







1. 系统监控的综合思路
好的系统需要监控,监控包括系统和应用两部分,系统监控包括整体资源的使用情况,比如CPU、内存、磁盘和文件系统以及网络等;应用监控包含应用程序内部的各种运行状态,比如进程的CPU、磁盘IO等整体运行情况,也需要包括接口的调用耗时、执行过程中的错误、内部对象的内存使用。
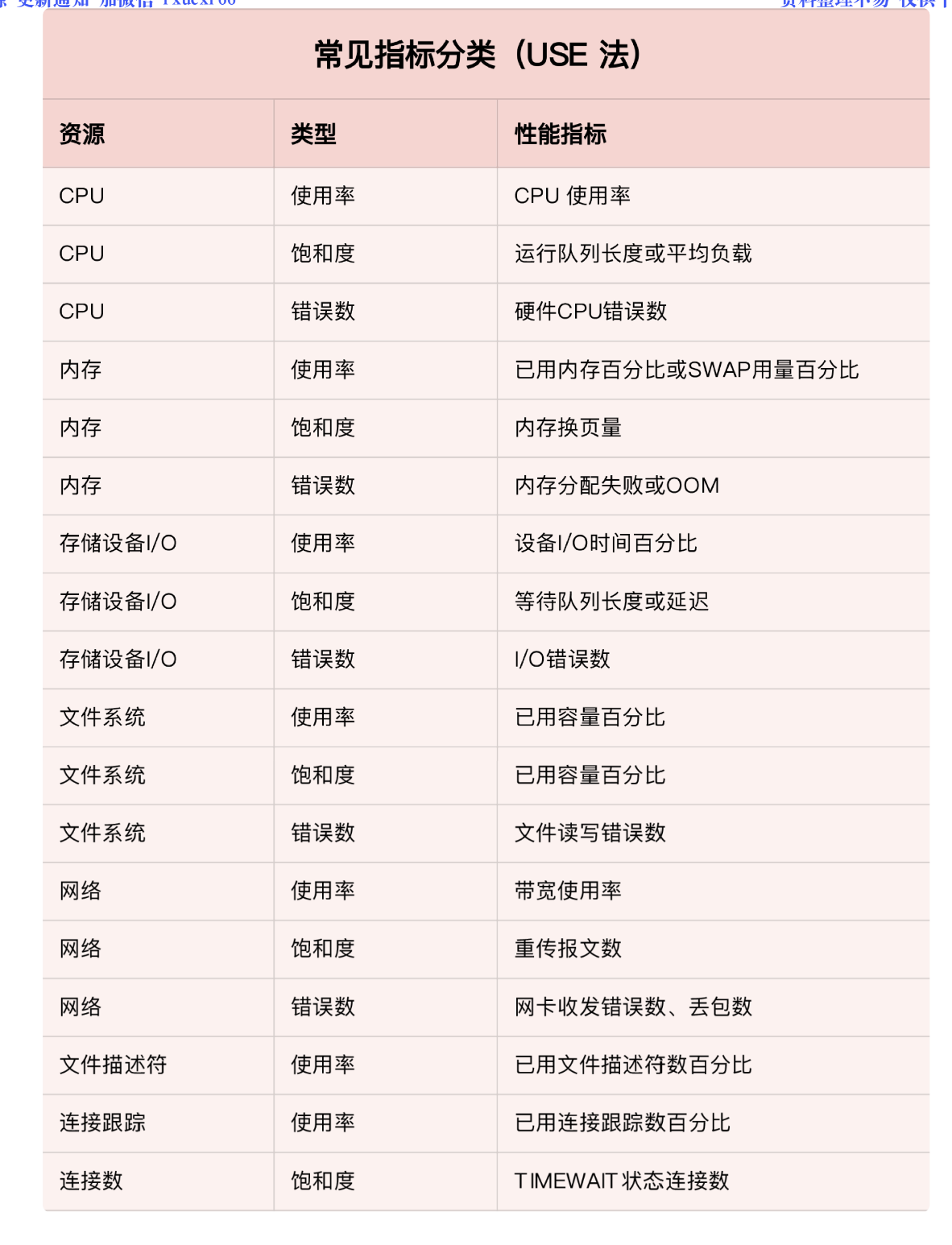
USE法适合系统监控,但不一定适合应用监控,比如应用监控的cpu使用率很低,但因为存在死锁、慢sql、rpc调用超时等问题。
USE 法
- 使用率,表示资源用于服务的时间或容量百分比。100% 的使用率,表示容量已经用尽或者全部时间都用于服务。
- 饱和度,表示资源的繁忙程度,通常与等待队列的长度相关。100% 的饱和度,表示资源无法接受更多的请求。
- 错误数表示发生错误的事件个数。错误数越多,表明系统的问题越严重。
2. 应用监控的一般思路
