







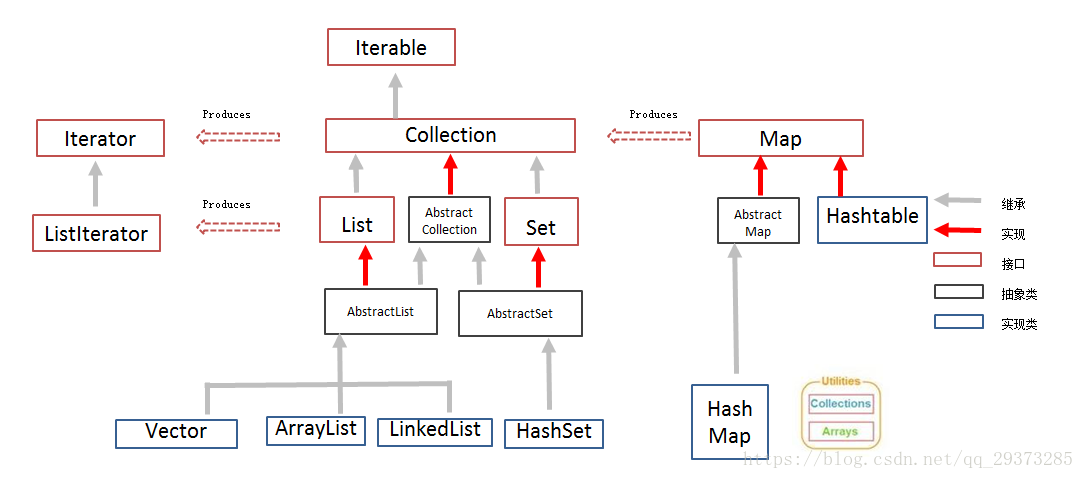
Map
-
collection中的集合,元素是单个存在的,像集合储存元素采取一个个元素的方式储存。
-
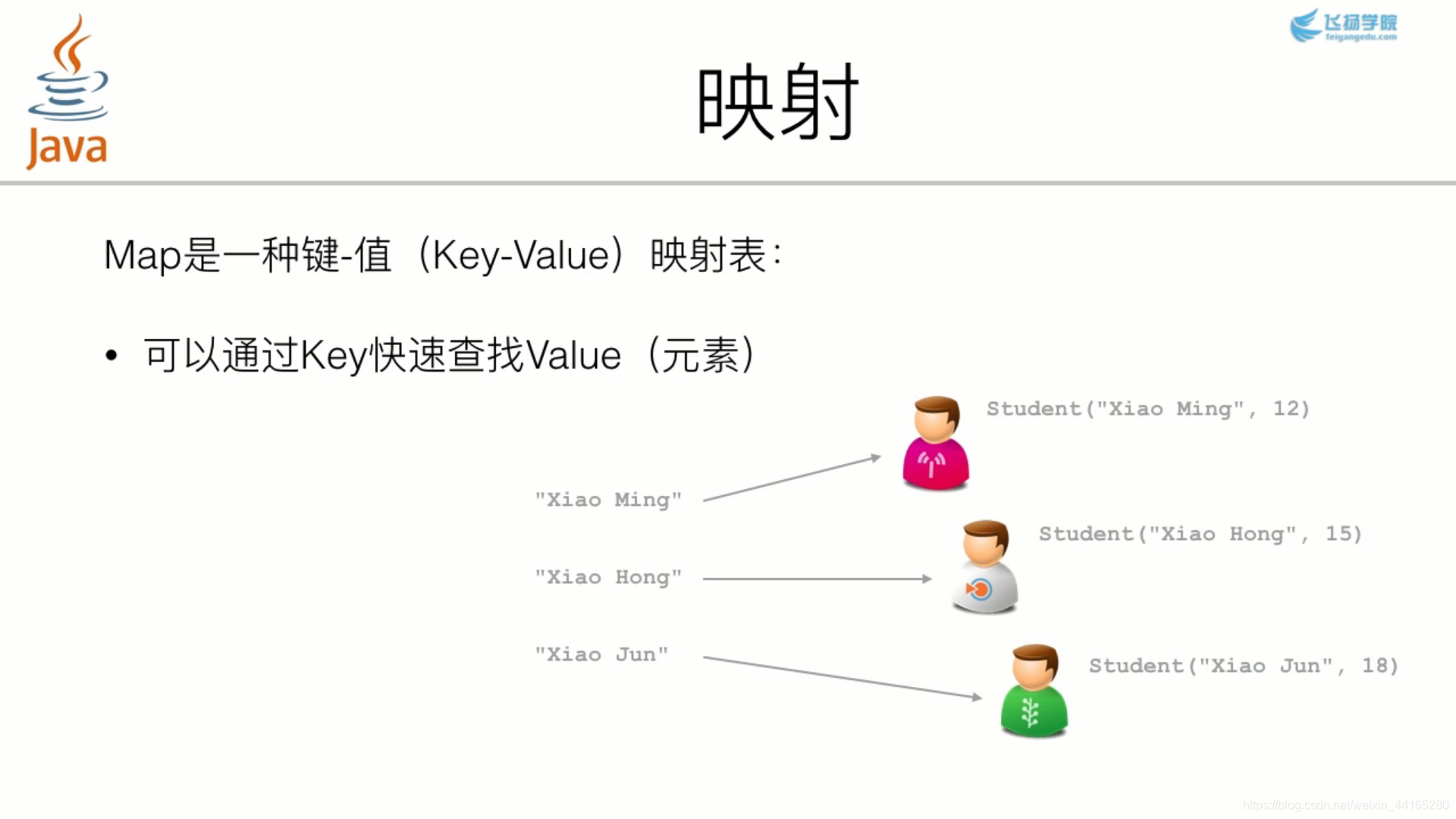
map中的集合,元素是成对存在的,键值对(k-v),其中键不能重复,值可以重复,每个键只能对应一个值,可以通过键找到对应的值。
-
collection中的集合称为单列集合,map中的集合称为双列集合。
-
map中常用的集合为hashmap集合、linkedhashmap集合。

HashMap和LinkedHashMap
-
HashMap:存储数据采用的哈希表结构,元素的存取顺序不能保证一致。由于要保证键的唯一、不重复,需要重写键的hashCode()方法、equals()方法
-
LinkedHashMap:HashMap下有个子类LinkedHashMap,存储数据采用的哈希表结构+链表结构。通过链表结构可以保证元素的存取顺序一致;通过哈希表结构可以保证的键的唯一、不重复,需要重写键的hashCode()方法、equals()方法 。
-
注意:Map接口中的集合都有两个泛型变量<K,V>,在使用时,要为两个泛型变量赋予数据类型。两个泛型变量<K,V>的数据类型可以相同,也可以不同。
map接口常用的方法 map<k,v>

- put()方法: map.put(“code”, 0);
- get()方法:string a= map.get(code);
- remove()方法:hashMap.remove(“code”);
- 如果对同一个k值put值拿的是最后put的那个值
- 注意:Map集合不能直接使用迭代器或者foreach进行遍历。但是转成Set之后就可以使用了。
public class MapDemo {
public static void main(String[] args) {
//创建Map对象
Map<String, String> map = new HashMap<String,String>();
//给map中添加元素
map.put("邓超", "孙俪");
map.put("李晨", "范冰冰");
map.put("刘德华", "柳岩");
//获取Map中的所有key
Set<String> keySet = map.keySet();
//遍历存放所有key的Set集合
Iterator<String> it =keySet.iterator(); **
while(it.hasNext()){ //利用了Iterator迭代器**
//得到每一个key
String key = it.next();
//通过key获取对应的value
String value = map.get(key);
System.out.println(key+"="+value);
}
}
}
public class map {
public static void main(String[] args) {
HashMap<String,String> hashMap = new HashMap<>();
