







1.查看所有键:keys *
2.键总数:dbsize
dbsize命令在计算键总数时不会遍历所有键,而是直接获取Redis内置的键总数变量,所以dbsize命令的时间复杂度是O(1)。而keys命令会遍历所有键,所以它的时间复杂度是O(n),当Redis保存了大量键时,线上环境禁止使用。
Redis提供了两个命令遍历所有的键,分别是keys和scan,
全量遍历键:keys pattern
pattern使用的是glob风格的通配符:
·*代表匹配任意字符。
·代表匹配一个字符。
·[]代表匹配部分字符,例如[1,3]代表匹配1,3,[1-10]代表匹配1到10的任意数字。
·\x用来做转义,例如要匹配星号、问号需要进行转义。
下面操作匹配以j,r开头,紧跟edis字符串的所有键:
127.0.0.1:6379> keys [j,r]edis
1) "jedis"
2) "redis"
当需要遍历所有键时(例如检测过期或闲置时间、寻找大对象等),keys是一个很有帮助的命令,例如想删除所有以video字符串开头的键,可以执行如下操作:
redis-cli keys video* | xargs redis-cli del
考虑到Redis的单线程架构,如果Redis包含了大量的键,执行keys命令很可能会造成Redis阻塞,所以一般建议不要在生
产环境下使用keys命令。但有时候确实有遍历键的需求该怎么办,可以在以下三种情况使用:
·在一个不对外提供服务的Redis从节点上执行,这样不会阻塞到客户端的请求,但是会影响到主从复制。
·如果确认键值总数确实比较少,可以执行该命令。
·使用下面要介绍的scan命令渐进式的遍历所有键,可以有效防止阻塞
scan:Redis从2.8版本后,提供了一个新的命令scan,scan采用渐进式遍历的方式来解决keys命令可能带来的阻塞问题,每次scan命令的时间复杂度是O(1),但是要真正实现keys的功能,需要执行多次scan。
Redis存储键值对实际使用的是hashtable的数据结构,其简化模型如图2-29所示。
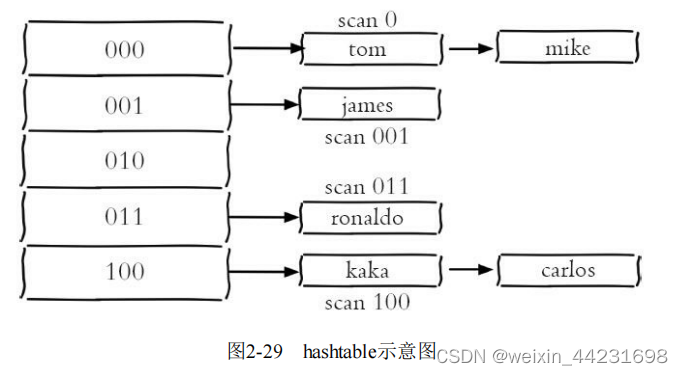
那么每次执行scan,可以想象成只扫描一个字典中的一部分键,直到将字典中的所有键遍历完毕。scan的使用方法如下:
scan cursor [match pattern] [count number] [TYPE type]
# 使用MATCH选项
SCAN 0 MATCH user*
# 使用COUNT选项
SCAN 0 COUNT 100
# 使用TYPE选项
SCAN 0 TYPE string
scan 0 match * count 20 type String
·cursor是必需参数,实际上cursor是一个游标,第一次遍历从0开始,每次scan遍历完都会返回当前游标的值,直到游标值为0,表示遍历结束。
·match pattern是可选参数,它的作用的是做模式的匹配,这点和keys的模式匹配很像。
·count number是可选参数,它的作用是表明每次要遍历的键个数,默认值是10,此参数可以适当增大。
现有一个Redis有26个键(英文26个字母),现在要遍历所有的键,使用scan命令效果的操作如下。第一次执行scan0,返回结果分为两个部分:第一个部分6就是下次scan需要的cursor,第二个部分是10个键:
127.0.0.1:6379> scan 0
1) "6"
2) 1) "w"
2) "i"
3) "e"
4) "x"
5) "j"
6) "q"
7) "y"
8) "u"
9) "b"
10) "o"
使用新的cursor=“6”,执行scan6:
127.0.0.1:6379> scan 6
1) "11"
2) 1) "h"
2) "n"
3) "m"
4) "t"
5) "c"
6) "d"
7) "g"
8) "p"
9) "z"
10) "a"
这次得到的cursor=“11”,继续执行scan11得到结果cursor变为0,说明所有的键已经被遍历过了:
127.0.0.1:6379> scan 11
1) "0"
2) 1) "s"
