







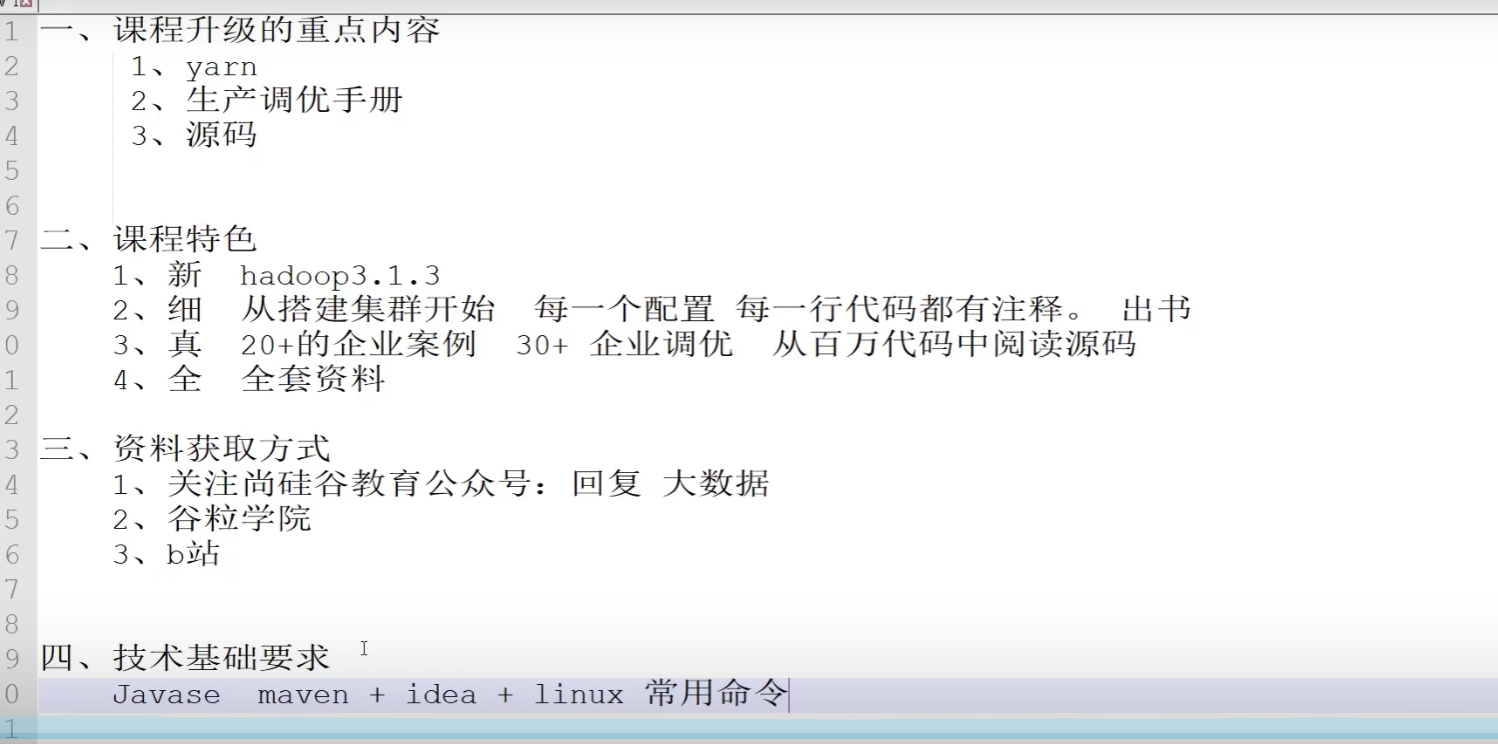
p01 课程整体介绍
p02 大数据的概念
p03大数据的特点




p04 05 大数据应用场景
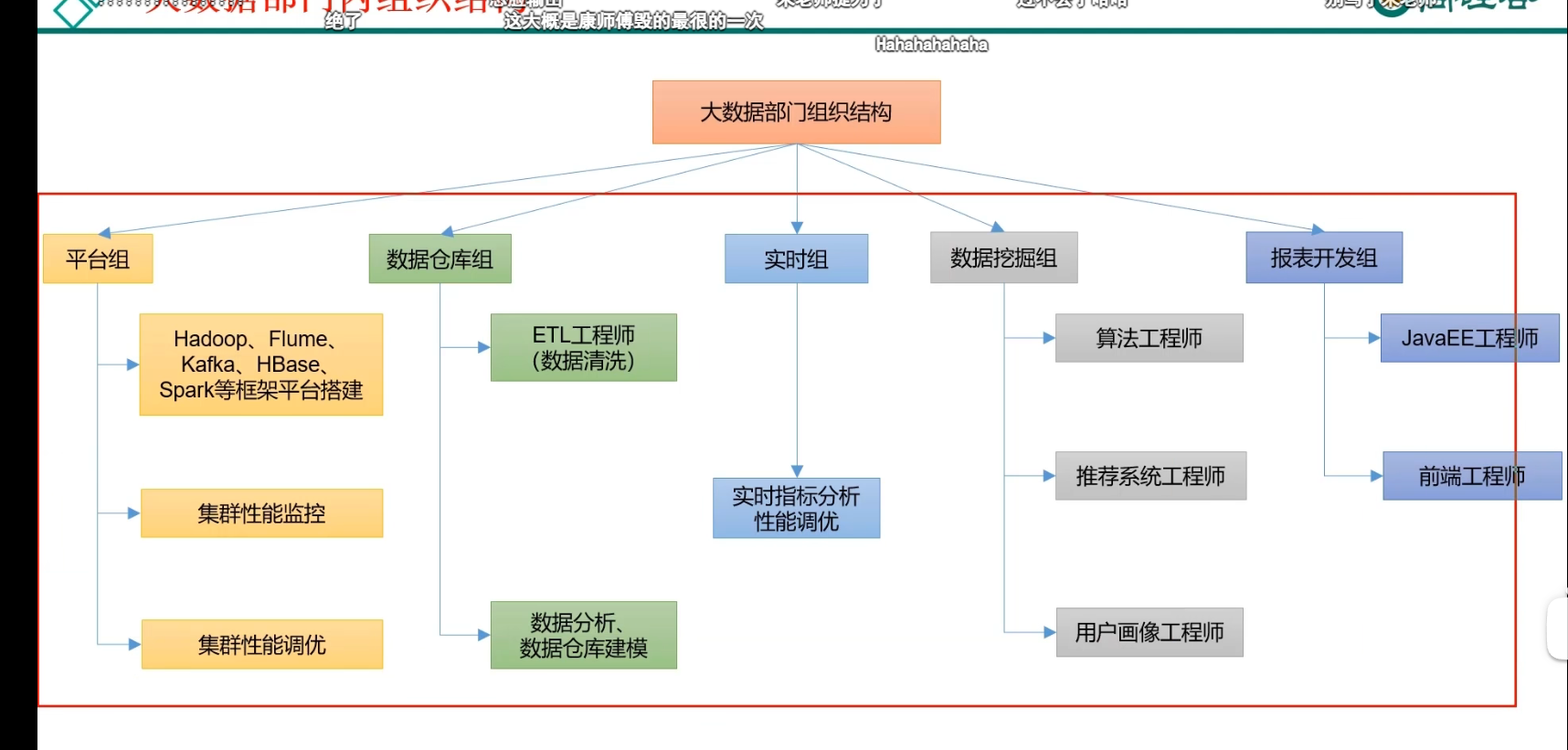
p06 未来工作内容
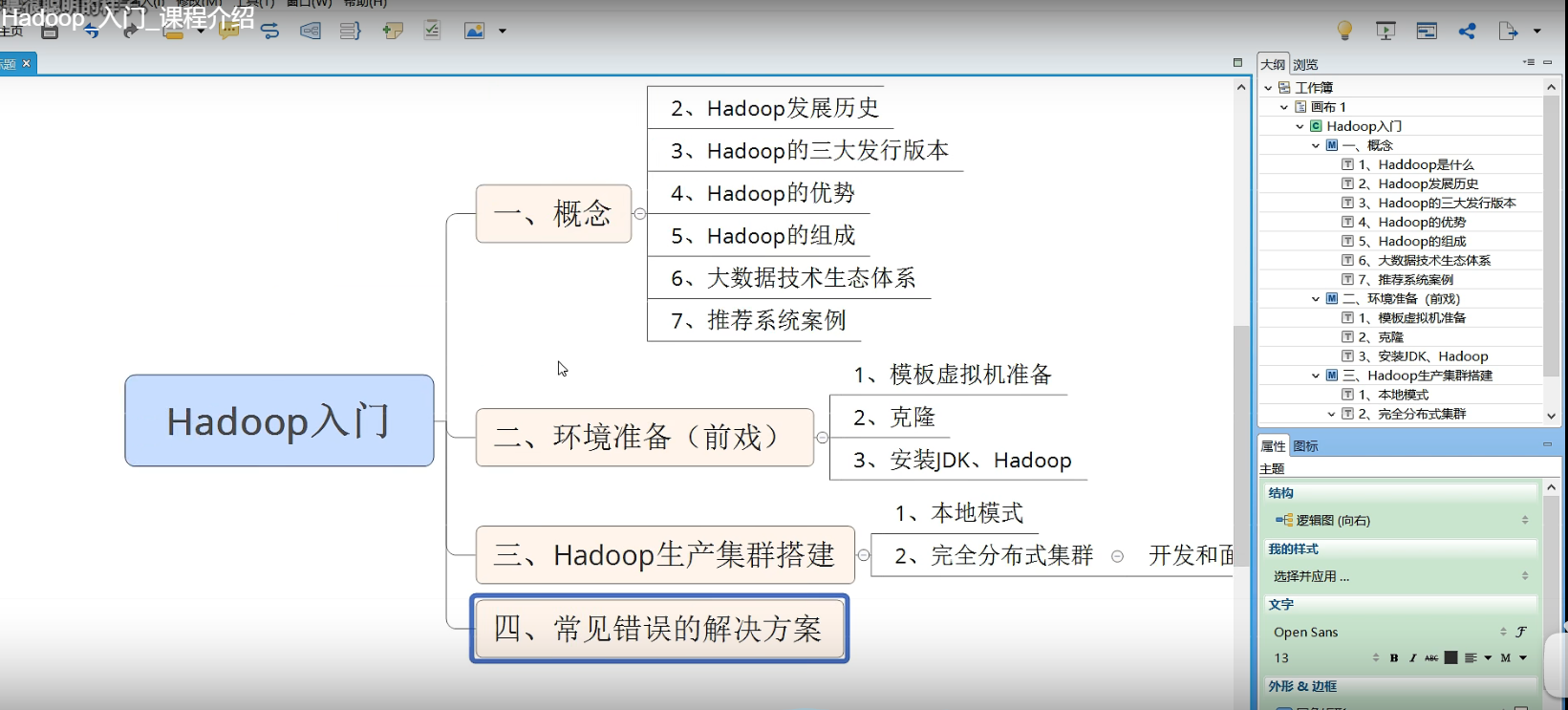
p07hadoop入门 课程介绍
p08 09 hadoop是什么

