







by:wenwenc9
如果本文有错误地方,欢迎指正。
01|LangChain | 从入门到实战-介绍
02|LangChain | 从入门到实战 -六大组件之Models IO
03|LangChain | 从入门到实战 -六大组件之Retrival
04|LangChain | 从入门到实战 -六大组件之Chain
一、简介
大多数法学硕士申请都有对话界面。对话的一个重要组成部分是能够引用对话中先前介绍的信息。至少,对话系统应该能够直接访问过去消息的某些窗口。更复杂的系统需要有一个不断更新的世界模型,这使得它能够执行诸如维护有关实体及其关系的信息之类的事情。
我们将这种存储过去交互信息的能力称为“记忆”。LangChain 提供了许多用于向系统添加内存的实用程序。这些实用程序可以单独使用,也可以无缝地合并到链中。
内存系统需要支持两个基本操作:读和写。
回想一下,每个链都定义了一些需要某些输入的核心执行逻辑。其中一些输入直接来自用户,但其中一些输入可以来自内存。在给定的运行中,一条链将与其内存系统交互两次。
- 在收到初始用户输入之后但在执行核心逻辑之前,链将从其内存系统中读取并增加用户输入。
- 在执行核心逻辑之后但在返回答案之前,链会将当前运行的输入和输出写入内存,以便在将来的运行中引用它们。
两个核心设计
- 如何读取 READ
- 如何写入 WRTIE
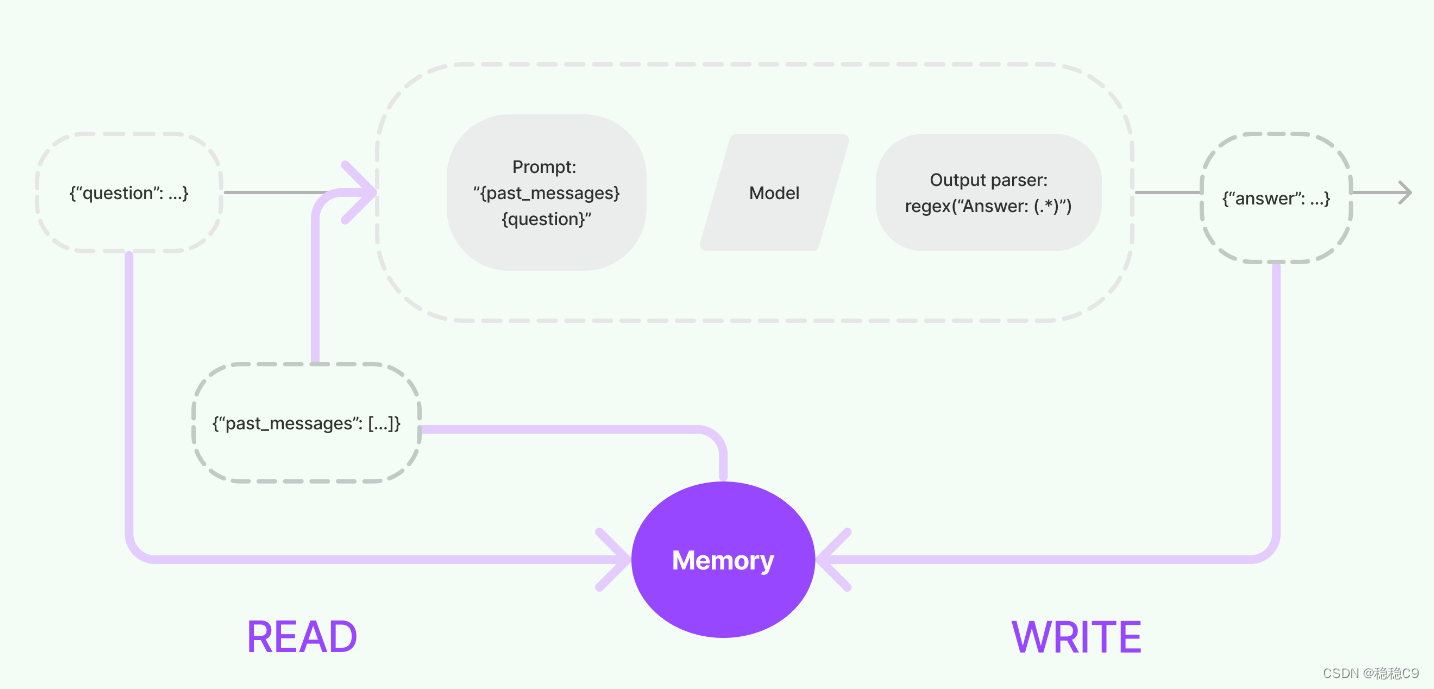
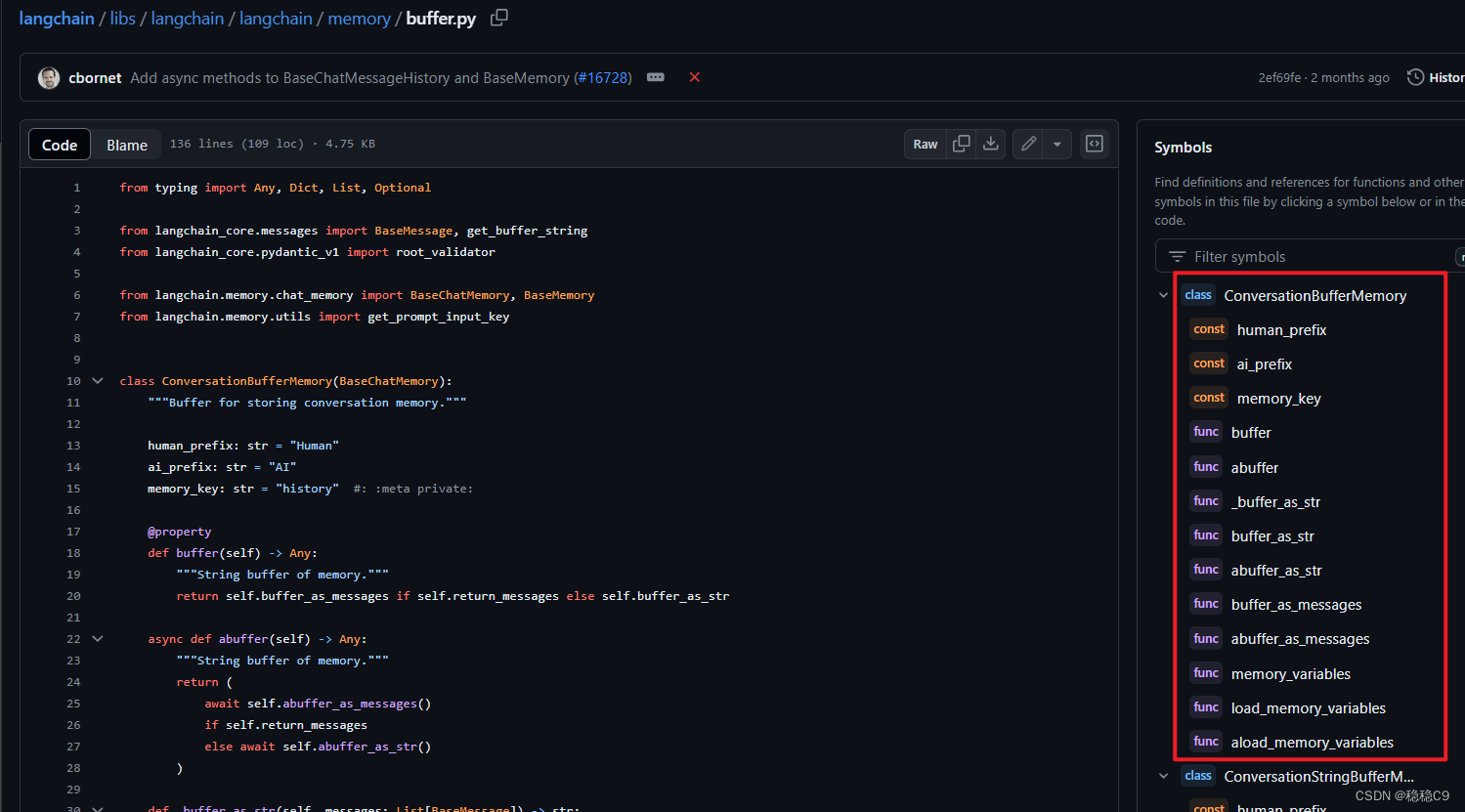
1、剖析 ConversationBufferMemory
利用 ConversationBufferMemory 实现会话缓存存储过程