2) "f"
3) "r"
4) "v"
5) "k"
6) "l"
除了scan以外,Redis提供了面向哈希类型、集合类型、有序集合的扫描遍历命令,解决诸如hgetall、smembers、zrange可能产生的阻塞问题,对应的命令分别是hscan、sscan、zscan,它们的用法和scan基本类似,下面以sscan为例子进行说明,当前集合有两种类型的元素,例如分别以old:user和new:user开头,先需要将old:user开头的元素全部删除,可以参考如下伪代码:
String key = "myset";
// 定义pattern
String pattern = "old:user*";
// 游标每次从0开始
String cursor = "0";
while (true) {
// 获取扫描结果
ScanResult scanResult = redis.sscan(key, cursor, pattern);
List elements = scanResult.getResult();
if (elements != null && elements.size() > 0) {
// 批量删除
redis.srem(key, elements);
}
// 获取新的游标
cursor = scanResult.getStringCursor();
// 如果游标为0表示遍历结束
if ("0".equals(cursor)) {
break;
}
}
渐进式遍历可以有效的解决keys命令可能产生的阻塞问题,但是scan并非完美无瑕,如果在scan的过程中如果有键的变化(增加、删除、修改),那么遍历效果可能会碰到如下问题:新增的键可能没有遍历到,遍历出了重复的键等情况,也就是说scan并不能保证完整的遍历出来所有的键,这些是我们在开发时需要考虑的。
3.检查键是否存在:exists key //如果键存在则返回1,不存在则返回0
4.删除键:del key [key …]//返回结果为成功删除键的个数,删除不存在的键,就会返回0:
5.键过期:expire key seconds//键在seconds秒后过期。当超过过期时间后,会自动删除键
·expireat key timestamp:键在秒级时间戳timestamp后过期。
expireat命令可以设置键的秒级过期时间戳,例如如果需要将键hello在2016-08-0100:00:00(秒级时间戳为1469980800)过期,可以执行如下操作:
127.0.0.1:6379> expireat hello 1469980800
(integer) 1
除此之外,Redis2.6版本后提供了毫秒级的过期方案:
·pexpire key milliseconds:键在milliseconds毫秒后过期。
·pexpireat key milliseconds-timestamp键在毫秒级时间戳timestamp后过期。
127.0.0.1:6379> set key4 value4
OK
127.0.0.1:6379> pexpire key4 1718251080401
(integer) 1
但无论是使用过期时间还是时间戳,秒级还是毫秒级,在Redis内部最终使用的都是pexpireat。
如果expire key的键不存在,返回结果为0:如果过期时间为负值,键会立即被删除,犹如使用del命令一样。
persist命令可以将键的过期时间清除:
127.0.0.1:6379> hset key f1 v1
(integer) 1
127.0.0.1:6379> expire key 50
(integer) 1
127.0.0.1:6379> ttl key
(integer) 46
127.0.0.1:6379> persist key
(integer) 1
127.0.0.1:6379> ttl key
(integer) -1
注意:对于字符串类型键,执行set命令会去掉过期时间,这个问题很容易在开发中被忽视。
下面的例子证实了set会导致过期时间失效,因为ttl变为-1:
127.0.0.1:6379> expire hello 50
