






后端开发
Java是世界上最好的编程语言——49年保皇派
MySQL
-
什么是数据库
- 数据库:DataBase(DB),存储和管理数据的仓库
- 数据库产品:Oracle(大型收费)、MySQL、DB2、SQLite、MariaDB…
-
数据模型:
- 关系型数据库(RDBMS):建立在关系模型基础上,由多张相互连接的二维表组成的数据库。
- 优点:
- 格式统一便于维护
- 使用SQL语言操作,标准统一使用方便,且可用于复杂查询
- 优点:
- 非关系型数据库
- 关系型数据库(RDBMS):建立在关系模型基础上,由多张相互连接的二维表组成的数据库。
-
SQL简介
-
SQL:一门操作关系型数据库的编程语言,定义操作所有关系型数据库的统一标准
- 通用语法:
- SQL语句可以单行或多行书写,分号结尾。
show databases; - SQL语句可以用空格/缩进来增强语句可读性。
show databases - MySQL数据库的SQL语句不区分大小写
- 注释:
- 单行注释:-- 注释内容 或 # 注释内容(MySQL特有的)
- 多行注释:/* 注释内容 */
- SQL语句可以单行或多行书写,分号结尾。
- 通用语法:
-
分类:
分类 全称 说明 DDL Data Definition Language 数据定义语言,定义数据库对象的(数据库、表、字段) DML Data Manipulation Language 数据操作语言,用来对表中数据进行增删改查 DQL Data Query Language 数据查询语言,用来查询表中记录 DCL Data Control Language 数据控制语言,用来创建数据库用户、控制数据库的访问权限
-
-
项目开发流程
- 拿到产品经理提供的页面原型和需求文档:项目包含哪些模块、模块包含哪些功能…
- 项目设计
- 概要设计
- 详细设计
- 接口设计
- 数据库设计:各个模块设计的表结构、表结构之间关系、表结构详细信息
- 项目开发 参照需求文档和表结构编写程序
- 优化项目
DDL(数据库操作)
-
查询:
操作 命令 查询所有数据库 show databases; 查询当前数据库 select database(); -
使用
使用数据库 :
use 数据库名; -
创建
创建数据库:
create database [if not exists] 数据库名; -
删除
删除数据库:
drop database [if exists] 数据库名; -
表
-
创建
create table 表名( 字段1 字段类型 [约束] [comment 字段1注释], 字段2 字段类型 [约束] [comment 字段2注释], ...... 字段n 字段类型 [约束] [comment 字段n注释] )[comment 表注释]约束的概念是作用于表中字段的规则,用于限制存储在表中的数据,其目的是保证数据库中数据的正确性、有效性和完整性。
约束 描述 关键字 非空约束 限制该字段值不能为null not null 唯一约束 保证字段的所有数据都是唯一的、不重复的 unique 主键约束 主键是一行数据的唯一标识,必须非空且唯一 primary key 默认约束 保存数据时,如果没有指定该字段值,就采用默认约束 default 外键约束 让两张表的数据建立连接,保证数据的一致性和完整性 foreign key -
数据类型
MySQL中的数据类型主要有三类:数值类型、字符串类型、日期时间类型。参考[《MySQL数据类型》](MySQL 数据类型 | 菜鸟教程 (runoob.com))
一个创建表的示例:
create table tb_emp ( id int auto_increment comment '主键id' primary key, username VARCHAR(20) unique not null comment '用户名', name varchar(10) not null comment '员工姓名', password varchar(32) default '123456' not null comment '密码', gender bool not null comment '性别', image varchar(300) null comment '图像', job tinyint unsigned null comment '职位,1 班主任 2 讲师 3 学工主管 4 教研主管', entry_date date null comment '入职日期', create_time datetime not null comment '数据创建时间', update_time datetime not null comment '数据更新时间' )comment '员工表'; -
-
查询
操作 命令 查询当前数据库所有表 show tables; 查询表结构 desc 表名; 查询建表语句 show create table 表名; -
修改
操作 命令 添加字段 alter table 表名 add 字段名 类型(长度) [comment 注释] [约束]; 修改字段类型 alter table 表名 modify 字段名 新数据类型(长度); 修改字段名和字段类型 alter table 表名 change 旧字段名 新字段名 类型(长度) [comment 注释] [约束]; 删除字段 alter table 表名 drop column 字段名 修改表名 rename table 表名 to 新表名; -
删除
删除表:
drop table [if exists] 表名;
-
DML(数据操作语言)
数据操作语言是用来对数据库中表的数据记录进行增删改操作的。
-
添加数据(INSERT)
操作 命令 指定字段添加数据 insert into 表名(字段名1,字段名2) values (值1,值2); 全部字段添加数据 insert into 表名 values (值1,值2,…); 批量添加数据(指定字段) insert into 表名(字段名1,字段名2) values (值1,值2), (值1,值2); 批量添加数据(全部字段) insert into 表名 values (值1,值2,…), (值1,值2,…); -
修改数据(UPDATE)
update 表名 set 字段名1=值1,字段名2=值2,...[where 条件]; -
删除数据(DELETE)
delete from 表名 [where 条件];
DQL(数据查询操作)
查询表中数据,关键字SELECT,这是所有SQL语句中最常见最重要的。
语法:
select
字段列表
from
表名列表
-----------------------------------------------基本查询
where
条件列表
-----------------------------------------------条件查询(where)
group by
分组字段列表
having
分组后条件列表
-----------------------------------------------分组查询(group by)
order by
排序字段列表
-----------------------------------------------排序查询(order by)
limit
分页参数
-----------------------------------------------分页查询(limit)
-
基本查询
操作 命令 查询多个字段 select 字段1,字段2,字段3 from 表名; 查询所有字段 select * from 表名; 设置别名 select 字段1 [as 别名1], 字段2 [as 别名2] from 表名; 去除重复记录 select distinct 字段列表 from 表名; -
条件查询
