






文章目录
week56 HA-GNN
摘要
本周阅读了题为Ha-gnn: a novel graph neural network based on hyperbolic attention的论文。本文引入了一种新的双曲图神经网络 HA-GNN,其能够在双曲空间中利用网络结构和节点特征进行图表示学习。通过引入双曲注意力机制,HA-GNN 能够同时捕捉网络结构属性和节点特征信息。具体来说,首先使用 Mercator(快速模式)将网络映射到双曲空间 H^2 模型中,学习网络结构属性并计算 SP 注意力。接下来,利用自注意力机制在欧几里得空间中学习节点特征信息,并计算 NF 注意力。最后,通过计算双曲注意力将 NF 和 SP 注意力结合起来,从而更好地平衡节点间的关系,提高节点表示的质量。在五个真实网络上的大量实验证明,HA-GNN 相较于其他方法表现出显著的优势。
Abstract
This week’s weekly newspaper decodes the paper entitled Ha-gnn: a novel graph neural network based on hyperbolic attention. The paper introduces a new hyperbolic graph neural network, HA-GNN, which is capable of performing graph representation learning in hyperbolic space by utilizing both the network structure and node features. By incorporating a hyperbolic attention mechanism, HA-GNN can simultaneously capture structural attributes of the network and node feature information. Specifically, it first uses Mercator (fast mode) to map the network into the hyperbolic space model H^2, learning the structural properties of the network and calculating SP attention. Subsequently, it employs a self-attention mechanism to learn node feature information in Euclidean space and calculates NF attention. Finally, by computing hyperbolic attention, it combines NF and SP attention, thereby better balancing the relationships between nodes and improving the quality of node representations. Extensive experiments on five real-world networks demonstrate that HA-GNN exhibits significant advantages over other methods.
一、大数据相关
1. 配置hadoop(完全分布式部署)
-
创建虚拟机的完全克隆两个,并分别命名slave1、slave2
-
在虚拟机设置 → \rightarrow →网络适配器 → \rightarrow →在高级选项中生成新的mac地址
- Slave1:00:50:56:22:A3:94
- Slave2:00:50:56:28:28:D9
-
按照上面的方法配置静态ip,分别为
- Master:172.16.227.129
- Slave1:172.16.227.130
- Slave2:172.16.227.131
-
修改主机名、ip映射
sudo vim /etc/hostnamesudo vim /etc/hosts
-
使用ssh将公钥分发,
ssh-copy-id master- 注意:每个机器都要分发
-
修改配置文件,在hadoop根目录下
/etc/hadoop下- 可以根据自己的需求进行修改
-
集群规划如下
-
分别修改一下内容
-
core-site.xml
-
<configuration> <!-- 指定NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://master:8020</value> </property> <!-- 指定hadoop数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.1.3/data</value> </property> <!-- 配置HDFS网页登录使用的静态用户为shuaikai --> <property> <name>hadoop.http.staticuser.user</name> <value>shuaikai</value> </property> </configuration> -
hdfs-site.xml
-