p 10 hadoop3大发行版本
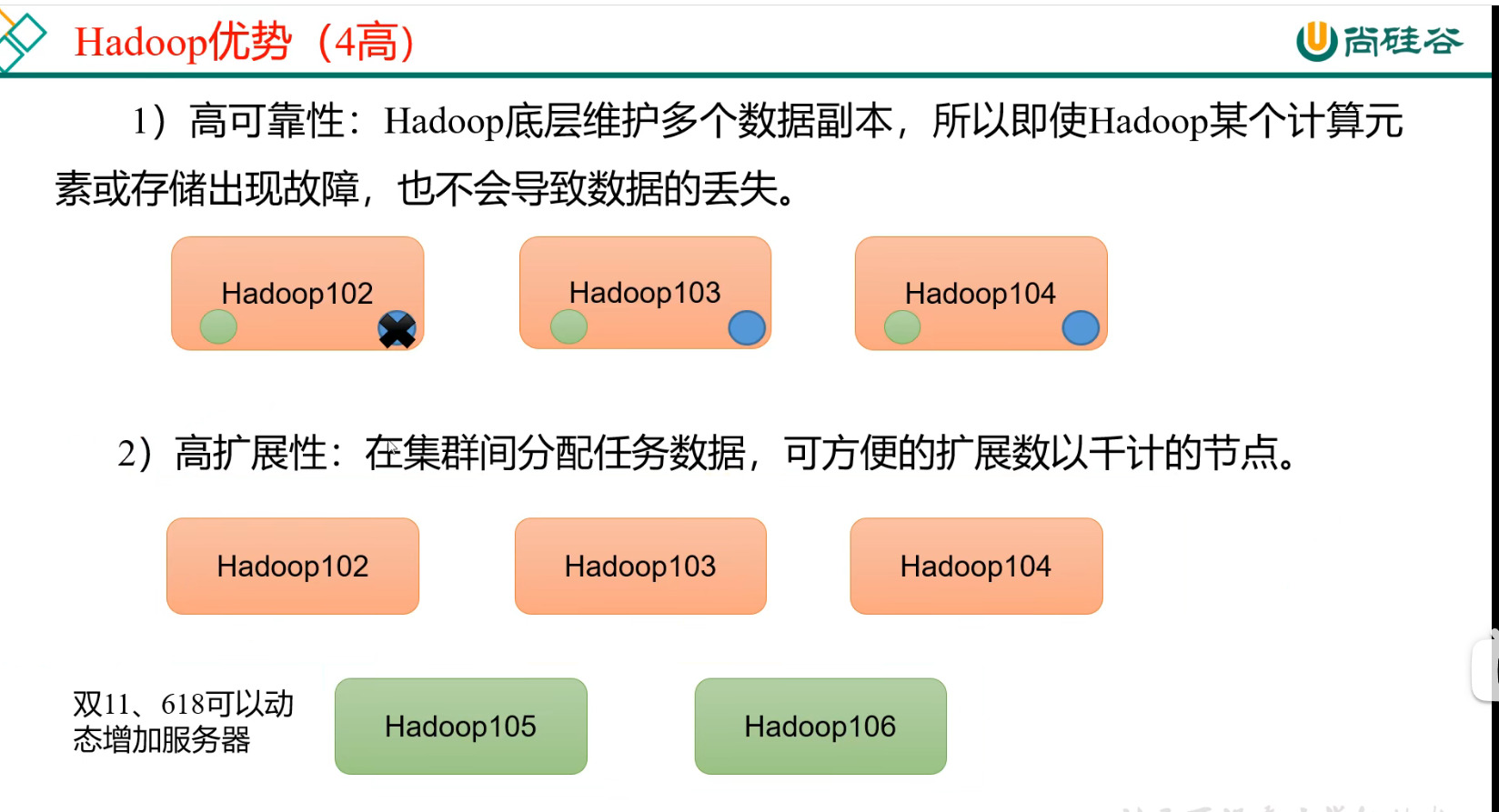
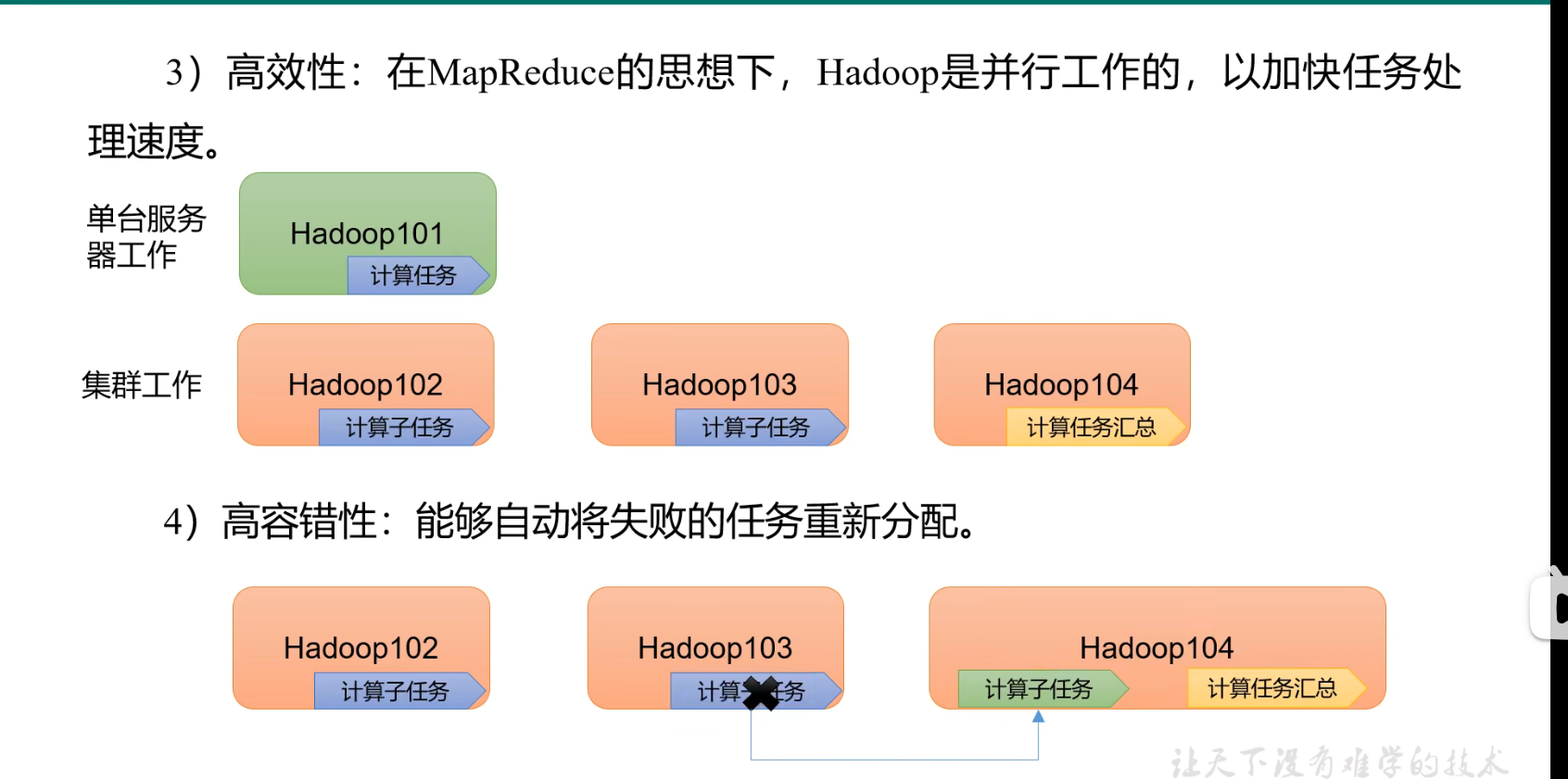
p11 hadoop优势
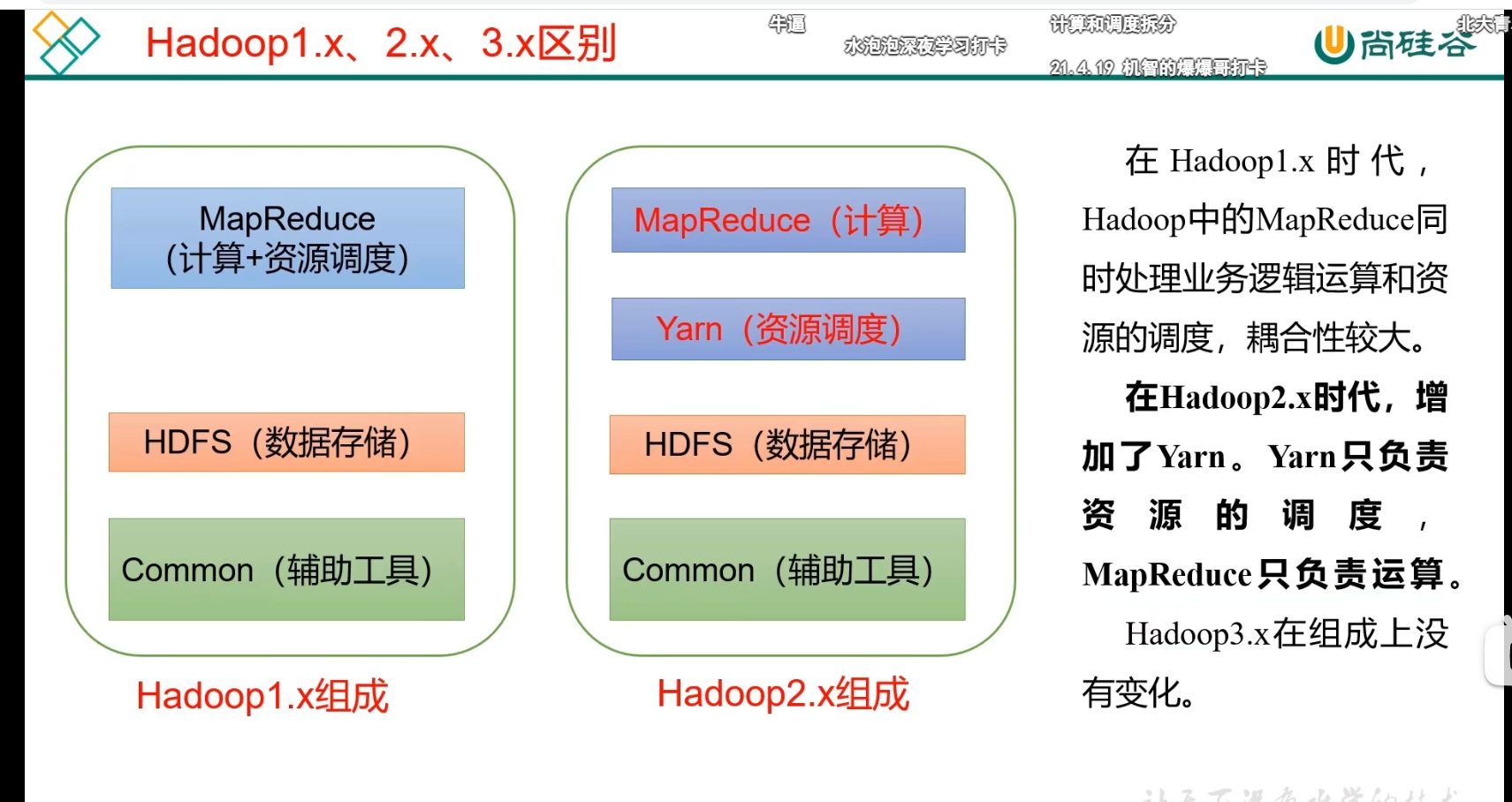
p12 hadoop 1 2 3版本区别
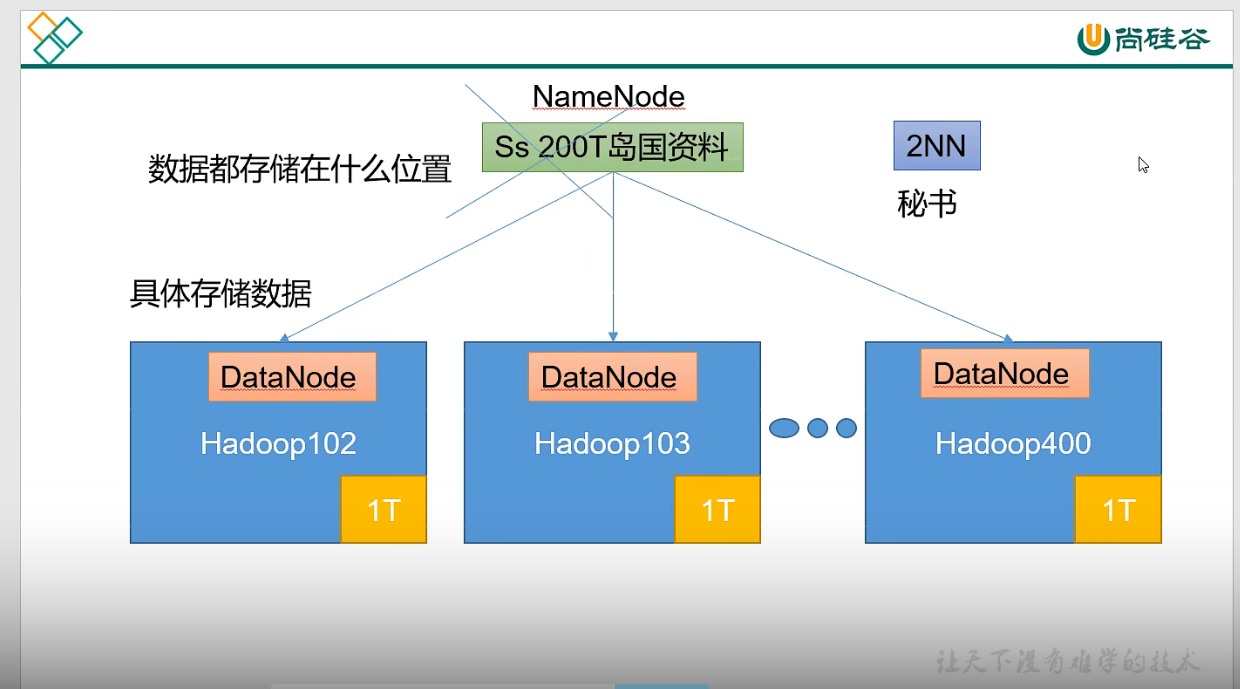
p13 HDFS概述
NameNode DataNode SecondNameNode


