









一、线性最小二乘法
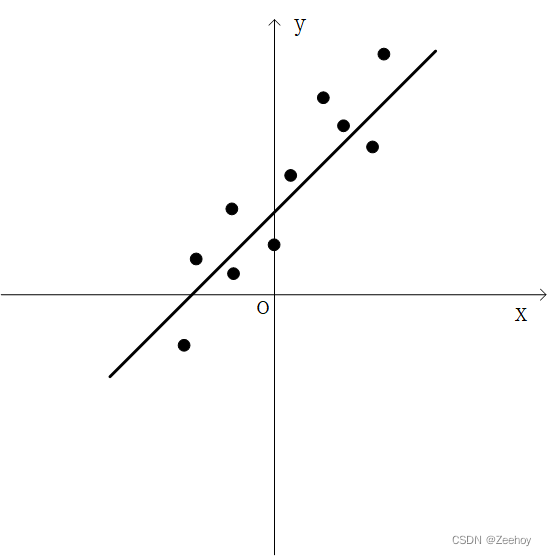
假设平面中存在一组数据点,需要找到一个数学模型(在这里是一条直线)去拟合这组数据点,这就是拟合。
而实际上,样本点的维数不会仅仅是2维的,而可以是任意的 p p p维。
为了不失一般性,假设有一组样本:
D
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
(
x
3
,
y
3
)
,
.
.
.
,
(
x
n
,
y
n
)
}
D=\{(x_1,y_1),(x_2,y_2),(x_3,y_3),...,(x_n,y_n)\}
D={(x1,y1),(x2,y2),(x3,y3),...,(xn,yn)}
x
i
x_i
xi 是一个
p
p
p 维的向量,用于表达第
i
i
i 个样本被观察的
p
p
p 个特征,而
y
i
y_i
yi 表示第
i
i
i 个样本的取值,是一个1维的数值。线性最小二乘法拟合出来的直线也就是样本的所有
p
p
p 维特征值到最终样本取值
y
i
y_i
yi的一个近似的线性映射关系。
这里需要明确一下适用范围,只有当所要拟合的数学模型( y i y_i yi 与 x i x_i xi之间可能的关系) 是线性函数的关系,才能适用线性最小二乘法。
线性函数:
从数学角度来说,对于一个函数 y = f ( x ) y=f(x) y=f(x) 如果它是线性函数,需要满足两个法则:
(1)比例性:对于任意常数 a a a,都有 a y = f ( a x ) ay=f(ax) ay=f(ax) 成立,即将 x x x 扩大 a a a 倍, y y y 也将随之扩大 a a a 倍。
(2)叠加性:若 y 1 = f ( x 1 ) , y 2 = f ( x 2 ) y_1=f(x_1),y_2=f(x_2) y1=f(x1),y2=f(x2)则 y 1 + y 2 = f ( x 1 + x 2 ) y_1+y_2=f(x_1+x_2) y1+y2=f(x1+x2)
但这么看来,只有 y = w x y=wx y=wx属于线性函数,而 y = w x + b y=wx+b y=wx+b 不属于数学角度上的线性函数,但这里暂且把深度学习领域与数学领域分开,在深度学习领域 y = w x + b y=wx+b y=wx+b也属于线性函数。
回到最小二乘法,对于每个样本
x
i
x_i
xi 都可以写成一个
p
p
p 维的向量:
x
i
=
[
x
i
1
x
i
2
x
i
3
.
.
.
x
i
p
]
x_i=\begin{bmatrix} x_{i1}\\ x_{i2}\\ x_{i3}\\ ...\\ x_{ip} \end{bmatrix}
xi=⎣⎢⎢⎢⎢⎡xi1xi2xi3...xip⎦⎥⎥⎥⎥⎤
因此最小二乘法的目标就是估计出一个系数向量:
w
=
[
w
1
w
2
w
3
.
.
.
w
p
]
w=\begin{bmatrix} w_1\\ w_2\\ w_3\\ ...\\ w_p \end{bmatrix}
w=⎣⎢⎢⎢⎢⎡w1w2w3...wp⎦⎥⎥⎥⎥⎤
和一个偏置常数
b
b
b
来建立如下线性关系:
w
T
x
+
b
⇒
y
w^Tx+b\Rightarrow y
wTx+b⇒y
为简化描述,另
b
=
w
0
x
i
0
b=w_0x_{i0}
b=w0xi0,其中
x
i
0
x_{i0}
xi0恒为1,则上述两个向量更新为:
x
i
=
[
1
x
i
1
x
i
2
x
i
3
.
.
.
x
i
p
]
x_i=\begin{bmatrix} 1\\ x_{i1}\\ x_{i2}\\ x_{i3}\\ ...\\ x_{ip} \end{bmatrix}
xi=⎣⎢⎢⎢⎢⎢⎢⎡1xi1xi2xi3...xip⎦⎥⎥⎥⎥⎥⎥⎤
w
=
[
w
0
w
1
w
2
w
3
.
.
.
w
p
]
w=\begin{bmatrix} w_0\\ w_1\\ w_2\\ w_3\\ ...\\ w_p \end{bmatrix}
w=⎣⎢⎢⎢⎢⎢⎢⎡w0w1w2w3...wp⎦⎥⎥⎥⎥⎥⎥⎤
映射关系简化成:
w
T
x
⇒
y
w^Tx\Rightarrow y
wTx⇒y
最小二乘法就是估计参数向量
w
w
w 的一种方法,在最小二乘法中,定义了如下的一个目标函数:
L
(
w
)
=
∑
i
=
1
N
∣
w
T
x
i
−
y
i
∣
2
L(w)=\sum_{i=1}^{N}|w^Tx_i-y_i|^2
L(w)=i=1∑N∣wTxi−yi∣2
可以看出,目标函数 L ( w ) L(w) L(w)是以参数向量 w w w 为自变量的线性函数。
其中, w T x i w^Tx_i wTxi意味着拟合得到的数学模型针对输入值 x i x_i xi得到的输出值,而 y i y_i yi意味着真实情况下, x i x_i xi对应的真实值,也就是实际的观测值。找到一个系数向量 w w w,也就是找到一个数学模型,使得 L ( w ) L(w) L(w)的取值最小,也就是模型的输出值和真实值之间的误差的平方和最小。
具体计算步骤:
L
(
w
)
=
∑
i
=
1
N
∣
w
T
x
i
−
y
i
∣
2
L(w)=\sum_{i=1}^{N}|w^Tx_i-y_i|^2
L(w)=i=1∑N∣wTxi−yi∣2
=
[
w
T
x
1
−
y
1
w
T
x
2
−
y
2
.
.
.
w
T
x
N
−
y
N
]
[
w
T
x
1
−
y
1
w
T
x
2
−
y
2
.
.
.
w
T
x
N
−
y
N
]
=\begin{bmatrix} w^Tx_1-y_1&w^Tx_2-y_2&...&w^Tx_N-y_N \end{bmatrix}\begin{bmatrix} w^Tx_1-y_1\\ w^Tx_2-y_2\\ ...\\ w^Tx_N-y_N \end{bmatrix}
=[wTx1−y1wTx2−y2...wTxN−yN]⎣⎢⎢⎡wTx1−y1wTx2−y2...wTxN−yN⎦⎥⎥⎤
对于第一块向量:
[
w
T
x
1
−
y
1
w
T
x
2
−
y
2
.
.
.
w
T
x
N
−
y
N
]
\begin{bmatrix} w^Tx_1-y_1&w^Tx_2-y_2&...&w^Tx_N-y_N \end{bmatrix}
[wTx1−y1wTx2−y2...wTxN−yN]
=
w
T
[
x
1
x
2
.
.
.
x
N
]
−
[
y
1
y
2
.
.
