







# 前面已经对数据进行了初步清洗。Python暂时搞不定的,用excel先搞定了应应急。
# 下面正式开始数据分析
# 导入常用模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 读取卡罗拉口碑数据文件
corolla1=pd.read_csv("D:\\2018_BigData\\Python\\Python_files_Notebook\\Decision on buying cars COROLLA or LEVIN\\corolla_1st_deal.csv",encoding="ANSI")
corolla1.head(1)
# 发现有31列那么多。。。23+1+2+5,还是得drop一些列,清爽一些先。
| Unnamed: 0 | name-text | 车型 | 购买地点 | 购车经销商 | 购买时间 | nakedprice | driven-distance | 发表时间 | 空间 | ... | reviews | 购车目的1 | 购车目的2 | 购车目的3 | 购车目的4 | 购车裸车价 | 行驶里程 | 支持人数 | 阅览人数 | 评论人数 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 八号零陈 | 2018款 双擎 1.8L E-CVT智尚版 | 北京 | 北京中业丰田 | 2018年12月 | 14.18 | 2500 | 2019/1/13 | 4 | ... | 29 | 购物 | 接送小孩 | 无 | 无 | 14.18?万元 | 2500?公里 | 有36人支持该口碑 | 有82222人看过 | 评论(29) |
1 rows × 31 columns
# 删除多余列——其实本来可以在Excel里将多出的6列先删除。
corolla2=corolla1.drop(["Unnamed: 0","购车裸车价","行驶里程","支持人数","阅览人数","评论人数"],axis=1)
corolla2.head(1)
| name-text | 车型 | 购买地点 | 购车经销商 | 购买时间 | nakedprice | driven-distance | 发表时间 | 空间 | 动力 | ... | 内饰 | 性价比 | 购买车型 | support | read | reviews | 购车目的1 | 购车目的2 | 购车目的3 | 购车目的4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 八号零陈 | 2018款 双擎 1.8L E-CVT智尚版 | 北京 | 北京中业丰田 | 2018年12月 | 14.18 | 2500 | 2019/1/13 | 4 | 3 | ... | 4 | 4 | 卡罗拉 2018款 双擎 1.8L E-CVT智尚版?>> | 36 | 82222 | 29 | 购物 | 接送小孩 | 无 | 无 |
1 rows × 25 columns
# 同样,导入levin口碑数据并删除多余列
levin1=pd.read_csv("D:\\2018_BigData\\Python\\Python_files_Notebook\\Decision on buying cars COROLLA or LEVIN\\levin_1st_deal.csv",encoding="ANSI")
levin2=levin1.drop(["Unnamed: 0","购车裸车价","行驶里程","支持人数","阅览人数","评论人数"],axis=1)
levin2.head(1)
| name-text | 车型 | 购买地点 | 购车经销商 | 购买时间 | nakedprice | driven-distance | 发表时间 | 空间 | text-cont | ... | 内饰 | 性价比 | 购买车型 | support | read | reviews | 购车目的1 | 购车目的2 | 购车目的3 | 购车目的4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | VOLVO110 | 2018款 双擎 1.8H GS-V CVT尊贵版 国V | 广州 | 广汽丰田天河店 | 2018年11月 | 13.18 | 3300 | 2018/11/29 | 4 | 【最满意的一点】最满意当然是油耗,还有就是能在广州摇节能号,广州人都知道摇号不是一般的难啊,... | ... | 3 | 3 | 雷凌 2018款 双擎 1.8H GS-V CVT尊贵版 国V?>> | 26 | 47833 | 25 | 上下班 | 自驾游 | 泡妞 | 跑长途 |
1 rows × 25 columns
corolla2.shape
(405, 25)
levin2.shape
(340, 25)
# 好了,至此,统一corolla和levin的数据列,且都是有效数据样本。
# 按照之前拟好的分析框架思路,先看下裸车价格分布
plt.hist(corolla2['nakedprice'],bins=18)
plt.xlabel("购车裸车价",fontproperties="SimHei",fontsize=18)
plt.ylabel("数量",fontproperties="SimHei",fontsize=18)
plt.title("Nakedprice Distribution",fontsize=20)
plt.show() # 此语句可不用。
# 发现有个漏网之鱼,数值为2左右。估计是Excel里填充的时候出错或者源数据有误。
# 速战速决,就不用Python替换了,直接回去Excel里搞定,顺便检查一下其他填充处理的几列有没有异常值。
# Excel处理完后,回Python更新数据,得到如下直方图。
# 可见,卡罗拉裸车价分布主要集中在11~12.8万,14.5~15.3万,对应两个价位区间的车型及客户群体。
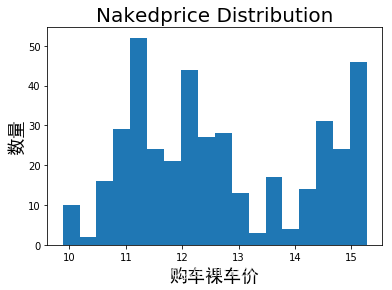
# 其实之前的分析框架是根据行业经验定下的,现在既然有数据了,那先把框架放一边,先继续看看数据呈现。
# 先试试提取一列
price=corolla2["nakedprice"]
price.head(5)
0 14.18
1 11.28
2 14.43
3 14.18
4 14.28
Name: nakedprice, dtype: float64
# 然后试试提取两列。
# 为什么要提取两列呢?因为后面有一些画图,data来源是两列或多列表格。需要提取定义。
# area_price=corolla2["nakedprice","购买地点"]
# area_price.head(5)
# 运行报错 KeyError: ('nakedprice', '购买地点')
# 以为是“购买地点”中文字符的原因,就替换成了“driven-distance”再试,也是报同样的KeyError,说明不是字符格式问题。
area_price=corolla2[["nakedprice","购买地点"]]
area_price.head(5)
# 尝试corolla2(["nakedprice","购买地点"]),错误
# 尝试corolla2(["nakedprice","购买地点"]).values,错误
# 尝试corolla2.ix(["nakedprice","购买地点"]),错误
# ……
# 找了好久都找不到提取两列数据的方法,终于在这里找到了,原来加多一个中括号就搞定——http://www.sohu.com/a/289195562_468731
| nakedprice | 购买地点 | |
|---|---|---|
| 0 | 14.18 | 北京 |
| 1 | 11.28 | 泉州 |
| 2 | 14.43 | 郑州 |
| 3 | 14.18 | 沈阳 |
| 4 | 14.28 | 上海 |
# 耍耍帅,购车裸车价这列,再用其他可视化形式看看
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