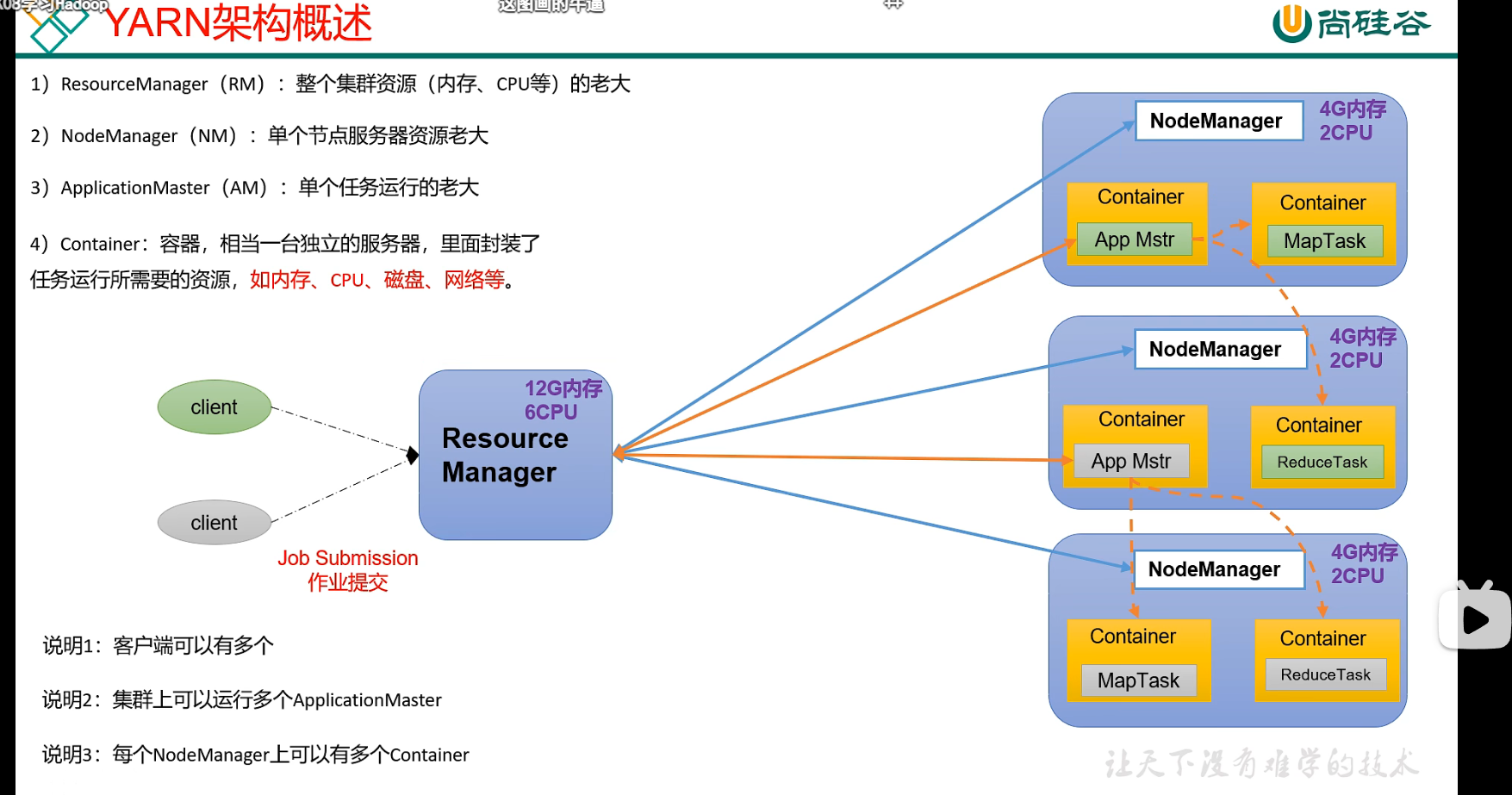
p14 Hadoop入门 YARN概述
ResourceManager NodeManager
p15 MapReduce概述
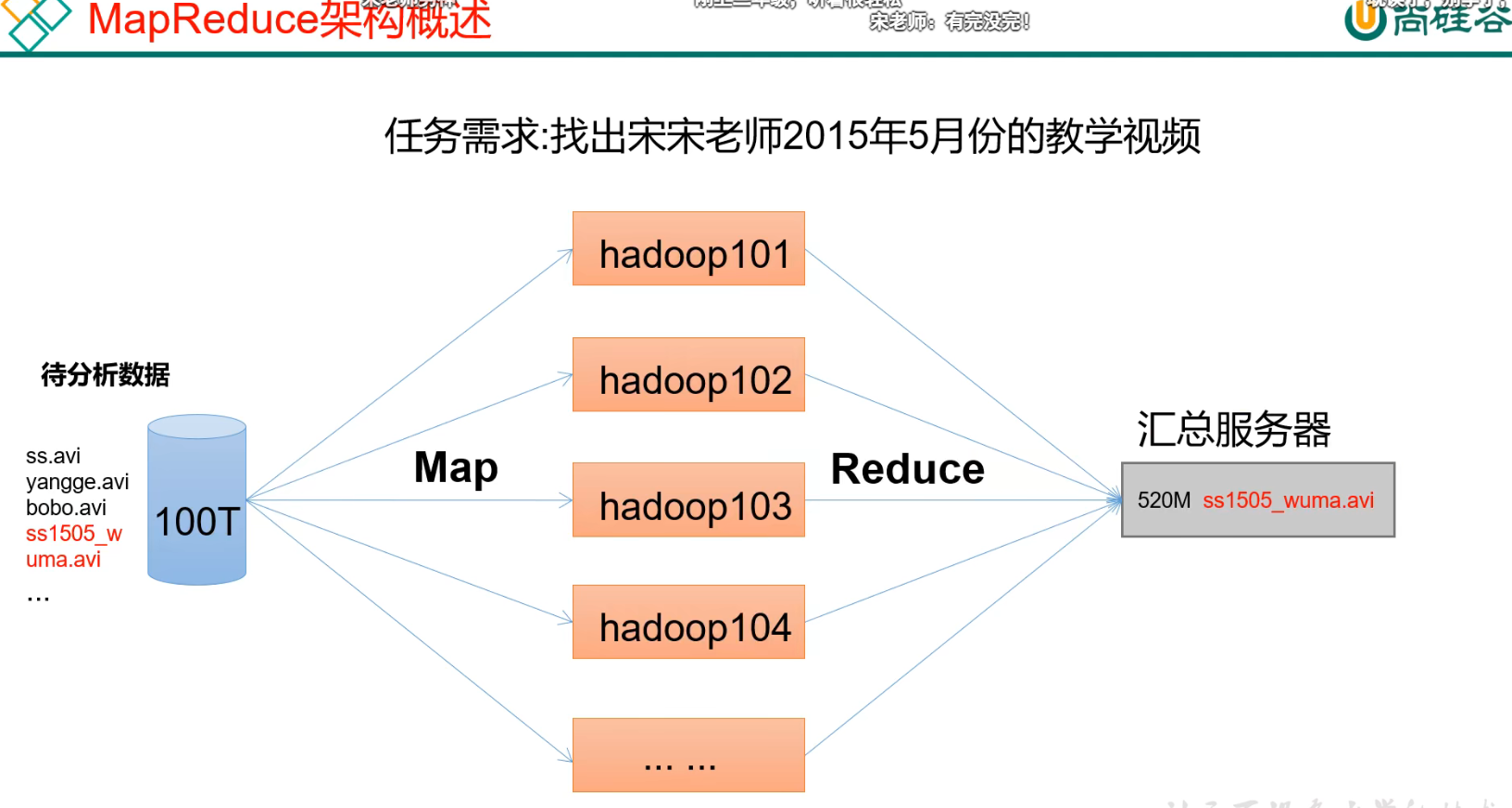
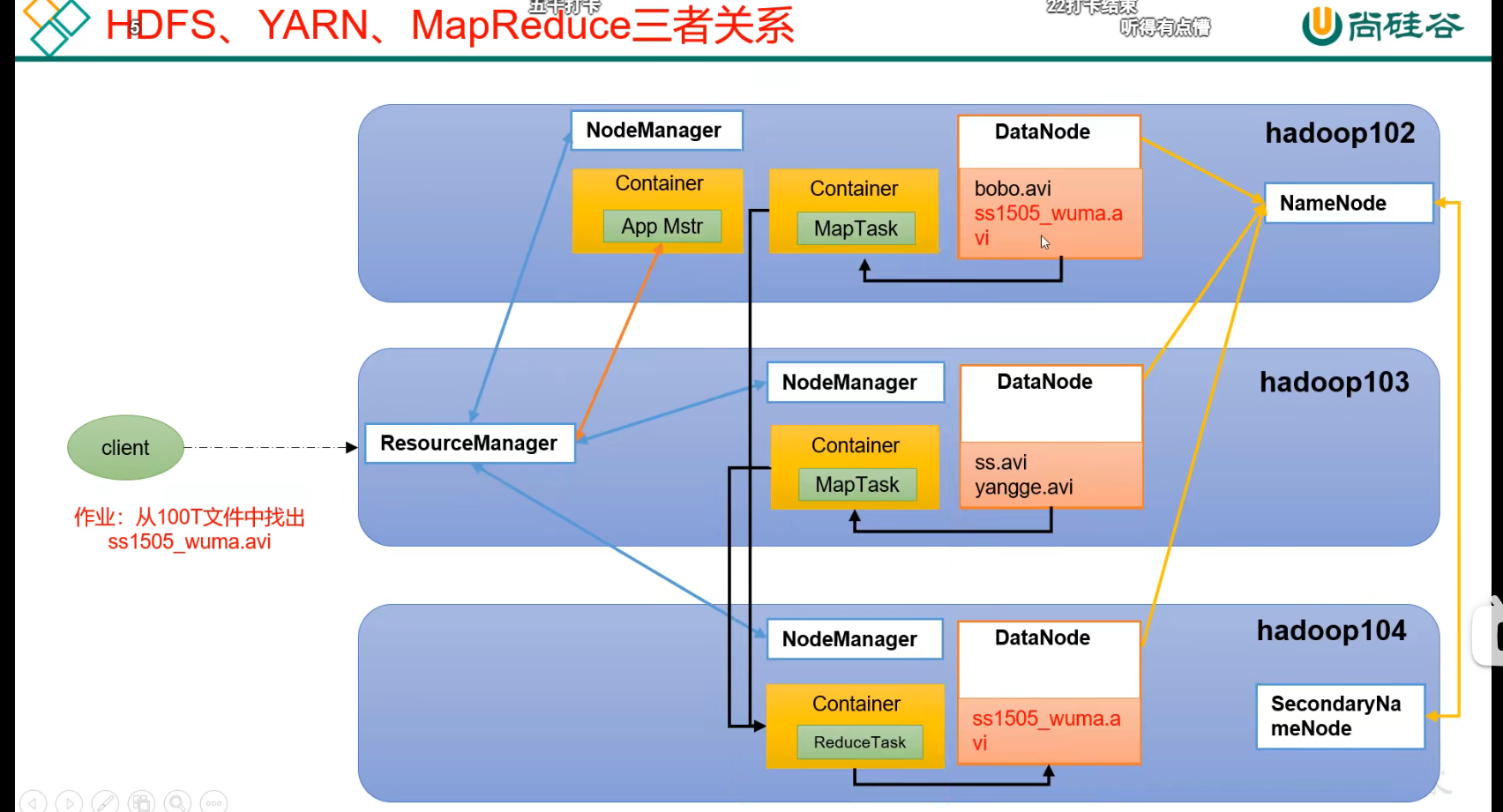
p16 HDFS YARN MapReduce三者关系
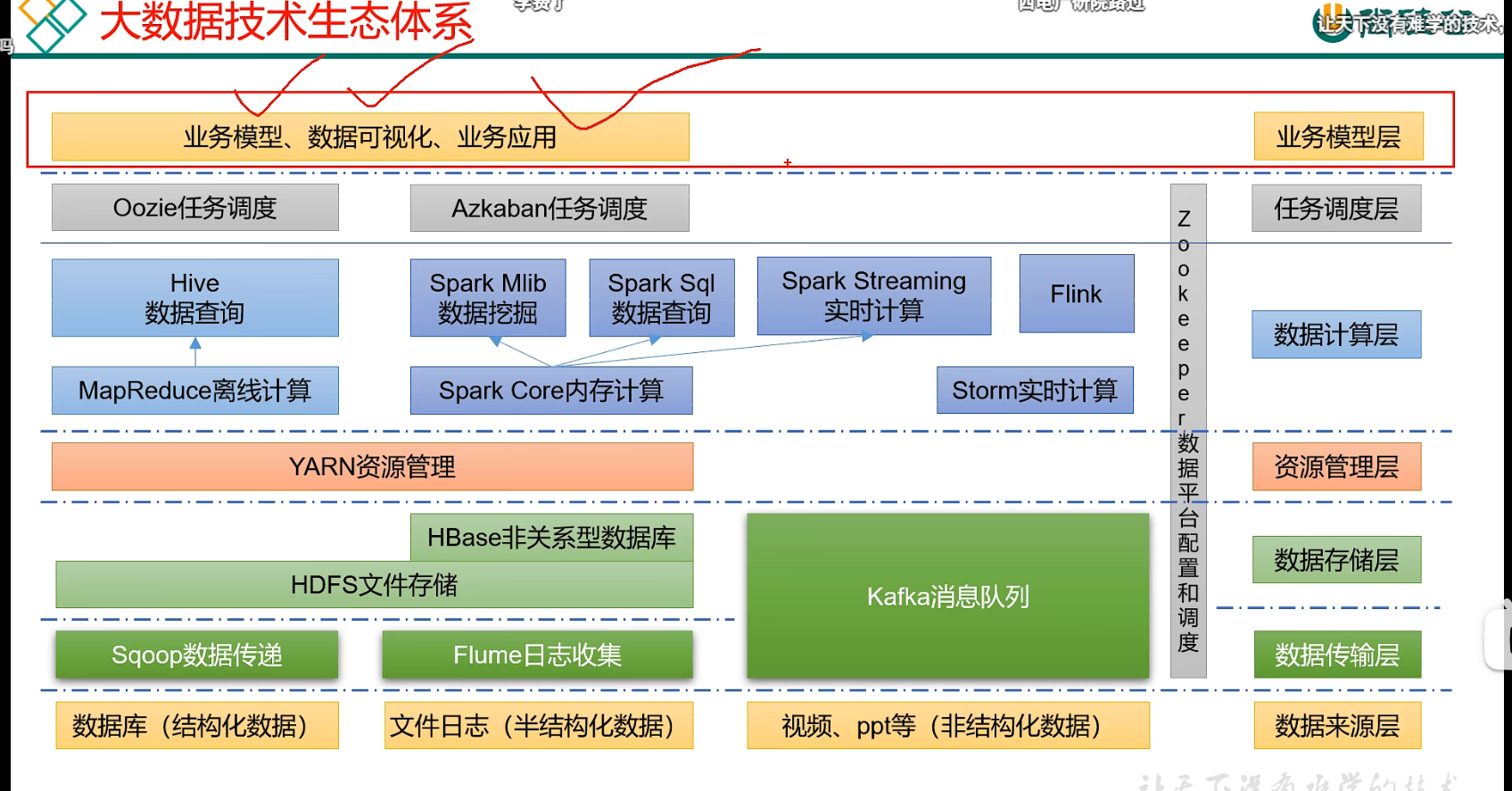
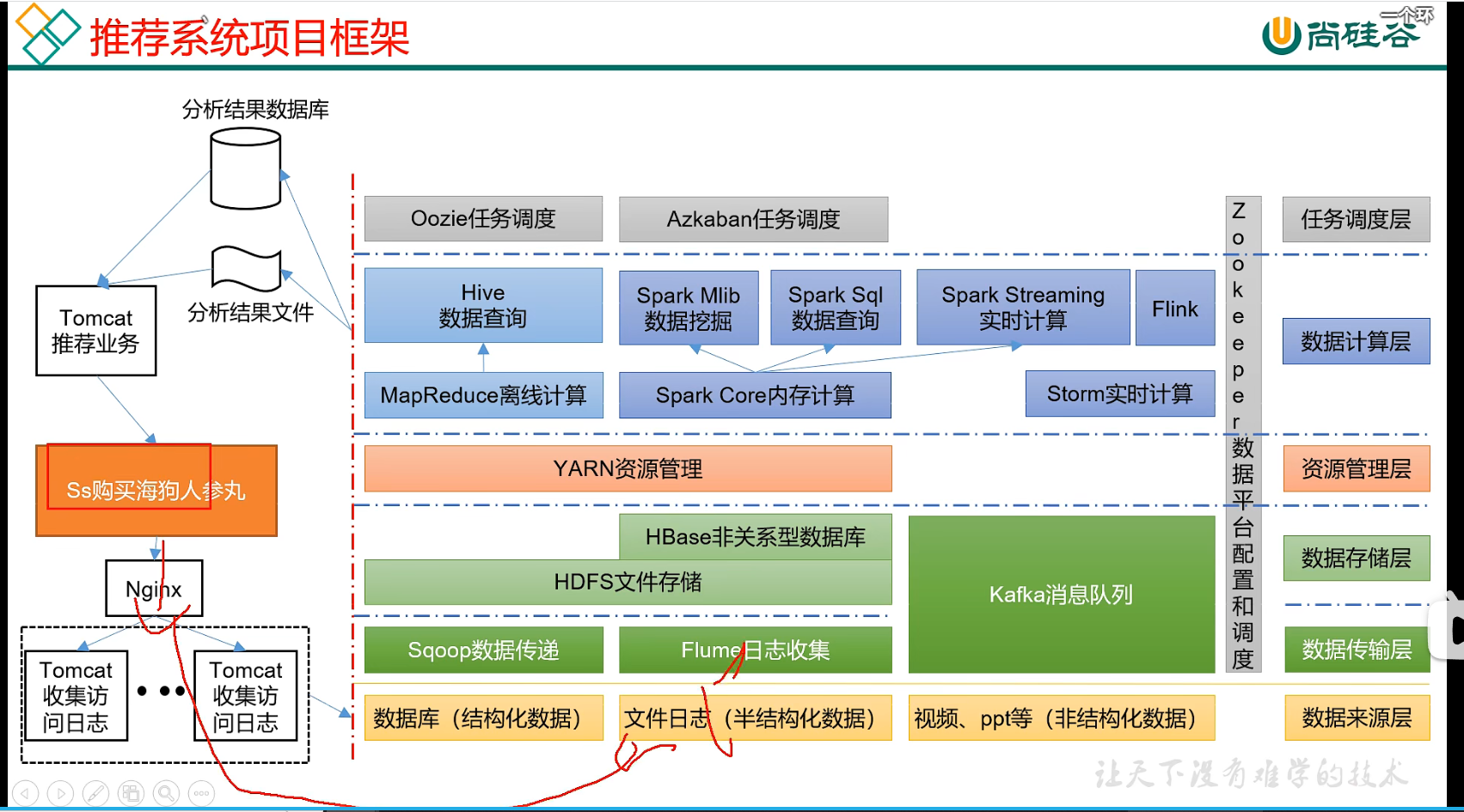
p17 大数据技术生态体系
p18 VMWARE安装
我安装的16 网上找序列码直接用
p19 centos7安装
看到韩老师的linux视频
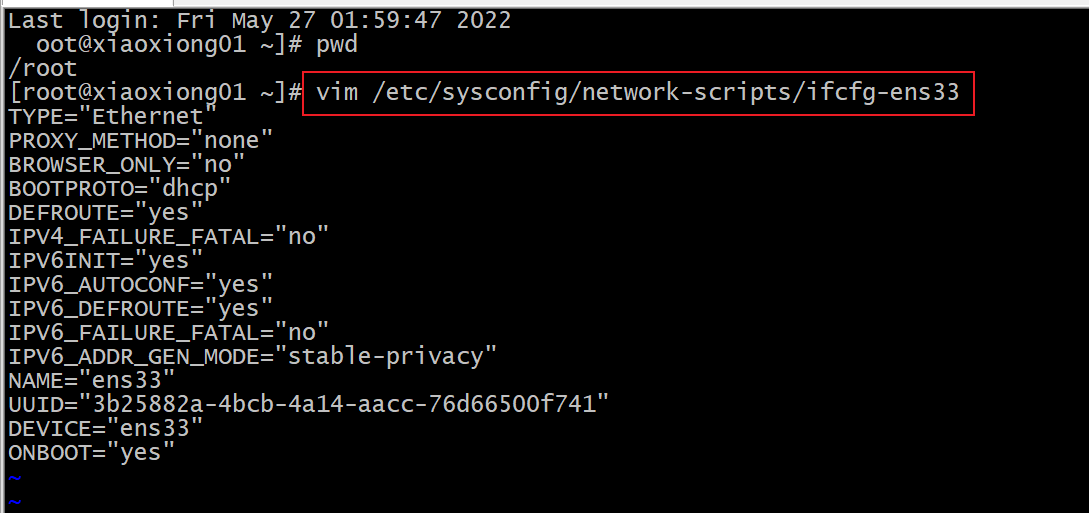
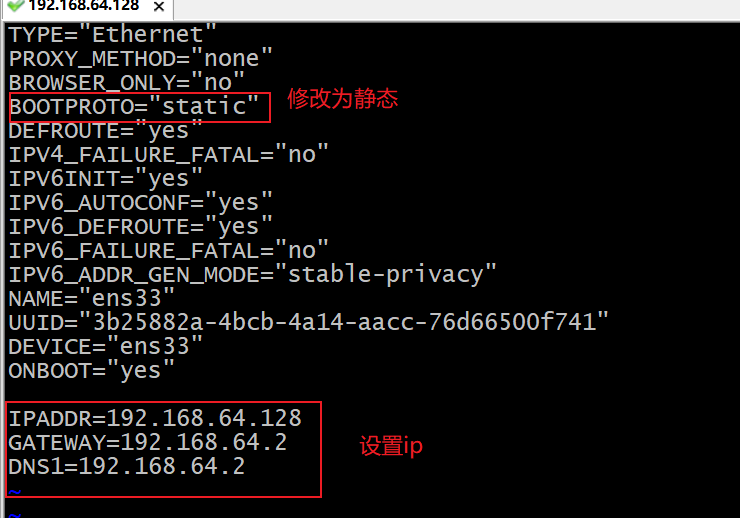
p20 ip和主机名称配置
