







1. 前言
PageHelper我们都不陌生,经常在项目中用作分页,它的用法也很简单,直接用PageHelper.startPage就可以完成分页了,那么PageHelper底层是怎么帮助我们实现分页功能的呢?
在进入源码的剖析之前先猜想一下PageHelper的原理:PageHelper通过在sql最后面拼接limit从而实现分页,在这里初步推测是拦截了query方法,把原来的MapperStatement替换成了新的MapperStatement,新的MS有分页信息。我们都知道mybatis底层执行查询操作的时候,其实是通过Executor.query去完成的,那么这里进一步猜测,是为executor生成了代理类,代理类在MS中增加了分页信息。
2. 源码解析
有了上述的猜测,下面就带着问题进入PageHelper的源码。分析源码最好的方式是一步步debug进去看看,每一步的背后都发生了什么,这里以平时最常使用的一种方法作为切入点:
public List<ProjectSpace> getSpace() {
// 返回第一页的前十条数据
PageHelper.startPage(1, 10);
return spaceMapper.selectByExample(new ProjectSpaceExample());
}点击进入,是一连串构造方法的调用,大概就是设置查询之前是否需要先做count操作、入参不合理的时候是否进行自动的参数合理化等,到最后可以来到:
public static <E> Page<E> startPage(int pageNum, int pageSize, boolean count, Boolean reasonable, Boolean pageSizeZero) {
