







信息收集步骤流程
目录
1.1 第一步 域名探测
当我们要对一个站点进行渗透测试之前,一般渗透测试人员常见方法是直接通漏洞扫描器来对指定目标站点进行渗透,当指定的目标站点无漏洞情况,渗透测试员就需要进行信息收集工作来完成后期的渗透。
目前一般域名漏洞扫描工具分为Web与系统扫描器
Web主要有:AWVS、APPSCAN、Netspark、WVSS 、WebInspect
系统扫描器有:Nmap、Nessus、天镜、明鉴、RSAS等,后面会分开给大家讲解。
1.2 第二步 子域名探测
根据主域名,可以获取二级域名、三级域名、…主要姿势可以有:

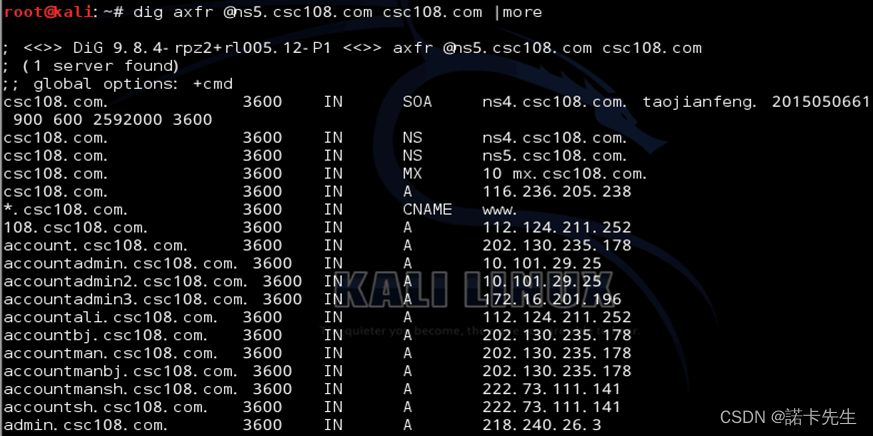
【1】DNS域传送漏洞(不得不称赞)
如果存在,不仅能搜集子域名,还能轻松找到一枚洞,这样子的好事百试不厌。如果SRC一级域名不多,直接在kali下 使用dnsenum工具,命令语法:`dnsenum oldboyedu.com`
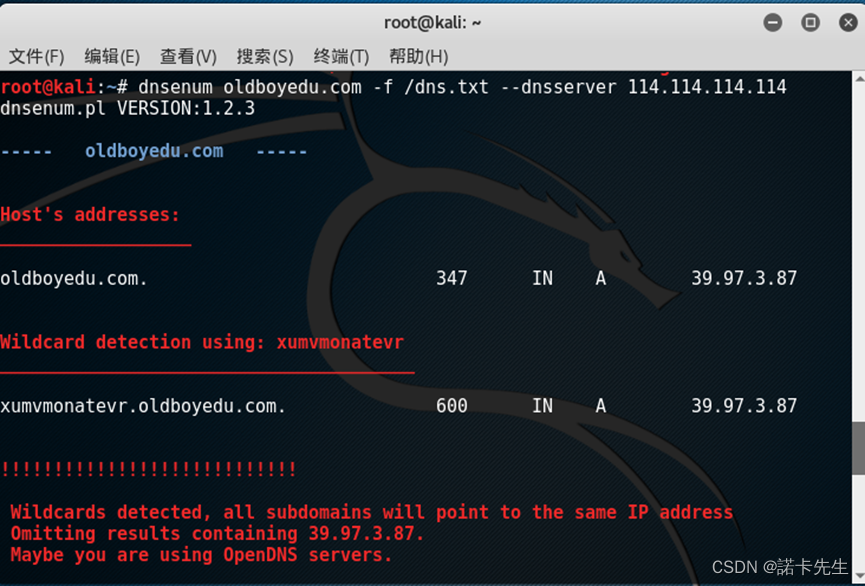
工具说明及用法可参考如下:
dnsenum的目的是尽可能收集一个域的信息,它能够通过谷歌或者字典文件猜测可能存在的域名,以及对一个网段进行反向查询。它可以查询网站的主机地址信息、域名服务器、mx record(函件交换记录),在域名服务器上执行axfr请求,通过谷歌脚本得到扩展域名信息(google hacking),提取自域名并查询,计算C类地址并执行whois查询,执行反向查询,把地址段写入文件。
参数说明:
-h 查看工具使用帮助
--dnsserver <server> 指定域名服务器
--enum 快捷选项,相当于"--threads 5 -s 15 -w"
--noreverse 跳过反向查询操作
--nocolor 无彩色输出
--private 显示并在"domain_ips.txt"文件结尾保存私有的ips
