







学完List本来应该继续学Set的,但是由于Set的底层就是靠Map实现的,所以我们必须先了解Map。
前面的数组、链表那是正规学过的,哈希表是自学,树也仅仅停留在二叉排序树,这篇理解的比较浅薄,还望指正。
一.Map接口
德国哲学家莱布尼茨说过:“世上没有两片完全相同的树叶。”,在以Map为接口的容器里也同样符合这个道理。在这个领域中,人为的把数据内部(或者说与该数据有关联的)一个属性用来作为判别不同数据的依据,并“抽离出来”,以组成一个由该属性和该数据组成的“集合”,然后Map接口认为,该属性就是该数据的“化身”。因此,这个属性可不能随便定义,要符合数据的唯一性。
举个例子吧:我们要存储人员信息并实现Map接口,然后人为规定身份证号为刚才说的属性。假设小刚被要求来存储信息,他的身份证号是123456,然后我们发现这个身份证号已经存在,并且原来的信息是小明的,于是我们就会认为现在的小刚就是原来的小明,并且将他现在的信息全部覆盖原有的信息。个人认为类似这种情况在现实生活中非常多,所以Map的应用应该很广泛,也就很重要了。
现在我们来用稍微专业的语句复述一遍:Map就是以“键(key)-值(value) 对”的形式存储数据的(这里的Key对应着刚才说的属性,而Value就是要存储的数据)。Map类中存储的“键值对”通过键来标识,所以“键对象”不能重复(这里的不能重复是不能重复存储的意思,遇见一样的Key,那么新的Value会替换旧的Value值)。
Map 接口的实现类有HashMap、Hashtable( t小写,目前不知道原因,可能是一个单词?)、TreeMap等。
要注意一点的是: Map接口和Collection接口没有关系。

来看看Map接口都有哪些常用方法吧:

老样子,测试一下:
package cn.zjb.test;
import java.util.HashMap;
import java.util.Map;
/**
* 测试Map的常用方法
* @author 张坚波
*
*/
public class TestMap {
public static void main(String[] args) {
Map m=new HashMap();
m.put("A", 90);
m.put("B", 80);
m.put("C", 70);
System.out.println(m);
System.out.println(m.get("B"));
m.remove("B");
System.out.println(m.size());
m.clear();
System.out.println(m.isEmpty());
}
}
运行结果如下:
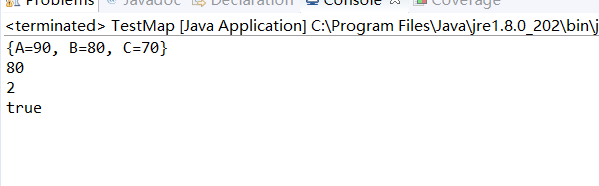
感觉和Collection接口的方法定义的差不多。
二. HashMap
引入:
在之前List的学习里,我们接触了List接口和它的三个实现类,并且知道了它们底层用来存储数据的数据结构——顺序表(数组)、链表。好,咱们不妨复习一下它们各自的优略:
- 数组:操作更简单;因为数组是一段连续的内存空间,简单来说就是可以从上一块内存快速访问到下一块内存,因此查询效率高;但是任意位置增加或者删除元素时需要移动大量元素,因此增删效率低。
