




 本文详细记录了Hadoop环境配置的全过程,从SSH无密码验证登录到环境变量配置,再到解决常见错误,如资源管理器与节点管理器进程缺失、命令未找到及权限问题等。并分享了使用不同JDK版本的教训。
本文详细记录了Hadoop环境配置的全过程,从SSH无密码验证登录到环境变量配置,再到解决常见错误,如资源管理器与节点管理器进程缺失、命令未找到及权限问题等。并分享了使用不同JDK版本的教训。
花了5个小时,终于把这个hadoop环境给配置好了,太考验人的耐心了,但也确实学到不少东西。其中最大的教训就是:如果按照网络上的教程或者视频安装某项软件时,应当严格按照他所安装的软件版本号(或者说老版本)来进行安装(有时新版本安装会出现各种新安装方式与新问题)。如果说,我安装的是jdk1.8以及hadoop2.7.1大概就不会出现我下面所说的这些问题了。
安装hadoop
0-使用ssh进行无密码验证登录
需要对ssh进行设置,在配置完hadoop后才能成功运行hadoop,不然在运行时会出现下面截图:

步骤如下:
首先运行ssh localhost
正常情况下是免密登录的,如果你还要输入密码的话,那就是你ssh没有配置好。这里要说一下的是ssh7.0之后就关闭了dsa的密码验证方式,如果你的秘钥是通过dsa生成的话,需要改用rsa来生成秘钥。
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
再次运行ssh localhost。如果不需要输入密码,说明ssh配置好了。
接下来,在配置完hadoop之后,再运行hadoop,执行如下指令:start-all.sh就可以了。
1-从官网下载hadoop
这里有两种方法,如下:
- 第一种:从官网下载tar.gz后缀名的linux下的压缩包到win10系统下,然后通过Xshell的FTP插件或者
rz指令来从win10中上传该压缩包到linux的当前用户目录下。 - 第二种:直接利用wget命令
wget http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz
这里需要注意一点—下载网址不能直接从浏览器的网址栏目中赋值,而应当复制官方提供的下载网址(就是点一下会弹出下载到本地窗口的那种)。两种方法相比,第二种很明显比第一种要快速很多很多(再提一句,下载jdk不能使用第二种,因为官网有个accept框需要同意)
2-解压缩压缩包到指定文件夹
这里可以随意指定一个文件夹,但linux系统下,通常usr/local目录下习惯存储
本地用户(local目录下)的应用程序与工具(usr目录下),所以这里我也会把该压缩包解压到该目录下。命令如下:
tar -zxvf hadoop-3.2.1.tar.gz -C /usr/local/hadoop3.2.1
3-配置相关文件
hadoop3.2.1目录下的etc/hadoop中共四个文件需要配置:hadoop-env.sh,core-site.xml,mapred-site.xml,hdfs-site.xml
1.配置hadoop-env.sh
执行命令vim hadoop-env.sh
设置JAVA_HOME: export JAVA_HOME=/usr/local/jdk-1.8(这里是安装jdk时配置的java环境变量)
2.core-site.xml 配置如下:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/leesf/program/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
其中的hadoop.tmp.dir的路径可以根据自己的习惯进行设置。
3.mapred-site.xml.template配置如下:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
