






深度学习之tensorflow入门实例线性回归
首先需要生成一组原始数据
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
train_x=np.linspace(-1,1,100)
train_y=2*train_x+np.random.randn(*train_x.shape)*0.3
plt.plot(train_x,train_y,'ro',label='original data')
plt.legend()
plt.show()
关于函数的具体使用方法与参数传递可使用如下语句
print(help(np.linspace))
np.linspace(2.0, 3.0, num=5)
array([ 2. , 2.25, 2.5 , 2.75, 3. ])
np.linspace(2.0, 3.0, num=5, endpoint=False)//endpoint - 是否包含stop数值,默认为True,包含stop值;若为False,则不包含stop值
array([ 2. , 2.2, 2.4, 2.6, 2.8])
np.linspace(2.0, 3.0, num=5, retstep=True)//retstep - 返回值形式,默认为False,返回等差数列组,若为True,则返回结果(array([`samples`, `step`])),
(array([ 2. , 2.25, 2.5 , 2.75, 3. ]), 0.25)
生成的原始数据为y=2x加入了干扰信号所得,如下图所示

至此原始数据的生成已经完成
接下来需要进行搭建模型,分为正向搭建模型和反向搭建模型,正向搭建模型所需的神经网络知识在此不再赘述,写作z=wx+b
然后就可以创建模型了!
#正向搭建模型
X=tf.placeholder("float")
Y=tf.placeholder("float")
W=tf.Variable(tf.random_normal([1]),name="weight")
b=tf.Variable(tf.zeros([1]),name="bias")
z=tf.multiply(X,W)+b
说明:X,Y为占位符,一个代表x的输入,一个代表对应的真实值y。W,b为参数,其中W初始化为[-1,1]的随机数,形状为一维的数字,b的初始化为0,形状为一维的数字。
神经网络在训练的过程中数据的流向有两个方向,即将正向生成值与真实值进行比对,再通过反向过程进行参数调整。然后调来调去,最后得到满意的结果就OK了。
#反向优化模型
cost=tf.reduce_mean(tf.square(Y-z))
learning_rate=0.01
optimizer=tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
说明:cost为生成值与真实值的平方差,learning_rate为学习率,代表调参速度的快慢,值越小,精读越高,但是速度会越慢。tf.train.GradientDescentOptimizer这个东西是封装好的梯度下降算法(偷懒ing)。
准备工作完成后就可以进行迭代训练模型了!
#迭代训练模型
init=tf.global_variables_initializer()
training_epochs=20
display_step=2
with tf.Session() as sess:
sess.run(init)
plotdata={"batchsize":[],"loss":[]}
for epoch in range(training_epochs) :
for(x,y)in zip(train_x,train_y):
sess.run(optimizer,feed_dict={X:x,Y:y})
if epoch % display_step==0:
loss=sess.run(cost,feed_dict={X:train_x,Y:train_y})
print("Epoch",epoch+1,"cost=",loss,"W=",sess.run(W),"b=",sess.run(b))
if not (loss=="NA"):
plotdata["batchsize"].append(epoch)
plotdata["loss"].append(loss)
print("okk了")
print("cost=",sess.run(cost,feed_dict={X:train_x,Y:train_y}),"W=",sess.run(W),"b=",sess.run(b))
其输出结果如下所示

关于迭代训练模型的说明:training_epochs=20为迭代次数,sess.run可以进行网络节点的运算,feed机制进行反馈,将数据正确的放置到站位符的位置。
观察训练结果可以发现,cost的值在逐渐变小,而w,b也在不断调整,所得的线性回归结果也越发精确。
为了更加直观的表示线性回归的结果,在此使训练模型可视化
以下为枯燥的绘图代码
plt.plot(train_x,train_y,'ro',label='original data')
plt.plot(train_x,sess.run(W)*train_x+sess.run(b),label='Fittedline')
plt.legend()
plt.show()
输出结果如下

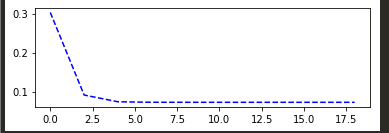
为了更加直观的表示迭代过程,再来一段枯燥的绘图代码
plotdata["avgloss"]=moving_average(plotdata["loss"])
plt.figure(1)
plt.subplot(211)
plt.plot(plotdata["batchsize"],plotdata["avgloss"],'b--')
plt.show()
其中需在代码顶端进行函数定义
plotdata= plotdata={"batchsize":[],"loss":[]}
def moving_average(a,w=10):
if len(a)<w:
return a[:]
return[val if idx<w else sum(a[(idx-w):idx])/w for idx,val in enumerate(a)]
可得到loss的变化趋势
至此,tensorflow的线性拟合功能已经实现。
对于拟合结果的应用我们可以通过传值进行预测
例如,预测x=0.6时的z值
print("x=0.6,z=",sess.run(z,feed_dict={X:0.6}))
可得x=0.6,z= [1.2273693]
为了提高精度,在此提高迭代次数为40,再次查看输出结果

cost= 0.104141384 W= [1.9663191] b= [0.01071851]
发现精度有所提高,理论上迭代次数足够高时,就能得到更为精确的结果。
那么本次实例就到此结束了,不定期更新哦>_<
附源代码
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
plotdata= plotdata={"batchsize":[],"loss":[]}
def moving_average(a,w=10):
if len(a)<w:
return a[:]
return[val if idx<w else sum(a[(idx-w):idx])/w for idx,val in enumerate(a)]
train_x=np.linspace(-1,1,100)
train_y=2*train_x+np.random.randn(*train_x.shape)*0.3
plt.plot(train_x,train_y,'ro',label='original data')
plt.legend()
plt.show()
X=tf.placeholder("float")
Y=tf.placeholder("float")
W=tf.Variable(tf.random_normal([1]),name="weight")
b=tf.Variable(tf.zeros([1]),name="bias")
z=tf.multiply(X,W)+b
cost=tf.reduce_mean(tf.square(Y-z))
learning_rate=0.01
optimizer=tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
init=tf.global_variables_initializer()
training_epochs=40
display_step=2
with tf.Session() as sess:
sess.run(init)
plotdata={"batchsize":[],"loss":[]}
for epoch in range(training_epochs) :
for(x,y)in zip(train_x,train_y):
sess.run(optimizer,feed_dict={X:x,Y:y})
if epoch % display_step==0:
loss=sess.run(cost,feed_dict={X:train_x,Y:train_y})
print("Epoch",epoch+1,"cost=",loss,"W=",sess.run(W),"b=",sess.run(b))
if not (loss=="NA"):
plotdata["batchsize"].append(epoch)
plotdata["loss"].append(loss)
print("okk了")
print("cost=",sess.run(cost,feed_dict={X:train_x,Y:train_y}),"W=",sess.run(W),"b=",sess.run(b))
plt.plot(train_x,train_y,'ro',label='original data')
plt.plot(train_x,sess.run(W)*train_x+sess.run(b),label='Fittedline')
plt.legend()
plt.show()
plotdata["avgloss"]=moving_average(plotdata["loss"])
plt.figure(1)
plt.subplot(211)
plt.plot(plotdata["batchsize"],plotdata["avgloss"],'b--')
plt.show()
print("x=0.6,z=",sess.run(z,feed_dict={X:0.6}))
ps:csdn自带的水印可太丑了
参考文献:深度学习之TensorFlow入门,原理与进阶实战















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