.
y
N
]
=w^T\begin{bmatrix} x_1&x_2&...&x_N \end{bmatrix}-\begin{bmatrix} y_1&y_2&...&y_N \end{bmatrix}
=wT[x1x2...xN]−[y1y2...yN]
=
w
T
X
T
−
Y
T
=w^TX^T-Y^T
=wTXT−YT
=
[
w
0
w
1
w
2
w
3
.
.
.
w
p
]
[
1
1
1
.
.
.
1
x
11
x
21
x
31
.
.
.
x
N
1
x
12
x
22
x
32
.
.
.
x
N
2
.
.
.
x
1
p
x
2
p
x
3
p
.
.
.
x
N
p
]
–
[
y
1
y
2
y
3
.
.
.
y
N
]
=\begin{bmatrix} w_0& w_1& w_2& w_3& ...& w_p \end{bmatrix}\begin{bmatrix} 1&1&1&...&1\\ x_{11}&x_{21}&x_{31}&...&x_{N1}\\ x_{12}&x_{22}&x_{32}&...&x_{N2}\\ ...\\ x_{1p}&x_{2p}&x_{3p}&...&x_{Np} \end{bmatrix}–\begin{bmatrix} y_1& y_2& y_3& ...& y_N \end{bmatrix}
=[w0w1w2w3...wp]⎣⎢⎢⎢⎢⎡1x11x12...x1p1x21x22x2p1x31x32x3p............1xN1xN2xNp⎦⎥⎥⎥⎥⎤–[y1y2y3...yN]
其中,
X
X
X为N个样本集合:
X
=
[
x
1
T
x
2
T
x
3
T
.
.
.
x
N
T
]
=
[
1
x
11
x
12
x
13
.
.
.
x
1
p
1
x
21
x
22
x
23
.
.
.
x
2
p
1
x
31
x
32
x
33
.
.
.
x
3
p
.
.
.
1
x
N
1
x
N
2
x
N
3
.
.
.
x
N
p
]
X=\begin{bmatrix} x_1^T\\ x_2^T\\ x_3^T\\ ...\\ x_N^T \end{bmatrix}=\begin{bmatrix} 1&x_{11}&x_{12}&x_{13}&...&x_{1p}\\ 1&x_{21}&x_{22}&x_{23}&...&x_{2p}\\ 1&x_{31}&x_{32}&x_{33}&...&x_{3p}\\ ...\\ 1&x_{N1}&x_{N2}&x_{N3}&...&x_{Np} \end{bmatrix}
X=⎣⎢⎢⎢⎢⎡x1Tx2Tx3T...xNT⎦⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎡111...1x11x21x31xN1x12x22x32xN2x13x23x33xN3............x1px2px3pxNp⎦⎥⎥⎥⎥⎤
Y
Y
Y为这N个样本对应的观测值的集合:
Y
=
[
y
1
y
2
y
3
.
.
.
y
N
]
Y=\begin{bmatrix} y_1\\ y_2\\ y_3\\ ...\\ y_N \end{bmatrix}
Y=⎣⎢⎢⎢⎢⎡y1y2y3...yN⎦⎥⎥⎥⎥⎤
而后面一块向量是前面一块的转置,因此:
[
w
T
x
1
−
y
1
w
T
x
2
−
y
2
.
.
.
w
T
x
N
−
y
N
]
=
[
w
T
x
1
−
y
1
w
T
x
2
−
y
2
.
.
.
w
T
x
N
−
y
N
]
T
=
(
w
T
X
T
−
Y
T
)
T
=
X
w
−
Y
\begin{bmatrix} w^Tx_1-y_1\\ w^Tx_2-y_2\\ ...\\ w^Tx_N-y_N \end{bmatrix}= \begin{bmatrix} w^Tx_1-y_1&w^Tx_2-y_2&...&w^Tx_N-y_N \end{bmatrix}^T=(w^TX^T-Y^T)^T=Xw-Y
⎣⎢⎢⎡wTx1−y1wTx2−y2...wTxN−yN⎦⎥⎥⎤=[wTx1−y1wTx2−y2...wTxN−yN]T=(wTXT−YT)T=Xw−Y
最终得到:
L
(
w
)
=
(
w
T
X
T
−
Y
T
)
(
X
w
−
Y
)
L(w)=(w^TX^T-Y^T)(Xw-Y)
L(w)=(wTXT−YT)(Xw−Y)
化简得:
L
(
w
)
=
w
T
X
T
X
w
−
w
T
X
T
Y
−
Y
T
X
w
+
Y
T
Y
L(w)=w^TX^TXw-w^TX^TY-Y^TXw+Y^TY
L(w)=wTXTXw−wTXTY−YTXw+YTY
由于L(w)的最终结果是一个标量(实数),所以式子中的每一项必然也是一个实数,式子内
w
T
X
T
Y
w^TX^TY
wTXTY和
Y
T
X
w
Y^TXw
YTXw是互为转置的关系,又由于两者都是实数,所以可知两者相等,于是式子进一步化简:
L
(
w
)
=
w
T
X
T
X
w
−
2
w
T
X
T
Y
+
Y
T
Y
L(w)=w^TX^TXw-2w^TX^TY+Y^TY
L(w)=wTXTXw−2wTXTY+YTY
L(w)对w求偏导
∂
∂
w
L
(
w
)
\frac{\partial}{\partial{w}}L(w)
∂w∂L(w),当
∂
∂
w
L
(
w
)
=
0
\frac{\partial}{\partial{w}}L(w)=0
∂w∂L(w)=0时,L(w)取得极值,可能是全局最大值、全局最小值或局部极大值、极小值,如果存在多个值,只要逐个比较它们的函数值的大小即可,最终可以寻找到全局最小值(在这里可能不需要,这个目标函数似乎是个凸函数,极值便是全局最小值):
∂
∂
w
L
(
w
)
=
∂
∂
w
(
w
T
X
T
X
w
−
2
w
T
X
T
Y
+
Y
T
Y
)
=
2
X
T
X
w
−
2
X
T
Y
=
0
\frac{\partial}{\partial{w}}L(w)=\frac{\partial}{\partial{w}}(w^TX^TXw-2w^TX^TY+Y^TY)=2X^TXw-2X^TY=0
∂w∂L(w)=∂w∂(wTXTXw−2wTXTY+YTY)=2XTXw−2XTY=0
得:
2
X
T
X
w
−
2
X
T
Y
=
0
2X^TXw-2X^TY=0
2XTXw−2XTY=0
X
T
X
w
=
X
T
Y
X^TXw=X^TY
XTXw=XTY
最终得到用于估计参数向量w的表达式:
w
=
(
X
T
X
)
−
1
X
T
Y
w=(X^TX)^{-1}X^TY
w=(XTX)−1XTY
注意到,最后一步中,对
X
T
X
X^TX
XTX有一个取逆的步骤,因此,存在潜在假设:
X T X X^TX XTX是非奇异矩阵,即 X T X X^TX XTX可逆,即 X T X X^TX XTX的行列式不为零
但
X
T
X
X^TX
XTX在以下情况会是不可逆的:
(1)当样本数量
N
N
N 小于参数向量
w
w
w 的维度的时候
(2)在所有特征中,存在一个特征与另一个特征线性相关或一个特征与若干个特征线性相关的时候
具体来说,矩阵
X
X
X 是
N
×
p
N\times p
N×p 维的矩阵,若存在线性相关的特征,即
p
p
p 个特征之间不是线性无关,即列不满秩:
R
(
X
)
<
p
,
R
(
X
T
)
<
p
,
R
(
X
T
X
)
<
p
R(X)<p,R(X^T)<p,R(X^TX)<p
R(X)<p,R(XT)<p,R(XTX)<p,所以
X
T
X
X^TX
XTX不可逆
X
=
[
x
1
T
x
2
T
x
3
T
.