看看这个类是怎么个组成的,继承调用方式,可能有点啰嗦,但是我想说的是,通过dir() 查看类函数的构成、继承、方法、参数 是一个不错的选择
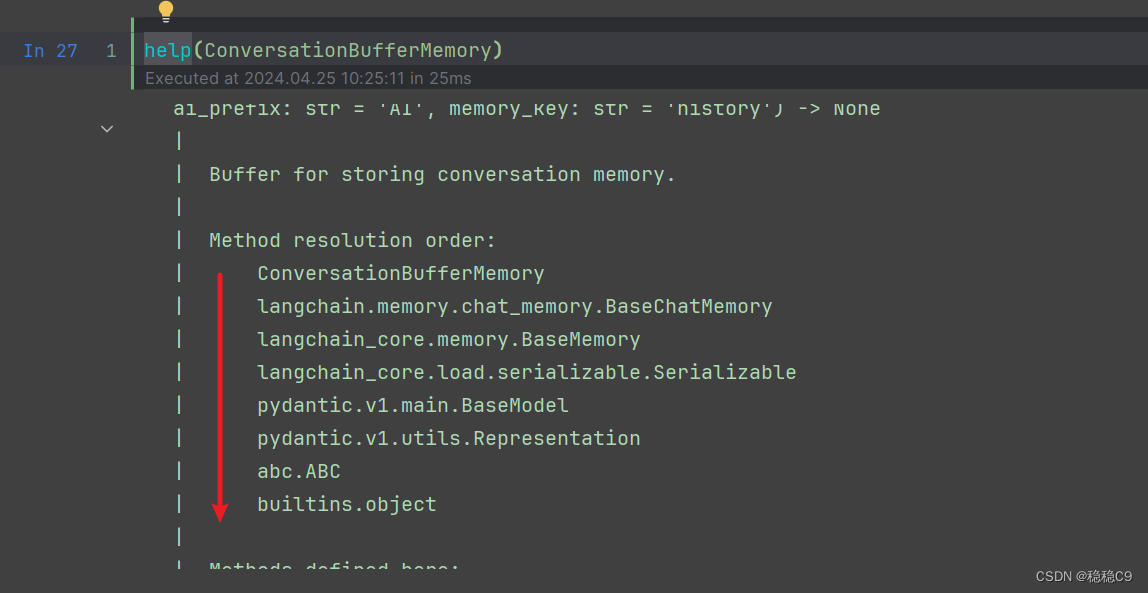
看看这个类方法有哪些参数,黄色部分为常用的
看看这个类本身有哪些方法,如果是继承的方法这里不看了,自己help()查看内容
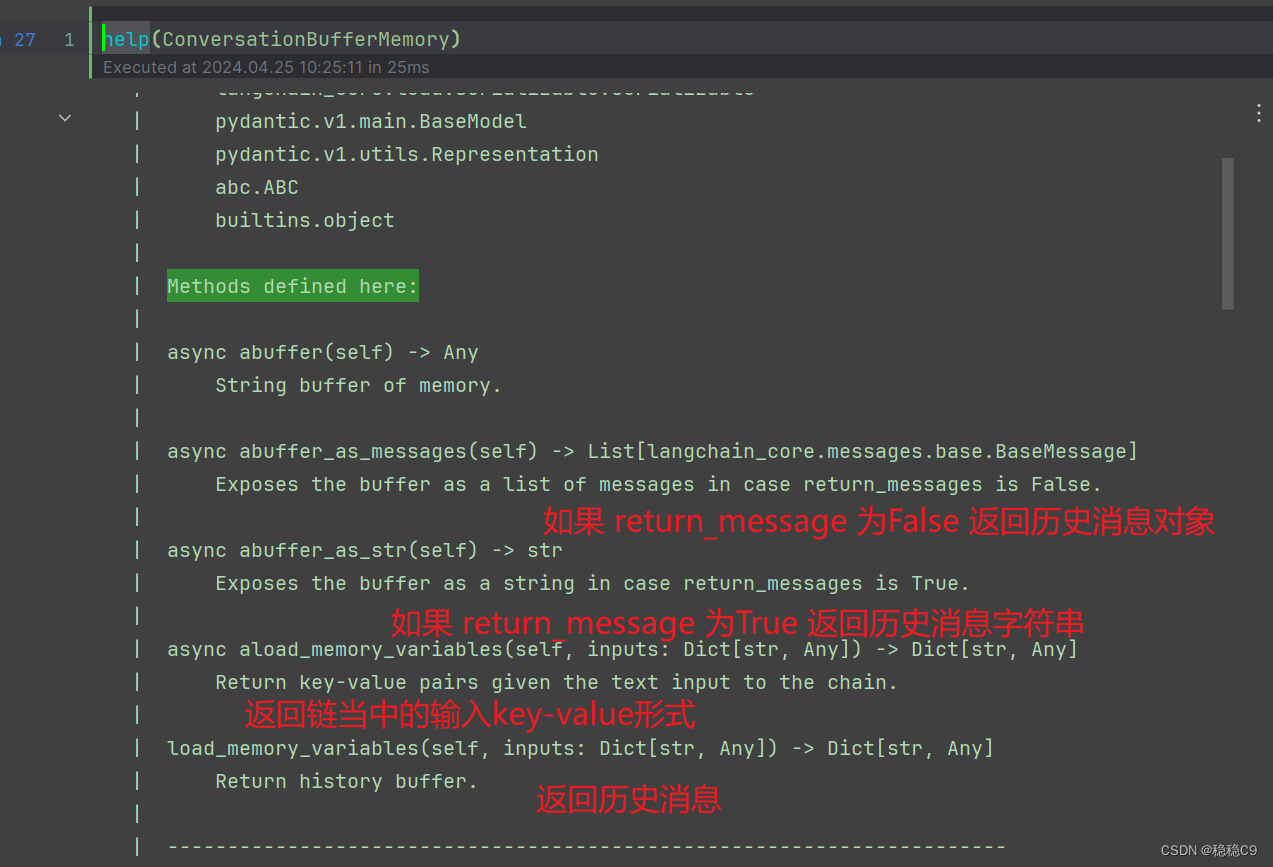
当然也可以自己打开源码链接,github上面查看也很方便
好了,现在用一些代码,看看怎么事
from langchain.memory import ConversationBufferMemory
# 构建会话内存
memory = ConversationBufferMemory()
# 添加用户对话内容
memory.chat_memory.add_user_message("你好!")
# 添加机器对话内容
memory.chat_memory.add_ai_message("你好,有什么需要帮助的吗?")
消息存储在memory中,进行查看
memory.load_memory_variables({})

默认的对话内容为history,也可以设置key
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key='chat_history')
# 添加用户对话内容
memory.chat_memory.add_user_message("你好!")
# 添加机器对话内容
memory.chat_memory.add_ai_message("你好,有什么需要帮助的吗?")
memory.load_memory_variables({})

默认返回的是字符串对象,也可以返回消息实体
