






CentOS7.5搭建Hadoop3.2.1+HBase2.3.5+Hive3.1.2+zookeeper3.4.9
一、安装包选择
公司项目需要搭建HBase和Hive测试环境,需要兼容Apache/FusionInsight/CDH、星环等发行版本,其他发行版本已做好Hadoop各组件的版本兼容,只有Apache需要自己选择匹配的安装包,查询官网资料,版本兼容需要考虑以下几个兼容关系:
1.Hadoop和HBase版本兼容关系:
http://hbase.apache.org/book.html#basic.prerequisites
搜索Hadoop version support matrix定位到兼容表格位置,建议选择对号标识的版本,这种是官方测试过的。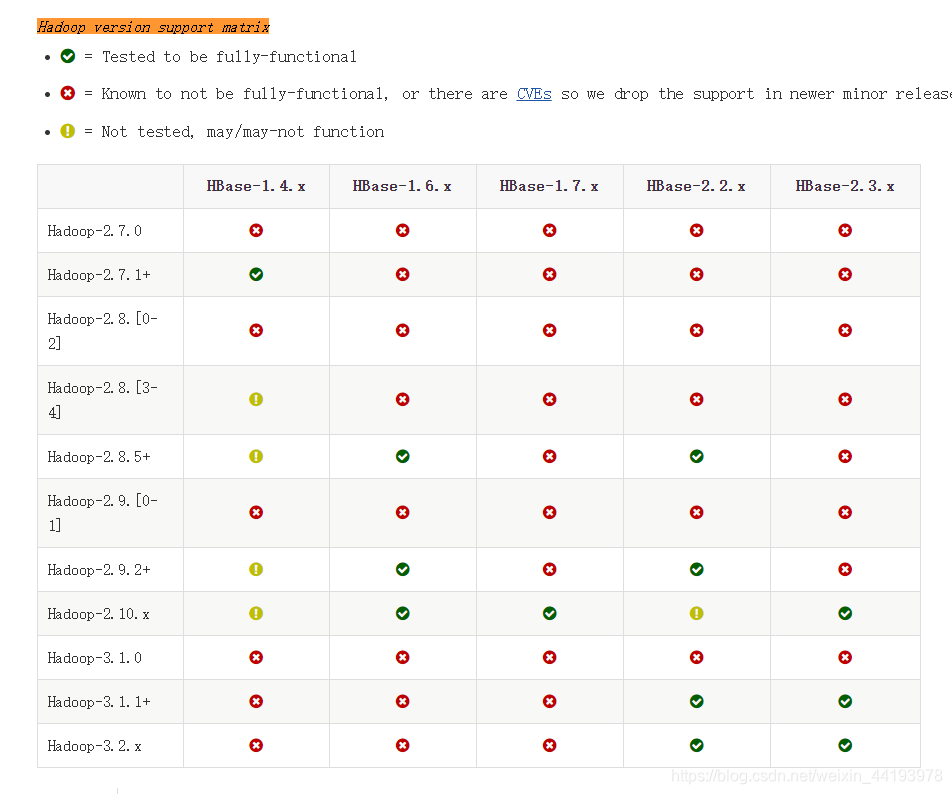
2.Hadoop与Hive版本对应关系
http://hive.apache.org/downloads.html
打开Hive官网下载界面,上面有说明Hive和Hadoop版本对应的关系如下图:
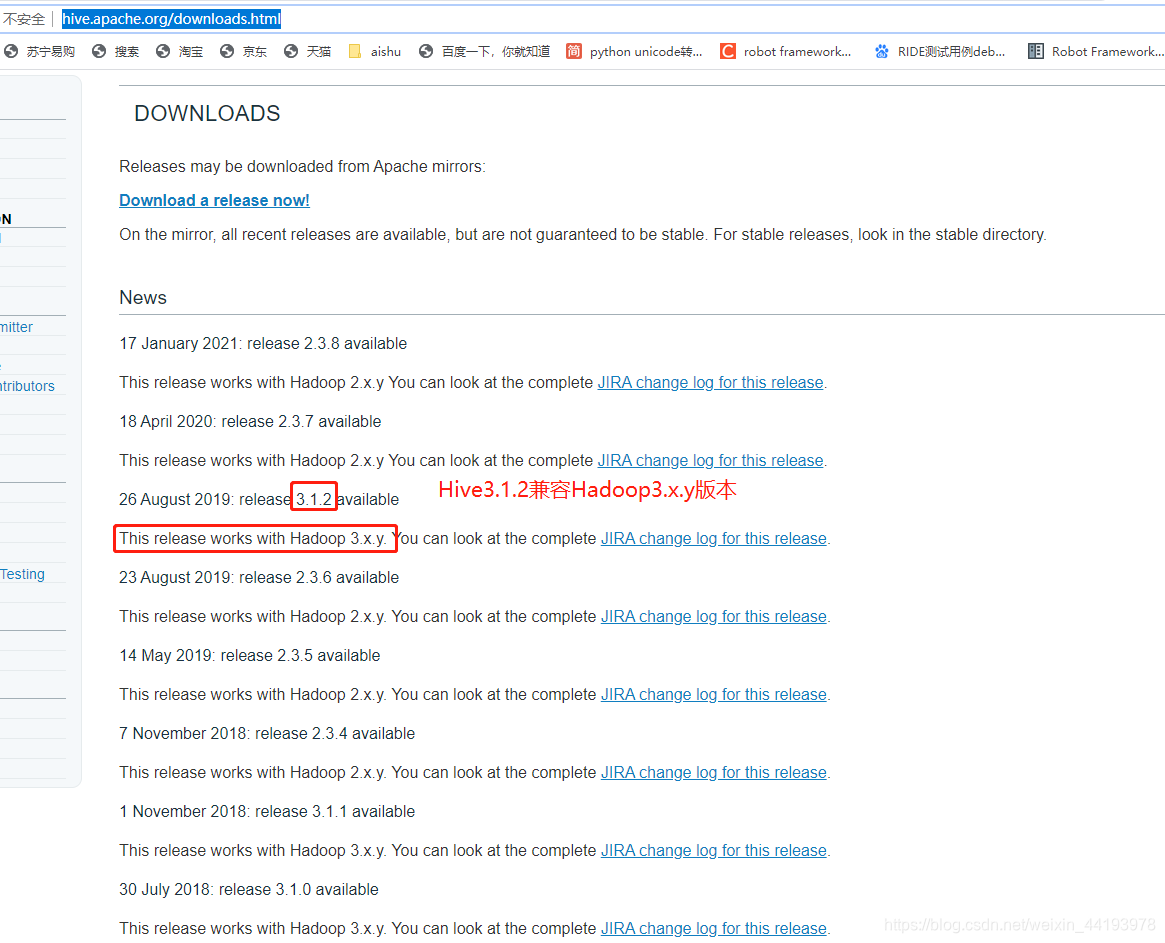
3.HBase和Hive版本兼容
https://cwiki.apache.org/confluence/display/Hive/HBaseIntegration

就这两句话,hive1.x与hbase0.98.x或则更低版本兼容;hive2.x与hbase1.x及比hbase1.x更高版本兼容
4.HBase与zookeeper版本对应
http://hbase.apache.org/book.html#basic.prerequisites
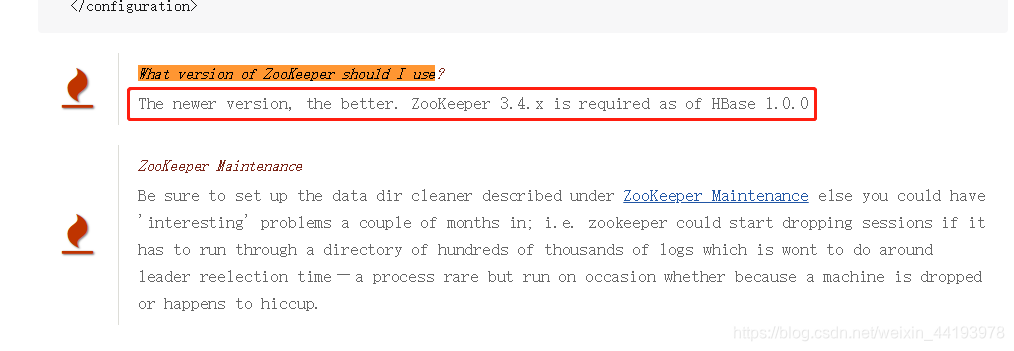
依然是HBase官方文档,HBase1.0.0之后需要zookeeper3.4.x版本,并且版本越新越好。
由此,我最终选择Hadoop3.2.1+HBase2.3.5+Hive3.1.2+zookeeper3.4.9的组合。
二、安装Hadoop3.2.1
本次安装的Hadoop集群为3节点,一个namenode,三个datanode。
| ip | 域名 | NameNode | DataNode |
|---|---|---|---|
| 192.168.129.11 | master | √ | √ |
| 192.168.129.12 | slave1 | × | √ |
| 192.168.129.13 | slave2 | × | √ |
用虚拟机搭建环境时,可以先配置好一个节点,然后克隆虚拟机,再更改一些特殊配置就可以了。
1.安装JDK