.
.
x
N
T
]
=
[
1
x
11
x
12
x
13
.
.
.
x
1
p
1
x
21
x
22
x
23
.
.
.
x
2
p
1
x
31
x
32
x
33
.
.
.
x
3
p
.
.
.
1
x
N
1
x
N
2
x
N
3
.
.
.
x
N
p
]
X=\begin{bmatrix} x_1^T\\ x_2^T\\ x_3^T\\ ...\\ x_N^T \end{bmatrix}=\begin{bmatrix} 1&x_{11}&x_{12}&x_{13}&...&x_{1p}\\ 1&x_{21}&x_{22}&x_{23}&...&x_{2p}\\ 1&x_{31}&x_{32}&x_{33}&...&x_{3p}\\ ...\\ 1&x_{N1}&x_{N2}&x_{N3}&...&x_{Np} \end{bmatrix}
X=⎣⎢⎢⎢⎢⎡x1Tx2Tx3T...xNT⎦⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎡111...1x11x21x31xN1x12x22x32xN2x13x23x33xN3............x1px2px3pxNp⎦⎥⎥⎥⎥⎤
因此,当出现不可逆的情况时,有如下解决方法:
(1)筛选出线性无关的特征,保证特征之间是线性无关的
(2)增加样本数量,保证样本数量大于特征维度(参数向量w的维度)(样本数据的维度)
(3)采用正则化的方法
二、非线性最小二乘法
1.一阶二阶泰勒展开
当所要拟合的数学模型是非线性的情况时,便不再适用非线性最小二乘法。
假设参数向量
w
w
w (维度仍然是
p
p
p 维)是某个标量非线性数学模型
f
(
x
)
f(x)
f(x) 的参数:
f
(
x
)
:
x
i
∈
R
p
⇒
y
i
∈
R
f(x):x_i\in R^p \Rightarrow y_i\in R
f(x):xi∈Rp⇒yi∈R
与线性最小二乘法类似,需要一个描述模型预测值与真实观测值之间的差距的函数:
f
(
x
i
)
−
y
i
f(x_i)-y_i
f(xi)−yi
需要注意的是,
x
i
x_i
xi 是样本数据,
y
i
y_i
yi 是样本取值,观测结果。于是,在导入数据后,
x
i
x_i
xi 和
y
i
y_i
yi 是已知的,而数学模型
f
(
x
)
f(x)
f(x) 内包含的参数
w
w
w 才是未知的,需要求解的。
因此,上述函数看作是自变量为
w
w
w 的函数:
r
i
(
w
)
r_i(w)
ri(w)
目标函数:
L
(
w
)
=
∑
i
=
1
N
r
i
2
(
w
)
L(w)=\sum_{i=1}^{N}r_i^2(w)
L(w)=i=1∑Nri2(w)
注:每个 r i ( w ) r_i(w) ri(w)是不一样的,在这个以 w w w 为自变量的函数中,它的参数是已知数据 x i x_i xi 和 y i y_i yi ,每次收集的数据都是不一样的,因此每个 r i ( w ) r_i(w) ri(w)是不同的函数。
从线性最小二乘法的步骤可以知道,通过令目标函数的导数为零
d
L
(
w
)
d
w
=
0
\frac{dL(w)}{dw}=0
dwdL(w)=0
求解上述方程,便能得到使目标函数最小的最优值
w
w
w
这个方程是否容易求解,取决于
L
(
w
)
L(w)
L(w)的导函数的形式,如果
L
(
w
)
L(w)
L(w)为简单的线性函数,那么这个问题就是线性最小二乘问题。
但是前面已说,
L
(
w
)
L(w)
L(w)并不是线性函数,这使得该方程可能不容易求解。
求解这个方程需要我们知道关于目标函数的全局性质,这在非线性情况下通常是不太可能的,对于此类非线性问题,可以使用迭代的方式,从一个初始值出发,不断更新当前的需要优化的变量,使目标函数逐步下降,具体步骤如下:
1.给定某个初始值
w
0
w_0
w0
2.对于第
k
k
k 次迭代,寻找一个增量
Δ
w
k
\Delta w_k
Δwk,使得
L
(
w
k
+
Δ
w
k
)
<
L
(
w
k
)
L(w_k+\Delta w_k)<L(w_k)
L(wk+Δwk)<L(wk),即目标函数下降
3.若
Δ
w
k
\Delta w_k
Δwk足够小,则停止迭代
4.否则,令
w
k
+
1
=
w
k
+
Δ
w
k
w_{k+1}=w_k+\Delta w_k
wk+1=wk+Δwk,返回第二步
这使得求解导函数为零的问题(全局问题)变成了不断寻找下降增量
Δ
w
k
\Delta w_k
Δwk的问题(局部问题),从而能只关心
L
(
w
)
L(w)
L(w)在迭代值处的局部性质,因此能引入微分的思想:
非
线
性
函
数
在
某
个
值
附
近
的
一
个
小
邻
域
内
,
可
以
视
作
线
性
的
非线性函数在某个值附近的一个小邻域内,可以视作线性的
非线性函数在某个值附近的一个小邻域内,可以视作线性的
具体来说,考虑第
k
k
k 次迭代,假设在
w
k
w_k
wk 处想寻找到一个增量
Δ
w
k
\Delta w_k
Δwk,使得目标函数
L
(
w
)
L(w)
L(w) 下降,通过将目标函数在
w
k
w_k
wk 附近作泰勒展开,近似成线性:
L
(
w
k
+
Δ
w
k
)
≈
L
(
w
k
)
+
J
(
w
k
)
1
×
p
T
(
Δ
w
k
)
p
×
1
+
1
2
Δ
w
k
T
H
(
w
k
)
Δ
w
k
(1)
L(w_k+\Delta w_k)≈L(w_k)+J(w_k)^T_{1×p}(\Delta w_k)_{p×1}+\frac{1}{2}\Delta w_k^TH(w_k)\Delta w_k\tag{1}
L(wk+Δwk)≈L(wk)+J(wk)1×pT(Δwk)p×1+21ΔwkTH(wk)Δwk(1)
其中,
J
(
w
k
)
J(w_k)
J(wk)(特殊情况下的雅可比矩阵、梯度向量、梯度)是
L
(
w
)
L(w)
L(w) 关于
w
w
w 的一阶导数,
H
(
w
k
)
H(w_k)
H(wk) (海森矩阵)则是二阶导数,它们需要在
w
k
w_k
wk 处取值。属于多元微积分课程的知识。贴一下相关概念的表述。


关于式(1)到底是怎么来的:
目标函数:
L
(
w
)
=
∑
i
=
1
N
r
i
2
(
w
)
=
r
1
2
(
w
)
+
r
2
2
(
w
)
+
.
.
.
+
r
N
2
(
w
)
L(w)=\sum_{i=1}^{N}r_i^2(w)=r^2_1(w)+r^2_2(w)+...+r^2_N(w)
L(w)=i=1∑Nri2(w)=r12(w)+r22(w)+...+rN2(w)
引入函数向量:
r
(
w
)
=
[
r
1
(
w
)
r
2
(
w
)
.
.