select 字段列表 from 表名 where 条件列表分类 运算符 功能 比较运算符 > 大于 比较运算符 >= 大于等于 比较运算符 < 小于 比较运算符 <= 小于等于 比较运算符 = 等于 比较运算符 <> 或 != 不等于 比较运算符 between … and … 在某个范围之内(包含最大最小值) 比较运算符 in(…) 在in之后的列表中的值,多选一 比较运算符 like 占位符 模糊匹配(_匹配单个字符,%匹配任意个字符) 比较运算符 is null 是null 逻辑运算符 and 或 && 并且 逻辑运算符 or 或 || 或者 逻辑运算符 not 或 ! 非 示例:查询所有姓张的员工:
select * from tb_emp where name like '张%';查询所有姓名为两个字的员工信息:
select * from tb_emp where name like '__'; -
分组查询
-
聚合函数:将一列数据作为一个整体进行纵向计算,
select 聚合函数(字段列表) from 表名;函数 功能 count 统计数量 max 最大值 min 最小值 avg 平均值 sum 求和 tips:null值不参与所有的聚合函数运算,统计数量可以用:
1. **count(*) 推荐** 2. count(字段) 3. count(常量) -
分组查询语法:
select 字段列表 from 表名 where 条件列表 group by 分组字段名 [having 分组后过滤条件];注意where后面不能有聚合函数,如果要对分组后的结果进行过滤,使用
having -
分组查询返回全部信息没有意义,所以可以返回分组字段以及聚合函数。例如,根据性别分组并返回男女员工的数量:
select gender,count(*) from tb_emp group by gender;
-
-
排序查询
-
语法:
select 字段列表 from 表名 where 条件列表 group by 分组字段 order by 字段1 排序方式1,字段2 排序方式2...; -
排序方式:ASC升序,DESC降序
-
示例:根据 入职时间 对公司员工进行升序排序,如果入职时间相同,再按照 更新时间 进行降序排序
select * from tb_emp order by entry_time asc,update_time desc;
-
-
分页查询
-
语法:
select 字段列表 from 表名 limit 起始索引,查询记录数; -
起始索引是从零开始的,计算公式为:*(页码-1)每页展示记录数
-
示例:查询第3页员工记录,每页10条数据
select * from tb_emp limit 20,10
-
多表联动
项目中在进行数据库表结构设计时,会根据业务需求和业务模块之间的关系分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种:
- 一对多,在多的一方添加外键约束
- 多对多,建立一张中间表,用两个外键关联两方主键
- 一对一,特殊的一对多
要建立联系,需要用到外键:
-
建表时设置外键:
create table 表名( 字段名 数据类型, ... [constraint] [外键名称] foreign key (外键字段名) references 主表(字段名) ); -
建表后添加外键:
alter table 表名 add constraint 外键名 foreign key (外键字段名) references 主表(字段名);
示例:员工表的dept_id字段与部门表的id建立联系:
alter table tb_emp add constraint tb_emp_fk_dept_id foreign key (dept_id) references tb_dept(id);
- 这种使用foreign key定义的外键称作物理外键,缺点是:
- 影响增删改的效率
- 仅适用于单节点数据库,不适用于分布式数据库
- 容易引发死锁
- 现在企业常用的办法为逻辑外键,就是在业务层逻辑中解决外键关联
多表查询
-
概述:从多张表中查询数据即为多表查询
-
select * from A,B;会返回表A与B的笛卡尔积,这是我们不想要的,因此要去掉不要的笛卡尔积:select * from tb_emp,tb_dept where tb_emp.dept_id = tb_dept.id; -
分类:
-
连接查询
- 内连接:A、B的交集部分
- 外连接
- 左外连接:查询左表的所有数据(包含两表交集部分)
- 右外连接:查询右表的所有数据(包含两表交集部分)
-
子查询:查询嵌套查询
select * from t1 where column1 = (select column1 from t2 ...);子查询外部的语句可以是insert / update / delete / select 中的任何一个,常见的是select,这样返回的是单行单列的值,因此称之为标量子查询。常用的操作符有:= <> > >= < <=
-
列子查询:返回的结果是一列多行,常见操作符是in、not in
示例:
select * from tb_emp where dept_id in (select id from tb_dept where name = '教研部' or name = '咨询部'); -
行子查询:返回结果是一行多列,常见操作符是=, <>, in, not in
示例:
select * from tb_emp where (entrydate,job)=(select entrydate,job from tb_emp where name = '韦一笑'); -
多行多列:结果作为一张临时表使用,常用操作符为in
示例:
select e.*,d.name from (select * from tb_emp where entrydate > '2006-01-01') e,tb_dept d where e.dept_id=d.id;
-
-
内连接
-
隐式内连接
select 字段列表 from 表1,表2 where 条件...; -
显式内连接
select 字段列表 from 表1 [inner] join 表2 on 连接条件;
外连接
-
左外连接
select 字段列表 from 表1 left [outer] join 表2 on 连接条件...; -
右外连接
select 字段列表 from 表1 right [outer] join 表2 on 连接条件...;
事务*
事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,也就是 这些操作要么同时成功要么同时失败。
tip:MySQL事务默认是自动提交的。当执行一条DML语句,MySQL会立即隐式提交事务。
手动事务控制:
- 开启事务:
start transaction; / begin; - 提交事务:
commit; - 回滚事务:
rollback;
四大特性:
- 原子性:事务是不可分割的最小单元,要么全部成功要么全部失败
- 一致性:事务完成时,必须使所有数据都保持一致状态
- 隔离性:数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行
- 持久性:事务一旦提交或回滚,对数据库中数据的改变就是永久的
索引
索引(index)是帮助数据库高效获取数据的数据结构
示例:有表如下:
| 内存地址 | id | name | age |
|---|---|---|---|
| 0x07 | 1 | 金庸 | 36 |
| 0x56 | 2 | 张无忌 | 22 |
| 0x6A | 3 | 杨逍 | 33 |
| 0xF3 | 4 | 韦一笑 | 48 |
| 0x90 | 5 | 常遇春 | 53 |
| 0x77 | 6 | 小昭 | 19 |
| 0xD1 | 7 | 灭绝 | 45 |
| 0x32 | 8 | 周芷若 | 17 |
| 0xE5 | 9 | 丁敏君 | 23 |
| 0xF2 | 10 | 赵敏 | 20 |
执行select * from user where age = 45;
