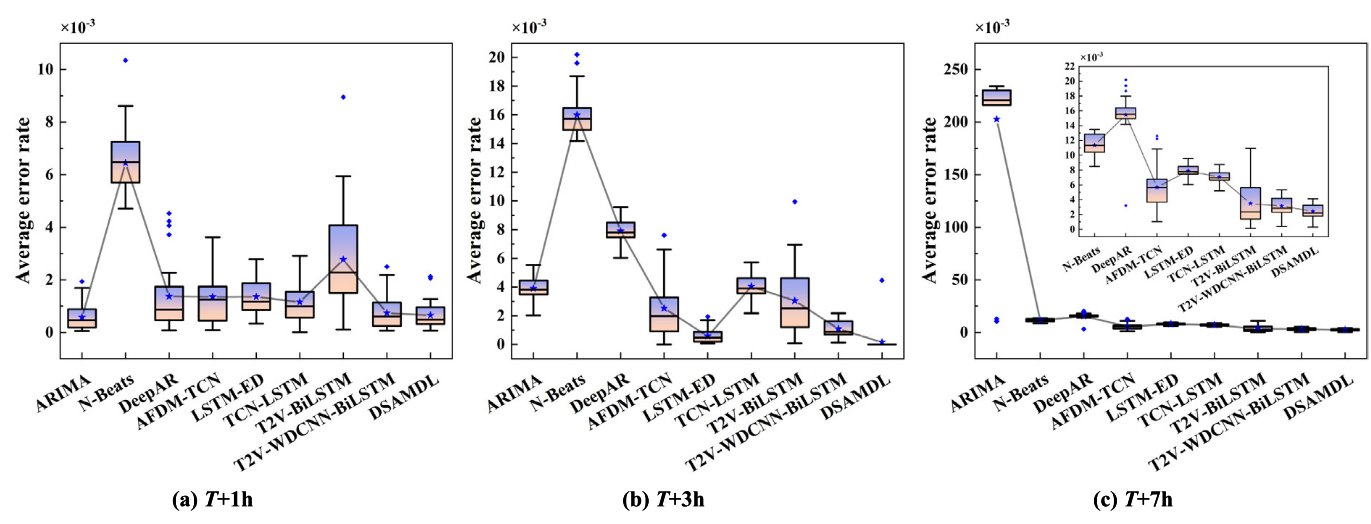
上图为DSAMDL 和比较模型在三个预测间隙处获得的平均预测误差率的框图。其中,第二四分位数用方框内的直线表示;菱形代表平均值;框的开头和结尾分别代表第一和第三四分位数。所以盒子越小,平均值越小,模型性能越稳健。
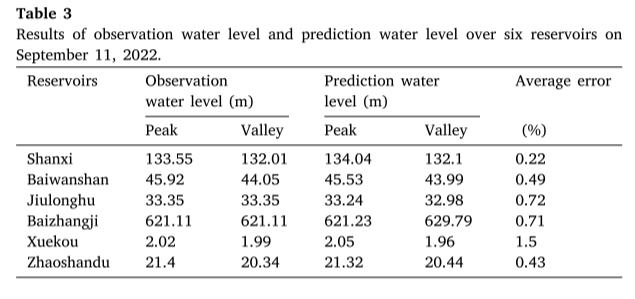
上表展示了2022 年 9 月 11 日观测到的 6 个水库全天峰谷水位,并将其与 DSAMDL 模型生成的预测进行比较,如表 3 所示。
中长期预测
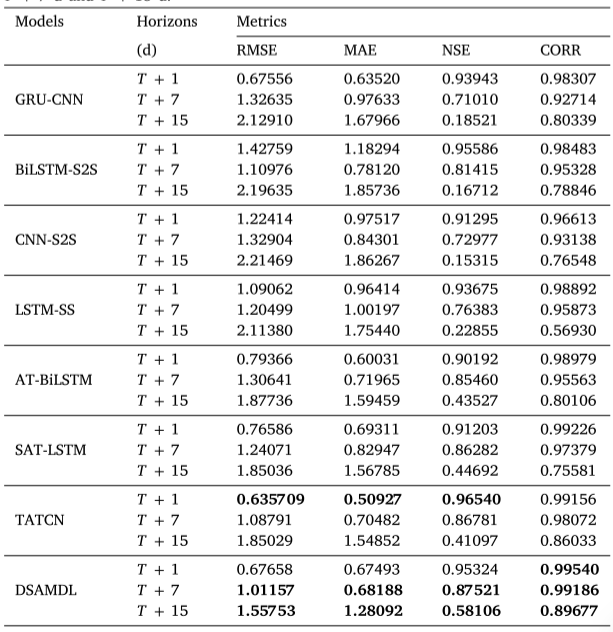
上表为该文所提出的模型与山西水库水位长期预测的七个最新模型在𝑇 + 1 d、𝑇 + 7 d和𝑇 + 15 d时间范围内的平均性能比较。
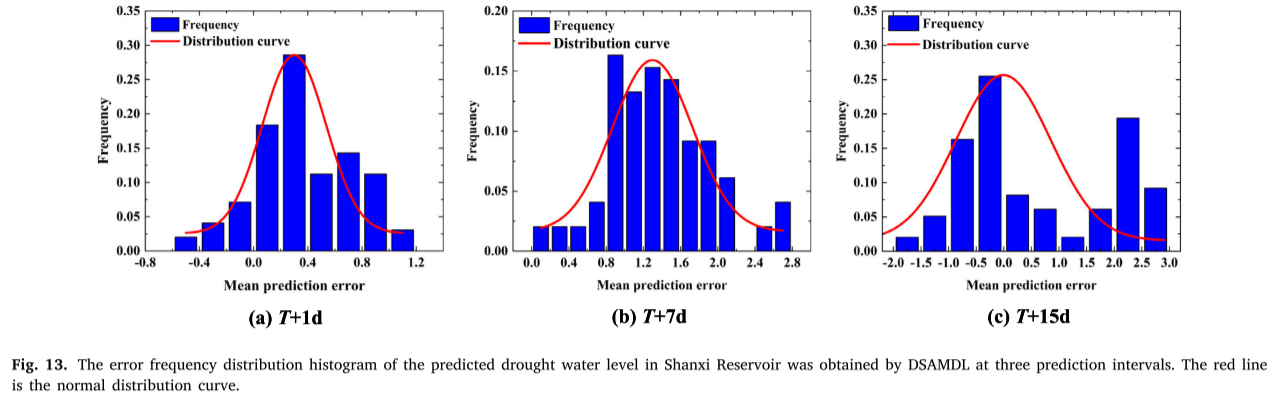
上图展示了利用DSAMDL获得了山西水库预测干旱水位在3个预测区间的误差频率分布直方图。红线是正态分布曲线。
不同场景下的预测
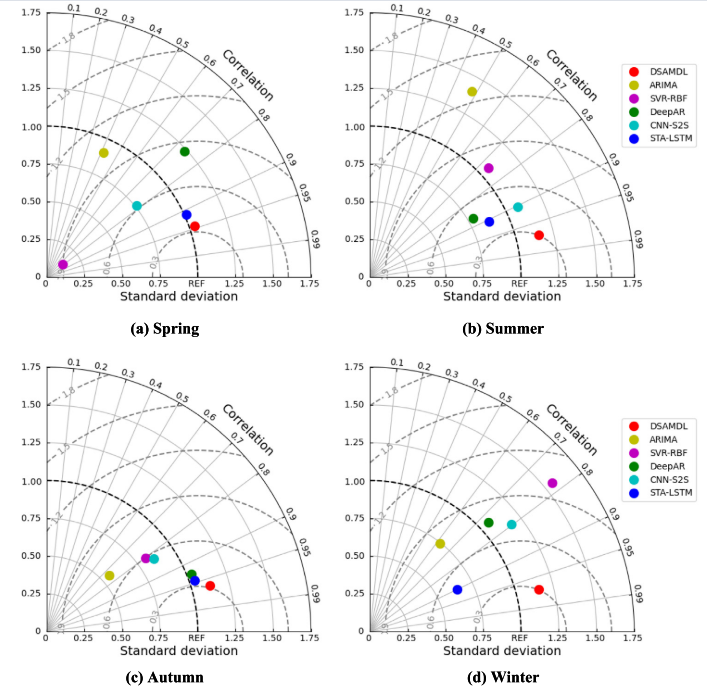
上图为归一化泰勒图显示了夏季(七月和八月)和秋季(九月和十月)期间山西水库水位观测与六个模型预测的比较结果。该图显示了标准差、CORR 和 RMSE 的比率。
消融研究
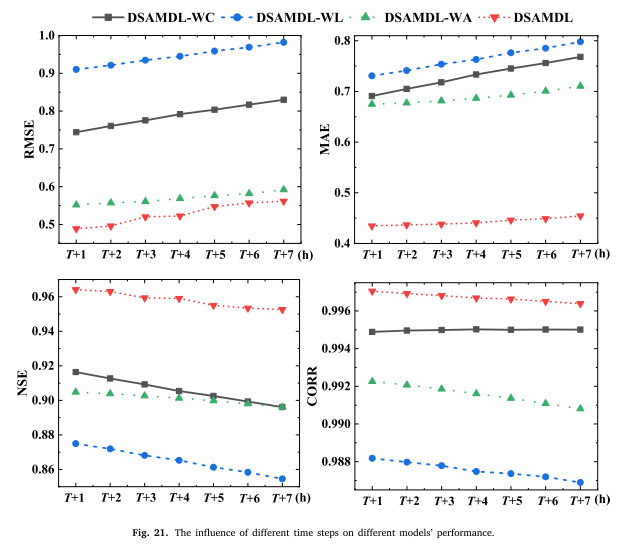
(1) DSAMDL-WC:不带特征提取模块的DSAMDL模型;
(2) DSAMDL-WL:不包含时间序列信息挖掘组件的DSAMDL模型;
(3) DSAMDL-WA:没有注意力机制的DSAMDL模型。
5. 结论
总之,该文提出了一种新型混合深度学习结构 DSAMDL 来预测飞云河流域六个水库的干旱水位。首先,构建多个CNN-BiLSTM来自适应融合多模态信息,以达到最优的预测结果。同时,双阶段注意力机制旨在过滤掉不相关的特征信息,从而能够更有效地探索多源数据中更深层的特征表示。最终,通过多尺度水位预测、敏感性因子分析、消融实验和复杂性分析验证了该方法的性能和效率。结果表明该方法表现出出色的预测潜力。在短期预测中,DSAMDL 准确捕捉局部极端变化,产生稳定的预测结果。此外,该模型有效地学习了长期依赖性,从而在中长期预测中准确捕捉水位趋势。
二、CNN-LSTM-AM实现
- CNN对输入数据进行卷积和池化操作,提取空间局部特征:
Feature_CNN = CNN(Input_Data)