.
r
N
(
w
)
]
N
×
1
r(w)=\begin{bmatrix} r_1(w)\\ r_2(w)\\ ...\\ r_N(w) \end{bmatrix}_{N×1}
r(w)=⎣⎢⎢⎡r1(w)r2(w)...rN(w)⎦⎥⎥⎤N×1
L
(
w
)
=
r
(
w
)
T
r
(
w
)
L(w)=r(w)^Tr(w)
L(w)=r(w)Tr(w)
目标函数显然是个关于自变量
w
w
w 的多元函数(
w
w
w是个p维参数向量),它在
w
k
w_k
wk 的泰勒展开式:
L
(
w
k
+
Δ
w
k
)
≈
L
(
w
k
)
+
∇
L
(
w
k
)
T
Δ
w
k
+
1
2
Δ
w
k
T
H
(
w
k
)
Δ
w
k
(2)
L(w_k+\Delta w_k)≈L(w_k)+ \nabla L(w_k)^T\Delta w_k+\frac{1}{2}\Delta w_k^TH(w_k)\Delta w_k\tag{2}
L(wk+Δwk)≈L(wk)+∇L(wk)TΔwk+21ΔwkTH(wk)Δwk(2)
∇
L
(
w
k
)
=
[
∂
L
w
1
∂
L
w
2
.
.
.
∂
L
w
p
]
p
×
1
\nabla L(w_k)=\begin{bmatrix} \frac{\partial{L}}{w_1}\\ \\ \frac{\partial{L}}{w_2}\\ \\ ...\\ \\ \frac{\partial{L}}{w_p} \end{bmatrix}_{p×1}
∇L(wk)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡w1∂Lw2∂L...wp∂L⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤p×1
其中:
∂
L
w
i
=
∂
L
r
1
∂
r
1
w
i
+
∂
L
r
2
∂
r
2
w
i
+
.
.
.
+
∂
L
r
N
∂
r
N
w
i
\frac{\partial{L}}{w_i}=\frac{\partial{L}}{r_1}\frac{\partial{r_1}}{w_i}+\frac{\partial{L}}{r_2}\frac{\partial{r_2}}{w_i}+...+\frac{\partial{L}}{r_N}\frac{\partial{r_N}}{w_i}
wi∂L=r1∂Lwi∂r1+r2∂Lwi∂r2+...+rN∂Lwi∂rN
=
[
∂
r
1
w
i
∂
r
2
w
i
.
.
.
∂
r
N
w
i
]
[
∂
L
r
1
∂
L
r
2
.
.
.
∂
L
r
N
]
=\begin{bmatrix} \frac{\partial{r_1}}{w_i}& \frac{\partial{r_2}}{w_i}& ...& \frac{\partial{r_N}}{w_i} \end{bmatrix} \begin{bmatrix} \frac{\partial{L}}{r_1}\\ \frac{\partial{L}}{r_2}\\ ...\\ \frac{\partial{L}}{r_N} \end{bmatrix}
=[wi∂r1wi∂r2...wi∂rN]⎣⎢⎢⎡r1∂Lr2∂L...rN∂L⎦⎥⎥⎤
则:
∇
L
(
w
k
)
=
[
∂
r
1
w
1
∂
r
2
w
1
.
.
.
∂
r
N
w
1
∂
r
1
w
2
∂
r
2
w
2
.
.
.
∂
r
N
w
2
.
.
.
.
.
.
.
.
.
.
.
.
∂
r
1
w
p
∂
r
2
w
p
.
.
.
∂
r
N
w
p
]
[
∂
L
r
1
∂
L
r
2
.
.
.
∂
L
r
N
]
=
[
∂
r
1
w
1
∂
r
2
w
1
.
.
.
∂
r
N
w
1
∂
r
1
w
2
∂
r
2
w
2
.
.
.
∂
r
N
w
2
.
.
.
.
.
.
.
.
.
.
.
.
∂
r
1
w
p
∂
r
2
w
p
.
.
.
∂
r
N
w
p
]
[
2
r
1
2
r
2
.
.
.
2
r
N
]
\nabla L(w_k)= \begin{bmatrix} \frac{\partial{r_1}}{w_1}&\frac{\partial{r_2}}{w_1}&...&\frac{\partial{r_N}}{w_1}\\ \frac{\partial{r_1}}{w_2}&\frac{\partial{r_2}}{w_2}&...&\frac{\partial{r_N}}{w_2}\\ ...&...&...&...\\ \frac{\partial{r_1}}{w_p}&\frac{\partial{r_2}}{w_p}&...&\frac{\partial{r_N}}{w_p} \end{bmatrix} \begin{bmatrix} \frac{\partial{L}}{r_1}\\ \frac{\partial{L}}{r_2}\\ ...\\ \frac{\partial{L}}{r_N} \end{bmatrix}= \begin{bmatrix} \frac{\partial{r_1}}{w_1}&\frac{\partial{r_2}}{w_1}&...&\frac{\partial{r_N}}{w_1}\\ \frac{\partial{r_1}}{w_2}&\frac{\partial{r_2}}{w_2}&...&\frac{\partial{r_N}}{w_2}\\ ...&...&...&...\\ \frac{\partial{r_1}}{w_p}&\frac{\partial{r_2}}{w_p}&...&\frac{\partial{r_N}}{w_p} \end{bmatrix} \begin{bmatrix} 2r_1\\ 2r_2\\ ...\\ 2r_N \end{bmatrix}
∇L(wk)=⎣⎢⎢⎢⎡w1∂r1w2∂r1...wp∂r1w1∂r2w2∂r2...wp∂r2............w1∂rNw2∂rN...wp∂rN⎦⎥⎥⎥⎤⎣⎢⎢⎡r1∂Lr2∂L...rN∂L⎦⎥⎥⎤=⎣⎢⎢⎢⎡w1∂r1w2∂r1...wp∂r1w1∂r2w2∂r2...wp∂r2............w1∂rNw2∂rN...wp∂rN⎦⎥⎥⎥⎤⎣⎢⎢⎡2r12r2...2rN⎦⎥⎥⎤
=
2
J
(
w
)
T
r
(
w
)
=2J(w)^Tr(w)
=2J(w)Tr(w)
2的影响不大,有时候目标函数前会特意设置个
1
2
\frac{1}{2}
21,目的就是抵消此处的2
最终结果:
∇
L
(
w
k
)
=
J
(
w
)
T
r
(
w
)
(3)
\nabla L(w_k)=J(w)^Tr(w)\tag{3}
∇L(wk)=J(w)Tr(w)(3)
其中,
J
(
w
)
J(w)
J(w)就是作为中间变量被引入的函数向量
r
(
w
)
r(w)
r(w)
r
(
w
)
=
[
r
1
(
w
)
r
2
(
w
)
.
.
.
r
N
(
w
)
]
r(w)=\begin{bmatrix} r_1(w)\\ r_2(w)\\ ...\\ r_N(w) \end{bmatrix}
r(w)=⎣⎢⎢⎡r1(w)r2(w)...rN(w)⎦⎥⎥⎤
关于自变量参数向量
w
w
w 的雅可比矩阵。
r
(
w
)
r(w)
r(w) 就是引入的函数向量。
将式(3)代入式(2),最终得到目标函数的泰勒展开式:
L
(
w
k
+
Δ
w
k
)
≈
L
(
w
k
)
+
r
(
w
)
1
×
N
T
J
(
w
)
N
×
p
(
Δ
w
k
)
p
×
1
+
1
2
Δ
w
k
T
H
(
w
k
)
Δ
w
k
(4)
L(w_k+\Delta w_k)≈L(w_k)+ r(w)^T_{1×N}J(w)_{N×p}(\Delta w_k)_{p×1}+\frac{1}{2}\Delta w_k^TH(w_k)\Delta w_k\tag{4}
L(wk+Δwk)≈L(wk)+r(w)1×NTJ(w)N×p(Δwk)p×1+21ΔwkTH(wk)Δwk(4)
与式(1)对比发现,式(1)中的一次项内并没有
r
(
w
)
r(w)
r(w) ,这是因为推导得到式(4)时引用了函数变量
r
(
w
)
r(w)
r(w) ,从而使得符合雅可比矩阵的适用情况,当没有引入函数变量
r
(
w
)
r(w)
r(w) 的时候,
J
(
w
)
J(w)
J(w)(或者说
∇
L
(
w
k
)
\nabla L(w_k)
∇L(wk)) 实际上就是目标函数
L
(
w
)
L(w)
L(w) 关于自变量参数向量
w
w
w 的梯度向量:
∇
L
(
w
k
)
=
J
(
w
)
=
[
∂
L
w
1
∂
L
w
2
.
