






👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

【python】python新闻数据抓取情感分析可视化(源码+数据)【独一无二】
一、设计目的
实现一个用于从特定新闻网站获取新闻内容,然后对新闻内容进行情感分析和词频统计,并生成词云图,以便了解新闻的情感倾向和主题关键词。
- 获取新闻内容:通过使用
requests库抓取特定新闻页面的内容。
- 本地文件操作:将获取的新闻内容保存到本地文件,以备后续处理。
-
数据清洗:对获取的新闻内容进行简单的清洗,去除空格和换行符等干扰信息。
-
中文分词及词频统计:利用jieba分词库对新闻内容进行分词,并统计每个词出现的频率,以便了解新闻的主题关键词。
-
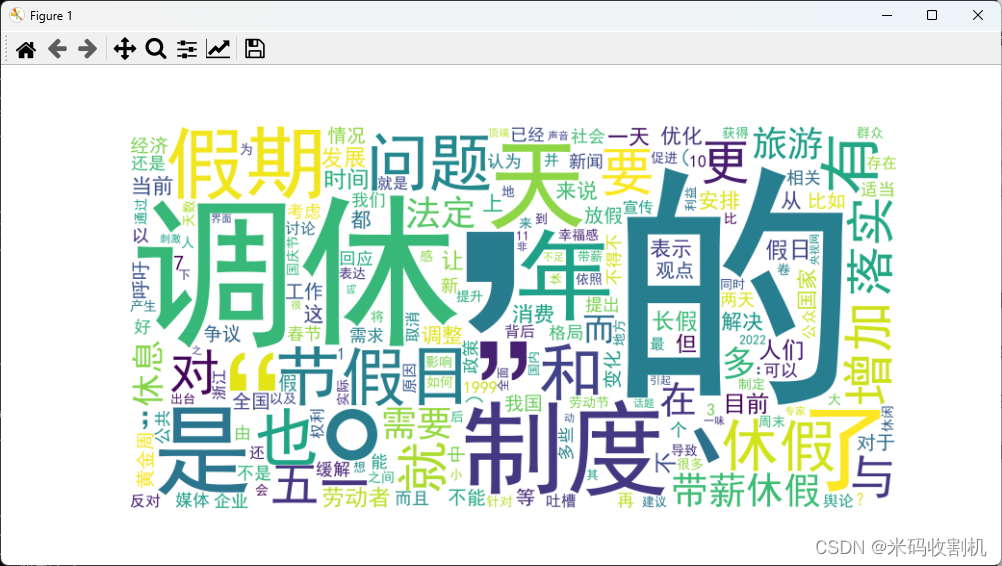
生成词云:根据词频统计结果生成词云图,直观展示新闻内容中的关键词。
-
情感分析:利用 SnowNLP 库对新闻内容进行情感分析,得出新闻的情感倾向,以便了解新闻对于产品或品牌的积极性或消极性。
二、功能展示
2.1 词频展示
词频:这些词语是在新闻内容中出现频率词汇,给出了每个词出现的次数。
关键字:原 次数:1
关键字:标题 次数:1
关键字:: 次数:5
关键字:争议 次数:5
关键字:“ 次数:34
关键字:五一 次数:10
关键字:调休 次数:61
关键字:” 次数:34
关键字:背后 次数:3
关键字:真 次数:1
关键字:问题 次数:13
关键字:亟需 次数:1
关键字:解决 次数:6
关键字: 次数:2
关键字:节假日 次数:14
关键字:还 次数:3
关键字:能 次数:4
关键字:增加 次数:11
关键字:吗 次数:2
关键字:? 次数:4
关键字:【 次数:1
关键字:本文 次数:1
关键字:资料 次数:1
关键字:来源于 次数:1
关键字:央视网 次数:2
关键字:、 次数:28
关键字:浙江 次数:3
关键字:宣传 次数:3
关键字:顶端 次数:2
关键字:新闻 次数:4
关键字:界面 次数:2
关键字:等 次数:5
关键字:】 次数:1
关键字:近些年 次数:1
关键字:, 次数:208
关键字:一直 次数:1
关键字:处在 次数:1
关键字:舆论 次数:3
关键字:的 次数:117
关键字:风口浪尖 次数:1
关键字:而 次数:7
关键字:今年 次数:1
关键字:关于 次数:1
关键字:讨论 次数:3
关键字:尤为 次数:1
关键字:热烈 次数:1
关键字:。 次数:76
关键字:其实 次数:1
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新分 ” 获取。👈👈👈
2.2 词云展示
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新分 ” 获取。👈👈👈
2.2 分析结果
情感得分:这是针对整个新闻内容进行的情感分析,得到的一个分数,用来表明新闻内容的整体情感倾向。
Sentiment score: 1.0
三、代码分析
好的,下面我将对每个实现思路进行说明,并附上对应的代码块:
- 获取新闻内容:
def get_news():
# 略.... > 👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新分 ” 获取。👈👈👈
with open('news.txt', 'w', encoding='utf-8') as f:
f.write(text)
f.close()
if __name__ == "__main__":
get_news()
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新分 ” 获取。👈👈👈
- 解析网页:
# 解析网页部分已经包含在获取新闻内容的代码块中
# 使用了requests库发送HTTP请求获取网页内容
- 保存到本地文件:
# 保存到本地文件的代码块
# 将提取的新闻内容保存到本地文件"news.txt"
with open('news.txt', 'w', encoding='utf-8') as f:
f.write(text)
f.close()
- 数据清洗:
# 数据清洗的函数
def clean_text(text):
# 略.... > 👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新分 ” 获取。👈👈👈
# 在主函数中调用数据清洗函数
text = clean_text(text)
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新分 ” 获取。👈👈👈
- 中文分词及词频统计:
# 中文分词及词频统计的函数
def get_word_frequency(text):
# 略.... > 👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新分 ” 获取。👈👈👈
return counter
frequencies = get_word_frequency(text)
- 生成词云:
# 生成词云的函数
def create_wordcloud(frequencies):
# 略.... > 👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新分 ” 获取。👈👈👈
# 略....
plt.axis("off")
plt.show()
create_wordcloud(frequencies)
- 情感分析:
# 情感分析的函数
def sentiment_analysis(text):
s = SnowNLP(text)
return s.sentiments
# 在主函数中调用情感分析函数
sentiment = sentiment_analysis(text)
print(f'Sentiment score: {sentiment}')
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新分 ” 获取。👈👈👈


















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