应用监控可以分为指标监控和日志监控两部分,指标监控主要是对一定时间段内性能指标进行测量,然后通过时间序列的方式,进行处理、存储和告警;日志监控可以提供更详细的上下文信息,通常通过ELK技术栈来进行收集、索引和图形化展示。
指标监控
应用程序的核心指标,不再是资源的使用情况,而是请求数、错误率和响应时间。
- 第一个,是应用进程的资源使用情况,比如进程占用的 CPU、内存、磁盘 I/O、网络等。使用过多的系统资源,导致应用程序响应缓慢或者错误数升高,是一个最常见的性能问题。
- 第二个,是应用程序之间调用情况,比如调用频率、错误数、延时等。由于应用程序并不是孤立的,如果其依赖的其他应用出现了性能问题,应用自身性能也会受到影响。
- 第三个,是应用程序内部核心逻辑的运行情况,比如关键环节的耗时以及执行过程中的错误等。由于这是应用程序内部的状态,从外部通常无法直接获取到详细的性能数据。所以,应用程序在设计和开发时,就应该把这些指标提供出来,以便监控系统可以了解其内部运行状态。
日志监控
ELK
3. 分析性能问题的一般步骤
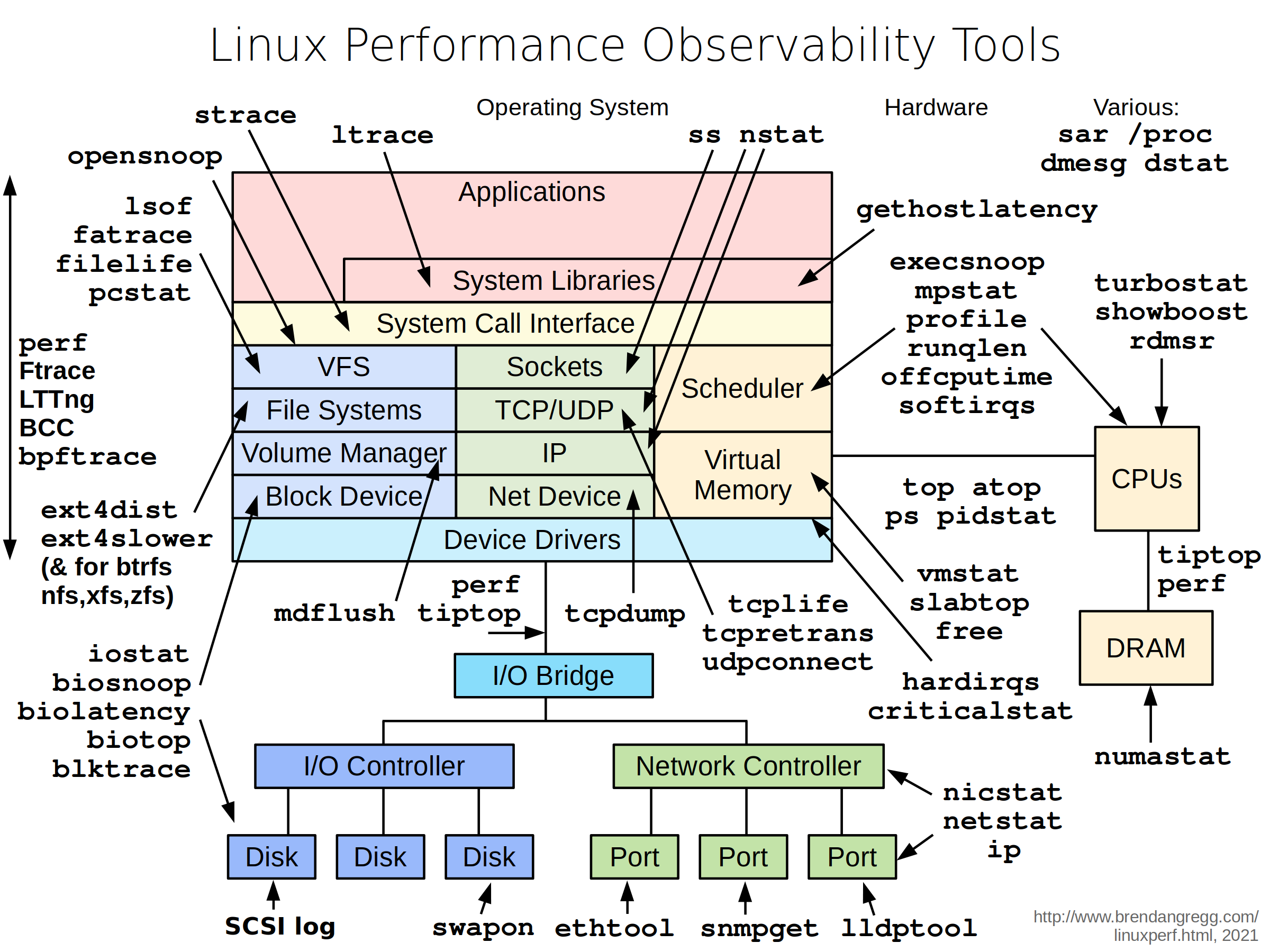