- 没有索引时:从第一条数据开始依次遍历,直到所有age为45的数据都找出来,这就是全表扫描,数据量越大效率越低。
- 有索引:对指定的字段建立树结构查找时间不超过树高
结构:
MySQL数据库支持的索引结构较多,包括Hash索引、B+Tree索引、Full-Text索引等。如果没有特别指明,都是默认B+Tree结构组织的索引。
B+树(多路平衡搜索树)
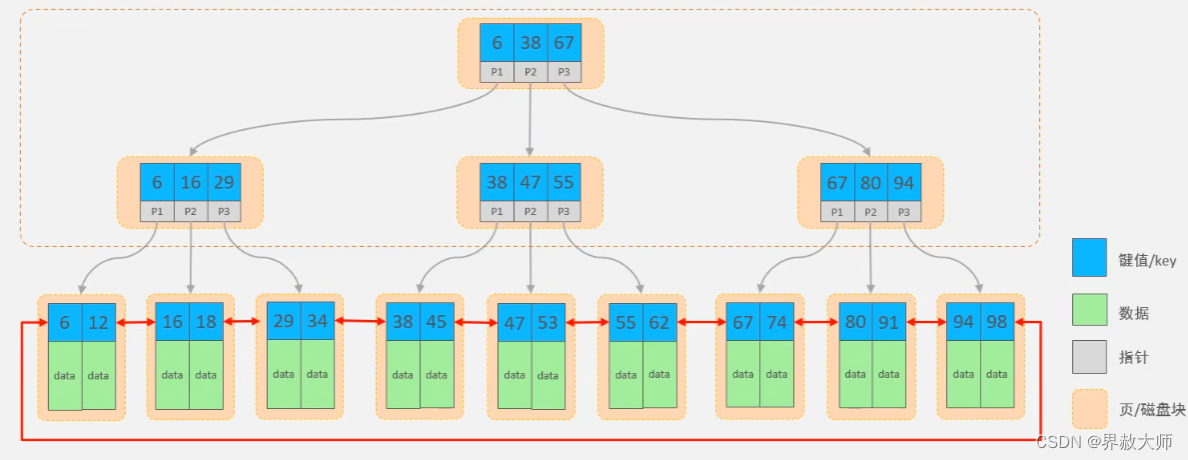
如果要查的数据为45,过程为:38->38->45,很容易理解
tips:
- 非叶节点不存数据只存索引,因此可以存多个索引
- 磁盘的页是最小单元,一个页的大小是16kb
- 叶子节点形成了一个双向链表,便于排序与区间范围查找
索引优点:
- 提高数据查询效率,降低数据库IO成本
- 可对数据进行排序,降低数据排序的成本,降低CPU消耗
缺点:
- 占用磁盘空间
- 提高了查询效率,但降低了insert、update、delete效率
语法:
- 创建索引:
create [unique] index 索引名 on 表名(字段名,...); - 查看索引:
show index from 表名; - 删除索引:
drop index 索引名 on 表名;
tips:
- 主键字段建表时会自动创建主键索引
- 添加唯一约束时,数据库会添加唯一索引
数据库连接池
-
数据库连接池是个容器,负责分配、管理数据库连接(Connection)
-
允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个
-
释放空闲时间超过最大空间时间的链接,避免因为没有释放连接引起的数据库连接遗漏
-
常见产品
-
C3P0
-
DBCP
-
Druid
-
阿里巴巴开源的数据库连接池项目
-
功能强大,性能优秀,是java语言最好的数据库连接池之一
-
切换Druid连接池:
<dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.2.8</version> </dependency>spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.url=jdbc:mysql://localhost:3306/mybatis spring.datasource.username=root spring.datasource.password=root
-
-
Hikari(springboot默认的)
-
QuickStart
工程流程:
-
拿到数据库表
id username password name gender image job entrydate dept_id create_time update_time 1 jinyong 123456 金庸 1 1.jpg 4 2000-01-01 2 2024-03-11 14:49:18 2024-03-11 14:49:18 2 zhangwuji 123456 张无忌 1 2.jpg 2 2015-01-01 2 2024-03-11 14:49:18 2024-03-11 14:49:18 3 yangxiao 123456 杨逍 1 3.jpg 2 2008-05-01 2 2024-03-11 14:49:18 2024-03-11 14:49:18 4 weiyixiao 123456 韦一笑 1 4.jpg 2 2007-01-01 2 2024-03-11 14:49:18 2024-03-11 14:49:18 5 changyuchun 123456 常遇春 1 5.jpg 2 2012-12-05 2 2024-03-11 14:49:18 2024-03-11 14:49:18 6 xiaozhao 123456 小昭 2 6.jpg 3 2013-09-05 1 2024-03-11 14:49:18 2024-03-11 14:49:18 7 jixiaofu 123456 纪晓芙 2 7.jpg 1 2005-08-01 1 2024-03-11 14:49:18 2024-03-11 14:49:18 8 zhouzhiruo 123456 周芷若 2 8.jpg 1 2014-11-09 1 2024-03-11 14:49:18 2024-03-11 14:49:18 9 dingminjun 123456 丁敏君 2 9.jpg 1 2011-03-11 1 2024-03-11 14:49:18 2024-03-11 14:49:18 10 zhaomin 123456 赵敏 2 10.jpg 1 2013-09-05 1 2024-03-11 14:49:18 2024-03-11 14:49:18 11 luzhangke 123456 鹿杖客 1 11.jpg 5 2007-02-01 3 2024-03-11 14:49:18 2024-03-11 14:49:18 12 hebiweng 123456 鹤笔翁 1 12.jpg 5 2008-08-18 3 2024-03-11 14:49:18 2024-03-11 14:49:18 13 fangdongbai 123456 方东白 1 13.jpg 5 2012-11-01 3 2024-03-11 14:49:18 2024-03-11 14:49:18 14 zhangsanfeng 123456 张三丰 1 14.jpg 2 2002-08-01 2 2024-03-11 14:49:18 2024-03-11 14:49:18 15 yulianzhou 123456 俞莲舟 1 15.jpg 2 2011-05-01 2 2024-03-11 14:49:18 2024-03-11 14:49:18 16 songyuanqiao 123456 宋远桥 1 16.jpg 2 2010-01-01 2 2024-03-11 14:49:18 2024-03-11 14:49:18 17 chenyouliang 123456 陈友谅 1 17.jpg null 2015-03-21 null 2024-03-11 14:49:18 2024-03-11 14:49:18 -
创建实体类
在
src/main/java/priv.jie下创建pojo.Emp实体类package priv.jie.pojo; @Data public class Emp { // 实体类建议驼峰命名,且类型用包装类不用基本类 private Integer id; private String username; private String password; private String name; private Short gender; private String image; private Short job; private LocalDate entryDate; private Integer deptId; private LocalDateTime createTime; private LocalDateTime updateTime; } -
在
application.properties中配置数据库连接信息spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.url=jdbc:mysql://localhost:3306/mybatis spring.datasource.username=root spring.datasource.password=root # 要看到MyBatis究竟执行了什么sql语句,需要打开日志输出 mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl -
编写接口,相当于dao层。创建