修改ip
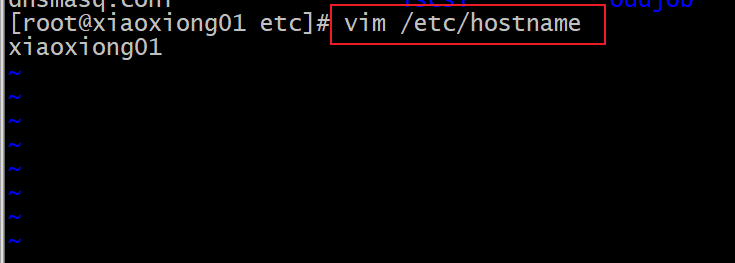
修改主机名称
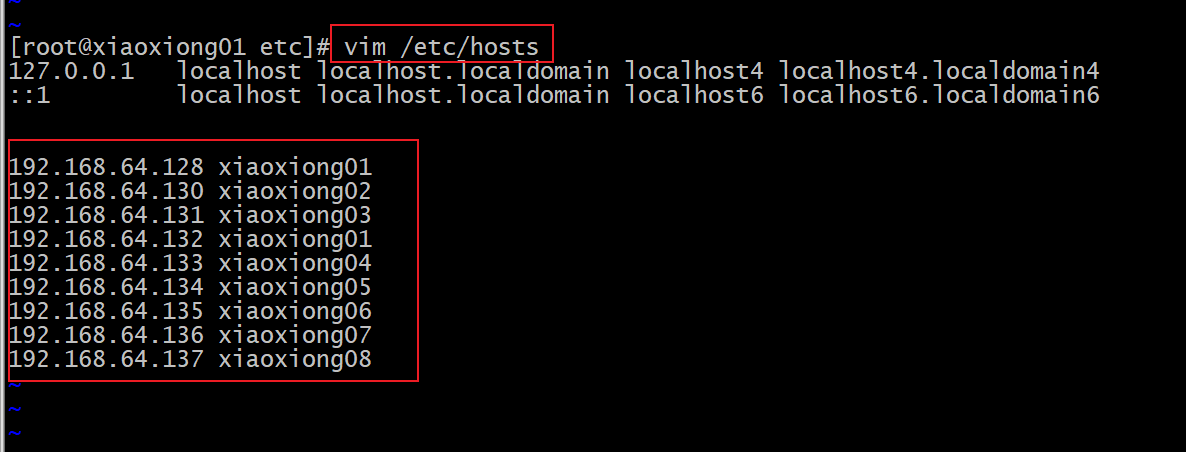
修改主机名和host映射
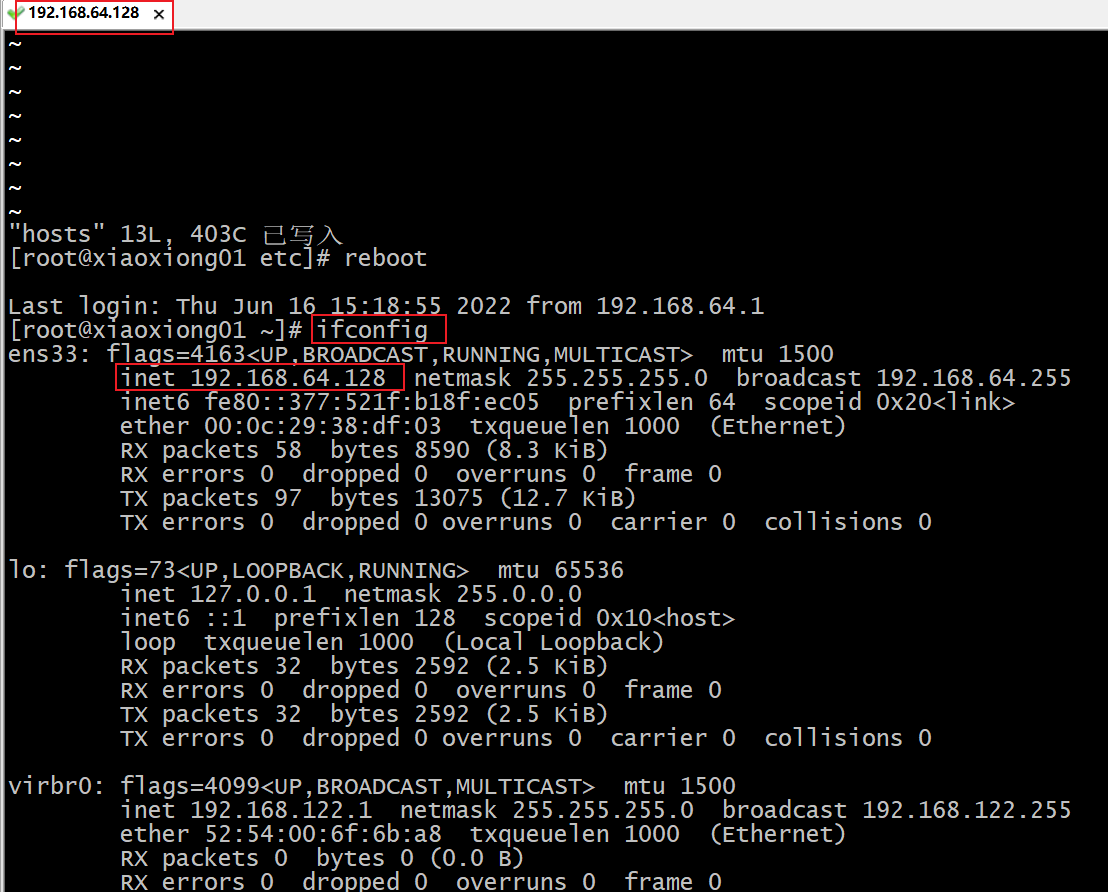
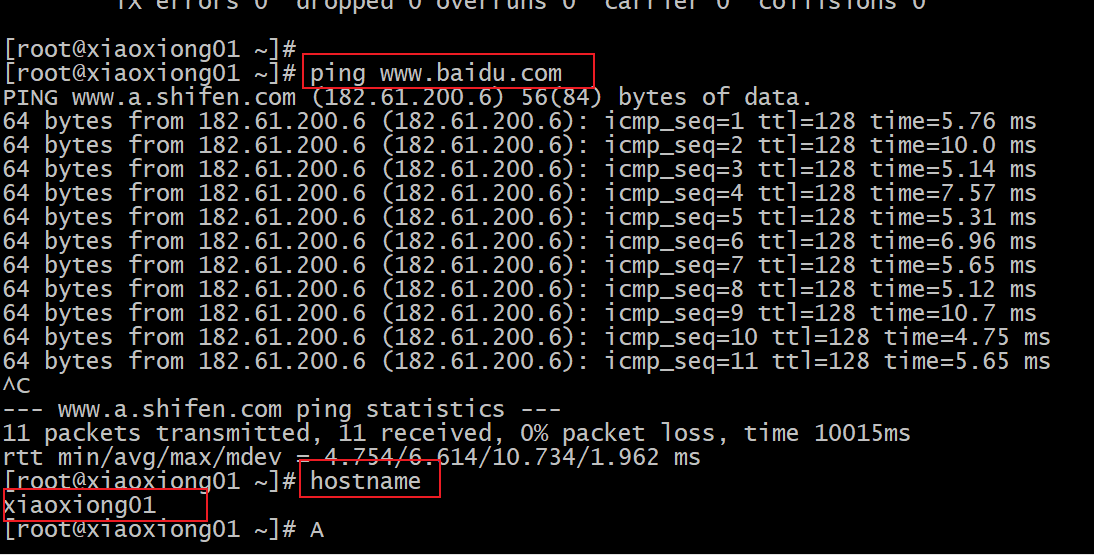
p21 xshell远程访问
我用的crt
p22 模版虚拟机准备完成
安装epel-release
Extra Packages for Enterprise Linux是为“红帽系”的操作系统提供额外的软件包,适用于 RHEL、CentOS和Scientific Linux。相当于是一个软件仓库,大多数 rpm 包在官方 repository 中是找不到的。
yum install -y epel-release
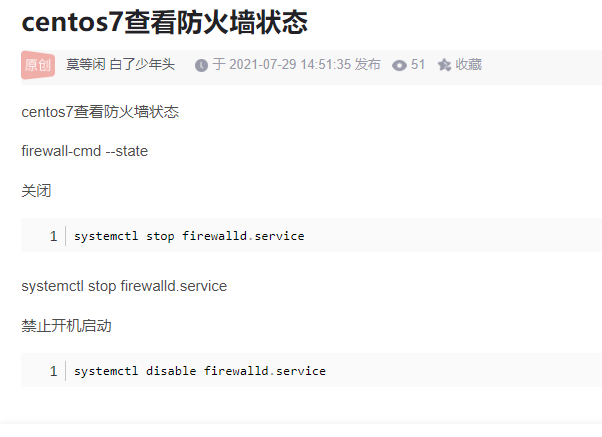
关闭防火墙
创建用户

