






一、RAG 概述
RAG(Retrieval Augmented Generation)技术,通过检索与用户输入相关的信息片段,并结合外部知识库来生成更准确、更丰富的回答。解决 LLMs 在处理知识密集型任务时可能遇到的挑战, 如幻觉、知识过时和缺乏透明、可追溯的推理过程等。提供更准确的回答、降低推理成本、实现外部记忆。
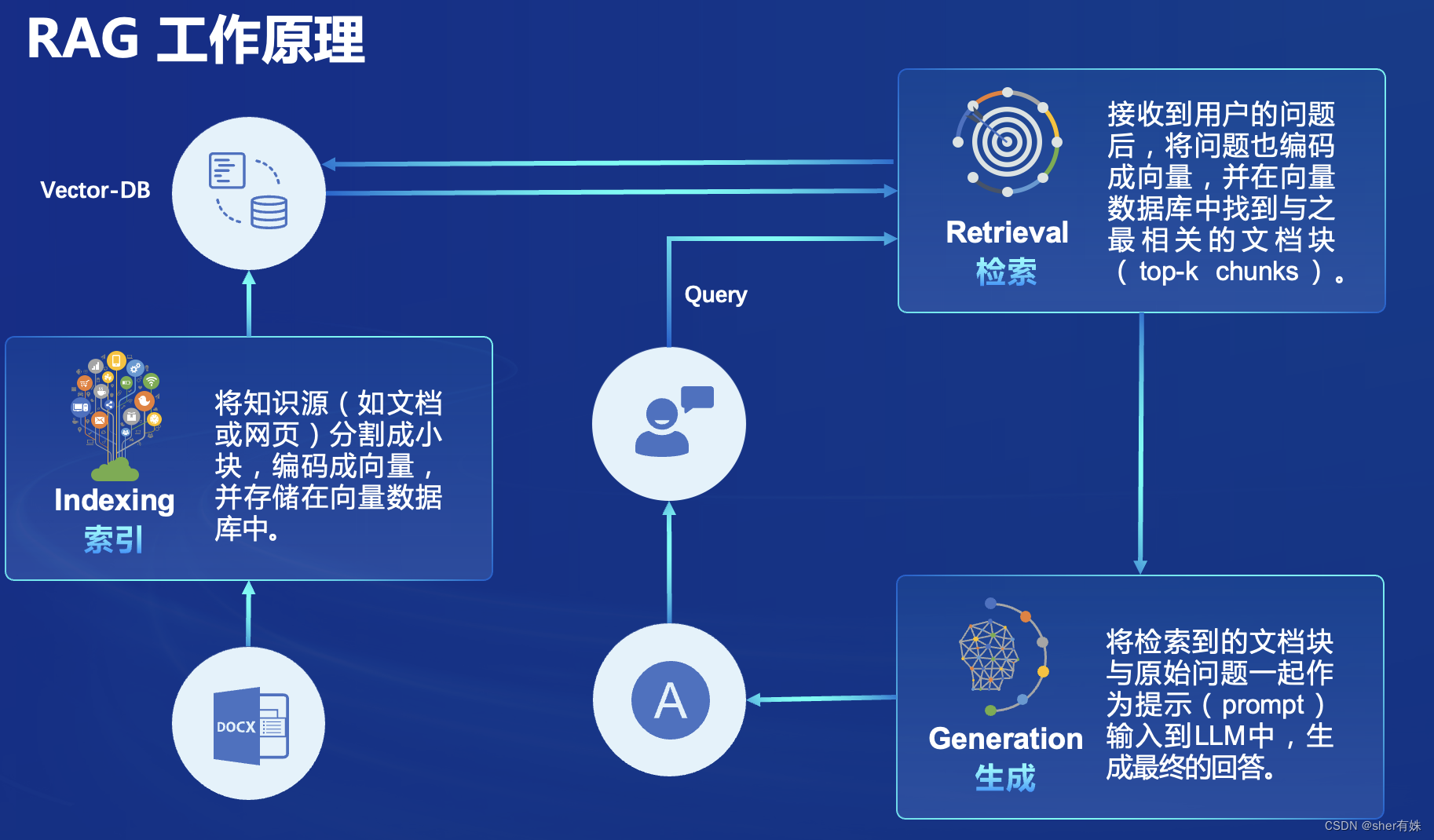 RAG 能够让基础模型实现非参数知识更新,无需训练就可以掌握新领域的知识。
RAG 能够让基础模型实现非参数知识更新,无需训练就可以掌握新领域的知识。
RAG流程示例
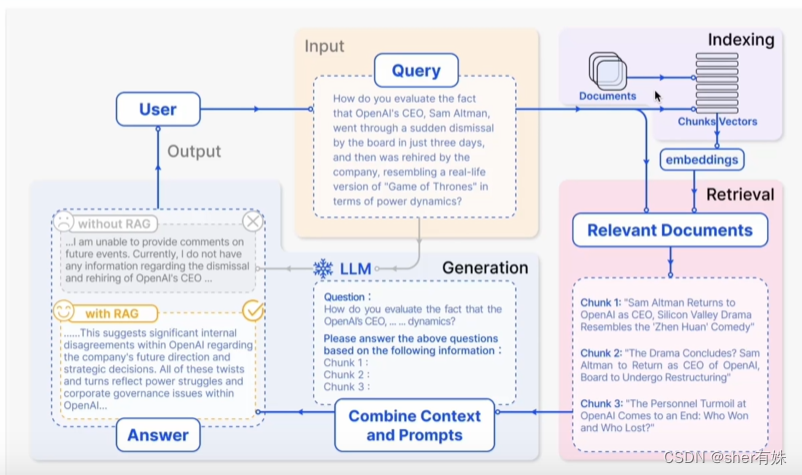
二、RAG的发展历程
RAG的概念最早是由Meta(Facebook)的Lewis等人在2020《Retrieval-Augmented Generation for
Knowledge-Intensive NLp Tasks》中提出的。
Naive RAG:基本范式,用于问答系统和信息检索场景;
Advanced RAG:对检索前后进行增强,用于摘要生成、内容推荐等场景;