Page<E> page = new Page<E>(pageNum, pageSize, count);
page.setReasonable(reasonable);
page.setPageSizeZero(pageSizeZero);
//当已经执行过orderBy的时候
Page<E> oldPage = SqlUtil.getLocalPage();
if (oldPage != null && oldPage.isOrderByOnly()) {
page.setOrderBy(oldPage.getOrderBy());
}
SqlUtil.setLocalPage(page);
return page;
} 第一行代码相对比较简单,就是生成一个Page对象,并为它赋值;PageHelper中Page都是存储在ThreadLocal里的,这样做的好处是两个线程互不影响,所以在这里需要将新生成的Page对象放入到该线程的ThreadLocal里。
到这里可能会有点疑惑,PageHelper执行了之后好像没有什么有效信息啊,都是一些简单的赋值操作。当分析不下去的时候可以看看这个功能的使用是不是还依赖了别的配置,果然,我们发现定义了一个PageHelper的Bean。
@Bean("onePageHelper")
public PageHelper onePageHelper() {
PageHelper pageHelper = new PageHelper();
// 一些属性的set
return pageHelper;
}查看PageHelper的UML类图发现,PageHelper是Interceptor的子类,这个方法有两个主要方法,一个是intercept,一个是plugin,看着方法可以推测一下,plugin是把目标包装成一个代理类,然后执行特定方法的时候调用的是这个代理类的intercept。那什么时候会用到这些Interceptor呢?