.
.
∂
L
w
p
]
\nabla L(w_k)=J(w)=\begin{bmatrix} \frac{\partial{L}}{w_1}\\ \\ \frac{\partial{L}}{w_2}\\ \\ ...\\ \\ \frac{\partial{L}}{w_p} \end{bmatrix}
∇L(wk)=J(w)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡w1∂Lw2∂L...wp∂L⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤
简单来说就是,梯度向量是雅可比矩阵的特殊情况。所以式(1)是没有引入函数向量
r
(
w
)
r(w)
r(w)时推导得到的式子,而式(4)更具一般性,是引入函数向量
r
(
2
)
r(2)
r(2) 后推导得到的式子。两个式子中,
J
(
w
)
J(w)
J(w) 的意义不同。
注意:
(1)留意文中向量的横竖,全文中向量都是竖着的列向量,导致某些公式的转置符号可能与网上别的文章的转置符号略有区别。
(2)留意文中矩阵的行列维数,多元函数泰勒展开式的矩阵形式,实际上是把累加的部分写成了矩阵形式
2. Δ w k \Delta w_k Δwk的求解
处理式(1):
L
(
w
k
+
Δ
w
k
)
≈
L
(
w
k
)
+
J
(
w
k
)
T
Δ
w
k
+
1
2
Δ
w
k
T
H
(
w
k
)
Δ
w
k
(1)
L(w_k+\Delta w_k)≈L(w_k)+J(w_k)^T\Delta w_k+\frac{1}{2}\Delta w_k^TH(w_k)\Delta w_k\tag{1}
L(wk+Δwk)≈L(wk)+J(wk)TΔwk+21ΔwkTH(wk)Δwk(1)
在使用泰勒展开后,可以将非线性的目标函数在某个邻域内采用线性多项式逼近,对这个线性多项式的不同处理(如保留一阶项或保留二阶项),取得增量
Δ
w
k
\Delta w_k
Δwk的方向,再指定一个步长
λ
\lambda
λ ,从而保证目标函数下降。求解
Δ
w
k
\Delta w_k
Δwk的不同处理方式,就是非线性最小二乘法的不同方法。
(1)最速下降法
已知梯度方向是函数值增长最快的方向,那么梯度方向的反方向自然是函数值下降最快的方向,如果取增量为反向的梯度,就一定可以保证函数下降(注:梯度即多元函数的一阶导数,即这里的雅可比矩阵
J
(
w
k
)
J(w_k)
J(wk) ):
Δ
w
k
=
−
J
(
w
k
)
\Delta w_k=-J(w_k)
Δwk=−J(wk)
由于讨论都是在第
k
k
k 次迭代进行,并不涉及其他迭代信息,为了简化符号,省略下标
k
k
k:
Δ
w
=
−
J
(
w
)
\Delta w=-J(w)
Δw=−J(w)
(2)牛顿法
最速下降法只保留了泰勒展开的一阶梯度信息,为了更加逼近非线性函数,也可以保留至泰勒展开的二阶梯度信息:
L
(
w
+
Δ
w
)
≈
L
(
w
)
+
J
(
w
)
T
Δ
w
+
1
2
Δ
w
T
H
(
w
)
Δ
w
L(w+\Delta w)≈L(w)+J(w)^T\Delta w+\frac{1}{2}\Delta w^TH(w)\Delta w
L(w+Δw)≈L(w)+J(w)TΔw+21ΔwTH(w)Δw
以处理线性多项式的方式处理上式,对
Δ
w
\Delta w
Δw 求一阶导数,并令结果为0(对线性多项式来说,一阶导数为0处便是极值所在处,也就是最小值可能所在处,如果有多个结果,对多个结果进行比较,最小的那个就是最小值所在处):
J
+
H
Δ
w
=
0
J+H\Delta w=0
J+HΔw=0
解得增量
Δ
w
\Delta w
Δw:
Δ
w
=
H
−
1
(
−
J
)
\Delta w=H^{-1}(-J)
Δw=H−1(−J)
上述的一阶和二阶梯度法都比较直观,利用泰勒展开在迭代点附近用线性的一次或二次多项式近似了目标函数,然后用该线性多项式最小值来猜测目标函数的最小值,这种方法只要目标函数在局部微小区域内是线性的,就能成立。由于微分思想保证非线性函数的局部微小区域确实可以采用线性去逼近,所以这种算法确实是可行的。
但上述两个方法存在一定的缺点,最速下降法过于贪心,在到达最小值的过程中常常走出锯齿路线,增加了迭代次数。
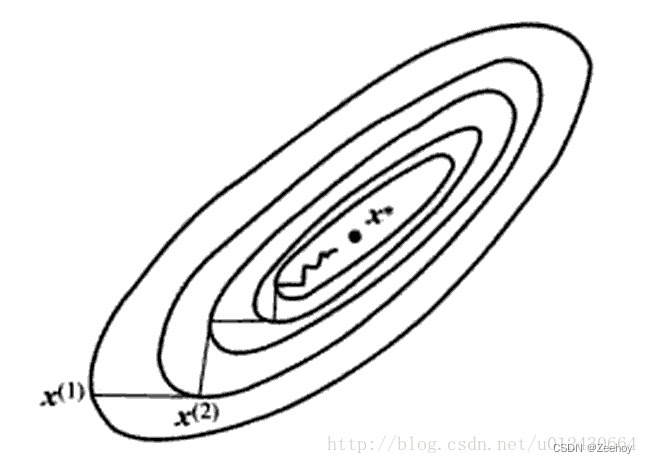
而牛顿法需要计算目标函数的
H
H
H 矩阵,这通常是比较麻烦的,实际上人们更倾向于避免
H
H
H 矩阵的计算,所以提出了几种更实用的方法(高斯牛顿法和列文伯格—马夸尔特法)。
(3)高斯牛顿法
最小二乘法的目标函数(为方便计算,消去求导后可能出现的2,所以前面添加了个系数
1
2
\frac{1}{2}
21):
L
(
w
)
=
1
2
∑
i
=
1
N
r
i
2
(
w
)
L(w)=\frac{1}{2}\sum_{i=1}^{N}r_i^2(w)
L(w)=21i=1∑Nri2(w)
记得之前引入的
r
(
w
)
=
[
r
1
(
w
)
r
2
(
w
)
.
.
.