hashMap.put("詹姆斯", "jams");
hashMap.put("乔丹", "jondon");
hashMap.put("科比", "kb");
//获取hashmap中所有key与value的关系
Set<Map.Entry<String,String>> entries = hashMap.entrySet();
//遍历set集合
Iterator<Map.Entry<String,String>> it = entries.iterator();
while (it.hasNext()){
//得到每一对对应关系
Map.Entry<String,String> entry = it.next();
String key = entry.getKey();
String value = entry.getValue();
System.out.println("中文"+key+"英文"+value);
}
}
}
输出结果
中文詹姆斯英文jams
中文乔丹英文jondon
中文科比英文kb
Process finished with exit code 0
遍历
//遍历
for (String key : hashMap.keySet()){
String value = hashMap.get(key);
System.out.println(key + value);
}
输出结果
詹姆斯jams
乔丹jondon
科比kb
Process finished with exit code 0
HashMap
- 无序
- 键值对(k-v)
- jdk1.8前数组+链表 jdk1.8后数据数组+链表+红黑树(效率高)
- 边界值大于8并且数组长度大于64链表转化为红黑树
- 数据结构:就是存储数据的一种方式
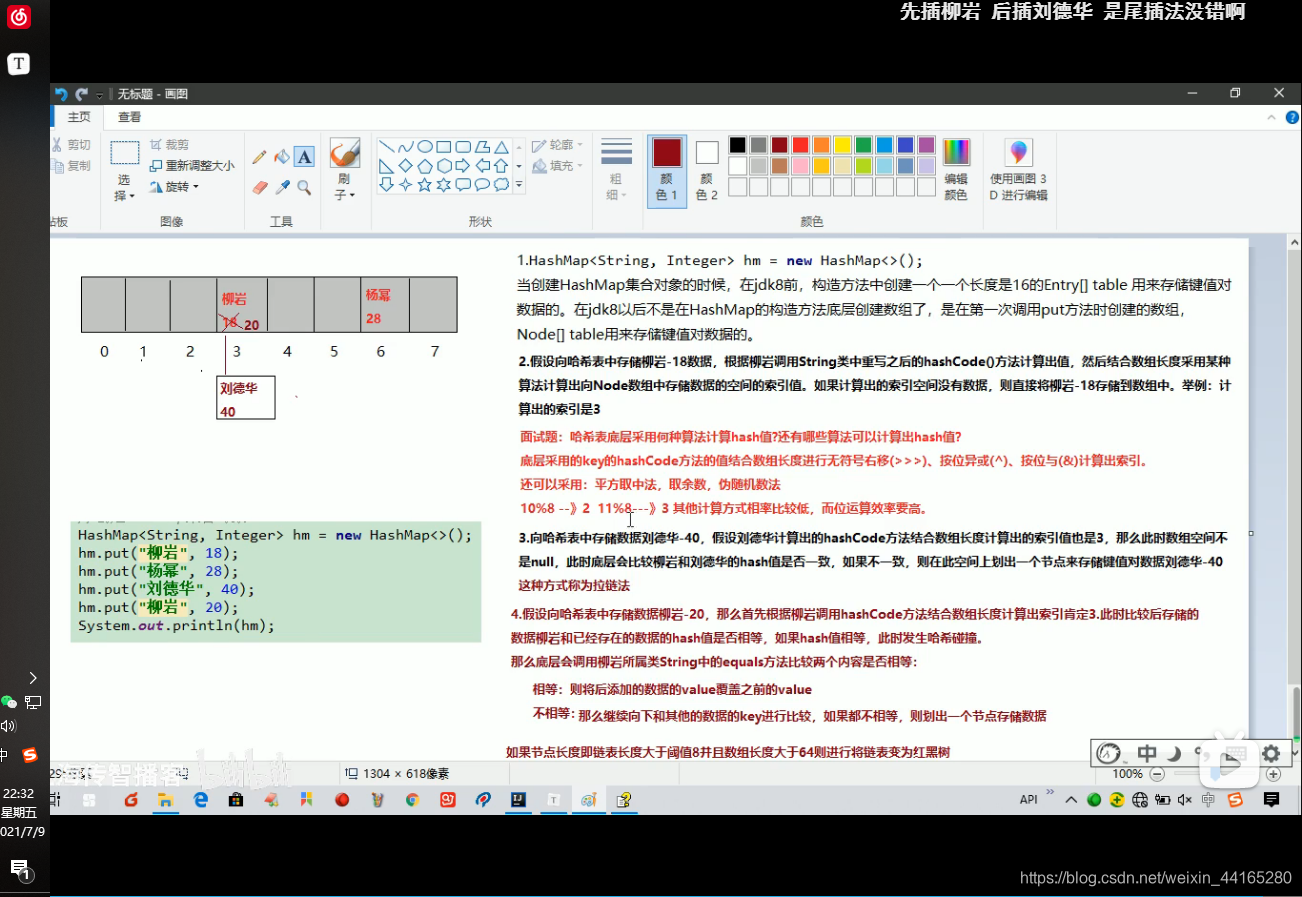
- HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(首先遍历链表,存在即覆盖,否则新增,hashmap中链表最少性能才会越好)
- 哈希冲突:如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞
- JDK1.8在JDK1.7的基础上针对增加了红黑树来进行优化。即当链表超过8时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高HashMap的性能,其中会用到红黑树的插入、删除、查找等算法。
Map<String,String> map = new HashMap<>(); //new一个map存kv值
map.put("diverId", printTransportData.getBzScheduling().getDiverId());//往map存值,前面是k,后面是value
map.put("employeeId", printTransportData.getBzScheduling().getEmployeeId());