mapper.EmpMapper接口package priv.jie.mapper; @Mapper public interface EmpMapper { @Delete("delete from mybatis.emp where id=#{id}") public Integer deleteById(Integer id); // @Options的内容作用是新增成功后返回主键,并且封装在emp对象的id属性中 @Options(useGeneratedKeys = true, keyProperty = "id") @Insert("insert into mybatis.emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) values(#{username},#{name},#{gender},#{image},#{job},#{entryDate},#{deptId},#{createTime},#{updateTime})") public void insert(Emp emp); @Update("update mybatis.emp set username = #{username},emp.name=#{name},gender=#{gender},image=#{image},job=#{job},entrydate=#{entryDate},dept_id=#{deptId},update_time=#{updateTime} where id=#{id}") public void update(Emp emp); @Select("select * from emp where id=#{id}") public Emp getById(Integer id); } -
测试接口
package priv.jie; @SpringBootTest class SpringbootProjectApplicationTests { @Autowired private EmpMapper empMapper; @Test public void testDelete() { Integer delete = empMapper.deleteById(17); System.out.println("受影响的行数:" + delete); } @Test public void testInsert() { // 创建emp对象的代码省略 empMapper.insert(emp); System.out.println(emp.getId()); } @Test public void testUpdate() { // 创建emp对象的代码省略 empMapper.update(emp); } @Test public void testSelect() { System.out.println(empMapper.getById(20)); } }tips:由于数据库中部分字段与Emp类的名字不是完全对应的(dept_id 和 deptId),因此要开启驼峰命名自动映射,在application.properties中
mybatis.configuration.map-underscore-to-camel-case=true打开日志后,查看日志可知MyBatis执行的语句是:
==> Preparing: delete from emp where id = ? ==> Parameters: 16 (Integer)这是预编译SQL语句,优势有:
-
性能更高
数据库收到java程序发送来的SQL语句之后并不是立即执行的,而是经历了:
SQL语法解析检查 -> 优化SQL -> 编译SQL -> 执行SQL这些过程。其中三步执行完后MySQL会将编译好的SQL语句缓存起来。下次再收到新指令的时候,会先从缓存区找。如果使用了预编译的语句,就不用每次变了参数都重新执行前三步了,因此提高了性能。 -
更安全,防止SQL注入
SQL注入是通过操作输入的数据来修改事先定义好的SQL语句达到执行代码对服务器进行攻击的方法。
例如:在登录窗口执行以下代码
账号 jinyong 密码 ‘or ‘1’ =’ 假设判断登录的语句是
select count(*) from emp where username = 'jinyong' and password = '123456';,返回结果1为成功,否则为失败;现在则变成了select count(*) from emp where username = 'jinyong' and password = '' or '1'='1';这样不论如何都能成功。引出了参数占位符的概念。
-
#{…}
执行SQL时,会将
#{...}替换为?,生成预编译的SQL,自动设置参数值。在参数传递的时候,都使用
#{...} -
${…}
拼接SQL,这个占位符会直接把参数拼接到SQL语句中,就存在SQL注入问题。如果对表名、列表进行动态设置时,可以使用。
-
-
进阶用法
-
条件查询
@Select("select * from emp where name like concat('%',#{name},'%') and gender = #{gender} and entrydate between #{begin} and #{end} order by update_time desc") public List<Emp> list(String name, Short gender, LocalDate begin, LocalDate end);concat函数的使用是因为#{}不能出现在引号内,而使用${}又不安全,因此用之。 -
动态SQL*
-
随着用户的输入或外部条件的变化而变化的SQL语句称为动态SQL
-
例如,在上面的条件查询中,三个条件是固定死的,但是实际业务中可能有些条件是空的,所以不好,应该用动态SQL替代之。暂时没找到好的用注解方法写的,所以用
xml方式,以下是EmpMapper.xml<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="priv.jie.mapper.EmpMapper"> <!-- id=Mapper中的方法名,resultType=返回结果单条记录的类型全类名--> <select id="list" resultType="priv.jie.pojo.Emp"> select * from emp <where> <if test="name!=null"> name like concat('%', #{name}, '%') </if> <if test="gender!=null"> and gender = #{gender} </if> <if test="begin!=null and end != null"> and entrydate between #{begin} and #{end} </if> </where> order by update_time desc </select> </mapper>这样一来,条件不为空才拼接,用
<where>标签可以保证就算第一个条件也不成立也不会在SQL语句中多一个and。 -
除了有
<if>标签外,还有以下标签:-
<set>:替代SQL语句的set,没有的条件自动去掉 -
<where>:替代SQL语句的where,没有的条件自动去掉 -
<foreach><!-- collection:遍历的集合种类--> <!-- item:遍历出来的元素--> <!-- separator:分隔符--> <!-- open:遍历开始前拼接的SQL片段--> <!-- close:遍历结束后拼接的SQL片段--> <delete id="deleteById"> delete from emp where id in <foreach collection="list" item="id" separator="," open="(" close=")"> #{id} </foreach> </delete> -
<sql> -
<include>4和5解决的是复用性问题,将常用的代码抽取出来放进