memory = ConversationBufferMemory(return_messages=True)
# 添加用户对话内容
memory.chat_memory.add_user_message("你好!")
# 添加机器对话内容
memory.chat_memory.add_ai_message("你好,有什么需要帮助的吗?")
memory.load_memory_variables({})

2、使用ConverstaionBufferMemory
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = OpenAI(temperature=0)
template = """
你是一个会话机器人,能够记住上一次会话的内容
上一次会话内容:{chat_history}
新一次对话:{question}
你的回复:
"""
prompt = PromptTemplate.from_template(template)
memory = ConversationBufferMemory(memory_key='chat_history')
chain = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory,
)
# chain = prompt | llm | memory
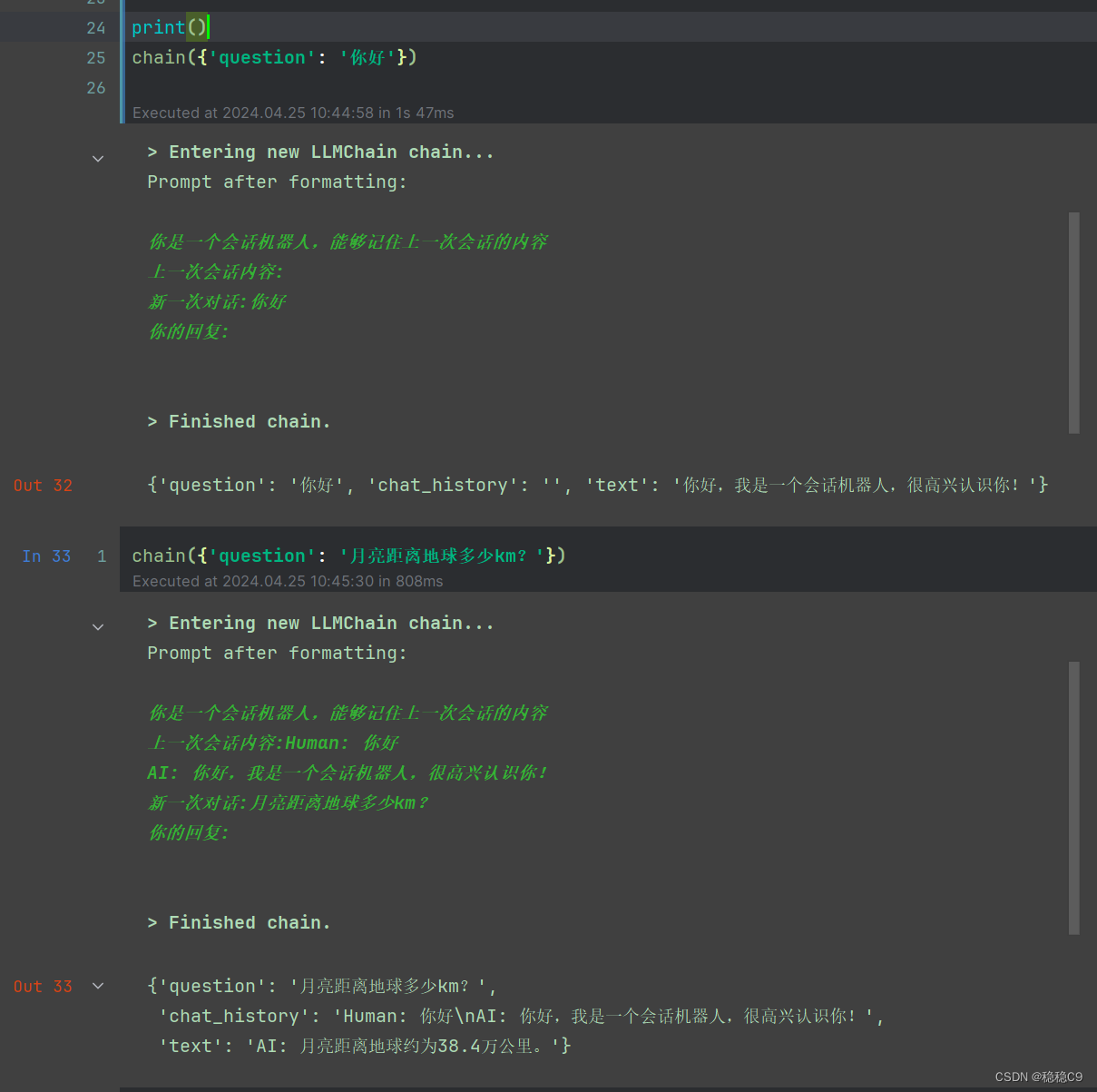
print()
chain({'question': '你好'})
from langchain.chat_models import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"你是一个会话机器人可以记录上一次对话内容."