r
N
(
w
)
]
r(w)=\begin{bmatrix} r_1(w)\\ r_2(w)\\ ...\\ r_N(w) \end{bmatrix}
r(w)=⎣⎢⎢⎡r1(w)r2(w)...rN(w)⎦⎥⎥⎤后续会用到。
之前的方法都是针对目标函数
L
(
w
)
L(w)
L(w)进行泰勒展开,而这个目标函数是多个非线性函数
r
i
(
w
)
r_i(w)
ri(w) 的平方的累加和,高斯牛顿的思想是先针对
r
i
(
w
)
r_i(w)
ri(w)
进行一阶的泰勒展开:
r
i
(
w
+
Δ
w
)
≈
r
i
(
w
)
+
J
i
(
w
)
T
Δ
w
r_i(w+\Delta w)≈r_i(w)+J_i(w)^T\Delta w
ri(w+Δw)≈ri(w)+Ji(w)TΔw
J
i
(
w
)
J_i(w)
Ji(w) 是 非线性函数
r
i
(
w
)
r_i(w)
ri(w) 关于 自变量参数向量
w
w
w 的雅可比矩阵,将经过一阶泰勒展开后的
r
i
(
w
)
r_i(w)
ri(w) 代入原目标函数,得到的目标函数如下:
L
(
w
+
Δ
w
)
=
∑
i
=
1
N
1
2
(
r
i
(
w
)
+
J
i
(
w
)
T
Δ
w
)
2
(5)
L(w+\Delta w)=\sum_{i=1}^N\frac{1}{2}(r_i(w)+J_i(w)^T\Delta w)^2\tag{5}
L(w+Δw)=i=1∑N21(ri(w)+Ji(w)TΔw)2(5)
问题转变成了:在此次迭代中(别忘了迭代仍然存在,只是没写下标
k
k
k而已),寻找增量
Δ
w
\Delta w
Δw ,使式(5)在此次迭代中达到最小值。
将式(5)的平方展开,并对 Δ w \Delta w Δw 求一阶导数,并令导数等于 0 ,便能取到使该式子达到最小值时的 Δ w \Delta w Δw 的取值。
先将目标函数的平方展开:
L
(
w
+
Δ
w
)
=
∑
i
=
1
N
1
2
[
r
i
(
w
)
+
J
i
(
w
)
T
Δ
w
)
]
T
[
r
i
(
w
)
+
J
i
(
w
)
T
Δ
w
)
]
L(w+\Delta w)=\sum_{i=1}^N\frac{1}{2}[r_i(w)+J_i(w)^T\Delta w)]^T[r_i(w)+J_i(w)^T\Delta w)]
L(w+Δw)=i=1∑N21[ri(w)+Ji(w)TΔw)]T[ri(w)+Ji(w)TΔw)]
=
∑
i
=
1
N
1
2
[
r
i
2
(
w
)
+
2
r
i
(
w
)
J
i
(
w
)
T
Δ
w
+
Δ
w
T
J
i
(
w
)
J
i
(
w
)
T
Δ
w
]
=\sum_{i=1}^N\frac{1}{2}[ r^2_i(w)+2r_i(w)J_i(w)^T\Delta w+\Delta w^TJ_i(w)J_i(w)^T\Delta w ]
=i=1∑N21[ri2(w)+2ri(w)Ji(w)TΔw+ΔwTJi(w)Ji(w)TΔw]
求上式对
Δ
w
\Delta w
Δw 的导数,并令其为零:
∑
i
=
1
N
J
i
(
w
)
r
i
(
w
)
+
∑
i
=
1
N
J
i
(
w
)
J
i
(
w
)
T
Δ
w
=
0
\sum_{i=1}^NJ_i(w)r_i(w)+\sum_{i=1}^NJ_i(w)J_i(w)^T\Delta w=0
i=1∑NJi(w)ri(w)+i=1∑NJi(w)Ji(w)TΔw=0
将累加形式写成矩阵形式:
第一个累加项:
J
i
(
w
)
=
[
∂
r
i
∂
w
1
∂
r
i
∂
w
2
.
.
.
∂
r
i
∂
w
p
]
J_i(w)= \begin{bmatrix} \frac{\partial r_i}{\partial w1}\\ \\ \frac{\partial r_i}{\partial w2}\\ \\ ...\\ \\ \frac{\partial r_i}{\partial wp} \end{bmatrix}
Ji(w)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡∂w1∂ri∂w2∂ri...∂wp∂ri⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤
r
i
(
w
)
r_i(w)
ri(w) 是第
i
i
i 个样本数据得到的输出值与真实值之间的误差
e
r
r
o
r
error
error,是个标量,是一个数。
J
i
(
w
)
r
i
(
w
)
=
[
r
i
(
w
)
∂
r
i
∂
w
1
r
i
(
w
)
∂
r
i
∂
w
2
.
.
.
r
i
(
w
)
∂
r
i
∂
w
p
]
J_i(w)r_i(w)= \begin{bmatrix} r_i(w)\frac{\partial r_i}{\partial w1}\\ \\ r_i(w)\frac{\partial r_i}{\partial w2}\\ \\ ...\\ \\ r_i(w)\frac{\partial r_i}{\partial wp} \end{bmatrix}
Ji(w)ri(w)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡ri(w)∂w1∂riri(w)∂w2∂ri...ri(w)∂wp∂ri⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤
∑
i
=
1
N
J
i
(
w
)
r
i
(
w
)
=
[
∑
i
=
1
N
r
i
(
w
)
∂
r
i
∂
w
1
∑
i
=
1
N
r
i
(
w
)
∂
r
i
∂
w
2
.
.
.
∑
i
=
1
N
r
i
(
w
)
∂
r
i
∂
w
p
]
\sum_{i=1}^NJ_i(w)r_i(w)= \begin{bmatrix} \sum_{i=1}^Nr_i(w)\frac{\partial r_i}{\partial w1}\\ \\ \sum_{i=1}^Nr_i(w)\frac{\partial r_i}{\partial w2}\\ \\ ...\\ \\ \sum_{i=1}^Nr_i(w)\frac{\partial r_i}{\partial wp} \end{bmatrix}
i=1∑NJi(w)ri(w)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡∑i=1Nri(w)∂w1∂ri∑i=1Nri(w)∂w2∂ri...∑i=1Nri(w)∂wp∂ri⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
=
[
∂
r
1
∂
w
1
∂
r
2
∂
w
1
.
.
.
∂
r
N
∂
w
1
∂
r
1
∂
w
2
∂
r
2
∂
w
2
.
.
.
∂
r
N
∂
w
2
.
.
.
∂
r
1
∂
w
p
∂
r
2
∂
w
p
.
.
.
∂
r
N
∂
w
p
]
[
r
1
(
w
)
r
2
(
w
)
.
.
.
r
N
(
w
)
]
=\begin{bmatrix} \frac{\partial r_1}{\partial w1}&\frac{\partial r_2}{\partial w1}&...&\frac{\partial r_N}{\partial w1}\\ \\ \frac{\partial r_1}{\partial w2}&\frac{\partial r_2}{\partial w2}&...&\frac{\partial r_N}{\partial w2}\\ \\ ...\\ \\ \frac{\partial r_1}{\partial wp}&\frac{\partial r_2}{\partial wp}&...&\frac{\partial r_N}{\partial wp} \end{bmatrix} \begin{bmatrix} r_1(w)\\ \\ r_2(w)\\ \\ ...\\ \\ r_N(w) \end{bmatrix}
=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡∂w1∂r1∂w2∂r1...∂wp∂r1∂w1∂r2∂w2∂r2∂wp∂r2.........∂w1∂rN∂w2∂rN∂wp∂rN⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡r1(w)r2(w)...rN(w)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤
=
J
(
w
)
T
r
(
w
)
=J(w)^Tr(w)
=J(w)Tr(w)
r
(
w
)
r(w)
r(w) 就是上面提到的引入的函数向量,
J
(
w
)
J(w)
J(w) 就是这个函数向量对自变量
p
p
p 维参数向量
w
w
w 的雅克比矩阵。
第二个累加项的系数:
J
i
(
w
)
J
i
(
w
)
T
=
[
∂
r
i
∂
w
1
∂
r
i
∂
w
2
.
.
.
∂
r
i
∂
w
p
]
[
∂
r
i
∂
w
1
∂
r
i
∂
w
2
.
.
.
∂
r
i
∂
w
p
]
J_i(w)J_i(w)^T= \begin{bmatrix} \frac{\partial r_i}{\partial w1}\\ \\ \frac{\partial r_i}{\partial w2}\\ \\ ...\\ \\ \frac{\partial r_i}{\partial wp} \end{bmatrix} \begin{bmatrix} \frac{\partial r_i}{\partial w1}& \frac{\partial r_i}{\partial w2}& ...& \frac{\partial r_i}{\partial wp} \end{bmatrix}
Ji(w)Ji(w)T=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡∂w1∂ri∂w2∂ri...∂wp∂ri⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤[∂w1∂ri∂w2∂ri...∂wp∂ri]
=
[
∂
r
i
∂
w
1
∂
r
i
∂
w
1
∂
r
i
∂
w
1
∂
r
i
∂
w
2
.
