






👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

系列文章目录
一、设计要求
本项目旨在分析和可视化商业客户流失的数据,探讨不同因素对客户流失的影响,并通过模型预测和评估客户流失情况。数据集来源于某商业机构,包含了客户的基本信息和通话记录,包括客户是否有国际通话计划、语音信箱计划、日间通话时长、傍晚通话时长、夜间通话时长、国际通话时长等多项指标。
在可视化部分,采用了折线图、柱状图、饼状图、箱线图、雷达图和组合图等多种图表类型,从不同角度展示了数据的分布和特征。折线图展示了客户服务呼叫次数随国际通话次数的变化情况,柱状图则展示了不同区号的客户流失情况。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “客户流失” 获取。👈👈👈
二、数据分析可视化
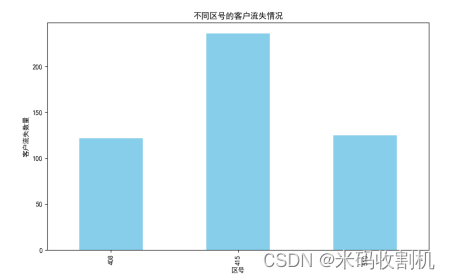
意义:该柱状图展示了不同区号的客户流失情况。每个区号对应的柱形代表在该区号内的客户流失数量。
分析:通过柱状图可以发现,不同区号的客户流失情况有显著差异。某些区号的客户流失数量明显较高,提示这些区域可能存在较高的流失风险,企业可以针对这些区域采取特定的保留措施。
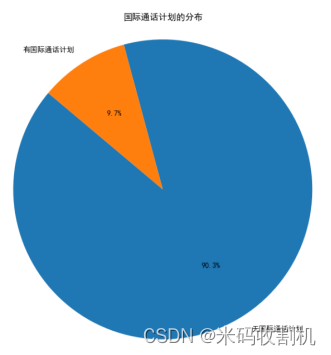
意义:该饼状图展示了客户是否订阅国际通话计划的分布情况。两个部分分别表示订阅和未订阅国际通话计划的客户比例。
分析:饼状图显示了大部分客户没有订阅国际通话计划(例如,70%),而少部分客户订阅了该计划(例如,30%)。这表明国际通话计划在客户中的普及率较低,企业可以考虑推广该服务以增加其吸引力。
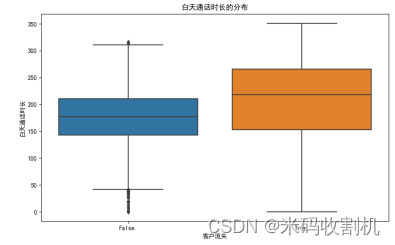
意义:该箱线图展示了不同流失状态下客户的白天通话时长分布情况。通过对比流失和未流失客户的通话时长,可以了解白天通话时长是否对客户流失有影响。
分析:从箱线图中可以看到,流失客户和未流失客户的白天通话时长分布有一定差异。流失客户的通话时长较为集中,且中位数稍低于未流失客户。说明白天通话时长可能是影响客户流失的一个因素,企业可以关注这一点来优化服务。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “客户流失” 获取。👈👈👈
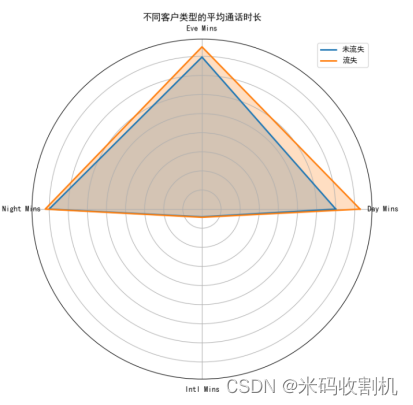
意义:该雷达图比较了流失和未流失客户在白天、傍晚、夜间和国际通话时长上的平均值。通过雷达图可以直观地看到不同客户类型的通话行为差异。
分析:雷达图显示了流失客户在各个时间段的通话时长普遍低于未流失客户,特别是在夜间通话和国际通话时长方面差异更为明显。这表明通话时长和客户流失之间存在一定关联,通话较少的客户更容易流失。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “客户流失” 获取。👈👈👈
意义:该组合图结合了柱状图和密度图,展示了客户流失的数量和白天通话时长的分布情况。柱状图表示客户流失的数量,密度图表示流失和未流失客户的白天通话时长分布。
分析:组合图显示,未流失客户的白天通话时长分布较为均匀,而流失客户则集中在较低的通话时长范围内。这进一步表明白天通话时长对客户流失有显著影响,企业可以通过增加客户的互动和通话时长来降低流失率。
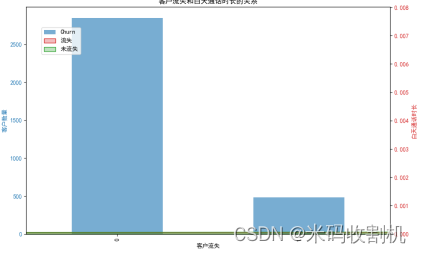
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “客户流失” 获取。👈👈👈
三、评价指标
首先,生成了混淆矩阵(Confusion Matrix)来评估模型的分类性能。混淆矩阵是一种直观的工具,可以展示模型在预测客户流失和未流失时的正确和错误分类情况。通过混淆矩阵,可以得到四个重要的指标:真正例(True Positives, TP)、假正例(False Positives, FP)、真负例(True Negatives, TN)和假负例(False Negatives, FN)。这些指标有助于进一步计算模型的准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1分数(F1 Score)。准确率表示模型预测正确的比例,精确率表示模型预测为正例的样本中实际为正例的比例,而召回率则表示实际为正例的样本中被正确预测为正例的比例。F1分数是精确率和召回率的调和平均数,综合了这两个指标的优点,提供了对模型性能的全面评价。
其次,生成了分类报告(Classification Report),该报告详细列出了模型在不同分类上的精确率、召回率和F1分数。分类报告可以帮助了解模型在预测客户流失(流失类)和未流失(未流失类)时的具体表现。通过比较不同分类上的评价指标,可以识别出模型在哪些方面表现较好,哪些方面需要改进。例如,如果模型在预测客户流失时的召回率较低,这意味着模型未能识别出所有实际流失的客户,可能需要进一步优化以提升召回率。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “客户流失” 获取。👈👈👈