--subfile <file> 写入所有有效的子域名到指定文件
-t, --timeout <value> tcp或者udp的连接超时时间,默认为10s(时间单位:秒)
--threads <value> 查询线程数
-v, --verbose 显示所有的进度和错误消息
-o ,--output <file> 输出选项,将输出信息保存到指定文件
-e, --exclude <regexp> 反向查询选项,从反向查询结果中排除与正则表达式相符的PTR记录,在排查无效主机上非常有用
-w, --whois 在一个C段网络地址范围提供whois查询
-f dns.txt 指定字典文件,可以换成 dns-big.txt 也可以自定义字典
相关解析记录说明可参考:https://wenku.baidu.com/view/d2d597b669dc5022aaea0030.html
【2】备案号查询
这算是奇招吧,通过查询系统域名备案号,再反查备案号相关的域名,收获颇丰。
网站备案查询地址:
http://www.beianbeian.com、
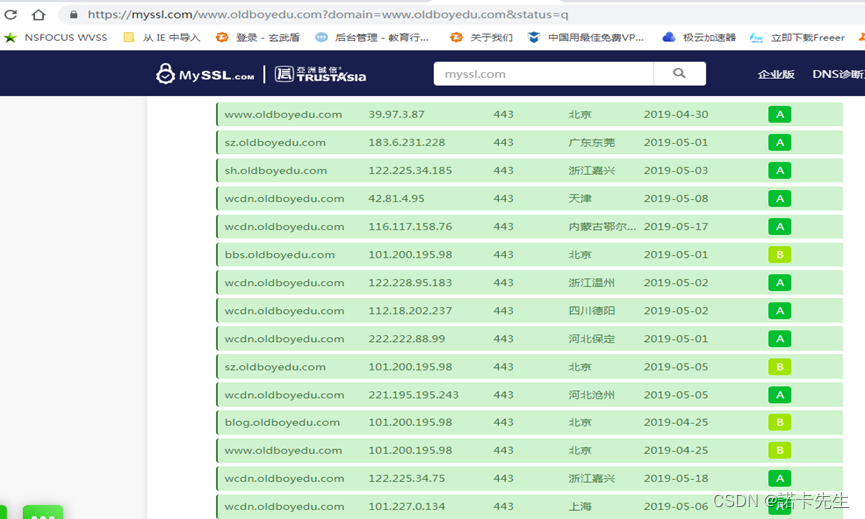
【3】SSL证书
通过查询SSL证书,获取的域名存活率很高,这应该也是不错的思路。
查询网址: https://myssl.com/ssl.html 和https://www.chinassl.net/ssltools/ssl-checker.html
【4】google搜索C段
这招用的比较少,国内没条件的就用bing或百度吧(国内站点足矣),在没什么进展的时候或许会有意外惊喜。
**方法一:**参考GoogleHack用法
**方法二:**用k8工具,前提条件记得注册bing接口
什么是C段:
比如在:127.127.127.4 这个IP上面有一个网站 127.4 这个服务器上面有网站我们可以想想…他是一个非常大的站几乎没什么漏洞!
