






文章目录
week55 GL-GNN
摘要
本周阅读了题为GL-GNN: Graph learning via the network ofgraphs的论文。本文提出了GL-GNN模型,它能够从零开始构建图结构或优化现有图结构,从而拓展了GNN(图神经网络)的应用范围,使其能够应对图数据不可用或含有噪声边缘的情况。GL-GNN通过集成多个子模块,从多个维度对图进行学习,其中特别引入了选择向量来捕捉关键特征。为了验证GL-GNN的有效性,我们在图形学习和精炼的多个场景下进行了全面的实验。此外,还设计了专门的“笑容实验”来进一步验证其关键设计。实验结果表明,在图的学习和精炼场景中,GL-GNN均展现出了优于当前最先进GNN的性能。
Abstract
This week’s weekly newspaper decodes the paper entitled Failure Prediction for Large-scale Water Pipe Networks Using GNN and Temporal Failure Series. This paper proposes GL-GNN, which can learn graphs from scratch or refine available graphs, thereby extending the application scenarios of GNNs to cases where graphs are unavailable or contain noisy edges. GL-GNN employs multiple submodules to learn graphs from different aspects, with selection vectors used to learn key features. Comprehensive experiments are conducted in scenarios involving graph learning and refinement to evaluate the effectiveness of GL-GNN. Further smile experiments are performed to validate its key design. The results show that the proposed GL-GNN outperforms relevant state-of-the-art GNNs in both graph learning and refinement scenarios.
一、大数据相关
1. 配置hadoop(单机)
-