<sql>标签,在要用的地方用<include>标签引用。<sql id="commonSelect"> select id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time from emp </sql> ... <select id="list" resultType="priv.jie.pojo.Emp"> <include refid="commonSelect"/> <where> <if test="name!=null"> name like concat('%', #{name}, '%') </if> <if test="gender!=null"> and gender = #{gender} </if> <if test="begin!=null and end != null"> and entrydate between #{begin} and #{end} </if> </where> order by update_time desc </select>
-
-
案例
-
环境搭建
- 数据库表
- 创建springboot工程,引入以下依赖:
- web
- MyBatis
- mysql驱动
- lombok
- 配置文件application.properties中引入mybatis的配置信息,并准备对应实体类
- 准备对应的Mapper、Service(接口、实现类)、Controller基础结构
-
RESTFUL风格:
-
GET查询
-
POST新增
-
PUT修改
-
DELETE删除
-
-
开发流程
- 明确需求
- 接口文档
- 思路分析
- 接口开发
必须严格遵守接口文档,一般是后端写接口文档
-
接口调试
postman测试 -> 前后端联调测试
-
日志技巧
加
@Slf4j注解,然后用log对象,不要用System.Out.Println,显得不高级
登录
基础版
-
LoginControllerpackage priv.jie.controller; @RestController @RequestMapping("/login") @Slf4j public class LoginController { @Autowired private LoginService loginService; /** * 登录 * @param emp 封装了用户名和密码的对象 * @return */ @PostMapping public Result login(@RequestBody Emp emp) { log.info("员工登录:{}", emp); Emp e = loginService.login(emp); return e != null ? Result.success(e) : Result.error("用户名或密码错误"); } } -
LoginServiceImplpackage priv.jie.service.impl; @Service public class LoginServiceImpl implements LoginService { @Autowired private LoginMapper loginMapper; /** * 登录 * @param emp 封装了用户名和密码的对象 * @return */ @Override public Emp login(Emp emp) { return loginMapper.select(emp); } } -
LoginMapperpackage priv.jie.mapper; /** * @author Jie * @date 03-12-2024 19:21 */ @Mapper public interface LoginMapper { /** * 查找数据库 * @param emp 封装了用户名和密码的对象 * @return 数据库中的检索结果 */ @Select("select * from emp where username=#{username} and password=#{password}") public Emp select(Emp emp); }
存在的问题:不用登录也能直接通过地址访问到想访问的资源,所以要有登录校验
登录校验
会话技术
-
会话:用户打开浏览器,访问web服务器的资源,会话建立,直到有一方断开连接,会话结束。一次会话中可以包含多次请求和响应。
-
会话跟踪:一种维护浏览器状态的方法,服务器需要识别多次请求是否来自同一浏览器,以便在同一次会话的多次请求间共享数据。
-
会话跟踪方案:
-
客户端会话跟踪技术:Cookie
优点:
- HTTP协议支持的技术
缺点:
-
移动端APP无法使用Cookie
-
不安全,用户自己甚至都可以禁用Cookie
-
Cookie不能跨域
协议、IP/域名、端口三者有一个不同就属于跨域,这种情况下Cookie也无法使用
-
服务端会话跟踪技术:Session
优点:
- 存储在服务器端,比较安全
缺点:
- 服务器集群环境下用不了
- 由于这东西底层就是Cookie,所以Cookie的缺点它全有
-
令牌技术(当前企业主流)
优点:
- 支持PC端、移动端
- 解决集群环境下的认证问题
- 减轻服务器储存压力
缺点:
- 需要程序员自己写(妈的)
-
JWT令牌
-
全称:JSON Web Token (https://jwt.io/)
-
定义了一种简洁的、自包含的格式,用于在通信双方以json数据格式安全的传输信息。由于数字签名的存在,这些信息是可靠的。
-
组成:
- 第一部分:Header(头),记录令牌类型、签名算法等。例如:{“alg”:“HS256”,“type”:“JWT”}
- 第二部分:Payload(有效载荷),携带一些自定义信息、默认信息等。例如:
{"id":"1","username":"Tom"} - 第三部分:Signature(签名),防止Token被篡改、确保安全性。将Header、payload和指定密钥一起通过签名算法计算得来。
上述内容用Base64进行编码。Base64是一种基于64个可打印字符(A-Z a-z 0-9 + /)来表示二进制数据的编码方式。
-
应用场景:登录认证
- 登录成功后生成令牌
- 后续每个请求都要携带JWT令牌,系统在处理请求之前要先校验令牌,通过后才处理
-
使用:
-
引入JWT依赖
<dependency> <groupId>io.jsonwebtoken</groupId> <artifactId>jjwt</artifactId> <version>0.9.1</version> </dependency> -
生成和校验
package priv.jie.utils; public class JwtUtils { private static final String signKey = "I am Iron man"; private static final Long expire = 43200000L; /** * 生成jwt令牌 * * @param claims JWT第二部分payload中存储的内容 * @return 返回生成的jwt令牌 */ public static String generateJwt(Map<String, Object> claims) { return Jwts.builder() .addClaims(claims) .signWith(SignatureAlgorithm.HS256, signKey) .setExpiration(new Date(System.currentTimeMillis() + expire)) .compact(); } /** * 解析JWT令牌 * * @param jwt 待解析的JWT令牌 * @return JWT第二部分payload中存储的内容 */ public static Claims parseJwt(String jwt) { return Jwts.parser() .setSigningKey(signKey) .parseClaimsJws(jwt) .getBody(); } } -