),
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
conversation({'question': '你好'})
conversation({'question': 'python语言难吗'})
二、常用会话缓存
1、会话链 ConversationChain
-
记录会话历史。它会记录用户的每一轮输入,以便于后续回复。
-
根据会话历史回复。它会根据之前的输入来生成相应的回复,实现多轮对话。
-
实现会话状态跟踪。它可以跟踪会话的状态,根据状态来生成不同的回复。
-
实现会话转移。在多轮对话过程中,它可以根据需要转移会话主题。
-
实现会话结束。当满足某些条件时,它可以结束当前会话。
-
实现会话记忆。它可以记住会话中的一些重要信息,在后续会话中使用。
-
实现会话回环。它可以根据会话历史将会话引导回之前的主题。
总的来说,ConversationChain主要实现多轮对话的能力,包括会话状态跟踪、会话转移、会话记忆等功能。通过它可以构建出较为复杂的多轮对话系统。

from langchain.llms import OpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
llm = OpenAI(temperature=0)
chain = ConversationChain(
llm=llm,
verbose=True,
memory=ConversationBufferMemory() # 默认用的缓存就是这个
)
2、对话缓存窗口 ConversationBufferWindowMemory
1. 通过K值设置保留历史会话次数
from langchain.memory import ConversationBufferWindowMemory
# 这里设置K值为2,为2记忆两轮对话
memory = ConversationBufferWindowMemory(k=2)
memory.save_context({"input": "你好"}, {"output": "什么事?"})
memory.save_context({"input": "1+2等于几"}, {"output": "3"})
memory.load_memory_variables({})
2. 在会话链中使用
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferWindowMemory
conversation_with_summary = ConversationChain(
llm=OpenAI(temperature=0),
memory=ConversationBufferWindowMemory(k=2),
verbose=True
)
3、实体缓存 ConversationEntityMemory
ConversationEntityMemory的作用是用于存储和跟踪会话中的实体信息。
具体来说,它主要用于:
- 存储会话中的实体。在会话过程中,它会存储用户提到的各种实体,如人名、地名、组织名等。
- 跟踪实体状态。它会跟踪实体在不同轮次出现的状态,如第一次提及、第二次提及等。
- 提供实体信息。在生成回复时,它可以提供之前存储的实体信息。
- 更新实体信息。在新的一轮会话中,它可以根据用户的输入来更新实体信息。
- 删除实体信息。在会话结束时,它可以删除存储的实体信息。
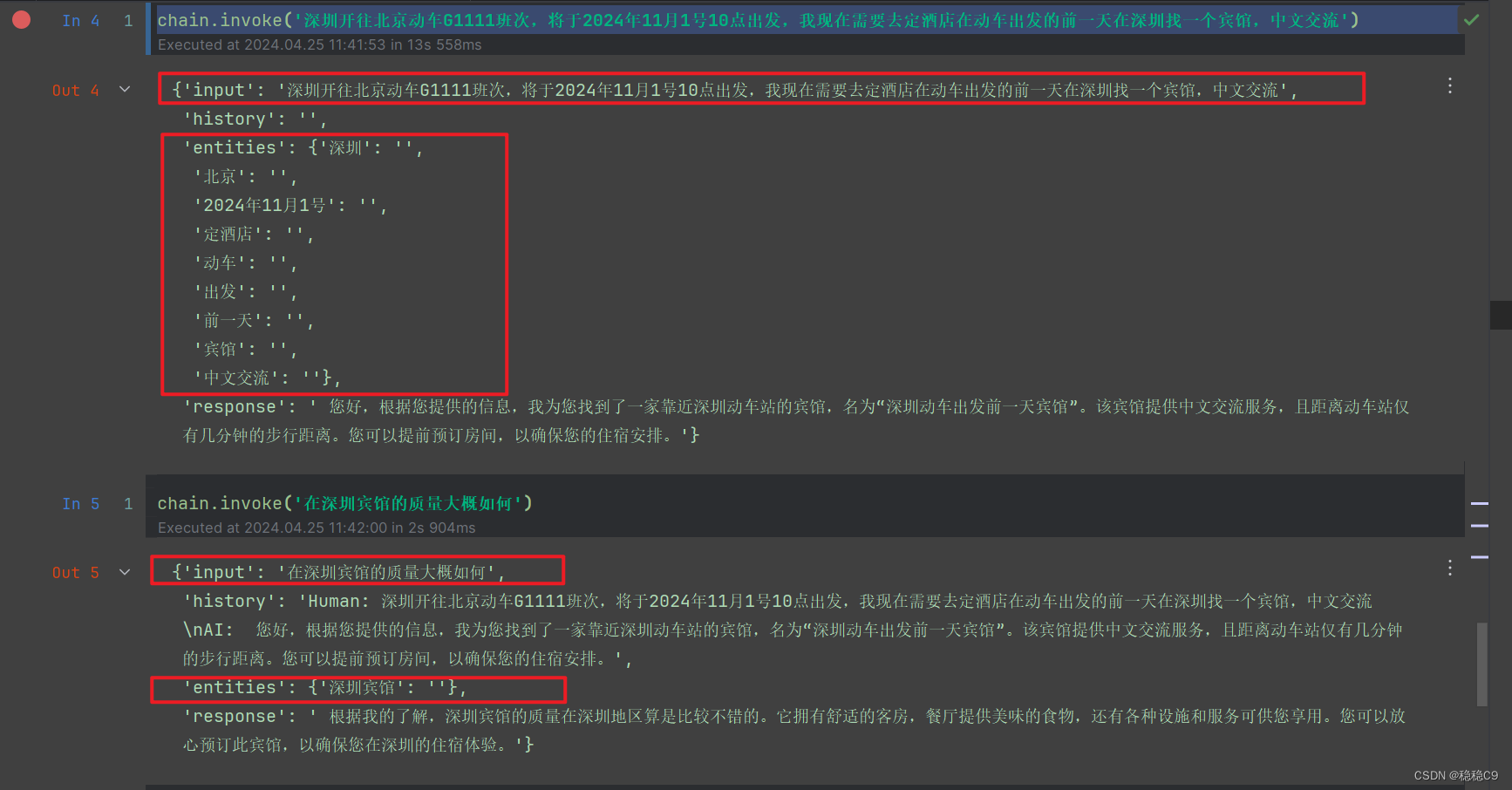
通过ConversationEntityMemory,我们可以实现会话中实体的存储、跟踪和使用。比如:
用户:你好,我是李四。
系统:你好,李四。
用户:张三是我的朋友。
系统:了解,张三是你的朋友。
系统就可以通过ConversationEntityMemory跟踪"李四"和"张三"这两个实体,在后续回复中使用。
总的来说,ConversationEntityMemory主要用于存储和跟踪会话中的实体信息,为多轮对话提供支持。
from langchain.llms import OpenAI
from langchain.memory import ConversationEntityMemory
llm = OpenAI(temperature=0)
memory = ConversationEntityMemory(llm=llm)
_input = {"input": "小明和小红是好朋友,正在一起看书"}
memory.load_memory_variables(_input)