配置用户权限

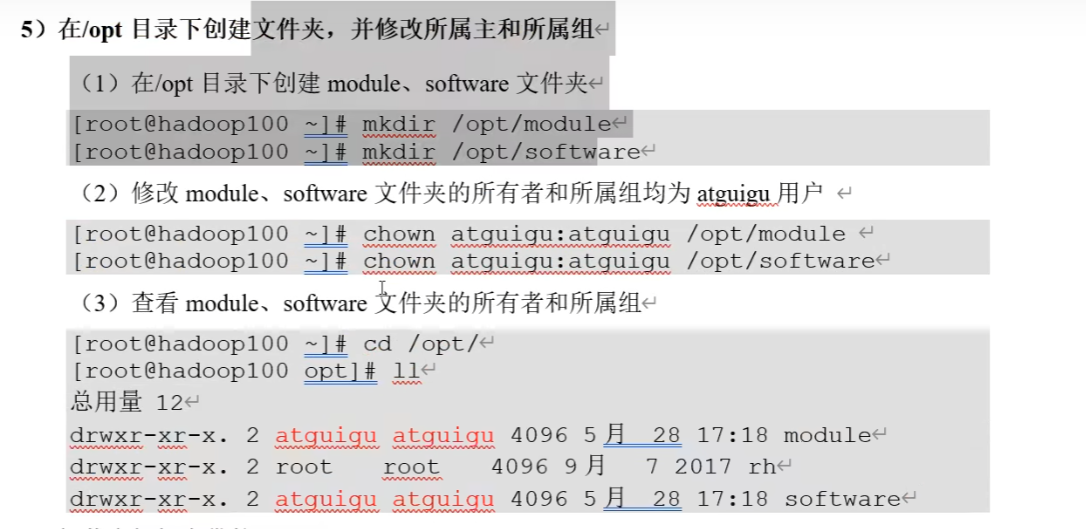
在opt目录下创建文件夹,改变文件所有者
卸载自带的JDK
检查系统中自带的JDK:
rpm -qa | grep -i java
卸载自带的JDK:(需要以root用户运行)
# grep -i 忽略大小写
# xargs 将前面的输出结果作为命令的参数
# -n1 每次只取一个结果作为命令参数。如果不加,则会将所有结果以空格分隔拼接作为命令的参数
# rpm -e --nodeps:不验证套件档的相互关联性进行卸载
rpm -qa | grep -i java | grep -v ".noarch" | xargs -n1 rpm -e --nodeps
p23 克隆3台虚拟机

克隆完成之后,还需要依次修改 hadoop102、hadoop103、hadoop104的ip和hostname。
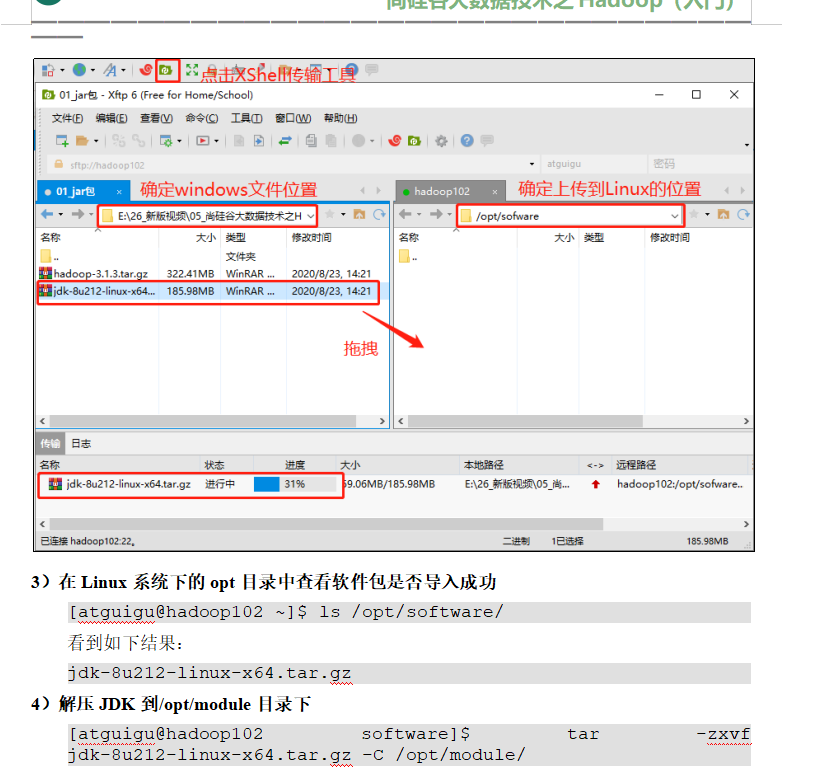
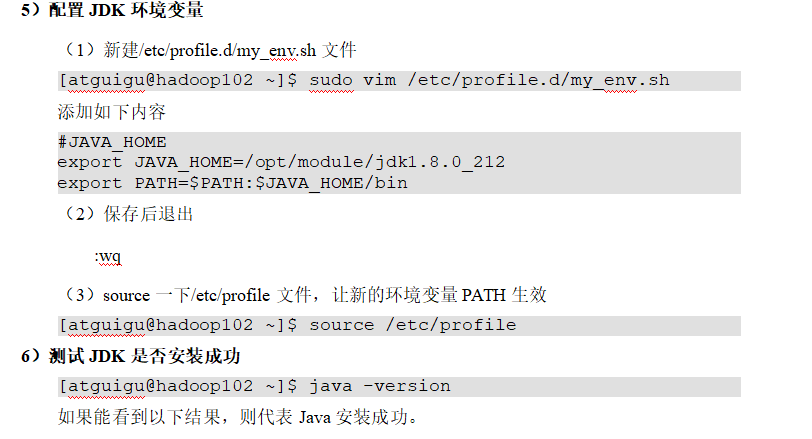
p24 jdk安装
在02上安装jdk和hadoop 剩下2台复制就行了


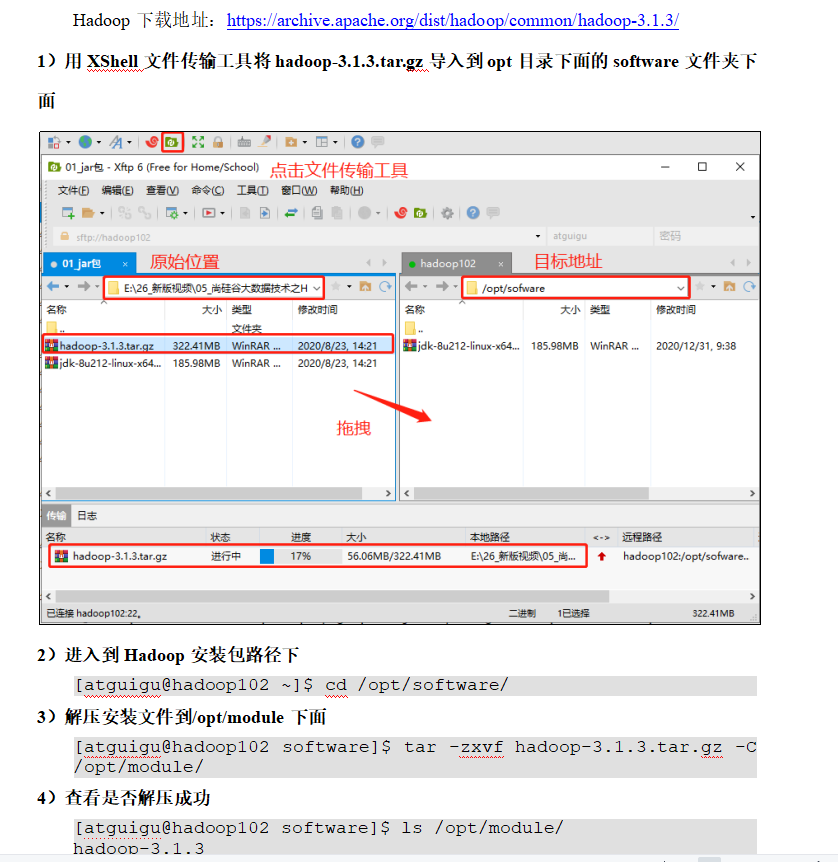
p25 hadoop安装


hadoop目录结构

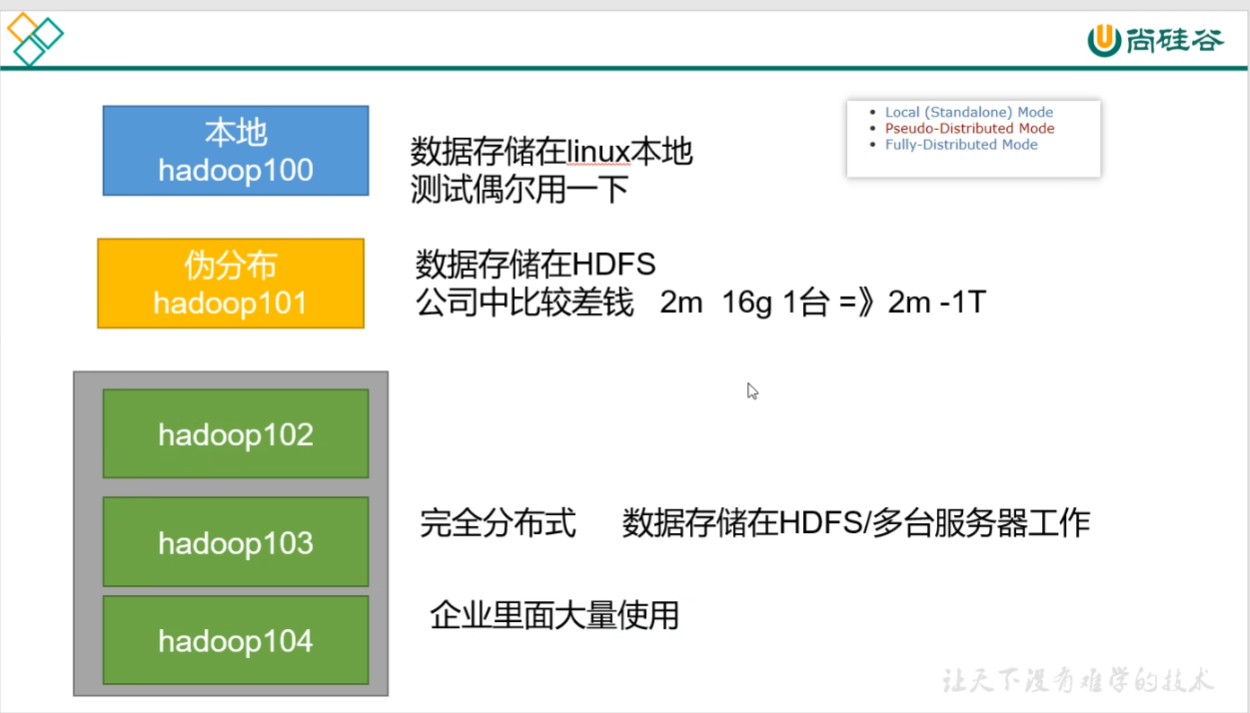
p26 hadoop入门 本地运行模式

p27 scp&rsync命令
集群模式 把在hadoop1机器上安装的东西同步到hadoop2 和hadoop3上
scp(secure copy)安全拷贝
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
scp -r $pdir/$fname $user@$host:$pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
前提:在hadoop102、hadoop103、hadoop104都已经创建好的/opt/module、
sudo chown atguigu:atguigu -R /opt/module
在hadoop102上,将hadoop102中/opt/module/jdk1.8.0_212目录拷贝到hadoop103上。
scp -r /opt/module/jdk1.8.0_212 atguigu@hadoop103:/opt/module
或者 hadoop103上,将hadoop102中/opt/module/hadoop-3.1.3目录拷贝到hadoop103上。
scp -r atguigu@hadoop102:/opt/module/hadoop-3.1.3 /opt/module/
或者在hadoop103上操作,将hadoop102中/opt/module目录下所有目录拷贝到hadoop104上。
scp -r atguigu@hadoop102:/opt/module/* atguigu@hadoop104:/opt/module
rsync远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
rsync -av $pdir/$fname $user@$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
选项参数说明
选项 功能
-a 归档拷贝
-v 显示复制过程
rsync -av hadoop-3.1.3/ atguigu@hadoop103:/opt/module/hadoop-3.1.3/
p28 xsync集群分发脚本
自定义xsync集群分发脚本
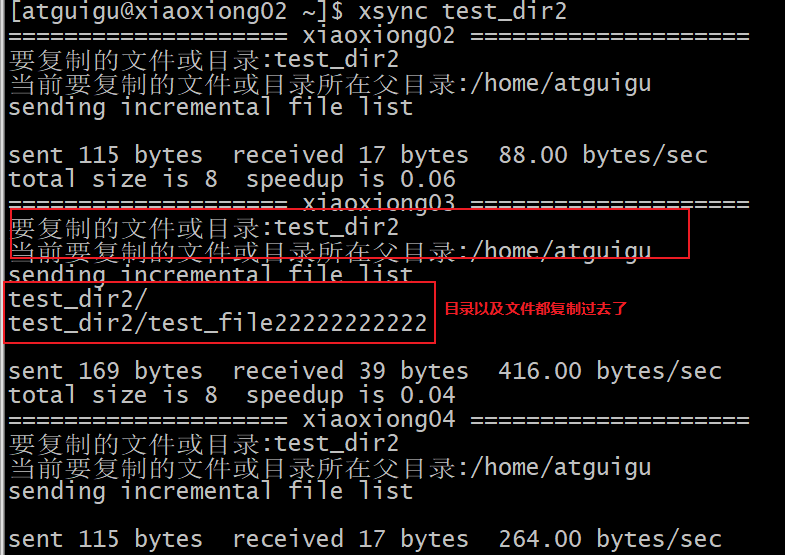
需求:循环复制文件到所有节点的相同目录下
rsync命令原始拷贝:
rsync -av /opt/module atguigu@hadoop103:/opt/
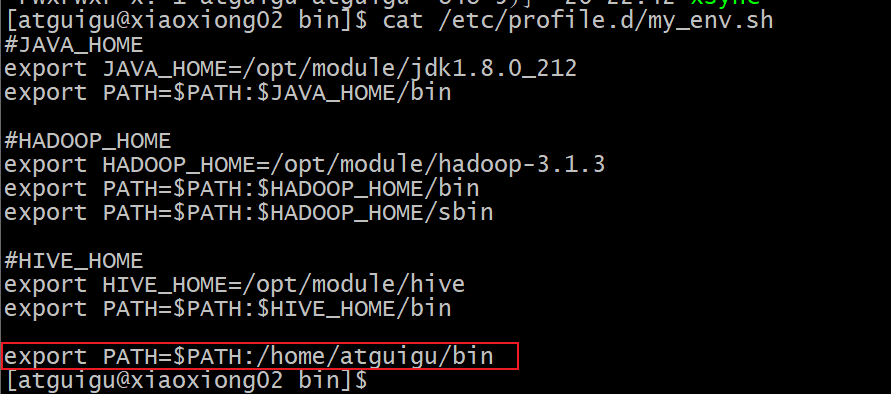
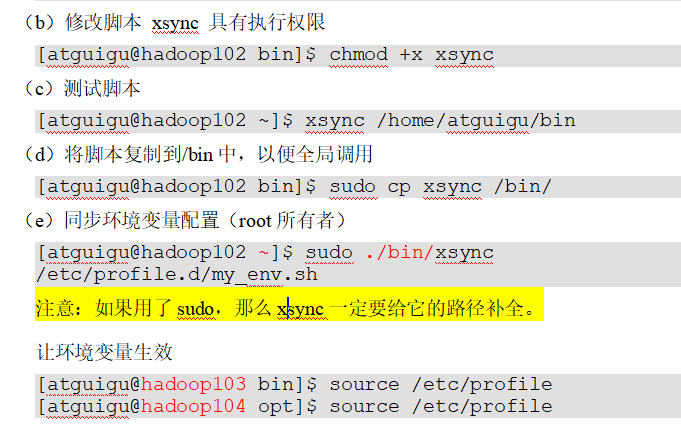
在/home/atguigu/bin目录下创建xsync文件,如果想直接执行命令,配置好PATH路径
追加path