.
.
∂
r
i
∂
w
1
∂
r
i
∂
w
p
∂
r
i
∂
w
2
∂
r
i
∂
w
1
∂
r
i
∂
w
2
∂
r
i
∂
w
2
.
.
.
∂
r
i
∂
w
2
∂
r
i
∂
w
p
.
.
.
∂
r
i
∂
w
p
∂
r
i
∂
w
1
∂
r
i
∂
w
p
∂
r
i
∂
w
2
.
.
.
∂
r
i
∂
w
p
∂
r
i
∂
w
p
]
=\begin{bmatrix} \frac{\partial r_i}{\partial w1}\frac{\partial r_i}{\partial w1}&\frac{\partial r_i}{\partial w1}\frac{\partial r_i}{\partial w2}&...&\frac{\partial r_i}{\partial w1}\frac{\partial r_i}{\partial wp}\\ \\ \frac{\partial r_i}{\partial w2}\frac{\partial r_i}{\partial w1}&\frac{\partial r_i}{\partial w2}\frac{\partial r_i}{\partial w2}&...&\frac{\partial r_i}{\partial w2}\frac{\partial r_i}{\partial wp} \\ ... \\ \frac{\partial r_i}{\partial wp}\frac{\partial r_i}{\partial w1}&\frac{\partial r_i}{\partial wp}\frac{\partial r_i}{\partial w2}&...&\frac{\partial r_i}{\partial wp}\frac{\partial r_i}{\partial wp} \end{bmatrix}
=⎣⎢⎢⎢⎢⎢⎡∂w1∂ri∂w1∂ri∂w2∂ri∂w1∂ri...∂wp∂ri∂w1∂ri∂w1∂ri∂w2∂ri∂w2∂ri∂w2∂ri∂wp∂ri∂w2∂ri.........∂w1∂ri∂wp∂ri∂w2∂ri∂wp∂ri∂wp∂ri∂wp∂ri⎦⎥⎥⎥⎥⎥⎤
∑
i
=
1
N
J
i
(
w
)
J
i
(
w
)
T
=
=
[
∑
i
=
1
N
∂
r
i
∂
w
1
∂
r
i
∂
w
1
∑
i
=
1
N
∂
r
i
∂
w
1
∂
r
i
∂
w
2
.
.
.
∑
i
=
1
N
∂
r
i
∂
w
1
∂
r
i
∂
w
p
∑
i
=
1
N
∂
r
i
∂
w
2
∂
r
i
∂
w
1
∑
i
=
1
N
∂
r
i
∂
w
2
∂
r
i
∂
w
2
.
.
.
∑
i
=
1
N
∂
r
i
∂
w
2
∂
r
i
∂
w
p
.
.
.
∑
i
=
1
N
∂
r
i
∂
w
p
∂
r
i
∂
w
1
∑
i
=
1
N
∂
r
i
∂
w
p
∂
r
i
∂
w
2
.
.
.
∑
i
=
1
N
∂
r
i
∂
w
p
∂
r
i
∂
w
p
]
\sum_{i=1}^NJ_i(w)J_i(w)^T= =\begin{bmatrix} \sum_{i=1}^N\frac{\partial r_i}{\partial w1}\frac{\partial r_i}{\partial w1}&\sum_{i=1}^N\frac{\partial r_i}{\partial w1}\frac{\partial r_i}{\partial w2}&...&\sum_{i=1}^N\frac{\partial r_i}{\partial w1}\frac{\partial r_i}{\partial wp}\\ \\ \sum_{i=1}^N\frac{\partial r_i}{\partial w2}\frac{\partial r_i}{\partial w1}&\sum_{i=1}^N\frac{\partial r_i}{\partial w2}\frac{\partial r_i}{\partial w2}&...&\sum_{i=1}^N\frac{\partial r_i}{\partial w2}\frac{\partial r_i}{\partial wp} \\ ... \\ \sum_{i=1}^N\frac{\partial r_i}{\partial wp}\frac{\partial r_i}{\partial w1}&\sum_{i=1}^N\frac{\partial r_i}{\partial wp}\frac{\partial r_i}{\partial w2}&...&\sum_{i=1}^N\frac{\partial r_i}{\partial wp}\frac{\partial r_i}{\partial wp} \end{bmatrix}
i=1∑NJi(w)Ji(w)T==⎣⎢⎢⎢⎢⎢⎡∑i=1N∂w1∂ri∂w1∂ri∑i=1N∂w2∂ri∂w1∂ri...∑i=1N∂wp∂ri∂w1∂ri∑i=1N∂w1∂ri∂w2∂ri∑i=1N∂w2∂ri∂w2∂ri∑i=1N∂wp∂ri∂w2∂ri.........∑i=1N∂w1∂ri∂wp∂ri∑i=1N∂w2∂ri∂wp∂ri∑i=1N∂wp∂ri∂wp∂ri⎦⎥⎥⎥⎥⎥⎤
=
[
∂
r
1
∂
w
1
∂
r
2
∂
w
1
.
.
.
∂
r
N
∂
w
1
∂
r
1
∂
w
2
∂
r
2
∂
w
2
.
.
.
∂
r
N
∂
w
2
.
.
.
∂
r
1
∂
w
p
∂
r
2
∂
w
p
.
.
.
∂
r
N
∂
w
p
]
[
∂
r
1
∂
w
1
∂
r
1
∂
w
2
.
.
.
∂
r
1
∂
w
p
∂
r
2
∂
w
1
∂
r
2
∂
w
2
.
.
.
∂
r
2
∂
w
p
.
.
.
∂
r
N
∂
w
1
∂
r
N
∂
w
2
.
.
.