HBase2.3.5要求jdk版本为1.8以上,所以直接安装JDK1.8,可以下载rpm包安装,或下载压缩包解压。
#查看安装包
> rpm -qa | grep openjdk
#卸载
> rpm -e --nodeps `rpm -qa | grep openjdk`
下载jdk1.8压缩包,选择对应操作系统的版本,下载地址如下:
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
下载后解压至/usr/local/java,其他目录也可
> tar -zxvf jdk-8u271-linux-x64.tar.gz -C /usr/local/java
配置环境变量,在/etc/profile最后加上下面三个变量,JAVA_HOME对应的是jdk路径
export JAVA_HOME=/usr/local/java/jdk1.8.0_271
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
执行source /etc/profile命令导入环境变量,输入java -version,提示java版本即安装成功

2.关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
3.上传hadoop3.2.1压缩包,解压缩并配置环境变量
> tar -zxvf hadoop-3.2.1.tar,gz -C /usr/local/
在/etc/profile末尾加入如下内容
export HADOOP_HOME=/usr/local/hadoop-3.2.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
导入环境变量,输入hadoop,查看是否提示帮助信息
4.创建hadoop需要用到的目录
> mkdir -p /data/hadoop/tmp
> mkdir -p /data/hadoop/hdfs/name
> mkdir -p /data/hadoop/hdfs/data
5.修改hadoop配置文件
hadoop配置文件目录为:安装目录/etc/hadoop/
- hadoop-env.sh、yarn-env.sh
#修改JAVA_HOME值
export JAVA_HOME=/usr/local/java/jdk1.8.0_271
- core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
<description>HDFS的URI</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/data/hadoop/tmp</value>