下载文件,在如下链接,根据自身需求进行下载hadoop-3.4.0,aarch64为arm版本
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.4.0/
-
将已经下载好的文件移动至vmware窗口上,上传至虚拟机
- 默认的上传地址为tmp/VMwareDnD
-
该链接下执行如下命令,文件名称根据自己下载的配置
sudo tar -zxf ./hadoop-3.3.5.tar.gz -C /usr/local
-
修改文件名称为hadoop
cd /usr/localsudo mv ./xxx ./hadoop
-
赋予可执行权限
sudo chown -R hadoop ./hadoop
-
查看安装信息
-
cd ./hadoop ./bin/hadoop version
-
-
运行实例
-
新建input子目录
sudo mkdir input -
复制 “/usr/local/hadoop/etc/hadoop” 中的配置文件到 input 目录下:
sudo cp ./etc/hadoop/*.xml ./input -
运行grep实例:
./bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep ./input ./output 'dfs[a-z.]+'- 注意修改文件名称
-
查看运行结果
cd ./outputls- 结果如下
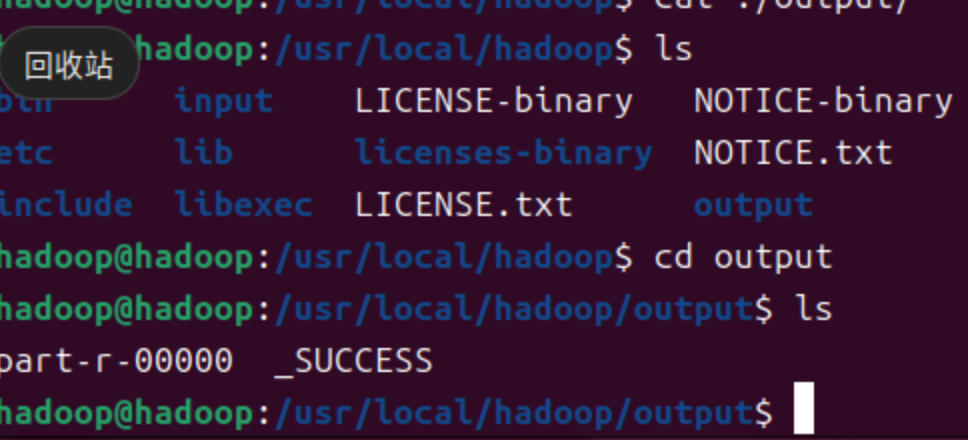
-
2. MPI与hadoop的区别
- Hadoop与MPI的主要区别体现在数据存储和数据处理在系统中位置不同。
MPI是计算与存储分离,Hadoop是计算向存储迁移。这一点体现出,hadoop系统中数据存储的位置更重要。
MPI是一种基于消息传递机制的并行编程标准,它为程序设计者提供了丰富而方便的通信函数,在程序设计上非常简单而且符合普通程序员的编程习惯。然而MPI有一个比较大的缺陷,即底层没有一个分布式的文件系统对其进行支持。在MPI中数据存储的节点和数据处理的节点往往是不同的,一般在每次计算开始时MPI需要从数据存储节点读取需要处理的数据分配给各个计算节点,然后进行数据处理,即MPI的数据存储和数据处理是分离的。对于计算密集型的应用MPI能表现出良好的性能,但对于处理TB级数据的数据密集型应用,大量的数据在节点间进行交换,网络通信时间将成为影响系统性能的重要因素,性能会大大降低。用“计算换通信”也是MPI并行程序设计中的基本原则 。
在Hadoop中有HDFS文件系统的支持,数据是分布式存储在各个节点的,计算时各节点读取存储在自己节点的数据进行处理,从而避免了大量数据在网络上的传输,实现“计算向存储的迁移”。这对处理TB级的海量数据有很大的优势。