(integer) 1
127.0.0.1:6379> ttl hello
(integer) 46
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> ttl hello
(integer) -1
6.ttl命令会返回键的剩余过期时间(单位:秒)pttl命令精度更高(单位:毫秒),它有3种返回值: 大于等于0的整数:键剩余的过期时间。-1:键没设置过期时间。 -2:键不存在 。
7.键的数据结构类型:type key//如果键不存在,则返回none
8.键重命名 :rename key newkey //rename之前,键newkey 已经存在,那么它的值将被覆盖。
127.0.0.1:6379> set a b
OK
127.0.0.1:6379> set c d
OK
127.0.0.1:6379> rename a c
OK
127.0.0.1:6379> get a
(nil)
127.0.0.1:6379> get c
"b"
9.renamenx:为了防止被强行rename,确保只有newKey不存在时候才被覆盖,
例如下面操作renamenx时,newkey=python已经存在,返回结果是0代表没有完成重命名,所以键java和python的值没变:
127.0.0.1:6379> set java jedis
OK
127.0.0.1:6379> set python redis-py
OK
127.0.0.1:6379> renamenx java python
(integer) 0
127.0.0.1:6379> get java
"jedis"
127.0.0.1:6379> get python
"redis-py"
在使用重命名命令时,有两点需要注意:
·由于重命名键期间会执行del命令删除旧的键,如果键对应的值比较大,会存在阻塞Redis的可能性,这点不要忽视。
·如果rename和renamenx中的key和newkey如果相同,在Redis3.2和之前版本返回结果略有不同。
Redis3.2中会返回OK:
127.0.0.1:6379> rename key key
OK
Redis3.2之前的版本会提示错误:
127.0.0.1:6379> rename key key
(error) ERR source and destination objects are the same
10.随机返回一个键:randomkey
11.setex命令作为set+expire的组合,不但是原子执行,同时减少了一次网络通讯的时间。
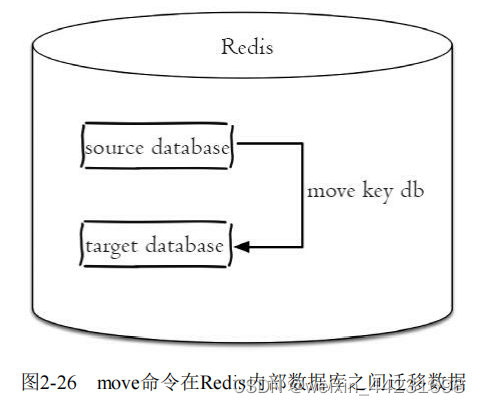
12.迁移键:,Redis提供了move、dump+restore、migrate三组迁移键的方法,它们的实现方式以及使用的场景不太相同
(1)move:move key db//,move命令用于在Redis内部进行数据迁移,Redis内部可以有多个数据库,彼此在数据上是相互隔离的,move key db就是把指定的键从源数据库移动到目标数据库中,但多数据库功能不建议在生产环境使用。
(2)dump+restore:
dump key
restore key ttl value
dump+restore可以实现在不同的Redis实例之间进行数据迁移的功能,整个迁移的过程分为两步:
1)在源Redis上,dump命令会将键值序列化,格式采用的是RDB格式。
2)在目标Redis上,restore命令将上面序列化的值进行复原,其中ttl参数代表过期时间,如果ttl=0代表没有过期时间。
整个过程如图2-27所示
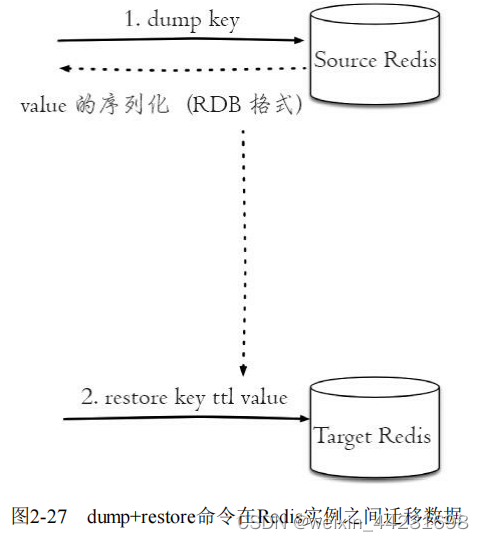
有关dump+restore有两点需要注意:第一,整个迁移过程并非原子性的,而是通过客户端分步完成的。第二,迁移过程是开启了两个客户端连接,所以dump的结果不是在源Redis和目标Redis之间进行传输,下面用一个例子演示完整过程
1)在源Redis上执行dump:
redis-source> set hello world
OK