登录并下发令牌
@PostMapping public Result login(@RequestBody Emp emp) { log.info("员工登录:{}", emp); Emp e = loginService.login(emp); //登录成功,生成令牌并下发 if (e != null) { Map<String, Object> claims = new HashMap<>(); claims.put("id", e.getId()); claims.put("name", e.getName()); claims.put("username", e.getUsername()); String jwt = generateJwt(claims);//JWT中包含了当前登录的用户信息 return Result.success(jwt); }
-
过滤器(不如拦截器)
-
概述:Filter过滤器,是JavaWeb三大组件
(Servlet、Filter、Listener)之一。 -
过滤器可以把对资源的请求拦截下来,从而实现一些特殊功能
-
过滤器一般完成一些通用操作,例如:登录校验、统一编码处理、敏感字符处理等。
-
QuickStart:
-
定义Filter:定义一个类,实现Filter接口,重写其所有方法
-
配置Filter:Filter类上加 @WebFilter注解,配置拦截资源的路径。引导类上加 @ServletComponentScan开启Servlet组件支持
public class DemoFilter implements Filter{ public void init(FilterConfig filterConfig) throws ServletException{ //初始化方法,Web服务器启动,创建Filter时调用。只调用一次 Filter.super.init(filterConfig); } public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain){ //拦截到请求时调用该方法,可调用多次 System.out.println("拦截方法执行,拦截到了请求..."); chain.doFilter(request, response); } public void destory(){ //销毁方法,服务器关闭时调用,仅调用一次 Filter.super.destory(); } }
-
-
详解
-
执行流程
放行前逻辑 -> doFilter方法 -> 放行后逻辑Note: 放行后访问对应资源,访问完成后还会回到 Filter 中,且只执行放行后逻辑
-
拦截路径
在重写的类上使用注释@WebFilter(urlPatterns = “/*”)来对指定路径进行拦截
拦截路径 urlPatterns值 含义 拦截具体路径 /login 只有访问*/login*路径时才会被拦截 目录拦截 /emps/* 访问*/emps*下的所有资源都会被拦截 拦截所有 /* 访问所有资源都会被拦截 -
过滤器链
- 一个web应用中可以配置多个过滤器,多个过滤器就形成了一个过滤器链。
- 顺序:注解配置的Filter,优先级是按照过滤器类名(字符串)的自然排序。
-
-
应用
package priv.jie.filter; import com.alibaba.fastjson.JSONObject; import lombok.extern.slf4j.Slf4j; import org.springframework.util.StringUtils; import priv.jie.pojo.Result; import priv.jie.utils.JwtUtils; import javax.servlet.*; import javax.servlet.annotation.WebFilter; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import java.io.IOException; /** * @author Jie * @date 03-14-2024 14:50 * 登录过滤器 */ @Slf4j @WebFilter("/*") public class LoginCheckFilter implements Filter { @Override public void init(FilterConfig filterConfig) throws ServletException { Filter.super.init(filterConfig); } @Override public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException { //1.获取请求url HttpServletRequest req = (HttpServletRequest) servletRequest; HttpServletResponse res = (HttpServletResponse) servletResponse; String url = req.getRequestURI(); log.info("请求的url:{}", url); //2.判断url中是否包含login,如果包含说明是登录操作,放行 if (url.contains("login")) { log.info("登录操作,放行"); filterChain.doFilter(servletRequest, servletResponse); return; } //3.获取请求头中的令牌token String jwt = req.getHeader("token"); //4.判断令牌是否存在,若不存在返回错误结果(未登录) if (!StringUtils.hasLength(jwt)) { log.info("token为空"); String notLogin = JSONObject.toJSONString(Result.error("NOT_LOGIN")); res.getWriter().write(notLogin); return; } //5.解析token,若解析失败,返回错误结果(未登录) try { JwtUtils.parseJwt(jwt); } catch (Exception e) { log.error("令牌解析失败"); String notLogin = JSONObject.toJSONString(Result.error("NOT_LOGIN")); res.getWriter().write(notLogin); return; } //6.放行 log.info("令牌合法,放行"); filterChain.doFilter(servletRequest, servletResponse); } @Override public void destroy() { Filter.super.destroy(); } }
拦截器
-
概念:一种动态拦截方法调用的机制,类似于过滤器。是Spring框架中提供的,用来动态拦截控制器(Controller)方法的执行。
-
作用:拦截请求,在指定的方法调用前后,根据业务需要执行预先设定的代码。
-
细节
-
拦截路径
-
拦截器可以根据需求,配置不同的拦截器路径。其中,
addPathPatterns方法后跟要拦截的路径,excludePathPatterns方法后是不需要拦截的路径@Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(loginCheckInterceptor).addPathPatterns("/**").excludePathPatterns("/login") }拦截路径 含义 示例 /* 一级路径 能匹配/depts,/emps,/login,不能匹配/depts/1 /** 任意级路径 全部拦截 /depts/* /depts下的一级路径 能匹配/depts/1,不能匹配/depts/1/2,/depts /depts/** /depts下的任意路径 /depts下的全部拦截