Hadoop从上层架构上看是一种典型的主从式结构,主从式的结构在MPI并行程序设计中也是一种重要的并行程序设计方法,主节点负责对整个系统的数据和工作进行管理和分发。而Hadoop与MPI最根本的区别在于,Hadoop有一个主从式的文件系统HDFS在底层支撑其Map/Reduce的数据处理功能。有了HDFS,Hadoop可以方便地实现“计算向数据存储位置的迁移”,从而大大提高了系统计算效率。主从式基础存储和主从式数据处理构成了Hadoop的基本架构模型。
- MPI无法应对节点的失效。
如果MPI在运行过程出现节点失效及网络通信中断,则只有返回并退出,MPI没有提供一套机制处理节点失效后的备份处理方案问题,所以如果中途出现问题,所有的计算将重新开始,这是非常耗时的。Hadoop为应对服务器的失效,在数据备份上下了很大的功夫,数据块会形成多个副本存储在不同的地方,一般会有3个副本,采用简单化的跨机架数据块存储,最大限度避免了数据丢失,数据的安全性得到了保证。
3. 关于各大数据技术的概述
hadoop用于基本的分布式系统构建,将数据隐式的通过hdfs存储在各文件系统中,并通过mapreduce令各文件系统处理存储在自身系统中的数据。
zookeeper用于分布式系统的管理,相当于展示各分布式应用的桌面,其管理各分布式系统并以zookeeper应用的方式统一调用,使用zkCli.sh就像在正常使用linux命令行。将hbase、hive、hdfs集成在一起
hbase将存储在hdfs中的数据抽象为表,表以kv形式存储在底层,每行数据都以rowkey和多个column组成。其操作更多是对数据的增删改,而查的部分则需要hive来实现。
hive实现类sql语句操作hadoop,其主要用于联机分析处理,即数据的非实时计算。hive将HiveQL转换为mapreduce语句在hadoop集群上运行。
kafka用于管理和持久化数据流,处理多个数据生产者与多个数据处理者之间的关系,具体表现为,日志收集、消息系统、用户活动跟踪、运营指标、流式处理等。
spark,分布式计算工具(初衷是用于代替mapreduce),对内存和cpu的要求更高,因为中间结果需要存储在内存中(该部分功能通过RDD实现)。此外,还实现了sql操作数据(spark sql)、流式计算(spark streaming)、机器学习计算(spark mlib)等
二、文献阅读
1. 题目
标题:GL-GNN: Graph learning via the network ofgraphs
作者:Yixiang Shan, Jielong Yang, Yixing Gao
发布:Knowledge-Based Systems (7.2 影响因子)
链接:https://doi.org/10.1016/j.knosys.2024.112107