但是在他同C段 127.127.127.1~127.127.127.255 这 1~255 上面也有服务器而且也有网站并且存在漏洞,那么我们就可以来渗透 1~255任何一个站 之后提权来嗅探得到127.4 这台服务器的密码 甚至3389连接的密码后台登录的密码 如果运气好会得到很多的密码…
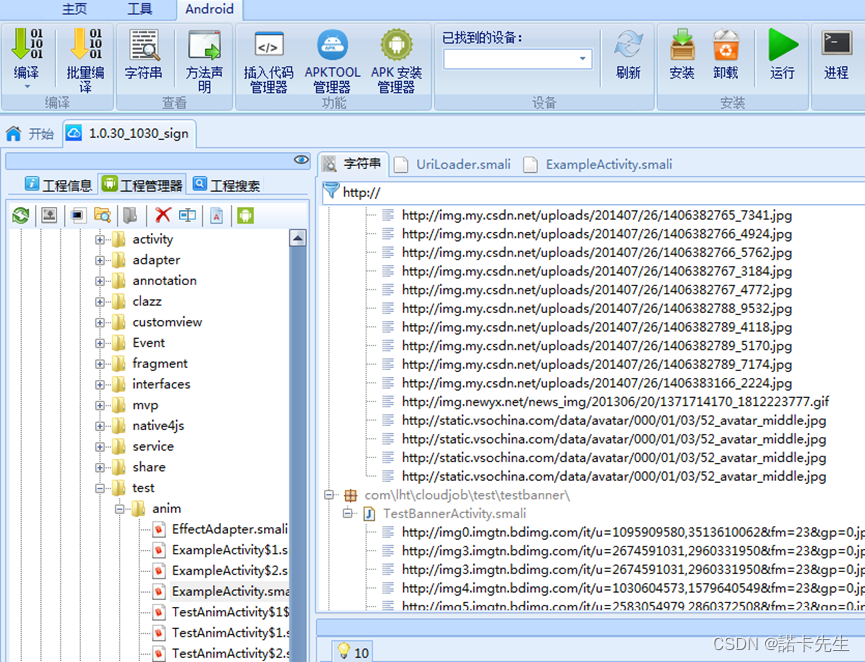
【5】APP提取
反编译APP(可使用反编译APP软件,网上很多)进行提取相关IP地址,此外在APP上挖洞的时候,可以发现前面招式找不到的域名,在APP里面有大量的接口IP和内网 IP,同时可获取不少安全漏洞。
【6】VX公众号
企业的另一通道,渗透相关公众号,绝对会有意外收获:不少漏洞+域名,有关Burp如何抓取微信公众号数据可参考 Burp APP抓包。
【7】字典枚举法
字典枚举法是一种传统查找子域名的技术,这类工具有 DNSReconcile、Layer子域名挖掘机、DirBuster等。
【8】公开DNS源
(1)DNS解析记录可以反查IP,比较早的解析记录有时可以查到真实IP,需要留意一下。
(2)注册人电话,注册人邮箱等社工信息可以钓鱼或者收集进字典来爆破目标办公系统。
Rapid7下Sonar项目发布的: https://scans.io/study/sonar.fdns_v2。
DNS历史解析: https://dnsdb.io/zh-cn/
【9】威胁情报查询
【10】JS文件域名、ip探测
【11】网站在线查找
查找目标域名信息的方法有:
(1)FOFA title=“公司名称”
(2)百度 intitle=公司名称
(3)Google intitle=公司名称
(4)站长之家,直接搜索名称或者网站域名即可查看相关信息:
http://tool.chinaz.com/
(5)钟馗之眼 site=域名即可https://www.zoomeye.org/
找到官网后,再收集子域名,下面推荐几种子域名收集的方法,直接输入domain即可查询
(6)子域名在线查询https://phpinfo.me/domain/
(7)子域名在线查询https://www.t1h2ua.cn/tools/
(8)Layer子域名挖掘机4.2(使用方便,界面整洁):https://www.webshell.cc/6384.html
(9)Layer子域名挖掘机5.0(使用方便,界面整洁):
点击下载 提取码:uk1j
(10)SubDomainBrute
https://github.com/lijiejie/subDomainsBrute
(11)Sublist3r
https://github.com/aboul3la/Sublist3r
提示:以上方法为爆破子域名,由于字典比较强大,所以效率较高。
(12)IP138查询子域名
https://site.ip138.com/baidu.com/domain.htm
(13)FOFA搜索子域名https://fofa.so/
语法:domain=”baidu.com”
更多语法可参看网址教程
提示:以上两种方法无需爆破,查询速度快,需要快速收集资产时可以优先使用,后面再用其他方法补充。
