







qemu 是一个在 linux 上广泛使用的可以模拟 ARM 的模拟器。通过交叉编译工具,我们就可以在 CPU 能力很强、存储空间足够的主机平台上(比如 PC 上)编译出针对其他平台的可执行程序。在安装 qemu 模拟器之前安装了交叉编译工具链,满足交叉编译的要求,然后安装了相应的依赖库以满足 qemu 的正常运行。
qemu-arm和qemu-system-arm的区别:
qemu-arm是用户模式的模拟器(更精确的表述应该是系统调用模拟器),而qemu-system-arm则是系统模拟器,它可以模拟出整个机器并运行操作系统
qemu-arm仅可用来运行二进制文件,因此你可以交叉编译完例如hello world之类的程序然后交给qemu-arm来运行,简单而高效。而qemu-system-arm则需要你把hello world程序下载到客户机操作系统能访问到的硬盘里才能运行。
运行环境具体搭建可见博文:https://blog.csdn.net/tycoon1988/article/details/46530063
实战演练:
1.file guest //查看文件格式 checksec guest //查看保护机制

可以看见是32位可执行文件,正常查看安全防护,开启了 DEP 保护后栈上就没有执行的权限也就无法控制程序流程。
此处要加深一下印象,之前学的模模糊糊的。一存在溢出漏洞的程序,当处理某些文件时未能检查文件长度的限制,导致栈区溢出,若不开启DEP保护,则溢出后EIP可以跳转至栈区执行指令,而当添加了DEP保护后,由于栈区被标记为不可执行。
一般题目中有目标函数,直接覆盖返回地址到函数入口就可以getshell,
其他题,需要执行指令拿shell,即编写shellcode。当获取任意地址读写能力时,即可写入shellcode,再执行此处的代码即可。了解到开启PIE(内存空间随机化)的话可以防范基于return2libc方式的针对DEP的攻击,这里没开启哈哈哈哈。
2.既然是32位的,当然要拉进ida里康康咯
不看不知道,一看吓一跳(第一反应确实如此)
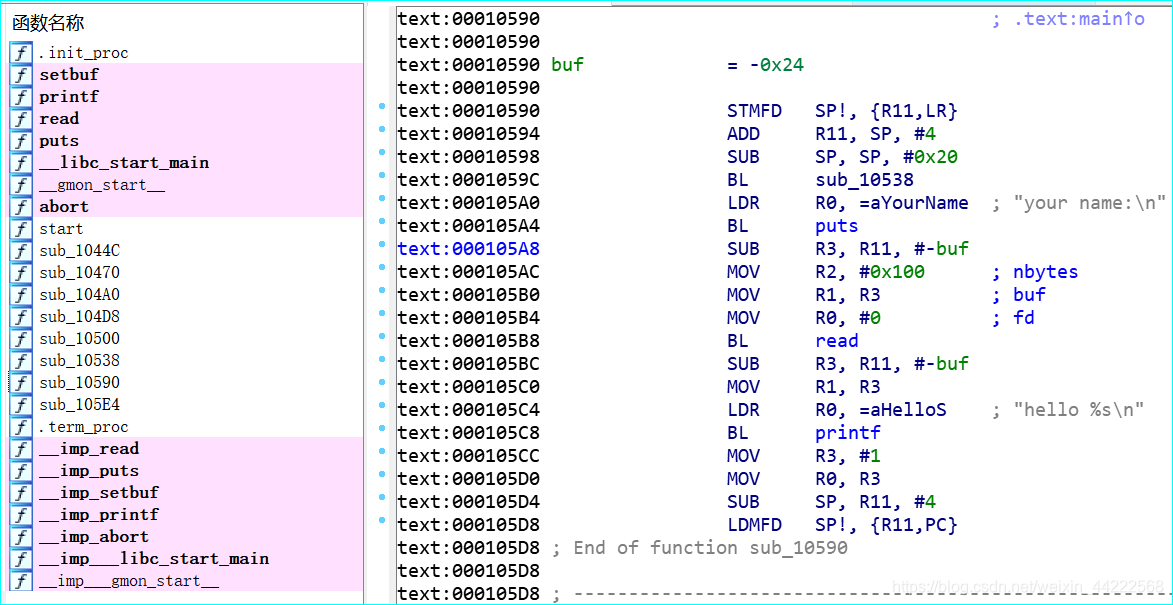
第一疑惑,没有main函数,所有东西都去符号了,挨个F5反编译一下中间白色地带的函数。
#IDA里的一些表示:
sub_XXXXX 地址XXXX的子例程
loc_XXXXX 地址XXXX的一个指令
byte/word/dword_XXXXX 地址XXXX的8/16/32位数据
unk_XXXXX 地址XXXX的未知数据
反编译结果如下:
__int64 sub_10500()
{
return sub_104A0();
}
sub_10500函数的功能是return sub_104A0();
__int64 sub_104A0()
{
__int64 result; // r0
LODWORD(result) = &unk_21034;
HIDWORD(result) = 0;
return result;
}
这是在32位系统上为变量分配64位值的典型模式——分别计算每个32位值,然后将它们推入64位值的高32位和低32位。
“LODWORD()”从“result”和“HIDWORD()”中提取了低DWORD,而“HIDWORD()”从高DWORD中提取了高DWORD。
(DWORD 就是 Double Word, 每个word为2个字节的长度,DWORD 双字即为4个字节,每个字节是8位,共32位。DWORD在Windows下经常用来保存地址(或者存放指针))
sub_104A0函数的功能是返回result—低32位是未知地址unk_21034的数据,高32位为0.
点进unk_21034未知地址,
LOAD:00021034 ; ORG 0x21034
LOAD:00021034 unk_21034 % 1 ; DATA XREF: sub_10470+4↑o
LOAD:00021034 ; .text:off_10498↑o ...
LOAD是取后面地址单元的内容,放到前面地址单元里面去。SORE是把前面地址的内容存储到后面地址单元里面去。也就是说未知地址unk_21034里存放的就是1?一会在gdb里确认一下就好。
void *sub_10470()
{
return &unk_21034;
}
sub_10470函数也是返回这个地址;啥情况
void sub_10538()
{
setbuf((FILE *)stdin, 0);
setbuf((FILE *)stdout, 0);
setbuf((FILE *)stderr, 0);
}
sub_10538 ,就是调用一些标准输入输出的函数
C 库函数 void setbuf(FILE *stream, char *buffer) 定义流 stream 应如何缓
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