<configuration> <!-- nn web端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>master:9870</value> </property> <!-- 2nn web端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>slave2:9868</value> </property> </configuration> -
yarn-site.xml
-
<configuration> <!-- 指定MR走shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>slave1</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <!-- 开启日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志聚集服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://master:19888/jobhistory/logs</value> </property> <!-- 设置日志保留时间为7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration> -
mapred-site.xml
-
<configuration> <!-- 指定MapReduce程序运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration>
-
-
创建分发命令xsync
-
sudo vim /home/usr/bin/xsync -
# 编写以下内容: #!/bin/bash #1. 判断参数个数 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. 遍历集群所有机器 for host in master slave1 slave2 do echo ==================== $host ==================== #3. 遍历所有目录,挨个发送 for file in $@ do #4. 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前文件的名称 fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done -
设置权限
sudo chmod 777 xsync -
更新
source ~/.profile -
注:亦可将上述内容编写在某固定文件夹下,并将该文件夹添加入环境变量
~/.profile,并更新环境变量
-
-
在集群上分发
xsync $HADOOP_HOME/etc/hadoop -
配置hadoop环境变量,路径如上所示
-
export HADOOP_HOME=本机的hadoop安装路径 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
-
-
debug:过高版本jdk导致的bug,cannot set priority of nodemanger&resourcemanager process
-
原因:查看日志文件后发现有一个java.lang相关的调用失败,搜索后发现是高版本jdk导致的bug,同时该文也指出
hive3.x仅支持jdk1.8(即低版本),遂决定降低版本 -
步骤如下
-
安装jdk:运行命令
apt install openjdk-8-jdk -
配置环境变量
/etc/environment、~/.bashrc -
配置hadoop环境变量
/etc/hadoop/hadoop-env.sh,修改java版本 -
xsync分发文件,source更新系统配置 -
若已经启动过,则需重新执行
hdfs namenode -format
-
-
-
执行命令
hdfs namenode -format -
执行命令
start-dfs.sh- 调用
jps查看进程 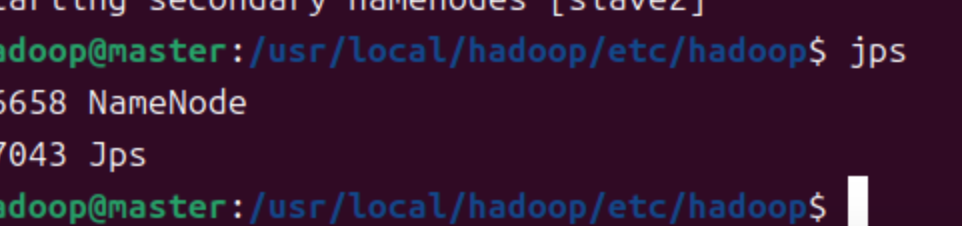
- 调用
-
slave1执行命令
start-yarn.sh- 调用
jps查看进程 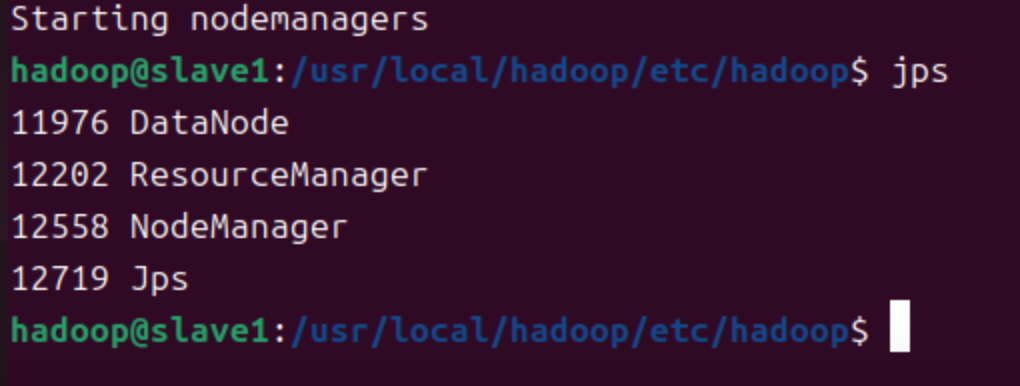
- 调用

2. 技术概论
hive的情况在上周已经讨论,这周主要讨论如何使用idea等开发工具链接在本地部署的hadoop集群。
2.1 hadoop链接至idea
对于hadoop集群,若要链接hadoop,则需要配置idea的插件——big data tools。进行如下配置
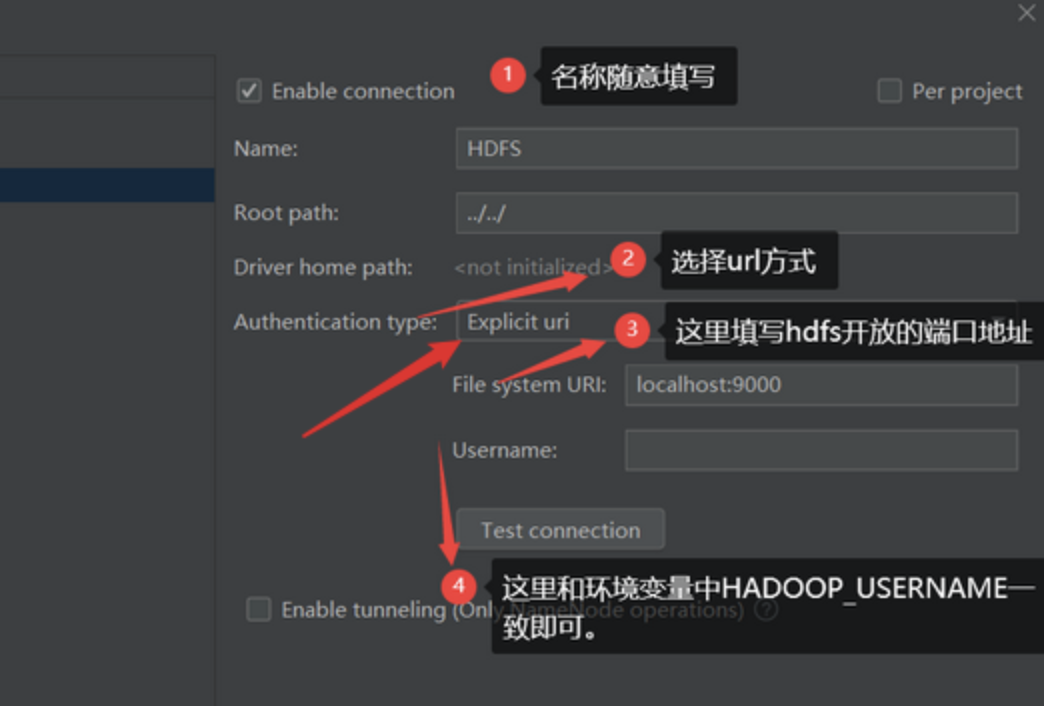
2.2 使用idea操作
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount {
// 定义一个Mapper类,用于将输入的数据分割成单词,并为每个单词分配一个计数值1。
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
// 创建一个常量IntWritable对象,值为1,用于在map函数中使用。
private final static IntWritable one = new IntWritable(1);
// 创建一个Text对象,用于存储单词。
private Text word = new Text();
// 实现map方法,该方法接收输入键值对(key, value),并产生输出键值对(word, 1)。