# 将这段对话追加到前面缓存对话中
memory.save_context(
_input,
{"output": "听起来很棒,他们正在看什么书?"}
)
memory.load_memory_variables({'input':'小明是谁'})
看看结果

可以看到,将小明作为实体提取出来。
实体,能够帮助机器人,有效的进行重点记忆,也可以在后续chain当中,进
行相应的工程处理
再来看一个例子,这里是用了langchain提供的实体模版 ENTITY_MEMORY_CONVERSATION_TEMPLATE
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationEntityMemory
from langchain.memory.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE
llm = OpenAI()
memory = ConversationEntityMemory(llm=llm)
chain = ConversationChain(
llm=llm,
verbose=False,
prompt=ENTITY_MEMORY_CONVERSATION_TEMPLATE,
memory=memory
)
3、知识图对话实体 ConversationKGMemory
from langchain.memory import ConversationKGMemory
from langchain.llms import OpenAI
llm = OpenAI(temperature=0.5)
memory = ConversationKGMemory(llm=llm)
memory.save_context({"input": "你好小红"}, {"output": "谁是小红"})
memory.save_context({"input": "小红是我的朋友"}, {"output": "好的"})
memory.save_context({"input": "小红也是李刚的朋友"}, {"output": "好的"})
memory.load_memory_variables({'input':'小红的关系'})

1. 进行实体抽取
2.获取三元关系
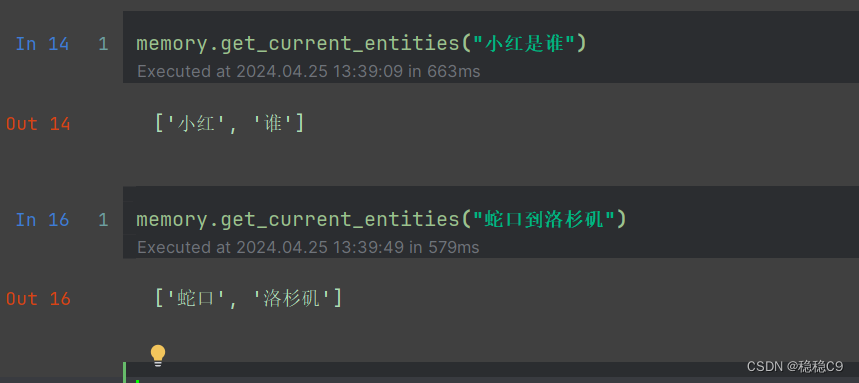
memory.get_knowledge_triplets("他最喜欢的颜色是红色")
Out[7]: [KnowledgeTriple(subject='小红', predicate='最喜欢的颜色是', object_='红色')]
memory.get_knowledge_triplets("蛇口到洛杉矶船期")
Out[8]:
[KnowledgeTriple(subject='蛇口', predicate='到', object_='洛杉矶'),
KnowledgeTriple(subject='船期', predicate='来自', object_='蛇口')]
3. 完整使用
from langchain.llms import OpenAI
from langchain.memory import ConversationKGMemory
from langchain.prompts.prompt import PromptTemplate
from langchain.chains import ConversationChain
llm = OpenAI(temperature=0)
template = """
以下是一段人类与人工智能之间的友好对话。 人工智能很健谈,并根据上下文提供了许多具体细节。
如果人工智能不知道问题的答案,它就会如实说它不知道。 人工智能仅使用"Relevant Information"部分中包含的信息,不会产生幻觉。
Relevant Information:
{history}
对话:
Human: {input}
AI:"""
prompt = PromptTemplate(input_variables=["history", "input"], template=template)
conversation_with_kg = ConversationChain(
llm=llm, verbose=False, prompt=prompt, memory=ConversationKGMemory(llm=llm)
)
conversation_with_kg.predict(input="你好?")