(14)Hackertarget查询子域名https://hackertarget.com/find-dns-host-records/
注意:通过该方法查询子域名可以得到一个目标大概的ip段,接下来可以通过ip来收集信息。
1.3 第三步 特殊信息
【1】Web源代码泄露
最想强调的是github信息泄露了,直接去github上搜索,收获往往是大于付出。可能有人不自信认为没能力去SRC挖洞,可是肯定不敢说不会上网不会搜索。github相关的故事太多,但是给人引出的信息泄露远远不仅在这里:
github.com、
rubygems.org、
pan.baidu.com…
**信息泄露收集可能会用到如下方式:
- 网盘搜索
- 社工信息泄露
- 源码搜索
- 钟馗之眼
- 天眼查
其它:威胁情报:微步在线、 ti.360.cn、 Virustotal等等
【2】Email信息收集
收集邮箱信息主要有两个作用:
1.通过发现目标系统账号的命名规律,可以用来后期登入其他子系统。
2.爆破登入邮箱用。
通常邮箱的账号有几种规律
当我们收集几个邮箱之后,便会大致猜出对方邮箱的命名规律。除了员工的邮箱之外,通过公司会有一些共有的邮箱,比如人力的邮箱、客服的邮箱,这种邮箱有时会存在弱口令,在渗透时可额外留意一下。我们可以通过手工或者工具的方式来确定搜集邮箱:
手工的方式:
1.可以到百度等搜索引擎上搜索邮箱信息
2.github等第三方托管平台
3.社工库
工具方式:
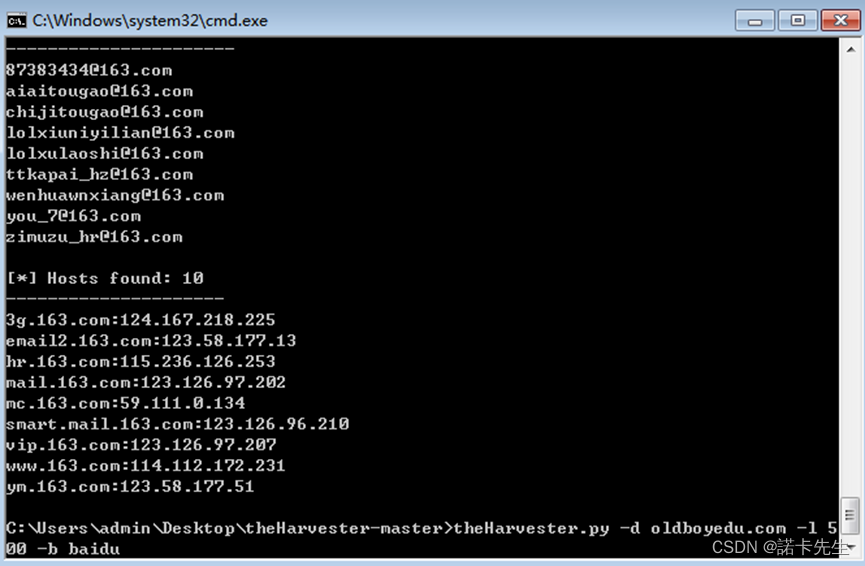
在邮箱收集领域不得不提一个经典的工具,The Harvester,The Harvester可用于搜索Google、Bing和PGP服务器的电子邮件、主机以及子域名,因此需要翻墙运行该工具。工具下载地址为:https://github.com/laramies/theHarvester
• 注:python -m pip install -r requirements.txt 导入相关配置,python3.6版本
使用方式很简单:
./theHarvester.py -d 域名 -1 1000 -b all
【3】历史漏洞收集
仔细分析,大胆验证,发散思维,对企业的运维、开发习惯了解绝对是有很大的帮助。可以把漏洞保存下来,进行统计,甚至炫一点可以做成词云展示给自己看,看着看着或者就知道会有什么漏洞。
【4】工具信息收集
如:7kbscan、破壳Web极速扫描器等
【5】whois查询
1、在线whois查询
通过whois来对域名信息进行查询,可以查到注册商、注册人、邮箱、DNS解析服务器、注册人联系电话等,因为有些网站信息查得到,有些网站信息查不到,所以推荐以下信息比较全的查询网站,直接输入目标站点即可查询到相关信息。
1.4 第四步 指纹识别、Waf、CDN识别
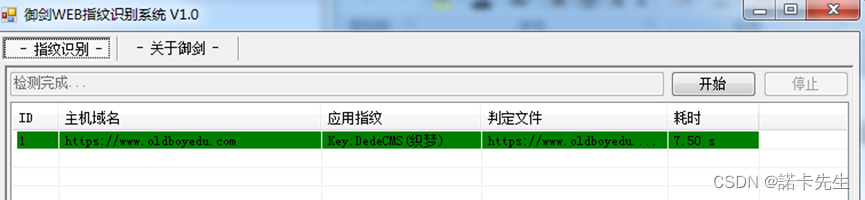
在这个过程中,可以加入端口扫描、敏感文件扫描之类的操作,工具可自由选择,如:
御剑WEB指纹识别系统、whatweb、Wapplyzer等工具。
一、在线识纹识别:
1、云悉
http://www.yunsee.cn/info.html
2、潮汐指纹
http://finger.tidesec.net/