- 使用贝叶斯优化器进行调参
def model_tuning():
tuner = BayesianOptimization(
create_model,
objective='val_accuracy',
max_trials=10,
executions_per_trial=2,
directory='model_tuning',
project_name='cnn_lstm_am'
)
tuner.search(x_train, y_train, epochs=10, validation_data=(x_val, y_val), callbacks=[EarlyStopping(monitor='val_loss', patience=3)])
best_model = tuner.get_best_models(num_models=1)[0]
return best_model
- 将CNN提取的特征重塑为时间序列格式,送入LSTM学习时间依赖关系:
其中LSTM的计算过程可以表示为:
其中
W
f
,
W
i
,
W
o
,
W
C
W_f, W_i, W_o, W_C
Wf,Wi,Wo,WC分别为遗忘门、输入门、输出门、候选记忆状态的权重矩阵,h为隐藏状态,C为记忆状态。
f
t
=
σ
(
W
f
∗
[
h
t
−
1
,
x
t
]
+
b
f
)
i
t
=
σ
(
W
i
∗
[
h
t
−
1
,
x
t
]
+
b
i
)
o
t
=
σ
(
W
o
∗
[
h
t
−
1
,
x
t
]
+
b
o
)
C
t
=
f
t
∗
C
t
−
1
+
i
t
∗
t
a
n
h
(
W
C
∗
[
h
t
−
1
,
x
t
]
+
b
C
)
h
t
=
o
t
∗
t
a
n
h
(
C
t
)
f_t = σ(W_f * [h_{t-1}, x_t] + b_f) i_t = σ(W_i * [h_{t-1}, x_t] + b_i) o_t = σ(W_o * [h_{t-1}, x_t] + b_o) C_t = f_t * C_{t-1} + i_t * tanh(W_C * [h_{t-1}, x_t] + b_C) h_t = o_t * tanh(C_t)
ft=σ(Wf∗[ht−1,xt]+bf)it=σ(Wi∗[ht−1,xt]+bi)ot=σ(Wo∗[ht−1,xt]+bo)Ct=ft∗Ct−1+it∗tanh(WC∗[ht−1,xt]+bC)ht=ot∗tanh(Ct)
-
对LSTM各时间步的隐藏状态计算注意力权重,并加权求和。
