









疫情肆虐,时间空余,将HashMap源码看了看,加上之前的知识,总结了一篇针对hashMap的常见问题,放在这里分享,如理解有误,请留言指正。
讲讲你对HashMap的理解?
hashMap其实就是一个以key-value形式组成的键值对容器。
在jdk1.8之前,底层是以数组+链表形式组成的,在jdk1.8及其以后,底层是以数组+链表+红黑树组成。数组里面每个地方都存了Key-Value这样的实例,在Java7叫Entry在Java8中叫Node。
数组的长度可以在创建对象的时候指定,如果未做指定,那么默认数组长度为16。创建对象时,还有一个值可以指定,那就是装载因子,如果未做指定,那么默认设定为0.75(为啥是0.75而不是0.9或0.5?主要是符合泊松分布规律,在0.75时,key的分布最为均匀,这里不多赘述)。
你知道新的Entry节点在插入链表的时候,是怎么插入的么?
java8之前是头插法,就是说新来的值会取代原有的值,原有的值就顺推到链表中去,就像上面的例子一样,因为写这个代码的作者认为后来的值被查找的可能性更大一点,提升查找的效率。
但是,在java8之后,都是所用尾部插入了。
为啥改为尾部插入呢?
因为在多线程进行put操作的时候,如果插入的值超过了阈值,那么就会触发Resize扩容机制。而在多线程的情况下进行扩容,如果有多个线程操作了同一个桶(同一个数组位置)的数据的话,可能会出现‘环形链表’的情况,那么如果程序来get当前桶中的一个entry时,会导致程序进入死循环!
你都都说了头插是JDK1.7的那1.8的尾插是怎么样的呢?
使用头插会改变链表的上的顺序,但是如果使用尾插,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。
就是说原本是A->B,在扩容后那个链表还是A->B
那是不是意味着Java8就可以把HashMap用在多线程中呢?
我认为即使不会出现死循环,但是通过源码看到put/get方法都没有加同步锁,多线程情况最容易出现的就是:无法保证上一秒put的值,下一秒get的时候还是原值,所以线程安全还是无法保证。
我记得你上面说过他是线程不安全的,那你能跟我聊聊你们是怎么处理HashMap在线程安全的场景么?
面试官,在这样的场景,我们一般都会使用使用
- Collections.synchronizedMap(Map)创建线程安全的map集合 (对hashmap的所有方法加synchronize方法块)
- HashTable (在所有的方法上加synchronize关键字)
- ConcurrentHashMap(使用分布式锁,下面会讲)
不过出于线程并发度的原因,我都会舍弃前两者使用最后的ConcurrentHashMap,他的性能和效率明显高于前两者。
HashTable我看过他的源码,很简单粗暴,直接在方法上锁,并发度很低,最多同时允许一个线程访问,ConcurrentHashMap就好很多了,1.7和1.8有较大的不同,不过并发度都比前者好太多了。
那Collections.synchronizedMap是怎么实现线程安全的你有了解过么?
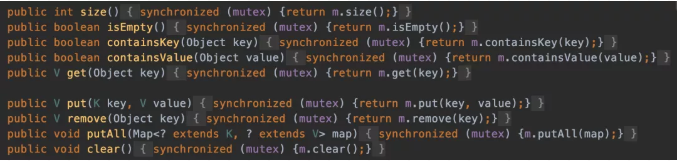
在SynchronizedMap内部维护了一个普通对象Map,还有排斥锁mutex,如图