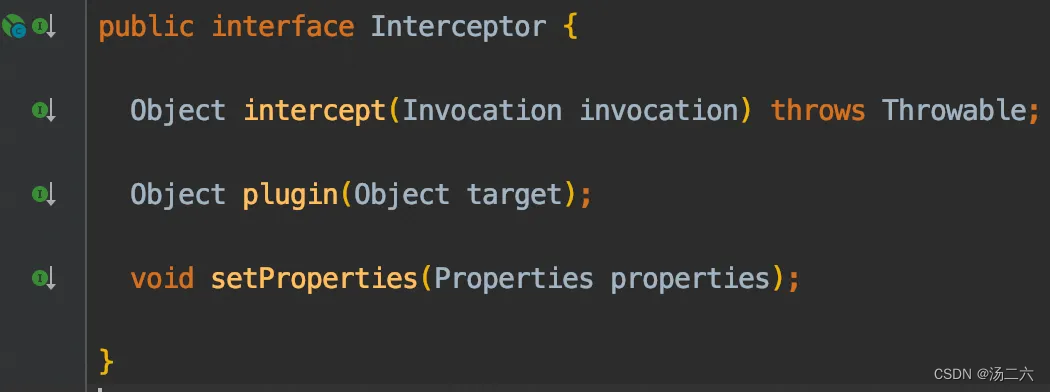
这里我们通过反推的方式,在InterceptorChain里中找到了pluginAll方法,这个方法是把对target挨个执行plugin操作,进一步反推,在如下四个方法中用到了pluginAll方法:

上面的四个操作分别是对参数、对返回的结果、对预编译的语句以及执行器做拦截操作,这里是对executor进行了拦截。(PageHelper只针对Executor类),进入生成Executor的方法:
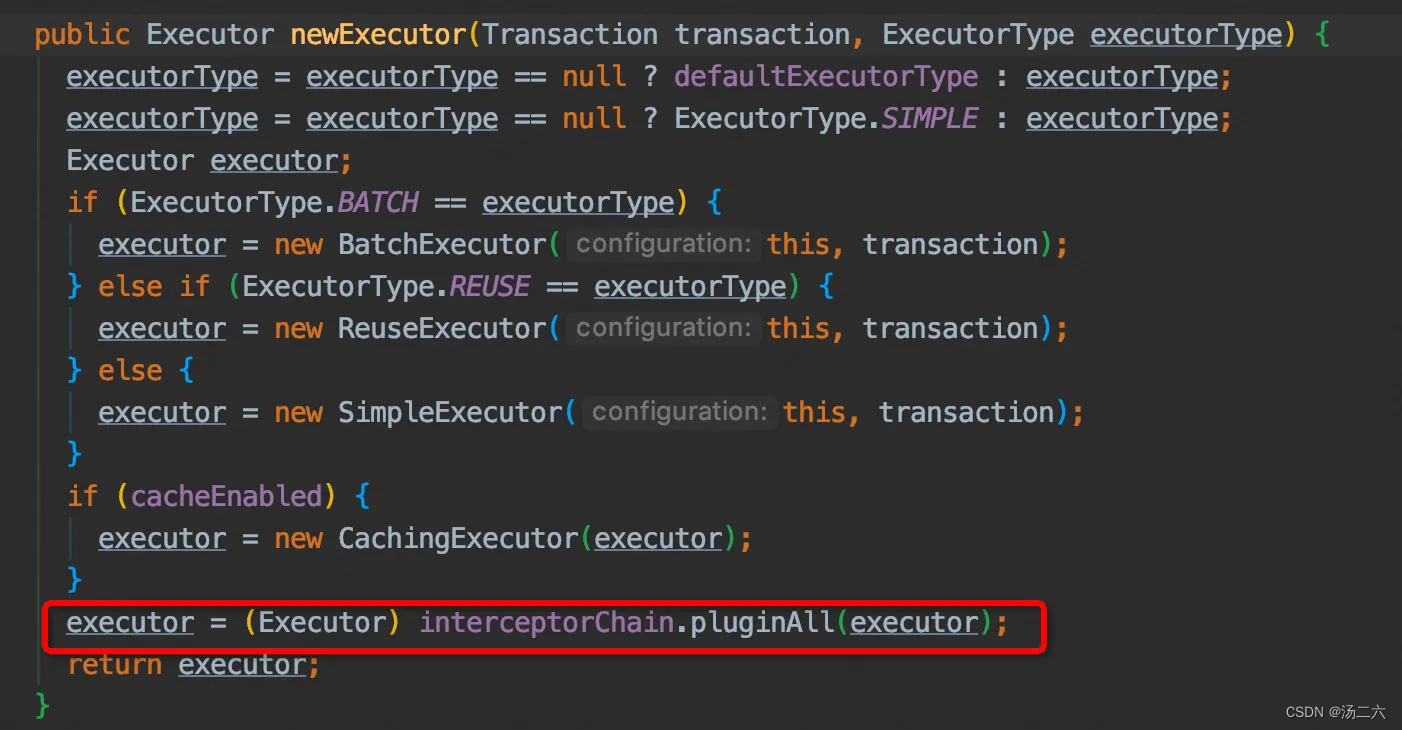
可以看到,生成executor的时候,会把所有的拦截器都作用在这个target上,进一步跟进plugin方法。
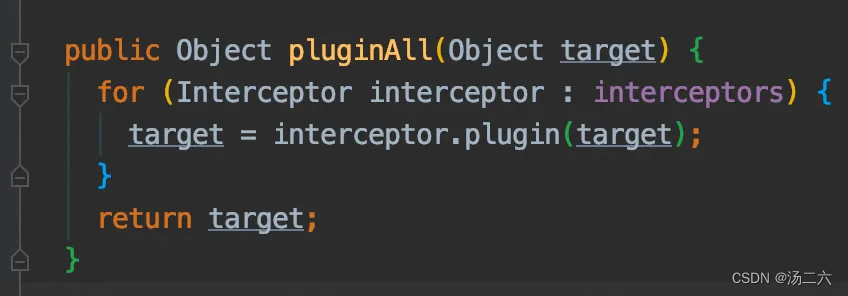
发现跳入了PageHelper的plugin,这个plugin方法只对executor起效,而我们传入的正是executor,进一步到Plugin.wrap里。
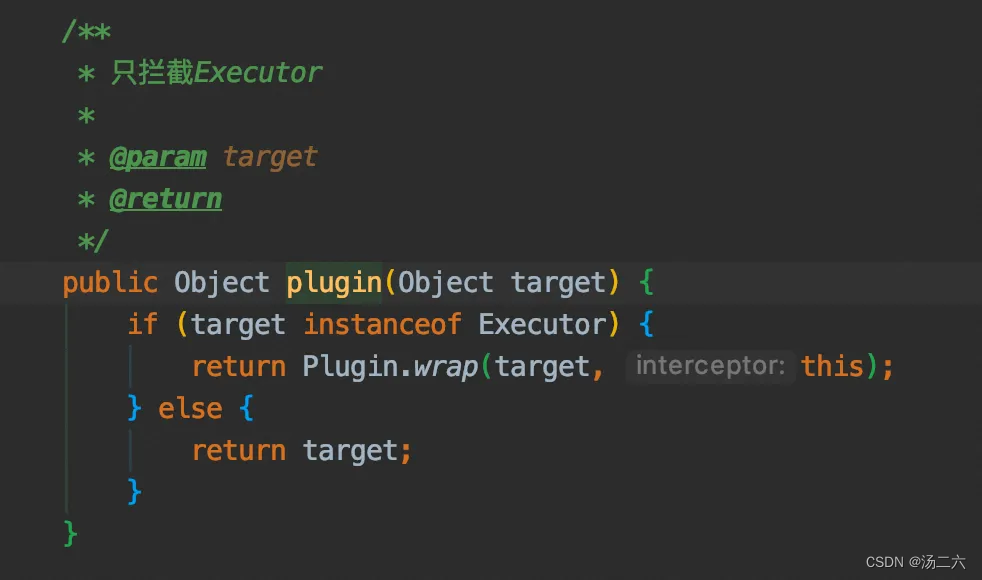
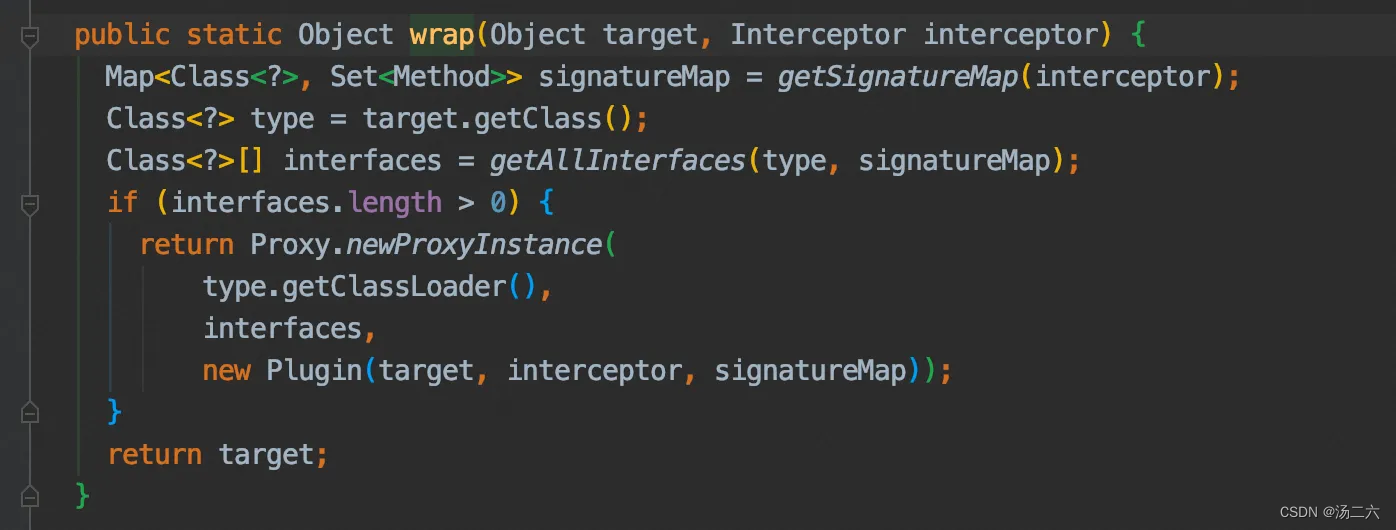
重点来了,先整体浏览一下代码,在看局部细节。
看代码大概意思是:
a. 解析interceptor的签名,得到一个key是类,value是方法的map;
b. 找到这个目标类的所有接口;
c. 为接口生成代理对象;
d. 返回目标类或者代理对象
下面深入细节看看,getSignatureMap这个方法,其实就是把注解上的信息按照一定的格式解析,然后放入到map中,
