







问题背景
现网业务高峰期大概在每小时的20-30分,每小时约1100万并发业务分布在此10分钟期间的约占75-80%,在此期间,服务需要频繁查询redis。目前服务搭建了二级缓存+一级db/接口的缓存结构如下:
-
一级:loadingCache缓存
-
二级:redis缓存
-
三级:db、外部接口
但实际运行场景下,由于业务的重复度相比业务总量占比是很少的,所以大部分情况下loadingCache会被击穿,压力将给到redis,导致redis在高峰期cpu持续达到90%-100%,为了解决这个问题,服务采取loadingcache预热的形式:以pipeline的模式从redis批量获取缓存,一次性存入loadingcache中,同时为了减少loadingcache的逐出,取消了loadingcache的最大数量限制,同时将过期时间缩短至5min(保证99.9%以上的话单都能在这个时间内处理完,即都从loadingcache中加载数据)。以billing2管道的优化效果为例,效果如下:
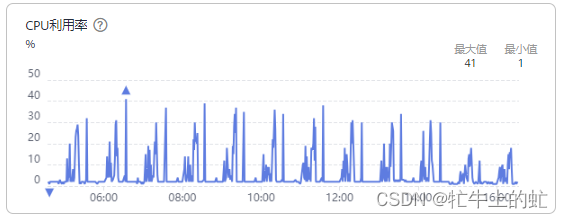
可见优化是有效果的,cpu利用率峰值时降低达到20%。但是这种对loadingcache的优化产生了新问题:垃圾回收变得更加频繁,导致服务性能下降:
优化前:垃圾回收占总时长15.36%,6倍压测服务处理时长约25min
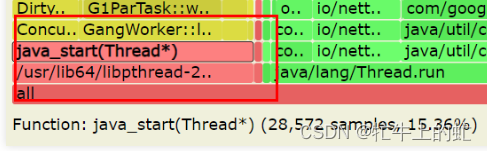
优化后:垃圾回收总时长占36%,6倍压测metric处理时长约30min+
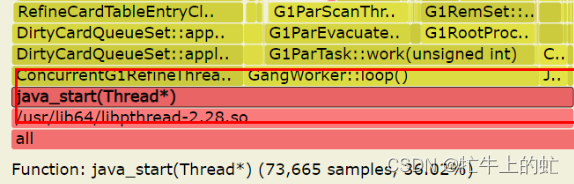
问题分析
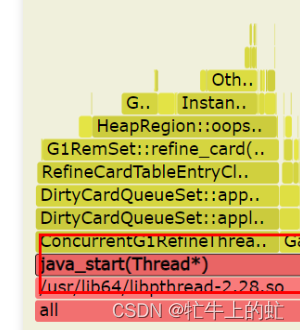
看上去G1的refine流程占比是比较多的
在服务脚本中补充G1相关参数,增加refine流程相关的日志输出,跑一次六倍
-XX:+PrintGCDetails # 开启详细GC日志
-XX:+UnlockDiagnosticVMOptions # 解锁诊断参数
-XX:+G1TraceConcRefinement # 输出G1 refine流程
-XX:+G1SummarizeRSetStats # 输出G1的RSet状态
-XX:G1SummarizeRSetStatsPeriod=2 # refine流程统计周期,每两次统计一次虽然看上去refine流程的耗时比较多,但是实际上看单次refine耗时不高,单次gc耗时也不高

![]()
虽然表面上refine耗时多,但是结合gc日志的耗时看来,这是refine总时长高是结果而不是原因。因此继续通过gcviewer分析gc日志
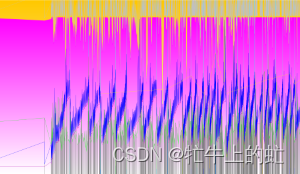
浅看一下gcviewer绘制的内存分布图,可以看出黄色的young区完全兜不住内存占用,触发了G1的动态扩容,只勾选新生代、老年代容量以及占用看下