-
-
执行流程
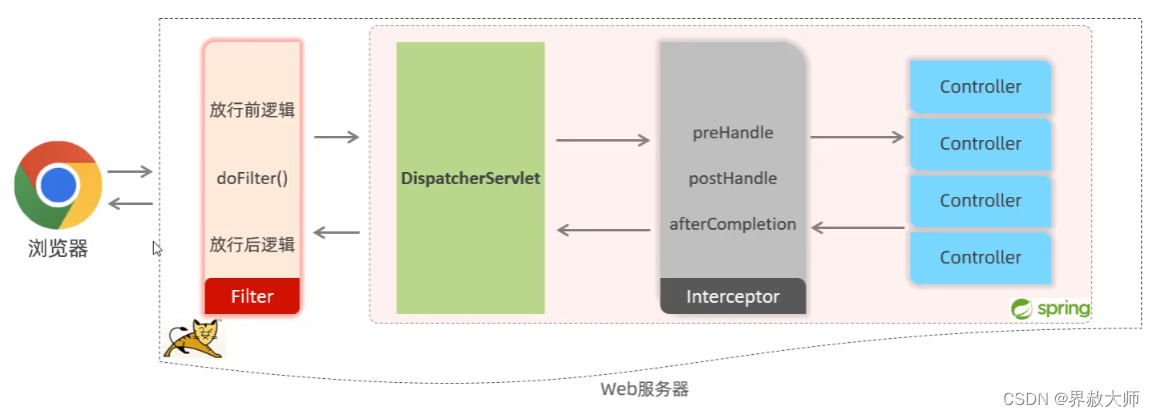
显然,过滤器先于拦截器。过滤器是Tomcat服务器弄的,必须使Servlet才能用;拦截器是Spring弄的,只要用了Spring就可以用。
需要两个类,一个是自定义的拦截器类,需要继承
HandlerInterceptor;另一个是配置类,需要继承WebMvcConfigurer。从逻辑上说,拦截器和过滤器的逻辑是一样的。package priv.jie.interceptor; import com.alibaba.fastjson.JSONObject; import lombok.extern.slf4j.Slf4j; import org.springframework.lang.Nullable; import org.springframework.stereotype.Component; import org.springframework.stereotype.Service; import org.springframework.util.StringUtils; import org.springframework.web.servlet.HandlerInterceptor; import org.springframework.web.servlet.ModelAndView; import priv.jie.pojo.Result; import priv.jie.utils.JwtUtils; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; /** * @author Jie * @date 03-14-2024 15:57 */ @Component @Slf4j public class LoginCheckInterceptor implements HandlerInterceptor { @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { //目标资源方法运行前运行,返回true //1.获取请求url String url = request.getRequestURI(); log.info("请求的url:{}", url); //2.判断url中是否包含login,如果包含说明是登录操作,放行 if (url.contains("login")) { log.info("登录操作,放行"); return true; } //3.获取请求头中的令牌token String jwt = request.getHeader("token"); //4.判断令牌是否存在,若不存在返回错误结果(未登录) if (!StringUtils.hasLength(jwt)) { log.info("token为空"); String notLogin = JSONObject.toJSONString(Result.error("NOT_LOGIN")); response.getWriter().write(notLogin); return false; } //5.解析token,若解析失败,返回错误结果(未登录) try { JwtUtils.parseJwt(jwt); } catch (Exception e) { log.error("令牌解析失败"); String notLogin = JSONObject.toJSONString(Result.error("NOT_LOGIN")); response.getWriter().write(notLogin); return false; } //6.放行 log.info("令牌合法,放行"); return true; } @Override public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, @Nullable ModelAndView modelAndView) throws Exception { //目标资源方法运行后运行 } @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, @Nullable Exception ex) throws Exception { //视图渲染完毕后运行,最后运行 } }package priv.jie.config; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Configuration; import org.springframework.web.servlet.config.annotation.InterceptorRegistry; import org.springframework.web.servlet.config.annotation.WebMvcConfigurer; import priv.jie.interceptor.LoginCheckInterceptor; /** * @author Jie * @date 03-14-2024 16:07 */ @Configuration public class WebConfig implements WebMvcConfigurer { @Autowired private LoginCheckInterceptor loginCheckInterceptor; @Override public void addInterceptors(InterceptorRegistry registry){ registry.addInterceptor(loginCheckInterceptor).addPathPatterns("/**").excludePathPatterns("/login"); } }
-
全局异常处理器
package priv.jie.exception;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RestControllerAdvice;
import priv.jie.pojo.Result;
/**
* @author Jie
* @date 03-14-2024 16:26
* 全局异常处理器
*/
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(Exception.class)
public Result ex(Exception exception){
exception.printStackTrace();
return Result.error("操作失败,请联系管理员");
}
}
不管后端发生了什么,返回前端的一定是约定好的Result类封装好的结果。
Spring事务和AOP面向切面编程
-
Spring事务管理
- 注解:@Transcational
- 位置:业务层的方法、接口、类上都可以
- 作用:将当前方法交给Spring进行事务管理。方法执行前开启事务,成功执行完毕提交事务;出现异常回滚。
-
进阶属性
-
rollbackFor
- 默认情况下是只有出现
RuntimeException才回滚事务。rollbackFor就是用于指定出现哪种异常回滚的。 - 用法:@Transcational(rollbackFor=“Exception.class”)
- 默认情况下是只有出现
-
propagation
-
事务传播行为:指的是一个事务方法调用另一个事务方法时,被调用的事务方法如何进行事务控制