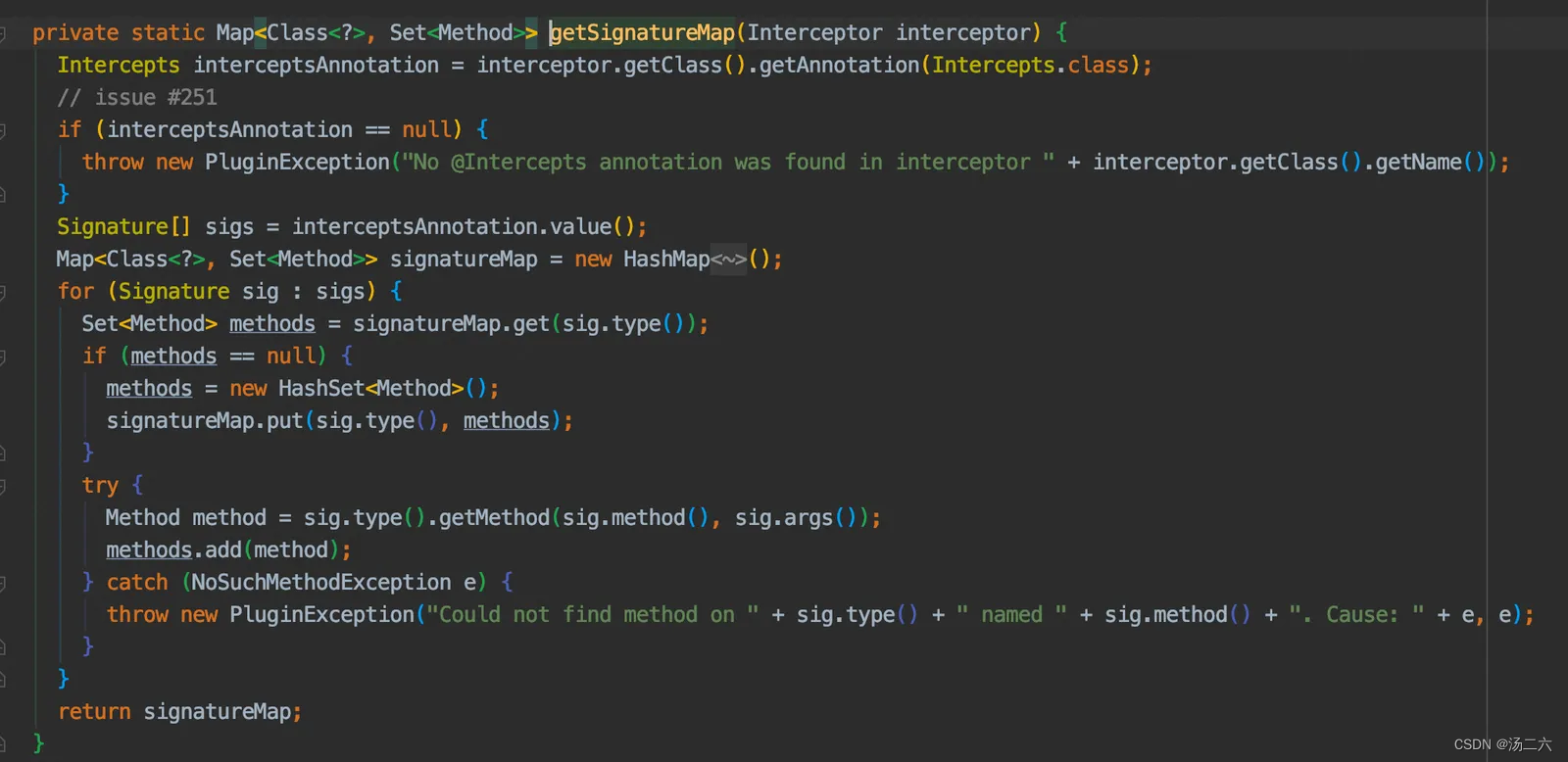
例如我们的PageHelper,解析出来key是Executor.class,value是Executor中的query方法,因为Executor中query方法重载了,所以需要通过args找到真正符合要求的query方法。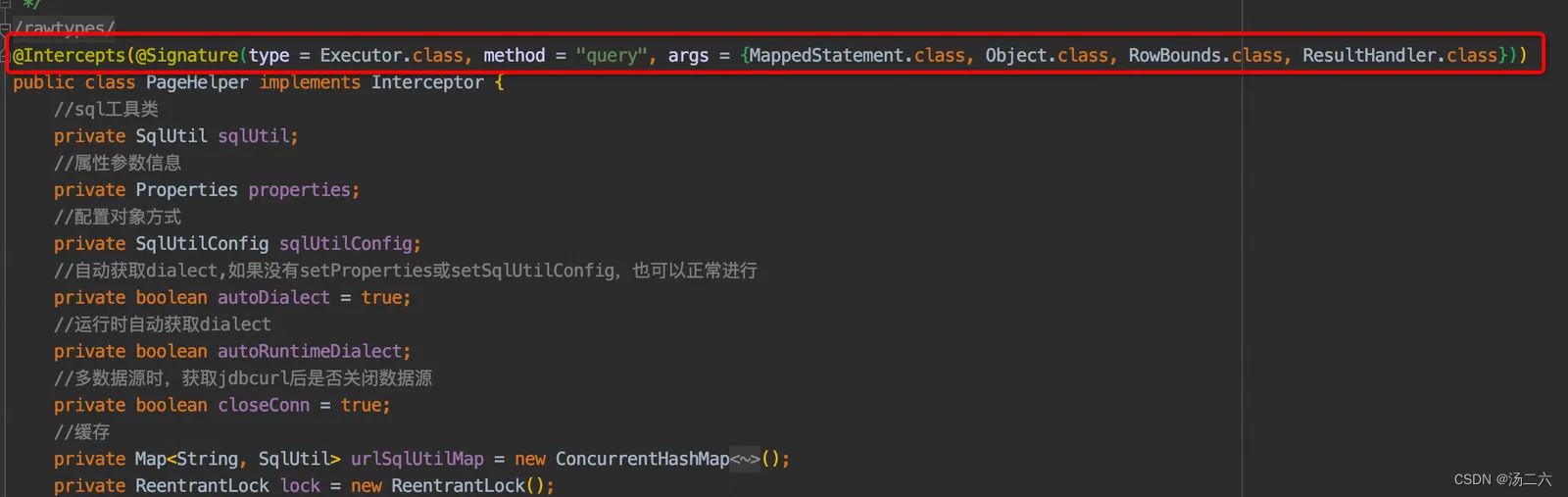
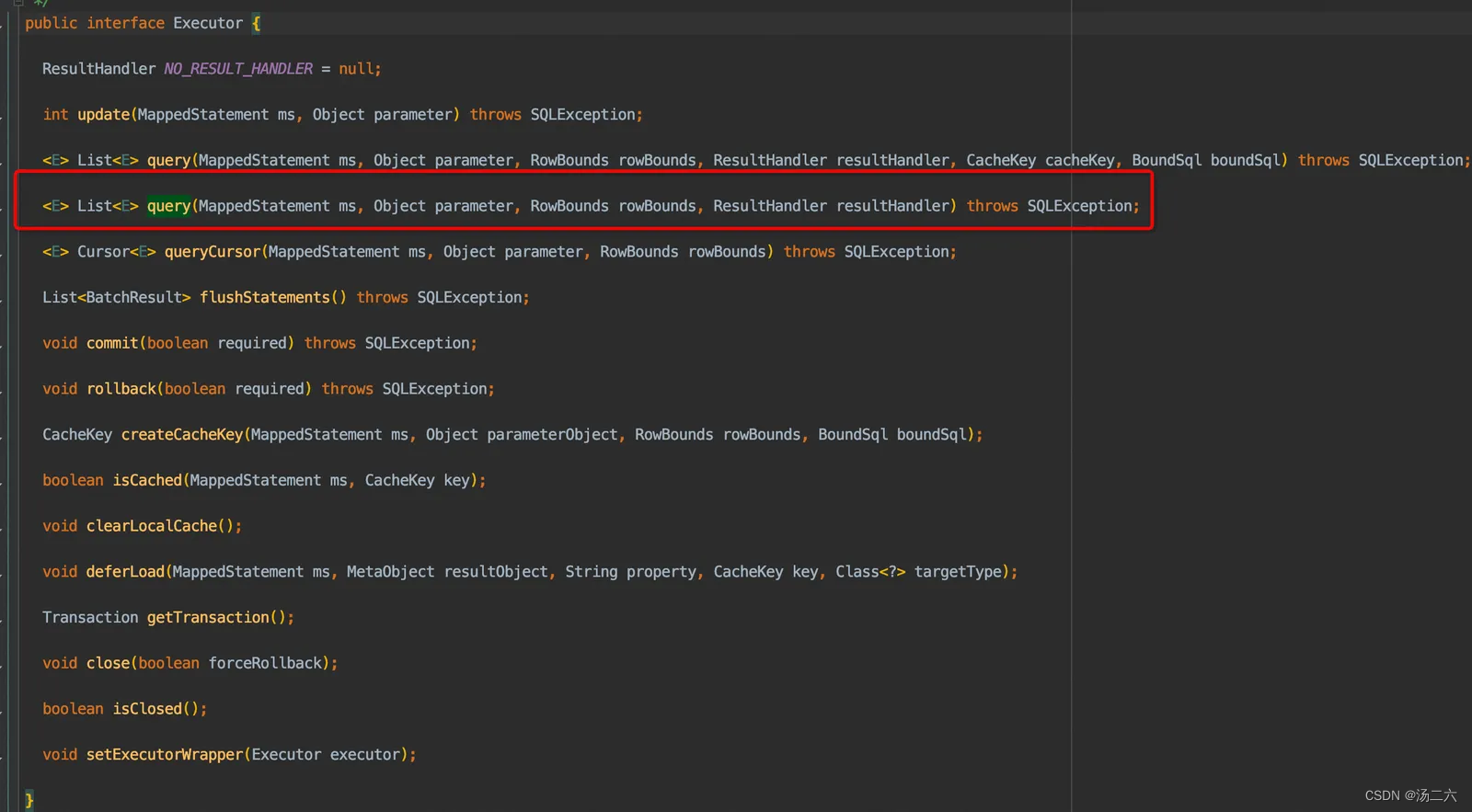
getAllInterfaces是找到符合要求的接口,比较简单,不做赘述。后面的部分就是帮Executor类生成了代理,当方法执行到Executor的方法的时候,就会进入代理类,也就是Plugin的invoke方法中,这里会先判断执行的方法是不是上面说的那个query方法,如果是则进入intercept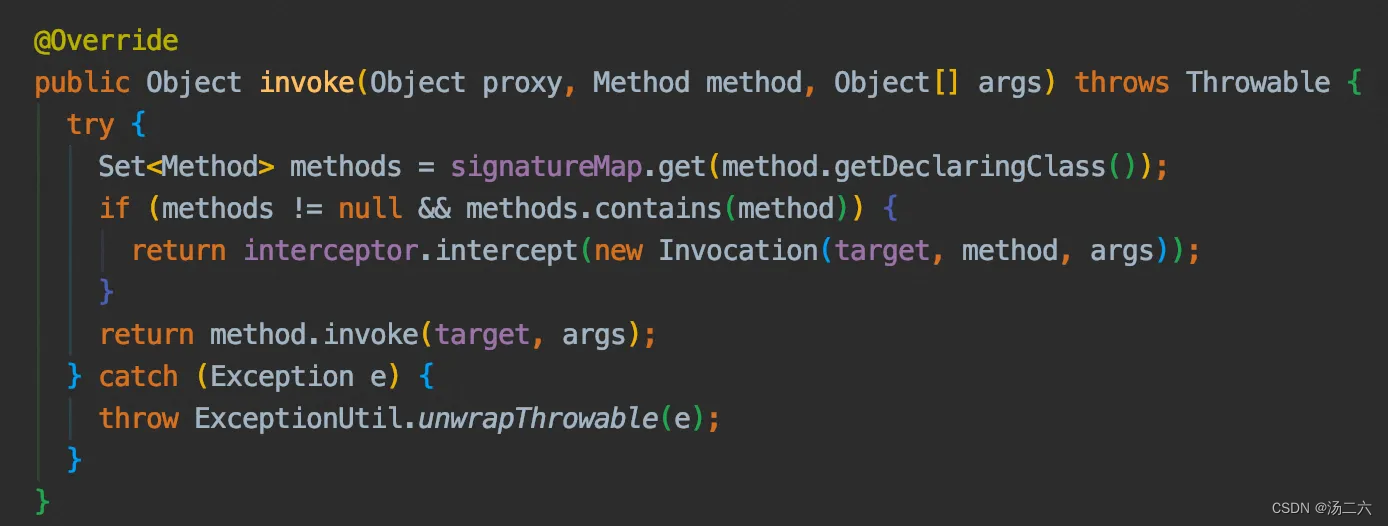
跟踪intercept方法可以来到SqlUti.doProcessPage,这个方法的入参page是从ThreadLocal里获取的,里面存放的是一开始通过PageHelper.startPage(1,10)中塞入的数据,下面主要看绿框里的部分。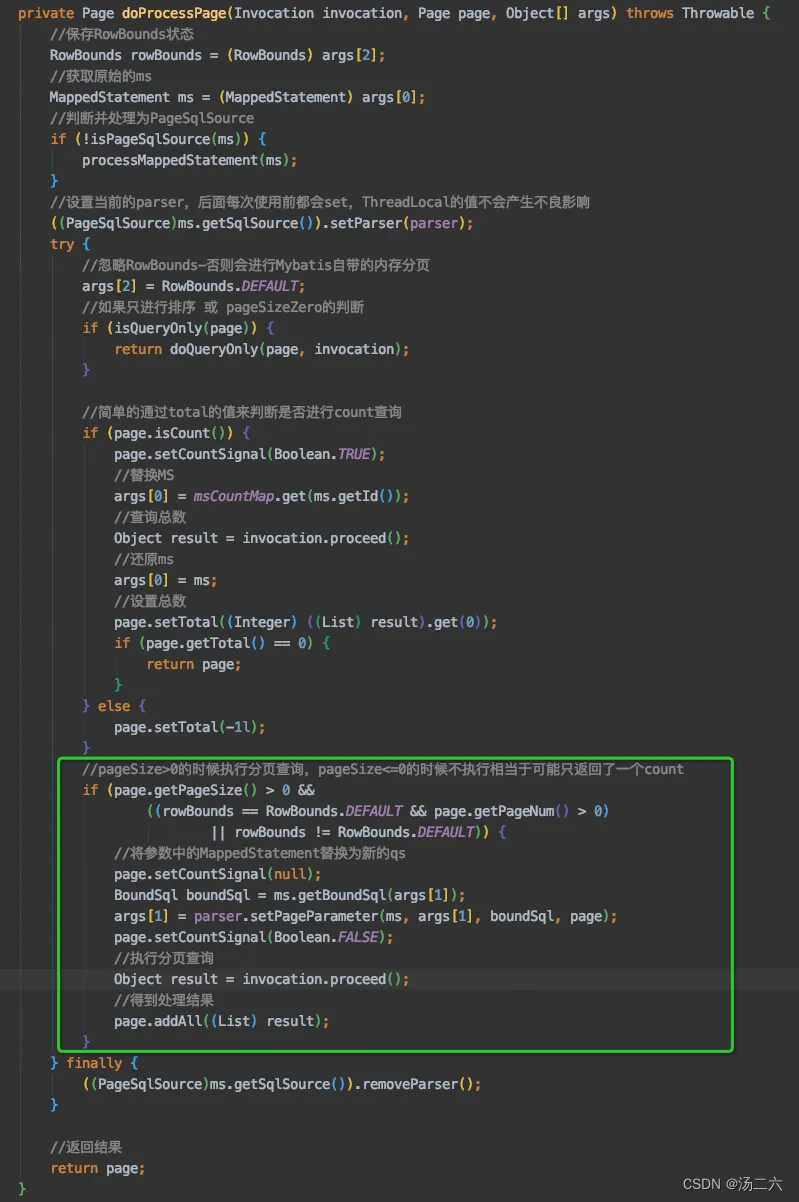
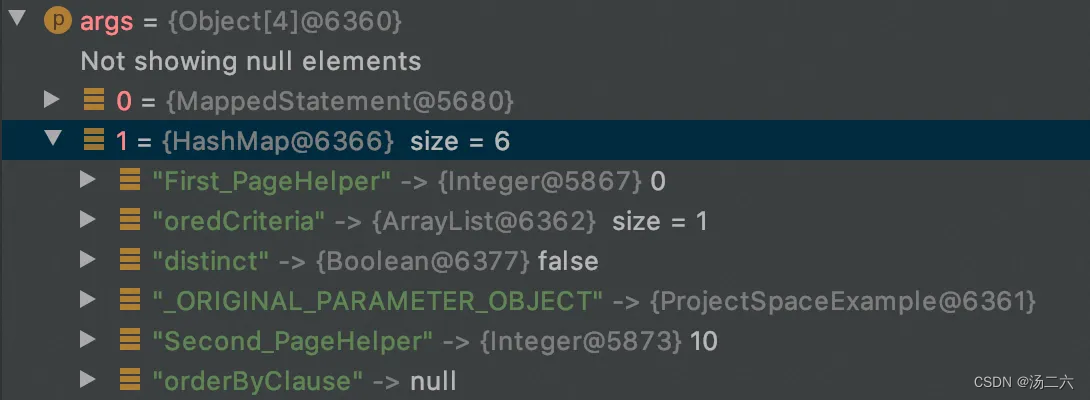
绿框中的内容是针对需要分页的场景的,可以看到,在执行真正的逻辑处理之前,先拿到了BoundSql(存放sql以及参数映射关系)此时的boundSql中的sql语句如下图所示,后面通过执行parser.setParameter方法将args[1]中原来的值替换成了分页信息。