3、CMS指纹识别
http://whatweb.bugscaner.com/look/
二、工具识别
工具下载链接:点击这里
1、Waf识别
github.com/EnableSecurity/wafw00f
2、CDN识别
如果目标网站使用了CDN,那么我们就需要找到它的真实ip
注意:很多时候,主站虽然是用了CDN,但子域名可能没有使用CDN,如果主站和子域名在一个ip段中,那么找到子域名的真实ip也是一种途径。
1、多地ping确认是否使用CDN
http://ping.chinaz.com/http://ping.aizhan.com/
2、查询历史DNS解析记录
在查询到的历史解析记录中,最早的历史解析ip很有可能记录的就是真实ip,快速查找真实IP推荐此方法,但并不是所有网站都能查到。
(1)DNSDB
https://dnsdb.io/zh-cn/
(2)微步在线
https://x.threatbook.cn/
(3)在线网站查找
https://tools.ipip.net/cdn.php
https://raw.githubusercontent.com/3xp10it/mytools/master/xcdn.py
1.5 第五步 旁站与C段
旁站往往存在业务功能站点,建议先收集已有IP的旁站,再探测C段,确认C段目标后,再在C段的基础上再收集一次旁站。
旁站是和已知目标站点在同一服务器但不同端口的站点,通过以下方法搜索到旁站后,先访问一下确定是不是自己需要的站点信息。
1、站长之家
同ip网站查询
http://stool.chinaz.com/same
2、网络空间搜索引擎
如FOFA搜索旁站和C段

该方法效率较高,并能够直观地看到站点标题,但也有不常见端口未收录的情况,虽然这种情况很少,但之后补充资产的时候可以用下面的方法nmap扫描再收集一遍。
3、Nmap,Msscan扫描等
例如:
nmap -p 80,443,8000,8080 -Pn 39.97.3.0/24
4、常见端口表
21,22,23,80-90,161,389,443,445,873,1099,1433,1521,1900,2082,2083,2222,2601,2604,3128,3306,3311,3312,3389,4440,4848,5432,5560,5900,5901,5902,6082,6379,7001-7010,7778,8080-8090,8649,8888,9000,9200,10000,11211,27017,28017,50000,50030,50060
注意:探测C段时一定要确认ip是否归属于目标,因为一个C段中的所有ip不一定全部属于目标。
1.6 第六步 资产梳理
有了庞大的域名,接下来就是帮助SRC梳理资产了。域名可以先判断存活,活着的继续进行确定IP环节。根据IP的分布,确定企业的公网网段。这其实是一项不小的工程,精准度比较难以拿捏。
-
SRC众测平台
-
国内平台
-
国外平台
-
威胁情报
-
社工库


















 1137
1137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