- 链表:操作更复杂些;因为链表的每个节点的内存空间是任意分配的,没有物理上的相邻,简单来说就是从上一块内存访问到下一块内存的时间就会变长,因此查询效率低;但是有指针的存在每个节点有一定的独立性,因此增删效率高。
总结完它们的优略,现在有个问题了:数组的一大特点——有显式的索引,仅仅体现在让操作更简单?体现在作为上一块内存和下一块内存之间的标识区分?这显然没有完全利用好它的优势啊!都说物尽其用,咱们也不能眼睁睁看着它大材小用吧!是啊,我们可以直接通过索引值访问到这块连续内存的任意一个内存空间,也就是说我们以后在查询操作时,不用挨个比较、不用指针移动,可以一步到位,按照索引值直接找到我要的那个元素!于是一个问题应运而生:如果我还是按照普通数组(顺序表)的存储方式,从索引0开始依次往后存,那么我的元素存储到的内存区域对应的索引值是和我本身元素值是没有任何关系的,那我又如何知道我的元素存储位置所对应的索引值呢?总不可能死记硬背吧?哈哈,必然是不可能的。转念一想,这不和刚才学的“键值对”正好对应了起来嘛!Key对应着索引值,Value对应着要存储的数据。我们可以通过Key来锁定一个索引值(Key是一个对象,并不能直接对应一个数字,我们需要按照一定的规则进行转换),再把Value放进去。这样以后如果我们要找到这个元素,就可以一步到位了,它就在数组指定索引的地方,按这种方式啊增加删除的效率也很高,这是不是比数组和链表都快?!不过有一点要注意的是,这种方式来存储数据,在放入元素的时候就没有规律了,是分散的,一定要放到指定区域!
HashMap底层实现的哈希表就是运用到了这个思想,那么啥是哈希表呢?
哈希表( hash,音译哈希, 又叫散列 ) 的实现还是数组,我们可以利用下标对元素进行快速索引。新元素的插入位置,是通过哈希函数来确定的。
那么什么是哈希函数呢?
哈希函数又称哈希算法,哈希函数的作用是将一个任意范围的数值经过运算,转化为一个在规定区间的数值。将插入元素的key进行运算后,得到某个索引值,从而确定在数组中的存储位置(每个对象都有地址,这就能变成数值,再转化)。但多个不相同的元素,经过哈希函数运算后,可能得到相同的索引,这就出现了哈希冲突。
那么什么是哈希冲突呢?
哈希冲突又称哈希碰撞,概念其实刚才已经说了🤭多个不相同的元素,经过哈希函数运算后,可能得到相同的索引,从而引起存储位置的冲突。再好的哈希算法在有限长度的哈希表上,都会造成哈希冲突,这很容易理解。
那么怎么解决哈希冲突呢?
最常见的有两种方式:
- 开放地址法:放弃本次求得的索引值,在这个索引值对应的接下来的连续地址里找还没用的内存空间。
- 拉链法:采用数组(哈希表主体)+链表(为了解决哈希冲突而存在)的形式,其中链表多为单链表,图解更清晰:
 HashMap采用的就是这种方法!
HashMap采用的就是这种方法!
我们用源码的方式来详解一下HashMap的底层实现:
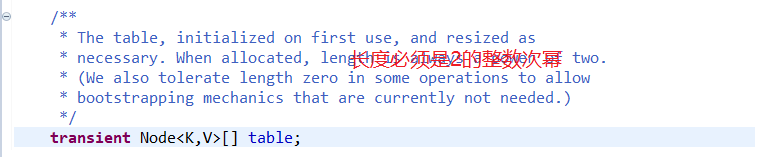
首先就是核心数组table,也称“位桶数组”。它代表着哈希表的主体:
再来就是链式存储结构,它是真正的存储单元:

再就是一些其他默认属性:



扩容后,新数组的长度为原来数组的两倍。数组的默认大小与扩容倍数共同决定了数组长度永远是一个2的幂。
链表存储的优化:
JDK1.8开始,HashMap在存储一个元素时,当对应链表长度大于8时,链表就转换为红黑树,这样又大大提高了查找的效率。(红黑树目前就不深入了,平衡二叉树都没搞懂,这就够我学个好多天了,有空再来吧)

存储数据的过程: 图示更直观

老样子,实现一下自己的HashMap:
package cn.zjb.practice;
/**
* MyHashMap类是用来对数据进行存储和管理的容器类,存储数据的主体结构为哈希表。
* <p>解决哈希冲突的方式是拉链法。
* <p>该类没有实现任何接口,并且是Object的直接子类。
* @author 张坚波
*
*/
public class MyHashMap <K,V> {
/* -------------------inner---------------------*/
/**
* 内部类Node用来存放数据,是存储单位元。
*/
private static class Node<K,V>{
// final int hash; //已移除,不必要存储。
final K key;
V value;
Node<K,V> next;
Node(K key,V value,Node<K,V> next){
this.key=key;
this.value=value;
this.next=next;
}
}
/* -------------------fields---------------------*/
/**
* MyHashMap的核心数组 container。
*/
private Node<K,V>[] container;
/**
* container数组的默认初始值=8。
*/
private static final int DEFAULT_CAPACITY=1<<3;
/**
* 容器所含元素的个数。
*/
private static int length;
/**
* container数组的当前长度。
*/
private static int currentLength;
/**
* 每个元素对应的hash值。
*/
private static int hash;
/**
* 默认的扩容因子=0.75。
*/
private static final double DEFAULT_PERCENTAGE=0.75;
/**
*判断哈希表是否需要扩容。
*/
private static int threshold;
/* ----------------constructor---------------------*/
public MyHashMap(){
container=new Node[DEFAULT_CAPACITY];
currentLength=DEFAULT_CAPACITY;
}
/* ------------------method------------------------*/
/**
* 哈希函数:为每个新对象创建一个索引值。
*/
private int turnToIndex(K key) {
return Math.abs(key.hashCode()%currentLength);
}
/**
* 哈希表的扩容。
*/
private void expend() {
int newlength=currentLength<<1;
int oldlength=currentLength;
currentLength=newlength;
/*
* 哈希表范围变化,哈希函数变化,要重建哈希表
*/
Node<K, V>[] old=container;
container=new Node[currentLength];
int index=0;
length=0; //长度初始化
for(int i=0;i<oldlength;i++) {
if(old[i]==null)
continue;
else {
Node<K,V> temp=old[i];
while(temp!=null) {
put(temp.key,temp.value);
temp=temp.next;
}
}
}
}
/**
* 将新元素放入MyHashMap。
*/
public void put(K key,V value) {
threshold=(int) (currentLength*DEFAULT_PERCENTAGE)+1;
if(length>=threshold)
expend();
hash=turnToIndex(key);
Node<K,V> newNode=new Node<>(key,value,null);
if(container[hash]==null)
container[hash]=newNode;
else {
Node<K,V> temp=container[hash];
while(temp.next!=null&&!temp.key.equals(newNode.key))
temp=temp.next;
if(temp.key.equals(newNode.key)) //是相等而退出循环
temp.value=newNode.value;
else
temp.next=newNode;
}
length++;
}
/**
* 返回哈希表存储了多少个元素。
*/
public int size() {
return length;
}
/**
* 判断哈希表是否为空
*/
public boolean isEmpty() {
if(length==0)
return true;
return false;
}
/**
* 通过键值,找到元素位置。
*/
private Node<K,V> search(K key){
int temp=turnToIndex(key);
if(container[temp]==null)
throw new RuntimeException("该值不存在");
Node<K,V> t=container[temp];
while(t!=null&&!t.key.equals(key))
t=t.next;
if(t.key.equals(key))
return t;
else
throw new RuntimeException("该值不存在");
}
/**
* 通过键值获取元素值。
*/
public V get(K key) {
return search(key).value;
}
/**
* 通过键值,删除某元素。单链表要删除某个节点,必须要有两个指针移动。
*/
public void remove(K key) {
Node<K,V> is=search(key);
int temp=turnToIndex(key);
Node<K,V> pre=container[temp];
if(pre.key.equals(key)) {
container[temp]=pre.next;
}
else {
while(pre.next!=null&&!pre.next.key.equals(key))
pre=pre.next;
pre.next=is.next;
is.next=null; //不必要
}
length--;
}
/**
* 重写toString方法。
*/
@Override
public String toString() {
if(length==0)
return "[]";
StringBuilder sb=new StringBuilder();
sb.append("[");
for(int i=0;i<currentLength;i++) {
if(container[i]==null)
continue;
sb.append(container[i].key+": "+container[i].value+",");
Node<K,V> temp;
temp=container[i].next;
while(temp!=null) {
sb.append(temp.key+": "+temp.value+",");
temp=temp.next;
}
}
sb.setCharAt(sb.length()-1, ']');
return sb.toString();
}
}
package cn.zjb.practice;
/**
* practice包中主方法所在的类
* @author 张坚波
*
*/
public class MainClass {
public static void main(String[] args) {
MyHashMap<String,String> a=new MyHashMap<>();
System.out.println(a.isEmpty()); //true
for(int i=0;i<16;i++)
a.put("zhang"+i, "value"+i);
System.out.println(a.isEmpty()); //false
System.out.println(a.size()); //16
System.out.println(a); //[zhang15: value15,zhang14: value14,zhang13: value13,zhang9: value9,zhang12: value12,zhang8: value8,zhang11: value11,zhang7: value7,zhang10: value10,zhang6: value6,zhang5: value5,zhang4: value4,zhang3: value3,zhang2: value2,zhang1: value1,zhang0: value0]
System.out.println(a.get("zhang0")); //value0
a.remove("zhang15");
System.out.println(a.size()); //15
System.out.println(a); //[zhang14: value14,zhang13: value13,zhang9: value9,zhang12: value12,zhang8: value8,zhang11: value11,zhang7: value7,zhang10: value10,zhang6: value6,zhang5: value5,zhang4: value4,zhang3: value3,zhang2: value2,zhang1: value1,zhang0: value0]
}
}
今天弄得着实有些晚。















 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