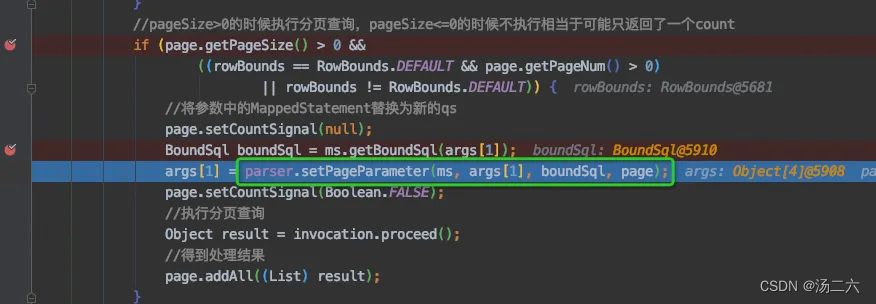
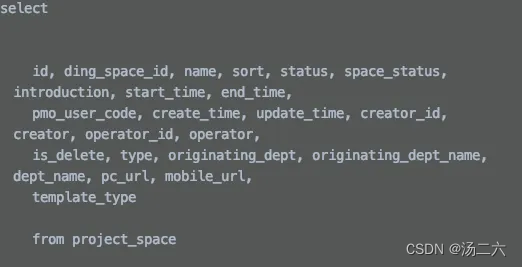

接着会执行invocation.proceed(),这里会回到executor.query方法,这里是首先生成boundSql,然后生成唯一的key,最后做查询。重点分析一下第一步,看怎么拓展原来的boundSql。
一路debug可以进入PageDynamicSqlSource#getPageBoundSql,这里主要是去获取MySqlParser里的pageSql,这里对原来的sql增加了limit属性。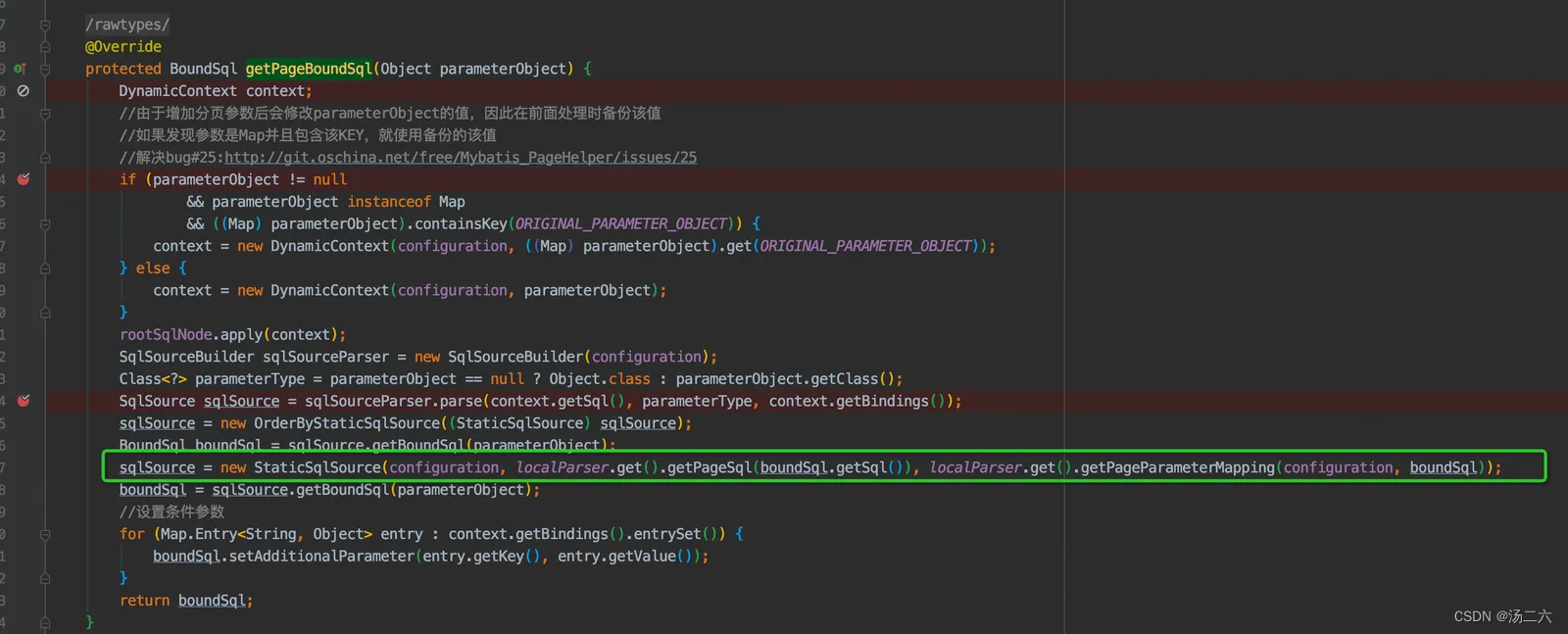
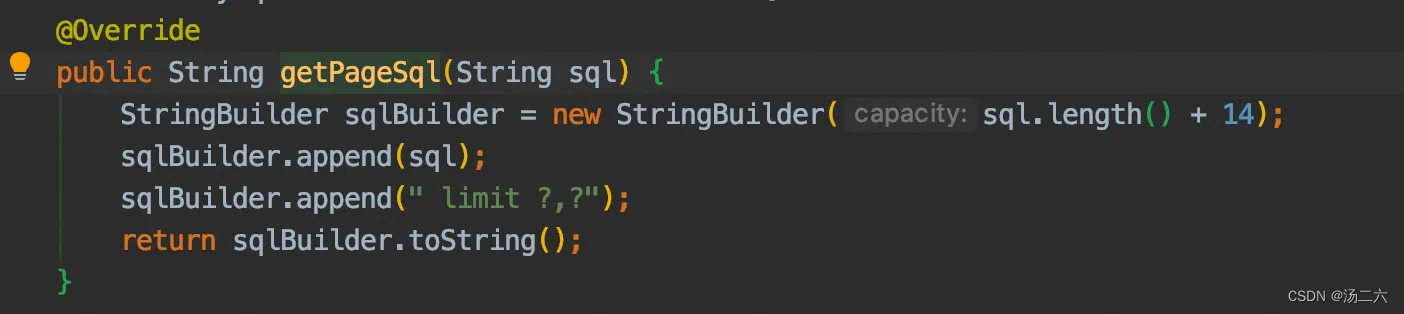
获取了boundSql后,执行query方法的时候,就会把ParameterMapping中的参数映射到预编译的位置,从而达到分页。
3. 问题
看了源码之后,可以解答下述的问题了~
问题1:以下代码中,为什么第一个是10条,第二个是770条?
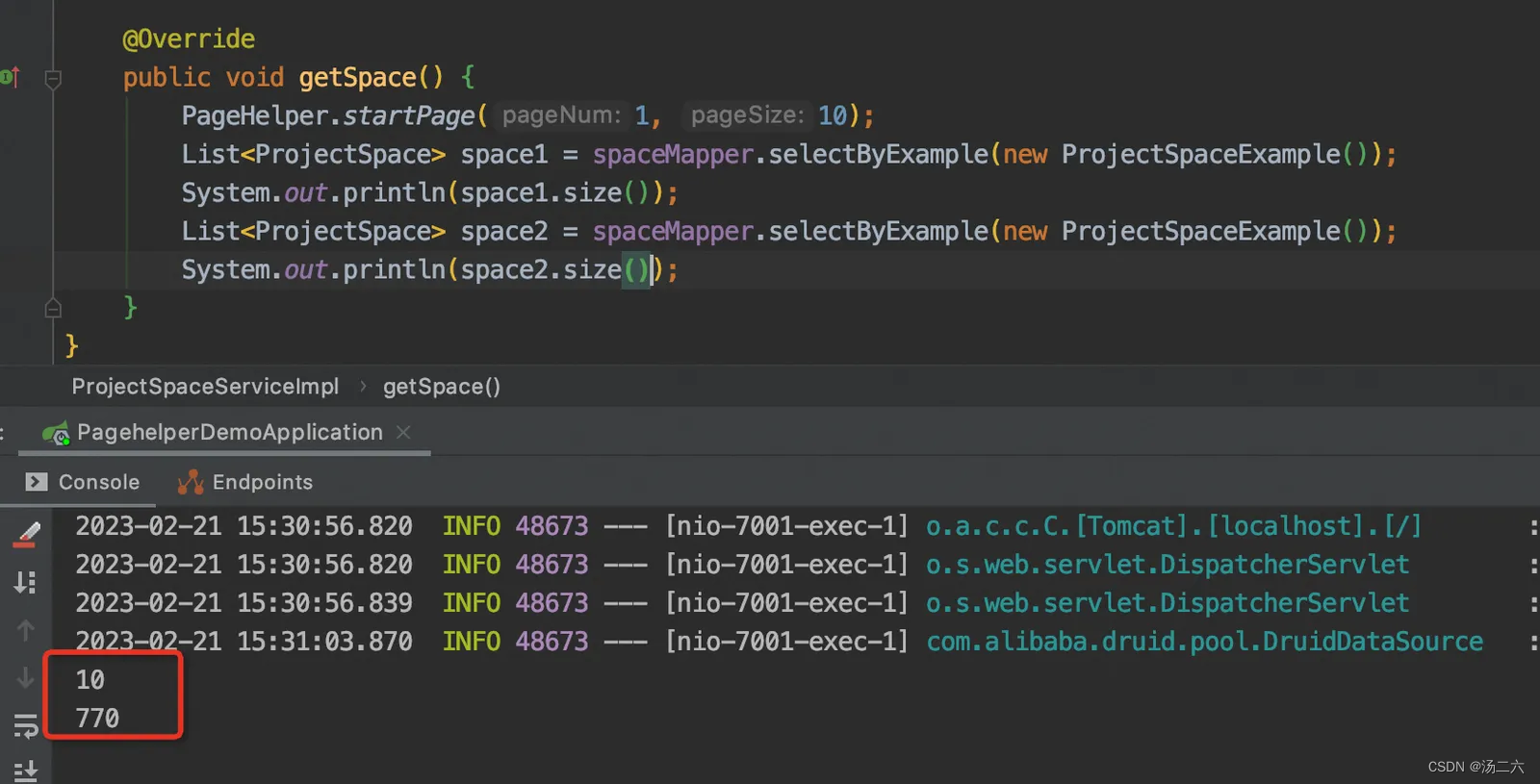
答案:奥秘在对Executor执行query方法,进入代理方法后,会执行到下图中的方法,可以看到,执行完sql获得结果后,不管执行有没有异常都会清空ThreadLocal的page属性,这也是为什么我们以前说的pageHelper.startPage只对下一行sql有效,因为执行完下一行sql后,ThreadLocal里的page被清空了,分页信息也没了。所以第二条查询操作返回的是全部的数据~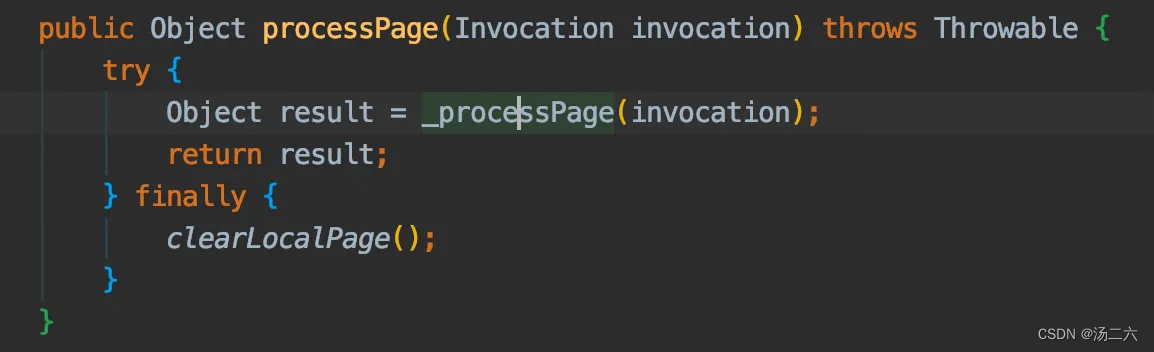