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 使用StringTokenizer来分割输入的Text对象,根据空格分割成单词。
StringTokenizer itr = new StringTokenizer(value.toString());
// 循环遍历每一个单词。
while (itr.hasMoreTokens()) {
// 设置当前单词。
word.set(itr.nextToken());
// 将单词及其计数值1写入上下文(context),传递给reducer。
context.write(word, one);
}
}
}
// 定义一个Reducer类,用于汇总各个Mapper产生的中间结果。
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// 创建一个IntWritable对象,用于存储最终的单词计数值。
private IntWritable result = new IntWritable();
// 实现reduce方法,该方法接收输入键值对(key, values),并产生输出键值对(word, sum)。
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 初始化计数值sum为0。
int sum = 0;
// 遍历所有的IntWritable对象,累加它们的值。
for (IntWritable val : values) {
sum += val.get();
}
// 设置result对象的值为sum。
result.set(sum);
// 将单词及其计数值写入上下文(context),输出最终结果。
context.write(key, result);
}
}
// 主方法,启动MapReduce作业。
public static void main(String[] args) throws Exception {
// 创建一个新的Configuration对象,用于配置作业。
Configuration conf = new Configuration();
// 创建一个新的Job实例,并设置作业的名称。
Job job = Job.getInstance(conf, "word count");
// 设置作业使用的jar包类。
job.setJarByClass(WordCount.class);
// 设置Mapper类。
job.setMapperClass(TokenizerMapper.class);
// 设置Combiner类,用于在Reducer之前对中间结果进行局部聚合。
job.setCombinerClass(IntSumReducer.class);
// 设置Reducer类。
job.setReducerClass(IntSumReducer.class);
// 设置作业输出键值对的类型。
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入路径。
FileInputFormat.addInputPath(job, new Path(args[0]));
// 设置输出路径。
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 执行作业,并等待其完成。
// 如果作业成功完成,退出码为0;否则为1。
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
2.3 hive与hbase的对比
Hive 和 HBase 是 Hadoop 生态系统中两个重要的组件,它们各自解决了大数据处理中的不同问题。下面是Hive与HBase之间的对比:
1. 设计目标
- Hive:设计目的是为了提供一个类似SQL的查询语言(HiveQL),使得用户能够方便地进行数据查询和分析。Hive主要用于批处理和离线数据分析,它将SQL查询转换为MapReduce任务来处理大规模数据集。
- HBase:设计目的是为了提供一个可伸缩、高性能的分布式数据库,它支持实时读写访问。HBase借鉴了Google Bigtable的设计理念,能够处理海量数据,并提供低延迟的随机访问。
2. 数据存储
- Hive:数据存储在HDFS上,以文本文件的形式(默认为TextFile,也可使用SequenceFile、ORC等格式)。Hive支持结构化数据,并且数据可以被分区和桶化,以优化查询性能。
- HBase:数据存储在HDFS上,以列族(column family)的形式组织。每个表由行键(row key)、列族、列标识符(column qualifier)和时间戳组成。HBase支持非结构化数据,并且数据可以被水平切分(sharding)以支持水平扩展。
3. 查询与处理
- Hive:使用HiveQL进行查询,这是一种类似于SQL的查询语言。HiveQL查询会被转换为MapReduce作业来执行,这意味着查询执行可能相对较慢,尤其是在处理大量数据时。
- HBase:使用客户端API进行数据的读写操作,不支持SQL查询。HBase提供了对数据的随机访问能力,并且支持简单的过滤器和扫描器(scanner)来执行查询。
4. 扩展性
- Hive:支持水平扩展,可以通过添加更多的节点来增加处理能力。但是,由于Hive依赖于MapReduce,其查询性能受限于MapReduce的执行速度。
- HBase:同样支持水平扩展,通过分区(Region)和负载均衡机制来支持大规模数据的分布存储和处理。
5. 数据一致性与事务