4.hdfs-site.xml配置如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/leesf/program/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/leesf/program/hadoop/tmp/dfs/data</value>
</property>
</configuration>
其中dfs.namenode.name.dir和dfs.datanode.data.dir的路径可以自由设置,最好在hadoop.tmp.dir的目录下面。
4-将hadoop添加到环境变量中
vim /etc/profile
profile中存储的就是很多配置的环境变量
配置结果如图: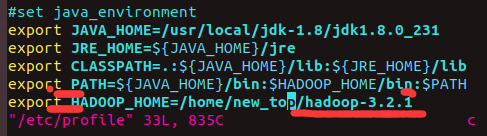
保存该文件之后,source /etc/profile使此配置立即生效.—该指令在修改上面四个hadoop配置文件时也可以使用一下, 来进行更新。
然后,输入hadoop若出现
至此,hadoop配置完成。
5-运行Hadoop
- 初始化HDFS系统
在hadop2.7.1目录下使用如下命令:
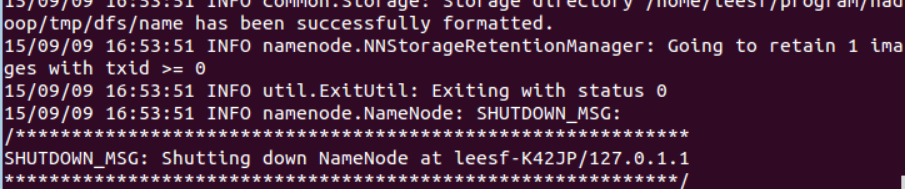
bin/hdfs namenode -format
截图如下:
过程需要进行ssh免密验证,这里只需要输入y继续运行即可
运行成功的截图如下:
- 开启NameNode和DataNode守护进程
使用命令:sbin/start-all.sh。
然后使用命令:jps。若出现截图
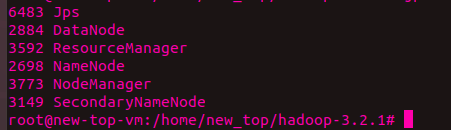
就代表运行成功。
然而就是这里出现了最多的问题,具体如下:
①jps或者java命令使用后,显示没有resourceMananger与NodeManager这两个进程,如下:
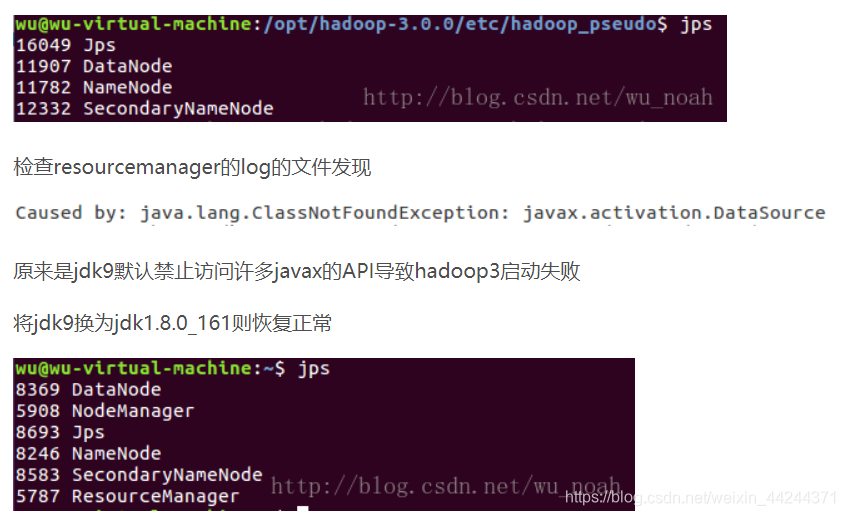
好,那么问题又来了,如何切换jdk版本呢?有如下三种方法:
1. 从官网下载jdk1.8(与jdk8一样,只是名字不同),解压到usr/local/下的自定义目录,然后配置相关环境变量(/etc/profile中),因为我之前已经安装了jdk13,所以这里配置时只需要把相应位置的名称换一下。最后source /etc/profile即可。—这种是配置文件进行改变,比较麻烦。
2. 通过alternative命令进行切换—见: jdk版本切换-系统命令版
3. 通过自定义命令进行切换----见:jdk版本切换-自定义命令版
② 执行jps与java时,显示找不到的命令。原因是在切换到root目录时使用的是:su root而不是su - root,su - root 才是真正的完全切换,包括将环境变量也切换过去
③执行sbin/start-all.sh时,出现如下截图:
Starting namenodes on [namenode]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [datanode1]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
解决办法:
在Hadoop安装目录下找到sbin文件夹,在里面修改四个文件:
1、对于start-dfs.sh和stop-dfs.sh文件,添加下列参数:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
2、对于start-yarn.sh和stop-yarn.sh文件,添加下列参数:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
之后再start一次即可

















 1063
1063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