redis-source> dump hello
"\x00\x05world\x06\x00\x8f<T\x04%\xfcNQ"
2)在目标Redis上执行restore:
redis-target> get hello
(nil)
redis-target> restore hello 0 "\x00\x05world\x06\x00\x8f<T\x04%\xfcNQ"
OK
redis-target> get hello
"world"
上面2步对应的伪代码如下:
Redis sourceRedis = new Redis("sourceMachine", 6379);
Redis targetRedis = new Redis("targetMachine", 6379);
targetRedis.restore("hello", 0, sourceRedis.dump(key));
(3)migrate
migrate host port key|"" destination-db timeout [copy] [replace] [AUTH password] [AUTH2 username password][keys key [key ...]]
下面对migrate的参数进行逐个说明:
·host:目标Redis的IP地址。
·port:目标Redis的端口。
·key|“”:在Redis3.0.6版本之前,migrate只支持迁移一个键,所以此处是要迁移的键,但Redis3.0.6版本之后支持迁移多个键,如果当前需要迁移多个键,此处为空字符串""。
·destination-db:目标Redis的数据库索引,例如要迁移到0号数据库,这里就写0。
·timeout:迁移的超时时间(单位为毫秒)。
·[copy]:如果添加此选项,迁移后并不删除源键。
·[replace]:如果添加此选项,migrate不管目标Redis是否存在该键都会正常迁移进行数据覆盖。
·[keys key[key…]]:迁移多个键,例如要迁移key1、key2、key3,此处填写“keys key1 key2 key3”。
migrate命令也是用于在Redis实例间进行数据迁移的,实际上migrate命令就是将dump、restore、del三个命令进行组合,从而简化了操作流程。migrate命令具有原子性,而且从Redis3.0.6版本以后已经支持迁移多个键的功能,有效地提高了迁移效率。
整个过程如图2-28所示,实现过程和dump+restore基本类似,但是有3点不太相同:第一,整个过程是原子执行的,不需要在多个Redis实例上开启客户端的,只需要在源Redis上执行migrate命令即可。第二,migrate命令的数据传输直接在源Redis和目标Redis上完成的。第三,目标Redis完成restore后会发送OK给源Redis,源Redis接收后会根据migrate对应的选项来决定是否在源Redis上删除对应的键。
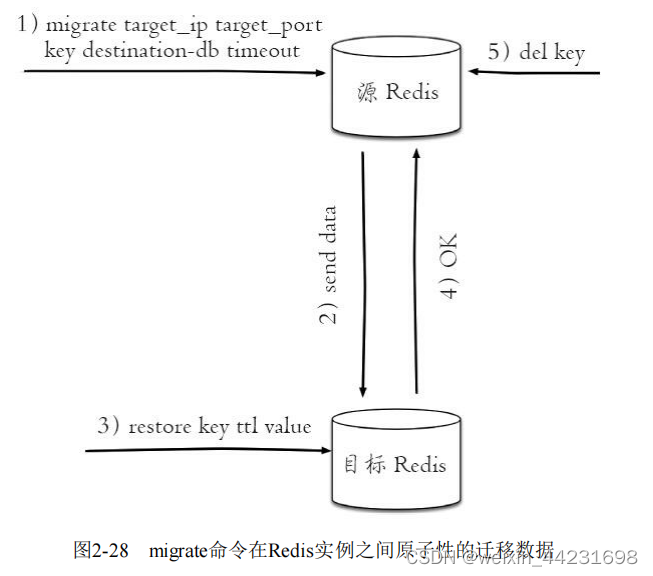
下面用示例演示migrate命令,为了方便演示源Redis使用6379端口,目标Redis使用6380端口,现要将源Redis的键hello迁移到目标Redis中,会分为如下几种情况:
情况1:源Redis有键hello,目标Redis没有:
127.0.0.1:6379> migrate 127.0.0.1 6380 hello 0 1000 auth mypassword
OK
情况2:源Redis和目标Redis都有键hello:
127.0.0.1:6379> get hello
"world"
127.0.0.1:6380> get hello
"redis"
如果migrate命令没有加replace选项会收到错误提示,如果加了replace会
返回OK表明迁移成功:
127.0.0.1:6379> migrate 127.0.0.1 6379 hello 0 1000
(error) ERR Target instance replied with error: BUSYKEY Target key name already exists.