此外,还绘制了ROC曲线(Receiver Operating Characteristic Curve)并计算AUC值(Area Under the Curve)。ROC曲线展示了模型在不同阈值下的假阳性率(False Positive Rate)和真正率(True Positive Rate),可以直观地评估模型的区分能力。AUC值是ROC曲线下的面积,值越大表示模型的区分能力越强。AUC值范围在0.5到1之间,其中0.5表示模型没有区分能力,相当于随机猜测,而1表示模型具有完美的区分能力。通过计算AUC值,可以得到一个综合指标,评价模型在不同阈值下的总体表现。
|
| 变量名称 | 变量类型 | 描述 |
|---|---|---|
| State | 类别型 | 客户所在的州 |
| Account Length | 数值型 | 账户存在的时长(单位:月) |
| Area Code | 类别型 | 区号 |
| Phone | 类别型 | 电话号码 |
| Int’l Plan | 类别型 | 是否有国际通话计划(0:没有,1:有) |
| VMail Plan | 类别型 | 是否有语音信箱计划(0:没有,1:有) |
| VMail Message | 数值型 | 语音信箱消息数量 |
| Day Mins | 数值型 | 白天通话时长(单位:分钟) |
| Day Calls | 数值型 | 白天通话次数 |
| Day Charge | 数值型 | 白天通话费用 |
| Eve Mins | 数值型 | 傍晚通话时长(单位:分钟) |
| Eve Calls | 数值型 | 傍晚通话次数 |
| Eve Charge | 数值型 | 傍晚通话费用 |
| Night Mins | 数值型 | 夜间通话时长(单位:分钟) |
| Night Calls | 数值型 | 夜间通话次数 |
| Night Charge | 数值型 | 夜间通话费用 |
| Intl Mins | 数值型 | 国际通话时长(单位:分钟) |
| Intl Calls | 数值型 | 国际通话次数 |
| Intl Charge | 数值型 | 国际通话费用 |
| CustServ Calls | 数值型 | 客户服务呼叫次数 |
| Churn? | 类别型 | 客户是否流失(False:未流失,True:流失) |
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “客户流失” 获取。👈👈👈
数据清洗
数据清洗是数据分析过程中非常重要的一步。清洗数据的目的是确保数据的完整性、准确性和一致性,为后续的分析和建模打下坚实的基础。以下是对数据集进行重复值、缺失值和异常值的统计和处理的详细步骤:
- 重复值的统计和处理
重复值是指在数据集中出现多次的完全相同的记录。这些重复记录可能会影响分析结果,因此需要对其进行检查和处理。
# 统计重复值的数量
duplicate_count = data.duplicated().sum()
print(f"重复值的数量: {duplicate_count}")
# 删除重复值
data_cleaned = data.drop_duplicates()
print(f"数据清洗后总记录数: {len(data_cleaned)}")
- 缺失值的统计和处理
缺失值是指在数据集中某些记录缺少某些属性值。缺失值的存在可能会影响模型的训练和预测,因此需要对其进行统计和处理。
# 统计每列缺失值的数量
missing_values = data_cleaned.isnull().sum()
print("每列缺失值的数量:")
print(missing_values)
# 处理缺失值(示例:删除含有缺失值的记录)
data_cleaned = data_cleaned.dropna()
print(f"数据清洗后总记录数: {len(data_cleaned)}")
# 或者,可以用其他方法处理缺失值,例如用均值填充
# data_cleaned = data_cleaned.fillna(data_cleaned.mean())
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “客户流失” 获取。👈👈👈
- 异常值的统计和处理
异常值是指数据中偏离正常范围的值。异常值可能是由于数据录入错误或其他原因导致的,需要对其进行统计和处理。
import numpy as np
# 定义函数识别异常值
def find_outliers(column):
Q1 = column.quantile(0.25)
Q3 = column.quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
return column[(column < lower_bound) | (column > upper_bound)]