- Hive:不支持ACID特性,即不支持原子性、一致性、隔离性和持久性。Hive更适合于数据仓库场景,主要用于批量处理和分析,不适用于需要强一致性的应用。
- HBase:支持某种程度的一致性,每个单元格的写操作是原子的。虽然HBase不支持复杂的事务处理,但它提供了基于行的原子操作。
6. 数据访问模式
- Hive:适用于批处理场景,例如数据汇总、报告生成等。Hive不擅长实时查询和更新操作。
- HBase:适用于需要实时查询和更新的应用场景,例如在线服务、日志分析、物联网数据存储等。
7. 应用场景
- Hive:适用于离线数据处理和分析,如数据仓库、数据湖等。Hive适用于需要执行复杂查询和分析的场景。
- HBase:适用于需要实时读写访问的应用场景,如社交网络、广告系统、实时监控等。HBase适用于需要高性能随机访问的场景。
总结
- Hive 主要用于离线数据分析,提供类SQL查询能力,适合于批处理和数据仓库场景。
- HBase 提供实时读写访问能力,适用于需要低延迟随机访问的场景。
在实际应用中,Hive和HBase常常结合使用,Hive用于处理和清洗数据,而HBase用于存储和实时查询处理后的数据。这种组合可以发挥两者的优势,满足不同场景下的需求。
综上所述,hive提供了类sql查询能力,便于在后续进行离线的数据分析以将数据预处理后用于神经网络处理。是否使用视情况而定
二、文献阅读
1. 题目
标题:Ha-gnn: a novel graph neural network based on hyperbolic attention
作者:Hongbo Qu, Yu-Rong Song, Minglei Zhang, Guo-Ping Jiang, Ruqi Li, Bo Song
发布:neural computing and applications
链接:https://doi.org/10.1016/j.knosys.2024.112107
2. Abstract
双曲图神经网络(hgnn)通过将图嵌入到双曲空间来解决这一限制,可以更好地捕获网络的层次结构。然而,在训练过程中,hgnn往往涉及复杂的双曲空间或其切线空间的计算,这可能会阻碍其效率。在本文中,提出了双曲注意图神经网络(HA-GNN),它可以有效地利用网络结构和节点特征进行图表示学习。具体来说,设计了一个结构属性注意机制,该机制基于节点之间的双曲嵌入来测量节点之间的结构连接。还设计了一个节点特征关注机制来量化节点之间的特征相似度。然后,将这两个注意结合起来,得到一个双曲注意,该双曲注意对所有连接节点之间的相关性进行加权。在五个现实世界的网络上进行了广泛的实验,并证明的模型始终显著优于其他最先进的方法。例如,在Cora网络上,的模型在节点分类任务上达到了83.1(±0.4)的准确率,比欧氏空间中最好的基线方法提高了1.6%。
3. 文献解读
3.1 Introduce
传统GNNs由于在欧几里得空间中操作,可能无法充分保留现实世界网络的自相似性和层次性特征。为了解决这一问题,本文提出了一种新的模型——双曲注意力图神经网络(HA-GNN),它能够在保持高效的同时,利用网络结构和节点特征进行图表示学习。HA-GNN通过设计结构属性注意机制来衡量基于节点双曲嵌入的结构连接,并通过节点特征注意机制来量化节点间的特征相似度,然后结合这两种注意力机制形成双曲注意力,用于加权所有相连节点的相关性。实验结果表明,HA-GNN在Cora网络上的节点分类任务中,准确率达到了83.1%,比最佳的欧几里得空间基线方法高出1.6%。
此外,虽然超曲面图神经网络(HGNNs)能够更好地捕捉网络的层次结构,但其在训练过程中复杂的双曲空间计算可能影响效率。HA-GNN通过引入双曲注意力机制解决了这一问题。
3.2 创新点
主要贡献如下
- 提出了HA-GNN,一种新的双曲注意力图神经网络,该模型首次将网络映射到H2模型以收集丰富的网络结构信息,并同时使用自注意力机制来捕捉节点特征信息。
- 设计了双曲注意力机制来结合结构属性注意和节点特征注意,为不同节点对指定相关权重。
- 探讨了不同比例的NF注意和SP注意在双曲注意力上对不同网络的有效性。
4. 网络框架
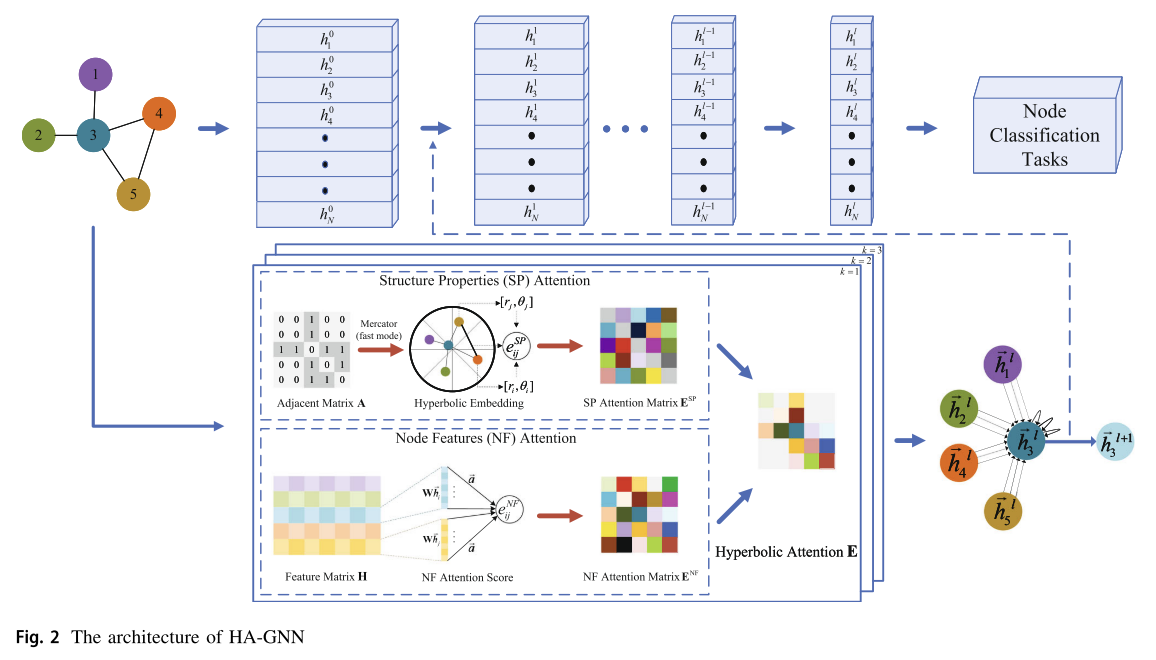
图2显示了Ha-gnn的整体架构。对于网络 G = ( V , E ) G=(V,E) G=(V,E),其中节点 i ∈ V i\in V i∈V,边 e i j ∈ E e_{ij}\in E eij∈E, N = ∣ V ∣ N=|V| N=∣V∣表示G中的节点数量,构造两个矩阵成为邻接矩阵 A ∈ R N × N A\in \mathbb R^{N\times N} A∈RN×N、特征矩阵 H ∈ R N × F H\in \mathbb R^{N\times F} H∈RN×F。邻接矩阵A表示G的拓扑结构信息,元素aij在表明如果有两个节点i和j之间的直接路径。如果是这样令 a i j = 1 a_{ij}=1 aij=1,如果令 a i j = 0 a_{ij}=0 aij=0。因此,对于无向网络,其邻矩阵A是对称矩阵。节点特征矩阵H包含所有节点特征信息, H = { h 1 , h 2 , . . . , h N } T \mathbf H=\{\mathbf h_1,\mathbf h_2,...,\mathbf h_N\}^{\text T} H={h1,h2,...,hN}T,其中 h i h_i hi为节点i的特征,F为每个节点特征的维数。对于节点分类任务,给定G中的一些节点标签,目标是基于对节点特征和网络拓扑结构的了解,预测剩余节点的标签。HA-GNN以G为输入,学习节点表示,然后输出节点的预测标签。