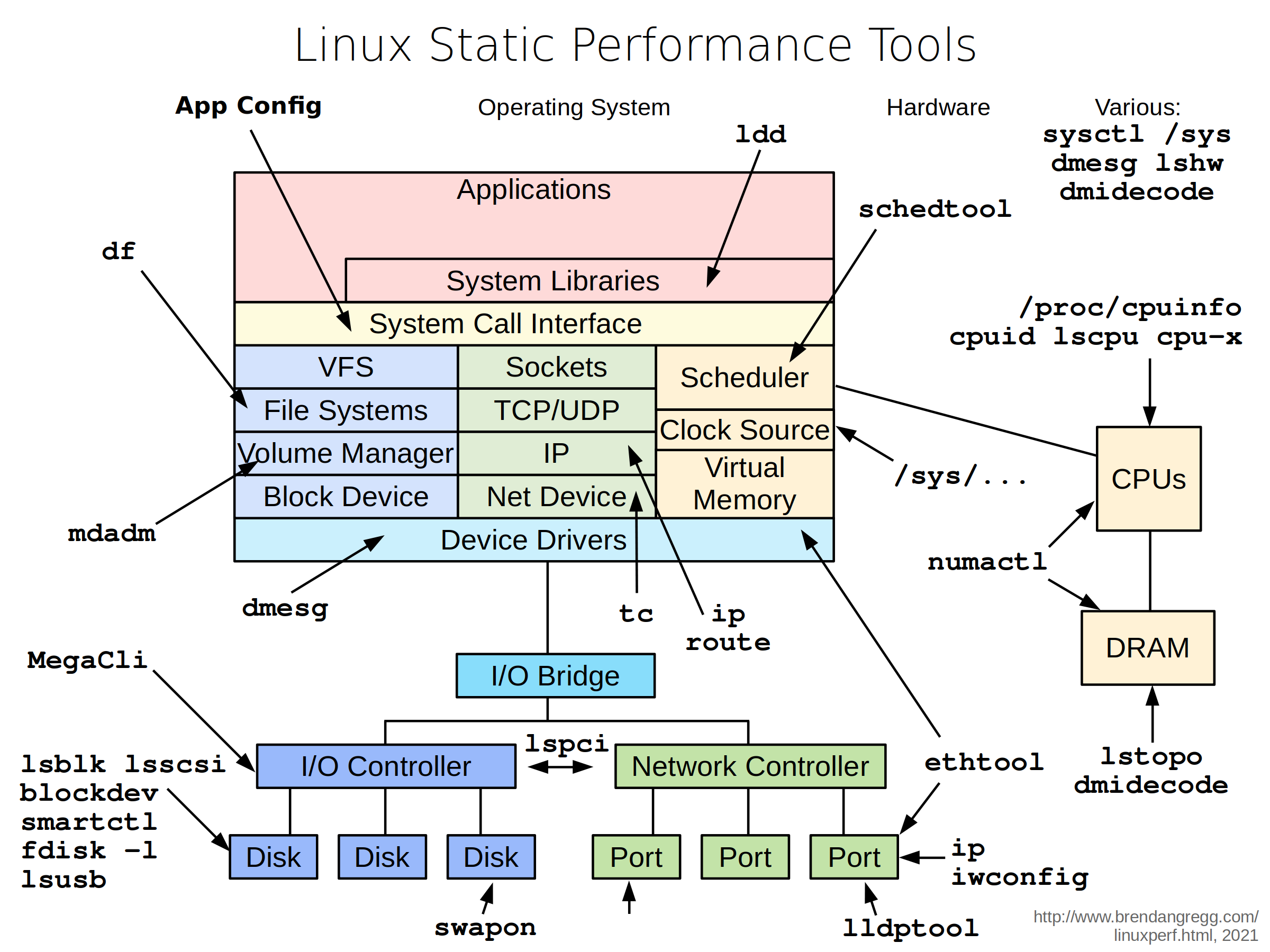
当确定了监控指标后,当系统的运行数据超过了设定的指标后,那么怎么分析性能问题呢?下面从系统资源瓶颈和应用瓶颈入手分析。
3.1 系统资源瓶颈
系统资源的瓶颈,可以通过USE法来衡量,系统的资源分为硬件资源(cpu、网络
、内存、io、文件)和软件资源(文件描述符、连接跟总数、套接字缓冲区大小)两大类。
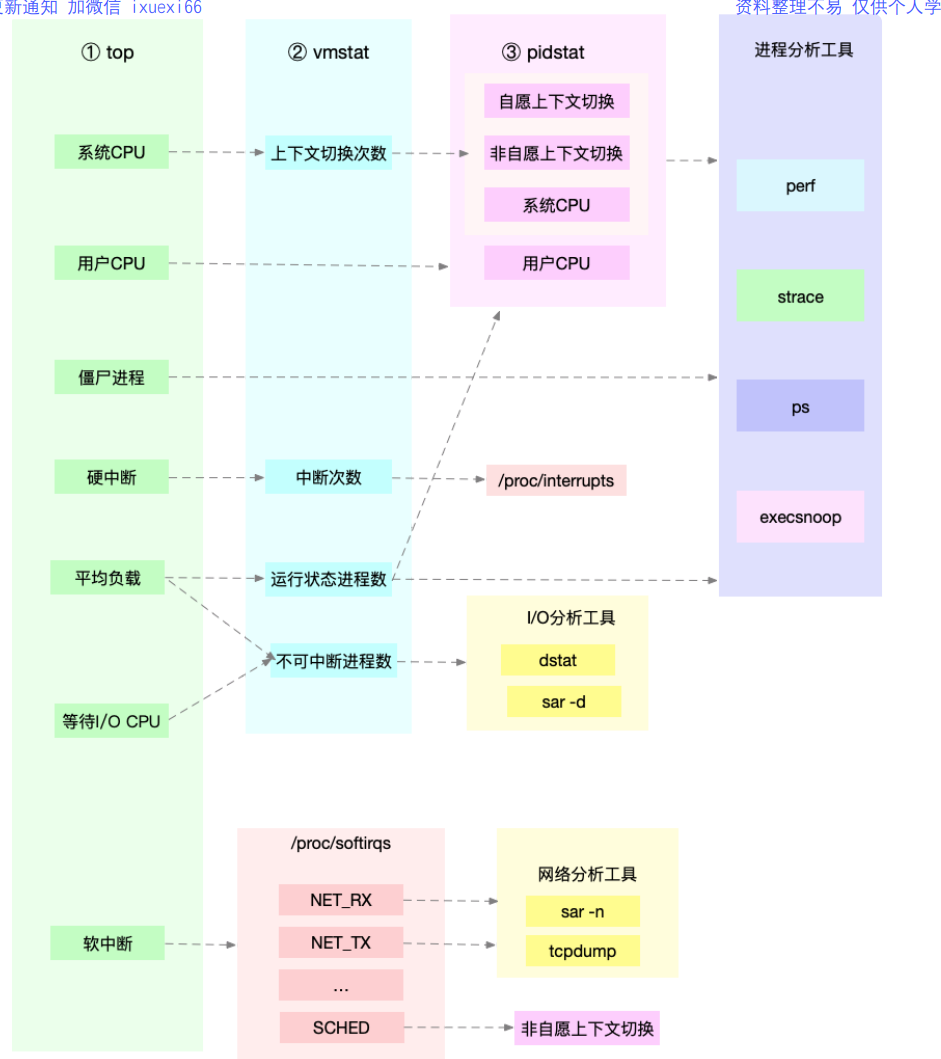
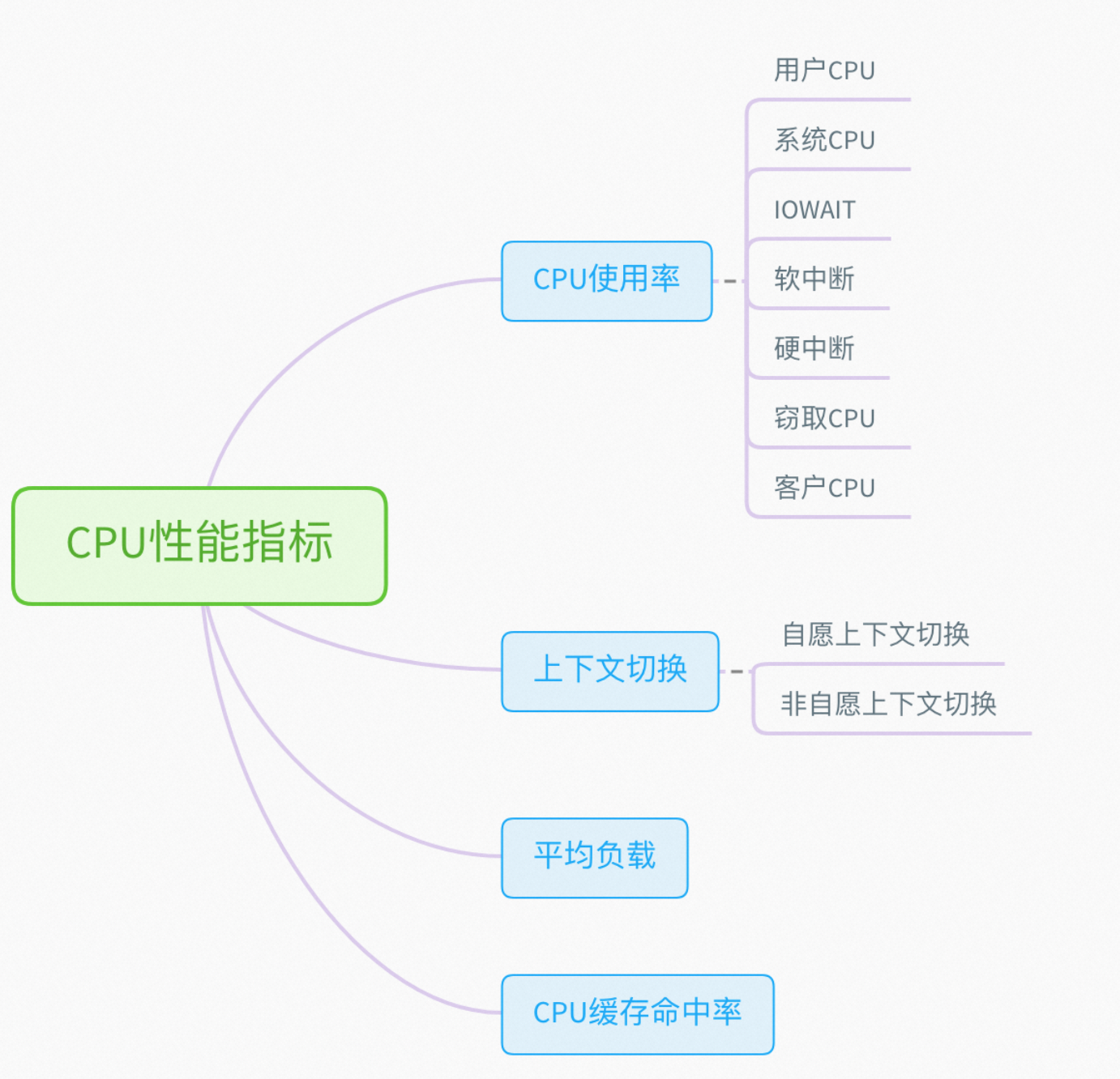
3.1.1 CPU性能分析
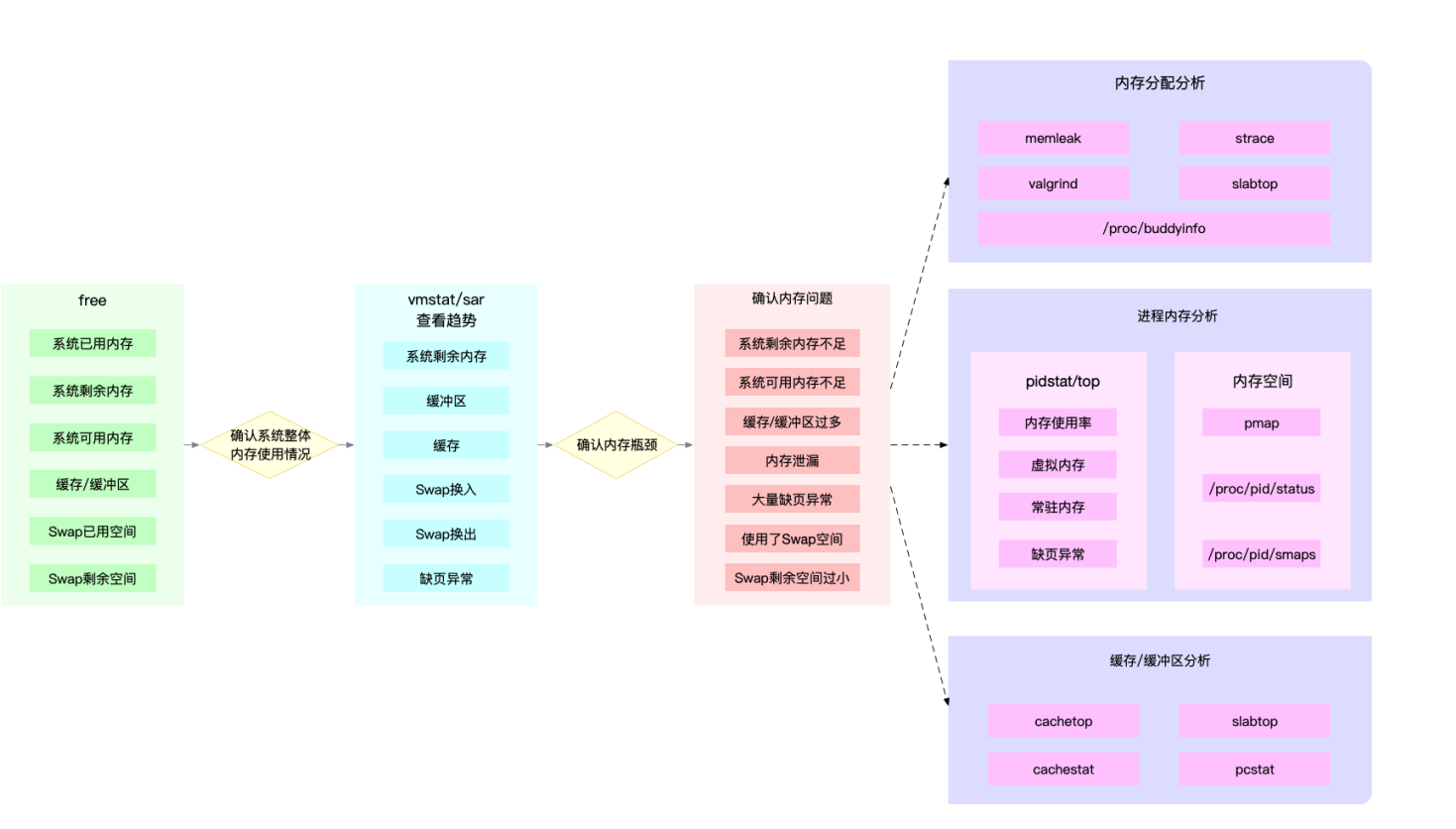
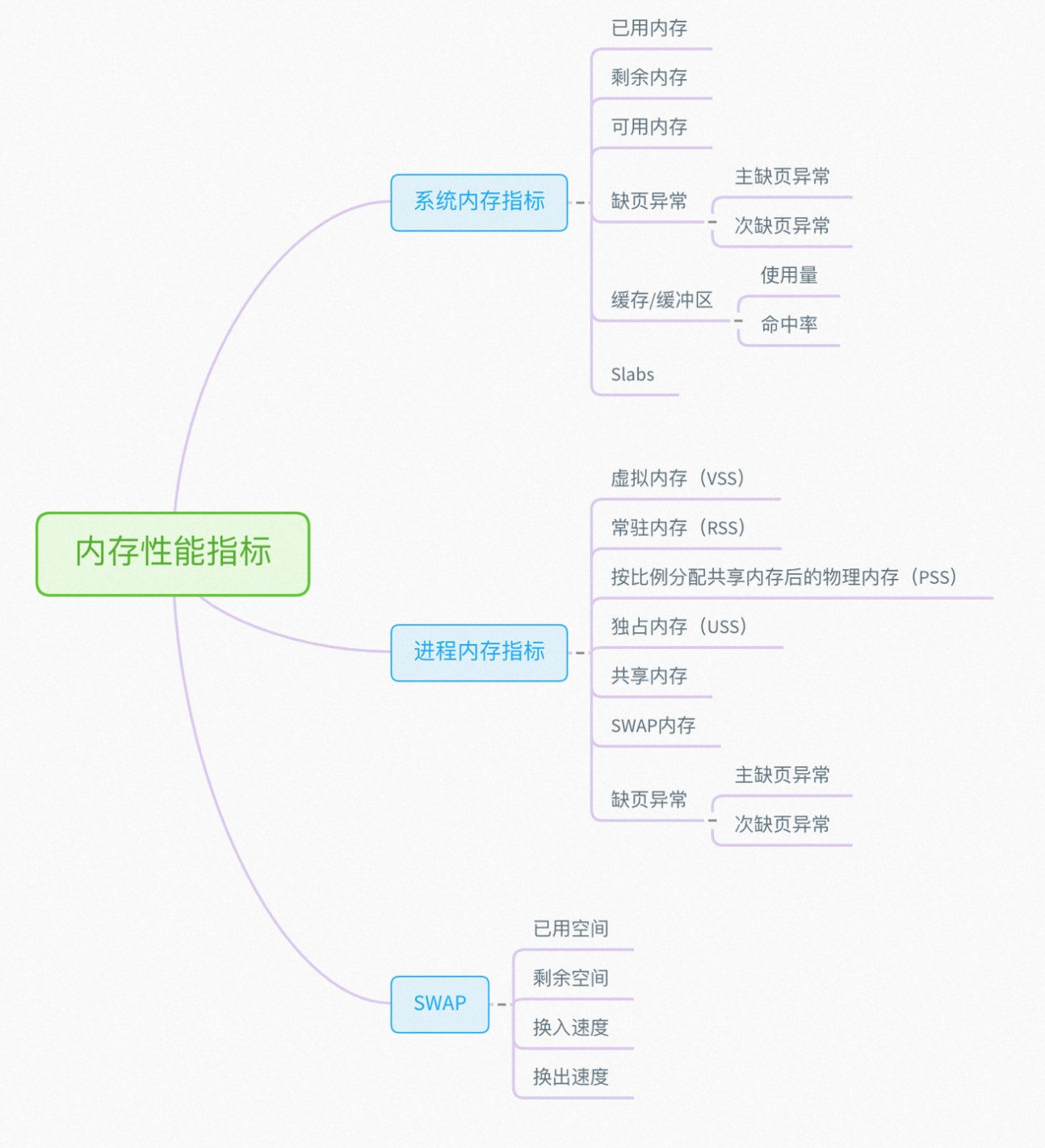
3.1.2 内存性能分析
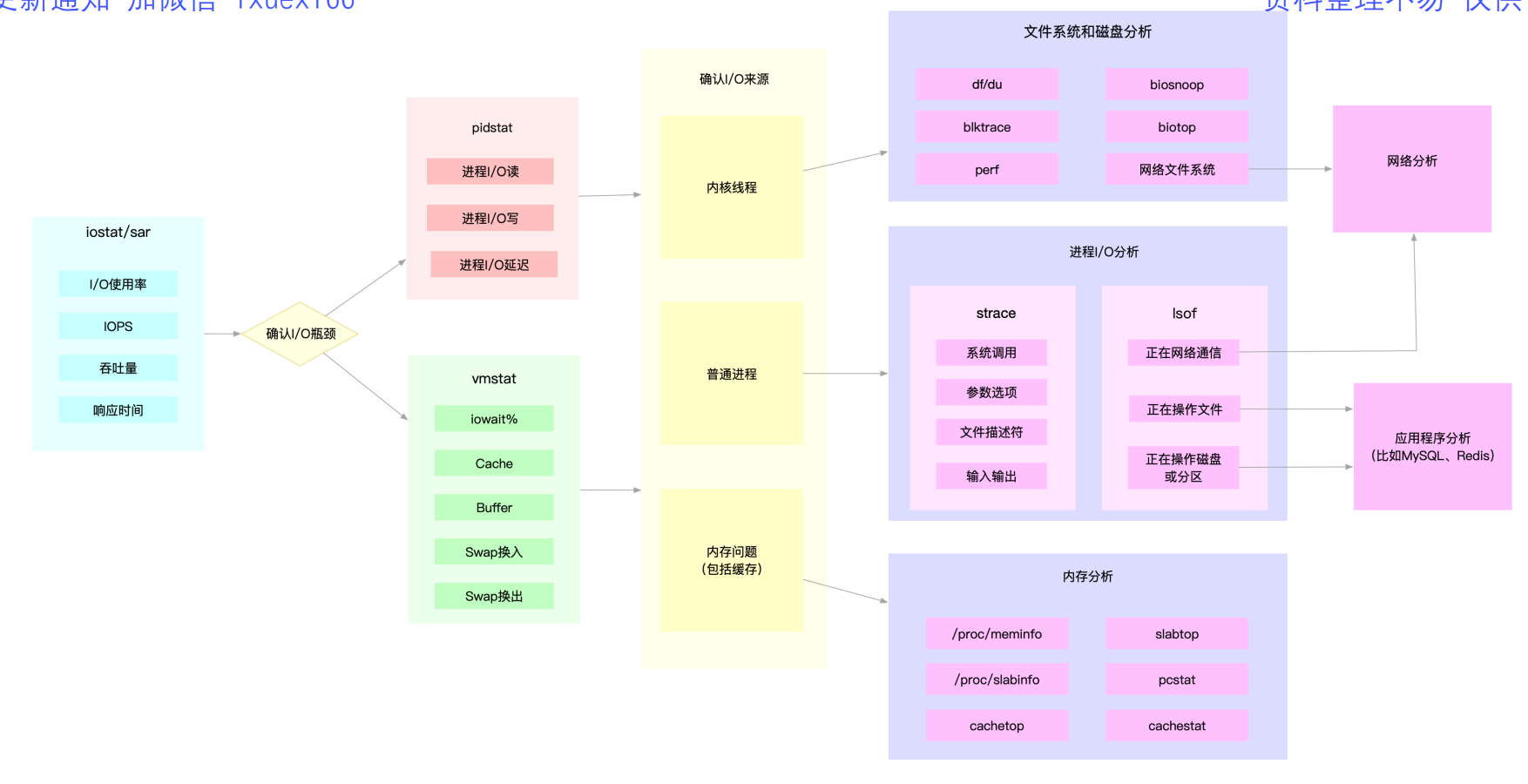
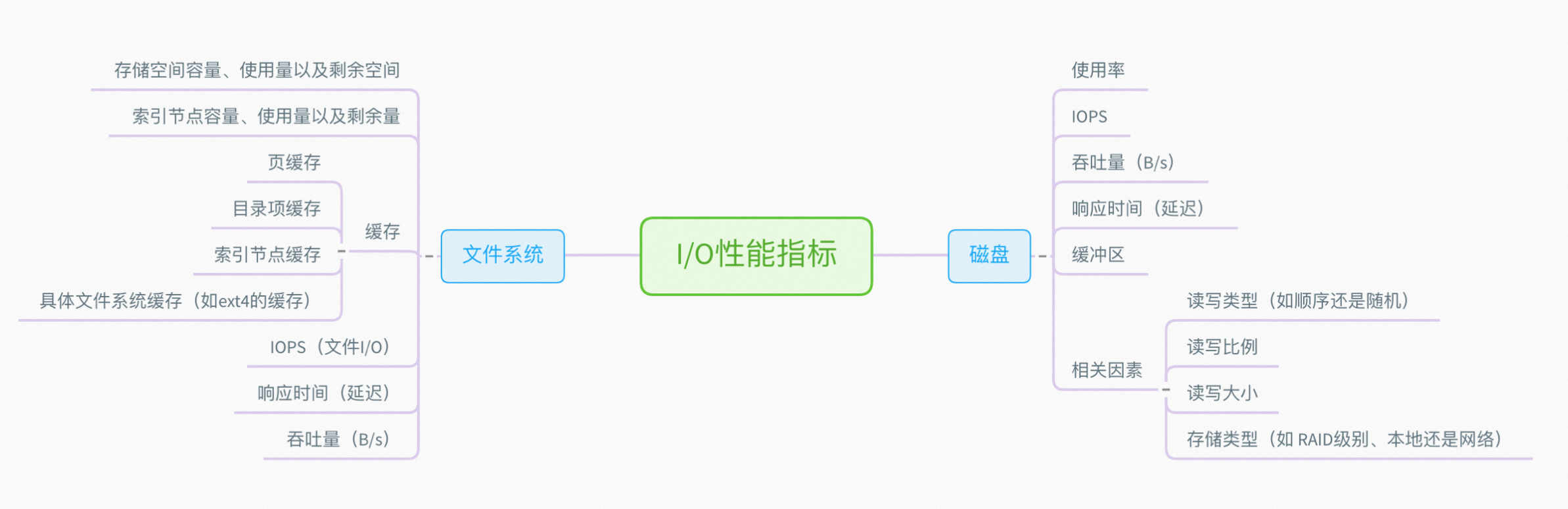