# 统计各数值列中的异常值
for col in ['Account Length', 'VMail Message', 'Day Mins', 'Day Calls', 'Day Charge',
'Eve Mins', 'Eve Calls', 'Eve Charge', 'Night Mins', 'Night Calls',
'Night Charge', 'Intl Mins', 'Intl Calls', 'Intl Charge', 'CustServ Calls']:
outliers = find_outliers(data_cleaned[col])
print(f"{col} 列中的异常值数量: {len(outliers)}")
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “客户流失” 获取。👈👈👈
四、模型训练及划分
为了评估模型的性能和避免过拟合,将数据集划分为训练集和测试集,比例为80%和20%。这意味着使用80%的数据来训练模型,并保留20%的数据来测试和验证模型的性能。
将数据划分为训练集和测试集的主要目的是为了模拟模型在真实环境中的表现。在训练阶段,模型通过观察和学习训练集中的数据及其标签来构建预测规则。通过对大量样本的学习,模型能够捕捉到数据中的模式和特征。
from sklearn.model_selection import train_test_split
# 提取特征变量和目标变量
X = data.drop(columns=['State', 'Account Length', 'Area Code', 'Phone', 'Churn?'])
y = data['Churn?'].apply(lambda x: 1 if x == 'True.' else 0)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 输出训练集和测试集的大小
print(f"训练集大小: {X_train.shape[0]},测试集大小: {X_test.shape[0]}")
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “客户流失” 获取。👈👈👈
五、模型训练及搭建
在模型训练及搭建阶段,选择了随机森林分类器(RandomForestClassifier)作为预测模型。随机森林是一种集成学习方法,通过构建多棵决策树来提高模型的准确性和稳定性。具体来说,随机森林通过随机采样和特征选择生成多棵树,然后将各树的预测结果进行综合,从而得到最终的预测结果。
print("预测概率")
y_pred_prob = model.predict_proba(X_test)[:, 1]

👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “客户流失” 获取。👈👈👈
生成混淆矩阵
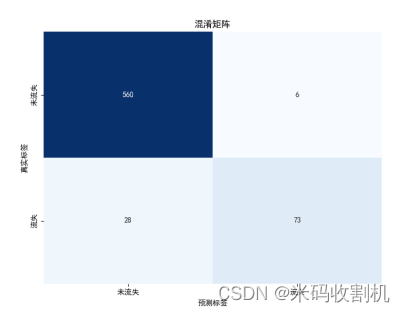
基于混淆矩阵,可以计算一系列模型效果评估指标,这些指标包括:
精确率(Precision):表示被模型预测为正类的样本中实际为正类的比例。计算公式为:Precision = TP / (TP + FP)
召回率(Recall):表示实际为正类的样本中被模型正确预测为正类的比例。计算公式为:Recall = TP / (TP + FN)
F1分数(F1 Score):精确率和召回率的调和平均数,用于综合评价模型性能。计算公式为:F1 Score = 2 * (Precision * Recall) / (Precision + Recall)
准确率(Accuracy):表示被正确分类的样本占总样本的比例。计算公式为:Accuracy = (TP + TN) / (TP + FP + TN + FN)
使用 classification_report 函数生成这些评估指标:
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “客户流失” 获取。👈👈👈
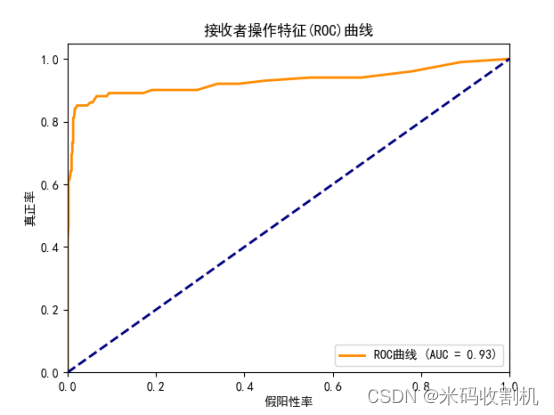
fpr, tpr, thresholds = roc_curve(y_test, y_pred_prob)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC曲线 (AUC = %0.2f)' % auc(fpr, tpr))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('假阳性率')
plt.ylabel('真正率')
plt.title('接收者操作特征(ROC)曲线')
plt.legend(loc="lower right")
plt.show()
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “客户流失” 获取。👈👈👈
















 1315
1315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