消息传递神经网络(message passing neural networks, MPNNs)作为gnn的主流框架,具有易于理解和高效的图表示学习能力,是基于MPNNs的HA-GNN的整体框架。mpnn由两个部分组成,即消息传递和读出。考虑到只解决节点级任务,将只讨论消息传递部分的细节。在mpnn中,节点特征被视为消息,消息传递过程包括传递节点特征的表示。图2顶部显示了节点特征传递过程的层次和表示。对于节点分类任务,gnn实际上是将邻居的节点表示传递给源节点表示并更新源节点表示,最终预测节点标签。HA-GNN的消息传递部分描述为:
h
i
l
+
1
=
σ
(
∑
j
∈
N
~
(
i
)
(
e
i
j
l
+
1
W
l
+
1
h
j
l
)
)
(6)
\mathbb h^{l+1}_i=\sigma(\sum_{j\in \tilde {\mathcal N}(i)}(e^{l+1}_{ij}\mathbf W^{l+1}\mathbf h^l_j))\tag{6}
hil+1=σ(j∈N~(i)∑(eijl+1Wl+1hjl))(6)
注意节点I和节点j在l + 1层。双曲注意力的计算流程如图2下半部分所示。其中有三个关键组成部分,即:(1)基于相邻矩阵的结构属性(SP)注意力计算,(2)基于特征矩阵的节点特征(NF)注意力计算,以及(3)结合上述两种注意力的双曲注意力计算。下面将介绍每个组件的详细信息。
为了提高HA-GNN的能力,考虑了HA-GNN的多头注意机制,可以表示为:
h
i
l
+
1
=
∣
∣
k
=
1
K
σ
(
∑
j
∈
N
~
(
i
)
e
k
i
j
l
+
1
W
k
l
+
1
h
j
l
)
(7)
\mathbf h^{l+1}_i=||^K_{k=1}\sigma(\sum_{j\in \tilde{\mathcal N}(i)}e^{l+1}_{k_{ij}}\mathbf W_k^{l+1}\mathbf h_j^l)\tag{7}
hil+1=∣∣k=1Kσ(j∈N~(i)∑ekijl+1Wkl+1hjl)(7)
4.1 注意力机制的结构特性
首先,基于图G的拓扑构造邻接矩阵A,然后以A为输入,使用墨卡托(快速模式)将G嵌入到H2模型中。嵌入过程在3.2节中描述。嵌入后,每个节点有一个双曲坐标 c i [ r i , θ i ] c_i[r_i,\theta_i] ci[ri,θi]。
其次,计算双曲距离
d
i
s
t
(
c
i
,
c
j
)
dist(c_i,c_j)
dist(ci,cj)。双曲空间可以隐式表达两两节点之间结构相似性的相关性。如果两个节点之间的距离较近,说明它们之间的连接较强,它们之间的权重应该较高,反之亦然。因此,取
d
i
s
t
(
c
i
,
c
j
)
dist(c_i,c_j)
dist(ci,cj)的逆表示节点对之间的重要性,得到
d
i
j
d_{ij}
dij如下:
d
i
j
=
1
d
i
s
t
(
c
i
,
c
j
)
(
i
≠
j
)
(8)
d_{ij}=\frac1{dist(c_i,c_j)}(i\neq j)\tag{8}
dij=dist(ci,cj)1(i=j)(8)
使用
d
i
j
=
1
(
i
=
j
)
d_{ij}=1(i=j)
dij=1(i=j)以确保可以聚合自身特征
映射
d
i
j
d_{ij}
dij以获取SP注意力
e
i
j
S
P
e^{SP}_{ij}
eijSP,映射函数如下:
f
l
:
d
i
j
→
e
i
j
S
P
(9)
f^l:d_{ij}\rightarrow e^{SP}_{ij}\tag{9}
fl:dij→eijSP(9)
使用多层感知机(MLP)作为
f
t
f^t
ft,因为MLP是一种通用近似机,可以很容易地设计到模型中进行端到端训练。为了防止数值爆炸,将softmax函数S应用于节点i的所有邻居的
MLP
(
d
i
j
)
\text{MLP}(d_{ij})
MLP(dij),包括它自己,
j
∈
N
~
(
i
)
j\in \tilde{\mathcal N}(i)
j∈N~(i)。map函数可表示为:
e
i
j
S
P
=
S
(
MLP
(
d
i
j
)
)
(10)
e^{SP}_{ij}=S(\text{MLP}(d_{ij}))\tag{10}
eijSP=S(MLP(dij))(10)
MLP有三层:输入层、非线性转换层和输出层。输入层In将
d
i
j
d_{ij}
dij转换为与消息
M
j
→
i
l
M_{j\rightarrow i}^l
Mj→il大小相同的输出层。非线性转换层使用LeakyReLU函数。输出层Out使用一个变换矩阵来计算重称重向量。在形式上,
M
L
P
=
O
u
t
(
L
e
a
k
y
R
e
L
U
(
I
n
)
)
(11)
MLP=Out(LeakyReLU(In))\tag{11}
MLP=Out(LeakyReLU(In))(11)
最后,计算所有节点对SP注意力
e
i
j
S
P
e^{SP}_{ij}
eijSP,得到SP注意力矩阵
E
S
P
∈
R
N
×
N
E^{SP}\in\mathbb R^{N\times N}
ESP∈RN×N
4.2 节点特征注意力
下面,将介绍NF注意力的计算过程。该步骤的流程图如图2的下半部分所示,其灵感来源于。该模块的输入为节点特征矩阵 H = { h 1 , h 2 , . . . , h N } T , h i ∈ R F H=\{h_1,h_2,...,h_N\}^T,h_i\in \mathbb R^F H={h1,h2,...,hN}T,hi∈RF,其中hi为节点i的特征向量,N为G中的节点数量,F为hi的维数。
