






一、先看效果
1、文本识别

2、图片识别

二、方案
(1)文件格式处理
传统利用固定模板方式处理,需要针对固定模板处理
1、文件格式处理:
使用专门的库来处理不同的文件格式。例如,PyPDF2 或 PDFMiner 用于PDF文件,python-docx 用于DOCX文件,openpyxl 或 pandas 用于XLSX文件。
2、文本提取:
从各种文件中提取文本内容。
3、数据解析和模式匹配:
使用正则表达式或自定义的解析规则来从提取的文本中识别和提取关键信息。
实现模板匹配,基于预定义的字段和结构识别不同的订舱委托书模板。
缺点:应对模版多样性,只能简历固定模板方式处理,疲于奔命
(2)深度学习和OCR
1、图像提取
将所有文档转换为图像格式(如PDF和DOCX页面的屏幕截图)。
2、使用OCR技术
使用光学字符识别(OCR)技术(如Tesseract,Google Vision API)从图像中提取文本。
3、深度学习模型
使用深度学习模型(如卷积神经网络CNN)来处理从OCR获得的文本,并识别不同的模板。
这种方法可能需要大量的训练数据和高昂的计算资源。
缺点:
1、需要大量数据集进行训练调试
关于这个ocr可以利用读光OCR 但是
读光开源模型:https://modelscope.cn/search?search=%E8%AF%BB%E5%85%89
将这个模型拉下来,非训练模型的效果如下:
用官方的一个普通文本图片,可以看到可以识别出来
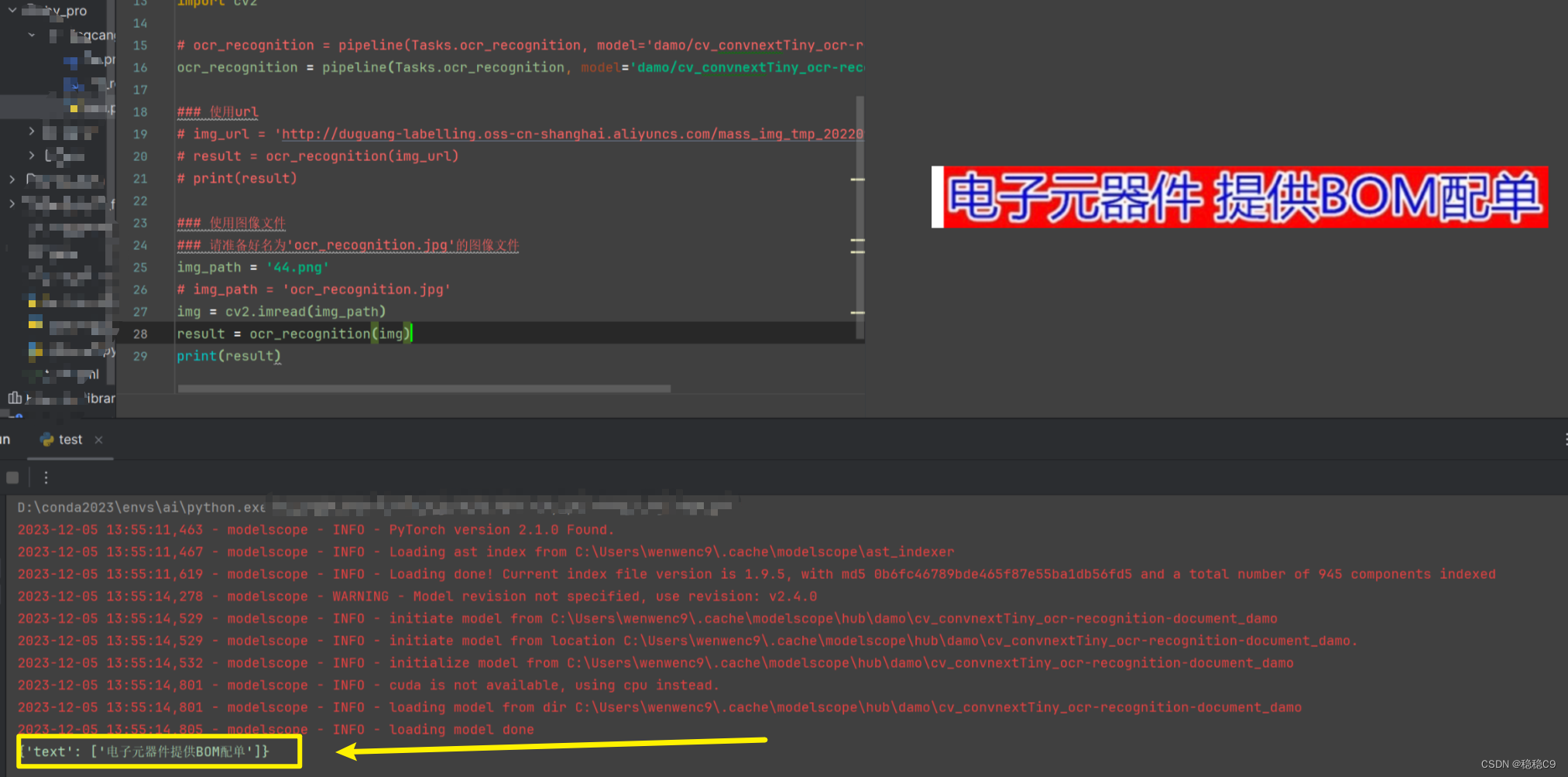
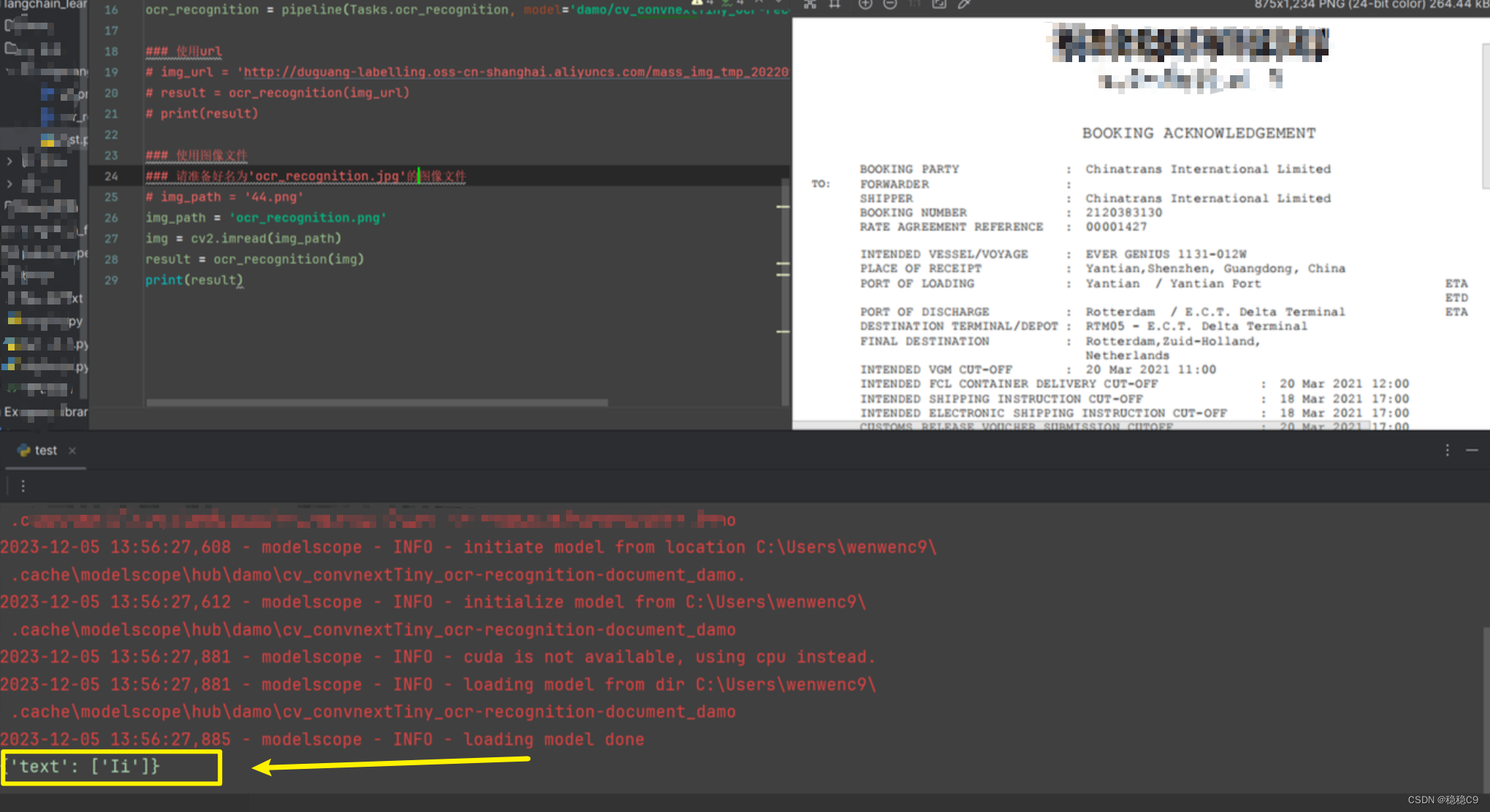
复杂多格式文本,都需要模型调参,可以看到效果并不好
当然阿里的读光有提供训练后的,并且结合了AI,效果就很明显了,并且能够根据prompt输出结构化数据 JSON
服务地址,可以去体验一下https://modelscope.cn/studios/iic/DocMaster/summary:

当然,读光也提供了,普通的识别,不加上AI
接口文档:https://help.aliyun.com/document_detail/272538.html?spm=5176.28087359.0.0.20266d18eMXPr7
体验地址:https://duguang.aliyun.com/experience?spm=a2c4g.295338.0.0.1d335f5erZ6RvY&type=universal
问题是,测试多个不同模板,输出的结构并非固定 JSON key-value,这导致在实际开发过程中无法覆盖取值问题

因此基于上面论述,可以使用下面方案,当然不一定用openai接口,可以用其它厂商
ocr离线(大量训练) + openai = 提取文本内容核心字段
限制条件:多样性文本的覆盖度
费用预期:openai,3.5 - turbo,预期一次3分钱
读光付费接口识别+ openai = 提取文本内容核心字段
准确率:~
限制条件:阿里已经训练,如果文档结构有问题不便于调优
费用预期:
梯度计费,阿里费用 + openai费用
一次调用 7分~1毛钱
适用:没有GPU设备的人群
openai 直接识别图片【结合规则引擎和人工智能】
准确率:~
限制条件:阿里已经训练,如果文档结构有问题不便于调优
费用预期:
梯度计费,阿里费用 + openai费用
一次调用 3分+
适用:有GPU设备的人群
当然还有别的方法,。。。模型离线什么的
三、构建工程
- 基于规则的初步处理:
使用规则引擎预处理文档,识别明显的模式和结构。 - AI增强的解析:
-对于复杂或不明显的案例,使用机器学习或深度学习模型来辅助识别和分类。 - 持续学习和适应:
系统可以通过用户反馈或持续的训练来不断优化和适应新的模板Prompt。
Fastapi接口脚本 read_datas.py
当然如果你想,可以在请求参数时候,将prompt变为动态的,这样就不单单只识别水单了
# -*- coding: utf-8 -*-
"""
-------------------------------------------------
# @File :read_datas
# @Date :2024/3/13 9:28
# @Author :wenwenc9
# @Software :PyCharm
-------------------------------------------------
"""
import os
import json
from fastapi.encoders import jsonable_encoder
from langchain.chains import LLMChain
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
import uvicorn
from fastapi import FastAPI
from pydantic import BaseModel
os.environ["OPENAI_API_KEY"] = '你的openaikey'
os.environ["OPENAI_API_BASE"] = "你的代理地址" # 直接用key的忽略这个代理设置
# 构建APP
app = FastAPI()
class BODY(BaseModel):
content: str
@app.post(path='/cotent')
async def process_content(content: BODY):
content = jsonable_encoder(content)['content']
print(content)
_template = """
订舱回执:{docs}
你是一个水单识别助手,专门识别水单,你遵循如下规则:
规则1-水单内容必须带有银行二字才开始识别
规则2-主要提取内容为:
1、付款人账号
2、付款人名称
3、付款人开户行
4、日期
5、收款人账号
6、收款人名称
7、收款人开户行
8、交易金额
规则3-返回的结果,请以字典形式返回,请严遵循规则2仅有8个键,如果找不到则值为空字符串
"""
llm_chain = LLMChain(
llm=ChatOpenAI(),
prompt=PromptTemplate(
template=_template,
input_variables=["content"]
),
)
# res = llm_chain.run(content)
try:
res = llm_chain.run(content)
final = json.loads(res)
except:
final = '识别失败'
return final
if __name__ == '__main__':
uvicorn.run('read_datas:app', host='0.0.0.0', port=10086, reload=True)
图片识别脚本 read_images.py
import os
from typing import List
from langchain.document_loaders.unstructured import UnstructuredFileLoader
from typing import TYPE_CHECKING
from langchain.chains import LLMChain
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
os.environ["OPENAI_API_KEY"] = '你的openaikey'
os.environ["OPENAI_API_BASE"] = "你的代理地址" # 直接用key的忽略这个代理设置
if TYPE_CHECKING:
try:
from rapidocr_paddle import RapidOCR
except ImportError:
from rapidocr_onnxruntime import RapidOCR
def get_ocr(use_cuda: bool = True) -> "RapidOCR":
try:
from rapidocr_paddle import RapidOCR