158
127.0.0.1:6379> migrate 127.0.0.1 6379 hello 0 1000 replace
OK
情况3:源Redis没有键hello。如下所示,此种情况会收到nokey的提示:
127.0.0.1:6379> migrate 127.0.0.1 6380 hello 0 1000
NOKEY
下面演示一下Redis3.0.6版本以后迁移多个键的功能。
·源Redis批量添加多个键:
127.0.0.1:6379> mset key1 value1 key2 value2 key3 value3
OK
源Redis执行如下命令完成多个键的迁移:
127.0.0.1:6379> migrate 127.0.0.1 6380 "" 0 5000 keys key1 key2 key3
OK
至此有关Redis数据迁移的命令介绍完了,最后使用表2-9总结一下move、dump+restore、migrate三种迁移方式的异同点,笔者建议使用migrate命令进行键值迁移。
| 命令 | 作用域 | 原子性 | 支持多个键 |
|---|---|---|---|
| move | Redis 实例内部 | 是 | 否 |
| dump + restore | Redis 实例之间 | 否 | 否 |
| migrate | Redis 实例之间 | 是 | 是 |
13.Redis默认配置中是有16个数据库,切换数据库:select dbIndex
默认使用的就是0号数据库,Redis3.0中已经逐渐弱化这个功能,例如Redis的分布式实现Redis Cluster只允许使用0号数据库,只不过为了向下兼容老版本的数据库功能,该功能没有完全废弃掉,分析一下为什么废弃掉这个“优秀”的功能呢?总结起来有三点:
·Redis是单线程的。如果使用多个数据库,那么这些数据库仍然是使用一个CPU,彼此之间还是会受到影响的。
·多数据库的使用方式,会让调试和运维不同业务的数据库变的困难,假如有一个慢查询存在,依然会影响其他数据库,这样会使得别的业务方定位问题非常的困难。
·部分Redis的客户端根本就不支持这种方式。即使支持,在开发的时候来回切换数字形式的数据库,很容易弄乱。
笔者建议如果要使用多个数据库功能,完全可以在一台机器上部署多个Redis实例,彼此用端口来做区分,因为现代计算机或者服务器通常是有多个CPU的。这样既保证了业务之间不会受到影响,又合理地使用了CPU资源。
15.清除数据库:flushdb/flushall,两者的区别的是flushdb只清除当前数据库,flushall会清除所有数据库。
flushdb/flushall命令可以非常方便的清理数据,但是也带来两个问题:
·flushdb/flushall命令会将所有数据清除,一旦误操作后果不堪设想,可以通过rename-command配置规避这个问题。
·如果当前数据库键值数量比较多,flushdb/flushall存在阻塞Redis的可能性。所以在使用flushdb/flushall一定要小心谨慎。
16.排序:返回或保存给定列表、集合、有序集合 key 中经过排序的元素。排序默认以数字作为对象,值被解释为双精度浮点数,然后进行比较。
SORT key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern …]] [ASC | DESC] [ALPHA] [STORE destination]
- 使用外部 key 进行排序 :可以使用外部 key 的数据作为权重,代替默认的直接对比键值的方式来进行排序。

127.0.0.1:6379> lpush uid 1 2 3 4
(integer) 4
127.0.0.1:6379> mset user_name_1 admin user_name_2 jack user_name_3 peter user_name_4 mary user_level_1 9999 user_level_2 10 user_level_3 25 user_level_4 70
OK
127.0.0.1:6379> mget user_name_1 user_name_2 user_name_3 user_name_4 user_level_1 user_level_2 user_level_3 user_level_4
1) "admin"
2) "jack"
3) "peter"
4) "mary"
5) "9999"
6) "10"