#!/bin/bash
#1. 判断参数个数 $#代表参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in xiaoxiong02 xiaoxiong03 xiaoxiong04
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送. '$@' 代表所有参数
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
echo 要复制的文件或目录:$file;
#5. 获取父目录 这里-P的意思是防止是当前目录是软连接,进入真实目录
pdir=$(cd -P $(dirname $file); pwd)
echo 当前要复制的文件或目录所在父目录:$pdir
#6. 获取当前文件的名称,防止当前文件名是绝对路径
fname=$(basename $file)
# 在要复制到的目标机器上创建好目录,-p的意思是防止目标机器上已经存在该目录而报错,如果已存在不会再建立
ssh $host "mkdir -p $pdir"
# 复制当前 要复制的文件或目录 到 目标机器的父目录
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
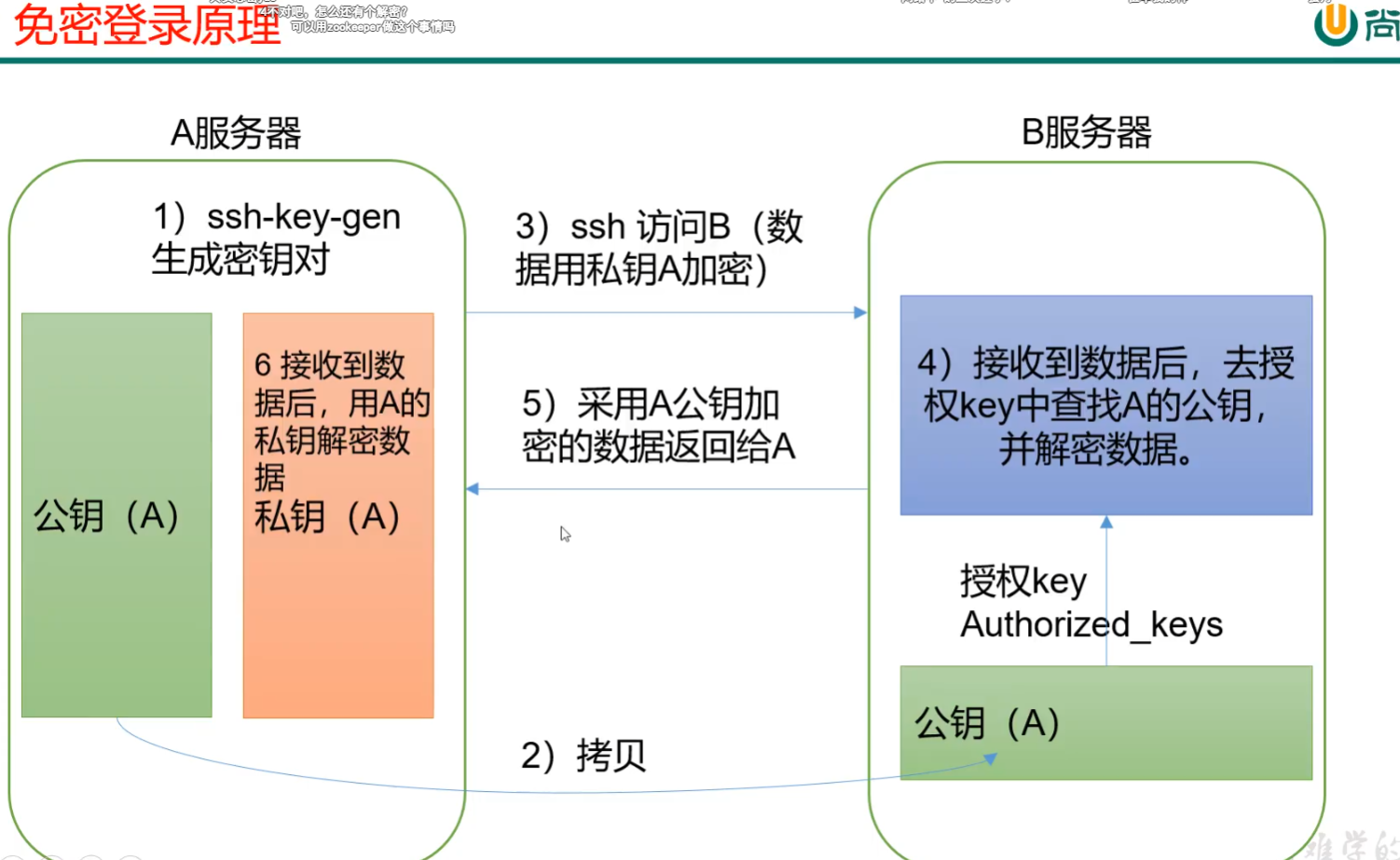
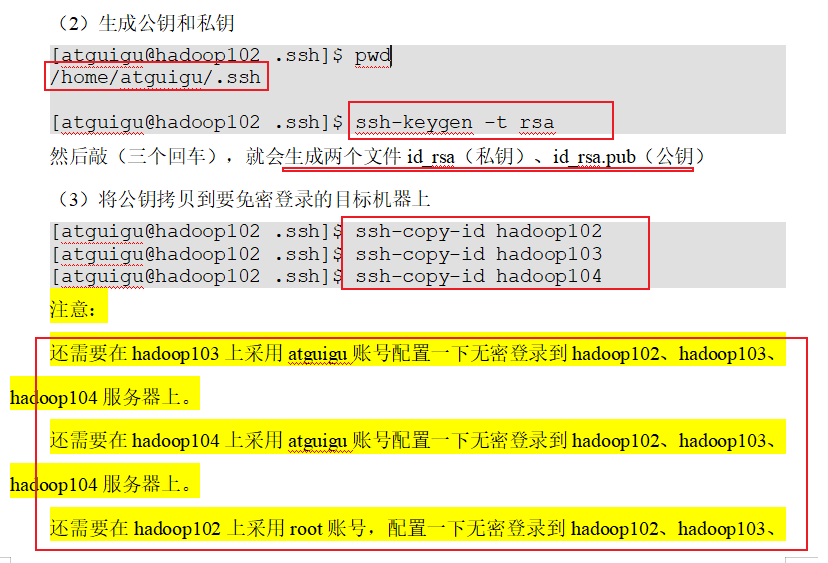
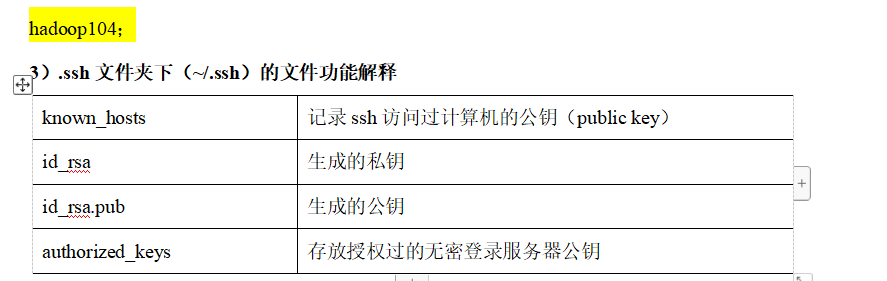
p29 ssh免密登陆
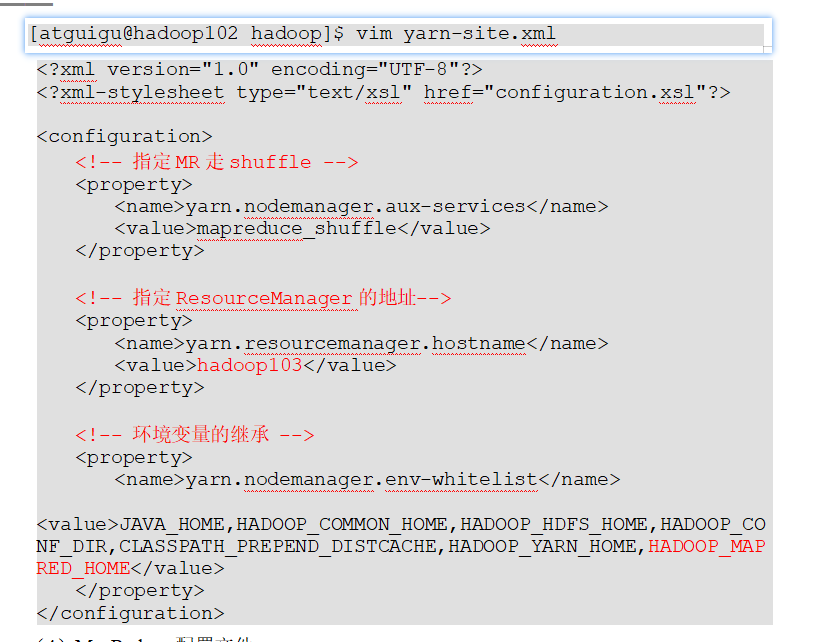
p30 集群配置




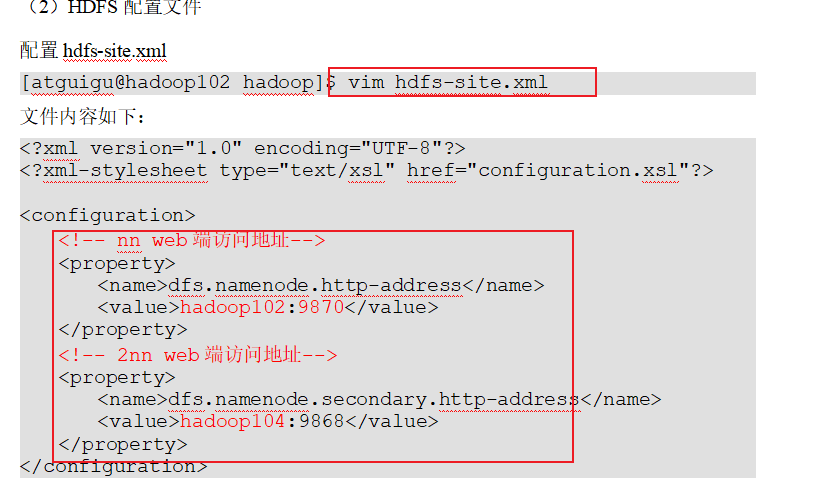


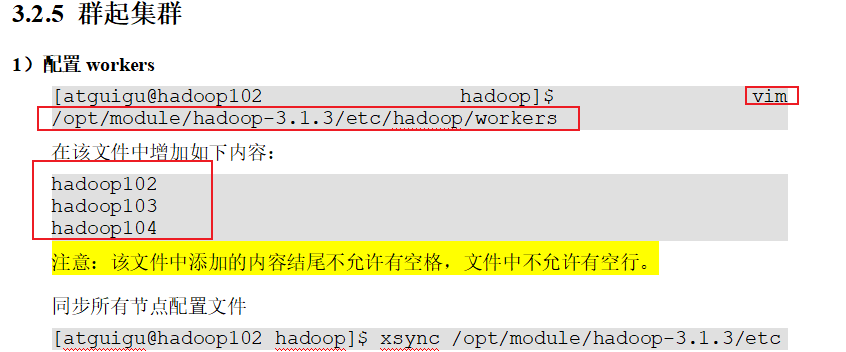
p31群起集群并测试

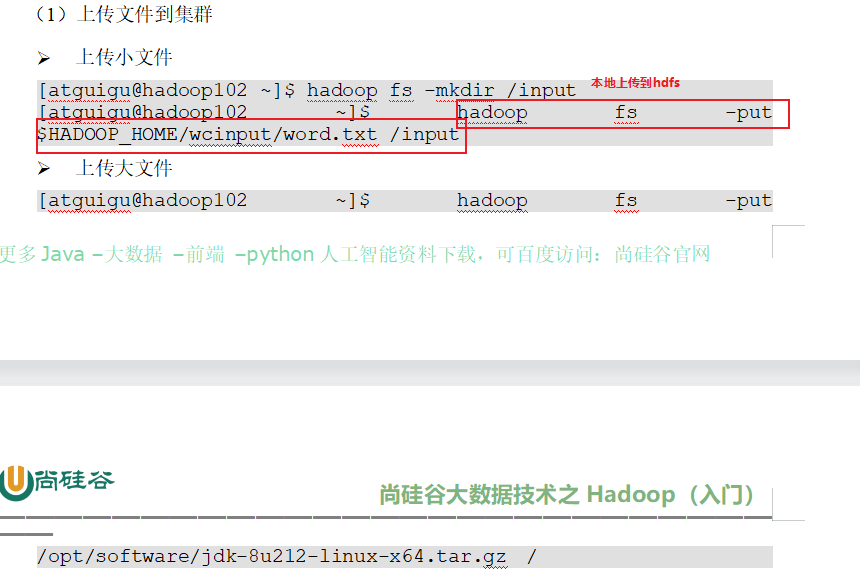
上传文件到hdfs
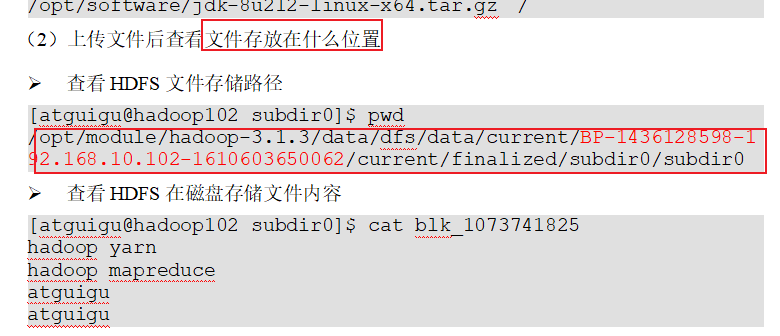
从hdfs下载到本地