<description>节点上本地的hadoop临时文件夹</description>
</property>
- hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
<description>副本个数,默认是3,应小于datanode数量</description>
</property>
<!--后增,如果想让solr索引存放到hdfs中,则还须添加下面两个属性-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
- mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定mapreduce使用yarn框架</description>
</property>
- yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<description>指定resourcemanager所在的hostname</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>
NodeManager上运行的附属服务。
需配置成mapreduce_shuffle,才可运行MapReduce程序
</description>
</property>
- workers
master
slave1
slave2
6.配置ssh免密登录
需要配置master到其他节点免密登录,可以在master上生成公钥文件并添加进authorized_keys中,这样复制出来的虚拟机可以免密登录
> ssh-keygen -t rsa #一直回车
> cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
7.克隆虚拟机,复制出其他节点
克隆后的虚拟机需要修改ip地址,hotsname
配置hosts:
vi /etc/hosts
#添加域名映射
192.168.237.10 master
192.168.237.11 slave1
192.168.237.12 slave2
8.格式化namenode
#在master机器上执行格式化命令
hdfs namenode -format
9.启动hadoop
#进入sbin目录,执行启动脚本
> cd /usr/local/hadoop-3.2.1/sbin
> ./start-dfs.sh
> ./start-yarn.sh
输入jps检查进程是否启动:
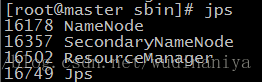
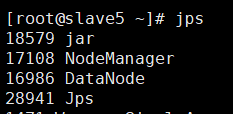
10.环境验证