我们在调用这个方法的时候就需要传入一个Map,可以看到有两个构造器,如果你传入了mutex参数,则将对象排斥锁赋值为传入的对象。
如果没有,则将对象排斥锁赋值为this,即调用synchronizedMap的对象,就是上面的Map。
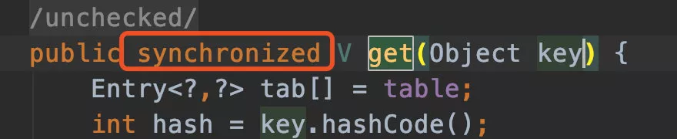
创建出synchronizedMap之后,再操作map的时候,就会对方法上锁,如图
很好,那能跟我聊一下Hashtable么?
跟HashMap相比,Hashtable是线程安全的,适合在多线程的情况下使用,但是效率可不太乐观。他在对数据操作的时候都会上锁,所以效率比较低下。
你还能说出一些Hashtable 跟HashMap不一样点么?
- Hashtable 是不允许键或值为 null 的,HashMap 的键值则都可以为 null。
- 实现方式不同:Hashtable 继承了 Dictionary类,而 HashMap 继承的是 AbstractMap 类。
- 初始化容量不同:HashMap 的初始容量为:16,Hashtable 初始容量为:11,两者的负载因子默认都是:0.75。
- 扩容机制不同:当现有容量大于总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 + 1。
- 迭代器不同:HashMap 中的 Iterator 迭代器是 fail-fast 的,而 Hashtable 的 Enumerator 不是 fail-fast 的。
那么为啥 Hashtable 是不允许 KEY 和 VALUE 为 null, 而 HashMap 则可以呢?
这是因为Hashtable使用的是安全失败机制(fail-safe),这种机制会使你此次读到的数据不一定是最新的数据。
因为hashtable,concurrenthashmap它们是用于多线程的,并发的 ,如果map.get(key)得到了null,不能判断到底是映射的value是null,还是因为没有找到对应的key而为空,而用于单线程状态的hashmap却可以用containKey(key) 去判断到底是否包含了这个null。
hashtable为什么就不能containKey(key)
一个线程先get(key)再containKey(key),这两个方法的中间时刻,其他线程怎么操作这个key都会可能发生,例如删掉这个key
HashMap却做了特殊处理。

fail-fast是啥?
快速失败(fail—fast)是java集合中的一种机制, 在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。
原理
迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。
集合在被遍历期间如果内容发生变化,就会改变modCount的值。
每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出异常,终止遍历。
你跟我说说ConcurrentHashMap的数据结构吧,以及为啥他并发度这么高?
我先说一下1.7中的数据结构吧:

如图所示,是由 Segment 数组、HashEntry 组成,和 HashMap 一样,仍然是数组加链表。
HashEntry跟HashMap差不多的,但是不同点是,他使用volatile去修饰了他的数据Value还有下一个节点next。
volatile的特性是啥?
-
保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。(实现可见性)
-
禁止进行指令重排序。(实现有序性)
-
volatile 只能保证对单次读/写的原子性。i++ 这种操作不能保证原子性。
你能说说他并发度高的原因么?
原理上来说,ConcurrentHashMap 采用了分段锁技术,其中 Segment 继承于 ReentrantLock。
不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。
每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
就是说如果容量大小是16他的并发度就是16,可以同时允许16个线程操作16个Segment而且还是线程安全的。
put方法
首先第一步的时候会尝试获取锁,如果获取失败肯定就有其他线程存在竞争,则利用 scanAndLockForPut() 自旋获取锁。
如果重试的次数达到了 MAX_SCAN_RETRIES 则改为阻塞锁获取,保证能获取成功。
get方法
get 逻辑比较简单,只需要将 Key 通过 Hash 之后定位到具体的 Segment ,再通过一次 Hash 定位到具体的元素上。
由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值。
ConcurrentHashMap 的 get 方法是非常高效的,因为整个过程都不需要加锁。
你有没有发现1.7虽然可以支持每个Segment并发访问,但是还是存在一些问题?
是的,因为基本上还是数组加链表的方式,我们去查询的时候,还得遍历链表,会导致效率很低,这个跟jdk1.7的HashMap是存在的一样问题,所以他在jdk1.8完全优化了。
那你再跟我聊聊jdk1.8他的数据结构是怎么样子的呢?
其中抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。
跟HashMap很像,也把之前的HashEntry改成了Node,但是作用不变,把值和next采用了volatile去修饰,保证了可见性,并且也引入了红黑树,在链表大于一定值的时候会转换(默认是8)。
那你觉得对于synchronizeMap、concurrentHashMap、HashTable的这些方法加了锁之后,就一定能确保线程安全吗?
我觉得,他们几个并发容器,能保证单独操作的情况下是线程安全的,但是在复合操作的情况下,还是会存在问题。虽然同步容器的所有方法都加了锁,但是对这些容器的复合操作无法保证其线程安全性。需要客户端通过主动加锁来保证。
简单举一个例子,我们定义如下删除Vector中最后一个元素方法:
public Object deleteLast(Vector v){
int lastIndex = v.size()-1;
v.remove(lastIndex);
}
上面这个方法是一个复合方法,包括size()和remove(),乍一看上去好像并没有什么问题,无论是size()方法还是remove()方法都是线程安全的,那么整个deleteLast方法应该也是线程安全的。
但是如果是多线程的情况下,A线程拿到了lastIndex,在未执行remove()方法的时候,B线程执行了这两步操作,那么A线程再去执行remove()操作时就会导致ArrayIndexOutOfBoundsException。
为了避免出现类似问题,可以尝试加锁:
public void deleteLast() {
synchronized (v) {
int index = v.size() - 1;
v.remove(index);
}
}
为什么会出现hash冲突?出现hash冲突是如何处理的?
第一点,我们知道hashCode值是一个int类型,所以hashCode值是有穷尽的,但是对象是无穷尽的,那么使用有穷尽的值来表示无穷尽的对象,可想而知,肯定会存在hashCode冲突(重复);第二点,通过对key的hashCode取余运算来计算该值存放的位置,那么肯定会存在余数相同的情况,例如:1%16=17%16,此时1和17就出现冲突。
当hashMap插入一个键值对时,首先会获取key,计算hashCode值,使用hashCode对数组长度减一做与(&)运算,计算获取到要存放的index值,如果数组当前的位置为空,那么就将键值对放入到数组的当前位置;如果当前位置已经有数据存放了,那么就将当前键值对挂载到当前位置的下面,以链表的形式存放,当链表长度要超过8时,为了增加查询效率,那么会将链表转换为红黑树。以此解决hash冲突。
为什么hashMap的数组长度一定是2的倍数?为什么与运算计算需要数组长度减一?
要解释这一点之前,我们首先要了解一下与(&)运算:&运算是针对二进制的位运算,它计算方式为 A & B 当A、B同位上都为1时,那么结果的同位上就是1。举例:1011 & 1110 = 1010 即:11&14=10。
我们知道,hashMap是通过对key进行取余(%)运算,将余数作为index找到数组中对应的位置,然后以链表或红黑树的形式挂载到该位置下边。但是相比于取余(%)运算,位运算的与(&)运算效率更高,因此hashMap计算index的方法也使用了该方法。在使用与运算时,由于数组长度为2的幂次,那么数组长度减一就是全是1,此时与运算分布的最均匀。
为什么每次扩容都是两倍?
解答:首先一点就是为了维持数组长度一直为2的倍数;还有就是刚好新增一倍的空间,将原来的一半移动到新的空间,重新达到散列平衡、保证效果。例如当数组长度为16时,当二倍扩容时,最大数组下标由二进制1111变成11111,由四位变为五位,那么计算的得到的index的第五位,不是0就是1,如果是0说明位置不变,如果是1说明 新下标=原位置下标+原容量大小!提升重散列的效率。
为什么构造方法里设置初始容量时,设置最大初始容量为 1<<30 ,而不能为(1<<31)-1或者1<<31 ?(源码如图)


众所周知,int类型的最大存储容量为2^31 -1,而1<<31大于int类型的最大值,所以1<<31不可以;同时,由于hashMap的容量必须是2的幂次,所以(1<<31)-1也并不合理,所以取了1<<30。
假设我知道,当前新建的hashMap需要存储100个键值对,那么在创建的时候需要指定hashMap数组的初始长度最好设置为多少?
我们知道,hashMap如果不指定初始容量,那么默认为16,为了减少扩容导致的重排序而浪费的性能,在知道存储量的情况下我们一般会指定初始容量。在没有特殊情况下,我们的负载因子都会指定为0.75,也就是说数组最大允许75%存在值,超过这个值就会再次扩容,所以当有100个数需要存放时,需要的数组长度为100/0.75=133.33~134,同时hashMap数组长度又必须是2的倍数,所以我们可以设置为256.















 3808
3808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