为了将原始特征转换为高级特征,每个节点通过共享权矩阵
W
∈
R
F
×
F
W\in \mathbb R^{F\times F}
W∈RF×F更新其特征,其中F’为节点高级特征的维数。然后,使用自注意机制a来计算两两节点之间的注意得分。a是一个单层前馈神经网络,由一个加权向量
a
∈
R
2
F
′
a\in \mathbb R^{2F'}
a∈R2F′参数化。由此,可以得到i和j两个节点之间的节点特征关注值:
e
i
j
N
F
=
a
T
[
W
h
i
∣
∣
W
h
j
]
(12)
e^{NF}_{ij}=a^T[Wh_i||Wh_j]\tag{12}
eijNF=aT[Whi∣∣Whj](12)
在计算节点对之间所有的NF注意值
e
i
j
N
F
e^{NF}_{ij}
eijNF后,可以构造NF注意矩阵
E
N
F
∈
R
N
×
N
E^{NF} \in \mathbb R^{N\times N}
ENF∈RN×N。
4.3 双曲注意力
在构造了SP注意矩阵 E S P E^{SP} ESP和NF注意矩阵 E N F E^{NF} ENF之后,需要将它们融合在一起得到双曲注意E。
首先,需要对
E
S
P
E^{SP}
ESP和
E
N
F
E^{NF}
ENF进行掩码关注,将网络拓扑结构考虑为:
E
^
S
P
=
L
⊙
E
S
P
(13)
\hat{\mathbf E}^{SP}=L\odot \mathbf E^{SP}\tag{13}
E^SP=L⊙ESP(13)
E ^ N F = L ⊙ E N F (14) \hat{\mathbf E}^{NF}=L\odot E^{NF}\tag{14} E^NF=L⊙ENF(14)
节点i的度是
D
i
=
∑
j
a
i
j
(15)
D_i=\sum_j a_{ij}\tag{15}
Di=j∑aij(15)
然后,为了评估
E
^
S
P
\hat E^{SP}
E^SP和
E
^
N
F
\hat E^{NF}
E^NF之间不同比例的影响,首先使用softmax函数对j的所有值进行归一化,并使用加权平均来融合SP注意和NF注意。整个过程如下:
E
=
α
⋅
softmax
(
E
^
S
P
)
+
β
⋅
softmax
(
E
^
N
F
)
=
α
⋅
exp
(
e
^
i
S
P
j
)
∑
k
=
1
N
exp
(
e
^
i
k
S
P
)
+
β
exp
(
e
^
i
j
N
F
)
∑
k
=
1
N
exp
(
e
^
i
N
F
k
)
(16)
\begin{aligned} E&=\alpha\cdot \text{softmax}(\hat E^{SP})+\beta\cdot \text{softmax}(\hat E^{NF}) \\&=\alpha\cdot \frac{\text{exp}(\hat e^{SP}_ij)}{\sum^{N}_{k=1}\text{exp}(\hat e^{SP}_{ik})}+\beta\frac{\text{exp}(\hat e_{ij}^{NF})}{\sum_{k=1}^N\text{exp}(\hat e^{NF}_ik)} \end{aligned}\tag{16}
E=α⋅softmax(E^SP)+β⋅softmax(E^NF)=α⋅∑k=1Nexp(e^ikSP)exp(e^iSPj)+β∑k=1Nexp(e^iNFk)exp(e^ijNF)(16)
最后,HA-GNN的消息传递可以表示为
h
i
l
+
1
=
σ
(
∑
j
∈
N
^
(
i
)
e
i
j
l
+
1
W
l
+
1
h
j
l
)
(17)
h^{l+1}_i=\sigma(\sum_{j\in \hat {\mathcal N}(i)}e^{l+1}_{ij}W^{l+1}h_j^l)\tag{17}
hil+1=σ(j∈N^(i)∑eijl+1Wl+1hjl)(17)
可以得到I在1 + 1层的表示。
为了增强表征能力,还扩展了消息传递部分,采用多头注意机制来获得hi:
h
i
l
+
1
=
σ
(
1
K
∑
k
=
1
K
∑
j
∈
N
^
(
i
)
(
e
k
i
j
l
+
1
W
k
l
+
1
h
j
l
)
)
(18)
\mathbf h^{l+1}_i=\sigma(\frac1K\sum_{k=1}^K\sum_{j\in \hat{\mathcal N}(i)}(e^{l+1}_{k_{ij}}\mathbf W^{l+1}_k\mathbf h^l_j))\tag{18}
hil+1=σ(K1k=1∑Kj∈N^(i)∑(ekijl+1Wkl+1hjl))(18)
采用平均值来聚合多头注意机制的结果
现有的大多数使用注意机制进行图表示学习的方法只考虑欧几里得空间,这可能不适合具有非欧几里得性质的图。因此,设计了双曲注意机制,该机制可以考虑双曲距离度量和节点特征信息,从而提高模型的准确性和鲁棒性。
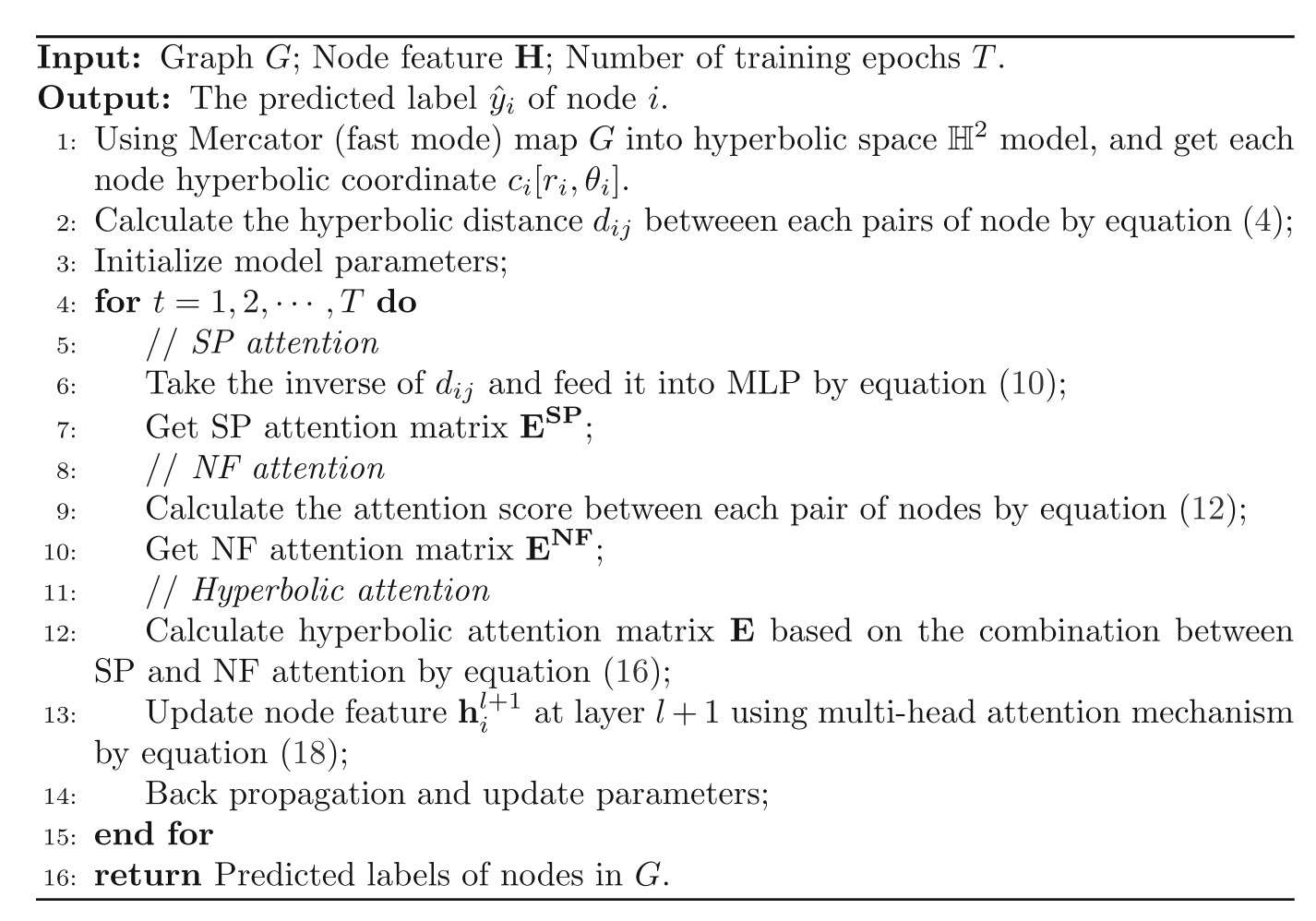
算法1介绍了HA-GNN的整个过程。在消息传递之后,节点的最终表示可用于解决不同的任务,例如节点分类、链接预测等。在本文中,使用节点分类任务来衡量HA-GNN的性能,正如之前讨论的那样。
I
n
p
u
t
:图
G
;节点特征
H
;训练轮数
T
。
O
u
t
p
u
t
:节点
i
的预测标签
y
^
i
。
使用
M
e
r
c
a
t
o
r
(快速模式)将
G
映射到双曲空间
H
2
模型,并获取每个节点的双曲坐标
c
i
[
r
i
,
t
h
e
t
a
i
]
.