7) "25"
8) "70"
- by选项:通过使用 BY 选项,可以让 uid 按其他键的元素来排序。
比如说, 以下代码让 uid 键按照 user_level_{uid} 的大小来排序:
redis 127.0.0.1:6379> SORT uid BY user_level_*
1) "2" # jack , level = 10
2) "3" # peter, level = 25
3) "4" # mary, level = 70
4) "1" # admin, level = 9999
user_level_* 是一个占位符, 它先取出 uid 中的值, 然后再用这个值来查找相应的键。
比如在对 uid 列表进行排序时, 程序就会先取出 uid 的值 1 、 2 、 3 、 4 , 然后使用 user_level_1 、 user_level_2 、 user_level_3 和 user_level_4 的值作为排序 uid 的权重。
- GET 选项 :使用 GET 选项, 可以根据排序的结果来取出相应的键值。
比如说, 以下代码先排序 uid , 再取出键 user_name_{uid} 的值:
redis 127.0.0.1:6379> SORT uid GET user_name_*
1) "admin"
2) "jack"
3) "peter"
4) "mary"
- 组合使用 BY 和 GET:通过组合使用 BY 和 GET , 可以让排序结果以更直观的方式显示出来。
比如说, 以下代码先按 user_level_{uid} 来排序 uid 列表, 再取出相应的 user_name_{uid} 的值:
redis 127.0.0.1:6379> SORT uid BY user_level_* GET user_name_*
1) "jack" # level = 10
2) "peter" # level = 25
3) "mary" # level = 70
4) "admin" # level = 9999
现在的排序结果要比只使用 SORT uid BY user_level_* 要直观得多。
获取多个外部键:可以同时使用多个 GET 选项, 获取多个外部键的值。
以下代码就按 uid 分别获取 user_level_{uid} 和 user_name_{uid} :
redis 127.0.0.1:6379> SORT uid GET user_level_* GET user_name_*
1) "9999" # level
2) "admin" # name
3) "10"
4) "jack"
5) "25"
6) "peter"
7) "70"
8) "mary"
GET 有一个额外的参数规则,那就是 —— 可以用 # 获取被排序键的值。
以下代码就将 uid 的值、及其相应的 user_level_* 和 user_name_* 都返回为结果:
redis 127.0.0.1:6379> SORT uid GET # GET user_level_* GET user_name_*
1) "1" # uid
2) "9999" # level
3) "admin" # name
4) "2"
5) "10"
6) "jack"
7) "3"
8) "25"
9) "peter"
10) "4"
11) "70"
12) "mary"
获取外部键,但不进行排序:通过将一个不存在的键作为参数传给 BY 选项, 可以让 SORT 跳过排序操作, 直接返回结果:
redis 127.0.0.1:6379> SORT uid BY not-exists-key
1) "4"
2) "3"
3) "2"
4) "1"
这种用法在单独使用时,没什么实际用处。
不过,通过将这种用法和 GET 选项配合, 就可以在不排序的情况下, 获取多个外部键, 相当于执行一个整合的获取操作(类似于 SQL 数据库的 join 关键字)。
以下代码演示了,如何在不引起排序的情况下,使用 SORT 、 BY 和 GET 获取多个外部键:
redis 127.0.0.1:6379> SORT uid BY not-exists-key GET # GET user_level_* GET user_name_*
1) "4" # id
2) "70" # level
3) "mary" # name
4) "3"
5) "25"
6) "peter"
7) "2"
8) "10"
9) "jack"