访问master的50070端口查看web端界面是否正常
#访问hdfs目录,查看是否正常
hdfs dfs -ls /
三、安装zookeeper
1.下载zookeeper压缩包
去官网下载zookeeper3.4.9版本压缩包
2.上传并解压HBase
把压缩包上传至3个节点,并解压
> tar -zxvf zookeeper-3.4.9.tar.gz -C /usr/local/
3.添加环境变量
在这3个节点上编辑环境变量vim /etc/profile,新增下面两行
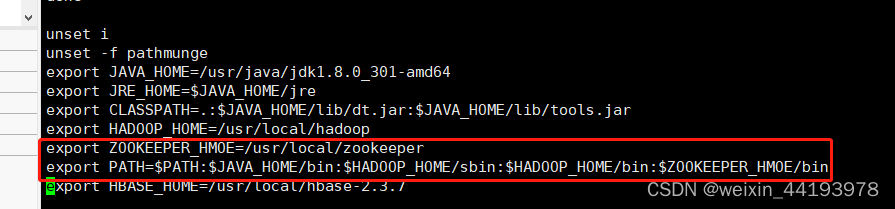
修改后加载环境变量,source /etc/profile
4.修改配置文件
3个节点都要修改下面的配置文件
进入zookeeper的conf目录下,复制并修改配置文件
> cd /usr/local/zookeeper/conf
> cp zoo_sample.cfg zoo.cfg
修改如下两处配置项,最下方是这三个节点的ip
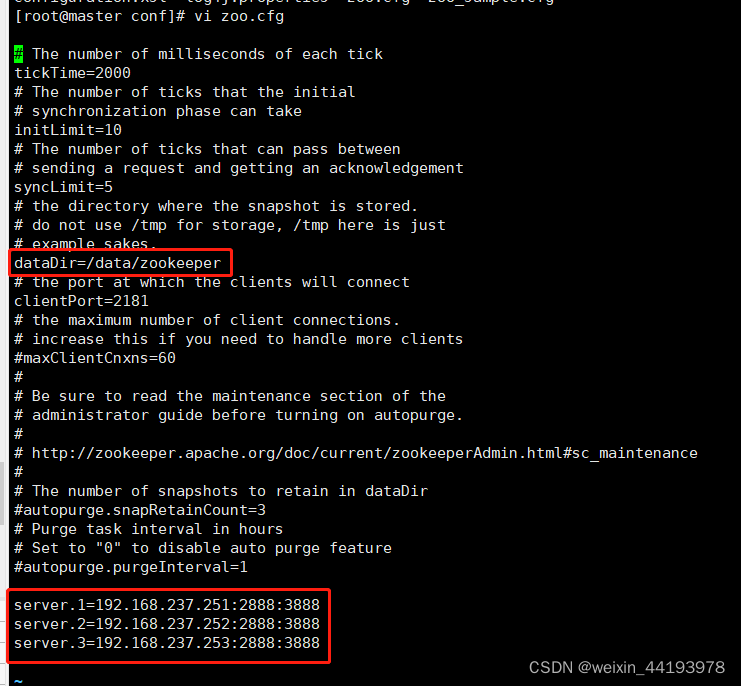
5.创建myid
进入这3个节点进入上面配置文件中dataDir对应的目录,创建文件myid,分别写入编号1、2、3,每个节点上的编号和zoo.cfg中的server.1、2、3序号一一对应
6.启动zookeeper
在3个节点上分别执行下面的命令
> zkServer.sh start
全部启动后可以查看下zookeeper的状态,应为一个leader,两个follower
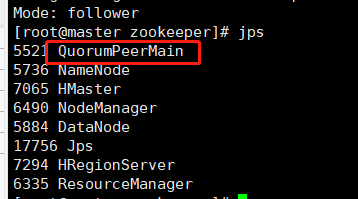
> zkServer.sh status

输入jps查看进程,可以看到QuorumPeerMain进程
四、安装HBase
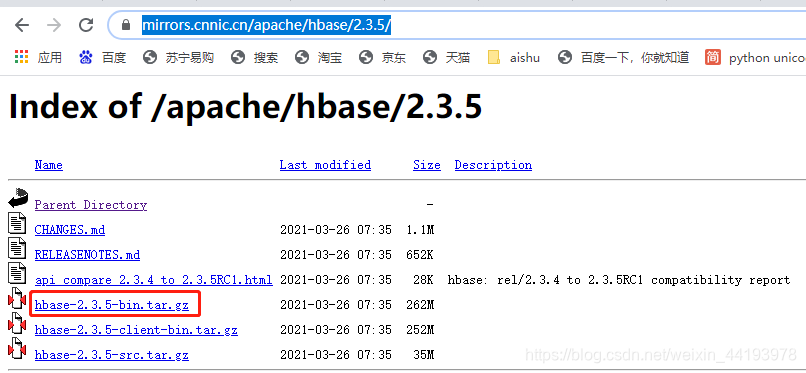
1.下载HBase压缩包
可以在官网下载,国内下载速度较慢:
http://archive.apache.org/dist/hbase/
推荐使用国内镜像源下载:
https://mirrors.cnnic.cn/apache/hbase/2.3.5/
2.上传并解压HBase
在所有节点上解压HBase压缩包
> tar -zxvf hbase-2.3.5-bin.tar.gz -C /usr/local/
3.配置hbase-env.sh
文件地址:hbase安装目录/conf/hbase-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_271
#是否使用hbase内置zookeeper
export HBASE_MANAGES_ZK=false
4.配置hbase-site.xml