ocr = RapidOCR(det_use_cuda=use_cuda, cls_use_cuda=use_cuda, rec_use_cuda=use_cuda)
except ImportError:
from rapidocr_onnxruntime import RapidOCR
ocr = RapidOCR()
return ocr
class RapidOCRLoader(UnstructuredFileLoader):
def _get_elements(self) -> List:
def img2text(filepath):
resp = ""
ocr = get_ocr()
result, _ = ocr(filepath)
if result:
ocr_result = [line[1] for line in result]
resp += "\n".join(ocr_result)
return resp
text = img2text(self.file_path)
from unstructured.partition.text import partition_text
return partition_text(text=text, **self.unstructured_kwargs)
if __name__ == '__main__':
loader = RapidOCRLoader(file_path=r"demo1.jpg")
images = loader.load()
print(images)
利用streamlit 构建ui页面 ocr_ui.py
# -*- coding: utf-8 -*-
import streamlit as st
from PIL import Image
import requests
import json
from read_images import RapidOCRLoader
import sys
import os
# 获取当前文件所在目录的绝对路径 fastapi调用的时候,导包问题解决掉
current_dir = os.path.abspath(os.path.dirname(__file__))
parent_dir = os.path.abspath(os.path.join(current_dir, ".."))
ct_utils_path = os.path.abspath(os.path.join(parent_dir))
sys.path.append(ct_utils_path)
# 目录工程
parent_dir2 = os.path.abspath(os.path.join(current_dir, "../.."))
ct_utils_path2 = os.path.abspath(os.path.join(parent_dir2))
sys.path.append(ct_utils_path2)
# 后端处理函数
def process(message):
# 定义请求的URL和头部
url = 'http://localhost:10086/cotent'
headers = {'accept': 'application/json', 'Content-Type': 'application/json'}
# 定义请求的数据
data = {'content': message}
# 发送POST请求
response = requests.post(url, headers=headers, data=json.dumps(data))
# 如果请求成功,返回响应的内容
if response.status_code == 200:
return response.json()
else:
return "请求失败,状态码:" + str(response.status_code)
# 创建侧边栏
st.sidebar.title("识别方式选择")
option = st.sidebar.selectbox("请选择一个功能", ["文本识别", "图片上传识别"])
if option == "文本识别":
st.title("文本识别")
user_input = st.text_area("请输入你的消息", height=200)
confirm_button = st.button("确认")
if confirm_button:
response = process(user_input)
st.text_area("回复", value=response, height=200, max_chars=None, key=None)
elif option == "图片上传识别":
st.title("图片上传识别")
uploaded_file = st.file_uploader("上传你的图片", type=["png", "jpg", "jpeg"])
if uploaded_file is not None:
image = Image.open(uploaded_file)
# 创建一个文件对象
with open('uploaded_image.jpg', 'wb') as f:
# 将上传的文件的内容写入到新文件中
f.write(uploaded_file.getvalue())
path = './uploaded_image.jpg'
# 将文件路径传递给img2text函数
loader = RapidOCRLoader(file_path=path)
images = loader.load()
st.write('PIL GPU OCR 识别结果')
st.write(images)
# 发送给接口
response = process(images[0].page_content)
#展示图片
st.image(image, caption='模型识别结果')
# 展示模型结果
st.write('模型结构化识别结果')
st.write(response)
ocr_ui.py 目录下执行命令
python -m streamlit run ocr_ui.py

然后百度随便找个图片试试吧!














 176
176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