a_t = softmax(v * tanh(W_a * h_t + b_a)) Context_Vector = sum(a_t * h_t)
其中 v 、 W a 、 b a v、W_a、b_a v、Wa、ba为注意力机制的可学习参数。
- 将注意力加权后的上下文向量送入全连接层,输出最终的预测结果:
Prediction = Dense(Context_Vector)
- 损失函数采用均方误差MSE:
Loss = MSE(Prediction, Target)
- 使用Adam优化器最小化损失函数,更新模型参数:
Params = Adam.minimize(Loss)
重复以上过程,直至模型收敛或达到预设的迭代次数。
import tensorflow as tf
# 定义超参数
input_size = 10
time_steps = 30
hidden_size = 64
attention_size = 32
output_size = 1
# 定义输入占位符
input_data = tf.placeholder(tf.float32, [None, time_steps, input_size])
target_data = tf.placeholder(tf.float32, [None, output_size])
# 定义CNN层
conv1 = tf.layers.conv1d(inputs=input_data, filters=32, kernel_size=3, activation=tf.nn.relu)
conv2 = tf.layers.conv1d(inputs=conv1, filters=64, kernel_size=3, activation=tf.nn.relu)
cnn_output = tf.layers.flatten(conv2)
# 重塑CNN输出为时间序列格式
lstm_input = tf.reshape(cnn_output, [-1, time_steps, hidden_size])
# 定义LSTM层
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(hidden_size)
outputs, states = tf.nn.dynamic_rnn(lstm_cell, lstm_input, dtype=tf.float32)
# 定义注意力层
attention_weights = tf.layers.dense(outputs, attention_size, activation=tf.nn.tanh)