3.1.3 磁盘和文件系统IO性能分析
3.1.4 网络性能分析
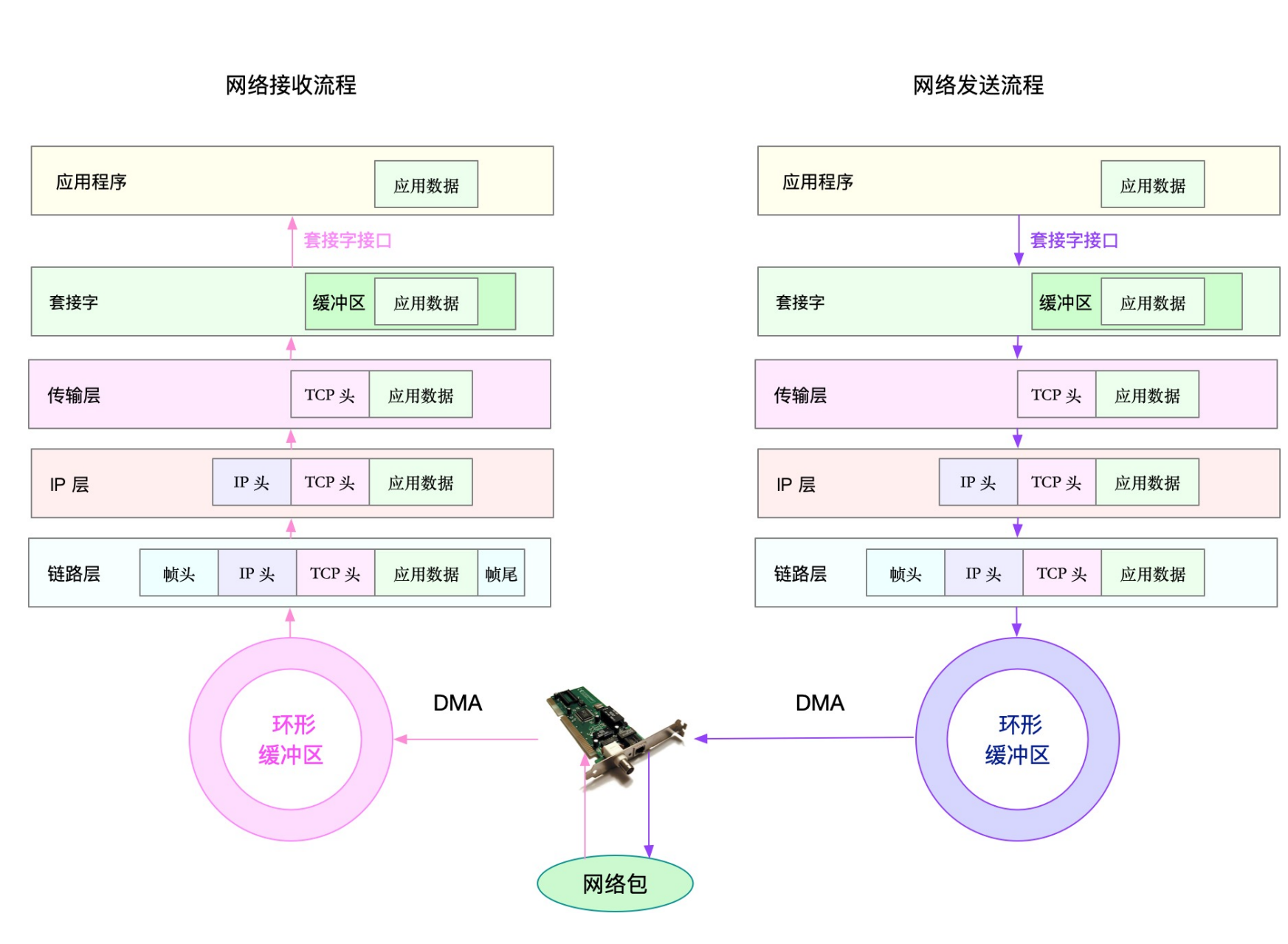
要分析网络的性能,自然也是要从这几个协议层入手,通过使用率、饱和度以及错误数这几类 性能指标,观察是否存在性能问题。比如 :
- 在链路层,可以从网络接口的吞吐量、丢包、错误以及软中断和网络功能卸载等角度分析;
- 在网络层,可以从路由、分片、叠加网络等角度进行分析;
- 在传输层,可以从 TCP、UDP 的协议原理出发,从连接数、吞吐量、延迟、重传等角度进行 分析;
- 在应用层,可以从应用层协议(如 HTTP 和 DNS)、请求数(QPS)、套接字缓存等角度进 行分析。
3.2 应用程序瓶颈
最典型的应用程序性能问题,就是吞吐量下降、错误率升高以及响应时间增大
应用程序性能瓶颈主要是三个来源:
- 资源瓶颈;比如cpu、内存、io、网络等
- 依赖服务的瓶颈:比如数据库、分布式缓存、直接或者间接调用的服务出现了性能问题