Modular RAG:模块化,用于多模态任务、对话系统等。
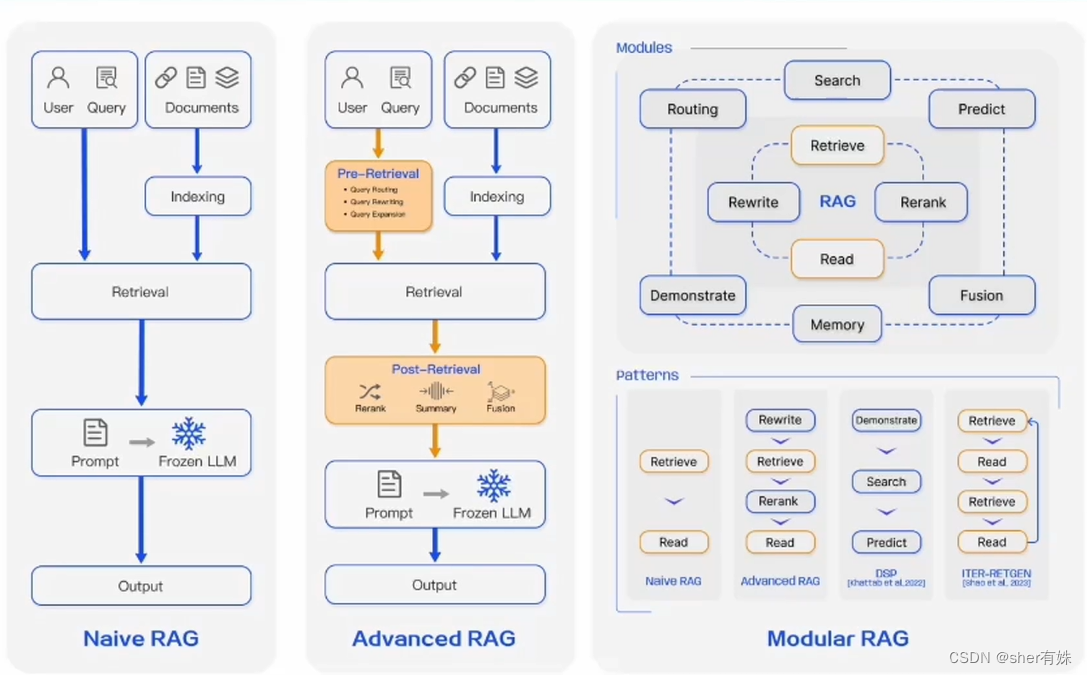
三、RAG的优化方法
1. 嵌入优化EmbeddingOptimization
通过结合稀疏和密集检索,多任务的方式增强嵌入的性能。
2. 索引优化IndexingOptimization
通过细粒度分割( Chunk ),元数据等策略来提升索引的质量。
3. 查询优化QueryOptimization
查询扩展、转换,多查询
4. 上下文管理Context Curation
重排(rerank),上下文选择/压缩
5. 迭代检索Iterative Retrieval
根据初始查询和迄今为止生成的文本进行重复搜索
6. 递归检索Recursive Retrieval
迭代细化搜索查询
链式推理(Chain-of-Thought)指导检索过程
7. 自适应检索Adaptive Retrieval
Flare , Self-RAG,使用LLMs主动决定检索的最佳时机和内容
8. LLM微调LLM Fine-tuning
检索微调,生成微调,双重微调