可以看出,服务默认配置的10%新生代基本上是扛不住的,另一边分配给老年代的90%也完全用不了
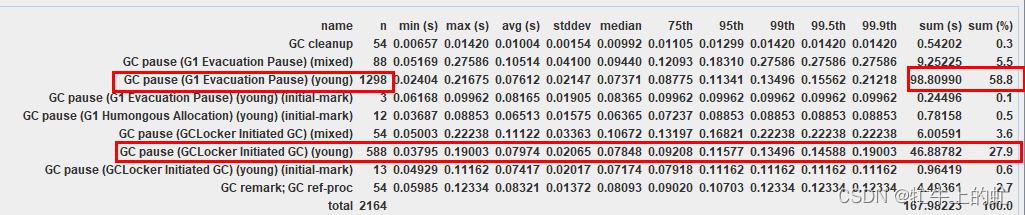
G1 Evacuation Pause是常规GC,发生于对象从新生代迁移至老年代
GCLocker Initiated GC是JNI临界区GC,发生于多线程执行时锁的切换(例如sychronized)
两种youngGC占了几乎86%,于是几乎可以确定是因为年轻代不够用了导致频繁GC,拖慢了业务处理性能
第一次调优:
-XX:G1NewSizePercent=10 ---> 25
-XX:MaxGCPauseMillis=100 ---> 200增大新生代区域占比到25,延长GC暂停时间到200ms
第一次调优后重新跑6倍,观察结果:

可以看出来young区扩容的情况明显变少了
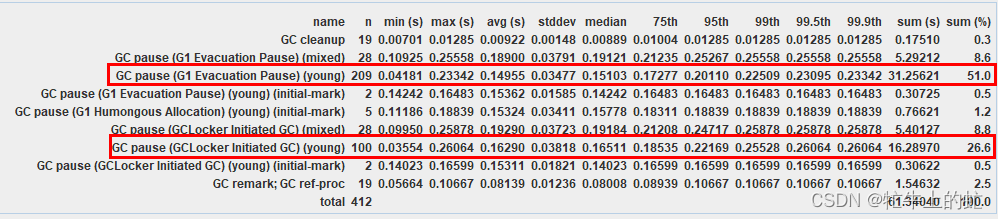
youngGC的次数也明显减少了
再观察下6倍曲线:
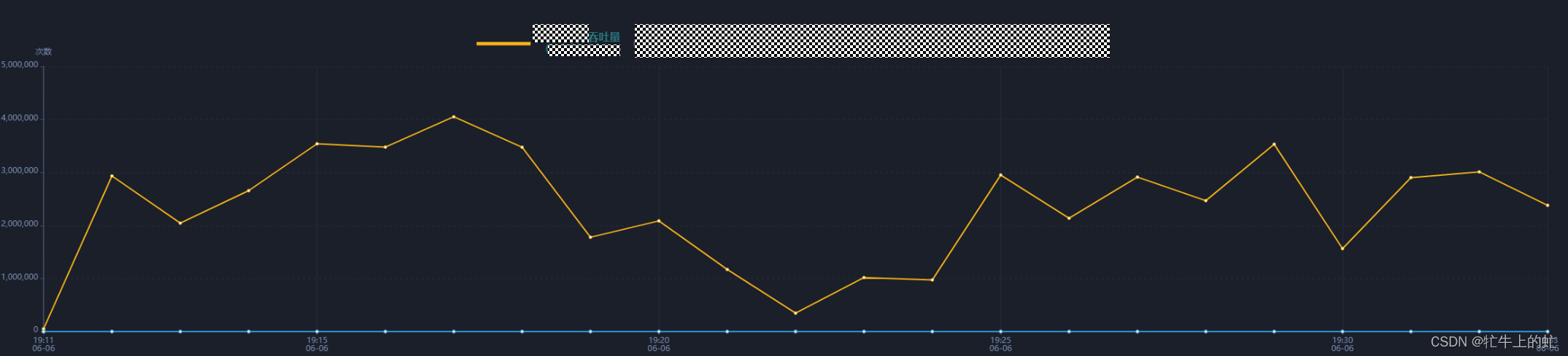
可以看出来在7点20的时候,触发了young区扩容,同时也导致了性能下降,可以推测为频繁youngGC导致了young区扩容,同时GC时需要STOP THE WORLD也拖慢了性能,于是进行二次优化:
-XX:G1NewSizePercent=25 ---> 40
-XX:MaxGCPauseMillis=200 ---> 250重新进行6倍,验证效果:
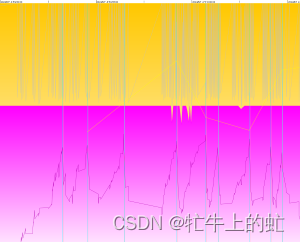
已经基本不扩容了,且6倍性能能跑到20min左右
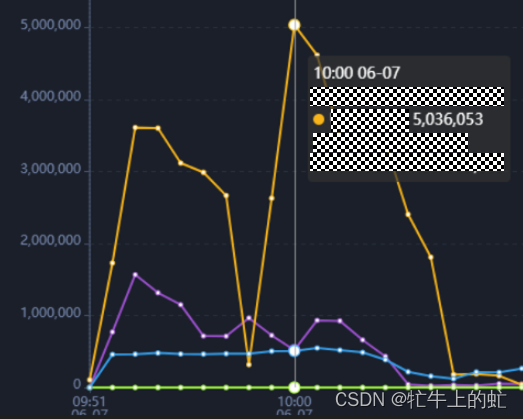
基本消除了长时间处于低性能的部分,只出现了少数的扩容,对应有一个点的性能下降
最终优化效果和结论
调整参数如下:
-XX:G1NewSizePercent=10 ---> 40
-XX:MaxGCPauseMillis=100 ---> 250效果如下:
-
6倍性能从30min(优化前)降低至20min(优化后),甚至redis预热上线后节省了redis通信的耗时,性能比做loadingcache预热前性能(25min)还好
-
GC占总时长由36%下降至25%,虽然没有loadingcache预热前的版本好,但是时间上总性能更好了,由内存分摊了部分压力是可以接受的
结论:
-
离线服务可以考虑适当扩大young区,同时增大GC停顿时间使GC效果更好,但是在线服务由于接口响应要求,需要具体问题具体分析
-
业务是峰谷周期的服务,young区的压力可能比old区更大,可以通过适当调整平衡压力,不要啥服务都直接套用脚手架里面的模板
知识储备
G1回收器的处理流程
初始标记、并发标记、最终标记、筛选回收。除了并发标记阶段,其他都要暂停用户线程。一般默认停顿在100~300毫秒比较合适。
G1回收器的refine流程
抽样线程。
G1常说是空间换时间,抽样线程就是它用空间换时间的方案。在线程中看到G1RefineThread相关的就是G1的抽样线程。抽样线程有两个作用:
-
处理新生代分区的抽样,并且在满足响应时间的这个指标下,更新YHR的数目
-
管理RSet,即引用关系,G1把所有的引用关系都放到一个队列中(DCQ),G1是分region的,DCQ就不止有一个,都存到一个set中即DCQS
为了处理这些引用关系,G1把线程分成了GC线程、refine线程,并且给了三个阈值划分了4个区:
-
白区:[0, Green),在该区中只有GC线程处理DCQ
-
绿区:[Green, Yellow),在该区中会依据queue set数值大小启动不同数量的Refine线程处理DCQ
-
黄区:[Yellow, Red),在该区中所有refine线程启动处理DCQ
-
红区:[Red, ),在该区中业务线程也参与进来处理DCQ
这三个阈值可以通过参数设置,也可以不设置,默认值为0,但G1会根据回收时间动态调整,即refine时间超过预期,变为1.1倍,反之变为0.9倍。
-XX:G1ConcRefinementGreenZone
-XX:G1ConcRefinementYellowZone
-XX: G1ConcRefinementRedZone在绿区中,refine线程的数量可以通过参数指定同时也具有动态调整能力,一般是CPU核数的5/8,这些线程都是处于冻结状态的,被逐渐唤醒:refine#0是被业务线程唤醒的,其他refine#n线程是被refine#n-1线程唤醒的,唤醒的条件是queue set数量达到了一个阈值,这个阈值也是动态调整的















 2033
2033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