执行wordcount程序,注意 后面两个路径是hdfs的文件路径

P32集群崩溃处理办法

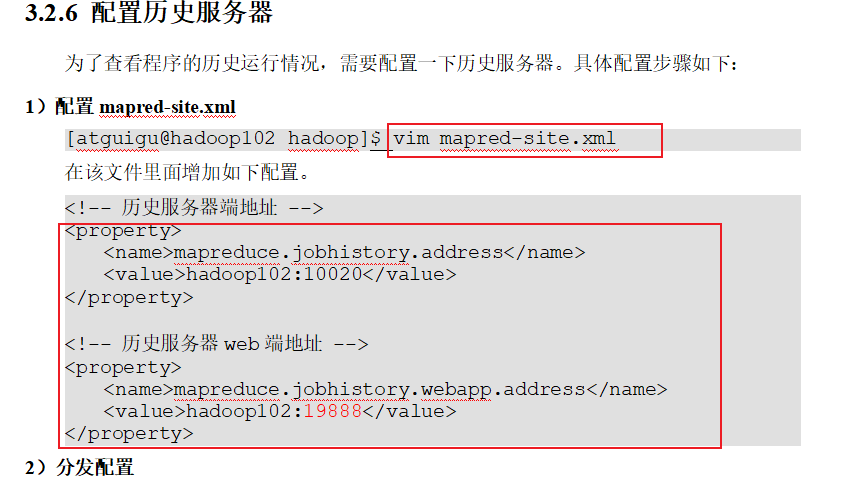
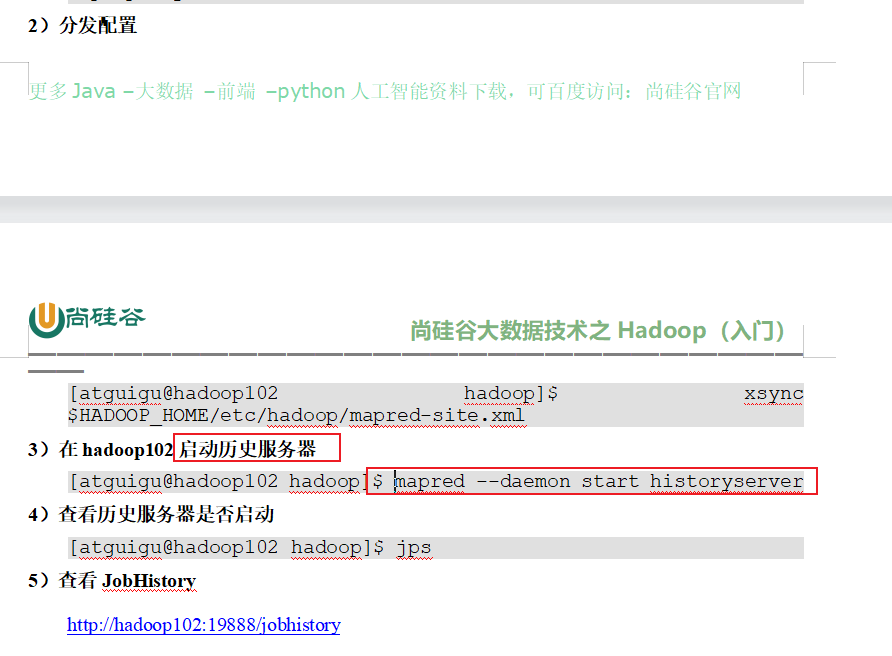
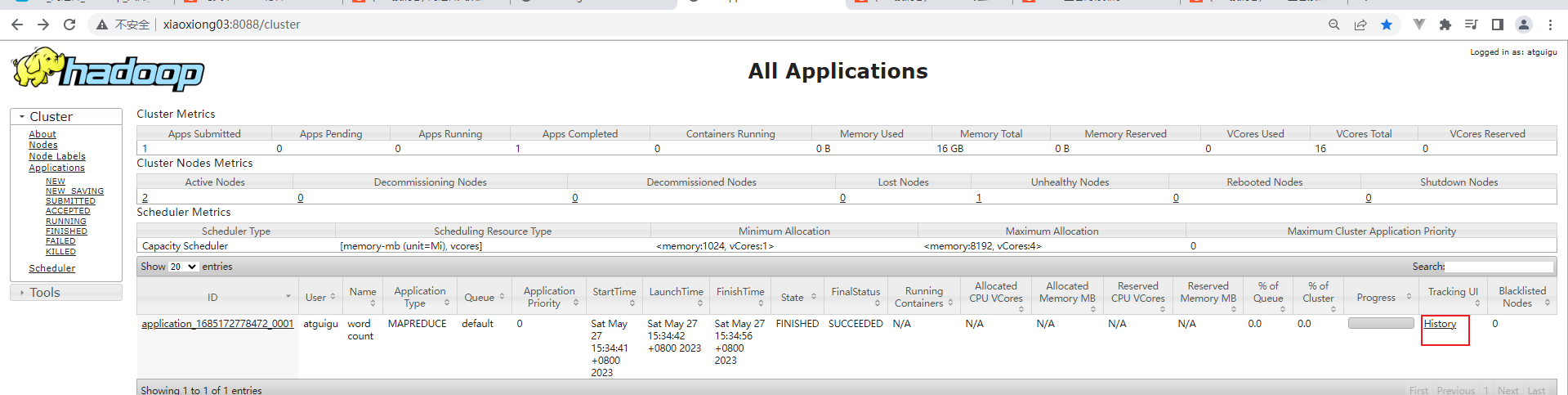
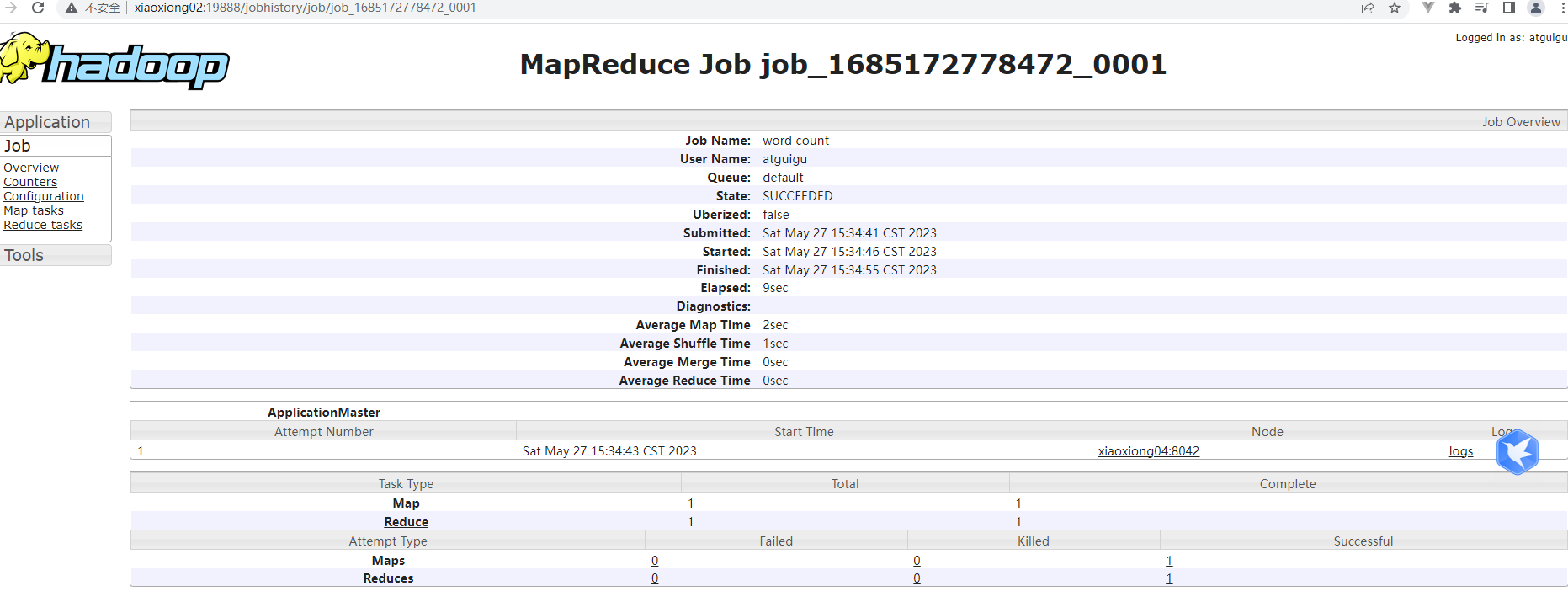
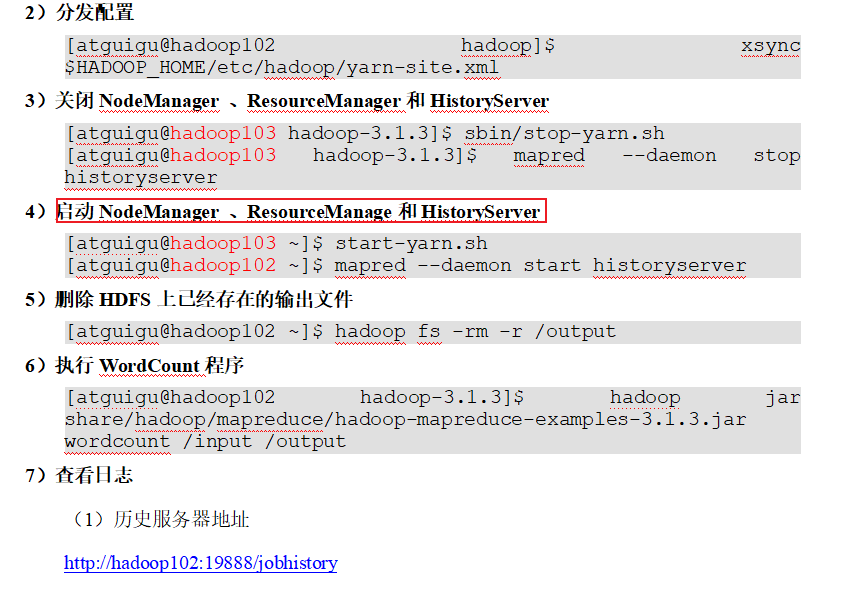
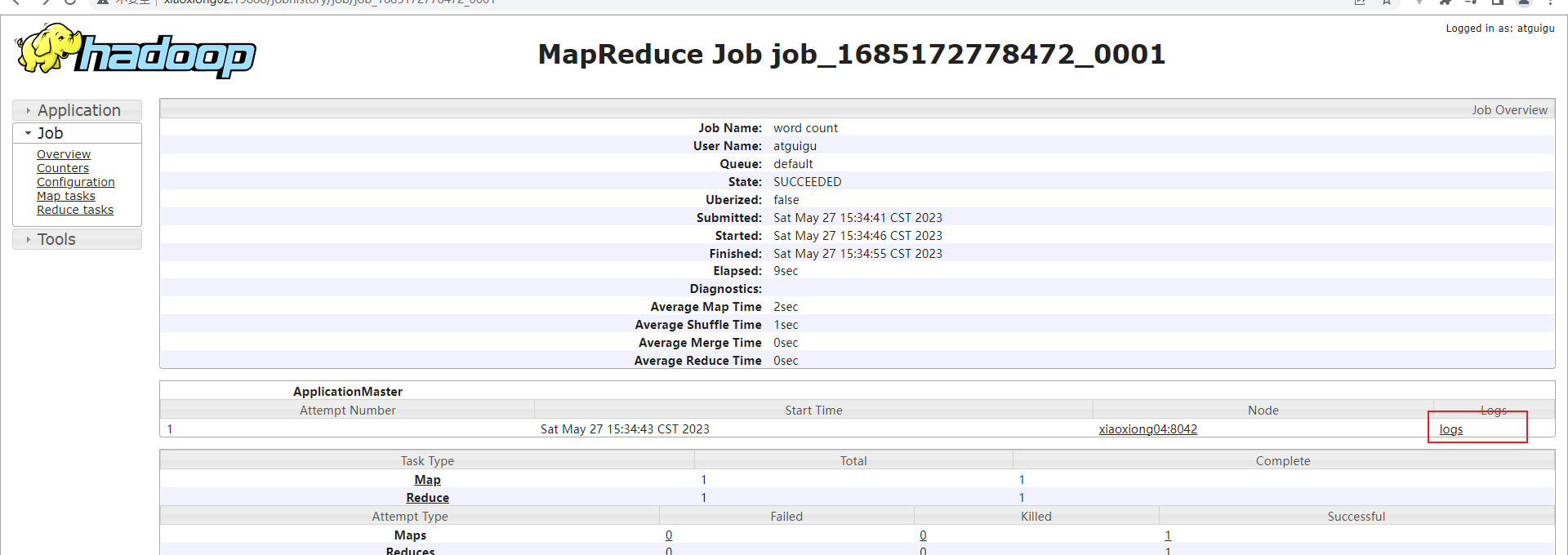
p33 历史服务器配置
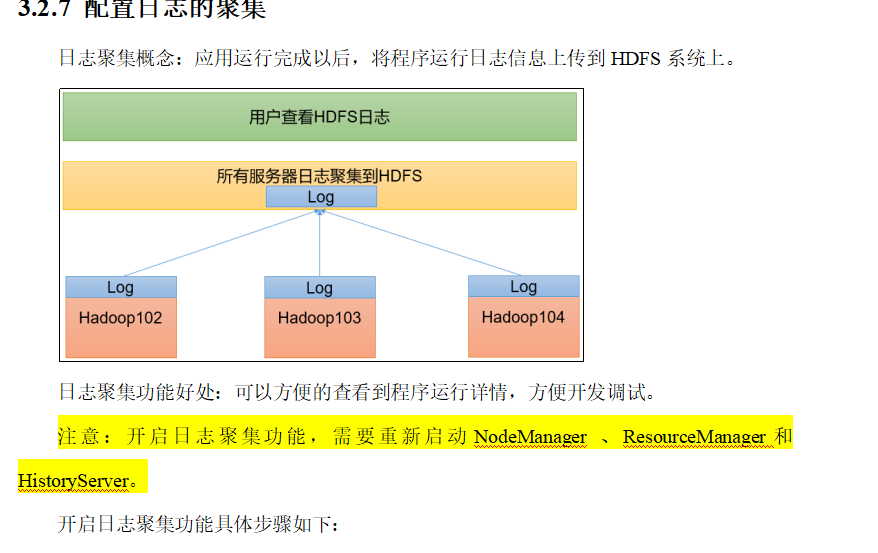
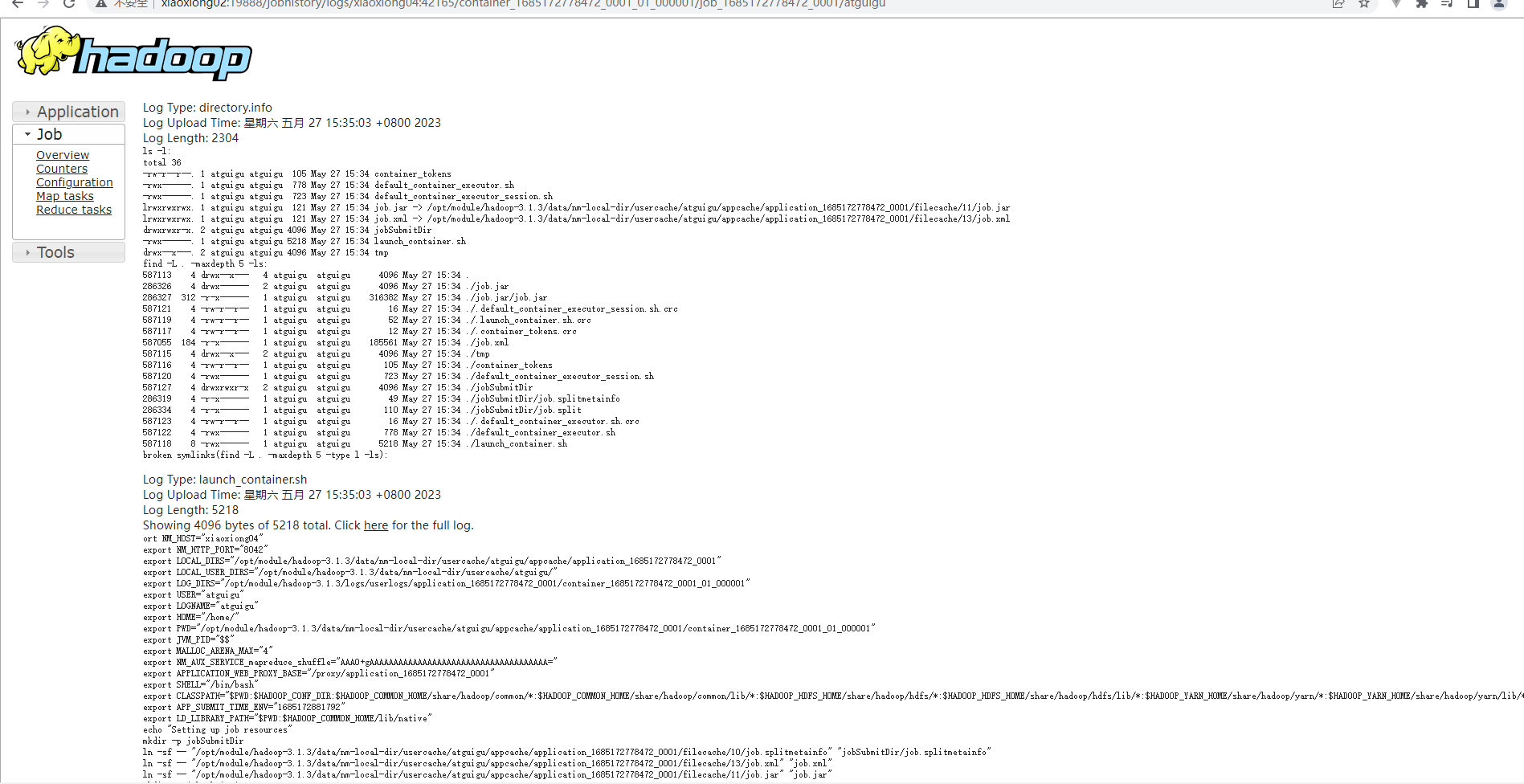
p34 日志聚集功能配置