4、会话缓存摘要 ConversationSummaryMemory
现在让我们看一下使用稍微复杂一点的内存类型 - ConversationSummaryMemory。
这种类型的记忆会随着时间的推移创建对话的摘要。
这对于随着时间的推移压缩对话中的信息非常有用。
对话摘要内存对发生的对话进行总结,并将当前摘要存储在内存中。
然后可以使用该内存将迄今为止的对话摘要注入提示/链中。
此内存对于较长的对话最有用,因为在提示中逐字保留过去的消息历史记录会占用太多令牌。
1. 基本使用
from langchain.memory import ConversationSummaryMemory
from langchain.chains import ConversationChain
from langchain.llms import OpenAI
memory = ConversationSummaryMemory(llm=OpenAI(temperature=0))
memory.save_context({"input": "你好"}, {"output": "什么事"})
chain = ConversationChain(
llm=OpenAI(temperature=0),
memory=memory
)
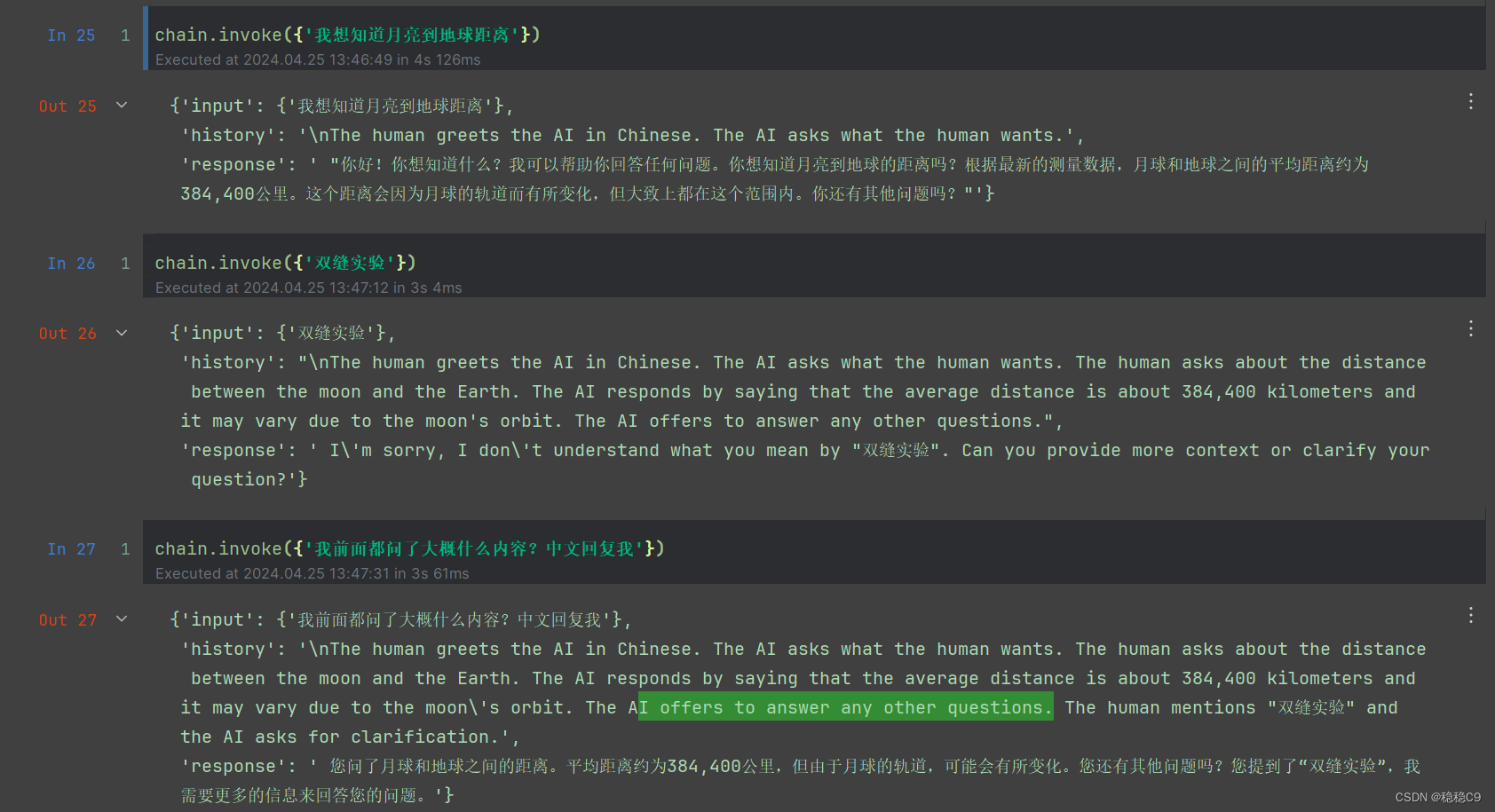
可以看到如下,进行了摘要总结
2. 加载已经存在的对话内容或摘要
from langchain.memory import ConversationSummaryMemory, ChatMessageHistory
from langchain.llms import OpenAI
# 对话内容
history = ChatMessageHistory()
history.add_user_message("你好")
history.add_ai_message("你好,有什么需要帮助的吗")
# 缓存内容(摘要)
memory = ConversationSummaryMemory.from_messages(
llm=OpenAI(temperature=0),
chat_memory=history,
return_messages=True
)
可以使用先前的摘要来加速初始化,并避免通过直接初始化来重新生成摘要。
memory = ConversationSummaryMemory(
llm=OpenAI(temperature=0),
buffer="The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good because it will help humans reach their full potential.",
chat_memory=history,
return_messages=True
)
5、会话缓存摘要 ConversationSummaryBufferMemory
ConversationSummaryBufferMemory结合了这两种想法(ConversationSummaryMemory和ConversationBufferWindowMemory的混合体)。它在内存中保留最近交互的缓冲区,但不仅仅是完全刷新旧的交互,而是将它们编译成摘要并使用两者。它使用令牌长度而不是交互次数来确定何时刷新交互。
可以看到两个名称非常相似
ConversationSummaryMemory
ConversationSummaryBufferMemory
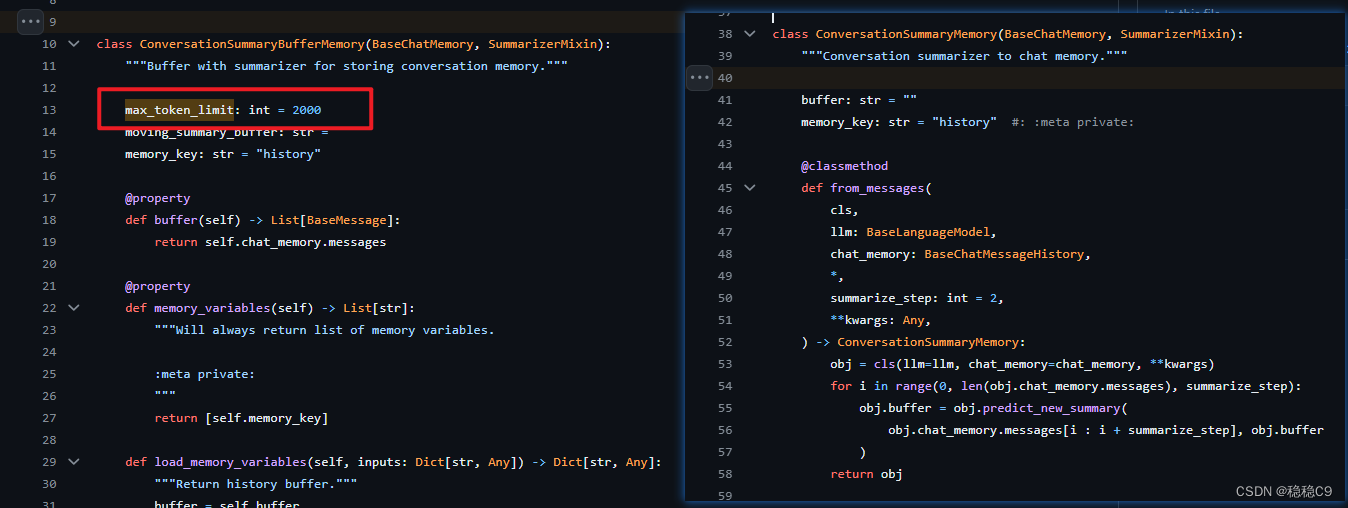
看看两个源码
ConversationSummaryMemory
ConversationSummaryBufferMemory