2. Abstract
图神经网络(gnn)在许多具有图结构数据的场景中取得了巨大成功。然而,在许多实际应用中,应用gnn时会出现三个问题:图不可用,节点具有噪声特征,图不完整。针对这些问题,提出了一种新颖的端到端可图学习的GNN,命名为GL-GNN。GL-GNN包含多个子模块,每个子模块学习样本的关键特征和在图不可用时对应的关键关系图。通过学习子模块网络得到的图网络,利用聚合模块对学习到的图进行进一步融合。GL-GNN通过同时学习多个样本的关系图和图的关系网络来解决第一个问题,通过选择关键特征和关键图来解决第二个和第三个问题。将GL-GNN与7个数据集上的12种基线方法进行了比较,当图不可用时,17种基线方法中的16种在7个数据集上的准确性和F1分数进行了比较。结果表明,与基线方法相比,GL-GNN取得了更好的性能,能够从数据集中学习关键特征和关键图。
3. 文献解读
3.1 Introduce
针对从不同因素学习图的问题,提出了一种新的图可学习的GNN,称为GL-GNN,它提取不同的特征子集来学习不同的图。为了对学习到的图进行聚合,进一步设计了一个学习图网络的模块。GL-GNN由多个子模块组成,每个子模块学习一个数据样本的关系图。图网络是通过学习子模块和聚合模块的关系网络来构建的。将学习到的图与图网络上的聚合模块进一步融合。每个子模块选择重要的节点特征,从不同的特征因子中学习数据样本对应的关系图。虽然这些子模块采用相同的神经网络结构,但它们的参数是相互独立的。同时学习数据样本的关系图和图网络。
3.2 创新点
主要贡献如下
- 提出了一种新的GNN,它可以在考虑不同因素、关键数据特征和这些因素的网络的情况下同时学习图结构。据我们所知,这是第一个使用图网络来学习gnn图结构的模型。
- GL-GNN同时学习图和半监督分类器,因此可以在分类器的训练过程中调整图。这一特性允许GL-GNN应用于图未知或不完整以及节点具有噪声特征的场景,从而扩展了gnn的应用范围。
- 在7个数据集上比较了GL-GNN与12种基线方法在图不可用时和17种基线方法的准确性和F1分数,包括能够学习和微调图的最新方法。结果表明,GL-GNN比基线方法具有更好的性能。
- 在7个真实数据集上的实验表明,GL-GNN可以去除样本的噪声特征,恢复样本之间的关系(即学习关键特征和关键图)。
4. 网络框架
考虑N数据样本 X = { x i } i = 1 N , where X i ∈ R F X=\{x_i\}^N_{i=1},\text{where}\ X_i\in R^F X={xi}i=1N,where Xi∈RF,F是特征的维数。数据样本的单热标签为 Y = { Y i } i = 1 N , where Y i ∈ R C Y=\{Y_i\}^N_{i=1},\text{where}\ Y_i\in R^C Y={Yi}i=1N,where Yi∈RC,C为类个数。