p35 两个常用脚本
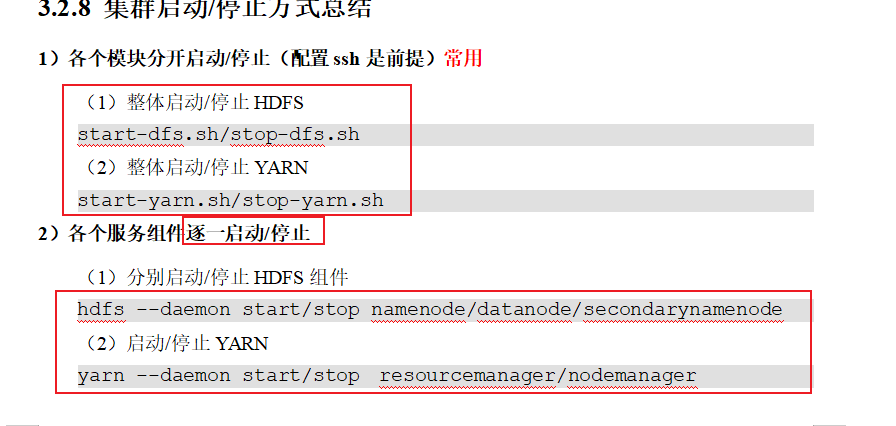
编写Hadoop集群常用脚本

启动与关闭集群脚本
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh xiaoxiong02 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh xiaoxiong03 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh xiaoxiong02 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh xiaoxiong02 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh xiaoxiong03 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh xiaoxiong02 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac

查看所有集群jps脚本
#!/bin/bash
for host in xiaoxiong02 xiaoxiong03 xiaoxiong04
do
echo =============== $host ===============
ssh $host jps
done

p36 两道面试题
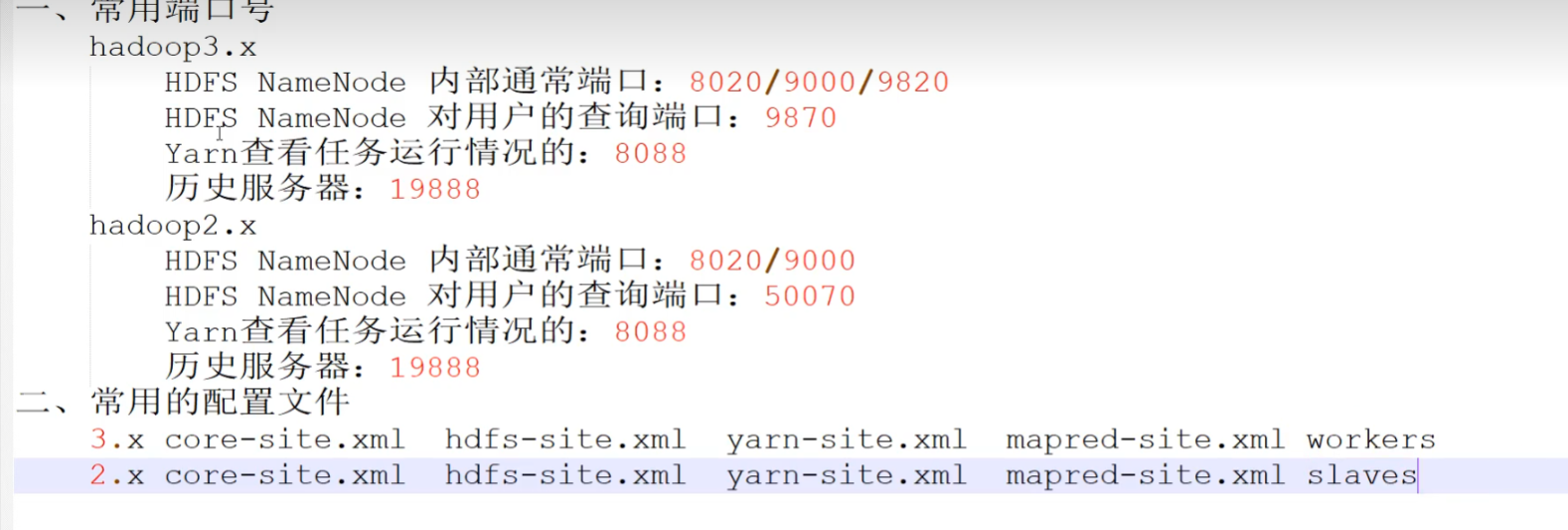
p37 集群时间同步

略
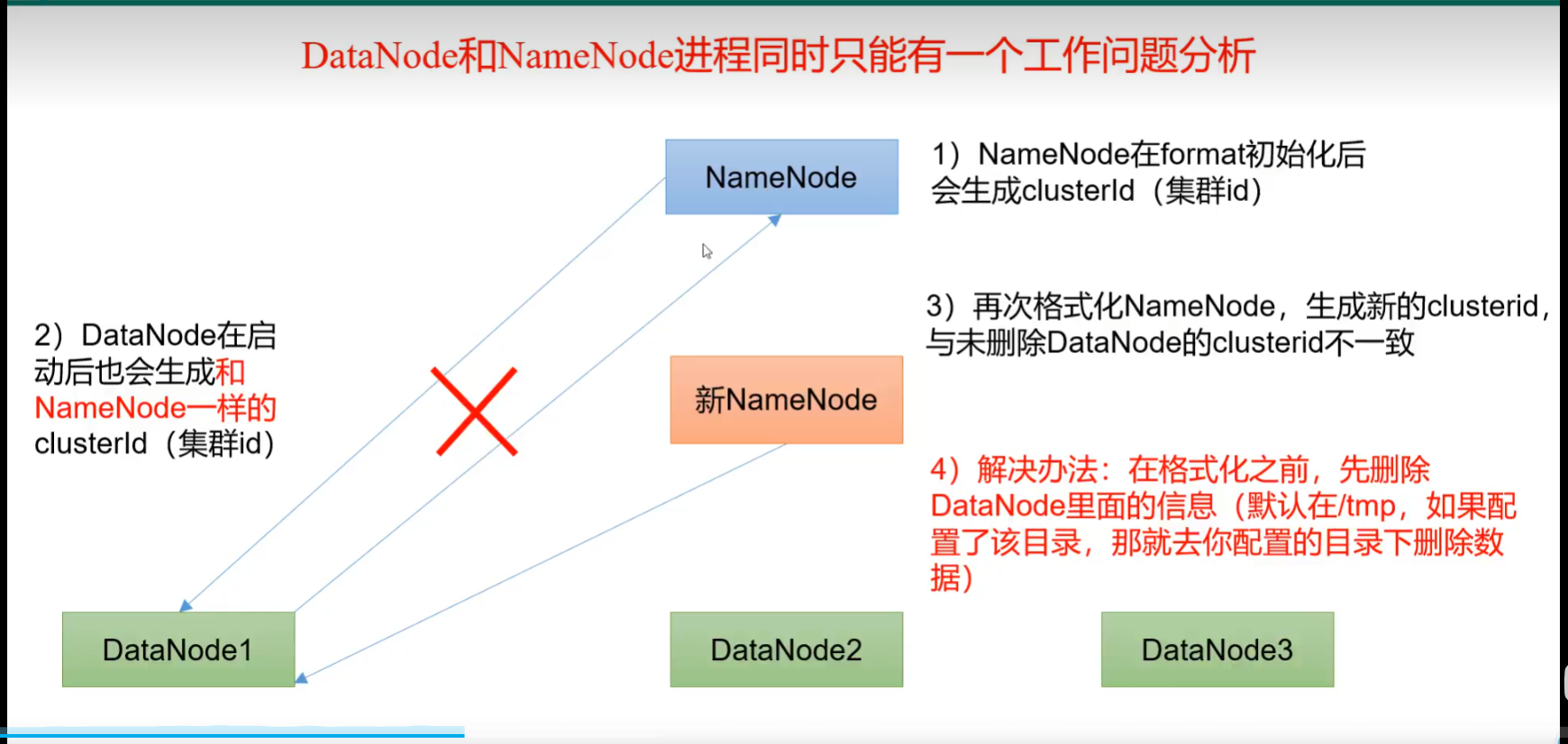
p38 常见问题总结














 263
263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