问题2:如下左图所示,线程1访问getSpaceWithException方法,设置了分页参数之后就因为异常返回了;因为线程池的线程是复用的,下一个请求也拿了线程1去请求getSpace方法,getSpace的逻辑是取出所有的空间数据,这里输出的空间个数是多少呢?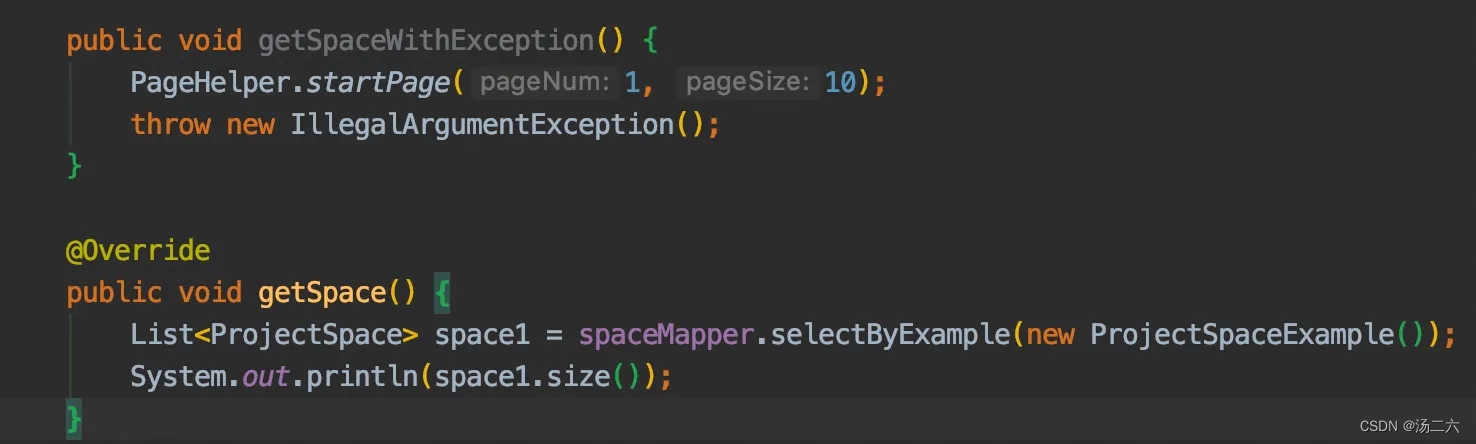
答案:返回的是10。问题1中可以看到,PageHelper其实底层是ThreadLocal,它在执行完sql后会把线程中的page属性擦除掉,那么如果在执行sql之前就发生了异常,是不会把ThreadLocal中的Page信息擦除的,那么下次请求中复用了这个线程的话,线程中就自带了Page的分页信息,所以输出的内容是分页之后的数据。
解法:1. 每次请求完都手动调用SqlUtil.clearLocalPage() 2. 分页行和mapper查询挨着写,不要有别的业务代码
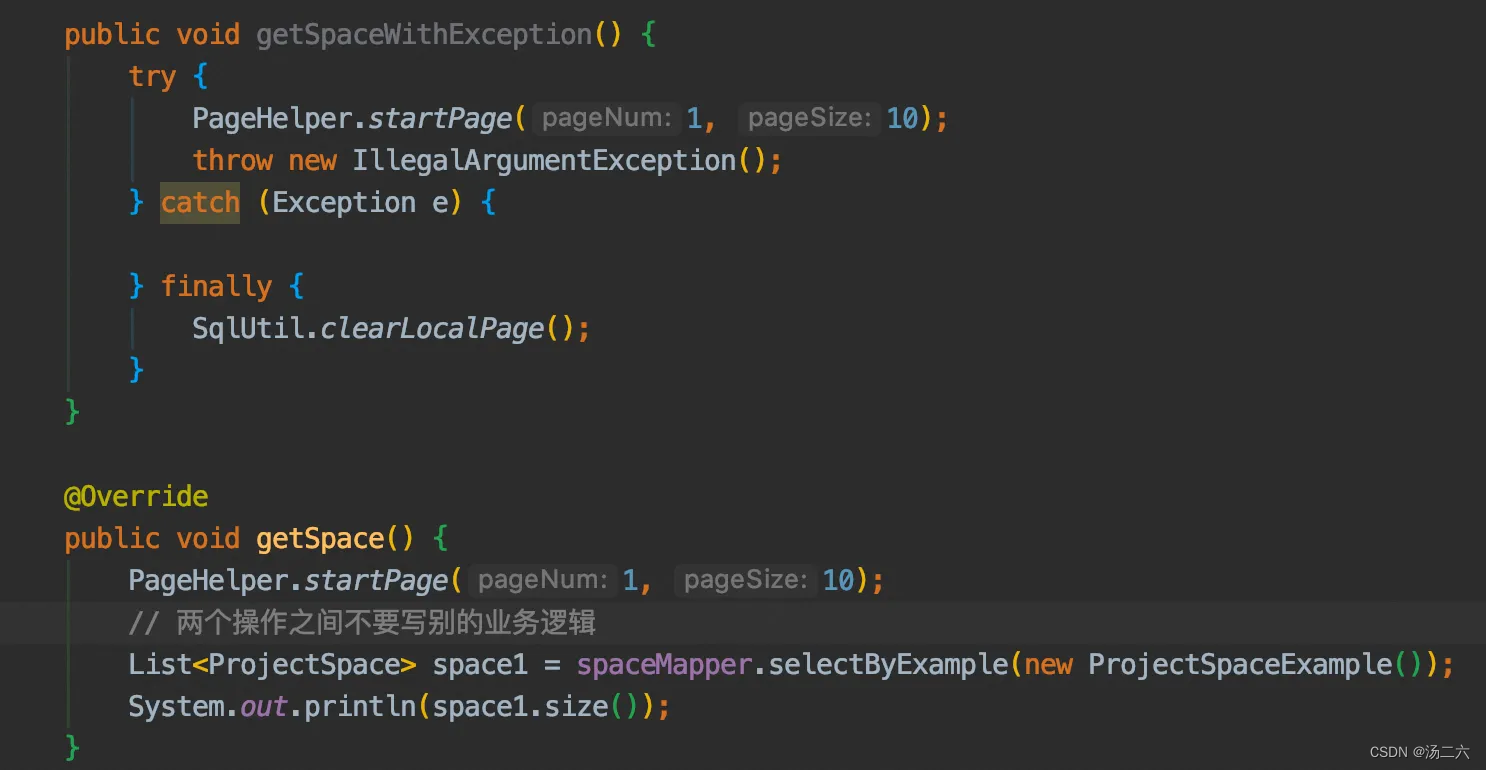
绿框中的内容是针对需要分页的场景的,可以看到,在执行真正的逻辑处理之前,先拿到了BoundSql(存放sql以及参数映射关系)此时的boundSql中的sql语句如下图所示,后面通过执行parser.setParameter方法将args[1]中原来的值替换成了分页信息。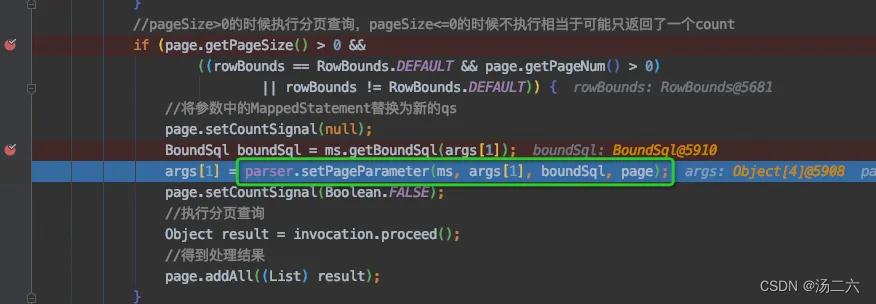
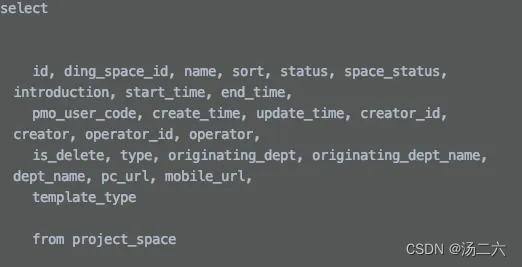
接着会执行invocation.proceed(),这里会回到executor.query方法,这里是首先生成boundSql,然后生成唯一的key,最后做查询。重点分析一下第一步,看怎么拓展原来的boundSql。