相对于这个,多出了一个token摘要限定
from langchain.memory import ConversationSummaryBufferMemory
from langchain.chains import ConversationChain
from langchain.llms import OpenAI
llm = OpenAI()
conversation_with_summary = ConversationChain(
llm=llm,
# 测试的目的,设置一个非常低的token限制
memory=ConversationSummaryBufferMemory(llm=OpenAI(), max_token_limit=40, language='zh'),
verbose=True,
)
conversation_with_summary.predict(input="你好")
conversation_with_summary.predict(input="我正在写一些文档笔记")
6、Token缓存 ConversationTokenBufferMemory
保存最近交互的缓冲区, 内存,并使用令牌长度而不是交互次数来 确定何时刷新交互
from langchain.memory import ConversationSummaryBufferMemory
from langchain.chains import ConversationChain
from langchain.llms import OpenAI
llm = OpenAI()
memory = ConversationSummaryBufferMemory(llm=OpenAI(), max_token_limit=10, language='zh')
memory.clear()
conversation_with_summary = ConversationChain(
llm=llm,
# 测试的目的,设置一个非常低的token限制
memory=memory,
verbose=True,
)
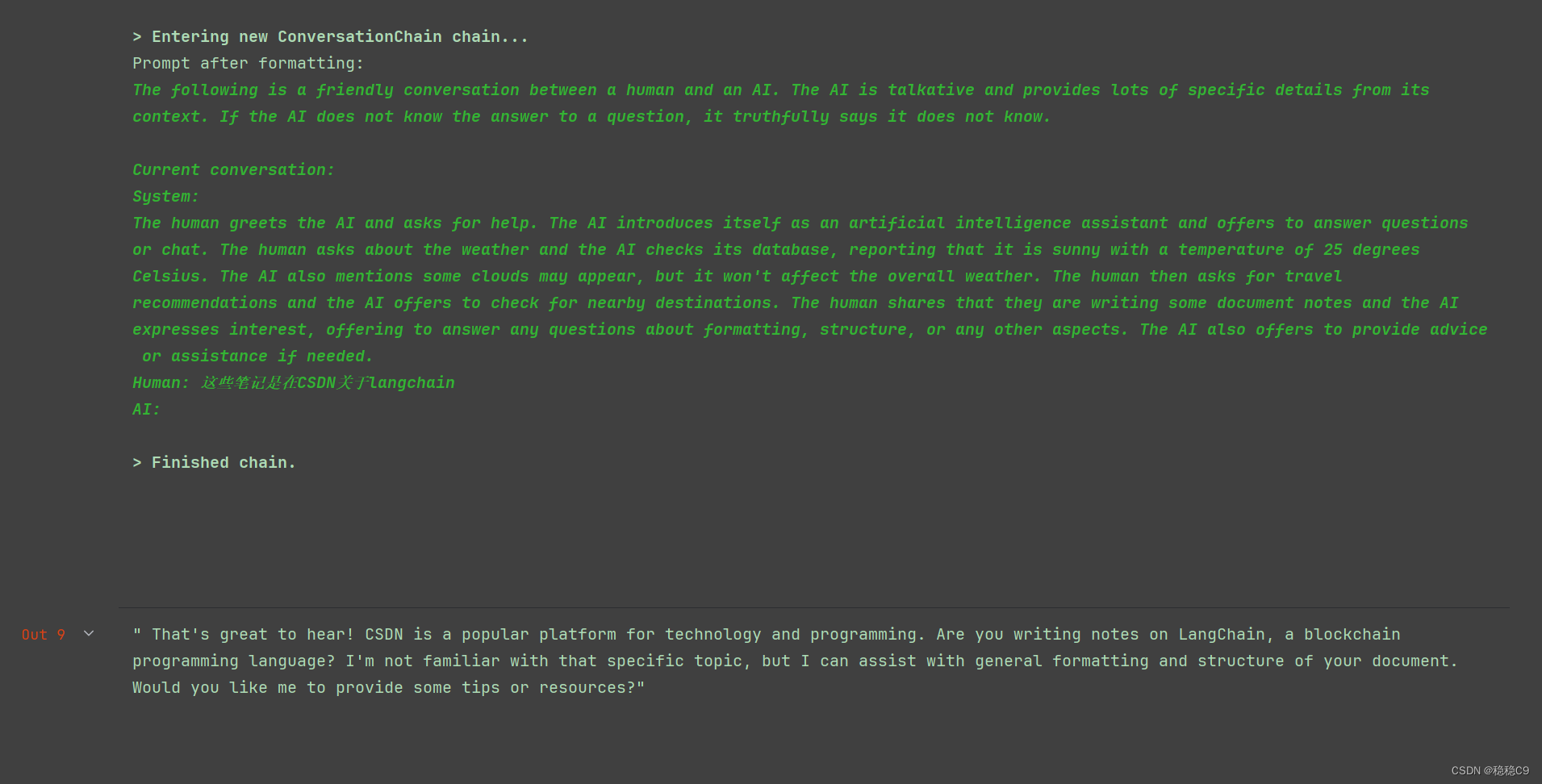
conversation_with_summary.predict(input="你好")
conversation_with_summary.predict(input="我正在写一些文档笔记")
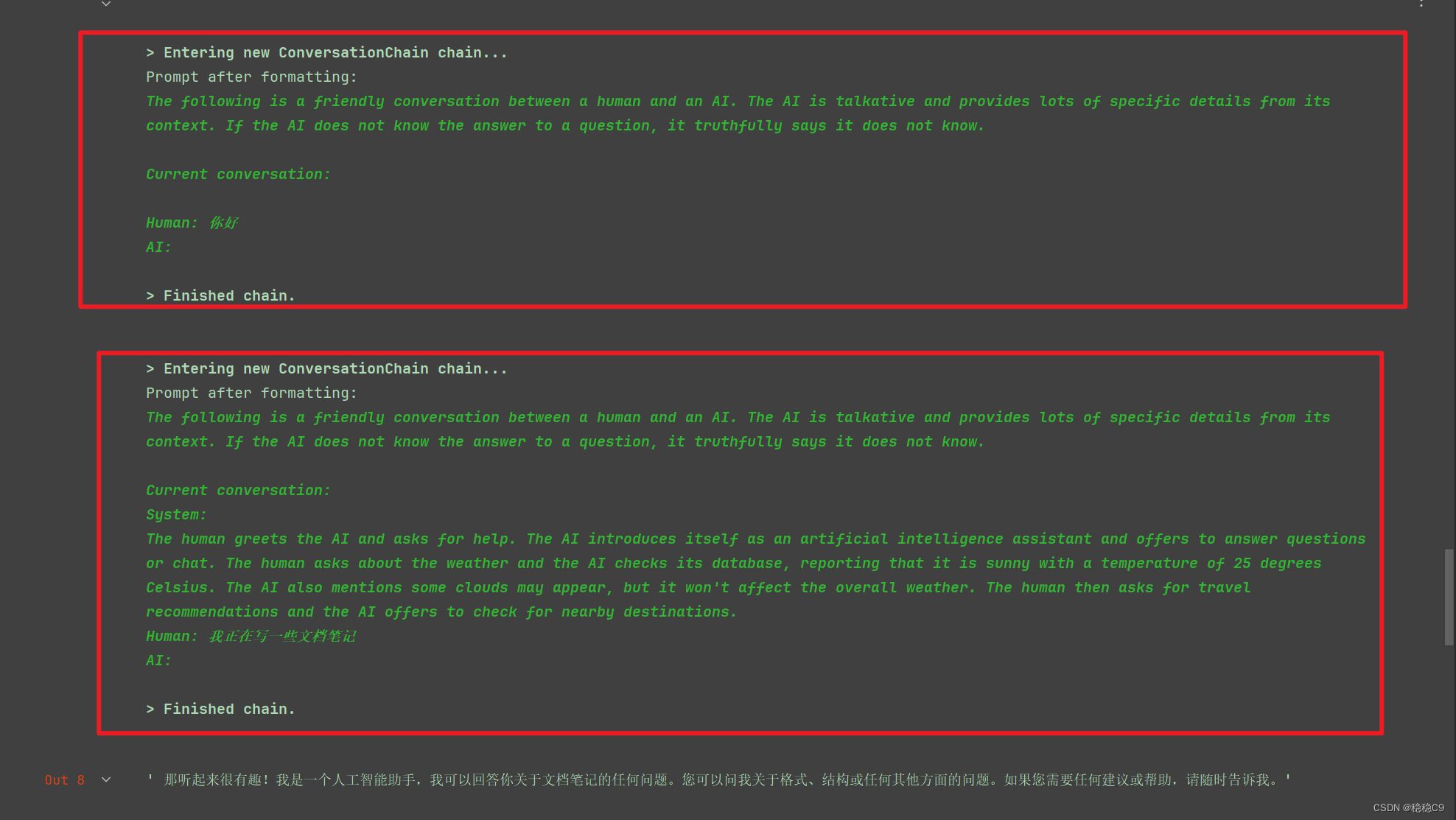
因为设置了是10,然后我们再来看看效果
7、量数据库缓存会话 VectorStoreRetrieverMemory
在前面的过程当中都是,在内存缓存中操作
VectorStoreRetrieverMemory将内存存储在向量存储中,并在每次调用时查询前 K 个最“显着”的文档。
这与大多数其他 Memory 类不同,因为它不显式跟踪交互的顺序。
在这种情况下,“文档”是以前的对话片段。这对于参考人工智能在对话之前被告知的相关信息很有用。
安装faiss
pip install -U langchain-community faiss-cpu langchain-openai tiktoken
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.memory import VectorStoreRetrieverMemory
import faiss
from langchain.docstore import InMemoryDocstore
from langchain.vectorstores import FAISS
# 创建一个空的向量数据库
embedding_size = 1536 # embeddings的维度