gnn在图结构数据集的半监督分类任务中取得了良好的性能。然而,图形通常是嘈杂的或完全不可用的。因此,在本文中,我们的目标是从不同的方面学习图,并将GNN应用于图不可用、节点具有噪声特征和图包含噪声连接的场景。具体来说,针对以下情况进行半监督节点分类:(1)当图不可用时,学习节点(即数据样本的图)之间的关系,去除数据样本中不重要的特征;(2)当图可用时,去除图中不重要的特征和有噪声的边。
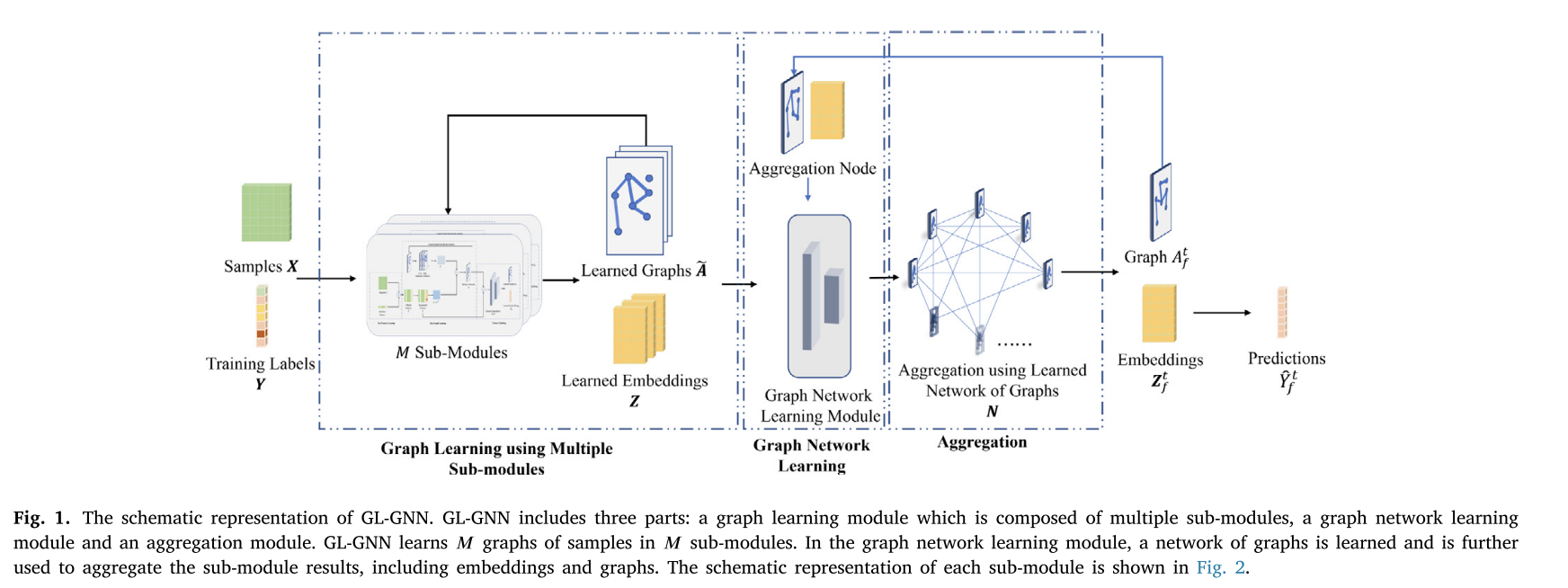
GL-GNN的整体结构如图1所示。GL-GNN包括三个部分:使用多个子模块的图学习模块、图网络学习模块和聚合模块。各子模块总体结构如图2所示。在图学习模块中,每个子模块选择一个特征子集,学习样本对应的关系图,以及嵌入。在图网络学习模块中,学习了子模块的网络,然后在子模块聚合模块中使用子模块聚合学习到的图和嵌入。数据样本输入到𝑀子模块中,独立学习𝑀样本关系图。
将M图和M学习到的嵌入进一步输入到图网络学习模块中,学习到一个图网络,在聚合模块中进一步使用该网络对学习到的图和嵌入进行聚合。同时学习参数和图结构,令学习到的离散结构可以在神经网络学习过程中自适应调整。
5. 实验过程
数据集:
对于图学习任务,评估了GL-GNN在七个现实世界数据集上的性能:葡萄酒,癌症,数字,20news10, FMA,以及Citeseer和Cora,没有先前的图表作为输入。在这种情况下,使用与LDS[11]相同的数据分割设置。
对于图精化任务,在DPGNN[43]之后,评估了GL-GNN在另外7个真实世界数据集上的性能,包括Citeseer、Cora、BlogCatalog、ACM、Flickr、UAI2010和CoraFull。在这种情况下,使用与DPGNN[43]相同的数据分割设置。
基线:
当图形可用时,将GL-GNN与以下基本GNN方法进行比较:GCN [22], GAT [44], GMNN [45], LSGNN [46], DPGNN [43], HCPL [47], AM-GCN[48]以及以下能够对图形进行微调的最先进方法:GRCN [38], GLCN [37], IDGL [39], IDGL- anch [39], Pro-GNN [34], rGNN [49], OAGS [50], GEN[51]和SUBLIME[52]。
当图根本不可用时,我们将GL-GNN与𝑘NN-LDS、SLAPS(FP)[40]、SLAPS(MLP)[40]、SLAPS(MLP)[40]、SLAPS(MLP- d)[40]、IDGL[39]、IDGL- anch[39]、SCRL[53]和SPGRL[54]等能够从头学习图的方法进行比较。我们还将𝑘NN构建的图形输入GCN、GAT、GEN[51]和SUBLIME[52]进行比较,即𝑘NN-GCN、𝑘NN-GAT、𝑘NN-GEN和𝑘NN-SUBLIME。