文件地址:hbase安装目录/conf/hbase-site.xml
<configuration>
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
<description>本地临时目录,配置一个本地地址</description>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
<description>分布式的hbase设置为false</description>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
<description>hdfs地址,和hdfs-site.xml中保持一致,若不是HA模式,则配置为机器名:端口号的模式</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>集群模式,true为分布式,false为单机</description>
</property>
<!-- 0.98后的新变动,之前版本没有.port,默认端口为60000 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master1:2181,master2:2181,slave1:2181</value>
<description>zookeeper集群地址,多个机器时逗号间隔,2181为默认端口</description>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/data/hbase/zkData</value>
</property>
</configuration>
5.配置regionservers
文件地址:hbase安装目录/conf/regionservers
#添加regionserver节点域名
master1
master2
slave1
slave2
slave3
slave4
slave5
slave6
6.配置软连接
注意替换Hadoop和hbase实际安装目录
ln -s /usr/local/hadoop-3.2.1/etc/hadoop/core-site.xml /usr/local/hbase-2.3.5/conf/core-site.xml
ln -s /usr/local/hadoop-3.2.1/etc/hadoop/hdfs-site.xml /usr/local/hbase-2.3.5/conf/hdfs-site.xml
7.同步hbase目录至其他节点
注意:scp -r 无法复制软连接,会把软连接指向的文件复制到当前目录,所以如果使用scp -r需要在每个节点单独设置一遍软连接。或者直接使用rsync和xsync同步hbase目录。
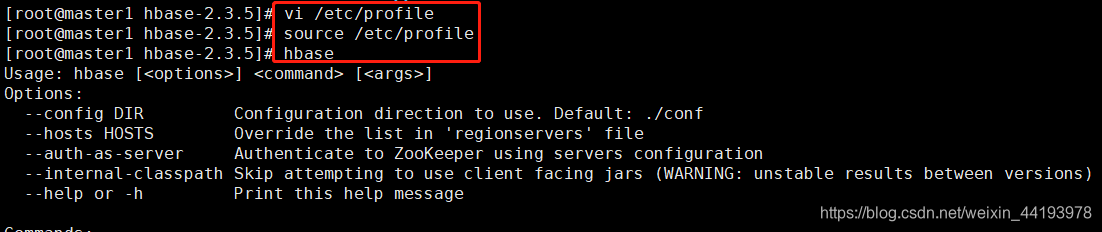
8.设置HBase环境变量(所有节点)
在/etc/profile末尾添加环境变量,并重新导入
export HBASE_HOME=/usr/local/hbase-2.3.5
export PATH=$PATH:$HBASE_HOME/bin
输入hbase查看是否提示帮助信息
9.配置备HMaster
在hbase安装目录下的conf下,新增文件backup-masters,添加备HMaster机器域名
文件地址:hbase安装目录/conf/backup-masters
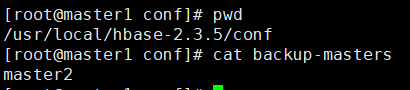
10.启动hbase
#全部启动
> cd /usr/local/hbase-2.3.5/bin
> start-hbase.sh
> stop-hbase.sh
#某个节点启动
> cd /usr/local/hbase-2.3.5/bin
> hbase-daemon.sh start master
> hbase-daemon.sh start regionserver
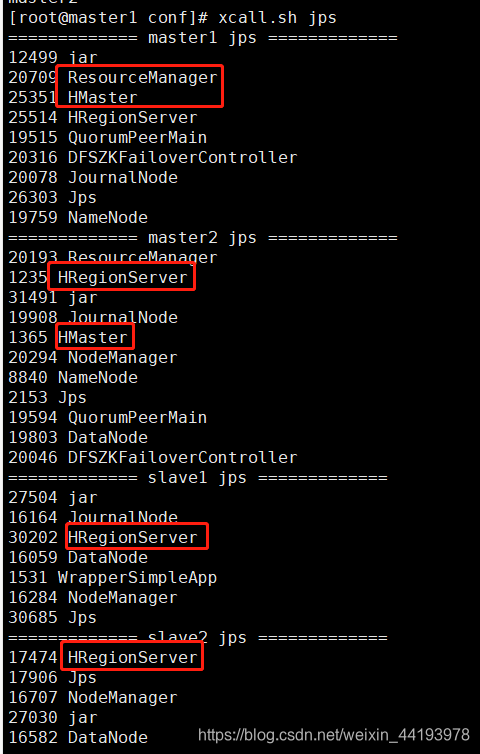
11.检查进程
各节点输入jps检查进程HMaster或HRegionServer是否启动成功
建议配置xcall.sh脚本批量查看集群所有节点jps
> vi xcall.sh
#!/bin/bash
nodelist=(master1 master2 slave1 slave2 slave3 slave4 slave5 slave6)
params=$@
for node in ${nodelist[*]};do
echo ============= $node $params =============
ssh $node "$params"
done
#设置全局可用
> mv xcall.sh /usr/local/bin
> cd /usr/local/bin
> chmod +x xcall.sh
> ln -s /usr/local/jdk1.8.0_271/bin/jps jps #所有节点
检查结果如下:
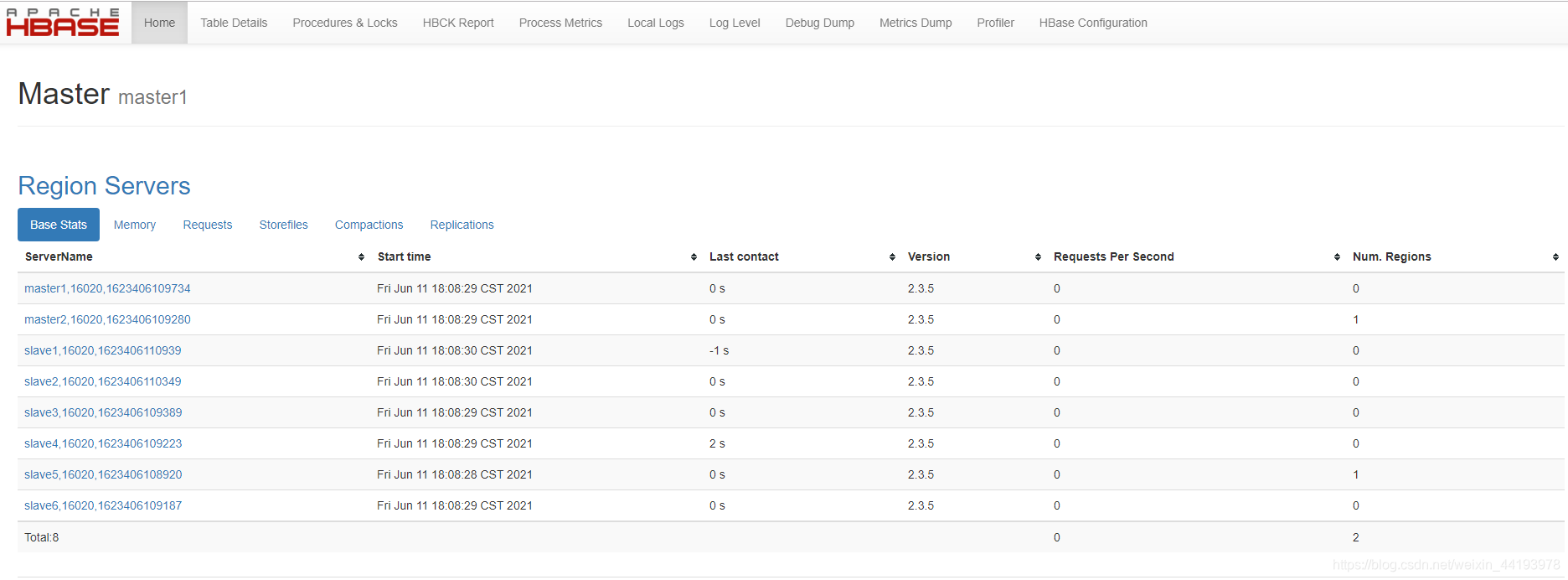
访问hbaseweb界面:http://master:16010
五、安装Hive
待补充。。。














 4384
4384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