attention_weights = tf.layers.dense(attention_weights, 1, activation=None)
attention_weights = tf.nn.softmax(attention_weights, axis=1)
context_vector = tf.reduce_sum(attention_weights * outputs, axis=1)
# 定义输出层
predictions = tf.layers.dense(context_vector, output_size)
# 定义损失函数和优化器
loss = tf.losses.mean_squared_error(target_data, predictions)
optimizer = tf.train.AdamOptimizer().minimize(loss)
小结
该文开发了一种新颖的混合深度架构,即基于双阶段注意力的多模态深度学习(DSAMDL),用于可靠且可解释的多尺度水位预测。结果充分证明,DSAMDL 框架取得了令人满意的精度,在这四个指标上平均提高了 22.4%、27.8%、29.7% 和 11.5%,展示了该模型在处理复杂的多尺度干旱水位预测方面的有效性。
首先,构建多个CNN-BiLSTM来自适应融合多模态信息,以达到最优的预测结果。同时,双阶段注意力机制旨在过滤掉不相关的特征信息,从而能够更有效地探索多源数据中更深层的特征表示。最终,通过多尺度水位预测、敏感性因子分析、消融实验和复杂性分析验证了该方法的性能和效率。
结果表明该方法表现出出色的预测潜力。在短期预测中,DSAMDL 准确捕捉局部极端变化,产生稳定的预测结果。此外,该模型有效地学习了长期依赖性,从而在中长期预测中准确捕捉水位趋势。
参考文献
[1] Rui Dai, Wanliang Wang, Rengong Zhang, Lijin Yu, “Multimodal deep learning water level forecasting model for multiscale drought alert in Feiyun River basin” [J], https://doi.org/10.1016/j.eswa.2023.122951


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