实现细节:
回想一下,为了学习3.2.2节中的样本关系图,在方程中选择R的top-k值。使用验证数据集为每个数据集设置一个适当的k。对于特征维度较小的数据集,采用较大的k值来聚合图中更多邻居的信息。当特征数量很大时,将k设置为10或20,以确保学习到的图足够稀疏。
实验结果:
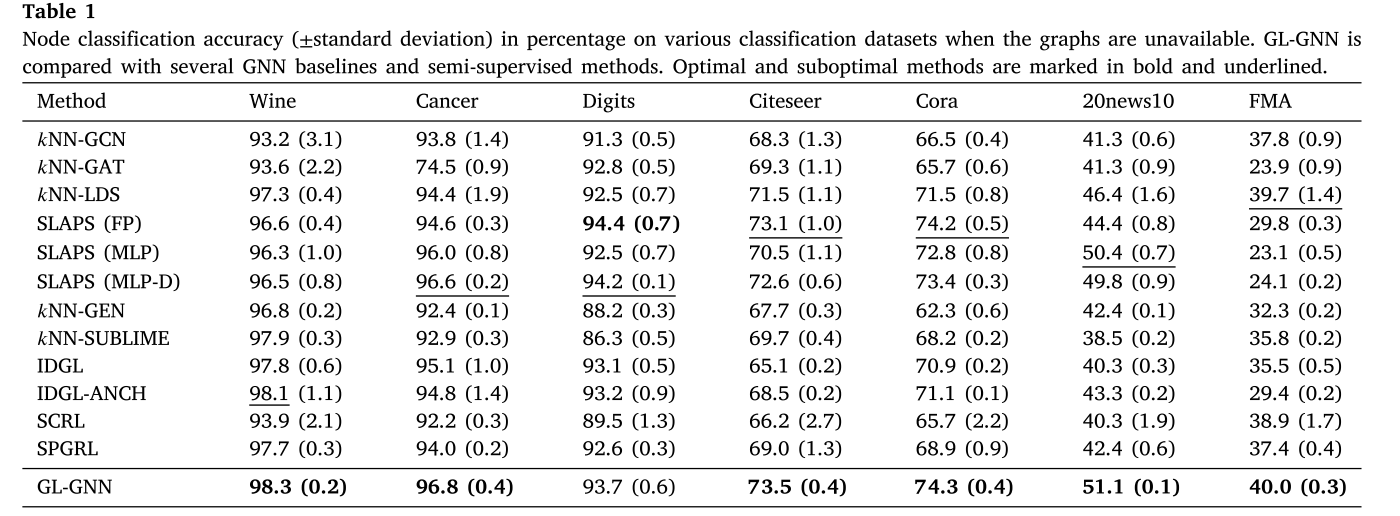
为了评估GL-GNN在学习图中的性能,将其与12种基线方法在5个没有可用图的数据集和2个未使用图的引文数据集上进行了比较。GL-GNN和基线法的结果见表1。最优和次优方法以粗体和下划线标记。总体而言,可以得出结论:(1)GL-GNN在7个数据集中的6个上优于所有其他基线方法,显示出更强的图学习能力;(2)GL-GNN比其他比较方法更稳定。虽然SLAPS (FP)在Digits数据集上比GL-GNN提高了0.7%,但在20news10数据集上却比GL-GNN的性能低15.1%。
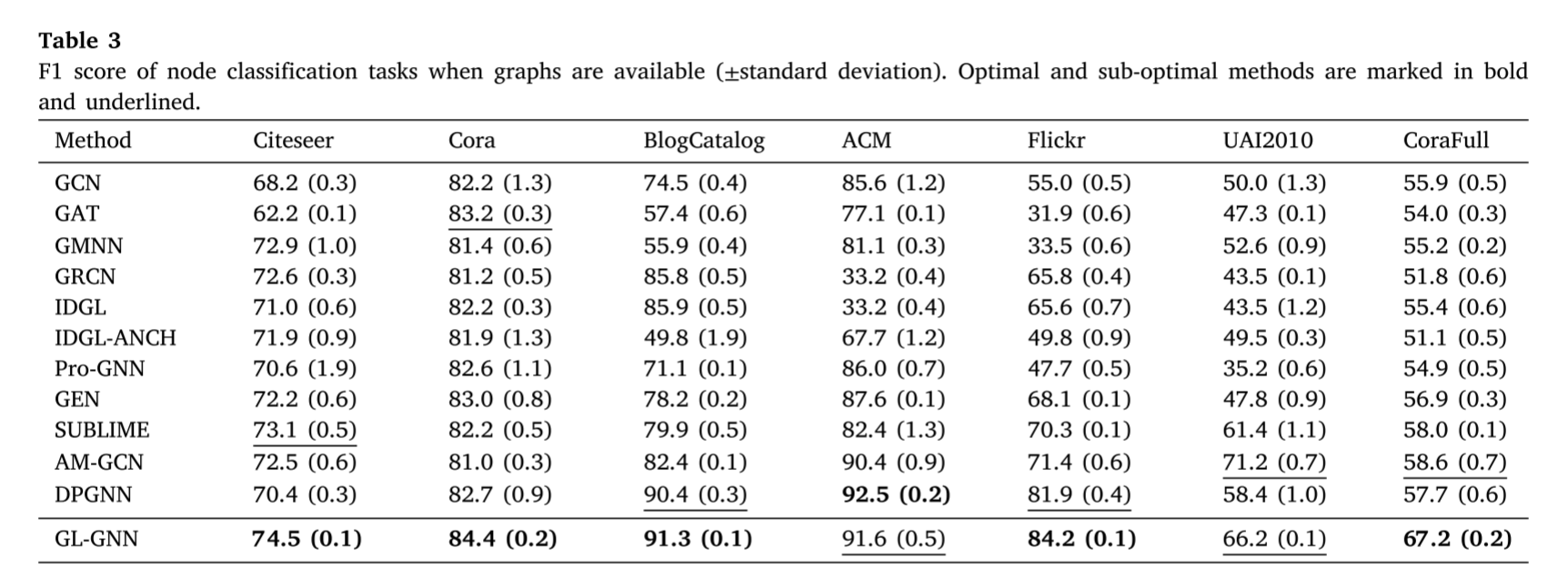
为了评估GL-GNN在精炼图上的性能,在另外七个数据集上进行了实验,这些数据集被称为先验图。继DPGNN后[43],也总结了GL-GNN的F1评分和基线方法,见表3。如图所示,GL-GNN在准确率和F1分数上都优于17种基线方法中的16种,这表明GL-GNN在精炼图方面更有效。
6. 结论
在本文中,提出了GL-GNN,它可以从零开始学习图或提炼可用图,将gnn的应用场景扩展到图不可用或包含噪声边缘的情况。GL-GNN采用多个子模块从不同方面学习图,其中使用选择向量学习关键特征。在涉及图形学习和精炼的场景下进行了全面的实验,以评估GL-GNN的有效性。进一步进行了笑容实验来验证的关键设计。结果表明,提出的GL-GNN在学习和精炼图的场景中都优于相关的最先进的gnn。
参考文献
[1] Yixiang Shan, Jielong Yang, Yixing Gao. GL-GNN: Graph learning via the network of graphs. Knowledge-Based Systems,Volume 299,2024,112107,ISSN 0950-7051,https://doi.org/10.1016/j.knosys.2024.112107















 1706
1706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