- 应用自身的性能问题:多线程处理不当、死锁、复杂度过高等
4. 优化性能问题的一般方法
4.1 系统优化
4.1.1 cpu优化
CPU性能优化的核心,在于排除所有不必要的工作、充分利用CPU缓存并减少进程调度对性能的影响。
优化方法:
- 把进程绑定到一个或者多个cpu上,充分利用cpu缓存的本地性,减少进程间的相互影响
- 为中断处理程序开启多个cpu负载均衡,以便在发生大量中断的适合,充分利用多cpu优势分摊负载
- 使用cgroups等方法,为进程设置资源限制,避免多个进程消耗过多的cpu,同时为核心应用程序设置更高的优先级,减少低优先级任务的影响
4.1.2 内存优化
- 除非有必要,Swap 应该禁止掉。这样就可以避免 Swap 的额外 I/O ,带来内存访问 变慢的问题。
- 使用 Cgroups 等方法,为进程设置内存限制。这样就可以避免个别进程消耗过多内 存,而影响了其他进程。对于核心应用,还应该降低 oom_score,避免被 OOM 杀死。
- 使用大页、内存池等方法,减少内存的动态分配,从而减少缺页异常。
4.1.3 磁盘和文件系统IO优化
- 也是最简单的方法,通过 SSD 替代 HDD、或者使用 RAID 等方法,提升 I/O 性能。
- 针对磁盘和应用程序 I/O 模式的特征,选择最适合的 I/O 调度算法。比如,SSD 和虚 拟机中的磁盘,通常用的是 noop 调度算法;而数据库应用,更推荐使用 deadline 算法。
- 优化文件系统和磁盘的缓存、缓冲区,比如优化脏页的刷新频率、脏页限额,以及内核 回收目录项缓存和索引节点缓存的倾向等等。
4.1.3 网络优化
首先,从内核资源和网络协议的角度来说,我们可以对内核选项进行优化,比如:
- 你可以增大套接字缓冲区、连接跟踪表、最大半连接数、最大文件描述符数、本地端口范围等 内核资源配额;
- 也可以减少 TIMEOUT 超时时间、SYN+ACK 重传数、Keepalive 探测时间等异常处理参数; 还可以开启端口复用、反向地址校验,并调整 MTU 大小等降低内核的负担。
其次,从网络接口的角度来说,我们可以考虑对网络接口的功能进行优化,比如:
- 你可以将原来 CPU 上执行的工作,卸载到网卡中执行,即开启网卡的 GRO、GSO、RSS、 VXLAN 等卸载功能;
- 也可以开启网络接口的多队列功能,这样,每个队列就可以用不同的中断号,调度到不同 CPU 上执行;
- 还可以增大网络接口的缓冲区大小以及队列长度等,提升网络传输的吞吐量。
最后,在极限性能情况(比如 C10M)下,内核的网络协议栈可能是最主要的性能瓶颈,所以, 一般会考虑绕过内核协议栈。
- 你可以使用 DPDK 技术,跳过内核协议栈,直接由用户态进程用轮询的方式,来处理网络请 求。同时,再结合大页、CPU 绑定、内存对齐、流水线并发等多种机制,优化网络包的处理效 率。
- 你还可以使用内核自带的 XDP 技术,在网络包进入内核协议栈前,就对其进行处理。这样,也 可以达到目的,获得很好的性能。
4.2 应用程序优化
在观察性能指标时,你应该先查看应用程序的响应时间、吞吐量以及错误率等指标,因为它们才是性能优化要解决的终极问题。以终为始,从这些角度出发,你一定能想到很多优化方法,而我比较推荐下面几种方法。
- 第一,从 CPU 使用的角度来说,简化代码、优化算法、异步处理以及编译器优化等,都是常用 的降低 CPU 使用率的方法,这样可以利用有限的 CPU 处理更多的请求。
- 第二,从数据访问的角度来说,使用缓存、写时复制、增加 I/O 尺寸等,都是常用的减少磁盘 I/O 的方法,这样可以获得更快的数据处理速度。
- 第三,从内存管理的角度来说,使用大页、内存池等方法,可以预先分配内存,减少内存的动 态分配,从而更好地内存访问性能。
- 第四,从网络的角度来说,使用 I/O 多路复用、长连接代替短连接、DNS 缓存等方法,可以优 化网络 I/O 并减少网络请求数,从而减少网络延时带来的性能问题。
- 第五,从进程的工作模型来说,异步处理、多线程或多进程等,可以充分利用每一个 CPU 的处 理能力,从而提高应用程序的吞吐能力。















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