属性值 含义 REQUIRED [默认值]需要事务,有则加入,无则新建 REQUIRES_NEW 需要新事务,无论原来有无都新建一个 SUPPORTS 支持事务,有则加入,无则在无事务状态中运行 NOT_SIPPORTED 不支持事务,有则挂起,无则在无事务状态中运行 MANDATORY 必须有事务,不然抛异常 NEVER 必须无事务,不然抛异常 -
示例:
@Transcational(propagation=Propagation.REQUIRED)
-
-
-
AOP*
-
概述
- 面向切面编程,面向方法编程,就是面向特定方法进行编程
- 场景:工程部分功能运行慢,需要一个统计每个业务方法运行时间的方法。
- 还可以应用在记录操作日志、权限控制、事务管理等
- 优势:
- 代码无侵入
- 减少重复代码
- 提高开发效率
- 方便维护
-
QuickStart
-
导入依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-aop</artifactId> </dependency> -
编写AOP程序
package priv.jie.aop; import lombok.extern.slf4j.Slf4j; import org.aspectj.lang.ProceedingJoinPoint; import org.aspectj.lang.annotation.Around; import org.aspectj.lang.annotation.Aspect; import org.springframework.stereotype.Component; /** * @author Jie * @date 03-14-2024 21:25 */ @Component @Aspect @Slf4j public class TimeAspect { @Around("execution(* priv.jie.service.*.*(..))") //包名.类名.方法 针对哪些方法进行编程 public Object recordTime(ProceedingJoinPoint proceedingJoinPoint) throws Throwable { long begin = System.currentTimeMillis(); Object object = proceedingJoinPoint.proceed();// 调用原始方法(要统计的业务层方法) long end = System.currentTimeMillis(); log.info(proceedingJoinPoint.getSignature() + "执行耗时:{}ms", end - begin); return object; } }
-
-
AOP核心概念
- 连接点:JoinPoint,可以被AOP控制的方法(暗含方法执行时的相关信息)
- 通知:Advice,指哪些重复的逻辑,也就是共性功能(最终体现为一个方法)
- 切入点:PointCut,匹配连接点的条件,通知仅会在切入点方法执行时被调用,体现为@Around后面的切入点表达式
- 切面:Aspect,描述通知与切入点的对应关系(通知+切入点)
- 目标对象:Target,通知所应用的对象
-
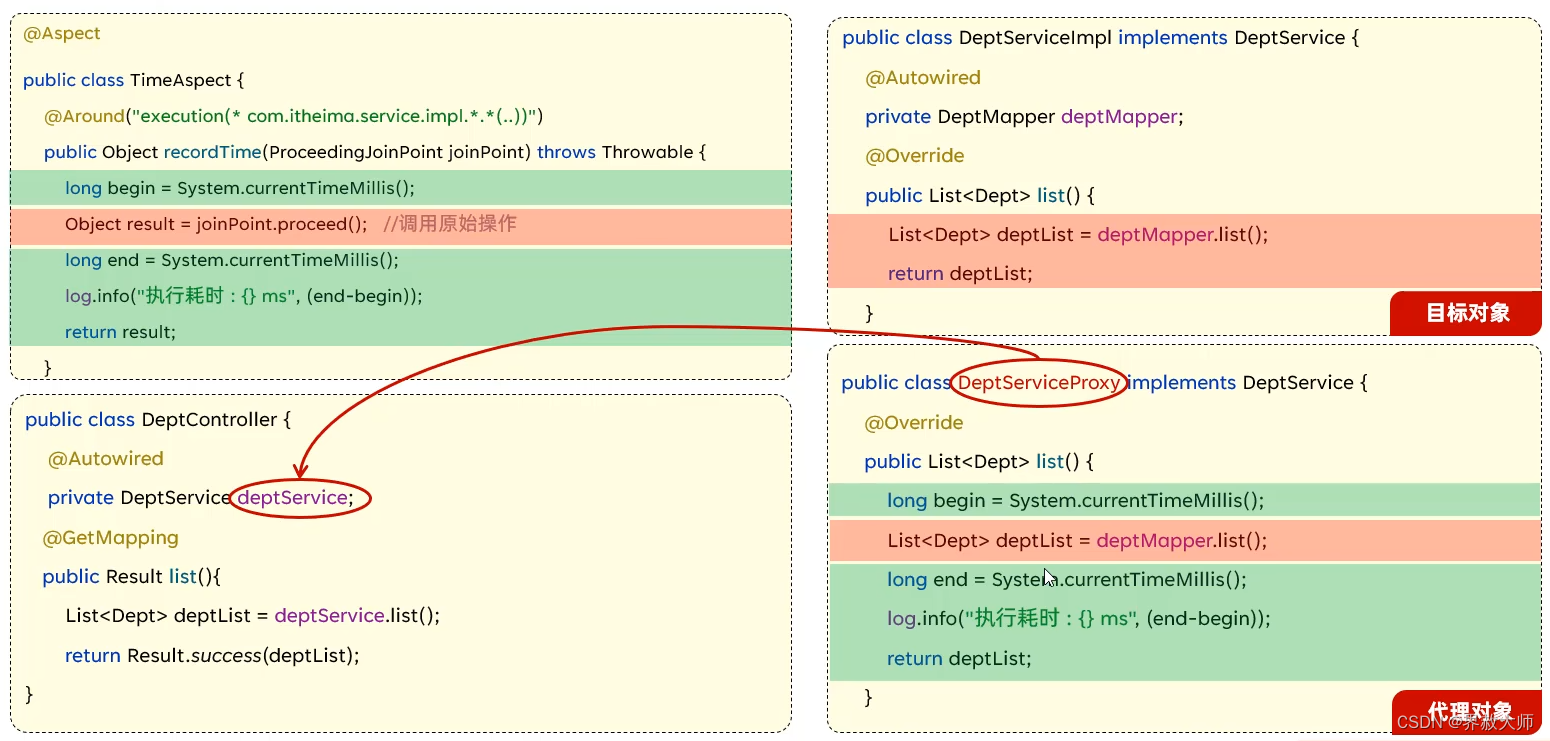
AOP执行流程
AOP是基于动态代理实现的。运行时会自动为目标对象生成一个代理对象。在上层自动注入的时候注入的就变成了代理对象而不是目标对象。
-
进阶
-
通知类型
- @Around:环绕通知,此注解标注的通知方法在目标方法前后都执行
- @Before:前置通知,此注解标注的通知方法在目标方法前执行
- @After:后置通知,此注解标注的通知方法在目标方法后执行,无论是否抛异常
- @AfterReturning:返回后通知,此注解标注的通知方法在目标方法后执行,抛异常不执行
- @AfterThrowing:异常后通知,此注解标注的通知方法在目标方法发生异常后执行
tips:@Around环绕通知需要自己调用ProceedingJoinPoint.proceed()来让原始方法执行,其他通知不需要考虑目标方法执行;@Around环绕通知方法的返回值必须为Object,来接收原始方法的返回值
@PointCut注解的作用是将公共的切点表达式抽取出来,需要用到的时候引用该切点表达式即可
@Pointcut("execution(* priv.jie.service.impl.DeptServiceImpl.*(..))") public void pt(){}; @Around("pt()") public Object recordTime(ProceedingJoinPoint joinPoint) throws Throwable{ }-
通知顺序
不同切面类中,默认按照切面类的类名字母排序:
- 目标方法前的通知:字母排名靠前的先执行
- 目标方法后的通知:字母排名靠前的后执行
也可以用@Order(数字)加在切面泪类上来控制顺序:
- 目标方法前的通知:数字小的先执行
- 目标方法后的通知:数字小的后执行
-
切入点表达式
- 描述切入点方法的一种表达式
- 作用:决定项目中哪些目标方法需要加入通知
- 形式:
- execution(…):根据方法的签名匹配,上面有,略
- @annotation(…):根据注解匹配
-
连接点
vice,指哪些重复的逻辑,也就是共性功能(最终体现为一个方法) -
切入点:PointCut,匹配连接点的条件,通知仅会在切入点方法执行时被调用,体现为@Around后面的切入点表达式
-
切面:Aspect,描述通知与切入点的对应关系(通知+切入点)
-
目标对象:Target,通知所应用的对象
-
-
AOP执行流程
AOP是基于动态代理实现的。运行时会自动为目标对象生成一个代理对象。在上层自动注入的时候注入的就变成了代理对象而不是目标对象。
[外链图片转存中…(img-wj3PPYmi-1716083522138)]
-
进阶
-
通知类型
- @Around:环绕通知,此注解标注的通知方法在目标方法前后都执行
- @Before:前置通知,此注解标注的通知方法在目标方法前执行
- @After:后置通知,此注解标注的通知方法在目标方法后执行,无论是否抛异常
- @AfterReturning:返回后通知,此注解标注的通知方法在目标方法后执行,抛异常不执行
- @AfterThrowing:异常后通知,此注解标注的通知方法在目标方法发生异常后执行
tips:@Around环绕通知需要自己调用ProceedingJoinPoint.proceed()来让原始方法执行,其他通知不需要考虑目标方法执行;@Around环绕通知方法的返回值必须为Object,来接收原始方法的返回值
@PointCut注解的作用是将公共的切点表达式抽取出来,需要用到的时候引用该切点表达式即可
@Pointcut("execution(* priv.jie.service.impl.DeptServiceImpl.*(..))") public void pt(){}; @Around("pt()") public Object recordTime(ProceedingJoinPoint joinPoint) throws Throwable{ }-
通知顺序
不同切面类中,默认按照切面类的类名字母排序:
- 目标方法前的通知:字母排名靠前的先执行
- 目标方法后的通知:字母排名靠前的后执行
也可以用@Order(数字)加在切面泪类上来控制顺序:
- 目标方法前的通知:数字小的先执行
- 目标方法后的通知:数字小的后执行
-
切入点表达式
- 描述切入点方法的一种表达式
- 作用:决定项目中哪些目标方法需要加入通知
- 形式:
- execution(…):根据方法的签名匹配,上面有,略
- @annotation(…):根据注解匹配
-
连接点
-
-















 6425
6425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