∂
r
N
∂
w
p
]
=\begin{bmatrix} \frac{\partial r_1}{\partial w1}&\frac{\partial r_2}{\partial w1}&...&\frac{\partial r_N}{\partial w1}\\ \\ \frac{\partial r_1}{\partial w2}&\frac{\partial r_2}{\partial w2}&...&\frac{\partial r_N}{\partial w2}\\ \\ ...\\ \\ \frac{\partial r_1}{\partial wp}&\frac{\partial r_2}{\partial wp}&...&\frac{\partial r_N}{\partial wp} \end{bmatrix} \begin{bmatrix} \frac{\partial r_1}{\partial w1}&\frac{\partial r_1}{\partial w2}&...&\frac{\partial r_1}{\partial wp}\\ \\ \frac{\partial r_2}{\partial w1}&\frac{\partial r_2}{\partial w2}&...&\frac{\partial r_2}{\partial wp}\\ \\ ...\\ \\ \frac{\partial r_N}{\partial w1}&\frac{\partial r_N}{\partial w2}&...&\frac{\partial r_N}{\partial wp} \end{bmatrix}
=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡∂w1∂r1∂w2∂r1...∂wp∂r1∂w1∂r2∂w2∂r2∂wp∂r2.........∂w1∂rN∂w2∂rN∂wp∂rN⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡∂w1∂r1∂w1∂r2...∂w1∂rN∂w2∂r1∂w2∂r2∂w2∂rN.........∂wp∂r1∂wp∂r2∂wp∂rN⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
=
J
(
w
)
T
J
(
w
)
=J(w)^TJ(w)
=J(w)TJ(w)
这段累加很繁琐,注意各个矩阵的元素以及各个矩阵的维度,对具体代码实现来说很重要。
最终可以得到如下方程组:
J
(
w
)
T
r
(
w
)
+
J
(
w
)
T
J
(
w
)
Δ
w
=
0
J(w)^Tr(w)+J(w)^TJ(w)\Delta w=0
J(w)Tr(w)+J(w)TJ(w)Δw=0
其中,
J
(
w
)
J(w)
J(w) 强调过很多次了,是引入的函数向量
r
(
w
)
r(w)
r(w) 针对自变量参数向量
w
w
w 的雅克比矩阵,
r
(
w
)
r(w)
r(w) 是引入的函数变量。
转换得到如下方程组:
J
(
w
)
T
J
(
w
)
Δ
w
=
−
J
(
w
)
T
r
(
w
)
(6)
J(w)^TJ(w)\Delta w=-J(w)^Tr(w)\tag{6}
J(w)TJ(w)Δw=−J(w)Tr(w)(6)
这个方程组是关于增量
Δ
w
\Delta w
Δw 的线性方程组,称作增量方程,或高斯牛顿方程,或正规方程。把左边的系数定义为
H
H
H ,右边定义为
g
g
g,得到如下线性方程组形式:
H
Δ
w
=
g
H\Delta w=g
HΔw=g
求解上述增量方程可以解出增量
Δ
w
\Delta w
Δw
Δ
w
=
−
(
J
T
J
)
−
1
J
T
r
(
w
)
\Delta w=-(J^TJ)^{-1}J^Tr(w)
Δw=−(JTJ)−1JTr(w)
这里把左侧系数记作 H H H 是有特殊意义的,对比牛顿法可知,高斯牛顿法用 J ( w ) T J ( w ) J(w)^TJ(w) J(w)TJ(w) 作为牛顿法中二阶海森矩阵的近似,从而省略了计算海森矩阵的步骤。求解线性方程组式(6)是整个算法的核心所在。
注意到求解过程中,有对矩阵 J T J J^TJ JTJ 取逆的操作,这就要求矩阵 J T J J^TJ JTJ 是可逆矩阵。但在实际情况中,可能出现 J T J J^TJ JTJ 为奇异矩阵(不满秩,即不可逆)的情况,直观来说,这时原函数在这个点的局部近似并不像是一个二次函数。列文伯格——马夸尔特方法在一定程度上解决了这个问题( J T J J^TJ JTJ 并不总是可逆),一般认为它比高斯牛顿法更健壮,但收敛速度可能会比高斯牛顿法慢,被称为阻尼牛顿法。
(4)列文伯格——马夸尔特法(LM法)
高斯牛顿法中采用的近似二阶泰勒泰勒展开的方式只在展开点附近一定范围内有较好的近似效果,当增量 Δ w \Delta w Δw 过大时,就有可能超出这个范围,因此自然想到给增量 Δ w \Delta w Δw 添加一个范围,称为信赖区域。这个范围定义了在什么情况下二阶近似是有效的,在这个信赖区域内,我们认为近似是有效的,超出这个区域,近似就可能出现问题。
通过近似模型和实际函数之间的差异来确定信赖区域的范围,定义一个指标
ρ
\rho
ρ 来刻画近似的好坏:
ρ
=
实
际
函
数
下
降
的
值
/
近
似
模
型
下
降
的
值
\rho=实际函数下降的值/近似模型下降的值
ρ=实际函数下降的值/近似模型下降的值
当
ρ
\rho
ρ 接近于1,则认为近似是良好的;当
ρ
\rho
ρ 太小,说明实际函数下降的值远小于近似模型下降的值,意味着近似比较差,需要缩小近似范围;当
ρ
\rho
ρ 比较大,说明实际函数下降的值比近似模型下降的值要大,意味着可以放大近似范围。
这部分理论先不写了,SLAM十四讲中跳得太快,理解能力有限。
直接上结论:
列文伯格——马夸尔特法在高斯牛顿法的基础上,加上了一个不等式约束:
∣
∣
D
Δ
w
k
∣
∣
2
≤
μ
||D\Delta w_k||^2≤\mu
∣∣DΔwk∣∣2≤μ
μ
\mu
μ 是信赖区域的半径,
D
D
D 为系数矩阵,列文伯格把
D
D
D 取为单位阵
I
I
I ,相当于把
Δ
w
k
\Delta w_k
Δwk 约束在一个高维球内,而马夸尔特特出可以将
D
D
D 取为非负数的对角阵——实际上通常用
J
T
J
J^TJ
JTJ 的对角元素的平方根,使得
Δ
w
k
\Delta w_k
Δwk 被约束在一个高维椭圆内,椭圆短轴对应梯度小的维度。
将该不等式约束用拉格朗日乘数法的方式放入目标函数内,构成拉格朗日函数,令该拉格朗日函数关于
Δ
w
\Delta w
Δw 的导数为零,最终的形式核心仍然是求解一个关于增量的线性方程组:
(
H
+
λ
D
T
D
)
Δ
w
k
=
g
(H+\lambda D^TD)\Delta w_k=g
(H+λDTD)Δwk=g
可以看到,相比于高斯牛顿法,增量方程中仅多了一项 λ D T D \lambda D^TD λDTD。 λ \lambda λ 为拉格朗日乘子。
一方面,当参数 λ \lambda λ 较小时, H H H 占主要地位,说明二次近似模型在该范围内的近似效果比较好,此时列文伯格——马夸尔特法更接近于高斯牛顿法。
另一方面,当参数 λ \lambda λ 较大时, λ D T D \lambda D^TD λDTD 占主要地位,说明二次近似模型在该范围内的近似效果并不好,若取简化形式 D = I D=I D=I , ( H + λ I ) Δ w k = g (H+\lambda I)\Delta w_k=g (H+λI)Δwk=g,此时列文伯格——马夸尔特法更接近一阶梯度下降法(即最速下降法,别忘了,右边 g = − J ( w ) T r ( w ) g=-J(w)^Tr(w) g=−J(w)Tr(w) ,里面是有一个一阶导数的)。
列文伯格——马夸尔特法在一定程度上避免了
H
H
H 不可逆的问题,提供更稳定、更准确的增量
Δ
w
k
\Delta w_k
Δwk 的计算方式。由于细节部分尚未完全吃透,这里先直接贴一下SLAM十四讲里的算法流程:

这里的式(6.34)是上文中计算
ρ
\rho
ρ 的式子。
参考:
1.什么是「最小二乘法」?
https://www.zhihu.com/question/304164814/answer/549972357?utm_source=wechat_session
2.[数值计算] 数据拟合——非线性最小二乘法
https://zhuanlan.zhihu.com/p/83320557
3.梯度的方向为什么是函数值增加最快的方向?
https://zhuanlan.zhihu.com/p/38525412
4.泰勒展开式&牛顿法
https://blog.csdn.net/weixin_42468475/article/details/114642193
5.到底什么是线性函数,什么是非线性函数
https://blog.csdn.net/qq_38973721/article/details/108709827
6.线性最小二乘法与非线性最小二乘法
https://blog.csdn.net/qq_40061206/article/details/118703747
7.多元函数的泰勒(Taylor)展开式
https://blog.csdn.net/red_stone1/article/details/70260070
8.雅可比矩阵与海森矩阵
https://blog.csdn.net/hero_cjn/article/details/87888801
9.《视觉SLAM十四讲》——高翔、张涛
10. 0 范数、1 范数、2 范数有什么区别?
https://www.zhihu.com/question/20473040
11.熟悉陌生的2-范数(向量的模)
https://blog.csdn.net/geter_CS/article/details/85100045
12.《The matrix cookbook》——Kaare Brandt Petersen、Michael Syskind Pedersen
13.【简要复习】牛顿法、高斯—牛顿法(Gauss–Newton)和其他拟牛顿法
https://zhuanlan.zhihu.com/p/162901829
14.《最优化理论与方法》——王景恒

















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