map.put("otherEmployeeId", printTransportData.getBzScheduling().getOtherEmployeeId());
List<BzEmployee> transportPersons = bzEmployeeService.findTransportPerson(map);//最后通过list<实体,返回类型> ;来接收返回的值
在controller层,使用map接收,在service封装好数据,返回map给controller层
controller层
Map<String,Object> map = bzConsumelistProjectRelationService.printMoreTwentyThousand(bzConsumelistProjectRelation);
model.addAttribute("list", map.get("relations"));
model.addAttribute("count", map.get("count"));
model.addAttribute("totalAmount",map.get("totalAmount"));//取值
service层
public Map<String,Object> printMoreTwentyThousand(BzConsumelistProjectRelation bzConsumelistProjectRelation) {
Map<String,Object> map = new HashedMap();
List<BzConsumelistProjectRelation> relations = dao.queryConsume(bzConsumelistProjectRelation);
map.put("relations",relations);//存值
map.put("count", relations.size());
BigDecimal totalAmount = BigDecimal.ZERO;
if (relations != null && relations.size()>0){
for (BzConsumelistProjectRelation relation : relations){
if (StringUtils.isNotBlank(relation.getAllTotalPrice())){
totalAmount = totalAmount.add(new BigDecimal(relation.getAllTotalPrice()));
}
}
}
map.put("totalAmount",totalAmount);
return map; //返回给controller
}
前端遍历map
遍历:
deceasedMap.forEach(function (value, key, map) {
console.log(key);
console.log(deceasedMap.get(key));
});
















 1657
1657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