10) "1"
11) "9999"
12) "admin"
将哈希表作为 GET 或 BY 的参数:除了可以将字符串键之外, 哈希表也可以作为 GET 或 BY 选项的参数来使用。
我们可以不将用户的名字和级别保存在 user_name_{uid} 和 user_level_{uid} 两个字符串键中, 而是用一个带有 name 域和 level 域的哈希表 user_info_{uid} 来保存用户的名字和级别信息:
redis 127.0.0.1:6379> HMSET user_info_1 name admin level 9999
OK
redis 127.0.0.1:6379> HMSET user_info_2 name jack level 10
OK
redis 127.0.0.1:6379> HMSET user_info_3 name peter level 25
OK
redis 127.0.0.1:6379> HMSET user_info_4 name mary level 70
OK
BY 和 GET 选项都可以用 key->field 的格式来获取哈希表中的域的值, 其中 key 表示哈希表键, field 则表示哈希表的域:
redis 127.0.0.1:6379> SORT uid BY user_info_*->level
1) "2"
2) "3"
3) "4"
4) "1"
redis 127.0.0.1:6379> SORT uid BY user_info_*->level GET user_info_*->name
1) "jack"
2) "peter"
3) "mary"
4) "admin"
- 保存排序结果:通过给 STORE 选项指定一个 key 参数,可以将排序结果保存到给定的键上。
默认情况下, SORT 操作只是简单地返回排序结果,并不进行任何保存操作。如果被指定的 key 已存在,那么原有的值将被排序结果覆盖。
127.0.0.1:6379> sort uid store sorted_uid
(integer) 4
可以通过将 SORT 命令的执行结果保存,并用 EXPIRE 为结果设置生存时间,以此来产生一个 SORT 操作的结果缓存。
这样就可以避免对 SORT 操作的频繁调用:只有当结果集过期时,才需要再调用一次 SORT 操作。另外,为了正确实现这一用法,你可能需要加锁以避免多个客户端同时进行缓存重建(也就是多个客户端,同一时间进行 SORT 操作,并保存为结果集),具体参见 SETNX 命令。
- SORT key 返回键值从小到大排序的结果。
- SORT key DESC 返回键值从大到小排序的结果。
- SORT 命令默认排序对象为数字, 当需要对字符串进行排序时, 需要显式地在 SORT 命令之后添加 ALPHA 修饰符:
# 网址
redis> LPUSH website "www.reddit.com"
(integer) 1
redis> LPUSH website "www.slashdot.com"
(integer) 2
redis> LPUSH website "www.infoq.com"
(integer) 3
# 默认(按数字)排序
redis> SORT website
1) "www.infoq.com"
2) "www.slashdot.com"
3) "www.reddit.com"
# 按字符排序
redis> SORT website ALPHA
1) "www.infoq.com"
2) "www.reddit.com"
3) "www.slashdot.com"
排序之后返回元素的数量可以通过 LIMIT 修饰符进行限制, 修饰符接受 offset 和 count 两个参数:
- offset 指定要跳过的元素数量。
- count 指定跳过 offset 个指定的元素之后,要返回多少个对象。
时间复杂度:
O(N+M*log(M)), N 为要排序的列表或集合内的元素数量, M 为要返回的元素数量。
如果只是使用 SORT 命令的 GET 选项获取数据而没有进行排序,时间复杂度 O(N)。
返回值:
没有使用 STORE 参数,返回列表形式的排序结果。
使用 STORE 参数,返回排序结果的元素数量。















 1013
1013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