计算每对节点之间的双曲距离
d
i
j
.
初始化模型参数
.
在训练过程中,对于每一轮
t
=
1
,
2
,
.
.
.
,
T
,我们进行如下操作:
/
/
S
P
注意力
取
d
i
j
的倒数,并按方程(
10
)馈入多层感知机,得到
S
P
注意力矩阵
E
S
P
.
/
/
N
F
注意力
计算每对节点之间的注意力分数,按方程(
12
),得到
N
F
注意力矩阵
E
N
F
.
/
/
双曲注意力
根据
S
P
和
N
F
注意力的结合,按方程(
16
)计算双曲注意力矩阵
E
.
使用多头注意力机制,按方程(
18
)更新
l
+
1
层的节点特征
h
i
l
+
1
.
反向传播并更新参数
.
return 图的双曲注意力网络
\begin{array}{l} Input:图 G;节点特征 H;训练轮数 T。\\ Output:节点 i 的预测标签 \hat y_i。\\ 使用 Mercator(快速模式)将 G 映射到双曲空间 H^2 模型,并获取每个节点的双曲坐标 c_i[r_i, theta_i]. \\ 计算每对节点之间的双曲距离 d_ij. \\ 初始化模型参数. \\ 在训练过程中,对于每一轮 t=1, 2, ..., T,我们进行如下操作:\\ \quad // SP 注意力\\ \quad 取 d_{ij} 的倒数,并按方程(10)馈入多层感知机,得到 SP 注意力矩阵 E^{SP}. \\ \quad // NF 注意力\\ \quad 计算每对节点之间的注意力分数,按方程(12),得到 NF 注意力矩阵 E^{NF}. \\ \quad // 双曲注意力\\ \quad 根据 SP 和 NF 注意力的结合,按方程(16)计算双曲注意力矩阵 E. \\ \quad 使用多头注意力机制,按方程(18)更新 l+1 层的节点特征 h_i^{l+1}. \\ \quad 反向传播并更新参数. \\ \text{return}\ 图的双曲注意力网络 \end{array}
Input:图G;节点特征H;训练轮数T。Output:节点i的预测标签y^i。使用Mercator(快速模式)将G映射到双曲空间H2模型,并获取每个节点的双曲坐标ci[ri,thetai].计算每对节点之间的双曲距离dij.初始化模型参数.在训练过程中,对于每一轮t=1,2,...,T,我们进行如下操作://SP注意力取dij的倒数,并按方程(10)馈入多层感知机,得到SP注意力矩阵ESP.//NF注意力计算每对节点之间的注意力分数,按方程(12),得到NF注意力矩阵ENF.//双曲注意力根据SP和NF注意力的结合,按方程(16)计算双曲注意力矩阵E.使用多头注意力机制,按方程(18)更新l+1层的节点特征hil+1.反向传播并更新参数.return 图的双曲注意力网络
4.4 复杂度分析
HA-GNN的时空复杂性具有可扩展性和高效性,因为它只将图结构映射到双曲空间一次,并使用注意机制捕获节点特征和结构属性。与其他hgnn相比,HA-GNN的复杂度较低,因为它避免了训练时在双曲空间或其切线空间进行复杂的计算。实验结果表明,HA-GNN在各种数据集上都优于其他最先进的方法。
5. 实验过程
数据集:
在五个具有不同结构的现实世界网络上评估了HA-GNN,并基于节点分类任务将其与各种浅网络、网络嵌入、欧几里得空间GNN和双曲空间基线GNN进行了性能比较。进一步将Cora数据集上的节点分类结果可视化,以说明双曲嵌入如何捕获许多现实世界网络的结构属性,并证明模型的优越性。此外,还对注意机制进行了详细的分析,以证明其有效性。
数据描述:
对于节点分类任务,使用了几个开放的网络数据集,包括引文网络数据集(Cora[45]、CiteSeer[32]和PubMed[46])和合著者网络数据集(CS和Physics[47])。在引文网络数据集中,每个节点代表一篇论文,每个边代表一个引文关系。每篇论文都有一个称为节点标签的标签和一个称为节点特征的词袋表示。在合著者网络数据集中,节点代表作者,如果他们合著了一篇论文,则边缘将它们连接起来。每个节点的特征是每个作者论文的索引项,标签是作者工作的区域。
基线:
将HA-GNN与一些最先进的模型进行了比较,例如网络嵌入模型(Deepwalk, Node2vec),欧几里得空间的gnn (GCN, GAT, GraphSAINT, CGNN)和双曲空间的gnn (HGNN, HGCN, ACE-HGNN, HAT, jHGCN)。以上方法的具体内容如下:
- Deepwalk[48]使用短随机行走来更新欧几里得空间中图节点的表示。
- Node2vec[49]使用了Deepwalk提出的一些想法,但更深入一步。它使用不同的算法来提取随机游动,以获得更好的性能。
- GCN [32] (Graph convolutional networks)是一种基于欧几里得空间的谱的GNN模型,它使用基于节点度的卷积运算来聚合节点表示。
- GAT [31] (Graph attention networks)是一种基于欧几里得空间的GNN模型。与GCN不同的是,它在消息传递部分加入了注意机制来衡量两个节点之间的重要性。
- GraphSAINT [50] (Graph sampling based inductive learning)是一种基于图采样的半监督GNN。它从完整的图中抽取子图,然后使用GCN对子图进行训练。
- CGNN [51] (Curvature graph neural networks)是一种基于图曲率的半监督GNN。它利用图曲率的结构特性,有效地增强了gnn的自适应局域能力。
- 双曲图神经网络(Hyperbolic graph neural networks, HGNN)[34]是双曲空间中的半监督GNN。它学习黎曼流形上的节点表示。
- HGCN [26] (Hyperbolic graph convolution networks,双曲图卷积网络)是双曲空间中的半监督GNN。它在双曲模型中导出GCN运算,并基于指数和对数映射进行计算。
- ACE-HGNN [35] (Adaptive curvature exploration hyperbolic graph neural networks)是一种基于HGCN的改进算法。不同的是,ACEHGNN可以通过强化学习来学习双曲空间中的最优曲率。
- HAT [36] (Hyperbolic graph attention networks,双曲图注意网络)将图注意机制引入双曲空间,可以更好地学习图的节点表示。
- KHGCN25在gnn中引入曲率来控制消息传递并改善远程传播。
实现细节:
将所有模型的实验嵌入维数设置为32。对于网络嵌入方法(DeepWalk和Node2vec),将窗口大小设置为5,每次行走的长度设置为80,并在Node2vec中选择0.5,1,1.5中的p和q。对于gnn模型,将层数设置为L¼2,辍学率设置为dropout¼0:6,Adam SGD优化器中使用的学习率lr范围为1e-4至5e-4。对于使用注意机制的模型(如GAT、HAT和模型HA-GNN),将每个注意头的维度设置为8,注意头的数量设置为4,这与其他方法的嵌入维度相似。对于GraphSAINT,需要首先修改它的采样器。具体来说,首先随机选择少量有标签的节点,并选择它们的邻居作为样本,而不是从整个网络中选择节点。对于CGNN,选择CGNN_Linear_Sym作为基线,在特征学习中采用线性变换和对称归一化操作。对于基于双曲空间的模型(即HGNN, HGCN, ACE-HGNN, HAT),设置曲率f¼1。此外,所有gnn都以150的耐心利用提前停止策略。
实验结果:
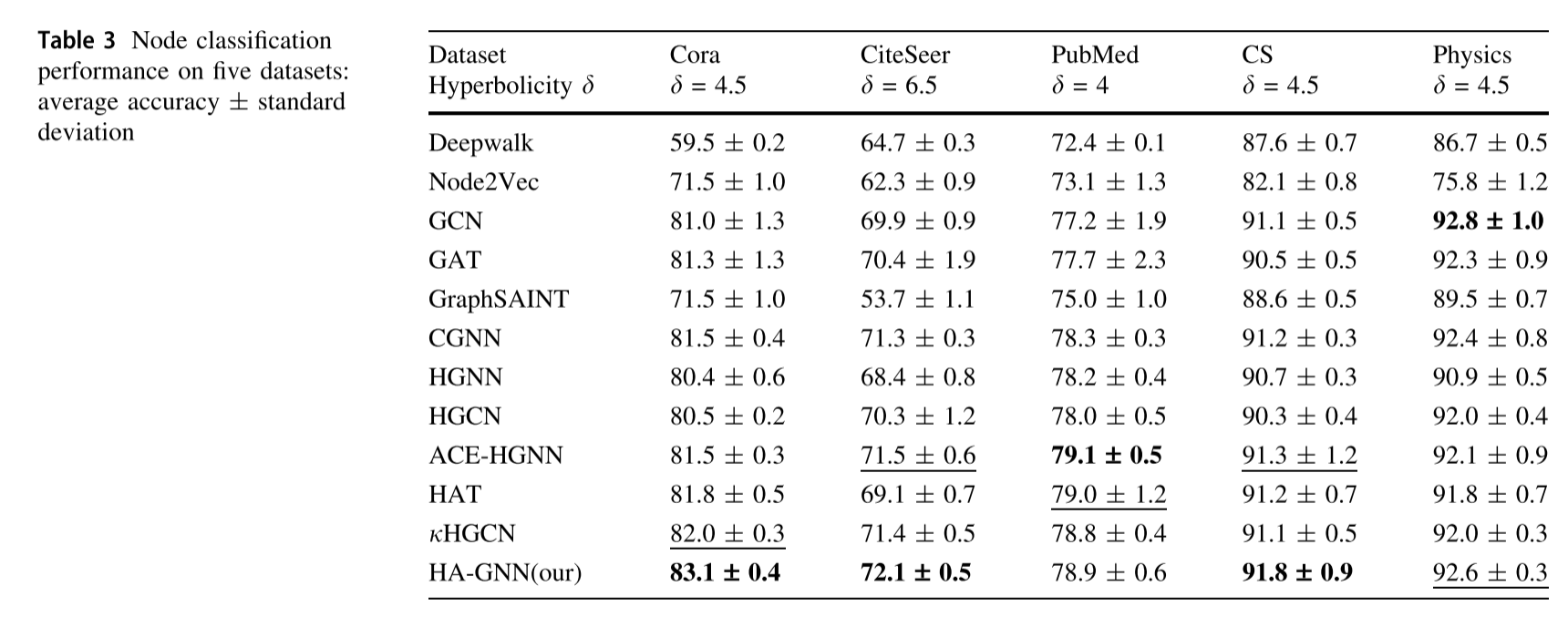
从表3可以看出,双曲空间中的gnn明显优于欧几里得空间和网络嵌入模型中的gnn。此外,模型HA-GNN在三个数据集(Cora, CiteSeer和CS)上实现了最佳性能,并且在其余两个数据集(PubMed和Physics)上与其他模型具有竞争力。从网络双曲性的角度来分析结果,网络双曲性量化了图的树似性。较低的双曲度d意味着图形更像树,并且具有潜在的双曲几何,这意味着将其嵌入双曲空间会导致较低的失真。
6.结论
在本研究中,引入了一种新的双曲图神经网络HA-GNN,它可以利用网络结构和节点特征在双曲空间中进行图表示学习。通过引入双曲注意,HA-GNN可以同时学习丰富的网络结构属性和节点特征信息。具体而言,首先将网络嵌入到双曲空间H2模型中,学习网络结构属性信息并计算SP关注。然后利用自注意机制学习欧几里得空间中的节点特征信息,计算NF注意。最后,计算双曲注意力,将NF和SP注意力结合起来,更好地权衡节点对之间的关系,从而更好地表示节点的表示。在五个真实网络上的大量实验表明,HA-GNN与其他方法相比具有优势。















 6691
6691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