index = faiss.IndexFlatL2(embedding_size)
embedding_fn = OpenAIEmbeddings().embed_query
vectorstore = FAISS(embedding_fn, index, InMemoryDocstore({}), {})
# 构建查询器
retriever = vectorstore.as_retriever(search_kwargs=dict(k=1))
memory = VectorStoreRetrieverMemory(retriever=retriever)
# 存储一些内容
memory.save_context({"input": "我最喜欢的运动就是骑车"}, {"output": "这非常棒"})
memory.save_context({"input": "我最喜欢的水果是苹果"}, {"output": "我也是"})
memory.save_context({"input": "我不喜欢榴莲"}, {"output": "明白"})
memory.load_memory_variables({"prompt": "我喜欢什么运动?"})

在链中使用
from langchain.chains import ConversationChain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.memory import VectorStoreRetrieverMemory
import faiss
from langchain.docstore import InMemoryDocstore
from langchain.vectorstores import FAISS
# 创建一个空的向量数据库
embedding_size = 1536 # embeddings的维度
index = faiss.IndexFlatL2(embedding_size)
embedding_fn = OpenAIEmbeddings().embed_query
vectorstore = FAISS(embedding_fn, index, InMemoryDocstore({}), {})
# 构建查询器
retriever = vectorstore.as_retriever(search_kwargs=dict(k=1))
memory = VectorStoreRetrieverMemory(retriever=retriever)
# 构建模型
llm = OpenAI(temperature=0) # Can be any valid LLM
# 构建模版
_DEFAULT_TEMPLATE = """以下是一段人类与人工智能之间的友好对话。 人工智能很健谈,并根据上下文提供了许多具体细节。 如果人工智能不知道问题的答案,它就会如实说它不知道。.
之前对话的相关片段:
{history}
(如果不相关,则无需使用这些信息)
当前对话:
Human: {input}
AI:"""
PROMPT = PromptTemplate(
input_variables=["history", "input"], template=_DEFAULT_TEMPLATE
)
conversation_with_summary = ConversationChain(
llm=llm,
prompt=PROMPT,
memory=memory,
verbose=True
)
conversation_with_summary.predict(input="你好,我是稳稳!")














 872
872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