一路debug可以进入PageDynamicSqlSource#getPageBoundSql,这里主要是去获取MySqlParser里的pageSql,这里对原来的sql增加了limit属性。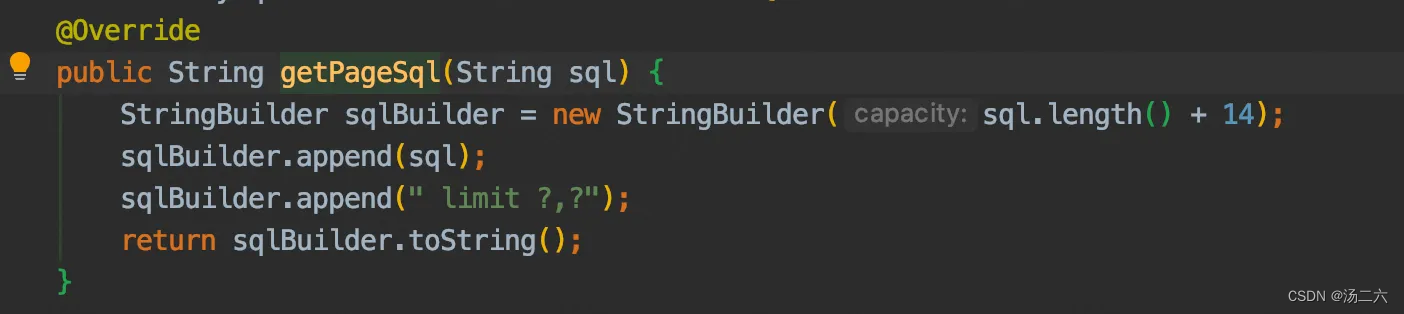
获取了boundSql后,执行query方法的时候,就会把ParameterMapping中的参数映射到预编译的位置,从而达到分页。
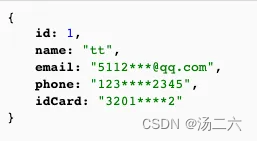
问题3:如果需要对返回的数据做脱敏处理,可以怎么实现?
在上述回答哪些地方调用了pluginAll的时候,有这么一张图,这张图分别是对参数、返回结果等的增强,那么想要实现数据脱敏,就可以照着PageHelper的原理,自己写一个Interceptor,拦截所有的ResultSetHandler,对返回的结果进行处理,核心代码见最后的章节。
4. 总结
- PageHelper分页操作最好紧挨着数据库操作
- 执行成功的情况下,PageHelper仅对最临近它的sql起效
- 可以自定义Interceptor来实现拦截器,对sql的语句、执行器、返回结果进行拦截
5. 核心代码
配置拦截器
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<plugins>
<plugin interceptor="com.tyy.config.MyBatisInterceptorConfig"/>
</plugins>
</configuration>定义脱敏注解,只有需要脱敏的字段才需要加这个注解
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Desensitization {
DesensitizationRule type();
}拦截器配置类(核心),拦截ResultSetHandler的handleResultSets方法,对返回的结果做脱敏处理
@Component
@Intercepts(
{@Signature(type = ResultSetHandler.class, method = "handleResultSets", args = {Statement.class})}
)
public class MyBatisInterceptorConfig implements Interceptor {
@Override
public Object intercept(Invocation invocation) {
try {
// 返回结果
Object proceed = invocation.proceed();
// 对结果进行解析
return DesensitizationUtil.desensitization(proceed);
} catch (Exception e) {
}
return null;
}
@Override
public Object plugin(Object target) {
if (target instanceof ResultSetHandler) {
return Plugin.wrap(target, this);
}
return target;
}
@Override
public void setProperties(Properties properties) {
}
}结果展示















 1092
1092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