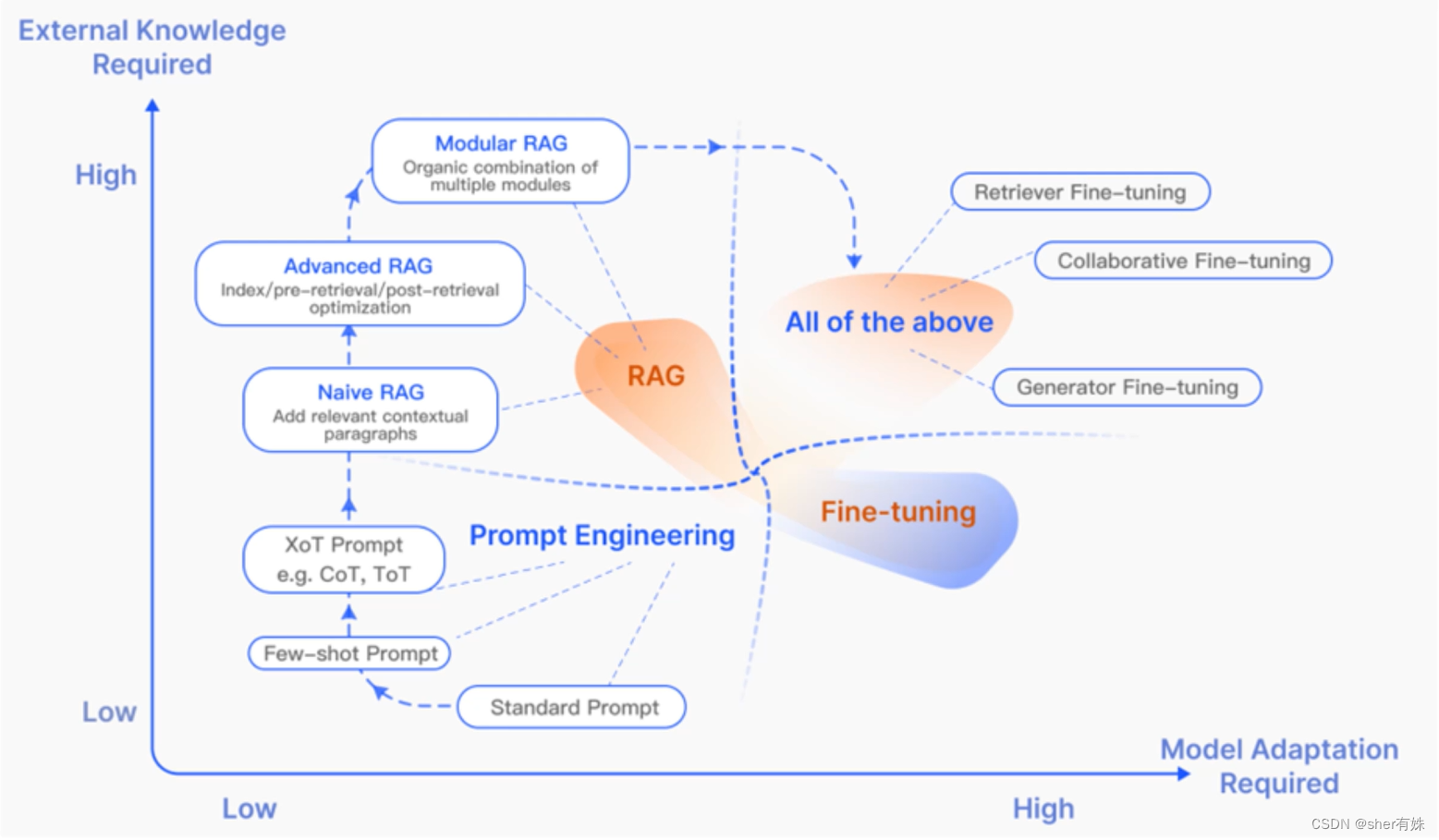
四、RAG VS 微调
RAG
非参数记忆,利用外部知识库提供实时更新的信息。
能够处理知识密集型任务,提供准确的事实性回答。
通过检索增强,可以生成更多样化的内容。
适用场景:适用于需要结合最新信息和实时数据的任务:开放域问答、实时新闻摘要等
优势:动态知识更新,处理长尾知识问题。
局限:依赖于外部知识库的质量和覆盖范围。依赖大模型能力。
Fine-tuning
参数记忆,通过在特定任务数据上训练,模型可以更好地适应该任务。
通常需要大量标注数据来进行有效微调。
微调后的模型可能过拟合,导致泛化能力下降。
适用场景:适用于数据可用且需要模型高度专业化的任务如特定领域的文本分类、情感分析、文本生成等。
优势:模型性能针对特定任务优化。
局限:需要大量的标注数据,且对新任务的适应性较差。
LLM 模型优化方法比较
五、评估指标
经典评估指标:
准确率(Accuracy)
召回率(Recall)
F1分数(F1 Score)
BLEU分数(用于机器翻译和文本生成)
ROUGE分数(用于文本生成的评估)
RAG 评测框架:
基准测试-RGB、RECALL、CRUD
评测工具-RAGAS、ARES、TruLens
茴香豆
茴香豆是一个基于LMs的领域知识助手,由书生浦语团队开发的开源大模型
- 专为即时(IM)工具中的群聊场景优化的工作流,提供及时准确的技术支持和自动化问答服务。
- 通过应用检索增强生成(RAG)技术,茴香豆能够理解和高效准确的回应与特定知识领域相关的复杂查询。
应用场景
智能客服:技术支持、领域知识对话
IM工具中创建用户群组,讨论、解答相关的问题,
随着用户数量的增加,答复内容高度重复,充斥大量无意义和闲聊,人工回复,成本高,影响工作效率
茴香豆通过提供自动化的问答支持帮助维护者减轻负担,同时确保用户问题得到有效解答。
场景难点
群聊中的信息量巨大,且内容多样,从技术讨论到闲聊应有尽有。
用户问题通常与个人紧密相关,需要准确的实时的专业知识解答。
传统的NLP解决方案无法准确解析用户意图且往往无法提供满意的答案。
需要一个能够在群聊中准确识别与回答相关问题的智能助手,同时避免造成消息过载。
构建自己的茴香豆


运行茴香豆助手
















 611
611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









